08 aug. 2025·8 min
Roy Fieldings REST: Begränsningar som formar moderna webb-API:er
Förstå Roy Fieldings REST-begränsningar och hur de påverkar praktisk API- och webbappdesign: client–server, tillståndslöshet, caching, enhetligt gränssnitt, lager och mer.
Varför Roy Fieldings REST fortfarande spelar roll
Roy Fielding är inte bara ett namn kopplat till ett API-buzzword. Han var en av huvudförfattarna till HTTP- och URI-specifikationerna och beskrev i sin doktorsavhandling en arkitekturstil kallad REST (Representational State Transfer) för att förklara varför webben fungerar så bra.
Den här bakgrunden är viktig eftersom REST inte uppfanns för att skapa “snygga endpoints.” Det var ett sätt att beskriva de begränsningar som låter ett globalt, rörigt nätverk skala: många klienter, många servrar, mellanhänder, caching, partiella fel och ständig förändring.
Vad du får ut av det här inlägget
Om du någonsin undrat varför två “REST API:er” känns helt annorlunda — eller varför ett litet designval senare blir till pagineringsproblem, cacheförvirring eller brytande ändringar — är den här guiden tänkt att minska sådana överraskningar.
Du kommer gå härifrån med:
- tydligare beslutsunderlag när du designar eller utvärderar ett API
- ett bättre vokabulär för att diskutera avvägningar med ditt team
- en praktisk känsla för vilka REST-idéer som faktiskt spelar roll i verkliga projekt
REST på en sida: Stil, inte en standard
REST är inte en checklista, ett protokoll eller en certifiering. Fielding beskrev det som en arkitekturstil: en uppsättning begränsningar som, när de tillämpas tillsammans, skapar system som skalar som webben — enkla att använda, kapabla att utvecklas över tid och vänliga mot mellanhänder (proxies, caches, gateways) utan ständig koordinering.
Problemet REST löste
Den tidiga webben behövde fungera över många organisationer, servrar, nätverk och klienttyper. Den måste växa utan central kontroll, överleva partiella fel och låta nya funktioner dyka upp utan att bryta gamla. REST adresserar det genom att favorisera ett litet antal vida delade koncept (som identifierare, representationer och standardoperationer) framför skräddarsydda, tätt koppade kontrakt.
“Arkitekturella begränsningar” på enkelt språk
En begränsning är en regel som begränsar designfriheten i utbyte mot fördelar. Till exempel kan du offra server-side sessionstillstånd så att förfrågningar kan hanteras av vilken servernod som helst, vilket förbättrar tillförlitlighet och skalning. Varje REST-begränsning gör en liknande uppoffring: mindre ad-hoc-flexibilitet, mer förutsägbarhet och möjligheten att utvecklas.
REST vs. “REST-liknande” API:er
Många HTTP-API:er lånar REST-idéer (JSON över HTTP, URL-endpoints, kanske statuskoder) men applicerar inte hela uppsättningen begränsningar. Det är inte “fel” — det speglar ofta produktdeadlines eller interna behov. Det är däremot användbart att kalla skillnaden vid namn: ett API kan vara resursorienterat utan att vara fullt REST.
Ett stycke mentalt modell
Tänk på ett REST-system som resurser (saker du kan namnge med URL:er) som klienter interagerar med genom representationer (en aktuell vy av resurserna, som JSON eller HTML), styrda av länkar (nästa åtgärder och relaterade resurser). Klienten behöver inga hemliga regler utanför kanalen; den följer standardsemantik och navigerar med länkar, precis som en webbläsare rör sig genom webben.
Resurser och representationer: Grundordförrådet
Innan vi går vilse i begränsningar och HTTP-detaljer börjar REST med ett enkelt förskjutet perspektiv: tänk i termer av resurser, inte åtgärder.
Resurs = ett substantiv du kan identifiera
En resurs är en adresserbar “sak” i ditt system: en användare, en faktura, en produktkategori, en kundvagn. Poängen är att det är ett substantiv med en identitet.
