30 okt. 2025·8 min
Hur du skapar en webbapp för att följa experimentresultat per produkt
Lär dig bygga en webbapp för att följa experiment över produkter: datamodell, mätvärden, behörigheter, integrationer, instrumentpaneler och pålitlig rapportering.
Vad den här webbappen bör lösa
De flesta team misslyckas inte med experiment för att idéerna saknas—de misslyckas för att resultaten är utspridda. En produkt har diagram i ett analysverktyg, en annan har ett kalkylblad, en tredje har en presentation med skärmdumpar. Några månader senare kan ingen svara på enkla frågor som “Har vi redan testat detta?” eller “Vilken version vann, med vilken mätdefinition?”
Kärnproblemet: fragmenterade resultat och inkonsekvent sanning
En experimenttracker bör centralisera vad som testades, varför, hur det mättes och vad som hände—över flera produkter och team. Utan detta slösar team tid på att bygga om rapporter, bråkar om siffror och kör om gamla tester eftersom lärdomar inte går att söka upp.
Vem den är för (och vad varje grupp behöver)
Det här är inte bara ett analystverktyg.
- Produktchefer behöver ett snabbt sätt att se utfall, konfidens och beslutstatus.
- Analytiker behöver en pålitlig plats att dokumentera antaganden, mätdefinitions och caveats.
- Ingenjörer behöver klarhet i vilka feature flags, varianter och rollout‑villkor som gällde.
- Ledning behöver en konsekvent överblick av påverkan över produkter, utan skräddarsydda presentationer.
Mål att optimera för
En bra tracker skapar affärsvärde genom att möjliggöra:
- Snabbare beslut (mindre tid som går åt att jaga länkar och godkännanden)
- Färre rapportfel (en källa till sanning för "slutliga siffror")
- Delade lärdomar (sökbar historik av vinster, förluster och neutrala tester)
Tydliga avgränsningar
Var tydlig: den här appen är främst för uppföljning och rapportering av experimentresultat—inte för att köra experiment end-to-end. Den kan länka till befintliga verktyg (feature flagging, analytics, data warehouse) samtidigt som den ansvarar för den strukturerade posten av experimentet och dess slutliga, överenskomna tolkning.
Krav: minimalt gångbar experimenttracker
En MVP för experimenttracking ska svara på två frågor utan att man behöver leta i dokument eller kalkylblad: vad testar vi och vad lärde vi oss. Börja med ett litet set entiteter och fält som fungerar över produkter, och expandera bara när teamen verkligen börjar känna smärta.
Kärn-entiteter att stödja
Håll datamodellen tillräckligt enkel för att alla team ska använda den på samma sätt:
- Product: den yta (app/site/API) där förändringen skickas ut.
- Experiment: en hypotes och ett beslut.
- Variant: kontroll och en eller flera behandlingar.
- Metric: en namngiven mätning med en ägare och definition.
- Segment: valfria publikskivor (nya användare, betalande användare, region) som används i rapporteringen.
Experiments-typer (starta litet, håll det flexibelt)
Stöd de vanligaste mönstren från dag ett:
- A/B‑tester (kontroll vs behandling)
- Multivariata tester (flera varianter)
- Feature flag rollouts (procentbaserad exponering)
Även om rollouts inte använder formell statistik i början, hjälper det att spåra dem tillsammans med experiment så att team undviker att upprepa samma “tester” utan någon post.
Minsta fält varje experiment behöver
Vid skapande, kräva bara det som behövs för att köra och tolka testet senare:
- Hypotes (vilken förändring, för vem, och varför)
- Owner (en ansvarig person)
- Start/slut‑datum (planerat och faktiskt)
- Targeting (eligibilitetsregler) och allocation (trafikfördelning)
- Länkar till rollout/flagga, ticket eller spec (relativa sökvägar som /projects/123)
Succeskriterier och beslutstatus
Gör resultaten jämförbara genom att tvinga struktur:
- Primär mätning (huvudsakligt framgångsmått)
- Guardrails (mått som inte får försämras)
- Beslutsstatus: proposed → running → analyzed → shipped/rolled back → archived
Om du bygger bara detta kan teamen pålitligt hitta experiment, förstå uppsättningen och dokumentera utfall—även innan du lägger till avancerad analys eller automation.
