14 okt. 2025·7 min
Vad är GraphQL? En tydlig guide för API:er och datahämtning
Lär dig vad GraphQL är, hur queries, mutationer och scheman fungerar, och när du bör använda det istället för REST — plus praktiska för- och nackdelar och exempel.
Lär dig vad GraphQL är, hur queries, mutationer och scheman fungerar, och när du bör använda det istället för REST — plus praktiska för- och nackdelar och exempel.
GraphQL är ett query-språk och en runtime för API:er. Enkelt förklarat: det är ett sätt för en app (webb, mobil eller en annan tjänst) att be ett API om data med en tydlig, strukturerad förfrågan — och för servern att returnera ett svar som matchar den förfrågan.
Många API:er tvingar klienter att acceptera vad en fast endpoint returnerar. Det leder ofta till två problem:
Med GraphQL kan klienten begära exakt de fält den behöver, varken mer eller mindre. Det är särskilt användbart när olika skärmar (eller olika appar) behöver olika "skivor" av samma underliggande data.
GraphQL sitter typiskt mellan klientappar och dina datakällor. Dessa datakällor kan vara:
GraphQL-servern tar emot en query, bestämmer hur varje efterfrågat fält ska hämtas från rätt plats, och sätter sedan ihop det slutliga JSON-svaret.
Tänk på GraphQL som att beställa ett skräddarsytt svar:
GraphQL missförstås ofta, här är några klargöranden:
Om du håller fast vid den kärndefinitionen — query-språk + runtime för API:er — har du en bra grund för allt annat.
GraphQL skapades för att lösa ett praktiskt produktproblem: team lade för mycket tid på att få API:er att passa verkliga UI-skärmar.
Traditionella endpoint-baserade API:er tvingar ofta ett val mellan att skicka data du inte behöver eller att göra extra anrop för att få vad du behöver. När produkter växer visar sig den friktionen som långsammare sidor, mer komplicerad klientkod och smärtsam samordning mellan frontend- och backend-team.
Överhämtning uppstår när en endpoint returnerar ett "fullt" objekt trots att en skärm bara behöver ett par fält. En mobil profilsida kanske bara behöver namn och avatar, men API:et returnerar adresser, preferenser, audit-fält och mer. Det slösar bandbredd och kan försämra användarupplevelsen.
Underhämtning är motsatsen: ingen enda endpoint har allt en vy behöver, så klienten måste göra flera förfrågningar och sammanfoga resultaten. Det ökar latens och risken för delvisa fel.
Många REST-stil API:er svarar på förändring genom att lägga till nya endpoints eller versionera (v1, v2, v3). Versionering kan vara nödvändig, men skapar långvarigt underhållsarbete: gamla klienter fortsätter använda gamla versioner medan nya funktioner byggs någon annanstans.
GraphQL:s tillvägagångssätt är att utveckla schemat genom att lägga till fält och typer över tid, samtidigt som befintliga fält hålls stabila. Det minskar ofta trycket att skapa "nya versioner" bara för att stödja nya UI-behov.
Moderna produkter har sällan bara en konsument. Webb, iOS, Android och partnerintegrationer behöver alla olika dataformer.
GraphQL designades så att varje klient kan begära exakt de fält den behöver — utan att backend måste skapa en separat endpoint för varje skärm eller enhet.
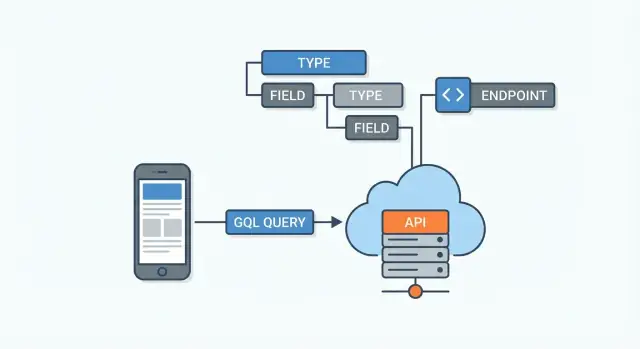
Ett GraphQL-API definieras av sitt schema. Tänk på det som avtalet mellan servern och alla klienter: det listar vilken data som finns, hur den hänger ihop och vad som kan begäras eller ändras. Klienter gissar inte endpoints — de läser schemat och ber om specifika fält.
Schemat består av typer (som User eller Post) och fält (som name eller title). Fält kan peka på andra typer, vilket är hur GraphQL modellerar relationer.
Här är ett enkelt exempel i Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Eftersom schemat är starkt typat kan GraphQL validera en förfrågan innan den körs. Om en klient ber om ett fält som inte finns (t.ex. Post.publishDate när schemat inte har ett sådant fält) kan servern avvisa eller delvis utföra förfrågan med tydliga fel — utan otydligt "kanske fungerar det"-beteende.
