09 sep. 2025·8 min
Hur du skapar en SaaS-statussida med incidenthistorik
Lär dig planera, bygga och publicera en SaaS-statussida med incidenthistorik, tydliga meddelanden och prenumerationer så kunder hålls informerade vid avbrott.
Lär dig planera, bygga och publicera en SaaS-statussida med incidenthistorik, tydliga meddelanden och prenumerationer så kunder hålls informerade vid avbrott.
En SaaS-statussida är en offentlig (eller kundbegränsad) webbplats som visar om din produkt fungerar just nu — och vad ni gör om den inte gör det. Den blir den enda sanningskällan under incidenter, åtskild från sociala medier, supportärenden och rykten.
Den hjälper fler personer än du kanske tror:
En bra tjänste-statussida innehåller vanligtvis tre relaterade (men olika) lager:
Målet är tydlighet: Realtidsstatus svarar “Kan jag använda produkten?” medan historik svarar “Hur ofta händer det?” och postmortems svarar “Varför hände det, och vad ändrades?”.
En status-sida fungerar när uppdateringar är snabba, begripliga och ärliga om påverkan. Du behöver inte en perfekt diagnos för att kommunicera. Du behöver tidsstämplar, omfattning (vem som påverkas) och när nästa uppdatering kommer.
Du kommer att förlita dig på den under avbrott, degraderad prestanda (sakta inloggningar, fördröjda webhooks) och planerat underhåll som kan orsaka korta störningar eller risk.
När du behandlar status-sidan som en produktyta (inte en engångs-ops-sida) blir resten av uppsättningen mycket enklare: du kan definiera ägare, bygga mallar och koppla övervakning utan att uppfinna processen inför varje incident.
Innan du väljer ett verktyg eller designar layouten, bestäm vad din status-sida ska göra. Ett tydligt mål och en tydlig ägare är vad som håller status-sidor användbara under en incident — när alla är upptagna och informationen är rörig.
De flesta SaaS-team skapar en status-sida för tre praktiska resultat:
Skriv ner 2–3 mätbara signaler du kan följa efter lansering: färre duplicerade ärenden under incidenter, snabbare tid-till-första-uppdatering eller fler kunder som använder prenumerationer.
Din primära läsare är vanligtvis en icke-teknisk kund som vill veta:
Det betyder att minimera jargong. Föredra “Vissa kunder kan inte logga in” framför “Förhöjd 5xx-frekvens på auth.” Om du behöver teknisk detalj, håll den som en kort sekundär mening.
Välj en ton du kan hålla under press: lugn, faktabaserad och transparent. Bestäm i förväg:
Gör ägarskapet explicit: status-sidan ska inte vara “allas jobb”, annars blir den ingens.
Du har två vanliga alternativ:
Om din huvudapp kan gå ner är en fristående status-site oftast säkrare. Du kan fortfarande länka till den tydligt från din app och hjälpsida (till exempel /help).
En status-sida är bara så användbar som “kartan” bakom den. Innan du väljer färger eller skriver text, bestäm vad ni faktiskt rapporterar om. Målet är att spegla hur kunder upplever produkten — inte hur er organisationsdiagram ser ut.
Lista de delar en kund kan tänkas beskriva när de säger ”det är trasigt”. För många SaaS-produkter ser en praktisk startuppsättning ut så här:
Om ni erbjuder flera regioner eller tierer, fånga det också (t.ex. “API – US” och “API – EU”). Håll namn kundvänliga: “Login” är tydligare än “IdP Gateway”.
Välj en gruppering som matchar hur kunder tänker om tjänsten:
Försök undvika en oändlig lista. Om ni har dussintals integrationer, överväg en överordnad komponent (“Integrationer”) plus några högpåverkande barn (t.ex. “Salesforce”, “Webhooks”).
En enkel, konsekvent modell förhindrar förvirring under incidenter. Vanliga nivåer inkluderar:
Skriv interna kriterier för varje nivå (även om ni inte publicerar dem). Till exempel, “Partial Outage = en region nere” eller “Degraded = p95-latens över X under Y minuter.” Konsekvens bygger förtroende.
De flesta avbrott involverar tredjepart: molnhosting, e-postleverans, betalningsleverantörer eller identitetsleverantörer. Dokumentera dessa beroenden så era incidentuppdateringar kan vara korrekta.
Om ni ska visa dem offentligt beror på publiken. Om kunder direkt kan påverkas (t.ex. betalningar), kan ett dependency-komponent vara hjälpsamt. Om det lägger till brus eller bjuder in skuldbeläggning, håll beroenden interna men referera till dem i uppdateringar när relevant (t.ex. “Vi undersöker förhöjda fel från vår betalningsleverantör”).
När ni har denna komponentmodell blir resten av status-sidans uppsättning mycket enklare: varje incident får en tydlig “var” (komponent) och “hur illa” (status) från start.
