16 mars 2025·8 min
Skapa en webbapp för kundeskaleringar och prioriterat stöd
Lär dig planera, designa och bygga en webbapp som routar eskaleringar, upprätthåller SLA:er och håller prioriterat stöd organiserat med tydliga flöden och rapportering.
Lär dig planera, designa och bygga en webbapp som routar eskaleringar, upprätthåller SLA:er och håller prioriterat stöd organiserat med tydliga flöden och rapportering.
Innan du bygger skärmar eller skriver kod, bestäm vad din app är till för och vilket beteende den ska upprätthålla. Eskaleringar är inte bara “arga kunder” — det är ärenden som kräver snabbare hantering, högre synlighet och tajtare samordning.
Definiera eskaleringskriterier i enkelt språk så agenter och kunder slipper gissa. Vanliga triggers inkluderar:
Definiera också vad som inte är en eskalering (till exempel hur-man-frågor, funktionsönskemål, mindre buggar) och hur de förfrågningarna istället bör routas.
Lista de roller ditt flöde behöver och vad varje roll kan göra:
Skriv ner vem som äger ärendet i varje steg (inklusive överlämningar) och vad “ägarskap” betyder (svarskrav, nästa uppdateringstid och befogenhet att eskalera).
Starta med ett litet antal ingångar så du kan leverera snabbare och hålla triage konsekvent. Många team börjar med e-post + webbformulär, och lägger till chat när SLA:er och routing är stabila.
Välj mätbara utfall som appen ska förbättra:
Dessa beslut blir produktkrav för resten av bygget.
En app för prioriterat stöd lever eller dör på sin datamodell. Får du grunderna rätt blir routing, rapportering och SLA-uppföljning enklare — eftersom systemet har de fakta det behöver.
Minst bör varje ärende fånga: requester (en kontakt), företag (kundkonto), ämne, beskrivning och bilagor. Behandla beskrivningen som det ursprungliga problemet; senare uppdateringar hör hemma i kommentarer så du kan se hur historien utvecklats.
Eskaleringar behöver mer struktur än allmän support. Vanliga fält inkluderar severity (hur allvarligt), impact (hur många användare/vilken intäkt) och priority (hur snabbt ni ska svara). Lägg till ett påverkad tjänst-fält (t.ex. Billing, API, Mobile App) så triage kan routa snabbt.
För deadlines, spara explicita förfallotider (som “first response due” och “resolution/next update due”), inte bara ett “SLA-namn.” Systemet kan beräkna dessa tidsstämplar, men agenter ska se de exakta tiderna.
En praktisk modell innehåller vanligtvis:
Detta håller samarbetet rent: konversationer i kommentarer, åtgärdspunkter i uppgifter och ägarskap på ärenden.
Använd en liten, stabil uppsättning statusar som: New, Triaged, In Progress, Waiting, Resolved, Closed. Undvik “nästan samma” statusar — varje extra status gör rapportering och automation mindre tillförlitlig.
För SLA-uppföljning och ansvar bör viss data vara append-only: skapade/uppdaterade tidsstämplar, historik av statusändringar, SLA start/stop-händelser, eskaleringsändringar och vem som gjorde varje ändring. Föredra en audit log (eller händelsetabell) så du kan rekonstruera vad som hände utan gissningar.
Prioritet och SLA-regler är det “kontrakt” din app upprätthåller: vad som hanteras först, hur snabbt och vem som är ansvarig. Håll schemat enkelt, dokumentera tydligt och gör det svårt att åsidosätta utan anledning.
Använd fyra nivåer så agenter snabbt kan klassificera och chefer enkelt kan rapportera konsekvent:
Definiera “impact” (hur många användare/kunder) och “urgency” (hur tidskänsligt) i UI:t för att minska felaktig klassificering.
Din datamodell bör tillåta att SLA:er varierar efter kundplan/tier (t.ex. Free/Pro/Enterprise) och prioritet. Vanligtvis spårar du åtminstone två timers:
Exempel: Enterprise + P1 kan kräva first response på 15 minuter, medan Pro + P3 kan vara 8 arbetstimmar. Håll regelbordet synligt för agenter och länka det från ärendesidan.
Support-SLA:er beror ofta på om planen inkluderar 24/7-täckning.
Visa både “SLA kvar” och vilket schema som används på ärendet (så agenter litar på timern).
Verkliga flöden behöver pauser. En vanlig regel: pausa SLA när ärendet är Waiting on customer (eller Waiting on third party), och återuppta när kunden svarar.