Scheman är designade för att växa. Du kan oftast lägga till nya fält (som User.bio) utan att bryta befintliga klienter, eftersom klienter bara får vad de frågar efter. Att ta bort eller ändra fält är känsligare, så team deprecierar ofta fält först och migrerar klienter successivt.
Ett GraphQL-API exponeras vanligtvis via en enkel endpoint (t.ex. /graphql). Istället för många URL:er för olika resurser (som /users, /users/123, /users/123/posts) skickar du en query till ett ställe och beskriver exakt vilken data du vill ha tillbaka.
En query är i princip en "inköpslista" av fält. Du kan begära enkla fält (som id och name) och även nästlad data (som en användares senaste inlägg) i samma förfrågan — utan att ladda onödiga fält.
Här är ett litet exempel:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
GraphQL-svar är förutsägbara: JSON du får tillbaka speglar strukturen i din query. Det gör det enklare att arbeta med på frontend, eftersom du inte behöver gissa var data dyker upp eller parsa olika svarformat.
Ett förenklat svarsformat kan se ut så här:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Om du inte ber om ett fält kommer det inte att ingå. Om du ber om det kan du förvänta dig att det finns på motsvarande plats — vilket gör GraphQL-queries till ett rent sätt att hämta exakt vad varje skärm eller funktion behöver.
Queries är för läsning; mutationer är hur du ändrar data i ett GraphQL-API — skapar, uppdaterar eller tar bort poster.
De flesta mutationer följer samma mönster:
input-objekt) med fälten som ska uppdateras.GraphQL-mutationer returnerar ofta data med vilja, istället för bara "success: true". Att returnera det uppdaterade objektet (eller åtminstone dess id och nyckelfält) hjälper UI att:
Ett vanligt mönster är en "payload"-typ som inkluderar både den uppdaterade entiteten och eventuella fel.
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
För UI-drivna API:er är en bra regel: returnera det du behöver för att rendera nästa tillstånd (t.ex. den uppdaterade user plus eventuella errors). Det håller klienten enkel, undviker att gissa vad som förändrats och gör det lättare att hantera fel graciöst.
Ett GraphQL-schema beskriver vad som kan efterfrågas. Resolvers beskriver hur du faktiskt hämtar det. En resolver är en funktion kopplad till ett specifikt fält i ditt schema. När en klient begär det fältet kallar GraphQL på resolvern för att hämta eller beräkna värdet.
GraphQL exekverar en query genom att gå igenom den begärda formen. För varje fält hittar den motsvarande resolver och kör den. Vissa resolvers returnerar enkelt en egenskap från ett objekt redan i minnet; andra gör en databasfråga, anropar en annan tjänst eller kombinerar flera källor.
Till exempel, om ditt schema har User.posts, kan posts-resolvern fråga en posts-tabell med userId, eller anropa en separat Posts-tjänst.
Resolvers är limmet mellan schemat och dina riktiga system:
Denna mappning är flexibel: du kan ändra din backend-implementation utan att ändra klientens query-form — så länge schemat förblir konsekvent.
Eftersom resolvers kan köras per fält och per item i en lista är det lätt att oavsiktligt trigga många små anrop (t.ex. hämta inlägg för 100 användare med 100 separata frågor). Det här "N+1"-mönstret kan göra svaren långsamma.
Vanliga åtgärder inkluderar batching och caching (t.ex. samla ID:n och hämta i en fråga) och att vara medveten om vilka nästlade fält du uppmuntrar klienter att begära.
Auktorisation genomförs ofta i resolvers (eller delad middleware) eftersom resolvers vet vem som frågar (via context) och vilken data de når. Validering sker typiskt på två nivåer: GraphQL hanterar typ-/formsvalidering automatiskt, medan resolvers ansvarar för affärsregler (t.ex. "endast admins kan sätta detta fält").
En sak som överraskar nybörjare med GraphQL är att en förfrågan kan "lyckas" och ändå innehålla fel. Det beror på att GraphQL är fält-orienterat: om vissa fält kan lösas och andra inte, kan du få tillbaka delvis data.
Ett typiskt GraphQL-svar kan innehålla både data och en errors-array:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Detta är användbart: klienten kan ändå rendera det den har (t.ex. användarprofilen) samtidigt som den hanterar det saknade fältet.
data ofta null.Skriv felmeddelanden för slutanvändaren, inte för debugging. Undvik att exponera stacktraces, databasenamn eller interna ID:n. Ett bra mönster är:
messageextensions.coderetryable: true)Logga detaljerade fel server-side med ett request-ID så du kan undersöka utan att exponera interna detaljer.
Definiera ett litet fel-"kontrakt" som webben och mobila appar delar: vanliga extensions.code-värden (som UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), när man visar en toast vs inline-fältfel, och hur man hanterar delvis data. Konsekvens här förhindrar att varje klient hittar på egna felregler.
