05 maj 2025·8 min
Skapa en webbapp för att hantera kundeskaleringstidslinjer
Steg-för-steg-plan för att bygga en webbapp som spårar kundeskaleringar, deadlines, SLA:er, ägarskap och aviseringar — inklusive rapportering och integrationer.
Steg-för-steg-plan för att bygga en webbapp som spårar kundeskaleringar, deadlines, SLA:er, ägarskap och aviseringar — inklusive rapportering och integrationer.
Innan du designar skärmar eller väljer teknikstack, var specifik med vad “eskalering” betyder i din organisation. Är det ett supportärende som åldras, en incident som hotar drifttid, ett klagomål från en nyckelkund eller en begäran som passerar en allvarlighetsnivå? Om olika team använder ordet olika kommer din app att bära på förvirring.
Skriv en enkelsatsdefinition som hela teamet kan enas om, och lägg till några exempel. Till exempel: “En eskalering är ett kundärende som kräver högre supportnivå eller ledningsinblandning och har ett tidsbundet åtagande.”
Definiera också vad som inte räknas (t.ex. rutinärenden, interna uppgifter) så att v1 inte växer onödigt.
Framgångskriterier bör spegla vad du vill förbättra — inte bara vad du vill bygga. Vanliga kärnutfall inkluderar:
Välj 2–4 mätvärden du kan spåra från dag ett (t.ex. brottsfrekvens, tid i varje eskaleringssteg, antal omfördelningar).
Lista primära användare (agenter, teamledare, chefer) och sekundära intressenter (account managers, engineering on-call). För varje roll, notera vad de behöver göra snabbt: ta ägarskap, förlänga en deadline med anledning, se vad som kommer härnäst eller summera status för en kund.
Fånga nuvarande felmodeller med konkreta berättelser: missade överlämningar mellan nivåer, oklara förfallotider efter omfördelning, “vem godkände förlängningen?”-debatter.
Använd dessa berättelser för att skilja must-haves (tidslinje + ägarskap + revisibilitet) från senare tillägg (avancerade dashboards, komplex automation).
När målen är klara, skriv ner hur en eskalering rör sig genom teamet. Ett delat arbetsflöde förhindrar att “specialfall” blir inkonsekvent hanterade och leder till missade SLA:er.
Börja med en enkel uppsättning steg och tillåtna övergångar:
Dokumentera vad varje steg innebär (inträdeskriterier) och vad som måste vara sant för att lämna det (utgångskriterier). Här undviker du tvetydigheter som “Resolved men fortfarande väntar på kund”.
Eskaleringar bör skapas av regler du kan förklara med en mening. Vanliga triggers inkluderar:
Bestäm om triggers skapar eskalering automatiskt, föreslår för agenten eller kräver godkännande.
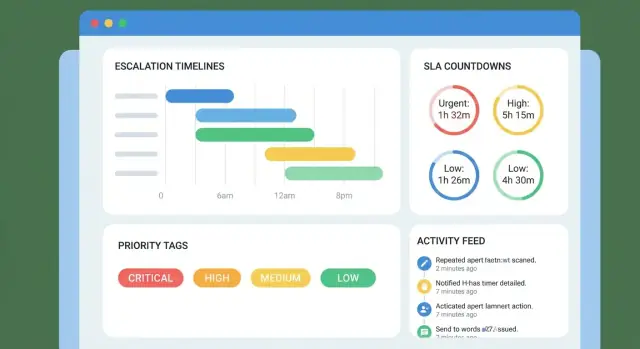
Din tidslinje är bara så bra som dess händelser. Minst bör du fånga:
Skriv regler för ägarbyten: vem kan omfördela, när godkännanden krävs (t.ex. cross-team eller vendor-handoff) och vad som händer om en ägare går av skift.
Kartlägg slutligen beroenden som påverkar tid: on-call-scheman, nivåer (T1/T2/T3) och externa leverantörer (inklusive deras svarsfönster). Detta styr senare dina tidslinjeberäkningar och eskalationsmatris.
En pålitlig eskaleringsapp är mestadels ett data-problem. Om tidslinjer, SLA:er och historik inte modelleras tydligt kommer UI och aviseringar alltid kännas “fel”. Börja med att namnge kärn-entiteterna och relationerna.
