31 aug. 2025·6 min
Schemändringar utan driftstopp med expand/contract-mönstret
Lär dig schemaändringar utan driftstopp med expand/contract-mönstret: lägg till kolumner säkert, backfilla i batchar, deploya kompatibel kod och ta bort gamla vägar.
Varför schemändringar orsakar driftstopp
Driftstopp från en databasändring är inte alltid ett rent, tydligt avbrott. För användare kan det se ut som en sida som laddar för länge, en checkout som misslyckas eller en app som plötsligt visar "något gick fel." För team syns det som alerts, ökade felgrader och en backlog av misslyckade skrivningar som måste städas upp.
Schemändringar är riskfyllda eftersom databasen delas av varje körande version av din app. Under en release har du ofta gammal och ny kod live samtidigt (rolling deploys, flera instanser, bakgrundsjobb). En migration som ser korrekt ut kan ändå bryta en av de versionerna.
Vanliga felorsaker inkluderar:
- Ny kod skriver till en kolumn som ännu inte finns, vilket ger omedelbara fel.
- Gammal kod läser en kolumn eller tabell som en migration har bytt namn på eller tagit bort, vilket orsakar krascher efter deploy.
- Ett backfill eller en indexbyggnad spikar CPU eller låser rader, vilket gör vanliga förfrågningar långsamma eller tidsutlösta.
- En "snabb" constraint-ändring (som NOT NULL) blockerar skrivningar medan tabellen kontrolleras.
Även när koden är bra blir releaser blockerade eftersom det verkliga problemet är timing och kompatibilitet över versioner.
Schemaändringar utan driftstopp handlar om en regel: varje mellanläge måste vara säkert för både gammal och ny kod. Du förändrar databasen utan att bryta befintliga läsningar och skrivningar, levererar kod som kan hantera båda formaten och tar bara bort den gamla vägen när inget längre beror på den.
Den extra ansträngningen är värd det när du har riktig trafik, strikta SLA:er eller många appinstanser och arbetare. För ett litet internt verktyg med låg belastning kan ett planerat underhållsfönster vara enklare.
Expand/contract med enkla ord
De flesta incidenter från databasarbete händer för att appen förväntar sig att databasen ändras omedelbart, medan databasen tar tid på sig. Expand/contract-mönstret undviker det genom att dela upp en riskfylld ändring i mindre, säkra steg.
Under en kort period stödjer systemet två "dialekter" samtidigt. Du introducerar den nya strukturen först, håller den gamla igång, flyttar data gradvis och städar sedan upp.
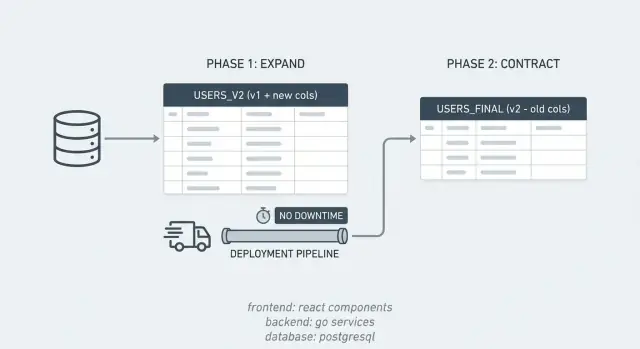
Mönstret är enkelt:
- Expand: lägg till det du behöver (kolumner, tabeller, index) utan att bryta den nuvarande appen.
- Kör båda vägarna: deploya kod som fungerar med gamla och nya strukturer så att blandade versioner fortfarande beter sig.
- Contract: när allt använder den nya strukturen, ta bort det gamla schemat och den gamla koden.
Det fungerar bra med rolling deploys. Om du uppdaterar 10 servrar en i taget kommer du att köra gamla och nya versioner tillsammans en kort stund. Expand/contract håller båda kompatibla med samma databas under det överlappet.
Det gör också rollbacks mindre skrämmande. Om en ny release har en bugg kan du rulla tillbaka appen utan att rulla tillbaka databasen, eftersom de gamla strukturerna finns kvar under expand-fönstret.
Ett exempel: du vill dela upp en PostgreSQL-kolumn full_name till first_name och last_name. Du lägger till de nya kolumnerna (expand), skickar kod som kan läsa och skriva båda formaten, backfillar gamla rader och tar sedan bort full_name när du är säker på att ingen använder den längre (contract).
