13 maj 2025·8 min
Bygg en webbapp för att spåra produktadoption per kontonivå
Lär dig hur du utformar data, händelser och dashboards för att mäta produktadoption över kontonivåer — och agera på insikter med aviseringar och automatisering.
Lär dig hur du utformar data, händelser och dashboards för att mäta produktadoption över kontonivåer — och agera på insikter med aviseringar och automatisering.
Innan du bygger dashboards eller instrumenterar händelser, var tydlig med vad appen ska göra, vem den tjänar och hur kontonivåer definieras. De flesta projekt för “adoption‑spårning” misslyckas för att de börjar i data och slutar i oenighet.
En praktisk regel: om två team inte kan definiera “adoption” i samma mening kommer de inte att lita på dashboarden senare.
Nämn de primära målgrupperna och vad varje grupp behöver göra härnäst efter att ha sett datan:
Ett användbart lakmustest: varje målgrupp ska kunna svara “så vad?” på under en minut.
Adoption är inte en enda metrisk. Skriv en definition som ditt team kan enas om — vanligen som en sekvens:
Håll det förankrat i kundvärde: vilka handlingar signalerar att de får resultat, inte bara utforskar.
Lista era tiers och gör tilldelningen deterministisk. Vanliga tiers inkluderar SMB / Mid‑Market / Enterprise, Free / Trial / Paid, eller Bronze / Silver / Gold.
Dokumentera reglerna i klartext (och senare i kod):
Skriv ner de beslut appen måste möjliggöra. Till exempel:
Använd dessa som acceptanskriterier:
Kontonivåer beter sig olika, så ett enda “adoption”‑mått kommer antingen att straffa små kunder eller dölja risk i större. Börja med att definiera vad framgång är per tier, och välj sedan mått som speglar den verkligheten.
Välj ett primärt utfall som representerar verkligt levererat värde:
Din nordstjärna ska vara räkningsbar, segmenterad per tier och svår att manipulera.
Skriv adoptionstratten som steg med explicita regler — så att ett dashboard‑svar inte beror på tolkning.
Exempelsteg:
Tier‑skillnader spelar roll: Enterprise‑“Aktiverad” kan kräva en admin‑åtgärd och minst en slutanvändaråtgärd.
Använd ledande indikatorer för att upptäcka tidig momentum:
Använd eftersläpande indikatorer för att bekräfta varaktig adoption:
Målen bör spegla förväntad time‑to‑value och organisatorisk komplexitet. Till exempel kan SMB sikta på aktivering inom 7 dagar; Enterprise kan sikta på integration inom 30–60 dagar.
Skriv ner målen så att aviseringar och scorecards förblir konsekventa mellan team.
En tydlig datamodell förhindrar “mystery math” senare. Du vill kunna svara enkla frågor — vem använde vad, i vilket konto, under vilken tier, vid den tidpunkten — utan att lägga ad‑hoc‑logik i varje dashboard.
Börja med en liten uppsättning entiteter som mappar till hur kunder faktiskt köper och använder din produkt:
account_id), namn, status och lifecycle‑fält (created_at, churned_at).user_id, e‑postdomän (hjälpsamt för matchning), created_at, last_seen_at.workspace_id och en foreign key till account_id.Var explicit om analysens “grain”:
Ett praktiskt default är att spåra händelser på user‑nivå (med account_id bifogat), och sedan aggregera till account‑nivå. Undvik account‑endast‑händelser om inte ingen användare finns (t.ex. systemimporter).
Händelser berättar vad som hände; snapshots berättar vad som var sant.
Skriv inte över “nuvarande tier” och förlora kontext. Skapa en account_tier_history‑tabell:
account_id, tier_idvalid_from, valid_to (nullable för aktuell)source (billing, sales override)Detta låter dig räkna adoption medan kontot var Team, även om det senare uppgraderade.
Skriv definitionerna en gång och behandla dem som produktkrav: vad räknas som en “aktiv användare”, hur attribuerar du händelser till konton, och hur hanterar du tier‑ändringar mitt i månaden. Detta förhindrar två dashboards från att visa två olika sanningar.
Din adoption‑analys är bara så bra som de händelser du samlar in. Börja med att mappa en liten uppsättning “kritiska väg”‑åtgärder som indikerar verklig progress för varje kontotier, och instrumentera dem konsekvent över web, mobile och backend.