En status-sida är mest användbar när den besvarar kundfrågor på sekunder. Människor kommer vanligtvis stressade och vill ha klarhet — inte mycket navigering.
Prioritera det viktigaste högst upp:
Skriv på enkel svenska. “Förhöjda fel på API-förfrågningar” är tydligare än “Partial outage in upstream dependency.” Om du måste använda tekniska termer, lägg till en kort översättning (“Vissa förfrågningar kan misslyckas eller time-out”).
Ett pålitligt mönster är:
För komponentlistan, håll etiketter kundvändliga. Om er interna service heter “k8s-cluster-2” behöver kunder sannolikt se “API” eller “Background Jobs”.
Gör sidan läsbar under press:
Placera ett litet set länkar nära toppen (i header eller precis under bannern):
Målet är förtroende: kunder ska omedelbart förstå vad som händer, vad som påverkas och när de hör från er nästa gång.
När en incident inträffar jonglerar teamet diagnostik, avhjälpning och kundfrågor samtidigt. Mallar tar bort gissningar så uppdateringar förblir konsekventa, tydliga och snabba — särskilt när olika personer kan publicera.
En bra uppdatering börjar med samma kärnfakta varje gång. Minst, standardisera dessa fält så kunder snabbt kan förstå vad som händer:
Om ni publicerar en incidenthistoriksida gör dessa fält konsekventa så tidigare incidenter blir lätta att skumma och jämföra.
Sikta på korta uppdateringar som svarar på samma frågor varje gång. Här är en praktisk mall du kan kopiera in i ditt statusverktyg:
Titel: Kort, specifik sammanfattning (t.ex. “API-fel för EU-regionen”)
Starttid: YYYY-MM-DD HH:MM (TZ)
Påverkade komponenter: API, Dashboard, Payments
Påverkan: Vad användare ser (fel, timeouts, degraderad prestanda) och vem som påverkas
Vad vi vet: En mening om orsaken om den är bekräftad (undvik spekulation)
Vad vi gör: Konkreta åtgärder (rollback, skalning, eskalering till leverantör)
Nästa uppdatering: Tidpunkt ni återkommer
Uppdateringar:
Kunder vill inte bara ha information — de vill ha förutsägbarhet.
Planerat underhåll ska kännas lugnt och strukturerat. Standardisera underhållsposter med:
Håll underhållsspråket specifikt (vad ändras, vad användare kan märka), och undvik att lova för mycket — kunder värderar noggrannhet över optimism.
En incidenthistorik är mer än en logg — det är ett sätt för kunder (och ditt eget team) att snabbt förstå hur ofta problem uppstår, vilka typer av problem som återkommer och hur ni svarar.
En tydlig historik bygger förtroende genom transparens. Den skapar också trendinsikt: om ni ser återkommande “API-latens”-incidenter varannan vecka är det en signal att investera i prestandaarbete (och prioritera post-incident-granskningar). Med tiden kan konsekvent rapportering minska supportärenden eftersom kunder själva hittar svar.
Välj ett retentionfönster som matchar kundförväntningar och produktmognad.
Vad ni än väljer, ange det tydligt (t.ex. “Incidenthistorik sparas 12 månader”).
Konsekvens gör det lätt att skumma. Använd ett förutsägbart namngivningsformat som:
YYYY-MM-DD — Kort sammanfattning (t.ex. “2025-10-14 — Fördröjd e-postleverans”)
För varje incident, visa åtminstone:
Om ni publicerar postmortems, länka från incidentdetaljsidan till genomgången (till exempel: “Läs postmortem”). Det håller tidslinjen ren samtidigt som de som vill ha mer kan läsa detaljer.
En status-sida hjälper när kunder kommer ihåg att kolla den. Prenumerationer vänder på det: kunder får uppdateringar automatiskt utan att refresha sidan eller mejla support för bekräftelse.
De flesta team förväntar sig åtminstone ett par alternativ:
Om ni stödjer flera kanaler, håll registreringsflödet konsekvent så kunder inte känner att de registrerar sig fyra olika sätt.
Prenumerationer ska alltid vara opt-in. Var tydlig med vad folk får innan de bekräftar — särskilt för SMS.
Ge prenumeranter kontroll över:
Dessa preferenser minskar notis-trötthet och håller era notifieringar trovärdiga. Om ni inte har komponentnivåprenumeration än, börja med “Alla uppdateringar” och lägg till filtrering senare.
Under en incident ökar meddelandevolymen och tredjepartsleverantörer kan throttla trafik. Kontrollera:
Det är värt att köra ett schemalagt test (t.ex. kvartalsvis) för att säkerställa att prenumerationer fortfarande fungerar.
