26 nov. 2025·8 min
Hur man bygger en webapp för att spåra operativa flaskhalsar
Steg-för-steg-guide för att planera, designa och leverera en webapp som fångar arbetsflödesdata, upptäcker flaskhalsar och hjälper team att åtgärda förseningar.
Börja med problemet och besluten
En app för processspårning hjälper bara om den svarar på en specifik fråga: "Var fastnar vi, och vad bör vi göra åt det?" Innan du ritar skärmar eller väljer arkitektur, definiera vad "flaskhals" betyder i er verksamhet.
Definiera vad som räknas som en flaskhals
En flaskhals kan vara ett steg (t.ex. "QA-granskning"), ett team (t.ex. "plock & pack"), ett system (t.ex. "betalningsgateway") eller till och med en leverantör (t.ex. "transportörens upphämtning"). Välj de definitioner du faktiskt kommer att hantera. Till exempel:
- Ett steg är en flaskhals när dess genomsnittliga kötid överstiger 24 timmar.
- Ett team är en flaskhals när pågående arbete ligger över en satt gräns i 3 dagar.
- Ett system är en flaskhals när incidenter får cykeltiden att skjuta i höjden utanför ett överenskommet spann.
Lista besluten appen måste möjliggöra
Din operationsdashboard ska driva åtgärd, inte bara rapportering. Skriv ner vilka beslut du vill fatta snabbare och med större säkerhet, till exempel:
- Bemanning: "Flyttar vi en person från Team A till Team B den här veckan?"
- Prioritering: "Vilka order/tickets ska prioriteras för att skydda SLA:er?"
- Automatisering: "Vilket steg är stabilt nog (och dyrt nog) att automatisera först?"
Identifiera primära användare och vad de behöver
Olika användare behöver olika vyer:
- Ops-managers behöver en tydlig "var ingripa idag"-vy.
- Teamledare behöver borrning till individuella köer, blockerare och överlämningar.
- Analytiker behöver konsekventa definitioner och exportmöjligheter för arbetsflödesanalys.
Sätt upp framgångsmått för appen själv
Bestäm hur ni vet att appen fungerar. Bra mått är adoption (veckovisa aktiva användare), sparad tid i rapportering och snabbare åtgärd (kortare tid till upptäckt och tid till lösning av flaskhalsar). Dessa mätvärden håller fokus på resultat, inte funktioner.
Välj arbetsflödet och skriv en enkel processkarta
Innan du designar tabeller, dashboards eller larm, välj ett arbetsflöde du kan beskriva med en mening. Målet är att spåra var arbete väntar—så börja smått och välj en eller två processer som betyder något och ger jämn volym, som orderhantering, supportärenden eller onboarding.
Ett snävt omfång håller "done"-definitionen tydlig och förhindrar att projektet stannar upp för att olika team är oense om hur processen bör fungera.
Börja med 1–2 processer med hög signal
Välj arbetsflöden som:
- Sker ofta (tillräckligt med data för att hitta mönster)
- Innefattar minst en överlämning (där köer bildas)
- Har tydlig kundpåverkan (tid, kostnad, nöjdhet)
Till exempel är "supportärenden" ofta bättre än "customer success" eftersom det finns en uppenbar enhet av arbete och tidsstämplade åtgärder.
Kartlägg steg och överlämningar i enkelt språk
Skriv arbetsflödet som en enkel lista med steg med de ord teamet redan använder. Du dokumenterar inte policy—du identifierar tillstånd som arbetsobjektet rör sig igenom.
En lätt processkarta kan se ut så här:
- Ticket skapad → triagerad → tilldelad → agent arbetar → väntar på kund → löst
Peka ut överlämningar explicit (triage → tilldelad, agent → specialist, osv.). Överlämningar är där kötid ofta döljer sig och är de ögonblick du senare vill mäta.
Definiera start-/sluthändelser och vad som är "klart" för varje steg
För varje steg, skriv två saker:
- Startevent (vad bevisar att steget började?)
- Slutevent (vad bevisar att steget avslutades?)