Var tydlig med:
Undvik tysta överträdelser. Hantering av överträdelser ska skapa en synlig händelse i ärendehistoriken.
Sätt minst två varningsnivåer:
Routa varningar baserat på prioritet och tier så människor inte blir uppringda för P4-brus. Om du vill ha mer detaljer, koppla detta avsnitt till dina on-call-regler i /blog/notifications-and-on-call-alerting.
Triage och routing är där en app för prioriterat stöd antingen sparar tid — eller skapar förvirring. Målet är enkelt: varje ny förfrågan ska landa rätt snabbt, med en tydlig ägare och ett uppenbart nästa steg.
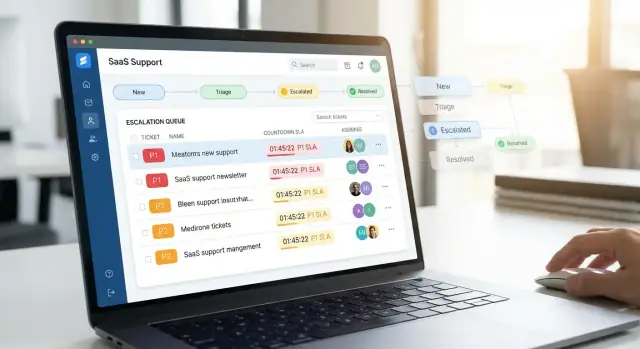
Börja med en dedikerad triage-inbox för unassigned eller needs-review ärenden. Håll den snabb och förutsägbar:
En bra inbox minimerar klick: agenter ska kunna ta, routa eller eskalera från listan utan att öppna varje ärende.
Routing bör vara regelbaserad men läsbar för icke-tekniker. Vanliga inputs:
Spara varför varje routingbeslut gjordes (t.ex. “Matched keyword: SSO → Auth team”). Det gör tvister enkla att lösa och förbättrar utbildning.
Även de bästa reglerna behöver en flyktväg. Tillåt auktoriserade användare att override:a routing och trigga eskaleringsvägar som:
Agent → Team lead → On-call
Overrides bör kräva en kort anledning och skapa en audit-post. Om du senare har on-call-alerting, länka eskaleringsåtgärder till det (se /blog/notifications-and-on-call-alerting).
Dubbletter slösar SLA-tid. Lägg till lättviktiga verktyg:
Länkade ärenden bör ärva statusuppdateringar och publik kommunikation från parent.
Definiera tydliga ägarskapsstatusar:
Visa ägarskap överallt: listvy, ärenderubrik och aktivitetslogg. När någon frågar “Vem har detta?”, ska appen svara direkt.
En app för prioriterat stöd vinner eller förlorar på de första 10 sekunder en agent lägger i den. Dashboarden ska omedelbart svara tre frågor: vad behöver uppmärksamhet nu, varför, och vad kan jag göra härnäst.
Börja med ett litet antal högnytta-vyer istället för en labyrint av flikar:
Använd klara, konsekventa signaler så agenter inte behöver “läsa” varje rad:
Håll typografin enkel: en primär accentfärg och en tydlig hierarki (titel → kund → status/SLA → senaste uppdatering).
Varje ärenderad bör stödja snabba åtgärder utan att öppna fullsidan:
Lägg till bulk actions (assign, close, apply tag, set blocker) för att snabbt rensa backloggar.
Stöd tangentbordsgenvägar för effektiva användare: / för sökning, j/k för att flytta, e för eskalera, a för tilldela, g sedan q för att återgå till kö.
För tillgänglighet, säkerställ tillräcklig kontrast, synliga focus-states, märkta kontroller och skärmläsarvänlig status-text (t.ex. “SLA: 12 minutes remaining”). Gör tabellen responsiv så samma flöde fungerar på mindre skärmar utan att dölja kritiska fält.
Notifieringar är appens “nervsystem”: de förvandlar ärendeändringar till snabb handling. Målet är inte att notifiera mer — utan att notifiera rätt personer, i rätt kanal, med tillräcklig kontext för att agera.
Börja med en tydlig uppsättning händelser som triggar meddelanden. Vanliga, hög-signalför typer inkluderar:
Varje meddelande bör inkludera ärende-ID, kundnamn, prioritet, aktuell ägare, SLA-timers och en djup-länk till ärendet.
Använd in-app-notiser för dagligt arbete och e-post för beständiga uppdateringar och handoffs. För verkliga on-call-scenarier, lägg till SMS/push som ett valbart kanalval reserverat för akuta händelser (som P1-eskalering eller omedelbart hotande brott).
