08 juli 2025·8 min
Hur man skapar en webbapp för tvärteam-beroendehantering
Lär dig planera och bygga en webbapp för tvärteam-beroendehantering: datamodell, UX, arbetsflöden, aviseringar, integrationer och utrullningssteg.
Lär dig planera och bygga en webbapp för tvärteam-beroendehantering: datamodell, UX, arbetsflöden, aviseringar, integrationer och utrullningssteg.
Innan du designar skärmar eller väljer tech stack, definiera tydligt vad “beroende” betyder i din organisation. Om folk använder ordet för allt blir din app bra på att spåra ingenting.
Skriv en enradersdefinition som alla kan återge, och lista vad som kvalificerar. Vanliga kategorier inkluderar:
Definiera också vad som inte är ett beroende (t.ex. “nice-to-have förbättringar”, generella risker eller interna uppgifter som inte blockerar ett annat team). Det håller systemet rent.
Beroendehantering misslyckas när den byggs bara för PMs eller bara för ingenjörer. Namnge dina primära användare och vad varje person behöver på 30 sekunder:
Välj en liten uppsättning utfall, som:
Samla problemen din app måste lösa från dag ett: föråldrade kalkylblad, oklara ägare, missade datum, dolda risker och statusuppdateringar utspridda i chattrådar.
När ni är överens om vad ni spårar och vem det är för, lås vokabulär och livscykel. Delade definitioner förvandlar “en lista med tickets” till ett system som minskar blockerare.
Välj en liten uppsättning typer som täcker de flesta situationer, och gör varje typ lätt att känna igen:
Målet är konsekvens: två personer ska klassificera samma beroende på samma sätt.
Ett beroendepost bör vara litet men komplett nog för att hantera:
Om du tillåter att skapa ett beroende utan owner team eller due date bygger du en “concern tracker”, inte ett koordinationsverktyg.
Använd en enkel statmodell som matchar hur team faktiskt arbetar:
Proposed → Accepted → In progress → Ready → Delivered/Closed, plus Rejected.
Skriv regler för state-changes. Till exempel: “Accepted kräver ett owner team och ett initialt måldatum”, eller “Ready kräver bevis”.
För stängning, kräva alla följande:
Dessa definitioner blir ryggraden i dina filter, påminnelser och statusgranskningar senare.
En beroende-tracker lyckas eller misslyckas beroende på om folk kan beskriva verkligheten utan att kämpa mot verktyget. Börja med ett litet antal objekt som matchar hur team redan pratar, och lägg till struktur där det förhindrar förvirring.
Använd ett fåtal primära poster:
Undvik att skapa separata typer för varje edge-case. Lägg hellre till några fält (t.ex. “type: data/API/approval”) än att dela upp modellen för tidigt.
Beroenden involverar ofta flera grupper och flera uppgifter. Modellera det explicit:
Detta förhindrar skört “ett beroende = en ticket”-tänkande och gör roll-up-rapportering möjlig.
Varje primärt objekt bör inkludera auditfält:
Inte varje beroende har ett team i din org-chart. Lägg till en Owner/Contact-post (namn, org, email/Slack, notes) och tillåt beroenden att peka på den. Det håller leverantörs- eller “annat avdelnings”-blockers synliga utan att tvinga in dem i er interna teamstruktur.
Om roller inte är explicita blir beroendehantering en kommentars-tråd: alla antar att någon annan ansvarar, och datum “justeras” utan kontext. En tydlig rollmodell gör appen trovärdig och gör eskalering förutsägbar.
Börja med fyra vardagsroller och en administrativ roll:
Gör Owner required och singular: ett beroende, en ansvarig owner. Du kan fortfarande stödja collaborators (bidragsgivare från andra team), men collaborators ska aldrig ersätta ansvar.
Lägg till en escalation path när en Owner inte svarar: först pinga Owner, sedan deras chef (eller team lead), sedan en program/release-ägare—baserat på er organisationsstruktur.
Separera “redigera detaljer” från “ändra åtaganden.” Ett praktiskt standard:
Om du stödjer privata initiativ, definiera vem som kan se dem (t.ex. bara involverade team + Admin). Undvik “hemliga beroenden” som överraskar leveransteamen.
Göm inte ansvar i en policydokument. Visa det på varje beroende:
Att märka “Accountable vs Consulted” direkt i formuläret minskar felroutning och gör statusgranskningar snabbare.
En beroende-tracker fungerar bara om folk hittar sina poster på några sekunder och uppdaterar dem utan att tänka. Designa kring de vanligaste frågorna: “Vad blockerar jag?”, “Vad blockerar mig?” och “Är något på väg att glida?”.
