09 dec. 2025·8 min
SQL vs NoSQL‑databaser: nyckelskillnader och användningsfall
Lär dig de verkliga skillnaderna mellan SQL och NoSQL: datamodeller, skalbarhet, konsistens och när varje typ passar bäst för dina applikationer.
Lär dig de verkliga skillnaderna mellan SQL och NoSQL: datamodeller, skalbarhet, konsistens och när varje typ passar bäst för dina applikationer.
Valet mellan SQL och NoSQL påverkar hur du designar, bygger och skalar din applikation. Databasmodellen påverkar allt från datastrukturer och frågemönster till prestanda, tillförlitlighet och hur snabbt teamet kan utveckla produkten.
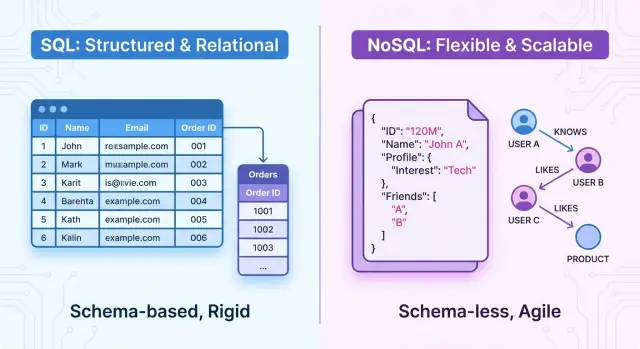
På en hög nivå är SQL‑databaser relationella system. Data organiseras i tabeller med fasta scheman, rader och kolumner. Relationer mellan entiteter är explicita (genom foreign keys), och du frågar data med SQL, ett kraftfullt deklarativt språk. Dessa system betonar ACID‑transaktioner, stark konsistens och väldefinierad struktur.
NoSQL‑databaser är icke‑relationella system. Istället för en enda rigid tabellmodell erbjuder de flera datamodeller anpassade för olika behov, till exempel:
Det innebär att ”NoSQL” inte är en enda teknologi utan ett paraplybegrepp för flera tillvägagångssätt, var och en med sina egna avvägningar i flexibilitet, prestanda och datamodellering. Många NoSQL‑system släpper vissa konsistensgarantier för att få högre skalbarhet, tillgänglighet eller lägre latens.
Denna artikel fokuserar på skillnaderna mellan SQL och NoSQL—datamodeller, frågespråk, prestanda, skalbarhet och konsistens (ACID vs eventual consistency). Målet är att hjälpa dig välja mellan SQL och NoSQL för specifika projekt och förstå när varje typ passar bäst.
Du behöver inte välja bara en. Många moderna arkitekturer använder polyglot persistence, där SQL och NoSQL samexisterar i ett system, och var och en hanterar de arbetsbelastningar de är bäst på.
En SQL (relationell) databas lagrar data i en strukturerad, tabellbaserad form och använder Structured Query Language (SQL) för att definiera, fråga och manipulera den datan. Den bygger på den matematiska idén om relationer, vilket du kan tänka på som välorganiserade tabeller.
Data organiseras i tabeller. Varje tabell representerar en typ av entitet, exempelvis customers, orders eller products.
email eller order_date.Varje tabell följer ett fastsatt schema: en fördefinierad struktur som anger
INTEGER, VARCHAR, DATE)NOT NULL, UNIQUE)Schemat upprätthålls av databasen, vilket hjälper till att hålla data konsekvent och förutsägbar.
Relationella databaser är mycket bra på att modellera hur entiteter förhåller sig till varandra.
customer_id).Dessa nycklar låter dig definiera relationer som:
Relationella databaser stöder transaktioner—grupper av operationer som beter sig som en enhet. Transaktioner definieras av ACID‑egenskaperna:
Dessa garantier är avgörande för finansiella system, lagerhantering och alla applikationer där korrekthet är viktig.
Populära relationssystem inkluderar:
Alla implementerar SQL och lägger till egna extensioner och verktyg för administration, prestandaoptimering och säkerhet.
NoSQL‑databaser är icke‑relationella datalager som inte använder det traditionella tabell–rad–kolumn‑mönstret från SQL‑system. Istället fokuserar de på flexibla datamodeller, horisontell skalbarhet och hög tillgänglighet, ofta på bekostnad av strikta transaktionsegenskaper.