Alert fatigue dödar responstiden. Lägg in kontroller som gruppering, tysta timmar och deduplicering:
Tilhandahåll mallar för både kundvända uppdateringar och interna notiser så ton och fullständighet förblir konsekventa. Spåra leveransstatus (sent, levererat, misslyckats) och håll en notifieringstidslinje per ärende för spårbarhet och uppföljning. En enkel flik “Notifications” på ärendedetaljsidan gör detta lätt att granska.
Ärendedetaljsidan är där eskaleringsarbetet faktiskt händer. Den ska hjälpa agenter att förstå kontext på sekunder, samordna med kollegor och kommunicera med kunden utan misstag.
Gör kompositorn tydlig: välj Customer Reply eller Internal Note, med olika stil och en klar förhandsgranskning. Interna noteringar bör stödja enkel formatering, länkar till runbooks och privata taggar (t.ex. “needs engineering”). Kundsvar bör ha en vänlig mall som standard och visa exakt vad som kommer skickas.
Stöd en kronologisk tråd som inkluderar e-post, chatttranskript och systemhändelser. För bilagor, prioritera säkerhet:
Om du visar kunduppladdade filer, ange vem som laddade upp dem och när.
Lägg till macros som sätter in förgodkända svar plus felsökningschecklistor (t.ex. “collect logs”, “restart steps”, “status page wording”). Låt teamen ha ett delat makro-bibliotek med versionshistorik så eskaleringar förblir konsekventa och följer regelverk.
Visa, vid sidan av meddelanden, en kompakt event-tidslinje: statusändringar, prioriteringsuppdateringar, SLA-pauser/återupptagningar, ansvarsförflyttningar och eskaleringsnivåskiften. Detta förhindrar onödig “vad ändrades?”-kommunikation och hjälper vid efterinsatsgranskningar.
Aktivera @-omnämnanden, följare och länkade uppgifter (engineering-ärende, incidentdokument). Omnämnanden bör notifiera bara rätt personer, och följare bör få sammanfattningar vid materiella ändringar — inte vid varje tangenttryckning.
Säkerhet är inte en “sen” funktion för en eskaleringsapp: eskaleringar innehåller ofta kundmail, skärmdumpar, loggar och interna noteringar. Bygg skydd tidigt så agenter kan agera snabbt utan att dela för mycket data eller tappa förtroende.
Börja med en liten uppsättning roller som går att förklara i en mening vardera (t.ex. Agent, Team Lead, On-Call Engineer, Admin). Definiera sedan vad varje roll kan se, redigera, kommentera, omfördela och exportera.
En praktisk approach är “default deny”:
Samla bara det arbetsflödet behöver. Om du inte behöver fullständiga meddelandetexter eller kompletta IP-adresser, spara dem inte. När du lagrar kunddata, markera vilka fält som är obligatoriska vs. frivilliga och undvik att kopiera data från andra system utan skäl.
Anta i åtkomstmönster att “supportagenter bör se minsta mängd för att lösa ärendet.” Använd konto- och kö-scoping innan du lägger till komplexa regler.
Använd beprövad autentisering (SSO/OIDC om möjligt), kräva starka lösenord när lösenord används och stöd multifaktor för höga roller.
Härda sessioner:
Spara hemligheter i en hanterad secret store (inte i källkod). Logga åtkomst till känsliga data (vem visade en eskalering, laddade ner en bilaga, exporterade ett ärende) och gör revisionsloggar svåra att manipulera och sökbara.
Definiera retention-regler för ärenden, bilagor och audit logs (t.ex. ta bort bilagor efter N dagar, behåll audit logs längre). Ge exports för kunder eller intern rapportering, men undvik att påstå specifika compliance-certifieringar om du inte kan verifiera dem. Ett enkelt “data export”-flöde plus ett admin-område för “delete request” är en bra start.
Din eskaleringsapp blir bara effektiv om den är lätt att förändra. Eskaleringsregler, SLA:er och integrationer utvecklas konstant, så prioritera en stack ditt team kan underhålla och anställa för.
Välj bekanta verktyg framför “perfekta” verktyg. Några vanliga, beprövade kombinationer:
Om du redan har en monolit någon annanstans, minskar matchning av det ekosystemet ofta inlärningstid och driftkomplexitet.
Om du vill komma snabbare igång utan ett stort ingenjörsbygge kan du prototypa arbetsflödet i en vibe-coding-plattform som Koder.ai — särskilt för standarddelar som en React-baserad agentdashboard, en Go/PostgreSQL-backend och jobbstyrd SLA-/notifikationslogik.