Fokusera på händelser som representerar meningsfulla steg — inte varje klick. En praktisk startuppsättning:
signup_completed (konto skapat)user_invited och invite_accepted (teamtillväxt)first_value_received (ditt “aha”‑ögonblick; definiera det uttryckligen)key_feature_used (upprepbar värdehändelse; kan vara flera händelser per funktion)integration_connected (om integrationer driver stickiness)Varje händelse bör bära tillräckligt med kontext för att kunna skivas per tier och roll:
account_id (obligatoriskt)user_id (obligatoriskt när en person är involverad)tier (fånga vid händelsetid)plan (billing‑plan/SKU om relevant)role (t.ex. owner/admin/member)workspace_id, feature_name, source (web/mobile/api), timestampAnvänd ett förutsägbart schema så att dashboards inte blir ett lexikonprojekt:
report_exported, dashboard_shared)account_id, inte acctId)invoice_sent) eller en enda händelse med feature_name; välj ett tillvägagångssätt och håll fast vid det.Stöd både anonym och autentiserad aktivitet:
anonymous_id vid första besöket, länka sedan till user_id vid inloggning.workspace_id och mappa det till account_id server‑side för att undvika klientbuggar.Instrumentera systemåtgärder i backend så att nyckelmått inte beror på webbläsare eller adblockers. Exempel: subscription_started, payment_failed, seat_limit_reached, audit_log_exported.
Dessa server‑side‑händelser är också idealiska triggers för aviseringar och arbetsflöden.
Här blir spårningen ett system: händelser kommer från din app, städas, lagras säkert och omvandlas till mått som teamet faktiskt kan använda.
De flesta team använder en mix:
Oavsett val, behandla ingestion som ett kontrakt: om en händelse inte kan tolkas ska den karantänföras — inte tyst accepteras.
Vid ingest tid standardisera de få fälten som gör downstream‑rapportering pålitlig:
account_id, user_id, och (om behövs) workspace_id.event_name, tier, plan, feature_key) och lägg bara till defaults när de är explicita.Bestäm var råa händelser ligger baserat på kostnad och query‑mönster:
Bygg dagliga/timvisa aggregeringsjobb som producerar tabeller som:
Gör rollups deterministiska så att du kan köra om dem vid tier‑definitioner eller backfills.
Sätt tydlig retention för:
En adoptionspoäng ger upptagna team en enda siffra att följa, men den fungerar bara om den är enkel och förklarbar. Sikta på en 0–100‑poäng som reflekterar meningsfulla beteenden (inte vanity‑aktivitet) och som kan brytas ned i ”varför det rörde sig”.
Börja med en viktad checklista av beteenden, begränsad till 100 poäng. Håll vikterna stabila under en kvart så att trender förblir jämförbara.
Exempelviktning (justera efter din produkt):
Varje beteende ska mappas till en klar händelseregel (t.ex. “använde kärnfunktion” = core_action på 3 separata dagar). När poängen ändras, lagra bidragande faktorer så att du kan visa: “+15 för att ni bjöd in 2 användare” eller “-10 eftersom kärnanvändning gick under 3 dagar.”
Beräkna poängen per konto (dagligen eller veckovis snapshot), och aggregera sedan per tier med distributioner, inte bara medelvärden:
Följ veckovisa förändringar och 30‑dagars förändringar per tier, men undvik att blanda tier‑storlekar:
Det gör små tiers läsbara utan att stora tiers dominerar berättelsen.
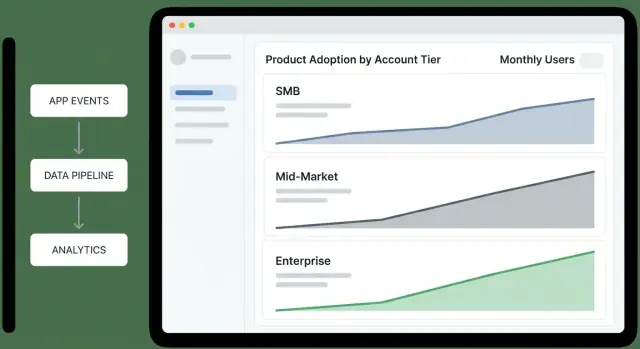
En tier‑översiktsdashboard ska låta en chef svara en fråga på under en minut: “Vilka tiers förbättras, vilka försämras och varför?” Behandla den som en decisions‑skärm, inte en rapporteringssamlingssida.