Börja med en liten uppsättning vyer som matchar hur team pratar om arbete:
De flesta verktyg misslyckas på “daglig uppdatering”. Optimera för hastighet:
Använd färg plus textetiketter (aldrig bara färg) och håll vokabulären konsekvent. Lägg till en tydlig “Last updated”-tidsstämpel på varje beroende, och en stale warning när det inte rörts under en definierad period (t.ex. 7–14 dagar). Detta uppmuntrar uppdateringar utan att tvinga möten.
Varje beroende bör ha en enda tråd som innehåller:
När detaljsidan berättar hela historien blir statusgranskningar snabbare—och många ”snabba syncs” försvinner eftersom svaret redan finns skrivet.
En beroende-tracker lyckas eller misslyckas på de vardagliga handlingarna den stödjer. Om team inte snabbt kan begära arbete, svara med ett tydligt åtagande och stänga loopen med bevis, blir din app en “FYI-board” istället för ett exekveringsverktyg.
Börja med ett enda “Create request”-flöde som fångar vad det levererande teamet måste leverera, varför det är viktigt och när det behövs. Håll det strukturerat: önskat due date, acceptanskriterier och en länk till relevant epic/spec.
Därifrån, tvinga ett explicit svarstillstånd:
Detta undviker det vanligaste felläget: tysta “kanske”-beroenden som ser okej ut tills de exploderar.
Definiera lätta förväntningar i själva workflowen. Exempel:
Målet är inte polisarbete; det är att hålla åtaganden aktuella så planering förblir ärlig.
Tillåt team att sätta ett beroende till At risk med en kort anteckning och nästa steg. När någon ändrar due date eller status, kräva en anledning (en dropdown + fri text). Denna enda regel skapar en audit trail som gör retrospektiv och eskalation faktabaserade, inte känslostyrda.
“Close” ska betyda att beroendet är tillfredsställt. Kräv evidence: en länk till en mergad PR, släppt ticket, dokument eller ett godkännandenotat. Om stängning är vag kommer team att “gröna” objekt tidigt för att minska buller.
Stöd bulkuppdateringar under statusgranskningar: välj flera beroenden och sätt samma status, lägga till en gemensam notis (t.ex. “re-planerat efter Q1-reset”) eller begär uppdateringar. Detta håller appen snabb nog att användas i riktiga möten, inte bara efter dem.
Notifieringar ska skydda leverans, inte distrahera folk. Det enklaste sättet att skapa brus är att larma alla om allt. Designa istället aviseringar kring beslutspunkter (någon måste agera) och risksignaler (något glider).
Håll första versionen fokuserad på händelser som ändrar planen eller kräver ett uttryckligt svar:
Varje trigger bör mappa till ett tydligt nästa steg: acceptera/avslå, föreslå nytt datum, lägg till kontext eller eskalera.
Vanligtvis ska du ha in-app notifications (så aviseringar hänger ihop med beroendeposten) plus email för allt som inte kan vänta.
Erbjud valfria chatintegrationer—Slack eller Microsoft Teams—men behandla dem som leveransmekanismer, inte system of record. Chattmeddelanden bör deep-linka tillbaka till posten (t.ex. /dependencies/123) och innehålla minimikontext: vem behöver agera, vad ändrades och när.
Ge team- och användarnivåkontroller:
Det är också här “watchers” spelar roll: notifiersa requester, owning team och uttryckligen tillagda stakeholders—undvik breda sändlistor.
Eskalering bör vara automatisk men konservativ: larma när ett beroende är försenat, när due date pushas upprepade gånger, eller när ett blocked-status saknar uppdatering under en definierad period.
Routa eskalationer till rätt nivå (team lead, program manager) och inkludera historiken så mottagaren kan agera snabbt utan att jaga kontext.
Integrationer ska eliminera ominmatning, inte lägga till installationsarbete. Den säkraste vägen är att börja med systemen team redan litar på (issue trackers, kalendrar och identitet), hålla första versionen read-only eller enväg, och expandera först när folk faktiskt använder det.
Välj en primär tracker (Jira, Linear eller Azure DevOps) och stöd ett enkelt link-first-flöde:
PROJ-123).Detta undviker “två sanningskällor” samtidigt som du ger beroendesynlighet. Senare, lägg till valfri tvåvägssync för ett litet fälturval (status, due date) med tydliga konfliktregler.
Milstolpar och deadlines hålls ofta i Google Calendar eller Microsoft Outlook. Börja med att läsa in events i din dependency-tidslinje (t.ex. “Release Cutoff”, “UAT Window”) utan att skriva tillbaka något.