Vad "expand" vanligtvis inkluderar
Expand-fasen handlar om att lägga till nya alternativ, inte att ta bort gamla.
Ett vanligt första steg är att lägga till en ny kolumn. I PostgreSQL är det oftast säkrast att lägga till den som nullable och utan default. Att lägga till en icke-null kolumn med default kan trigga en omskrivning av tabellen eller tyngre lås, beroende på din Postgres-version och ändringen. En säkrare sekvens är: lägg till nullable, deploya tolerant kod, backfilla och skärp sedan NOT NULL senare.
Index behöver också omvårdnad. Att skapa ett normalt index kan blockera skrivningar längre än du tror. När du kan, använd concurrent index creation så att läsningar och skrivningar fortsätter flyta. Det tar längre tid men undviker ett release-stoppande lås.
Expand kan också betyda att lägga till nya tabeller. Om du går från en enkel kolumn till en many-to-many-relation kan du lägga till en join-tabell medan du behåller den gamla kolumnen. Den gamla vägen fortsätter fungera medan den nya strukturen börjar samla data.
I praktiken inkluderar expand ofta:
- Att lägga till nya nullable-kolumner eller nya tabeller bredvid de befintliga
- Att lägga till index på icke-blockerande sätt när möjligt
- Att använda feature flags för att styra när nya läsningar eller skrivningar slås på
- Att skriva till både gamla och nya fält (dual-write) när det behövs
- Att hålla läsningar bakåtkompatibla (gammal, ny eller fallback)
Efter expand ska gamla och nya app-versioner kunna köras samtidigt utan överraskningar.
Deploya kod som förblir kompatibel
De flesta release-problem händer i mitten: vissa servrar kör ny kod, andra kör fortfarande gammal kod, medan databasen redan förändras. Ditt mål är enkelt: varje version i rollout ska fungera med både det gamla och det expanderade schemat.
Ett vanligt tillvägagångssätt är dual-write. Om du lägger till en ny kolumn skriver den nya appen till både den gamla och den nya kolumnen. Gamla appversioner fortsätter skriva endast det gamla fältet, vilket är okej eftersom det fortfarande finns. Håll den nya kolumnen valfri till en början och vänta med strikta constraints tills du är säker på att alla skrivare uppgraderats.
Läsningar byts vanligtvis försiktigare än skrivningar. Under en tid behålls läsningar på den gamla kolumnen (den du vet är fullt ifylld). Efter backfill och verifiering byter du läsningar till att föredra den nya kolumnen, med fallback till den gamla om den nya saknas.
Håll även ditt API-svar stabilt medan databasen ändras under ytan. Även om du introducerar ett internt fält, undvik att ändra responsformatet tills alla konsumenter är redo (webb, mobil, integrationer).
En rollback-vänlig rollout ser ofta ut så här:
- Release 1: lägg till den nya kolumnen och deploya kod som kan läsa gammal data och skriva båda kolumnerna.
- Release 2: backfilla befintliga rader och deploya kod som föredrar att läsa den nya kolumnen men kan falla tillbaka.
- Release 3: sluta skriva det gamla fältet (men behåll kolumnen).
- Release 4: ta bort gamla läsningar och ta sedan bort den gamla kolumnen.
Nyckelidén är att det första irreversibla steget är att droppa den gamla strukturen, så du skjuter upp det till slutet.
Backfilla data säkert (utan att överbelasta DB)
Snapshot innan schemarbete
Ta en snapshot innan riskabla ändringar så du kan återställa snabbt vid behov.
Backfilling är där många "schemaändringar utan driftstopp" går fel. Du vill fylla den nya kolumnen för befintliga rader utan långa lås, tunga queries eller överraskande belastningsspikar.
Batchning är viktig. Sikta på batcher som blir klara snabbt (sekunder, inte minuter). Om varje batch är liten kan du pausa, återuppta och finjustera jobbet utan att blockera releaser.
För att följa framsteg, använd en stabil cursor. I PostgreSQL är det ofta primärnyckeln. Processa rader i ordning och lagra det sista id du slutförde, eller jobba i id-intervall. Det undviker dyra full-table-scans när jobbet startas om.