För kärnposter — tickets, customers, SLA-händelser, eskaleringsevent, tilldelningar — använd en relationsdatabas (Postgres är vanligt standard). Den ger transaktioner, constraints och rapportvänliga frågor.
För snabb sökning i ämnesrader, konversationstext och kundnamn, överväg senare en sökindex (t.ex. Elasticsearch/OpenSearch). Håll det valfritt först: börja med Postgres full-text search och skala upp om du växer ur det.
Eskalationsappar beror på tidsbaserat och integrationsarbete som inte bör köras i en webbförfrågan:
Använd en jobbkön (t.ex. Celery, Sidekiq, BullMQ) och gör jobb idempotenta så retries inte skapar dubbla varningar.
Oavsett om du väljer REST eller GraphQL, definiera resursgränser tidigt: tickets, comments, events, customers och users. En konsekvent API-stil gör integrationer och UI-utveckling snabbare. Planera också för webhook-endpoints från start (signerade hemligheter, retries och rate limits).
Kör minst dev/staging/prod. Staging bör spegla prod-inställningar (mailleverantörer, köer, webhooks) med säkra testuppgifter. Dokumentera deployment- och rollback-steg och håll konfiguration i miljövariabler — inte i kod.
Integrationer förvandlar din eskaleringsapp från “ytterligare en plats att kolla” till systemet teamet faktiskt arbetar i. Börja med kanaler kunder redan använder, och lägg till automation-hooks så andra verktyg kan reagera på eskaleringshändelser.
E-post är ofta den högsta impact-integrationen. Stöd inbound-forwarding (t.ex. support@) och parsa:
För utgående, skicka från ärendet (reply/forward) och bevara trådningshuvuden så svar går tillbaka till samma ärende. Spara en ren konversationstidslinje: visa vad kunden såg, inte interna noteringar.
För chatt (Slack/Teams/intercom-widgetar), håll det enkelt: konvertera en konversation till ett ärende med ett tydligt transkript och deltagare. Undvik att synka varje meddelande som standard — erbjud en “Attach last 20 messages”-knapp så agenter kan styra brus.
CRM-synk gör “prioriterat stöd” automatiskt. Hämta företag, plan/tier, kontoeier och nyckelkontakter. Mappa CRM-konton till era tenants så nya ärenden kan ärva prioriteringsregler omedelbart.
Tillhandahåll webhooks för event som ticket.escalated, ticket.resolved och sla.breached. Inkludera en stabil payload (ticket ID, tidsstämplar, severity, customer ID) och signera för att mottagare ska kunna verifiera äkthet.
Lägg in ett litet admin-flöde med testknappar (“Send test email”, “Verify webhook”). Håll dokumentationen på ett ställe (t.ex. /docs/integrations) och visa vanliga felsökningstips som SPF/DKIM-problem, saknade trådningshuvuden och CRM-fältmappning.
En app för prioriterat stöd blir “sanningens källa” i stressade situationer. Om SLA-timers drifta, routing misslyckas eller behörigheter läcker data, förloras förtroendet snabbt. Behandla tillförlitlighet som en funktion: testa det som spelar roll, mät vad som händer och planera för fel.
Fokusera automatiska tester på logiken som förändrar utfall:
Lägg till en liten uppsättning end-to-end-tester som imiterar en agentes flöde (skapa ärende → triage → eskalera → lös) för att fånga brutna antaganden mellan UI och backend.
Skapa seed-data som är användbar bortom demos: några kunder, flera tier (standard vs. priority), varierande prioriteringar och ärenden i olika stadier. Inkludera knepiga fall som återöppnade ärenden, “waiting on customer” och flera ansvariga. Detta gör triage-övning meningsfull och hjälper QA reproducera edge-cases snabbt.
Instrumentera appen så du kan svara: “Vad misslyckades, för vem och varför?”
Kör belastningstester på högtrafikerade vyer som köer, sök och dashboards — särskilt kring skiftbyten.
Avslutningsvis, förbered en egen incident-playbook: feature flags för nya regler, databas-migration rollback-steg och en tydlig procedur för att inaktivera automationer samtidigt som agenter hålls produktiva.
En webbapp för prioriterat stöd är först “klar” när agenter litar på den under press. Bästa sättet att nå dit är att lansera litet, mäta vad som verkligen händer och iterera i snabba loopar.