Håll det observerbart. "Agenten börjar undersöka" är subjektivt; "status ändrad till In Progress" eller "första interna noten tillagd" går att spåra.
Definiera också vad "klart" betyder så appen inte förväxlar delvis färdig med färdig. Till exempel kan "löste" betyda "lösningsmeddelande skickat och ticket markerad som Resolved", inte bara "internt arbete klart".
Notera vanliga undantag att följa upp senare
Verklig drift innehåller röriga vägar: omarbete, eskalationer, saknad information och öppnade ärenden igen. Försök inte modellera allt från dag ett—skriv istället ner undantagen så du kan lägga till dem med avsikt senare.
En enkel notis som "10–15% av tickets eskaleras till Tier 2" räcker. Du använder dessa anteckningar för att avgöra om undantag ska bli egna steg, taggar eller separata flöden när systemet växer.
Definiera mätvärden som faktiskt avslöjar flaskhalsar
En flaskhals är inte en känsla—det är en mätbar fördröjning i ett specifikt steg. Innan du bygger diagram, bestäm vilka siffror som visar var arbete hopar sig och varför.
Välj en liten uppsättning kärnmått
Börja med fyra mått som passar de flesta arbetsflöden:
- Cykeltid: hur lång tid ett objekt tar från start till klart.
- Vänt-/kö-tid: hur länge ett objekt sitter stilla mellan steg.
- Throughput: hur många objekt som slutförs per tidsperiod.
- WIP (pågående arbete): hur många objekt som för närvarande är "i systemet".
Dessa täcker hastighet (cykel), inaktivitet (kö), output (throughput) och belastning (WIP). De flesta "mystiska förseningar" syns som ökande kötid och WIP vid ett särskilt steg.
Definiera beräkningar (inklusive kantfall)
Skriv definitioner som hela teamet kan enas om och implementera exakt så.
- Cycle time =
done_timestamp − start_timestamp.- Kantfall: objekt som öppnas igen (behandla som ny cykel vs. förläng ursprunglig), objekt som aldrig startades (exkludera från cykeltid men räkna i WIP), saknade tidsstämplar (flagga som datakvalitetsproblem).
- Queue time = summan av luckor mellan steg där status är "waiting".
- Kantfall: nätter/helger (kalendertid vs. kontorstimmar), blockerade tillstånd (räkna separat från normal väntetid om du vill klarare orsaker).
- Throughput = antal objekt med
done_timestampinom fönstret.- Kantfall: avbokningar (exkludera eller spåra separat), partiella slutföranden.
- WIP = antal objekt som inte är i ett terminalt tillstånd vid en given tidpunkt.
- Kantfall: pausade objekt (fortfarande WIP, men du kanske vill ha en separat "blocked WIP").
Välj uppdelningar som styr beslut
Välj snitt som dina chefer faktiskt använder: team, kanal, produktlinje, region och prioritet. Målet är att svara på: "Var är det långsamt, för vem och under vilka förhållanden?"
Sätt tidfönster och mål
Bestäm rapporteringsrytm (dagligt och veckovis är vanligt) och definiera mål som SLA/SLO-trösklar (t.ex. "80% av högt prioriterade ärenden färdiga inom 2 dagar"). Mål gör dashboarden handlingsbar istället för dekorativ.
Planera datakällor och insamlingsmetod
Det snabbaste sättet att stanna upp är att anta att data "bara finns där." Innan du designar tabeller eller diagram, skriv ner var varje event och tidsstämpel kommer ifrån—och hur ni håller det konsekvent över tid.
Inventera befintliga källor
De flesta driftteam spårar arbete på några ställen. Vanliga startpunkter inkluderar:
- Kalkylblad som används för överlämningar, dagliga loggar eller produktionsräkningar
- ERP/CRM-system (order, kunder, uppfyllnadssteg)
- Ticketverktyg (supportköer, change requests, underhållsuppgifter)
- Interna databaser (lageravläsningar, schemalagda jobb, data från produktionsstyrning)
För varje källa, notera vad den kan ge: ett stabilt ID, en historik av status (inte bara aktuell status) och minst två tidsstämplar (angiven steg, avslutat steg). Utan det blir övervakning av kötid och spårning av cykeltid gissningslek.