Många NoSQL‑databaser beskrivs som schema‑lösa eller schema‑flexibla. Istället för att definiera ett stelt schema i förväg kan du lagra poster med olika fält eller strukturer i samma collection eller bucket.
Detta är särskilt användbart för:
Eftersom fält kan läggas till eller utelämnas per post kan utvecklare iterera snabbt utan att köra migrationer för varje strukturell ändring.
NoSQL är ett paraplybegrepp som täcker flera olika modeller:
Många NoSQL‑system prioriterar tillgänglighet och partitionstolerans och erbjuder eventual consistency istället för strikta ACID‑transaktioner över hela datasetet. Vissa erbjuder justerbara konsistensnivåer eller begränsade transaktionsegenskaper (per dokument, partition eller nyckelintervall), så du kan välja starkare garantier för specifika operationer om det behövs.
Datamodellering är där SQL och NoSQL känns mest olika. Den formar hur du designar funktioner, frågar data och vidareutvecklar applikationen.
SQL‑databaser använder strukturerade, fördefinierade scheman. Du designar tabeller och kolumner i förväg, med strikta typer och constraints:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Varje rad måste följa schemat. Att ändra det senare innebär ofta migrationer (ALTER TABLE, backfilling, osv.).
NoSQL‑databaser stödjer vanligtvis flexibla scheman. En dokumentbutik kan tillåta att varje dokument har olika fält:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Fält kan läggas till per dokument utan en central schema‑migration. Vissa NoSQL‑system erbjuder ändå valfria eller tvingande scheman, men generellt är de lösare.
Relationsmodeller uppmuntrar normalisering: dela upp data i relaterade tabeller för att undvika duplicering och behålla integritet. Detta ger ofta snabba, konsekventa skrivningar och mindre lagring, men komplexa reads kan kräva JOINs över många tabeller.
NoSQL‑modeller föredrar ofta denormalisering: bädda in relaterad data tillsammans för de reads du bryr dig mest om. Detta förbättrar read‑prestanda och förenklar frågor, men skrivningar kan bli långsammare eller mer komplexa eftersom samma information kan finnas på flera ställen.
I SQL är relationer explicita och upprätthållna:
I NoSQL modelleras relationer genom:
Valet styrs av accessmönster:
Med SQL kräver schemaändringar mer planering men ger starka garantier och konsekvens över datasetet. Refaktorer är explicita: migrationer, backfills, constraint‑uppdateringar.
Med NoSQL är det vanligtvis enklare att stödja föränderliga krav på kort sikt. Du kan börja lagra nya fält direkt och gradvis uppdatera gamla dokument. Trade‑offen är att applikationskoden måste hantera flera dokumentformat och edge‑fall.
Att välja mellan normaliserade SQL‑modeller och denormaliserade NoSQL‑modeller handlar mindre om "bättre eller sämre" och mer om att anpassa datastrukturen till dina frågemönster, skrivvolym och hur ofta din domänmodell förändras.
SQL‑databaser frågas med ett deklarativt språk: du beskriver vad du vill ha, inte hur det ska hämtas. Kärnbyggstenar som SELECT, WHERE, JOIN, GROUP BY och ORDER BY låter dig uttrycka komplexa frågor över flera tabeller i ett enda uttalande.
Eftersom SQL är standardiserat (ANSI/ISO) delar de flesta relationssystem ett gemensamt kärnspråk. Leverantörer lägger till egna extensioner, men färdigheter och frågor överförs ofta relativt väl mellan PostgreSQL, MySQL, SQL Server och andra.
Denna standardisering ger ett rikt ekosystem: ORMs, query builders, rapportverktyg, BI‑dashboards, migrationsramverk och query‑optimizers. Många av dessa går att koppla till de flesta SQL‑databaser med små ändringar, vilket minskar vendor‑lockin och påskyndar utveckling.
NoSQL‑system exponerar frågor på mer varierande sätt:
Vissa NoSQL‑databaser erbjuder aggregeringspipelines eller MapReduce‑liknande mekanismer för analys, men kors‑collection eller kors‑partition JOINs är begränsade eller saknas ofta. Istället bäddar man ofta in relaterad data i samma dokument eller denormaliserar över poster.