Motstå frestelsen att leverera alla funktioner. Din första release bör täcka kortaste vägen från “ny eskalering” till “lösts med ansvar”:
Om du använder Koder.ai, mappar denna MVP-form väl till dess vanliga standarder (React UI, Go-tjänster, PostgreSQL), och möjligheten att snapshotta och rulla tillbaka kan vara användbar medan du finjusterar SLA-matematiken, routingregler och behörighetsgränser.
Rulla ut till en pilotgrupp (en region, en produktlinje eller en on-call-rotation) och håll en veckovis återkopplingsgranskning. Håll den strukturerad: vad bromsade agenter, vilken data saknades, vilka varningar var störande och var bröts eskaleringshanteringen (överlämningar, otydligt ägarskap eller felroutade ärenden).
En praktisk taktik: behåll en lätt changelog i appen så agenter ser förbättringar och känner sig hörda.
När användningen är konsekvent, introducera rapporter som besvarar operativa frågor:
Dessa rapporter bör vara lätta att exportera och enkla att förklara för icke-tekniska intressenter.
Routing- och triageregler kommer vara felaktiga i början — och det är normalt. Finjustera triageregler baserat på felroutningar, lösningstider och feedback från on-call. Gör samma sak för makron och färdiga svar: ta bort de som inte minskar tid, och förbättra de som ökar tydlighet och kommunikationen under incidenter.
Håll din roadmap kort och synlig i produkten (“Next 30 days”). Länka till hjälpinnehåll och FAQ så utbildning inte blir tribal knowledge. Om du har kundvänd information, håll den lättillgänglig via interna länkar som /pricing eller /blog så team kan självtjäna uppdateringar och bästa praxis.
Skriv kriterierna i klart språk och bygg in dem i UI:t. Typiska eskalerings-triggerar inkluderar:
Dokumentera också vad som inte är en eskalering (hur man-frågor, funktionsönskemål, mindre buggar) och var dessa bör routas i stället.
Definiera roller utifrån vad de kan göra i arbetsflödet och kartlägg ägarskap i varje steg:
Börja med en liten uppsättning så triage förblir konsekvent och du kan leverera snabbare—vanligtvis e-post + webbformulär. Lägg till chat senare när:
Det minskar tidig komplexitet (trådning, transkriptsynk, realtidsbrus) medan du validerar det grundläggande eskaleringsflödet.
Minst bör varje ärende lagra:
För eskaleringar, lägg till strukturerade fält som , , och (t.ex. API, Billing). För SLA:er, spara explicita tidsstämplar (t.ex. , ) så agenter ser exakta deadlines.
Använd en liten, stabil uppsättning statusar (t.ex. New, Triaged, In Progress, Waiting, Resolved, Closed) och definiera vad varje status betyder operativt.
För att göra SLA:er och ansvar spårbara, behåll en append-only-historik för:
En händelsetabell eller revisionslogg låter dig rekonstruera vad som hänt utan att lita på bara nuvarande status.
Håll prioriteringar enkla (t.ex. P1–P4) och knyt SLA:er till kundnivå/plan + prioritet. Spåra åtminstone två timers:
Gör undantag möjliga men kontrollerade: kräva en motivering och spara den i revisionshistoriken så rapportering förblir trovärdig.
Modellera tid explicit:
Definiera vilka statusar som pausar vilka timers (vanligtvis Waiting on customer/third party) och vad som händer vid överträdelse (tagga, notifiera, auto-eskalera, sida on-call). Undvik “tysta” överträdelser—skapa en synlig biljettshändelse.
Bygg en triage-inbox för obundna/behöver-granskning-ärenden med sortering efter priority + SLA due time + kundtier. Håll routing regelbaserad och förklarbar med signaler som:
Spara varför varje routing-beslut gjordes (t.ex. “Matchade nyckelord: SSO → Auth team”) och tillåt behöriga att göra overrides med obligatorisk anteckning och audit-logg.
Optimera för de första 10 sekunderna:
Lägg till bulkåtgärder för backloggstädning, samt tangentbordsgenvägar och tillgänglighetsstöd.
Skydda eskaleringsdata tidigt med praktiska skyddsåtgärder:
För tillförlitlighet: automatisera tester kring regler som förändrar utfall (SLA-beräkningar, routing/ägarskap, behörigheter) och kör bakgrundsjobb för timers och notifieringar med idempotenta retries för att undvika dubbletter.
För varje status, ange vem som äger ärendet, nödvändiga svar-/uppdateringstider och vem som har mandat att eskalera eller göra undantag från routing.