Välj en insamlingsmetod som passar källan
Du har vanligtvis tre alternativ, och många appar använder en mix:
- API-pull: schemalagd synk från ERP/CRM/ticketverktyg. Enkelt att resonera om, men hantera pagination, rate limits och inkrementella uppdateringar.
- Webhooks: push-uppdateringar när arbete ändras. Bra för nära realtidslarm, men designa för retries och händelser som kommer i fel ordning.
- Manuell inmatning / CSV-upload: användbart för team som startar från kalkylblad eller för kantfall. Gör det säkert med mallar, validering och tydliga felmeddelanden.
Planera för datakvalitet (för det kommer att hända)
Räkna med saknade tidsstämplar, dubbletter och inkonsekventa statusar ("In Progress" vs "Working"). Bygg regler tidigt:
- Föredra en oföränderlig händelselogg framför att skriva över poster
- Deduplicera med källa-ID + eventtid + status
- Normalisera statusar till appens kanoniska steg
- Flagga poster som inte kan ge pålitlig cykeltid
Besluta uppdateringsfrekvens
Inte alla processer behöver realtidsuppdateringar. Välj baserat på beslutsbehov:
- Realtid: dispatch, supporttriage, SLA-risk
- Timvis: lagergenomströmning, kötidövervakning
- Daglig: veckorapportering, kontinuerliga förbättringsgenomgångar
Skriv ner detta nu; det styr syncstrategi, kostnader och förväntningar för operationsdashboarden.
Designa en datamodell byggd för tidsanalys
En app för flaskhalsövervakning lever eller dör på hur väl den kan svara på tidsfrågor: "Hur lång tid tog detta?", "Var väntade det?" och "Vad förändrades precis innan det blev långsamt?" Det enklaste sättet att stödja dessa frågor senare är att modellera data kring händelser och tidsstämplar från dag ett.
Börja med kärn-entiteterna
Håll modellen liten och uppenbar:
- Process: det övergripande arbetsflödet (t.ex. "Orderhantering").
- Steg: ett stadium i processen (t.ex. "Plock", "Pack", "Skicka").
- Arbetsobjekt: enheten som rör sig genom steg (ticket, order, krav).
- Händelse: en registrerad tillståndsförändring (gick in i steg, tilldelad, blockerad, slutförd).
- Användare/Team och Tilldelning: vem som ägde arbetet vid en viss tid.
Denna struktur låter dig mäta cykeltid per steg, kötid mellan steg och throughput över hela processen utan specialfall.
Föredra en händelselogg framför "aktuell status"-fält
Behandla varje statusändring som en oföränderlig händelsepost. Istället för att skriva över current_step och förlora historik, append-enhändelser som:
- work_item_id
- from_step → to_step (eller "entered_step")
- event_type (assigned, started, blocked, completed)
- event_time
Du kan fortfarande lagra ett "current state"-snapshot för hastighet, men analysen bör bygga på händelseloggen.
Gör tid och spårbarhet icke-förhandlingsbart
Spara tidsstämplar konsekvent i UTC. Behåll också originala källaidentifikatorer (t.ex. Jira-nyckel, ERP-order-ID) på arbetsobjekt och händelser, så varje diagram kan spåras tillbaka till en verklig post.
Fånga undantag utan att skapa pappersarbete
Planera lätta fält för ögonblick som förklarar förseningar:
- reason_code (standardalternativ som "Waiting on customer")
- comment (valfri text)
- blocked_flag eller severity
Håll dem frivilliga och lätta att fylla i, så ni lär av undantag utan att appen blir ett formulärfyllningsprojekt.
Välj en arkitektur som passar ert team
Behåll full källkontroll
Ta med den genererade källkoden när ni är redo för långsiktigt ägande.
"Bäst" arkitektur är den ert team kan bygga, förstå och driva i åratal. Börja med en stack som matchar er rekryteringsbas och befintliga kunskaper—vanliga, välstödda val är React + Node.js, Django eller Rails. Konsekvens slår nyhet när ni driver en operationsdashboard som folk litar på dagligen.