Minst planera för:
Behandla varje milstolpe som en timer med:
start_at (när klockan börjar)due_at (beräknad deadline)paused_at / pause_reason (valfritt)completed_at (när den möttes)Spara varför ett förfallodatum finns (regeln), inte bara den beräknade tidsstämpeln. Det gör tvister lättare att lösa senare.
SLA:er betyder sällan “alltid”. Modellera en kalender per SLA-policy: arbetstider vs 24/7, helgdagar och regionspecifika scheman.
Beräkna deadlines i en konsekvent servertid (UTC), men spara alltid case-tidszonen (eller kundens tidszon) så UI kan visa deadlines korrekt och användare kan resonera om dem.
Bestäm tidigt mellan:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), ellerFör efterlevnad och ansvar, föredra en händelselogg (även om du också behåller “current state” kolumner för prestanda). Varje ändring bör logga vem, vad ändrades, när och källa (UI, API, automation), plus ett korrelations-ID för att spåra relaterade åtgärder.
Behörigheter är där eskaleringsverktyg antingen förtjänar förtroende — eller kringgås med sidokalkylblad. Definiera vem som kan göra vad tidigt, och tillämpa det konsekvent i UI, API och export.
Håll v1 enkelt med roller som matchar hur supportteam faktiskt arbetar:
Gör rollkontroller explicita i produkten: inaktivera kontroller istället för att låta användare klicka sig till fel.
Eskaleringar spänner ofta över flera grupper. Planera för multi-teamstöd genom att avgränsa synlighet med en eller flera dimensioner:
En bra standard: användare kan komma åt ärenden där de är assignee, watcher eller tillhör ägarteamet — plus konton som uttryckligen delats med deras roll.
Inte all data ska vara synlig för alla. Vanliga känsliga fält inkluderar kund-PII, kontraktsdetaljer och interna anteckningar. Implementera fält-nivå behörigheter som:
För v1 räcker ofta e-post/lösenord med stöd för MFA. Designa användarmodellen så att du kan lägga till SSO senare (SAML/OIDC) utan att skriva om behörigheter (t.ex. spara roller/team internt, mappa SSO-grupper vid inloggning).
Behandla behörighetsändringar som auditerbara. Logga händelser som rolluppdateringar, team-omfördelningar, exportnedladdningar och konfigurationsändringar — vem gjorde det, när och vad som ändrades. Detta skyddar vid incidenter och gör accessgranskningar enklare.
Din eskaleringsapp vinner eller förlorar på vardagssidorna: vad en supportlead ser först, hur snabbt de förstår ett ärende och om nästa deadline är omöjlig att missa.
Börja med en liten uppsättning sidor som täcker 90% av arbetet:
Håll navigation förutsägbar: en vänsterpanel eller toppflikar med “Queue”, “My Cases”, “Reports”. Gör kö-sidan till standardlandning.
I caseraden, visa bara fält som hjälper någon att avgöra vad som ska göras härnäst. En bra standardrad innehåller: kund, prioritet, aktuell ägare, status, nästa förfallodatum och en varningsindikator (t.ex. “Due in 2h” eller “Overdue by 1d”).
Lägg till snabba, praktiska filter och sök:
Designa för snabb skanning: konsekventa kolumnbredder, tydliga status-chips och en enda highlightfärg för brådskande ärenden.
Case-vyn ska svara, på en blick:
Placera snabba åtgärder nära toppen (inte gömda i menyer): Reassign, Escalate, Add milestone, Add note, Set next deadline. Varje åtgärd ska bekräfta ändringen och uppdatera tidslinjen omedelbart.
Din tidslinje ska läsas som en tydlig sekvens av åtaganden. Inkludera:
Använd progressiv visning: visa senaste händelser först, med möjlighet att expandera äldre historik. Om du har ett revisionsspår, länka till det från tidslinjen (t.ex. “View change log”).
Använd läsbar färgkontrast, para ihop färg med text (“Overdue”), se till att alla åtgärder nås med tangentbord och skriv etiketter som matchar användarnas språk (“Set next customer update deadline”, inte “Update SLA”). Detta minskar feltryckningar under press.
Aviseringar är eskalerings-tidslinjens “hjärtslag”: de håller ärenden i rörelse utan att tvinga folk att stirra på en instrumentpanel hela dagen. Målet är enkelt — meddela rätt person, vid rätt tidpunkt, med minsta möjliga brus.