Read-only kalender-synk låter team fortsätta planera där de redan gör det, medan din app visar konsekvenser och kommande datum på ett ställe.
Single sign-on minskar onboarding-friktion och behörighetsdrift. Välj baserat på kundrealitet:
Om du är tidig, leverera en provider först och dokumentera hur man begär fler.
Även icke-tekniska team drar nytta när intern ops kan automatisera handoffs. Erbjud några endpoints och event hooks med copy-paste-exempel.
# Create a dependency from a release checklist
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
Webhooks som dependency.created och dependency.status_changed låter team integrera med interna verktyg utan att vänta på din roadmap. För mer, se /docs/integrations.
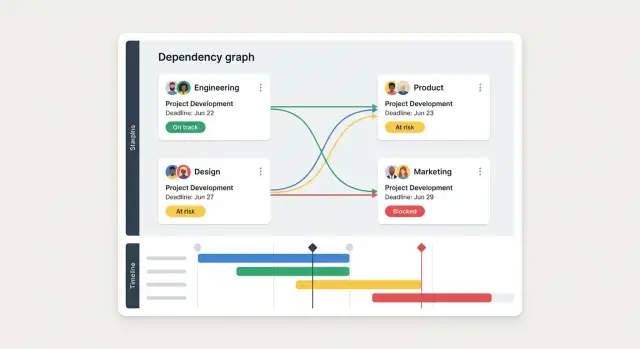
Dashboards är där en beroende-app tjänar sitt värde: de förvandlar “jag tror vi är blockerade” till en tydlig, delad bild av vad som behöver åtgärdas före nästa check-in.
En enda “one size fits all”-dashboard brukar misslyckas. Designa istället några vyer som matchar hur folk kör möten:
Bygg en liten uppsättning rapporter folk faktiskt använder i granskningar:
Varje rapport ska svara: “Vem behöver göra vad härnäst?” Inkludera ägare, förväntat datum och senaste uppdatering.
Gör filtrering snabb och uppenbar, för de flesta möten börjar med “visa bara …”
Stöd filter som team, initiative, status, due date range, risk level och tags (t.ex. “security review”, “data contract”, “release train”). Spara vanliga filter som namngivna vyer (t.ex. “Release A — nästa 14 dagar”).
Inte alla lever i din app hela dagarna. Erbjud:
Om du erbjuder en betald nivå, behåll adminvänliga delningskontroller och peka på /pricing för detaljer.
Du behöver ingen komplex plattform för att leverera en beroende-tracker. Ett MVP kan vara ett enkelt treaktssystem: en webb-UI för människor, ett API för regler och integrationer, och en databas som källa till sanning. Optimera för “lätt att ändra” över “perfekt.” Du lär dig mer av verklig användning än av månader av förhandsarkitektur.
En pragmatisk start kan se ut så här:
Om du förväntar dig Slack/Jira-integration snart, håll integrationerna som separata moduler/jobs som pratar med samma API, istället för att låta externa verktyg skriva direkt i databasen.
Om du vill nå ett fungerande produkt snabbt utan att bygga allt från scratch kan en vibe-coding-workflow hjälpa: till exempel kan Koder.ai generera en React-webb-UI och en Go + PostgreSQL-backend från en chattbaserad spec, och låta dig iterera med planning mode, snapshots och rollback. Du äger fortfarande arkitekturvalen, men kan korta vägen från “krav” till “användbar pilot” och exportera källkoden när du är redo att ta det in house.
De flesta skärmar är listvyer: öppna beroenden, blockers per team, ändringar den här veckan. Designa för det:
Beroendedata kan innehålla känsliga leveransdetaljer. Använd least-privilege access (team-nivå synlighet där lämpligt) och behåll audit logs för ändringar—vem ändrade vad och när. Denna audit-trail minskar debatt i statusgranskningar och gör verktyget pålitligt.
Att rulla ut en beroende-tracker handlar mindre om funktioner och mer om att ändra vanor. Behandla utrullningen som en produktlansering: börja smått, bevisa värde och skala med en tydlig operating-rutin.
Välj 2–4 team som jobbar på en gemensam initiative (t.ex. en release train eller ett kundprogram). Definiera framgångskriterier du kan mäta på några veckor:
Håll pilotkonfigurationen minimal: endast fälten och vyerna som krävs för att svara på “Vad är blockerat, av vem och när?”.
De flesta team spårar redan projektberoenden i kalkylblad. Importera dem, men gör det med eftertanke:
Kör en kort “data QA”-genomgång med pilotanvändare för att bekräfta definitioner och fixa tvetydiga poster.