Subscriptions är GraphQL:s sätt att pusha data till klienter när den ändras, istället för att klienten frågar upprepade gånger. De levereras vanligtvis över en persistent anslutning (oftast WebSockets), så servern kan skicka händelser i samma ögonblick som något händer.
En subscription liknar mycket en query, men resultatet är inte ett enda svar. Det är en ström av resultat — vart och ett representerar en händelse.
Under huven "prenumererar" en klient på ett ämne (t.ex. messageAdded i en chattapp). När servern publicerar en händelse får alla anslutna prenumeranter en payload som matchar subscriptionens selection set.
Subscriptions är utmärkta när användare förväntar sig omedelbara förändringar:
Med polling frågar klienten "Något nytt?" var N:e sekund. Det är enkelt, men kan slösa anrop (särskilt när ingenting ändrats) och känns fortfarande fördröjt.
Med subscriptions säger servern "Här är uppdateringen" direkt. Det kan minska onödig trafik och förbättra upplevd snabbhet — på bekostnad av öppna anslutningar och drift av realtidsinfrastruktur.
Subscriptions är inte alltid värda kostnaden. Om uppdateringar är sällsynta, inte tidskritiska eller lätta att batcha kan polling (eller att helt enkelt läsa om efter användaråtgärder) vara tillräckligt.
De kan också öka driftkostnaden: skalning av anslutningar, auth för långlivade sessioner, retries och övervakning. En bra regel: använd subscriptions endast när realtid är ett produktkrav, inte bara ett trevligt tillägg.
GraphQL beskrivs ofta som "makt till klienten", men den makten har kostnader. Att känna till avvägningarna i förväg hjälper dig att avgöra när GraphQL är ett bra val — och när det kan vara överdrivet.
Den största vinsten är flexibel datahämtning: klienter kan begära exakt de fält de behöver, vilket kan minska överhämtning och göra UI-ändringar snabbare.
En annan stor fördel är det starka kontraktet som ett GraphQL-schema ger. Schemat blir en enda sanningskälla för typer och tillgängliga operationer, vilket förbättrar samarbete och verktyg.
Team ser ofta bättre frontend-produktivitet eftersom frontend-utvecklare kan iterera utan att vänta på nya endpoint-varianter, och verktyg som Apollo Client kan generera typer och förenkla datahämtning.
GraphQL kan göra caching mer komplex. Med REST är caching ofta "per URL". Med GraphQL delar många queries samma endpoint, så caching bygger på query-former, normaliserade caches och noggrann server/klient-konfiguration.
På serversidan finns prestandafallgropar. En till synes liten query kan trigga många backend-anrop om du inte designar resolvers noggrant (batching, undvika N+1, och kontroll av dyra fält).
Det finns också en inlärningskurva: scheman, resolvers och klientmönster kan vara nya för team som är vana vid endpoint-baserade API:er.
Eftersom klienter kan be om mycket bör GraphQL-API:er införa begränsningar för query-djup och komplexitet för att förhindra missbruk eller oavsiktligt väldigt stora förfrågningar.
Autentisering och auktorisation bör upprätthållas per fält, inte bara på rutenivå, eftersom olika fält kan ha olika åtkomstregler.
Operationellt: investera i loggning, tracing och övervakning som förstår GraphQL: spåra operationsnamn, variabler (varsamt), resolver-tider och felkvoter så att du snabbt kan upptäcka långsamma queries och regressions.
GraphQL och REST hjälper båda appar att prata med servrar, men de strukturerar den konversationen på väldigt olika sätt.
REST är resursbaserat. Du hämtar data genom att anropa flera endpoints (URL:er) som representerar "saker" som /users/123 eller /orders?userId=123. Varje endpoint returnerar en fast datamängd bestämd av servern.
REST lutar också mot HTTP-semantik: metoder som GET/POST/PUT/DELETE, statuskoder och cache-regler. Det kan göra REST naturligt när du gör enkel CRUD eller arbetar nära browser/proxy-caches.
GraphQL är schema-baserat. Istället för många endpoints har du vanligtvis en endpoint, och klienten skickar en query som beskriver exakt vilka fält den vill ha. Servern validerar förfrågan mot GraphQL-schemat och returnerar ett svar som matchar queryns form.
Denna "klient-styrda selektion" är anledningen till att GraphQL kan minska överhämtning (för mycket data) och underhämtning (inte tillräckligt med data), särskilt för UI-skärmar som behöver data från flera relaterade modeller.
REST passar ofta bättre när:
Många team blandar båda:
Den praktiska frågan är inte "Vilken är bättre?" utan "Vad passar detta use case med minst komplexitet?"
Att designa ett GraphQL-API är enklast om du ser det som en produkt för de som bygger skärmar, inte som en spegel av din databas. Börja litet, validera med verkliga användningsfall och utöka efter behov.