Börja med ett litet antal händelser som leder direkt till åtgärd:
För v1 välj kanaler du kan leverera tillförlitligt och mäta:
SMS eller chattverktyg kan komma senare när regler och volymer är stabila.
Representera eskalering som tidsbaserade trösklar knutna till ärendets tidslinje:
Håll matrisen konfigurerbar per prioritet/kö så P1-incidenter inte följer samma mönster som faktureringsfrågor.
Implementera deduplicering (“skicka inte samma notis två gånger”), batchning (samla liknande notiser) och quiet hours som fördröjer icke-kritiska påminnelser men ändå loggar dem.
Varje notis bör stödja:
Spara dessa åtgärder i ditt revisionsspår så rapportering kan skilja på “ingen såg det” och “någon såg det och skjöt upp det”.
De flesta eskaleringsappar misslyckas när de kräver att folk skriver om data som redan finns någon annanstans. För v1 integrera bara det som behövs för att hålla tidslinjer och aviseringar korrekta.
Bestäm vilka kanaler som kan skapa eller uppdatera ett eskaleringsärende:
Håll inkommande payloads små: case ID, customer ID, status, prioritet, tidsstämplar och en kort sammanfattning.
Din app bör meddela andra system när något viktigt händer:
Använd webhooks med signerade requests och ett event-ID för deduplicering.
Om du synkar båda vägar, deklarera en sanningskälla per fält (t.ex. ticketing-verktyget äger status; din app äger SLA-timers). Definiera konfliktregler (“last write wins” är sällan rätt) och lägg till retry-logik med backoff plus en dead-letter-kö för fel.
För v1 importera kunder och kontakter med stabila externa ID:n och ett minimalt schema: kontonamn, nivå, nyckelkontakter och eskaleringspreferenser. Undvik djup CRM-spegelning.
Dokumentera en kort checklista (auth-metod, obligatoriska fält, rate limits, retries, testmiljö). Publicera ett minimalt API-kontrakt (till och med en enkelsidig spec) och versionera det så integrationer inte går sönder oväntat.
Din backend måste göra två saker bra: hålla eskaleringstider korrekta och vara snabb när ärendevolymen växer.
Välj den enklaste arkitektur ert team kan underhålla. En klassisk MVC-app med ett REST-API räcker ofta för en v1 supportarbetsflödes-app. Om ni redan använder GraphQL framgångsrikt kan det fungera — men undvik att lägga till det “bara för att”. Para det med en hanterad databas (t.ex. Postgres) så ni lägger tid på eskaleringslogik, inte databasdrift.
Om ni vill validera flödet end-to-end innan ni förbinder er till veckors utveckling kan en vibe-koding-plattform som Koder.ai hjälpa er att prototypa kärnloopen (kö → case-detalj → tidslinje → aviseringar) från en chattgränssnitt, iterera i planeringsläge och exportera källkod när ni är redo. Dess default-stack (React web, Go + PostgreSQL på backend) är praktisk för denna typ av revisionsintensiv app.
Eskaleringar beror på schemalagt arbete, så du behöver bakgrundsprocesser för:
Gör jobben idempotenta (säkra att köra två gånger) och retrybara. Spara en “last evaluated at” tidsstämpel per case/tidslinje för att undvika dubbla åtgärder.
Spara alla tidsstämplar i UTC. Konvertera till användarens tidszon endast i UI/API-gränsytan. Lägg till tester för kantfall: sommartidsändringar, skottårsdagar och ”pausade” klockor (t.ex. SLA pausad när man väntar på kund).
Använd paginering för köer och revisionsvyer. Lägg till index som matchar dina filter och sorteringar — vanliga index: (due_at), (status), (owner_id) och kompositindex som (status, due_at).
Planera filhantering separat från DB: sätt gränser för storlek/typ, skanna uppladdningar (eller använd leverantörsintegration), och ställ in rensningsregler (t.ex. ta bort efter 12 månader om inte legal hold). Håll metadata i case-tabeller; filer i objektlagring.
Rapportering är där din eskaleringsapp slutar vara en gemensam inkorg och blir ett ledningsverktyg. För v1 sikta på en enda rapportsida som svarar på två frågor: “Möter vi SLA:erna?” och “Var fastnar eskaleringarna?”. Håll det enkelt, snabbt och förankrat i definitioner alla är överens om.