Separera ansvar så systemet förblir redigerbart
En app för flaskhalsövervakning brukar fungera bättre om den delas i tydliga lager:
- Ingestion: ta emot händelser (statusändringar, tidsstämplar, överlämningar) från formulär, integrationer eller importer.
- Storage: en transaktionell databas för säkra skrivningar och revisionshistorik.
- Analytics queries: läsliggade vyer eller frågor för att beräkna cykeltid, kötid och throughput.
- UI/API: endpoints och skärmar som håller dashboards snabba och förutsägbara.
Denna separation låter er förändra en del (t.ex. lägga till ny datakälla) utan att skriva om allt.
Bestäm var beräkningarna ska leva
Vissa mätvärden räcker att beräkna i databasfrågor (t.ex. "genomsnittlig kötid per steg senaste 7 dagarna"). Andra är dyra eller behöver förbearbetning (t.ex. percentiler, anomalidetektion, veckokohorter). En praktisk regel:
- Gör realtidsfilter och uppdelningar i databasen.
- Använd bakgrundsjobb för att förberäkna tunga aggregat och lagra dem för snabba dashboards.
- Lägg till ett analyslager bara om teamet kan underhålla det tryggt.
Planera för prestanda tidigt
Operationsdashboards faller när de känns långsamma. Indexera tidsstämplar, workflow-step IDs och tenant/team IDs. Lägg till paginering för händelseloggar. Cachera vanliga vyer (som "idag" och "sista 7 dagarna") och ogiltigförklara cache när nya händelser anländer.
Om du vill diskutera tradeoffs djupare, skriv en kort beslutslogg i repo:t så framtida ändringar inte driver iväg.
Ett snabbare spår för team som vill leverera snabbt
Om målet är att validera arbetsflödesanalys och larm innan ni bygger fullt, kan en vibe-coding-plattform som Koder.ai hjälpa er stå upp en första version snabbare: ni beskriver arbetsflödet, entiteter och dashboards i chatten och itererar på den genererade React-UI:n och Go + PostgreSQL-backend när ni förfinar KPI-instrumenteringen.
Den praktiska fördelen är snabb feedback: ni kan pilota ingestion (API-pulls, webhooks eller CSV-import), lägga till borrningsskärmar och justera mätdefinitioner utan veckors ställning. När ni är redo stöder Koder.ai också export av källkod och distribution/hosting, vilket gör det enklare att gå från prototyp till ett underhållet internt verktyg.
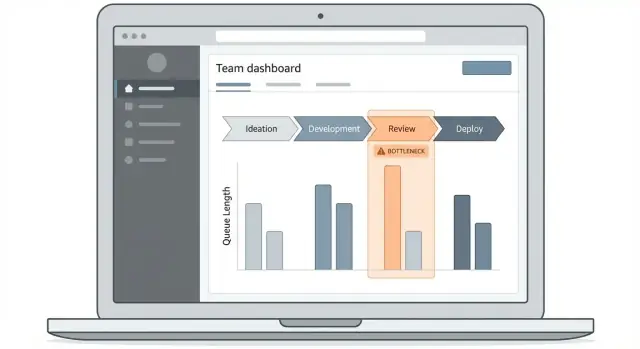
Designa dashboarden och drill-down-upplevelsen
En app för flaskhalsövervakning lyckas eller misslyckas beroende på om folk snabbt kan svara på en fråga: "Var fastnar arbete just nu, och vilka objekt orsakar det?" Dashboarden ska göra den vägen uppenbar, även för någon som bara tittar en gång i veckan.
Börja med 2–3 kärnskärmar
Håll första releasen snäv:
- Översiktsdashboard: "statusboard" för cykeltid, kötid och topp blockerade steg.
- Arbetsobjektslista: en sökbar, filtrerbar tabell över objekt som påverkas av förseningar.
- Detalj för arbetsflöde: steg-för-steg-vy som visar tid i varje stadium och överlämningspunkter.