Datamodell som fungerar över flera produkter
En tvärprodukts tracker vinner eller förlorar på sin datamodell. Om ID:n kolliderar, mätvärden driver isär eller segment är inkonsekventa kan din dashboard se “rätt” ut men berätta fel historia.
Välj stabila identifierare (och håll dem konsekventa)
Börja med en tydlig identifieringsstrategi:
- product_id: stabil över namnbyten (använd inte visningsnamn som nycklar)
- experiment_key: läsbar slug (t.ex.
checkout_free_shipping_banner) plus ett immutabelt experiment_id - variant_key: stabila etiketter som
control,treatment_a
Detta låter dig jämföra resultat över produkter utan att gissa om “Web Checkout” och “Checkout Web” är samma sak.
Kärn‑tabeller/collections
Håll kärn-entiteterna små och explicita:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (eller anonymous_id), variant_key, assigned_at
- metric_defs: metric name, numerator/denominator logic, unit (user/session/order), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Även om beräkningen händer någon annanstans, gör lagring av outputs (results) att dashboards blir snabba och historiken pålitlig.
Tidsfönster och versionering
Mätvärden och experiment är inte statiska. Modellera:
- time windows (t.ex. “first 7 days after assignment”, “calendar weeks”)
- versionerade metric definitions: när en metriks beräkning ändras, skapa en ny version istället för att redigera den gamla
Detta förhindrar att förra månadens experiment ändras när någon uppdaterar KPI‑logiken.
Segment och revisionsspår
Planera för konsekventa segment över produkter: land, enhet, plan‑nivå, nya vs återkommande.
Slutligen, lägg till ett audit trail som fångar vem som ändrade vad och när (statusändringar, trafikdelningar, uppdateringar av mätdefinitioner). Det är avgörande för förtroende, granskningar och styrning.
Mätdefinitions och konsekventa beräkningar
Om din tracker räknar fel (eller inkonsekvent över produkter) är “resultatet” bara en åsikt med ett diagram. Snabbaste sättet att förhindra detta är att behandla metrik som delade produktresurser—inte ad hoc‑querysnuttar.
Bygg en kanonisk metrikatalog
Skapa en metrikatalog som är enda sanningskälla för definitioner, beräkningslogik och ägarskap. Varje metrikpost bör innehålla:
- En vardaglig definition (vilket beslut den stödjer)
- En ägare (personen/teamet ansvarigt för ändringar)
- Exakt formel och nödvändiga events/fält
- Inklusions-/exklusionsregler (t.ex. interna användare, bots, återbetalda order)
- Giltiga aggregeringsnivåer och stödda produkter
Håll katalogen nära där folk arbetar (t.ex. länkad från experiment‑skapet) och versionera den så du kan förklara historiska resultat.
Standardisera aggregeringsnivåer
Bestäm i förväg vilken “analysenhet” varje metrik använder: per användare, per session, per konto eller per order. En konverteringsgrad “per user” kan skilja sig från “per session” även om båda är korrekta.
För att minska förvirring, lagra aggregeringsvalet med metrikdefinitionen och kräva att det anges vid experiment‑setup. Låt inte varje team välja enhet ad hoc.
Hantera fördröjda konversioner och attribuering
Många produkter har konversionsfönster (t.ex. signup idag, köp inom 14 dagar). Definiera attribueringsregler konsekvent:
- När startar klockan (exponeringstid, första besök, assignment‑tid)?
- Vad räknas som konversion om en användare exponeras flera gånger?
- Hur hanterar du cross‑device eller cross‑product‑resor?
Gör dessa regler synliga i dashboarden så läsaren vet vad de tittar på.
Lagra råa counts och beräknade statistik
För snabba dashboards och revisionsmöjlighet, lagra båda:
- Råa counts (exposures, converters, revenue sums, variance inputs)
- Beräknade statistik (lift, konfidensintervall, p‑värden)
Detta möjliggör snabb rendering samtidigt som du kan räkna om när definitioner ändras.
Namngivningskonventioner förhindrar metric‑sprawl
Anta en namngivningsstandard som kodar mening (t.ex. activation_rate_user_7d, revenue_per_account_30d). Kräv unika ID:n, stöd alias och flagga nära‑duplikat vid skapande av nya mätvärden för att hålla katalogen ren.