Lägg en tydlig uppmaning på statushemsidan — ovanför folden om möjligt — så kunder kan prenumerera innan nästa incident. Gör den synlig på mobil och inkludera den där kunder söker hjälp (som en länk från er supportportal eller /help center).
Att välja hur ni bygger status-sidan handlar mindre om “kan vi bygga det?” och mer om vad ni vill optimera: snabb lansering, tillförlitlighet under incidenter och löpande underhåll.
Ett hosted-verktyg är oftast snabbast. Ni får en färdig status-sida, prenumerationer, incidenttidslinjer och ofta integrationer med vanliga övervakningssystem.
Vad du ska leta efter i ett hosted-verktyg:
DIY kan vara rätt om ni vill full kontroll över design, datalagring och hur incidenthistoriken presenteras. Nackdelen är att ni ansvarar för tillförlitlighet och drift.
En praktisk DIY-arkitektur är:
Om ni self-hostar, planera för fel: vad händer om primärdatabasen är otillgänglig eller deploy-pipelinen ligger nere? Många team håller status-sidan på separat infrastruktur (eller till och med separat leverantör) från huvudprodukten.
Om ni vill ha kontrollen hos DIY utan att bygga allt från grunden kan en vibe-coding-plattform som Koder.ai hjälpa er att snabbt stå upp en skräddarsydd status-site (web UI plus ett litet incident-API) från en chattdriven specifikation. Det är särskilt användbart för team som vill ha anpassade komponentmodeller, custom incidenthistorik-UX eller interna adminflöden — samtidigt som ni kan exportera källkod, deploya och iterera snabbt.
Hosted-verktyg har förutsägbara månadsavgifter; DIY har kostnad i form av engineering-tid, hosting/CDN-kostnader och löpande underhåll. Om ni jämför alternativ, skissa på månadskostnaden och intern tid, och jämför mot er budget (se /pricing).
En status-sida är bara användbar om den speglar verkligheten snabbt. Det enklaste är att koppla systemen som upptäcker problem (övervakning) med systemen som koordinerar responsen (incidentflöde), så uppdateringar blir konsekventa och snabba.
De flesta team kombinerar tre datakällor:
En praktisk regel: övervakning upptäcker; incidentflöde koordinerar; status-sidan kommunicerar.
Automation kan spara minuter när det gäller:
Håll första offentliga meddelandet försiktigt. “Undersöker förhöjda fel” är säkrare än “Avbrott bekräftat” när ni fortfarande validerar.
Fullt automatiserade meddelanden kan slå tillbaka:
Använd automation för att utforma och föreslå uppdateringar, men kräver en människa för att godkänna kundvänd text — särskilt för Identified, Mitigated och Resolved-tillstånd.
Behandla status-sidan som en kundvänd loggbok. Säkerställ att ni kan svara på:
Detta revisionsspår hjälper vid post-incident-granskningar, minskar förvirring vid överlämningar och bygger förtroende när kunder frågar om förtydliganden.
En status-sida hjälper bara om den är nåbar när er produkt inte är det. Det vanligaste felet är att bygga status-sidan på samma infrastruktur som appen — så när appen går ner försvinner även status-sidan, och kunder blir utan sanningskälla.
När möjligt, hosta status-sidan hos en annan leverantör än er produkt (eller åtminstone i annat konto/region). Målet är att minska blast-radius: ett avbrott i appplattformen ska inte ta ner er kommunikation.
Överväg också att separera DNS. Om er huvuddomäns DNS hanteras samma som appens edge/CDN kan ett DNS- eller certifikatproblem blockera båda samtidigt. Många team använder en dedikerad subdomän (till exempel status.yourcompany.com) med DNS hanterat separat.
Håll tillgångarna lätta: minimal JavaScript, komprimerad CSS och inga beroenden som kräver era app-API:er för att rendera. Sätt en CDN framför status-sidan och aktivera caching för statiska resurser så den laddar även under hög belastning.
En praktisk säkerhetsåtgärd är ett fallback-statiskt läge:
Kunder ska inte behöva logga in för att se tjänstehälsan. Håll status-sidan publik, men lägg admin/editor-verktyg bakom autentisering (gärna SSO), med stark åtkomstkontroll och revisionsloggar.
Till sist, testa fel-scenarier: blockera tillfälligt er app-origin i en stagingmiljö och bekräfta att status-sidan fortfarande kan nås, laddar snabbt och kan uppdateras när det behövs som mest.
En status-sida bygger förtroende bara om den uppdateras konsekvent under verkliga incidenter. Den konsekvensen händer inte av en slump — ni behöver tydligt ägarskap, enkla regler och en förutsägbar kadens.
Håll core-teamet litet och explicit:
På små team kan en person ha två roller — bestäm det i förväg. Dokumentera rollöverlämningar och eskaleringsvägar i ert on-call-handbook (se /docs/on-call).
När ett larm blir en kundpåverkande incident, följ ett upprepbart flöde:
En praktisk regel: posta första uppdateringen inom 10–15 minuter, sedan var 30–60:e minut medan påverkan fortsätter — även om meddelandet är “Ingen förändring, vi utreder fortfarande.”
Inom 1–3 arbetsdagar, kör en lätt post-incident-granskning:
Uppdatera sedan incidentposten med slutlig sammanfattning så incidenthistoriken förblir användbar — inte bara en logg av “resolved”-meddelanden.
En status-sida är bara användbar om den är lätt att hitta, lätt att lita på och konsekvent uppdaterad. Innan ni annonserar den, gör en snabb “production-ready”-genomgång — och sätt sedan upp en lätt kadens för att förbättra den över tid.
Text och struktur
Branding och förtroende
Åtkomst och behörigheter
Testa hela flödet
Annonsera
Om ni bygger er egen status-site, överväg att köra samma lanseringschecklista i staging först. Verktyg som Koder.ai kan snabba på iterationen genom att generera web UI, adminskärmar och backend-endpoints från en enda spec — och låta er exportera koden och deploya där ni behöver.
Följ några enkla utfall och utvärdera månadsvis:
Behåll en grundläggande taxonomi så historiken blir handlingsbar:
Med tiden bygger små förbättringar — tydligare formuleringar, snabbare uppdateringar, bättre kategorisering — upp färre avbrott, färre ärenden och mer kundförtroende.
En SaaS-statussida är en dedikerad sida som visar aktuell tjänstehälso-status och incidentuppdateringar på ett enda kanoniskt ställe. Den är viktig eftersom den minskar ”Är det bara jag?”-frågor till support, sätter förväntningar under driftstörningar och bygger förtroende med tydlig, tidsstämplad kommunikation.
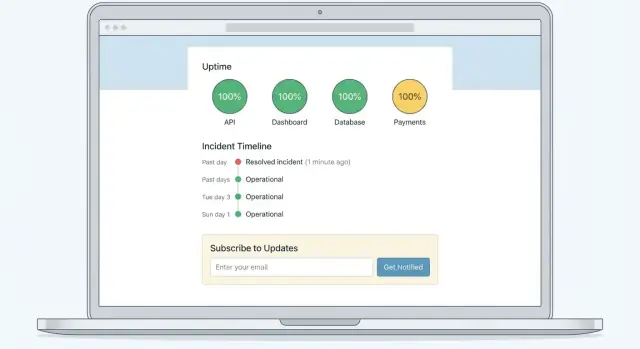
Real-tidsstatus svarar på “Kan jag använda produkten just nu?” med komponentnivåstatus.
Incidenthistorik svarar på “Hur ofta händer det här?” med en tidslinje över tidigare incidenter och underhåll.
Postmortems svarar på “Varför hände det och vad ändrades?” med rotorsaksanalys och förebyggande åtgärder (ofta länkade från incidentposten).
Börja med 2–3 mätbara mål:
Skriv ner dessa mål och granska dem månadsvis så sidan inte blir inaktuell.
Tilldela en tydlig ägare och en backup (ofta on-call-rotationen). Många team använder:
Definiera också regler i förväg: vem som får publicera, om godkännanden krävs och minimal uppdateringskadens (t.ex. var 30–60:e minut under större incidenter).
Välj komponenter utifrån hur kunder beskriver problem, inte interna servicenamn. Vanliga komponenter inkluderar:
Om tillgängligheten varierar per geografi, dela upp efter region (t.ex. “API – US” och “API – EU”).
Använd en liten, konsekvent uppsättning nivåer och dokumentera interna kriterier för varje:
Konsekvens är viktigare än perfekt precision. Kunder ska lära sig vad varje nivå betyder genom upprepade, förutsägbara användningar.
En praktisk incidentuppdatering bör alltid innehålla:
Även om ni inte vet rotorsaken än kan ni kommunicera omfattning, påverkan och vad ni gör härnäst.
Posta en initial “Investigating”-uppdatering snabbt (ofta inom 10–15 minuter efter bekräftad påverkan). Därefter:
Om ni inte kan hålla kadensen, posta en kort notis som återställer förväntningarna istället för att vara tyst.
Hosted-verktyg optimerar för snabb lansering och pålitlighet (ofta kvarstår de online även om er app ligger nere) och inkluderar vanligtvis prenumerationer och integrationer.
DIY ger full kontroll men ni måste designa för motståndskraft:
Erbjud de kanaler kunder redan använder (vanligtvis e-post och SMS, plus Slack/Teams eller RSS). Håll prenumerationer opt-in och var tydlig med:
Testa leveransbarhet och rate limits regelbundet så notifieringar fortfarande fungerar när trafiken ökar vid en incident.