Dessa skärmar skapar ett naturligt borrningsflöde utan att tvinga användare lära sig ett komplext gränssnitt.
Använd visualiseringar som förklarar tid och flöde
Välj diagramtyper som matchar operativa frågor:
- Stegsfunnel: visar var volym ackumuleras (bra för att hitta köer).
- Tid-i-steg-staplar: jämför steg med median och percentil, inte bara snitt.
- Trendlinjer: svarar på "blir det bättre eller sämre?" över veckor.
- Heatmaps: visar mönster som "måndagar i granskning" eller "skiftöverlämningar på natten".
Håll etiketter enkla: "Väntetid" istället för tekniska termer.
Gör filter konsekventa och lätta att hitta
Använd en gemensam filterrad över skärmar (samma placering, samma standarder): datumintervall, team, prioritet och steg. Visa aktiva filter som chips så folk inte missförstår siffrorna.
Designa tydliga borrningsvägar
Varje KPI-platta ska vara klickbar och leda någonstans användbart:
KPI → steg → påverkad objektslista
Exempel: klick på "Längsta kötid" öppnar stegdetaljen, och ett klick till visar de exakta objekt som väntar där—sorterade efter ålder, prioritet och ägare. Det förvandlar nyfikenhet till en konkret att-göra-lista, vilket gör att dashboarden används istället för ignoreras.
Lägg till larm och tidiga varningssignaler
Planera mätvärden först
Lås fast entiteter, mätvärden och kantfall innan du genererar skärmar och tabeller.
Dashboards är utmärkta för genomgångar, men flaskhalsar gör mest skada mellan möten. Larm förvandlar appen till ett tidigt varningssystem: du hittar problem medan de bildas, inte efter att veckan är förlorad.
Börja med tydliga, tråkiga regler
Starta med ett litet set larmtyper som teamet redan tycker är "dåliga":
- Tröskelbrott: cykeltid eller kötid över en känd gräns (t.ex. "Granskning > 24 timmar").
- Onormala ökningar: dagens mediancykeltid är upp 30% vs förra veckan.
- Fastnat-objekt: ingen statusändring på N timmar/dagar, eller objekt som överstiger maxålder.
Håll första versionen enkel. Ett fåtal deterministiska regler fångar de flesta problem och är lättare att lita på än komplexa modeller.
Lägg till lätta anomalikontroller
När trösklarna är stabila, lägg till grundläggande "är detta konstigt?"-indikatorer:
- Procentuell förändring vs förra veckan (samma veckodag minskar falsklarm).
- Rörligt medelvärdesdrift (t.ex. 7-dagarsmedelvärde som stadigt stiger).
- Volymmissmatchningar (input ökar snabbare än output i ett steg).
Gör anomalier till förslag, inte nödlarm: märk dem som "Heads up" tills användarna bekräftar att de är användbara.
Leverera larm där folk arbetar
Stöd flera kanaler så team kan välja vad som passar:
- E-post för chefer och dagliga sammanfattningar
- Slack/Microsoft Teams för realtids-triage
- In-app-notiser för ägare inne i verktyget
Gör varje larm handlingsbart
Ett larm bör svara på "vad, var och vad nästa":
- Vilket steg är drabbat, och vilket tidsfönster
- Topporsakerna (t.ex. team, kategori, prioritet)
- En direkt väg att undersöka, till exempel:
/dashboard?step=review&range=7d&filter=stuck
Om larm inte leder till en konkret nästa åtgärd kommer folk stänga av dem—behandla larmkvalitet som en produktfunktion, inte en eftertanke.
Hantera behörigheter, säkerhet och granskningsspår
En app för flaskhalsövervakning blir snabbt en "sanningens källa." Det är bra—tills fel person redigerar en definition, exporterar känsliga data eller delar en dashboard utanför sitt team. Behörigheter och audit logs är inte byråkrati; de skyddar förtroendet för siffrorna.
Definiera roller och åtkomstregler
Börja med en liten, tydlig rollmodell och växla bara vid behov:
- Viewer: read-only åtkomst till dashboards och rapporter.