Tier‑tratt (Awareness → Activation → Habit): “Var fastnar konton per tier?” Håll stegen konsekventa med er produkt (t.ex. “Invited users” → “Completed first key action” → “Weekly active”).
Aktiveringsgrad per tier: “Nått nya eller reaktiverade konton första värdet?” Para en rate med nämnaren (konton som är berättigade) så ledningen kan skilja signal från små stickprovs‑brus.
Retention per tier (t.ex. 7/28/90‑dagar): “Fortsätter konton använda efter första vinsten?” Visa en enkel linje per tier; undvik översegmentering i översikten.
Användningsdjup (funktionsbredd): “Adopterar de flera produktområden eller håller sig ytligt?” En stapel per tier fungerar bra: % som använder 1 område, 2–3 områden, 4+ områden.
Lägg till två jämförelser överallt:
Använd konsekventa deltas (absolut procentenheter) så chefer snabbt kan skanna.
Håll filter begränsade, globala och sticky:
Om ett filter ändrar metric‑definitioner, erbjud det inte här — skjut det till drill‑down‑vyer.
Inkludera en liten panel för varje tier: “Vad är mest associerat med högre adoption den här perioden?” Exempel:
Håll det förklarbart: föredra “Konton som satte upp X inom de första 3 dagarna behåller 18pp bättre” framför opaka modellutgångar.
Placera Tier‑KPI‑kort överst (aktivering, retention, bredd), en skroll av trenddiagram i mitten, och drivrutiner + nästa åtgärder längst ned. Varje widget ska svara en fråga — annars hör den inte hemma i ledningssammanfattningen.
En tier‑dashboard är användbar för prioritering, men det verkliga arbetet sker när du kan klicka vidare för att förstå varför en tier rörde sig och vem som behöver uppmärksamhet. Designa drill‑down‑vyer som en vägledd stig: tier → segment → konto → användare.
Börja med en tier‑översiktstabell, och låt användare skiva den i meningsfulla segment utan att bygga anpassade rapporter. Vanliga segmentfilter:
Varje segment‑sida ska svara: “Vilka konton driver upp eller ned detta tiers adoptionspoäng?” Inkludera en rankad lista med konton och poängförändring över tid samt toppbidragande funktioner.
Kontoprofilen ska kännas som en case‑fil:
Håll det skannbart: visa deltas (“+12 denna vecka”) och annotera toppar med den funktion/händelse som orsakade dem.
Från kontosidan, lista användare efter senaste aktivitet och roll. Klicka på en användare visar deras funktionsanvändning och sista‑inloggning‑kontext.
Lägg till kohortvyer för att förklara mönster: signup‑månad, onboarding‑program och tier vid signup. Detta hjälper CS att jämföra like‑with‑like i stället för att blanda nyregistrerade med mogna konton.
Inkludera en “Vem använder vad”‑vy per tier: adoptionsgrad, frekvens och trendande funktioner, med en klickbar lista över konton som använder (eller inte använder) varje funktion.
För CS och Sales, lägg till export/dela‑alternativ: CSV‑export, sparade vyer och delbara interna länkar (t.ex. /accounts/{id}) som öppnas med filter applicerade.
Dashboards är bra för förståelse, men team agerar när de blir påminda vid rätt tillfälle. Aviseringar ska kopplas till kontonivå så att CS och Sales inte översvämmas av låg‑värdes‑notiser — eller värre, missar kritiska problem i era högst värderade konton.
Börja med en liten uppsättning “något är fel”‑signaler:
Gör dessa signaler tier‑medvetna. Till exempel kan Enterprise larma vid 15% vecka‑till‑vecka‑minskning i ett kärnworkflow, medan SMB kanske kräver 40% för att undvika brus från sporadisk användning.
Expansion‑aviseringar ska lyfta konton som växer in i mer värde:
Återigen skiljer sig trösklar per tier: en ensam power‑user kan vara viktig för SMB, medan Enterprise‑expansion kräver multiteam‑adoption.