Insamling av data: events, pipelines och kvalitetskontroller
Din tracker är bara så trovärdig som datan den tar emot. Målet är att pålitligt svara på två frågor för varje produkt: vem exponerades för vilken variant, och vad gjorde de efteråt? Allt annat—mätvärden, statistik, dashboards—bygger på den grunden.
Välj en ingest‑strategi
De flesta team väljer ett av dessa mönster:
- Event stream (nära realtid): Bra för snabba läsningar och snabb debugging. Kräver mer ingenjörsmognad för att vara stabil.
- Daglig batch: Enklare att drifta och billigare. Bäst när beslut inte behöver fattas varje timme.
- Hybrid: Streama exposures och kritiska events (så du snabbt kan validera assignment), batcha resten för fullständighet och kostnadskontroll.
Oavsett val, standardisera minimiset events över produkter: exposure/assignment, nyckel konversionsevents, och tillräcklig kontext för att göra joins (user ID/device ID, timestamp, experiment ID, variant).
Mappa produktevents till mätvärden (och validera fullständighet)
Definiera en tydlig mappning från råa events till de metrik din tracker rapporterar (t.ex. purchase_completed → Revenue, signup_completed → Activation). Behåll denna mappning per produkt, men håll namnen konsekventa så din A/B‑dashboard jämför äpplen med äpplen.
Validera fullständighet tidigt:
- Bekräfta att varje exposure har ett experiment ID och variant.
- Säkerställ att konversionsevents innehåller samma identitetsfält som exposures använder för joins.
- Vakta för event‑dropoffs mellan klient, server och warehouse (mobila SDK:er är vanliga problemkällor).
Data quality checks du bör automatisera
Bygg kontroller som körs vid varje inläsning och larmar högljutt:
- Saknade exposure events: konversioner utan tidigare exposure (ofta instrumentationsluckor eller identitetsmissmatch)
- Skev allocation: varianter som får 70/30 när 50/50 förväntades (kan indikera targetingbugg)
- Tidsstämmarsanitet: exposure efter konversion, eller stora fördröjningar som antyder klockproblem
Visa dessa som varningar kopplade till ett experiment i appen, inte gömda i loggar.
Backfills och reprocessing
Pipelines förändras. När du fixar instrumentation eller dedupe‑logik måste du reprocessa historisk data för att hålla mätvärden och KPI:er konsekventa.
Planera för:
- Versionerade transformationer (så du vet vilken logik som producerade vilket resultat)
- Säkra backfills (begränsa scope per datum/produkt/experiment)
- Ett revisionsspår för omberäkningar
Dokumentera integrationer
Behandla integrationer som produktfunktioner: dokumentera stödda SDK:er, eventschema och felsökningssteg. Om du har en docs‑sektion, länka som relativ sökväg som /docs/integrations.
Statistik och resultaträkning du kan lita på
Behåll full kontroll över koden
Exportera källkoden när som helst och fortsätt bygga i ditt eget repo.
Om folk inte litar på siffrorna kommer de inte använda trackern. Målet är inte att imponera med matematik—det är att göra beslut repeterbara och försvarbara över produkter.
Välj en statistisk “dialekt” och håll dig till den
Bestäm i förväg om appen ska rapportera frequentist resultat (p‑värden, konfidensintervall) eller Bayesian resultat (sannolikhet för förbättring, trovärdighetsintervall). Båda kan fungera, men att blanda dem över produkter skapar förvirring (“Varför visar detta test 97% chans att vinna, medan det andra visar p=0.08?”).
En praktisk regel: välj det sätt din organisation redan förstår, och standardisera terminologi, defaults och trösklar.
Bestäm exakt vad UI visar
Som minimum bör resultatsvyn tydligt visa:
- Lift (absolut och/eller relativt) versus kontroll
- Intervall (konfidens‑ eller trovärdighetsintervall) visas som ett spann, inte bara en punktuppskattning
- Evidensstyrka (p‑värde för frequentist, eller sannolikhet att slå kontroll för Bayesian)
Visa också analysfönstret, räknade enheter (users, sessions, orders) och metrikdefinitionsversion som användes. Dessa “detaljer” är skillnaden mellan konsekvent rapportering och debatt.