Lista dina nyckelskärmar (t.ex. "Produktlista", "Produktdetaljer", "Checkout"). För varje skärm, skriv ner exakt vilka fält den behöver och vilka interaktioner den stöder.
Det hjälper dig undvika "god queries", minskar överhämtning och klargör var du behöver filtrering, sortering och paginering.
Definiera dina kärntyper först (t.ex. User, Product, Order) och deras relationer. Lägg sedan till:
Föredra affärsspråk i namngivning framför databasspråk. "placeOrder" kommunicerar avsikt bättre än "createOrderRecord".
Håll namngivningen konsekvent: singular för enstaka poster (product), plural för kollektioner (products). För paginering väljer du oftast:
Bestäm tidigt eftersom det formar API:ets svarsstruktur.
GraphQL stödjer beskrivningar direkt i schemat — använd dem för fält, argument och edge cases. Lägg sedan till några copy-paste-exempel i din dokumentation (inklusive paginering och vanliga felscenarion). Ett välbeskrivet schema gör introspektion och API-explorers mycket mer användbara.
Att börja med GraphQL handlar mest om att välja några välstödda verktyg och sätta upp ett arbetsflöde du litar på. Du behöver inte adoptera allt på en gång — få en query att fungera end-to-end och utöka sedan.
Välj en server baserat på din stack och hur mycket "batteries included" du vill ha:
Ett praktiskt första steg: definiera ett litet schema (ett par typer + en query), implementera resolvers och koppla en riktig datakälla (även om det bara är en stub i minnet).
Om du vill gå snabbare från idé till en fungerande API kan en vibe-coding-plattform som Koder.ai hjälpa dig att skaffa ett litet fullstack-projekt (React på frontend, Go + PostgreSQL på backend) och iterera på GraphQL-schema/resolvers via chat — och exportera källkoden när du är redo att ta över implementeringen.
På frontend beror valet ofta på om du vill ha opinionerade konventioner eller flexibilitet:
Om du migrerar från REST, börja med att använda GraphQL för en skärm eller funktion och behåll REST för resten tills tillvägagångssättet bevisat sitt värde.
Behandla ditt schema som ett API-kontrakt. Användbara testlager inkluderar:
För att fördjupa din förståelse, fortsätt med:
GraphQL är ett query-språk och en runtime för API:er. Klienter skickar en query som beskriver exakt vilka fält de vill ha, och servern returnerar ett JSON-svar som speglar den formen.
Tänk på det som ett lager mellan klienter och en eller flera datakällor (databaser, REST-tjänster, tredjeparts-API:er, mikrotjänster).
GraphQL hjälper främst mot:
Genom att låta klienten begära bara specifika fält (inklusive nästlade fält) kan GraphQL minska onödig dataöverföring och förenkla klientkoden.
GraphQL är inte:
Behandla det som ett API-kontrakt + en exekveringsmotor, inte som magi för lagring eller prestanda.
De flesta GraphQL-API:er exponerar en enkel endpoint (ofta /graphql). Istället för många URL:er skickar du olika operationer (queries/mutationer) till den ena endpointen.
Praktisk konsekvens: caching och observability baseras ofta på operationsnamn + variabler, inte URL:en.
Schemat är API-kontraktet. Det definierar:
User, Post)User.name)User.posts)Eftersom det är kan servern validera queries innan exekvering och ge tydliga fel om ett fält inte finns.
GraphQL-queries är läsoperationer. Du specificerar de fält du behöver, och svaret i JSON matchar queryns struktur.
Tips:
query GetUserWithPosts) för bättre debug och övervakning.posts(limit: 2)).Mutationer är skrivoperationer (create/update/delete). Ett vanligt mönster är:
input-objektAtt returnera data (inte bara success: true) hjälper UI att uppdatera direkt och håller caches konsekventa.
Resolvers är fält-nivå funktioner som berättar för GraphQL hur varje fält hämtas eller beräknas.
I praktiken kan resolvers:
Auktorisering brukar ofta skötas i resolvers (eller delad middleware) eftersom de vet vem som begär och vilket fält som åtkomstas.
Det är lätt att skapa ett N+1-mönster (t.ex. ladda inlägg separat för varje av 100 användare).
Vanliga motåtgärder:
Mät resolver-tider och leta efter upprepade downstream-anrop under en förfrågan.
GraphQL kan returnera delvis data tillsammans med en errors-array. Det inträffar när några fält löses framgångsrikt och andra misslyckas (t.ex. ett fält är förbjudet eller en downstream-tjänst tajmar ut).
Bra praxis:
message-strängarextensions.code-värden (t.ex. FORBIDDEN, BAD_USER_INPUT)Klienter bör själva avgöra när de visar partiell data kontra att betrakta operationen som ett fullständigt fel.