- Manager: kan filtrera per team, skapa sparade vyer, bekräfta larm och lägga till anteckningar (men kan inte ändra globala inställningar).
- Admin: hanterar processdefinitioner, KPI-formler, integrationer och användaråtkomst.
Var explicit om vad varje roll kan göra: se råa händelser vs aggregerade mått, exportera data, ändra trösklar och hantera integrationer.
Separera data per team eller affärsenhet
Om flera team använder appen, upprätthåll separation i datalagret—inte bara i UI. Vanliga alternativ:
- Multi-tenant: varje post har en
tenant_id, och varje fråga scoping till den. - Partitioner/projekt: separata "workspaces" per affärsenhet, med egna inställningar och dashboards.
Bestäm tidigt om chefer kan se andra teamers data. Gör tvärteam-synlighet till en uttrycklig rättighet, inte standard.
Säkra autentisering (SSO eller MFA-ready)
Om organisationen har SSO (SAML/OIDC), använd det så offboarding och åtkomstkontroll centraliseras. Annars implementera inloggning som är MFA-klar (TOTP eller passkeys), stöd för säker lösenordsåterställning och sessionstidsgränser.
Gör ändringar granskbara
Logga åtgärder som kan ändra utfall eller exponera data: exporter, tröskeländringar, arbetsflödesändringar, behörighetsuppdateringar och integrationsinställningar. Fånga vem som gjorde det, när, vad som ändrades (före/efter) och var (workspace/tenant). Ge en "Audit Log"-vy så problem kan undersökas snabbt.
Förvandla insikter till åtgärder och processförbättringar
En dashboard för flaskhalsar betyder bara något om den ändrar vad folk gör härnäst. Målet är att göra "intressanta diagram" till en återupprepbar driftcykel: besluta, agera, mät och behåll vad som fungerar.
Skapa en lättviktig bottleneck-review
Sätt en enkel veckorytm (30–45 minuter) med tydliga ägare. Börja med topp 1–3 flaskhalsar efter påverkan (t.ex. högst kötid eller största throughput-fall), och kom överens om en åtgärd per flaskhals.
Håll arbetsflödet litet:
- Ägare: en ansvarig person per åtgärd
- Deadline: nästa genomgång som standard
- Definition of done: en mätbar förändring (inte "utreda mer")
Spara besluten direkt i appen så dashboard och åtgärdslogg hänger ihop.
Spåra förbättringar som experiment
Behandla ändringar som experiment så ni lär er snabbt och undviker "slumpmässiga optimeringar." För varje förändring, skriv ner:
- Hypotes (vad som bromsar och varför)
- Förändring (vad ni gör)
- Förväntad påverkan (vilket mått ska röra sig, och med hur mycket)
- Resultat (vad som faktiskt hände)
Med tiden blir detta en playbook för vad som minskar cykeltid, minskar omarbete och vad som inte hjälper.
Lägg till kontext med annotationer
Diagram kan vilseleda utan kontext. Lägg enkla annotationer på tidslinjer (t.ex. nyanställd onboardad, systemavbrott, policyuppdatering) så tittare kan tolka skiften i kötid eller throughput rätt.
Gör delning enkel
Ge exportalternativ för analys och rapportering—CSV-nedladdningar och schemalagda rapporter—så team kan inkludera resultat i ops-uppdateringar och ledningsgenomgångar. Om ni redan har en rapporteringssida, länka till den från dashboarden (t.ex. /reports).
Driftsätt, övervaka och håll data färsk
Ställ in tidiga varningar
Skapa enkla tröskelregler så att flaskhalsar märks mellan veckogenomgångarna.
En app för flaskhalsövervakning är bara användbar om den är tillgänglig och siffrorna är pålitliga. Behandla driftsättning och datafärskhet som produktkrav, inte eftertanke.
Använd separata miljöer och repeterbara deploys
Sätt upp dev / staging / prod tidigt. Staging bör spegla produktion (samma databasmotor, liknande datavolym, samma bakgrundsjobb) så ni kan fånga långsamma queries och trasiga migrationer innan användare drabbas.