En rapport är bara så pålitlig som dess definitioner. Skriv ner dem i klartext och spegla dem i datamodellen:
Bestäm också vilken SLA-klocka du rapporterar: första svar, nästa uppdatering eller lösning (eller alla tre).
Din dashboard kan vara lättviktig men handlingsbar:
Lägg till operationella vyer för daglig belastningsbalansering:
CSV-export räcker ofta för v1. Knyt exporter till behörigheter (team-baserad åtkomst, rollkontroller) och logga varje export i revisionsloggen (vem, när, filter som användes, antal rader). Det förhindrar “mystery spreadsheets” och stödjer compliance.
Skicka ut den första rapportsidan snabbt, och granska den med supportleads veckovis i en månad. Samla feedback om saknade filter, förvirrande definitioner och “jag kan inte svara på X” — det är bra input för v2.
Att testa en eskalerings-app handlar inte bara om “fungerar det?” utan om “beter den sig som supportteam förväntar sig under press?”. Fokusera på realistiska scenarier som belastar tidslinjeregler, aviseringar och överlämningar.
Lägg mest testkraft på tidslinjeberäkningar — små fel här ger stora SLA-tvister.
Täcka fall som arbetstidsräkning, helgdagar och tidszoner. Lägg till tester för pauser (väntar på kund/engineeringsarbete), prioritetsskiften mitt i ärendet och eskaleringar som ändrar måltider. Testa också kantfall: ärende skapat en minut innan stängning eller en paus som börjar exakt vid en SLA-gräns.
Aviseringar fallerar ofta i glappet mellan system. Skriv integrationstester som verifierar:
Om ni använder e-post, chat eller webhooks, asserta payloads och timing — inte bara att “något skickades”.
Skapa realistiska exempeldata som avslöjar UX-problem tidigt: VIP-kunder, långvariga ärenden, frekventa omfördelningar, återöppnade incidenter och peakperioder. Detta hjälper er validera att köer, case-vy och tidslinje är läsbara utan förklaring.
Kör en pilot med ett team i 1–2 veckor. Samla in dagliga problem: saknade fält, förvirrande etiketter, notisbrus och undantag från era regler.
Spåra vad användare gör utanför appen (kalkylblad, sidokanaler) för att hitta luckor.
Skriv ner vad “klart” betyder innan bred lansering: nyckel-SLA-metriker matchar förväntade resultat, kritiska notiser är pålitliga, revisionsspår är kompletta och pilotteam kan hantera eskaleringar end-to-end utan tillfälliga lösningar.
Att leverera första versionen är inte slutmålet. En eskaleringsapp blir ”verklig” först när den överlever vardagliga fel: missade jobb, långsamma frågor, felaktigt konfigurerade notiser och ändrade SLA-regler. Behandla driftsättning och drift som en del av produkten.
Håll releaseprocessen tråkig och repeterbar. Dokumentera och automatisera minst:
Om ni har staging, fyll den med realistisk (sanerad) data så tidslinje- och notisbeteende kan verifieras före produktion.
Traditionella uptime-checkar fångar inte alltid de värsta problemen. Lägg övervakning där eskaleringar kan brytas tyst:
Skapa en liten on-call-playbook: “Om eskaleringspåminnelser inte skickas, kolla A → B → C.” Detta minskar driftstörningar under press.
Eskaleringdata innehåller ofta kundnamn, e-post och känsliga anteckningar. Definiera policyer tidigt:
Gör retention konfigurerbar så policyuppdateringar inte kräver kodändringar.
Redan i v1 behöver admins verktyg för att hålla systemet hälsosamt:
Skriv korta, uppgiftsbaserade guider: “Skapa en eskalering”, “Pausa en tidslinje”, “Åsidosätt SLA”, “Granska vem ändrade vad.”
Lägg till ett lätt onboardingflöde i appen som pekar användare till köer, case-vy och tidslinjeåtgärder samt en länk till en /help-sida för referens.
Version 1 ska bevisa kärnloopen: ett ärende har en tydlig tidslinje, SLA-klockan beter sig förutsägbart och rätt personer får notiser. Version 2 kan lägga till kraft utan att göra v1 till ett komplext “allt i ett”-system. Tricket är att hålla en kort, explict backlog med uppgraderingar som du bara drar in efter verklig användning.