Routa aviseringar till där arbetet sker:
Håll payloaden handlingsbar: konto‑namn, tier, vad som ändrats, jämförelsefönster och en länk till drill‑down‑vyn (t.ex. /accounts/{account_id}).
Varje avisering behöver en ägare och en kort playbook: vem svarar, de första 2–3 kontrollerna (datans färskhet, senaste releaser, admin‑ändringar) och rekommenderad outreach eller in‑app‑vägledning.
Dokumentera playbooks vid sidan av metric‑definitioner så att svar förblir konsekventa och aviseringar förblir trovärdiga.
Om adoptions‑mått driver tier‑specifika beslut (CS‑outreach, prisdiskussioner, roadmap‑satsningar) behöver datan som matar dem skyddsnät. Ett litet set kontroller och styrningsrutiner förhindrar “mystery drops” i dashboards och håller intressenter samstämda om vad siffrorna betyder.
Validera händelser så tidigt som möjligt (client SDK, API‑gateway eller ingest‑worker). Avvisa eller karantänför händelser som inte kan betraktas som pålitliga.
Inför kontroller som:
account_id eller user_id (eller värden som inte finns i accounts‑tabellen)Behåll en karantän‑tabell så att du kan inspektera felaktiga händelser utan att förorena analysen.
Adoptionsspårning är tidssensitiv; sena händelser förvränger veckovisa aktiva och tier‑rollups. Övervaka:
Routa monitorer till ett on‑call‑kanal, inte till alla.
Retries händer (mobila nät, webhook‑redelivery, batch‑replays). Gör ingest idempotent med en idempotency_key eller ett stabilt event_id, och dedupla inom ett tidsfönster.
Dina aggregeringar bör vara säkra att köra om utan dubbelräkning.
Skapa ett glossarium som definierar varje metrisk (inputs, filter, tidsfönster, tier‑attributionsregler) och behandla det som enda sanning. Länka dashboards och docs till det glossariet (t.ex. /docs/metrics).
Lägg till audit‑loggar för ändringar i metric‑definitioner och adoptionspoängsregler — vem ändrade vad, när och varför — så att trender snabbt kan förklaras.
Adoptionsanalys är bara användbar om folk litar på den. Det säkraste är att designa din tracking‑app för att svara adoptionsfrågor samtidigt som du samlar in så lite känslig data som möjligt, och göra “vem ser vad” till en första klass‑funktion.
Börja med identifierare som är tillräckliga för adoptionsinsikter: account_id, user_id (eller ett pseudonymt id), tidsstämplar, funktion och en liten uppsättning beteendeegenskaper (plan, tier, plattform). Undvik att fånga namn, e‑postadresser, fri‑textfält eller något som kan innehålla hemligheter.
Om du behöver användarnivåanalys, lagra användaridentifierare separat från PII och join:a bara när det är nödvändigt. Behandla IP‑adresser och enhetsidentifierare som känsliga; om du inte behöver dem för poängsättning, spara dem inte.
Definiera tydliga åtkomstroller:
Defaulta till aggregerade vyer. Gör användarnivå‑drilldown till en explicit behörighet, och dölj känsliga fält (e‑post, fullständiga namn, externa id:n) om inte en roll verkligen behöver dem.
Stöd raderingsförfrågningar genom att kunna ta bort en användares händelsehistorik (eller anonymisera den) och att radera kontodata vid kontraktsslut.
Inför retention‑regler (t.ex. behåll råa händelser i N dagar, aggregat längre) och dokumentera dem i er policy. Spåra samtycke och databehandlingsansvar där det är tillämpligt.
Det snabbaste sättet att leverera värde är att välja en arkitektur som matchar var er data redan finns. Ni kan alltid utveckla den senare — det viktiga är att snabbt få pålitliga tier‑insikter i människors händer.
Warehouse‑first analytics: händelser flödar in i ett warehouse (t.ex. BigQuery/Snowflake/Postgres), sedan beräknar ni adoptionsmått och serverar dem till en lätt webbapp. Detta är idealiskt om ni redan förlitar er på SQL, har analytiker eller vill ha en gemensam sanningskälla.
App‑first analytics: er webbapp skriver händelser till sin egen databas och beräknar mått i applikationen. Snabbare för ett litet produktteam, men lätt att växa ur när volymer och behov av historisk reprocessing ökar.