Automatisera deploys med en pipeline: kör tester, applicera migrationer, deploya, kör en snabb smoke-check (logga in, ladda dashboard, verifiera ingestion). Håll deploys små och frekventa; det minskar risk och gör rollback realistiskt.
Övervaka appen och pipeline:n
Du vill övervaka på två fronter:
- Apphälsa: felprocent, latens, långsamma endpoints och tunga queries.
- Datahälsa: ingestion-fel, backlogstorlek och "tid sedan senaste händelse mottagen."
Larma på symptom användare känner (dashboards timear ut) och tidiga signaler (en kö som växer i 30 minuter). Spåra också misslyckanden i metric-beräkningar—saknade cykeltider kan se ut som "förbättring".
Håll data färsk: sena händelser, korrigeringar och backfills
Operativ data kommer sent, i fel ordning eller korrigeras. Planera för:
- Idempotent ingestion (reprocessa samma händelse dubblar inte)
- Backfills för datumintervall när en källa var nere
- Rekalkyler när referensdata ändras (t.ex. uppdaterade skiftskalendrar)
Definiera vad "färskt" betyder (t.ex. 95% av händelser inom 5 minuter) och visa färskhet i UI:n.
Skriv runbooks så fixar inte blir gissningar
Dokumentera steg-för-steg-runbooks: hur man startar om en trasig sync, validerar gårdagens KPI:er och bekräftar att en backfill inte flyttade historiska siffror oväntat. Lagra dem med projektet och länka från /docs så teamet kan agera snabbt.
Iterera med användare och utöka täckningen
En app för flaskhalsövervakning lyckas när folk litar på den och verkligen använder den. Det händer först efter att du sett riktiga användare försöka svara riktiga frågor ("Varför är godkännanden långsamma den här veckan?") och sedan slipat produkten runt de behoven.
Börja med en pilot och lär av vad som går sönder
Starta med ett pilotteam och ett litet antal arbetsflöden. Håll omfånget tillräckligt smalt för att observera användning och snabbt svara.
Under de första veckorna, fokusera på vad som förvirrar eller saknas:
- Vilka diagram missförstår användarna?
- Var fastnar de när de borrar ner?
- Vilken data förväntar de sig men hittar inte?
- Vilka flaskhalsar känns "uppenbara" för dem men syns inte i appen?
Samla feedback i verktyget (en enkel "Var detta användbart?"-prompt på nyckelskärmar funkar bra) så ni inte förlitar er på mötesminnen.
Validera mätvärden för att undvika "dashboard-argument"
Innan ni rullar ut till fler team, lås definitioner tillsammans med de som kommer bli ansvariga. Många utrullningar misslyckas för att team är oense om vad ett mått betyder.
För varje KPI (cykeltid, kötid, omarbetsgrad, SLA-brott), dokumentera:
- Exakta start- och sluthändelser
- Hantering av pauser, helger och saknade tidsstämplar
- Hur undantag räknas (avbokningar, eskalationer, återöppningar)
Gå igenom definitionerna med användare och lägg in korta tooltips i UI:n. Om ni ändrar en definition, visa en tydlig changelog så folk förstår varför siffror rörde sig.
Utöka täckningen utan att göra appen rörig
Lägg till funktioner varsamt och bara när pilotteamets analys är stabil. Vanliga nästa steg är anpassade steg (olika team namnger stadier olika), fler källor (tickets + CRM + kalkylblad) och avancerad segmentering (produktlinje, region, prioritet, kundnivå).
En bra regel: lägg till en ny dimension i taget och verifiera att den förbättrar beslut, inte bara rapportering.
Gör onboarding enkel och repeterbar
När ni rullar ut till fler team behöver ni konsistens. Skapa en kort onboarding-guide: hur koppla data, hur tolka operationsdashboarden och hur agera på larm för flaskhalsar.
Länka användare till relevanta sidor i produkten och innehåll, som /pricing och /blog, så nya användare kan hitta svar själva istället för att vänta på utbildning.