Relationsfrågor förlitar sig ofta på JOIN‑tunga mönster: normalisera data och rekonstruera entiteter vid lästid med JOINs. Detta är kraftfullt för ad‑hoc‑rapportering och föränderliga frågor, men komplexa JOINs kan vara svårare att optimera och förstå.
NoSQL‑accessmönster tenderar att vara dokument‑ eller nyckel‑centrerade: designa data runt applikationens vanligaste frågor. Reads blir snabba och enkla—ofta en enda nyckeluppslagning—men att ändra accessmönster senare kan kräva omformning av data.
Vad gäller inlärning och produktivitet:
Team som behöver rika, ad‑hoc‑frågor över relationer brukar föredra SQL. Team med stabila, förutsägbara accessmönster i mycket stor skala hittar ofta att NoSQL‑modeller stämmer bättre med deras behov.
De flesta SQL‑databaser är designade kring ACID‑transaktioner:
Detta gör SQL‑databaser väl lämpade när korrekthet är viktigare än rå skrivgenomströmning.
Många NoSQL‑databaser lutar mot BASE‑egenskaper:
Skrivningar kan vara mycket snabba och distribuerade, men en läsning kan kortvarigt se föråldrad data.
CAP säger att ett distribuerat system under nätverkspartitioner måste välja mellan:
Du kan inte garantera både C och A under en partition.
Typiska mönster:
Moderna system blandar ofta lägen (t.ex. justerbar konsistens per operation) så olika delar av en applikation kan välja de garantier de behöver.
Traditionellt är SQL‑databaser gjorda för en enda, kraftfull nod.
Du börjar ofta med vertikal skalning: mer CPU, RAM och snabbare disk på en server. Många motorer stödjer också read replicas: extra noder som tar emot read‑trafik medan alla skrivningar går till primären. Detta passar för:
Men vertikal skalning når hårdvaru‑ och kostnadsgränser, och read replicas kan introducera replikeringsfördröjning.
NoSQL‑system är ofta byggda för horisontell skalning: sprid data över många noder med sharding eller partitionering. Varje shard håller en delmängd av datan, så både reads och writes kan distribueras, vilket ökar genomströmningen.
Denna metod passar för:
Trade‑offen är högre operationell komplexitet: välja shard‑nycklar, hantera ombalansering och hantera cross‑shard‑frågor.
För read‑tunga arbetsbelastningar med komplexa joins och aggregeringar kan en SQL‑databas med väl utformade index vara extremt snabb, eftersom optimeraren använder statistik och frågeplaner.
Många NoSQL‑system föredrar enkla, nyckelbaserade accessmönster. De utmärker sig för låg latens‑uppslagningar och hög throughput när frågorna är förutsägbara och datan modelleras runt accessmönstren istället för ad‑hoc‑frågor.
Latens i NoSQL‑kluster kan vara mycket låg, men cross‑partition‑frågor, sekundära index och multi‑dokumentoperationer kan vara långsammare eller mer begränsade. Operationellt innebär skalning av NoSQL ofta mer klusterhantering, medan skalning av SQL ofta innebär mer hårdvara och noggrann indexering på färre noder.
Relationella databaser utmärker sig när du behöver pålitlig, hög‑volym OLTP (online transaction processing):
Dessa system förlitar sig på ACID‑transaktioner, strikt konsistens och tydlig rollback‑beteende. Om en överföring aldrig får dubbeldebiteras eller tappa pengar mellan två konton är en SQL‑databas oftast säkrare än de flesta NoSQL‑alternativ.
När din datamodell är välkänd och stabil och entiteter är starkt ihopkopplade är en relationsdatabas ofta ett naturligt val. Exempel:
SQL:s normaliserade scheman, foreign keys och JOINs gör det enklare att säkerställa dataintegritet och fråga komplexa relationer utan att duplicera data.
För rapportering och BI över tydligt strukturerad data (stjärn/snowflake‑scheman, data marts) är SQL‑databaser och SQL‑kompatibla datalager vanligtvis att föredra. Analytiker kan SQL, och befintliga verktyg (dashboards, ETL, styrning) integrerar direkt med relationssystem.
Debatten relationell vs icke‑relationell förbiser ofta operativ mognad. SQL‑databaser erbjuder:
När revisioner, certifieringar eller juridisk exponering är viktiga är SQL ofta ett mer rakt och försvarbart val i SQL vs NoSQL‑avvägningen.