Multipla jämförelser och policy för "peeking"
Om team kör många varianter, många mätvärden eller kollar resultat dagligen blir false positives troliga. Din app bör koda en policy istället för att lämna det åt varje team:
- Multipla jämförelser: bestäm om ni justerar (t.ex. kontrollera false discovery rate) eller tydligt märk resultat som “unadjusted exploratory.”
- Upprepad peeking: antingen (1) avråd från det med ett fixerat slutdatum och "finalized" status, eller (2) stöd sekventiella metoder och visa "safe-to-stop"‑riktlinjer.
Guardrails som fångar vanliga fel
Lägg till automatiska flaggor som visas bredvid resultat, inte gömda i loggar:
- Sample Ratio Mismatch (SRM): varna när trafikfördelningen avviker från förväntat
- Anomalidetektion: flagga plötsliga droppar/peak i trafik, konversioner eller intäkter som kan indikera spårningsfel eller bottrafik
Förklaringar på vardagsspråk
Bredvid siffrorna, lägg en kort förklaring som en icke‑teknisk läsare kan lita på, t.ex: “Bästa uppskattning är +2.1% lift, men den sanna effekten kan rimligen vara mellan -0.4% och +4.6%. Vi har inte tillräckligt starkt bevis för att utropa en vinnare än.”
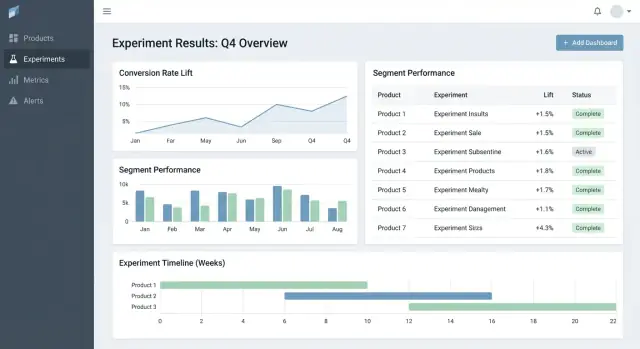
UX och dashboards för snabba beslut
Bra experimentverktyg hjälper folk att snabbt svara på två frågor: Vad ska jag titta på härnäst? och Vad bör vi göra åt det? UI bör minimera letande efter kontext och göra “beslutsstatus” explicit.
Nyckelsidor för arbetsflödet
Börja med tre sidor som täcker mest användning:
- Experiments list: en sorteringsbar kö för hela organisationen (eller per produkt).
- Experiment detail: enda sanningskällan för setup, resultat och beslut.
- Product overview: en rollup av aktiva tester, senaste beslut och metrikhälsa för en produkt.
På list‑ och produktsidor, gör filter snabba och ihållande: product, owner, date range, status, primary metric, och segment. Folk ska kunna begränsa till “Checkout‑experiment, ägda av Maya, körs denna månad, primär mätning = conversion, segment = new users” på sekunder.
Beslutsstatus folk kan lita på
Behandla status som ett kontrollerat vokabulär, inte fritext:
Draft → Running → Stopped → Shipped / Rolled back
Visa status överallt (lista, detaljrubrik och delningslänkar) och dokumentera vem som ändrade och varför. Detta förhindrar “tysta lanseringar” och oklara utfall.
En resultattabell som gör beslutet uppenbart
I experimentdetaljen, börja med en kompakt resultattabell per metrik:
- Baseline
- Variant
- Lift
- Osäkerhet (konfidens- eller trovärdighetsintervall)
- Anteckningar (t.ex. instrumentationscaveats, segment‑egendomar)
Håll avancerade diagram bakom en “Mer detaljer”‑sektion så beslutsfattare inte blir överväldigade.
Delning och export utan förlorad kontroll
Lägg till CSV‑export för analytiker och delbara länkar för intressenter, men tvinga åtkomst: länkar ska följa roller och produktbehörigheter. En enkel “Kopiera länk”-knapp plus “Exportera CSV” täcker det mesta av samarbetet.