Adoption fastnar när appen stödjer en befintlig rytm. Ge:
Om du bygger snabbt (t.ex. itererar piloten i Koder.ai), använd environments/snapshots för att testa ändringar i obligatoriska fält, statusar och dashboards med pilotteamen—sedan rulla framåt (eller tillbaka) utan att störa alla.
Spåra var folk fastnar: förvirrande fält, saknade statusar eller vyer som inte svarar på granskningsfrågor. Granska feedback veckovis under piloten och justera fält och standardvyer innan du bjuder in fler team. En enkel “Report an issue”-länk till /support hjälper hålla loopen tight.
När din beroende-tracker är live är de största riskerna beteendemässiga, inte tekniska. De flesta team överger inte verktyg för att de “inte fungerar”, utan för att uppdatering känns valfri, förvirrande eller bullrig.
För många fält. Om det känns som att fylla i ett formulär kommer folk skjuta upp eller hoppa över det. Börja med minimala obligatoriska fält: title, requesting team, owning team, “next action”, due date och status.
Oklart ägarskap. Om det inte är uppenbart vem som ska agera blir beroenden kommentars-trådar. Gör “owner” och “next action owner” explicita och visa dem framträdande.
Ingen uppdateringsvana. Även en bra UI misslyckas om saker blir gamla. Lägg in milda påminnelser: markera föråldrade objekt i listor, skicka påminnelser bara när due date närmar sig eller senaste uppdatering är gammal, och gör uppdateringar enkla (enklicks statusändring + kort notis).
Notifieringsöverbelastning. Om varje kommentar pingar alla kommer användare tysta systemet. Standardisera till opt-in watchers och skicka instead sammanfattningar (dagliga/veckovisa) för låg-urgensuppdateringar.
Behandla “next action” som ett förstaklassfält: varje öppet beroende ska alltid ha ett klart nästa steg och en enda ansvarig person. Om det saknas ska objektet inte se “komplett” ut i viktiga vyer.
Definiera också vad “done” betyder (t.ex. löst, inte längre nödvändigt eller flyttat till annan tracker) och kräva en kort stängningsorsak för att undvika zombie-objekt.
Bestäm vem som äger dina tags, team-lista och kategorier. Vanligtvis är det en program manager eller ops-roll med lätt change control. Sätt en enkel retire-policy: arkivera gamla initiatives automatiskt efter X dagar stängda och granska oanvända tags kvartalsvis.
När adoption stabiliserats, överväg förbättringar som ger värde utan att lägga friktion:
Om du behöver ett strukturerat sätt att prioritera förbättringar, koppla varje idé till en review-ritual (veckomöte, releaseplanering, incident-retrospektiv) så förbättringar drivs av verklig användning—inte gissningar.
Börja med en enradersdefinition som alla kan återge, och lista vad som kvalificerar (work item, deliverable, decision, environment/access).
Skriv också vad som inte räknas (nice-to-haves, generella risker, interna uppgifter som inte blockerar ett annat team). Det här hindrar verktyget från att bli ett vagt “concern tracker”.
Som minimum, designa för:
Om du bygger för endast en grupp kommer de andra inte att uppdatera det—och systemet blir gammalt.
Använd en liten, konsekvent livscykel såsom:
Definiera sedan regler för tillståndsbyten (t.ex. “Accepted kräver en owner team och ett mål datum”, “Ready kräver bevis”). Konsekvens är viktigare än komplexitet.
Kräv bara det du behöver för att koordinera:
Om du tillåter saknade owner eller due date kommer du samla objekt som inte går att agera på.
Gör “done” verifierbart. Kräv:
Detta förhindrar tidiga “grön” uppdateringar som bara minskar buller.
Definiera fyra vanliga roller plus admin:
Behåll “en dependency, en owner” för att undvika oklarhet; använd collaborators som hjälp, inte ansvarstagare.
Börja med vyer som svarar på dagliga frågor:
Optimera för snabba uppdateringar: templates, inline-redigering, tangentbordsvänliga kontroller och en tydlig “Last updated”.
Alert endast vid beslutspunkter och risksignaler:
Använd watchers istället för att sända brett, stöd digest-läge och deduplicera notifieringar (en sammanfattning per dependency per tidsfönster).
Integrera för att eliminera dubbelarbete, inte skapa en andra sanningskälla:
dependency.created, dependency.status_changed)Behandla chat (Slack/Teams) som en leveranskanal som deep-linkar tillbaka till posten, inte som system of record.
Kör en fokuserad pilot innan du skalar:
Behandla “ingen owner eller due date” som ofullständig och iterera baserat på var användare fastnar.