NoSQL‑databaser passar bättre när skalbarhet, flexibilitet och alltid‑tillgänglighet är viktigare än komplexa JOINs och strikta transaktioner.
Om du förväntar dig massiv skrivvolym, oförutsedda trafiktoppar eller dataset som växer till terabyte och vidare är NoSQL‑system (som key‑value eller wide‑column stores) ofta enklare att skala horisontellt. Sharding och replikering är ofta inbyggt, så du kan lägga till kapacitet genom att lägga till noder istället för att bygga om en enda kraftfull server.
Detta är vanligt för:
När din datamodell ändras ofta är en flexibel eller schema‑lös design värdefull. Dokumentdatabaser låter dig utveckla fält och strukturer utan migrationer för varje ändring.
Det fungerar bra för:
NoSQL‑lager är också starka för append‑tunga och tidsordnade arbetsbelastningar:
Nyckel‑värde och tidsserie‑databaser är särskilt optimerade för väldigt snabba skrivningar och enkla reads.
Många NoSQL‑plattformar prioriterar geo‑replikering och multi‑region skrivningar, vilket låter användare runt om i världen läsa och skriva med låg latens. Detta är användbart när:
Trade‑offen är att du ofta accepterar eventual konsistens istället för strikta ACID‑semantiker över regioner.
Att välja NoSQL innebär ofta att ge upp vissa funktioner som SQL erbjuder:
När dessa kompromisser är acceptabla kan NoSQL leverera bättre skalbarhet, flexibilitet och global räckvidd än traditionella relationsdatabaser.
Polyglot persistence innebär att medvetet använda flera databas‑teknologier i samma system, välja bästa verktyget för varje uppgift istället för att pressa allt i en enda lagringslösning.
Ett vanligt mönster är:
Detta håller "system of record" i en relationsdatabas, samtidigt som volatila eller read‑tunga arbetsbelastningar flyttas till NoSQL.
Du kan också kombinera flera NoSQL‑system:
Målet är att anpassa varje datalager till ett specifikt accessmönster: enkla uppslag, aggregeringar, sök eller tidsbaserade reads.
Hybridarkitekturer förlitar sig på integrationspunkter:
Trade‑offen är operationell överhead: fler teknologier att lära sig, övervaka, säkra, backa upp och felsöka. Polyglot persistence fungerar bäst när varje extra datastore tydligt löser ett mätbart problem—inte bara för att det är modernt.
Att välja mellan SQL och NoSQL handlar om att matcha dina data‑ och accessmönster med rätt verktyg, inte att följa en trend.
Fråga dig:
Om ja, är en relationsdatabas ofta standardvalet. Om din data är dokumentlik, nästlad eller varierar mycket per post kan en dokument‑ eller annan NoSQL‑modell passa bättre.
Strikt konsistens och komplexa transaktioner brukar peka mot SQL. Hög skrivgenomströmning med avslappnad konsistens kan peka mot NoSQL.
De flesta projekt kan skala långt med SQL genom bra indexering och hårdvara. Om du förutser mycket stor skala med enkla accessmönster (nyckeluppslag, tidsserier, loggar) kan vissa NoSQL‑system vara mer kostnadseffektiva.
SQL glänser för komplexa frågor, BI‑verktyg och ad‑hoc‑utforskning. Många NoSQL‑databaser är optimerade för fördefinierade accessvägar och kan göra nya frågetyper svårare eller dyrare.
Föredra teknologier som ditt team kan drifta tryggt, särskilt i produktion.
En enda managed SQL‑databas är ofta billigare och enklare tills du tydligt vuxit ur den.
Innan du bestämmer dig:
Använd dessa mätvärden—inte antaganden—för att välja. För många projekt är att börja med SQL den tryggaste vägen, med möjlighet att lägga till NoSQL‑komponenter senare för specifika, högskaliga eller specialiserade behov.
NoSQL kom inte för att döda relationsdatabaser; det kom för att komplettera dem.
Relationsdatabaser dominerar fortfarande för system of record: finans, HR, ERP, lager och alla arbetsflöden där strikt konsistens och rika transaktioner räknas. NoSQL lyser där flexibla scheman, enorm skrivgenomströmning eller globalt distribuerade reads är viktigare än komplexa JOINs och strikta ACID‑garantier.