Behörigheter, integritet och styrning
Planera bygget i steg
Skissera din datamodell, API:er och statusarbetsflöde innan du genererar appen.
Om din tracker spänner över flera produkter är accesskontroll och revisionsmöjlighet inte valfritt. Det är vad som gör verktyget säkert att adoptera och trovärdigt vid granskningar.
Rollbaserad åtkomstkontroll (RBAC)
Börja med ett enkelt set roller och håll dem konsekventa i appen:
- Viewer: read‑only tillgång till experiment, resultat och dashboards.
- Editor: skapa/redigera experiment, ladda upp stödmaterial, ändra status (draft → running → concluded).
- Admin: hantera användare, behörigheter, mätdefinitions, retention och integrationer.
Håll RBAC-beslut centraliserade (ett policylager) så UI och API tvingar samma regler.
Produkt‑ och radnivåbehörigheter
Många organisationer behöver produkt‑scopead åtkomst: Team A kan se Product A‑experiment men inte Product B. Modellera detta explicit (t.ex. user ↔ product memberships), och säkerställ att varje fråga filtreras på produkt.
För känsliga fall (partnerdata, reglerade segment) lägg till radnivå‑restriktioner ovanpå produkt‑scope. Ett praktiskt angreppssätt är att tagga experiment eller resultatsnitt med en känslighetsnivå och kräva extra behörighet för att se dem.
Revisionsspår: access + ändringshistorik
Logga två saker separat:
- Change logs: vem redigerade ett experiment, mätdefinition eller beslut—vad ändrades och när.
- Access logs: vem tittade eller exporterade resultat (särskilt för känsliga experiment).
Visa ändringshistoriken i UI för transparens och behåll djupare loggar för utredningar.
Retention och raderingsregler
Definiera retention för:
- Experimentmetadata (hypotes, ägare, datum, beslutsanteckningar)
- Beräknade resultat (effect sizes, konfidensintervall, signifikansflaggor)
Gör retention konfigurerbar per produkt och känslighet. När data måste tas bort, behåll en minimal tombstone‑post (ID, raderingstid, orsak) för att bevara rapportintegritet utan att behålla känsligt innehåll.
Arbetsflödesfunktioner: från idé till lärandebibliotek
En tracker blir verkligen användbar när den täcker hela experimentets livscykel, inte bara slutlig p‑value. Arbetsflödesfunktioner förvandlar utspridda dokument, tickets och diagram till en repeterbar process som höjer kvalitet och gör lärdomar enkla att återanvända.
Livscykel: idé → review → run → post‑mortem
Modellera experiment som serier av states (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Varje state bör ha klara “exit criteria” så experiment inte går live utan essentials som hypotes, primär mätning och guardrails.
Godkännanden behöver inte vara tunga. Ett enkelt reviewer‑steg (t.ex. produkt + data) plus ett revisionsspår över vem godkände vad och när kan förhindra undvikbara misstag. Efter avslut kräva en kort post‑mortem innan ett experiment kan markeras “Published” för att säkerställa att resultat och kontext fångas.
Mallar som standardiserar tänkandet
Lägg till mallar för:
- Experimentbrief (mål, hypotes, målgrupp, succesmätningar, guardrails, rollout‑plan)
- Analysanteckningar (datakällor, exclusioner, sanity checks, tolkning, risker)
Mallar minskar friktion och snabbar upp reviews eftersom alla vet var de ska titta. Håll dem redigerbara per produkt men bevara en gemensam kärna.
Lärdomar: länka allt, håll det sökbart
Experiment lever sällan ensamma—folk behöver omgivande kontext. Låt användare bifoga länkar till tickets/specs och relaterade writeups (till exempel: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Spara strukturerade “Learning”‑fält som:
- Vad som ändrades (beslut)
- Vad vi lärde oss (insikt)
- Vad som ska göras härnäst (uppföljning)
Aviseringar för guardrails och förändrade resultat
Stöd notifieringar när guardrails försämras (t.ex. fel‑rate, avbokningar) eller när resultat ändras materiellt efter sena data eller metrikeräkningar. Gör aviseringar handlingsbara: visa metrik, tröskel, tidsfönster och en ägare att bekräfta eller eskalera.