Därför läser /users/123 naturligt: det identifierar användaren med ID 123. Jämför med action-formade URL:er som /getUser eller /updateUserPassword. De beskriver verb — operationer — inte saken du opererar på.
REST säger inte att du inte kan utföra åtgärder. Det säger att åtgärder bör uttryckas genom det enhetliga gränssnittet (för HTTP-API:er betyder det vanligtvis metoder som GET/POST/PUT/PATCH/DELETE) som verkar på resursidentifierare.
Representation = en vy av resursen
En representation är vad du skickar över nätet som en ögonblicksbild eller vy av en resurs vid en tidpunkt. Samma resurs kan ha flera representationer.
Till exempel kan resursen /users/123 representeras som JSON för en app eller HTML för en webbläsare.
GET /users/123
Accept: application/json
Kan returnera:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
Medan:
GET /users/123
Accept: text/html
Kan returnera en HTML-sida som renderar samma användarinformation.
Huvudidén: resursen är inte JSON och den är inte HTML. De är bara format som används för att representera den.
Varför detta synsätt ändrar API-design
När du modellerar ditt API kring resurser och representationer blir flera praktiska beslut enklare:
- Namngivning blir stabilare.
/users/123förblir giltig även om ditt UI, arbetsflöden eller datamodell förändras. - Endpoints blir enklare. Istället för att uppfinna en ny URL för varje operation återanvänder du resurs-URL:er och varierar metod eller representation.
- Klientkod blir mindre kopplad. Klienter fokuserar på “hämta användaren” eller “uppdatera fält på användaren” snarare än att memorera ett katalog av action-endpoints.
Detta resursorienterade tänkesätt är grunden som REST-begränsningarna bygger på. Utan det blir “REST” ofta bara “JSON över HTTP med trevliga URL-mönster.”
Begränsning 1: Klient–server-separation
Klient–server-separation är REST:s sätt att upprätthålla en ren uppdelning av ansvar. Klienten fokuserar på användarupplevelsen (vad människor ser och gör), medan servern fokuserar på data, regler och persistens (vad som är sant och vad som är tillåtet). När du håller dessa bekymmer isär kan varje sida förändras utan att tvinga fram en omskrivning av den andra.
Vad ligger på klienten respektive servern?
I vardagstermer är klienten “presentationslagret”: skärmar, navigation, formulärvalidering för snabb återkoppling och optimistisk UI-beteende (som att visa en ny kommentar omedelbart). Servern är “sanningskällan”: autentisering, auktorisation, affärsregler, datalagring, revision och allt som måste vara konsekvent över enheter.
En praktisk regel: om ett beslut påverkar säkerhet, pengar, behörigheter eller delad datakonsistens hör det hemma på servern. Om ett beslut bara påverkar hur upplevelsen känns (layout, lokala input-hints, laddningstillstånd) hör det hemma på klienten.
Varför det passar moderna appmönster
Denna begränsning kartlägger direkt till vanliga upplägg:
- SPA + API: en webapp (React/Vue/etc.) itererar på UI medan API:t fortsätter leverera resurser.
- Mobila appar: iOS- och Android-klienter kan dela samma serverregler och endpoints.
- Tredjepartsintegrationer: partners använder samma serverkapacitet utan att behöva ditt UI.
Klient–server-separation gör “en backend, många frontender” realistiskt.
Vanlig fallgrop: läckage av UI-tillstånd in i serversessioner
Ett vanligt misstag är att lagra UI-arbetsflödestillstånd på servern (t.ex. “vilket steg i checkout användaren är på”) i en server-side session. Det kopplar backend till ett särskilt skärmflöde och gör skalning svårare.
Skicka hellre nödvändig kontext med varje förfrågan (eller härled den från lagrade resurser), så servern fokuserar på resurser och regler — inte på att komma ihåg hur en viss UI utvecklas.