De flesta organisationer använder båda och väljer rätt verktyg per arbetsbelastning.
Relationssystem har historiskt skalat uppåt med större servrar, men moderna motorer stödjer:
Att skala ett relationssystem kan vara mer involverat än att lägga till noder i vissa NoSQL‑kluster, men horisontell skalning är fullt möjlig med rätt design och verktyg.
"Schema‑löst" betyder ofta "schemat upprätthålls av applikationen, inte databasen."
Dokument, nyckel‑värde och wide‑column stores har fortfarande struktur. De tillåter oftare att strukturen varierar per post, men utan tydliga datakontrakt, styrning och validering leder det snabbt till inkonsekvent data.
Prestanda beror mer på datamodellering, indexering och accessmönster än på kategorin "SQL vs NoSQL."
En dåligt indexerad NoSQL‑collection kan vara långsammare än en väloptimerad relations-tabell för många frågor. På samma sätt kan en relationsschema som ignorerar frågemönster underprestera jämfört med en NoSQL‑modell skräddarsydd för samma queries.
Många NoSQL‑databaser stödjer stark durabilitet, kryptering, revision och åtkomstkontroll. Omvänt kan en felkonfigurerad relationsdatabas vara osäker och bräcklig.
Säkerhet och tillförlitlighet är egenskaper hos en specifik produkt, dess distribution, konfiguration och driftmognad—inte av kategorin i sig.
Team byter ofta mellan SQL och NoSQL av två skäl: skalning och flexibilitet. En högtrafikerad produkt kan behålla en relationsdatabas som betrodd system of record och införa NoSQL för läsningar i stor skala eller för nya funktioner med mer flexibla scheman.
En big‑bang‑migration från SQL till NoSQL (eller tvärtom) är riskfylld. Säkrare alternativ inkluderar:
När man går från SQL till NoSQL frestas team att spegla tabeller som dokument eller nyckel‑värde‑par. Det leder ofta till:
Planera accessmönstren först och designa NoSQL‑schemat runt verkliga queries.
Ett vanligt mönster är SQL för auktoritativ data (fakturering, användarkonton) och NoSQL för read‑tunga vyer (feeds, sök, cache). Oavsett mix, investera i:
Detta håller SQL vs NoSQL‑migrationer kontrollerade snarare än smärtsamma envägsflyttar.
SQL och NoSQL skiljer sig främst i fyra områden:
Ingen kategori är universellt bättre. Det "rätta" valet beror på dina verkliga krav, inte på trender eller slogans.
Skriv ner dina behov:
Defaulta förnuftigt:
Börja litet och mät:
Var öppen för hybrider:
/docs/architecture/datastores).För djupare studier, komplettera denna översikt med interna standarder, migrations‑checklistor och vidare läsning i din engineering‑handbok eller /blog.
SQL (relationella) databaser:
NoSQL (icke‑relationella) databaser:
Använd en SQL‑databas när:
För de flesta nya affärssystem som fungerar som ”system of record” är SQL ett rimligt standardval.
NoSQL passar bäst när:
SQL‑databaser:
NoSQL‑databaser:
SQL‑databaser:
Många NoSQL‑system:
Välj SQL när föråldrade läsningar är farliga; välj NoSQL när kortvarig föråldring är acceptabel i utbyte mot skalbarhet och hög tillgänglighet.
SQL‑databaser brukar:
NoSQL‑databaser brukar:
Ja. Polyglot persistence är vanligt:
Integrationsmönster inkluderar:
Nyckeln är att lägga till varje extra databas endast när den löser ett tydligt problem.
För att flytta gradvis och säkert:
Undvik big‑bang‑migreringar; föredra inkrementella, välövervakade steg.
Tänk på:
Vanliga missuppfattningar:
Utvärdera specifika produkter och arkitekturer istället för att förlita dig på kategori‑nivå myter.
Det innebär att schemakontroll flyttas från databasen (SQL) till applikationen (NoSQL).
Trade‑off: NoSQL‑kluster är ofta mer operationellt komplexa medan SQL kan nå gränser på en enda nod snabbare.
Prototypa båda alternativen för kritiska flöden och mät latens, genomströmning och komplexitet innan beslut.