Ett bibliotek för att återanvända tidigare arbete
Tillhandahåll ett bibliotek som filtrerar efter produkt, funktionsområde, målgrupp, metrik, utfall och taggar (t.ex. “pricing”, “onboarding”, “mobile”). Lägg till förslag på “liknande experiment” baserat på delade taggar/metrik så team kan undvika att köra om samma test och istället bygga vidare på tidigare lärdomar.
Arkitektur och tekniska stack‑val
Du behöver inte en “perfekt” stack för att bygga en experimenttracker—men du behöver klara gränser: var datan bor, var beräkningarna körs och hur teamen får tillgång till resultat konsekvent.
Ett praktiskt basstack
För många team ser en enkel och skalbar setup ut så här:
- Frontend: React (eller Vue) för dashboards och arbetsflöden
- Backend API: Node.js/Express, Python/FastAPI eller Java/Spring—välj vad teamet kan underhålla
- Databas: Postgres för appdata (experiments, metrikdefinitioner, behörigheter)
- Analytics warehouse: BigQuery/Snowflake/Redshift för eventdata och tunga aggregeringar
Denna uppdelning håller transaktionella arbetsflöden snabba medan warehouse hanterar storskaliga beräkningar.
Om du vill prototypa workflow‑UI snabbt (experiments list → detail → readout) innan du satsar på full engineering‑cykel kan en vibe‑kodningsplattform som Koder.ai hjälpa dig att generera en fungerande React + backend‑grund från en chatt‑spec. Det är särskilt användbart för att få entiteter, formulär, RBAC‑stommar och audit‑vänlig CRUD på plats, och sedan iterera på datakontrakten med analys‑teamet.
Var borde metrikberäkningar ligga?
Du har vanligtvis tre alternativ:
- Warehouse‑first: SQL‑modeller beräknar mätvärden och experimentresultattabeller. Appen läser mest.
- Backend‑jobs: En worker beräknar resultat enligt schema eller när experiment ändras.
- Hybrid: Kanoniska aggregeringar i warehouse, med backend‑efterbearbetning (formatering, guardrails, caching).
Warehouse‑first är ofta enklast om datateamet redan äger pålitliga SQL‑modeller. Backend‑tungt kan fungera när du behöver låg latens eller speciallogik, men det ökar applikationskomplexiteten.
Prestanda: cache och förberäkna
Experimentdashboards upprepar ofta samma queries (top‑line KPI:er, tidsserier, segment). Planera att:
- Förberäkna rollups (dagliga metrikaggregeringar per experiment/variant/segment)
- Cache dyra reads i API‑lagret (t.ex. Redis) med tydliga invalidationsregler
- Använd materialiserade vyer eller schemalagda tabeller i warehouse för vanliga dashboards
Multi‑tenant vs single‑tenant
Om du stödjer många produkter/enheter, bestäm tidigt:
- Single‑tenant (delat schema): Lättare att drifta, men kräver strikt permission filtering.
- Multi‑tenant: Separata scheman/projekt per produkt/team för starkare isolation, mer overhead.
Ett vanligt kompromiss är delad infrastruktur med stark tenant_id‑modell och genomdriven radnivå‑åtkomst.
Definiera kärn‑API:er
Håll API‑ytan liten och explicit. De flesta system behöver endpoints för experiments, metrics, results, segments och permissions (plus audit‑vänliga reads). Det gör det enklare att lägga till nya produkter utan att skriva om all infrastruktur.
Testning, övervakning och pålitlig drift
Lägg till RBAC från dag ett
Skapa Viewer-, Editor- och Admin-roller så att åtkomst över produkter förblir tydlig.
En tracker är bara användbar om folk litar på den. Det förtroendet kommer från disciplinerad testning, tydlig övervakning och förutsägbar drift—särskilt när flera produkter och pipelines matar samma dashboards.
Observability som speglar hur folk använder appen
Börja med strukturerad loggning för varje kritiskt steg: event‑ingestion, assignment, metrikrollups och resultaträkning. Inkludera identifierare som product, experiment_id, metric_id och pipeline run_id så support kan spåra ett enskilt resultat tillbaka till dess input.
Lägg till system‑metrik (API‑latens, jobbruntimes, ködjup) och data‑metrik (events processade, % sena events, % droppade vid validering). Komplettera med tracing över tjänster så du kan svara på “Varför saknas gårdagens data för detta experiment?”