Ett praktiskt default för de flesta SaaS‑team är warehouse‑first med en liten operationell databas för konfiguration (tiers, metric‑definitioner, avisningsregler).
Skicka en första version med:
3–5 mått (t.ex. aktiva konton, nyckelfunktionsanvändning, adoptionspoäng, veckovis retention, time‑to‑first‑value).
En tier‑översiktssida: adoptionspoäng per tier + trend över tid.
En kontovy: nuvarande tier, senaste aktivitet, toppfunktioner som används och en enkel “varför poängen är som den är.”
Lägg tidiga feedback‑loopar: låt Sales/CS flagga “det här ser fel ut” direkt från dashboarden. Versionshantera metric‑definitioner så att du kan ändra formler utan att tyst omskriva historiken.
Rulla ut gradvis (ett team → hela orgen) och behåll en changelog för metric‑uppdateringar i appen (t.ex. /docs/metrics) så intressenter alltid vet vad de tittar på.
Om ni vill gå från “spec” till en fungerande intern app snabbt kan en vibe‑coding‑approach hjälpa — särskilt för MVP‑fasen där ni validerar definitioner, inte perfekta infrastrukturer.
Med Koder.ai kan team prototypa en adoption‑analys‑webbapp via ett chattgränssnitt samtidigt som ni genererar verklig, redigerbar kod. Det passar bra eftersom omfattningen är tvärfunktionell (React‑UI, ett API‑lager, en Postgres‑datamodell och schemalagda rollups) och ofta förändras snabbt medan intressenter konvergerar kring definitioner.
Ett vanligt arbetsflöde:
Eftersom Koder.ai stöder deployment/hosting, custom domains och kodexport kan det vara ett praktiskt sätt att nå ett trovärdigt internt MVP samtidigt som långsiktiga arkitekturval hålls öppna.
Börja med en gemensam definition av adoption som en sekvens:
Gör den sedan tier‑medveten (t.ex. SMB aktivering inom 7 dagar vs. Enterprise som kräver admin + slutanvändar‑åtgärder).
Eftersom tiers beter sig olika kan ett enda mått:
Segmentering efter tier låter dig sätta realistiska mål, välja rätt nordstjärna per tier och trigga rätt aviseringar för högvärdiga konton.
Använd ett deterministiskt, dokumenterat regelverk:
valid_from / valid_to.Välj ett primärt resultat per tier som speglar verkligt värde:
Gör det räkningsbart, svårt att manipulera och tydligt kopplat till kundvärde — inte bara klick.
Definiera explicita steg och kvalifikationsregler så att tolkningen inte driver iväg. Exempel:
Spåra en liten uppsättning kritiska väg‑händelser:
signup_completeduser_invited, invite_acceptedfirst_value_received (definiera ditt “aha” noggrant)Inkludera egenskaper som gör slicing och attribution pålitlig:
Använd båda:
Snapshots lagrar vanligtvis aktiva användare, nyckelfunktionsräkningar, komponenter till adoptionspoäng och tieren för den dagen — så tier‑ändringar skriver inte över historisk rapportering.
Gör den enkel, förklarbar och stabil:
core_action på 3 separata dagar inom 14 dagar).Rulla upp per tier med distributioner (median, percentiler, % över tröskel) — inte bara medelvärden.
Gör aviseringarna tier‑specifika och handlingsbara:
Routa notifieringar dit arbetet sker (Slack/e‑post för brådskande, veckosammanställning för låg prioritet) och inkludera det väsentliga: vad som ändrats, jämförelseperiod och en drill‑down‑länk som /accounts/{account_id}.
Detta förhindrar att dashboards ändrar mening när konton uppgraderar eller nedgraderar.
Anpassa krav per tier (Enterprise‑aktivering kan kräva både admin‑ och slutanvändaråtgärder).
key_feature_used (eller per‑funktion‑händelser)integration_connectedPrioritera händelser som representerar progression mot utfall, inte varje UI‑klick.
account_id (obligatoriskt)user_id (obligatoriskt när en person är involverad)tier (fångat vid händelsetillfället)plan / SKU (om relevant)role (owner/admin/member)workspace_id, feature_name, source, timestampHåll namngivningen konsekvent (snake_case) så att queries inte blir ett översättningsprojekt.