Ett bra v2-item är något som (a) minskar manuellt arbete i skala, eller (b) förhindrar kostsamma misstag. Om det mest lägger till konfigurationsmöjligheter, parkera det tills du har bevis att flera team verkligen behöver det.
SLA-kalendrar per kund är ofta första meningsfulla expansionen: olika öppettider, helgdagar eller avtalade responstider.
Nästa steg: playbooks och mallar — färdiga eskaleringssteg, rekommenderade intressenter och textmallar som gör svar konsekventa.
När tilldelning blir en flaskhals, överväg skills-baserad routing och on-call-scheman. Håll första iterationen enkel: ett litet antal skills, en fallback-ägare och tydliga överskrivningskontroller.
Auto-eskalering kan triggas av signaler (allvarlighetsändringar, nyckelord, sentiment, upprepade kontakter). Börja med “föreslagen eskalering” (en prompt) innan du kör automatisk eskalering, och logga alltid triggerorsaken för förtroende och auditerbarhet.
Lägg till obligatoriska fält innan eskalering (impact, severity, customer tier) och godkännandesteg för höga severity-ärenden. Detta minskar brus och hjälper rapportering att förbli korrekt.
Om du vill utforska automationsmönster innan du bygger dem, se /blog/workflow-automation-basics. Om du matchar scope till paketering, sanity-checka hur funktioner kartläggs till nivåer på /pricing.
Börja med en enkel, enhällig mening som alla i teamet accepterar (plus några exempel). Inkludera också explicita icke-exempel (rutinsupport, interna uppgifter) så att v1 inte blir ett generellt ärendehanteringssystem.
Skriv sedan 2–4 mätbara framgångsmetrier som du kan följa direkt, till exempel SLA-brottsfrekvens, tid i varje steg eller antal omfördelningar.
Välj resultat som speglar operationell förbättring — inte bara vad ni vill bygga. Praktiska v1-metriker inkluderar:
Välj en liten uppsättning som du kan beräkna från dag ett-tidsstämplar.
Använd en kort gemensam uppsättning steg med tydliga in-/utgångskriterier, till exempel:
Skriv vad som måste vara sant för att gå in i och lämna varje steg. Det förhindrar tvetydigheter som “Resolved men fortfarande väntar på kunden.”
Fånga de minsta händelserna som behövs för att rekonstruera tidslinjen och försvara SLA-beslut:
Om du inte kan förklara hur en tidsstämpel används, samla inte in den i v1.
Modellera varje milstolpe som en timer med:
start_atdue_at (beräknad)paused_at och pause_reason (valfritt)completed_atSpara också regeln som gav upphov till (policy + kalender + anledning). Det gör revisioner och tvister mycket enklare än att bara lagra det slutliga datumet.
Spara alla tidsstämplar i UTC, men behåll en case-/kundtidszon för visning och användarrationalisering. Modellera SLA-kalendrar explicit (24/7 vs öppettider, helgdagar, regionsscheman).
Testa kantfall som sommartidsändringar, ärenden skapade nära arbetsdagens slut och pauser som startar exakt vid en gräns.
Håll v1-rollerna enkla och i linje med verkliga arbetssätt:
Lägg till scopes (team/region/konto) och fältbaserade regler för känsliga uppgifter som interna anteckningar och PII.
Designa de dagliga skärmarna först:
Optimera för snabb översikt och minimera kontextbyten — snabba åtgärder ska inte gömmas i menyer.
Börja med ett litet antal högsignal-aviseringar:
Välj 1–2 kanaler för v1 (vanligtvis in-app + e-post), och lägg till en eskaleringsmatris med tydliga trösklar (T–2h, T–0h, T+1h). Motverka trötthet med deduplering, batchning och tysta tider, och gör acknowledge/snooze auditerbart.
Integrera bara det som behövs för att hålla tidslinjerna korrekta:
Om du synkar tvåvägs, definiera en sanningskälla per fält och konfliktregler (undvik “last write wins”). Publicera en minimal versionerad API-spec så integrationer inte går sönder. För mer om automatiseringsmönster, se /blog/workflow-automation-basics; för paketeringsöverväganden, se /pricing.
due_at