Kontroller för datafärskhet är snabbaste sättet att förhindra tysta fel. Om en SLA är “daglig kl 09:00”, övervaka färskhet per produkt och källa och larma när:
- senaste partition saknas
- eventvolym avviker kraftigt från baslinje
- rollup‑jobb kör klart men producerar noll rader
Automatiska tester: skydda data och matte
Skapa tester på tre nivåer:
- Schema och constraints: obligatoriska fält, unikhet (t.ex. en assignment per user per experiment), foreign keys och giltiga datumintervall.
- Behörigheter: RBAC‑tester (viewer/editor/admin) och product‑scoping så team bara ser det de ska.
- Resultat‑matematik: enhetstester för lift, konfidensintervall, signifikansflaggor och edge‑cases (små sampel, noll i nämnare, flera varianter).
Behåll en liten “golden dataset” med kända outputs så du fångar regressioner innan du släpper.
Deploys, migrationer och historisk säkerhet
Behandla migrationer som en del av driften: versionera metrikdefinitioner och resultaträkningslogik, och undvik att skriva om historiska experiment om det inte uttryckligen begärs. När förändringar krävs, tillhandahåll en kontrollerad backfill‑väg och dokumentera vad som ändrades i revisionsspåret.
Admin‑verktyg för incidenter och omkörning
Ge en adminvy för att köra om pipeline för ett specifikt experiment/datumintervall, inspektera valideringsfel och markera incidenter med statusuppdateringar. Länka incidentnoteringar direkt från påverkade experiment så användare förstår förseningar och inte fattar beslut på ofullständig data.
Utrullningsplan och vanliga fallgropar
Att rulla ut en experimenttracker över produkter handlar mindre om “lanseringsdag” och mer om att stadigt minska oklarheter: vad som spåras, vem som äger det och om siffrorna stämmer med verkligheten.
En praktisk utrullningssekvens
Börja med en produkt och ett litet, hög‑konfidens mätset (till exempel: conversion, activation, revenue). Målet är att validera end‑to‑end‑flödet—skapa ett experiment, fånga exposure och utfall, räkna resultat och dokumentera beslut—innan du skalar upp komplexiteten.
När första produkten är stabil, expandera produkt‑för‑produkt med ett förutsägbart onboardingsflöde. Varje ny produkt bör kännas som en repeterbar setup, inte ett kundanpassat projekt.
Om organisationen ofta fastnar i långa “plattformbyggen”, överväg en tvåspårs‑strategi: bygg hållbara datakontrakt (events, ID:n, metrikdefinitioner) parallellt med ett tunt applikationslager. Team använder ibland Koder.ai för att snabbt stå upp det tunna lagret—formulär, dashboards, behörigheter och export—och sedan härda det allt eftersom adoptionen växer (inklusive export av källkod och iterativa rollback via snapshots när krav ändras).
Checklista för onboarding av varje ny produkt
Använd en lättviktig checklista för att onboarda produkter och eventschema konsekvent:
- Bekräfta eventtaxonomi och namngivningskonventioner (och vem som kan ändra dem)
- Verifiera att exposure events finns och är unikt attribuerbara till en användare/session
- Mappa metrik till produktens eventschema (inklusive edge‑cases som refunds, cancellations)
- Kör en backfill eller parallell‑körningsperiod för att jämföra med befintlig analys
- Tilldela ägarskap för experimentsetup, datavalidering och slutligt beslut
Där det hjälper adoption, länka “nästa steg” från experimentresultat till relevanta produktområden (t.ex. prisrelaterade experiment kan länka till /pricing). Behåll länkar informativa och neutrala—inga implicita slutsatser.