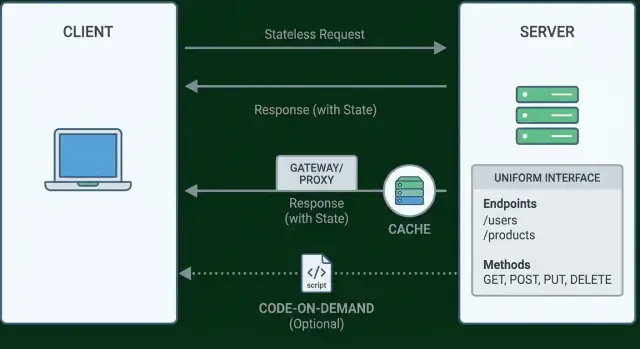
Begränsning 2: Tillståndslösa interaktioner
Tillståndslöshet betyder att servern inte behöver komma ihåg något om en klient mellan förfrågningar. Varje förfrågan bär all information som krävs för att förstå den och svara korrekt — vem som kallar, vad de vill och vilken kontext som behövs för att bearbeta den.
Varför detta spelar roll
När förfrågningar är oberoende kan du lägga till eller ta bort servrar bakom en load balancer utan att oroa dig för “vilken server som vet min session.” Det förbättrar skalbarhet och motståndskraft: vilken instans som helst kan hantera vilken förfrågan som helst.
Det förenklar också drift. Felsökning blir ofta lättare eftersom full kontext syns i förfrågan (och loggar), istället för att vara gömd i server-side sessionsminne.
Avvägningar du märker i verkliga API:er
Tillståndslösa API:er skickar ofta lite mer data per anrop. Istället för att lita på en lagrad serversession inkluderar klienter autentiseringsuppgifter och kontext varje gång.
Du måste också vara explicit om “stateful” användarflöden (som paginering eller flerstegs-checkout). REST förbjuder inte flerstegsupplevelser — det skjuter bara över tillståndet till klienten eller till server-side resurser som är identifierbara och hämtbara.
Praktiska mönster (och vad de löser)
- Auth-tokens (t.ex. Bearer JWTs): Varje förfrågan inkluderar en
Authorization: Bearer …-header så vilken server som helst kan autentisera den. - Idempotency-nycklar: För operationer som “skapa betalning” skickar klienter en
Idempotency-Keyså retries inte duplicerar arbete. - Correlation IDs: En header som
X-Correlation-Idlåter dig spåra en användaråtgärd över tjänster och loggar i ett distribuerat system.
För paginering: undvik att “servern kommer ihåg sida 3.” Föredra explicita parametrar som ?cursor=abc eller en next-länk som klienten kan följa, och håll navigeringstillstånd i svaren i stället för i serverminnet.
Begränsning 3: Cachebara svar
Exportera din källkod
Få full källaexport så ni kan fortsätta förfina API-kontrakt och implementation i teamet.
Caching handlar om att återanvända ett tidigare svar säkert så att klienten (eller något emellan) inte behöver be din server göra samma arbete igen. Görs rätt minskar det latens för användare och belastning för dig — utan att ändra API:ets mening.
Vad “cachebar” betyder i praktiken
Ett svar är cachebart när det är säkert att ett annat anrop får samma payload under en viss tid. I HTTP uttrycker du detta med cache-headers:
Cache-Control: huvudkontrollen (hur länge, om det kan lagras i delade caches osv.)ETagochLast-Modified: validerare som låter klienter fråga “har detta ändrats?” och få ett billigt “not modified”-svarExpires: ett äldre sätt att ange färskhet, fortfarande förekommande
Detta är större än “webbläsarcache.” Proxies, CDNs, API-gateways och till och med mobila appar kan återanvända svar när reglerna är tydliga.
Vad som oftast är säkert att cachea (och vad som inte är det)
Bra kandidater:
- Offentlig, identisk-för-alla-data (produktkataloger, dokumentation, feature flags som inte är användarspecifika)
- Read-only-resurser som ändras sällan (statisk konfiguration, referensdata)
- GET-svar som inte beror på cookies eller auktorisation
Oftast dåliga kandidater:
- Personliga data knutna till ett konto (profiler, ordrar, meddelanden)
- Auth-relaterade svar (tokenutbyten, sessionsstatus)
- Allt som varierar per användare om du inte explicit hanterar det (t.ex. med
privatecaching-regler)
Praktiska utfall du kommer märka
- Snabbare sidor och rappare appar (mindre väntan på nätverket)
- Lägre server- och databas-kostnader (färre upprepade beräkningar)
- Färre “rate limit”-incidenter (cached reads minskar antalet anrop)
Nyckelidén: caching är inte en eftertanke. Det är en REST-begränsning som belönar API:er som kommunicerar färskhet och validering tydligt.
Begränsning 4: Det enhetliga gränssnittet (vad det egentligen betyder)
Det enhetliga gränssnittet misstolkas ofta som “använd GET för läsning och POST för skapande.” Det är bara en liten del. Fieldings idé är större: API:er ska kännas tillräckligt konsekventa så att klienter inte behöver specialkunskap endpoint-för-endpoint för att använda dem.
De fyra delarna av det enhetliga gränssnittet
-
Identifiering av resurser: Du namnger saker (resurser) med stabila identifierare (vanligtvis URL:er), inte åtgärder. Tänk
/orders/123, inte/createOrder. -
Manipulation via representationer: Klienter ändrar en resurs genom att skicka en representation (JSON, HTML osv.). Servern kontrollerar resursen; klienten byter representationer av den.
-
Självbeskrivande meddelanden: Varje förfrågan/svar bör bära tillräcklig information för att förstå hur den ska behandlas — metod, statuskod, headers, mediatyp och en tydlig kropp. Om betydelsen göms i dokumentation utanför meddelandet blir klienter tätt kopplade.
-
Hypermedia (HATEOAS): Svar bör inkludera länkar och tillåtna åtgärder så klienter kan följa arbetsflödet utan att hårdkoda varje URL-mönster.
Varför det minskar kopplingen
Ett konsekvent gränssnitt gör klienter mindre beroende av interna serverdetaljer. Med tiden betyder det färre brytande ändringar, färre “specialfall” och mindre omarbete när teamen utvecklar endpoints.
Praktiska tumregler du kan applicera
- Använd statuskoder konsekvent: t.ex.
200för lyckade läsningar,201för skapade resurser (medLocation),400för valideringsfel,401/403för auth,404när en resurs inte finns. - Standardisera ditt error-format över API:t. Exempel på fält:
code,message,details,requestId. - Håll mediatyper och headers meningsfulla (
Content-Type, cache-headers), så meddelanden förklarar sig själva.
Det enhetliga gränssnittet handlar om förutsägbarhet och utvecklingsbarhet, inte bara “rätt verb.”
Självbeskrivande meddelanden: design för förståelse
Distribuera med rollback
Distribuera och hosta din app, använd snapshots och rollback när ändringar går fel.
Ett “självbeskrivande” meddelande är ett som berättar för mottagaren hur det ska tolkas — utan att kräva out-of-band tribal knowledge. Om en klient (eller mellanhand) inte kan förstå vad ett svar betyder bara genom att titta på HTTP-headers och kroppen har du skapat ett privat protokoll som åker med HTTP.
Använd mediatyper för att förklara payloaden
Det enklaste är att vara explicit med Content-Type (vad du skickar) och ofta Accept (vad du vill ha tillbaka). Ett svar med Content-Type: application/json talar om grundläggande parsningregler, men du kan gå längre med vendor- eller profilbaserade mediatyper när betydelsen är viktig.
Exempel på angreppssätt:
- Generisk mediatyp + stabila fält:
application/jsonmed ett noga underhållet schema. Lättast för de flesta team. - Vendor-mediatyper:
application/vnd.acme.invoice+jsonför att signalera en specifik representation. - Profiler: behåll
application/json, lägg till enprofile-parameter eller länk till en profil som definierar semantiken.
Versionering och kompabilitet (utan att bryta klienter)
Versionering ska skydda befintliga klienter. Populära alternativ inkluderar:
- URL-versionering (
/v1/orders): tydligt, men kan uppmuntra “forking” av representationer istället för att utveckla dem. - Header- eller mediatypversionering (via
Accept): håller URL:er stabila och gör “vad detta betyder” till en del av meddelandet. - Additiv evolution: föredra att lägga till nya fält och behålla gamla; deprecera gradvis.
Oavsett val, sikta på bakåtkompatibilitet som standard: byt inte namn på fält lättvindigt, ändra inte betydelser tyst och behandla borttagningar som brytande ändringar.
Konsekventa fel och tydlig namngivning
Klienter lär sig snabbare när fel ser likadana ut överallt. Välj en felform (t.ex. code, message, details, traceId) och använd den konsekvent. Använd tydliga, förutsägbara fältnamn (createdAt vs created_at) och håll dig till en konvention.
Dokumentation hjälper — men tydligheten måste leva i meddelandet
Bra dokumentation accelererar adoption, men den kan inte vara den enda platsen där betydelsen finns. Om en klient måste läsa en wiki för att veta om status: 2 betyder “paid” eller “pending”, är meddelandet inte självbeskrivande. Väl utformade headers, mediatyper och läsbara payloads minskar det behovet och gör systemen enklare att utveckla.
Hypermedia (HATEOAS): Den mest förbisedda REST-idén
Hypermedia (sammanfattat HATEOAS: Hypermedia As The Engine Of Application State) betyder att en klient inte behöver “känna” API:ets nästa URL:er i förväg. Istället innehåller varje svar upptäckbara nästa steg som länkar: vart man ska gå härnäst, vilka åtgärder som är möjliga och ibland vilken HTTP-metod man ska använda.
Hur det ser ut i praktiken
I stället för att hårdkoda vägar som /orders/{id}/cancel, följer klienten länkar som servern skickar. Servern säger i praktiken: “Givet resursens nuvarande tillstånd, här är giltiga drag.”
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
Om ordern senare blir paid kan servern sluta inkludera cancel och istället lägga till refund — utan att bryta en väluppförd klient.
När hypermedia hjälper mest
Hypermedia glänser när flöden utvecklas: onboarding-steg, checkout, godkännanden, prenumerationer eller processer där “vad som är tillåtet härnäst” ändras beroende på tillstånd, behörigheter eller affärsregler.
Det minskar också hårdkodade URL:er och sköra klientantaganden. Du kan omorganisera rutter, introducera nya åtgärder eller avskriva gamla medan klienter fortfarande fungerar, så länge du bevarar länkrelationernas betydelse.
Varför team hoppar över det (och vad de förlorar)
Team hoppar ofta över HATEOAS eftersom det kan kännas som extra arbete: definiera länkformat, komma överens om relationsnamn och lära klientutvecklare att följa länkar i stället för att konstruera URL:er.
Vad du förlorar är en nyckelREST-fördel: lös koppling. Utan hypermedia blir många API:er “RPC över HTTP” — de använder HTTP, men klienter är fortfarande starkt beroende av dokumentation utanför systemet och fasta URL-mallar.
Begränsning 5: Lagerindelat system
Ett lagerindelat system betyder att en klient inte behöver veta (och ofta inte kan se) om den pratar med den verkliga origin-servern eller med intermediärer på vägen. Lagerna kan inkludera API-gateways, reverse proxies, CDNs, auth-tjänster, WAFs, service-meshes och intern routing mellan mikrotjänster.
Varför lager är användbara
Lager skapar rena gränser. Security-team kan upprätthålla TLS, rate limits, autentisering och request-validering i kanten utan att ändra varje backend-tjänst. Operations-team kan skala horisontellt bakom en gateway, lägga till caching i en CDN eller skifta trafik vid incidenter. För klienter kan det förenkla: en stabil API-endpoint, konsekventa headers och förutsägbara error-format.
Avvägningarna du märker i praktiken
Intermediärer kan introducera dold latens (extra hopp, extra handskakningar) och göra felsökning svårare: buggen kan ligga i gateway-reglerna, CDN-cachen eller origin-koden. Caching blir också förvirrande när olika lager cacher olika eller när en gateway skriver om headers som påverkar cache-nycklar.
Praktiska tips som hindrar lager från att skada
- Använd tracing-IDs end-to-end: acceptera eller generera ett request-id och propagéra det genom varje hopp; inkludera det i svar och loggar.
- Gör felpropagering tydlig: standardisera felkroppar och mappa upstream-fel tydligt (förvandla inte varje problem till en generisk 500).
- Sätt timeouter per hopp: gateway-timeouter, upstream-timeouter och klient-timeouter bör vara synkade för att undvika mysteriedisconnects.
- Dokumentera cachingbeteende: var tydlig med vilka svar som är cachebara och vilka headers mellanhänder måste bevara.
Lager är kraftfulla — när systemet förblir observerbart och förutsägbart.
Begränsning 6 (valfri): Code-on-Demand
Planera innan du kodar
Använd Planning Mode för att kartlägga resurser, representationer och versionsval i förväg.
Code-on-demand är den ena REST-begränsningen som är uttryckligen valfri. Den betyder att en server kan utöka en klient genom att skicka exekverbar kod som körs på klientsidan. Istället för att skicka all logik i klienten i förväg kan klienten ladda ny logik vid behov.
Webben som bekant exempel: JavaScript
Om du någonsin laddat en webbsida som sedan blir interaktiv — validerar ett formulär, renderar en graf, filtrerar en tabell — har du redan använt code-on-demand. Servern levererar HTML och data, plus JavaScript som körs i webbläsaren för att ge beteende.
Detta är en stor anledning till att webben kan utvecklas snabbt: webbläsaren är en generaliserad klient medan sidor levererar ny funktionalitet utan att användaren måste installera en hel ny applikation.
Varför det är valfritt (och varför många API:er hoppar över det)
REST fungerar fortfarande utan code-on-demand eftersom de andra begränsningarna redan möjliggör skalbarhet, enkelhet och interoperabilitet. Ett API kan vara rent resursorienterat — leverera representationer som JSON — medan klienter implementerar sitt eget beteende.
Flera moderna web API:er undviker att skicka exekverbar kod eftersom det komplicerar:
- Säkerhet: exekverbar kod är en större attackyta (injektion, supply-chain-problem, skadliga skript).
- Content policies: webbläsare tillämpar Content Security Policy (CSP) och organisationer kan blockera inline-skript eller okända origin.
- Revision och efterlevnad: det är svårare att bevisa vilken kod som kördes på en klient vid en given tidpunkt om den hämtas dynamiskt.
När code-on-demand fortfarande kan vara relevant
Code-on-demand kan vara användbart när du kontrollerar klientmiljön och vill rulla ut UI-beteende snabbt, eller när du vill ha en tunn klient som laddar “plugins” eller regler från servern. Men behandla det som ett extra verktyg, inte ett krav.
Huvudslutsatsen: du kan fullt ut följa REST utan code-on-demand — och många produktions-API:er gör det — eftersom begränsningen handlar om valfri utbyggbarhet, inte grunden för resursorienterad interaktion.
Tillämpa REST idag: Praktiska val och vanliga misstag
De flesta team förkastar inte REST — de antar en “REST-ish” stil som behåller HTTP som transport samtidigt som viktiga begränsningar tyst droppas. Det kan vara okej, så länge det är ett medvetet val och inte en olycka som senare visar sig i sköra klienter och dyra omskrivningar.
Vanliga REST-ish genvägar (och varför de händer)
Några mönster återkommer:
- RPC-endpoints:
/doThing,/runReport,/users/activate— lätta att namnge och koppla ihop. - Verb-tunga URL:er:
/createOrder,/updateProfile,/deleteItem— HTTP-metoder blir eftertanke. - Dolda sessioner: “Tillståndslösa” API:er som ändå förlitar sig på sticky sessions, serverminne eller implicit arbetsflödestillstånd.
Dessa val känns ofta produktiva tidigt eftersom de speglar interna funktionsnamn och affärsoperationer.
Konsekvenser du märker senare
- Sköra klienter: Om klienter beror på specifika endpointformer och ad-hoc-beteenden blir små refaktoreringar brytande.
- Svår versionering: När URL:er kodar in åtgärder i stället för stabila resurser, versionerar du beteende i stället för att utveckla representationer.
- Cache-missar (och högre latens): Att ignorera cache-headers eller använda POST för allt förhindrar intermediärer (och webbläsare) från att hjälpa dig.
- Skalningsproblem: Doldt server-side sessionstillstånd komplicerar horisontell skalning och gör återställning vid fel svårare.
En pragmatisk checklist för att stämma av
Använd detta som en “hur REST-är-vi, egentligen?”-granskning:
- Namnge resurser, inte åtgärder: föredra
/orders/{id}framför/createOrder. - Använd HTTP-metoder med eftertanke: GET för läsning, POST för skapande, PUT/PATCH för uppdateringar, DELETE för borttagning.
- Gör förfrågningar oberoende: inget serversessionstillstånd krävs för att förstå “vilket steg klienten är på.”
- Utnyttja caching där det är säkert: definiera
Cache-Control,ETagochVaryför GET-svar. - Standardisera fel och mediatyper: konsekventa statuskoder och svarformer minskar specialfall.
Var detta visar sig när du faktiskt bygger
REST-begränsningar är inte bara teori — de är riktlinjer du känner av när du levererar. När du snabbt genererar ett API (t.ex. scaffoldar ett React-frontend med en Go + PostgreSQL-backend) är det enklaste misstaget att låta “vad som går snabbast att koppla” bestämma ditt gränssnitt.
Om du använder en vibe-coding-plattform som Koder.ai för att bygga en webapp från chatt hjälper det att ta med dessa REST-begränsningar tidigt i samtalet — namnge resurser först, håll dig tillståndslös, definiera konsekventa felformer och bestäm var caching är säker. Då kan även snabb iteration producera API:er som är förutsägbara för klienter och lättare att vidareutveckla. (Och eftersom Koder.ai stödjer export av källkod kan du fortsätta förfina API-kontraktet och implementationen när kraven växer.)
Slutsatser för API- och webbappsteam
Definiera dina nyckelresurser först och välj sedan begränsningar medvetet: om du hoppar över caching eller hypermedia, dokumentera varför och vad du använder istället. Målet är inte renlärighet — det är tydlighet: stabila resursidentifierare, förutsägbara semantiker och explicita avvägningar som håller klienter motståndskraftiga när systemet utvecklas.
Vanliga frågor
Vad menade Roy Fielding med “REST”, och varför är det inte en standard?
REST (Representational State Transfer) är en arkitekturstil som Roy Fielding beskrev för att förklara varför webben kan skalas så väl.
Det är inte ett protokoll eller en certifiering — det är en uppsättning begränsningar (client–server, statelessness, cachebarhet, enhetligt gränssnitt, lagerindelat system, valfri code-on-demand) som byter bort viss flexibilitet mot skalbarhet, utvecklingsbarhet och interoperabilitet.
Varför känns två “REST API:er” ofta helt olika?
Många API:er tar bara med vissa REST-idéer (till exempel JSON över HTTP och trevliga URL:er) men hoppar över andra (som cache-regler eller hypermedia).
Två “REST API:er” kan kännas mycket olika beroende på om de:
- modellerar stabila resurser vs. action-endpoints
- använder HTTP-semantik konsekvent (metoder, statuskoder, headers)
- stödjer caching och intermediärer
- minskar koppling till klienten med upptäckbara länkar
Vad är den praktiska skillnaden mellan “resurser” och “åtgärder” i URL-design?
En resurs är ett * substantiv * du kan identifiera (t.ex. /users/123). En action-endpoint är ett verb inbakad i URL:en (t.ex. /getUser, /updatePassword).
Resursorienterad design åldras ofta bättre eftersom identifierare förblir stabila medan arbetsflöden och UI ändras. Handlingar kan fortfarande finnas, men uttrycks vanligtvis via HTTP-metoder och representationer istället för verb-formade sökvägar.
Vad är en “representation”, och varför är resursen inte JSON?
En resurs är konceptet (“användaren 123”). En representation är ögonblicksbilden du överför (JSON, HTML osv.).
Detta är viktigt eftersom du kan utveckla eller lägga till representationer utan att ändra resursens identifierare. Klienter bör bygga logik kring resursens betydelse, inte kring ett specifikt payload-format.
Hur hjälper client–server-separation verkliga API-team?
Client–server-separation håller ansvarskedjorna isär:
- Klient: UI, interaktion, navigation, lokal validering, laddningsstatus
- Server: autentisering/auktorisation, affärsregler, persistens, revision
Om ett beslut påverkar säkerhet, pengar, behörigheter eller delad konsistens så hör det hemma på servern. Denna separation möjliggör “en backend, många frontender” (webb, mobil, partners).
Vad betyder “stateless” för ett HTTP API, och vad förändras i praktiken?
Tillståndslöshet innebär att servern inte förlitar sig på lagrat klient-sessionstillstånd för att förstå en förfrågan. Varje förfrågan innehåller vad som behövs (auth + kontext).
Fördelar: enklare horisontell skalning (vilken nod som helst kan hantera förfrågan) och enklare felsökning (kontekst syns i loggarna).
Vanliga mönster:
Vilka cache-headers är viktigast, och när ska jag använda dem?
Cachebara svar låter klienter och intermediärer återanvända tidigare svar säkert, vilket minskar latens och belastning.
Praktiska HTTP-verktyg:
Cache-Controlför freshness och scope- / för validering ()
Är REST bara “använd GET/POST/PUT/DELETE korrekt”, eller är det mer än så?
Det enhetliga gränssnittet handlar om konsekvens så att klienter inte behöver specialkunskap för varje endpoint.
I praktiken: fokusera på stabila resursidentifierare, korrekt användning av HTTP-metoder, konsekventa statuskoder (, + , , , ) och en standardiserad felkropp (t.ex. , , , ).
Vad är HATEOAS (hypermedia), och när är det värt att göra?
Hypermedia innebär att svar innehåller länkar till giltiga nästa åtgärder, så klienter följer länkar i stället för att hårdkoda URL-mallar.
Det hjälper mest när flöden ändras beroende på tillstånd eller rättigheter (checkout, godkännanden, onboarding). En klient kan förbli robust om servern lägger till eller tar bort tillåtna åtgärder genom att ändra länkuppsättningen.
Team hoppar ofta över detta eftersom det kräver designarbete (länkformat, relation-namn), men priset är tätare koppling till dokumentation och fasta rutter.
Hur påverkar “lagerindelade system” API-beteende, prestanda och felsökning?
Ett lagerindelat system tillåter intermediärer (CDN:er, gateways, proxys, auth-lager) så klienter inte behöver veta vilken komponent som svarade.
För att undvika att lager blir en felsökningsfälla:
- propagiera ett request/correlation ID genom varje hopp
- håll felmappning explicit (vänd inte allt till en generell
500) - synkronisera timeouter per hopp (klient, gateway, upstream)
- dokumentera cachingbeteende och bevara cache-relevanta headers
Lager är en styrka när systemet förblir observerbart och förutsägbart.