Här är ett enkelt mönster:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
Gör uppdateringen villkorad (till exempel WHERE new_col IS NULL) så att jobbet blir idempotent. Omgångar som körs om rör bara rader som fortfarande behöver arbete, vilket minskar onödiga skrivningar.
Planera för ny data som anländer under backfillen. Vanligt ordningsföljd är:
- Uppdatera applikationskoden först så att nya skrivningar också fyller det nya fältet.
- Backfilla historiska rader i batchar.
- Kör en kort catch-up-loop som recheckar senaste rader.
- Om det behövs, lägg till en guardrail (som en trigger eller default) för att förhindra nya NULLs.
Ett bra backfill är tråkigt: stadigt, mätbart och enkelt att pausa om databasen blir het.
Verifiera att migrationen verkligen är klar
Det riskfylldaste ögonblicket är inte att lägga till den nya kolumnen. Det är att bestämma att du kan lita på den.
Innan du går till contract, bevisa två saker: den nya datan är komplett och produktion har läst den tryggt.
Börja med snabb- och upprepbara fullständighetskontroller:
- Bekräfta att den nya kolumnen inte har oväntade NULLs.
- Jämför hur många rader som var aktuella mot hur många som fylldes.
- Spot-checka ett handfull ID:n och jämför gamla vs nya värden.
- Testa edge-cases (tomma strängar, nollor, mycket gamla poster).
- Kör samma kontroller igen senare så att inget driver iväg.
Om du dual-writear, lägg till en konsistenskontroll för att fånga tysta buggar. Till exempel, kör en query timvis som hittar rader där old_value <> new_value och larma om det inte är noll. Detta är ofta det snabbaste sättet att upptäcka att en writer fortfarande bara uppdaterar det gamla fältet.
Övervaka grundläggande produktionssignaler medan migrationen kör. Om querytider eller lock-waits spikar kan även dina "säkra" verifieringsfrågor lägga belastning. Monitorera felgrader för kodvägar som läser den nya kolumnen, särskilt precis efter deploys.
Hur länge bör du behålla båda vägarna? Längre än ett fullständigt releasecykel och en backfill-omkörning. Många team använder 1–2 veckor, eller tills de är säkra på att inga gamla appversioner körs.
Contract-fasen: ta bort den gamla vägen
Contract är där team blir nervösa eftersom det känns som point of no return. Om expand gjordes rätt är contract mest städning, och du kan fortfarande dela upp det i små, lågrisksteg.
Välj tidpunkten noggrant. Ta inte bort något direkt efter ett backfill. Ge det åtminstone en full releasecykel så att fördröjda jobb och edge-cases hinner dyka upp.
En säker contract-sekvens ser vanligtvis ut så här:
- Sluta dual-write och bekräfta att nya skrivningar landar endast i den nya kolumnen.
- Ta bort gamla läsningar i applikationen så att fallback försvinner.
- Radera döda kodvägar, feature flags och bakgrundsjobb som refererar det gamla schemat.
- Ta bort temporära triggers, sync-jobb eller kompatibilitetsvyer.
- Droppa gamla index och constraints, och därefter droppa den gamla kolumnen.
Om du kan, dela upp contract i två releaser: en som tar bort kodreferenser (med extra loggning) och en senare som tar bort databasobjekten. Den separeringen gör rollback och felsökning mycket enklare.
PostgreSQL-specifika detaljer spelar roll här. Att droppa en kolumn är mest metadata, men det kräver ändå ett kort ACCESS EXCLUSIVE-lock. Planera för en lugn period och håll migrationen snabb. Om du skapade extra index, föredra att ta bort dem med DROP INDEX CONCURRENTLY för att undvika att blockera skrivningar (det kan inte köras i en transaction block, så ditt migrationsverktyg måste stödja det).
Vanliga misstag och fällor
Planera säkrare schemändringar
Gör ditt expand–contract-schema till konkreta uppgifter och checkpoints innan du rör produktion.
Schemaändringar utan driftstopp misslyckas när databasen och appen slutar vara överens om vad som är tillåtet. Mönstret fungerar bara om varje mellanläge är säkert för både gammal och ny kod.
Fällor som bryter produktion
Dessa misstag dyker upp ofta:
- Att lägga till NOT NULL för tidigt, medan en äldre appversion fortfarande kan skriva rader utan det nya fältet.
- Att backfilla en jättetabell i en transaktion, vilket kan hålla lås, orsaka bloat och ge timeouts.
- Att anta att en default är gratis. I PostgreSQL kan vissa defaults trigga en tabellomskrivning.
- Att byta läsningar till den nya kolumnen innan skrivningar pålitligt fyller den.
- Att glömma andra skrivare och läsare (cron-jobb, workers, export, rapporteringsqueries).
Ett realistiskt scenario: du börjar skriva full_name från API:t, men ett bakgrundsjobb som skapar användare sätter fortfarande bara first_name och last_name. Det körs på natten, insertar rader med full_name = NULL, och senare kod antar att full_name alltid finns.
Hur undvika att fastna mitt i en migration
Behandla varje steg som en release som kan köra i dagar:
- Håll den nya kolumnen nullable under övergången och gör fältet "required" i koden först.
- Backfilla i små batchar med pauser och övervaka DB-load.
- Gör koden tolerant: läs båda vägarna, skriv båda vägarna när det behövs, hantera saknade värden.
- Granska varje plats som rör tabellen, inklusive workers och rapportering.
Snabb checklista före varje release
En upprepad checklista hindrar dig från att skicka kod som bara fungerar i ett databasläge.
Innan du deployar, bekräfta att databasen redan har de expanderade delarna på plats (nya kolumner/tabeller, index skapade på ett låglåsstarkt sätt). Bekräfta sedan att appen är tolerant: den ska fungera mot det gamla formatet, det expanderade formatet och ett halvt backfillat tillstånd.
Håll checklistan kort:
- Expansion finns: nya schemaobjekt finns och lades till på ett lågt-lås-sätt.
- Kompatibilitet är verklig: appen fungerar med gammalt och expanderat schema, inklusive workers och adminvägar.
- Backfill är kontrollerad: små batchar, pausbar, med grundläggande framstegsmetrik.
- Läsbyte är planerat: du vet exakt när läsningar flyttas och hur du rollbackar om resultat ser fel ut.
- Contract skjuts upp: vänta minst en eller två releasecykler innan du droppar gamla objekt.
En migration är bara klar när läsningar använder den nya datan, skrivningar inte längre underhåller den gamla datan och du verifierat backfillen med åtminstone en enkel kontroll (räkningar eller sampling).
Ett realistiskt exempel: ersätt en kolumn utan driftstopp
Exportera den genererade koden
Behåll full äganderätt genom att exportera källkoden efter att ditt migrationsflöde är klart.
Anta att du har en PostgreSQL-tabell customers med en kolumn phone som lagrar röriga värden (olika format, ibland tomt). Du vill ersätta den med phone_e164, men du kan inte blockera releaser eller ta ner appen.
En ren expand/contract-sekvens ser ut så här:
- Expand: lägg till
phone_e164som nullable, utan default och utan tunga constraints än. - Kompatibel deploy: uppdatera koden för att skriva både
phoneochphone_e164, men behåll läsningar påphoneså att inget ändras för användarna. - Backfill: konvertera befintliga rader i små batchar (t.ex. 1000 åt gången).
- Byt läsningar: deploya kod som läser
phone_e164först och faller tillbaka tillphoneom den fortfarande är NULL. - Contract: när du är säker på att allt använder
phone_e164, ta bort fallbacken, droppaphoneoch lägg till striktare constraints om du fortfarande behöver dem.
Rollback förblir enkel när varje steg är bakåtkompatibelt. Om läsbytet orsakar problem, rulla tillbaka appen och databasen har fortfarande båda kolumnerna. Om backfill spikar load, pausa jobbet, minska batchstorleken och fortsätt senare.
Om du vill att teamet ska hålla sig samlat, dokumentera planen på ett ställe: exakt SQL, vilken release som flippar läsningar, hur du mäter färdig (t.ex. procent icke-NULL phone_e164) och vem som äger varje steg.
Nästa steg: gör det upprepbart
Expand/contract fungerar bäst när det känns rutinmässigt. Skriv en kort runbook ditt team kan återanvända för varje schemändring, helst en sida och tillräckligt specifik för att en ny kollega ska kunna följa den.
En praktisk mall täcker:
- Expand (exakta migrationer)
- Kodändringar (vad som måste förbli bakåtkompatibelt och var dual-read eller dual-write används)
- Backfill (batchstorlek, rate-limits, paus/återuppta)
- Verifiera (queries och metrik som bevisar korrekthet)
- Contract (vad som tas bort och när)
Bestäm ägarskap i förväg. "Alla trodde att någon annan skulle göra contract" är hur gamla kolumner och feature flags lever i månader.
Även om backfillen körs online, schemalägg den när trafiken är lägre. Det är enklare att hålla batchar små, övervaka DB-load och stoppa snabbt om latenser stiger.
Om du bygger och deployar med Koder.ai (koder.ai), kan Planning Mode vara ett användbart sätt att kartlägga faser och checkpoints innan du rör produktion. Samma kompatibilitetsregler gäller, men att ha stegen nedskrivna gör det svårare att hoppa över de tråkiga delarna som förhindrar driftstopp.
Vanliga frågor
Varför orsakar schemändringar driftstopp även när SQL ser korrekt ut?
Eftersom databasen delas av alla körande versioner av din app. Vid rolling deploys och bakgrundsjobb kan gammal och ny kod köras samtidigt, och en migration som byter namn, tar bort kolumner eller lägger till constraints kan bryta den version som inte är skriven för just det schema-läget.
Vad betyder “schemaändring utan driftstopp” egentligen?
Det betyder att du designar migrationen så att varje mellanliggande databasstatus fungerar för både gammal och ny kod. Du lägger först till nya strukturer, kör båda vägarna en tid och tar sedan bort de gamla strukturerna först när inget längre är beroende av dem.
Vad är skillnaden mellan expand- och contract-faserna?
Expand lägger till nya kolumner, tabeller eller index utan att ta bort något som den nuvarande appen behöver. Contract är cleanup-fasen där du tar bort de gamla kolumnerna, gamla läs-/skrivvägar och temporär synklogik efter att du bevisat att den nya vägen fungerar fullt ut.
Vad är det säkraste sättet att lägga till en ny kolumn i PostgreSQL?
Att lägga till en nullable-kolumn utan default är oftast den säkraste starten eftersom det undviker tunga lås och håller gammal kod fungerande. Därefter deployar du kod som kan hantera att kolumnen saknas eller är NULL, backfillar gradvis och skärper senare constraints som NOT NULL.
När ska jag använda dual-write, och vad gör det?
När nya appversionen skriver både till det gamla fältet och det nya under övergången. Det håller datan konsekvent medan äldre app-instanser och jobb fortfarande bara känner till det gamla fältet.
Hur backfillar jag data utan att sakta ner produktionen?
Backfilla i små batchar som avslutas snabbt, och gör varje batch idempotent så att om den körs om uppdateras bara rader som fortfarande behöver arbete. Håll koll på frågetider, låsväntetider och replikationslagg, och var beredd att pausa eller minska batchstorleken om databasen blir het.
Hur kan jag verifiera att migrationen verkligen är klar innan jag tar bort något?
Börja med att kolla fullständigheten, till exempel hur många rader som fortfarande har NULL i den nya kolumnen. Kör sedan en konsistenskontroll som jämför gamla och nya värden för ett urval (eller kontinuerligt om det är billigt), och övervaka produktionsfel efter deploys för att fånga kodvägar som fortfarande använder fel schema.
Vilka migrationssteg brukar mest bryta produktion?
NOT NULL eller nya constraints kan blockera skrivningar medan tabellen valideras, och normal indexskapande kan hålla lås längre än väntat. Omvändningar och drops är också riskfyllda eftersom äldre kod fortfarande kan referera de gamla namnen under en rolling deploy.
När är det säkert att göra contract-steget och ta bort den gamla kolumnen?
Endast efter att du slutat skriva till det gamla fältet, bytt läsningarna till det nya fältet utan fallback och väntat tillräckligt länge för att vara säker på att inga gamla app-versioner eller arbetare fortfarande körs. Många team hanterar detta som en separat release så att rollback förblir enkel.
Behöver jag alltid expand/contract, eller kan jag bara ta ett maintenance-fönster?
Om du kan acceptera ett planerat underhållsfönster och det är låg trafik kan en enkel engångsmigration vara okej. Om du har riktiga användare, flera app-instanser, bakgrundsjobb eller SLA är expand/contract oftast värt extra arbete eftersom det gör rollout och rollback säkrare; i Koder.ai Planning Mode hjälper det att skriva ner faserna och kontrollerna i förväg så att du inte hoppar över de tråkiga men viktiga stegen.