Mät adoption så du kan åtgärda friktion tidigt
Mät om verktyget blir standardstället för beslut:
- Veckovisa aktiva användare per roll (PM, analytiker, ingenjör)
- Experiment skapade och avslutade
- Andel med ifyllda beslutsanteckningar (inte bara visade resultat)
- Tid från experimentslut → beslut dokumenterat
Vanliga fallgropar att undvika
I praktiken snubblar de flesta utrullningar på några återkommande problem:
- Inkonsekventa metrikdefinitioner över produkter (samma namn, olika matte)
- Saknad eller felaktig exposure‑tracking, vilket leder till bias
- Oklart ägarskap för validering och sign‑off, som skapar “zombie‑experiment”
- Tysta schemaändringar som bryter trender utan att någon märker
- Att skala upp till många mätvärden för tidigt, innan kärnflödet har förtroende
Vanliga frågor
What problem is an experiment tracking web app actually solving?
Börja med att centralisera den slutgiltiga, överenskomna posten för varje experiment:
- vad som testades (hypotes, varianter)
- var det kördes (produkt)
- hur det mättes (mätdefinition + version)
- vad som hände (resultat, osäkerhet, beslut)
Du kan länka ut till feature-flag-verktyg och analysverktyg, men trackern bör äga den strukturerade historiken så att resultat förblir sökbara och jämförbara över tid.
Does an experiment tracker need to run experiments end-to-end?
Nej—håll avgränsningen fokuserad på uppföljning och rapportering av resultat.
Ett praktiskt MVP:
- lagrar experimentmetadata (ägare, datum, targeting, trafikdelning)
- lagrar mätdefinitions (versionerade)
- lagrar beräknade resultat (lift + osäkerhet) och beslutsanteckningar
- länkar till externa system (flags, tickets, dashboards)
Detta undviker att bygga om hela experimentplattformen samtidigt som det löser problemet med "splittrade resultat."
What core entities should the MVP data model include?
En minsta modell som fungerar tvärs över team är:
How should we design identifiers so results stay consistent across products?
Använd stabila ID:n och behandla displaynamn som redigerbara etiketter:
product_id: ändras aldrig, även om produktnamnet gör detexperiment_id: immutabelt internt IDexperiment_key: läsbar slug (kan vara unik per produkt)
What fields should be required when creating an experiment?
Gör “succeskriterier” explicita vid setup:
- kräva en primär mätning (beslutsdrivare)
- definiera guardrails (mått som inte får försämras)
- lagra en kontrollerad beslutsstatus (t.ex. Draft → Running → Analyzed → Shipped/Rolled back → Archived)
Denna struktur minskar debatter senare eftersom läsare kan se vad “vinna” betydde innan testet kördes.
How do we prevent inconsistent metric definitions across teams?
Skapa en kanonisk metrikatalog med:
- enkel definition på vardagsspråk + beslutssyfte
- exakt formel och nödvändiga events/fält
- inklusions-/exklusionsregler (bots, interna användare, återbetalningar)
- analysenhet (user/session/order/account)
- ägarskap och versionering
När logiken ändras, publicera en ny metrikversion istället för att redigera historiken—lagra sedan vilken version varje experiment använde.
What’s the minimum instrumentation and data quality checks we need?
Som minimum behöver du pålitliga joins mellan exposure och utfall:
- ett assignment/exposure-event som innehåller experiment ID och variant
- viktiga konversionsevents med kompatibla identitetsfält (user/device/account)
- tidsstämplar du kan lita på för attribuering
Automatisera sedan kontroller som:
Should we use frequentist or Bayesian stats in the tracker?
Välj en “dialekt” och håll dig till den:
- Frequentist: p-värden + konfidensintervall
- Bayesian: sannolikhet att förbättra + trovärdighetsintervall
Oavsett val, visa alltid:
- lift vs kontroll
- ett intervall (inte bara en punktuppskattning)
- analysfönster, enheter som räknas och vilken metrikdefinitionsversion som användes
What permissions and governance features are essential for a cross-product tracker?
Behandla åtkomstkontroll som en grundförutsättning:
- RBAC: Viewer / Editor / Admin
- Produkt-scoped access: användare ser bara produkter de tillhör
- valfria radnivå-begränsningar för känsliga experiment
Håll två revisionsspår:
How should we roll out the tracker, and what pitfalls should we watch for?
Rulla ut i en upprepbar ordning:
- börja med en produkt och ett litet mätset (t.ex. conversion, activation, revenue)
- validera end-to-end: assignment → joins → metrics → resultat → beslutsanteckningar
- expandera produkt för produkt med samma onboardingschecklista
Undvik vanliga fallgropar: