22 sep. 2025·8 min
Vad är Kafka och hur används det i moderna system?
Lär dig vad Apache Kafka är, hur topics och partitioner fungerar och var Kafka passar in i moderna system för realtids-händelser, loggar och datapipelines.
Lär dig vad Apache Kafka är, hur topics och partitioner fungerar och var Kafka passar in i moderna system för realtids-händelser, loggar och datapipelines.
Apache Kafka är en distribuerad plattform för händelseströmning. Enkelt uttryckt är det ett delat, hållbart "rör" som låter många system publicera fakta om vad som hände och låter andra system läsa dessa fakta—snabbt, i skala och i ordning.
Team använder Kafka när data behöver flyttas påliteligt mellan system utan hård koppling. Istället för att en applikation ringer en annan direkt (och misslyckas när den är nere eller långsam), skriver producers events till Kafka. Consumers läser dem när de är redo. Kafka lagrar events under en konfigurerbar period, så system kan återhämta sig från driftstopp och till och med reprocessera historik.
Denna guide är för produktinriktade ingenjörer, datafolk och tekniska ledare som vill ha en praktisk mental modell av Kafka.
Du får lära dig de centrala byggstenarna (producers, consumers, topics, brokers), hur Kafka skalar med partitioner, hur det lagrar och spelar upp events, och var det passar in i en händelsestyrd arkitektur. Vi täcker även vanliga användningsfall, leveransgarantier, säkerhetsgrunder, driftsplanering och när Kafka är (eller inte är) rätt verktyg.
Kafka är lättast att förstå som en delad event-logg: applikationer skriver events till den, och andra applikationer läser dessa events senare—ofta i realtid, ibland timmar eller dagar efter.
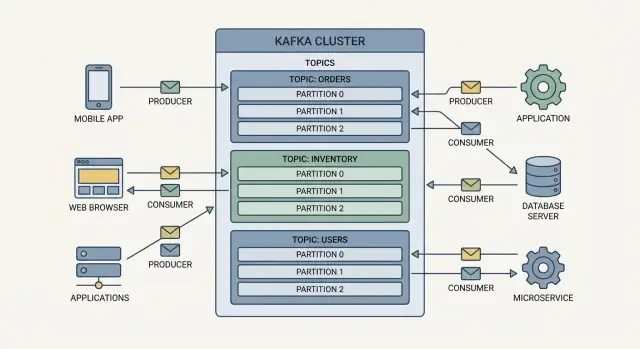
Producers är skrivarna. En producer kan publicera ett event som “order placed”, “payment confirmed” eller “temperature reading”. Producers skickar inte events direkt till specifika appar—de skickar dem till Kafka.
Consumers är läsarna. En consumer kan driva en dashboard, trigga ett leveransflöde eller ladda data till analytics. Consumers bestämmer vad som ska göras med events, och de kan läsa i egen takt.
Events i Kafka grupperas i topics, vilket i praktiken är namngivna kategorier. Exempel:
orders för orderrelaterade eventspayments för betalningarinventory för lagerförändringarEn topic blir den “sanna källan” för den typen av event, vilket gör det enklare för flera team att återanvända samma data utan att bygga engångsintegrationer.
En broker är en Kafka-server som lagrar events och serverar dem till consumers. I praktiken körs Kafka som ett kluster (flera brokers tillsammans) så att det kan hantera mer trafik och fortsätta fungera även om en maskin går ner.
Consumers körs ofta i en consumer group. Kafka fördelar läsarbete över gruppen, så du kan lägga till fler consumer-instanser för att skala ut bearbetningen—utan att varje instans gör samma jobb.
Kafka skalar genom att dela upp arbete i topics (ström av relaterade events) och sedan dela varje topic i partitioner (mindre, oberoende skivor av den strömmen).
En topic med en partition kan bara läsas av en consumer åt gången inom en consumer-grupp. Lägg till fler partitioner, och du kan lägga till fler consumers för att bearbeta events parallellt. Så skalar Kafka höghastighets händelseströmning och realtidsdata-pipelines utan att varje system blir en flaskhals.
Partitioner hjälper också till att sprida belastning över brokers. Istället för att en maskin hanterar alla skrivningar och läsningar för en topic, kan flera brokers hosta olika partitioner och dela trafiken.
Kafka garanterar ordning inom en enskild partition. Om events A, B och C skrivs till samma partition i den ordningen, kommer consumers att läsa dem A → B → C.
Ordning över partitioner garanteras inte. Om du behöver strikt ordning för en viss entitet (som en kund eller order), ser du vanligen till att alla events för den entiteten går till samma partition.
När producers skickar ett event kan de inkludera en key (till exempel order_id). Kafka använder key:n för att konsekvent routa relaterade events till samma partition. Det ger förutsägbar ordning för den key:n samtidigt som hela topicen kan skala över många partitioner.
Varje partition kan replikerats till andra brokers. Om en broker går ner kan en annan broker med en replica ta över. Replikering är en viktig anledning till att Kafka litas för kritiska pub/sub-meddelanden och händelsestyrda system: det förbättrar tillgänglighet och stödjer fel tolerans utan att varje applikation måste bygga egen failover-logik.
En nyckelidé i Apache Kafka är att events inte bara skickas vidare och glöms bort. De skrivs till disk i en ordnad logg, så consumers kan läsa dem nu—eller senare. Det gör Kafka användbart inte bara för att flytta data, utan också för att behålla en hållbar historik över vad som hände.
När en producer skickar ett event till en topic, appendas det till lagring på brokern. Consumers läser sedan från den lagrade loggen i egen takt. Om en consumer är nere i en timme finns events kvar och kan läsas när den återhämtar sig.
Kafka behåller events enligt retention-policyer:
Retention konfigureras per topic, vilket låter dig behandla "audit trail"-topics annorlunda än högvolym-telemetri.
Vissa topics är mer som en changelog än ett historiskt arkiv—till exempel “current customer settings.” Log compaction behåller åtminstone det senaste eventet för varje key, medan äldre ersatta poster kan tas bort. Du får fortfarande en hållbar källa för det senaste tillståndet utan oändlig tillväxt.
Eftersom events förblir lagrade kan du spela upp dem för att rekonstruera tillstånd:
I praktiken styrs replay av var en consumer “börjar läsa” (dess offset), vilket ger team ett kraftfullt säkerhetsnät när system utvecklas.
Kafka är byggt för att hålla data flödande även när delar av systemet fallerar. Det görs med replikering, tydliga regler för vem som är “ansvarig” för varje partition och konfigurerbara skrivbekräftelser.
Varje topic-partition har en leader broker och en eller flera follower-replicas på andra brokers. Producers och consumers pratar med leadern för den partitionen.
Followers kopierar kontinuerligt leaderns data. Om leadern går ner kan Kafka promota en up-to-date follower till ny leader så att partitionen förblir tillgänglig.
Om en broker kraschar blir de partitioner den var leader för otillgängliga en stund. Kafkas controller (intern koordinering) upptäcker felet och triggar en leader election för de berörda partitionerna.
Om minst en follower-replica är tillräckligt synkad kan den ta över som leader och klienterna fortsätter producera/consumera. Om ingen in-sync-replica finns kan Kafka pausa skrivningar (beroende på inställningar) för att undvika att förlora bekräftad data.
Två viktiga inställningar påverkar beständighet:
På konceptuell nivå:
För att minska dubbletter vid retries kombinerar team ofta säkrare acks med idempotenta producers och robust consumer-hantering.
Högre säkerhet innebär ofta att vänta på fler bekräftelser och hålla fler replicor synkade, vilket kan öka latens och minska maximal genomströmning.
Lägre latens-inställningar kan vara acceptabla för telemetri eller clickstream där viss förlust tolereras, medan betalningar, lager och revisionsloggar ofta motiverar extra säkerhet.
Händelsestyrd arkitektur (EDA) är ett sätt att bygga system där affärshändelser—en order lagd, en betalning bekräftad, ett paket skickat—representeras som events som andra delar av systemet kan reagera på.
Kafka sitter ofta i centrum av EDA som den delade “eventströmmen.” Istället för att Service A ringer Service B direkt, publicerar Service A ett event (till exempel OrderCreated) till en Kafka-topic. Ett godtyckligt antal andra tjänster kan consuma det eventet och agera—skicka e-post, reservera lager, starta fraud-kontroller—utan att Service A behöver veta att de finns.
Eftersom tjänster kommunicerar via events behöver de inte koordinera request/response-API:er för varje interaktion. Det minskar hård koppling mellan team och gör det enklare att lägga till nya funktioner: du kan introducera en ny consumer för ett befintligt event utan att ändra producenten.
EDA är naturligt asynkront: producers skriver events snabbt och consumers processar dem i egen takt. Vid trafikspikar hjälper Kafka till att buffra ökningen så att downstream-system inte kollapsar direkt. Consumers kan skalas ut för att komma ifatt, och om en consumer går ner tillfälligt kan den fortsätta där den slutade.
Tänk på Kafka som systemets “aktivitetssflöde.” Producers publicerar fakta; consumers prenumererar på de fakta de bryr sig om. Det mönstret möjliggör realtidsdata-pipelines och händelsestyrda arbetsflöden samtidigt som tjänster hålls enklare och mer oberoende.
Kafka dyker upp där team behöver flytta många små “fakta som hände” (events) mellan system—snabbt, pålitligt och så att flera consumers kan återanvända samma data.
Applikationer behöver ofta en append-only-historik: användarinloggningar, ändringar av rättigheter, uppdateringar eller admin-åtgärder. Kafka fungerar bra som en central ström av dessa events, så säkerhetsverktyg, rapportering och export för efterlevnad kan läsa samma källa utan att belasta produktionsdatabasen. Eftersom events behålls en tid kan du också spela upp dem för att bygga om en audit-vy efter en bugg eller schemaändring.
Istället för att tjänster ringer varandra direkt kan de publicera events som “order created” eller “payment received.” Andra tjänster prenumererar och reagerar i egen takt. Det minskar hård koppling, hjälper systemen att fortsätta fungera under partiella driftstopp och gör det enklare att lägga till nya kapabiliteter (t.ex. fraud-checks) genom att helt enkelt konsumera den befintliga eventströmmen.
Kafka är ett vanligt ryggrad för att flytta data från operationella system till analytics-plattformar. Team kan strömma förändringar från produktionsdatabaser och leverera dem till ett warehouse eller en datalake med låg fördröjning, samtidigt som produktionsappen hålls skild från tunga analytiska frågor.
Sensorer, enheter och app-telemetri kommer ofta i spikar. Kafka kan absorbera burstar, buffra dem säkert och låta downstream-bearbetning komma ikapp—nyttigt för övervakning, larm och långsiktig analys.
Kafka är mer än brokers och topics. De flesta team förlitar sig på kringverktyg som gör Kafka praktiskt för daglig dataflytt, strömbehandling och drift.
Kafka Connect är Kafkas integrationsramverk för att få data in i Kafka (sources) och ut ur Kafka (sinks). Istället för att bygga och underhålla engångspipelines kör du Connect och konfigurerar connectors.
Vanliga exempel är att hämta förändringar från databaser, importera SaaS-händelser eller leverera Kafka-data till ett data warehouse eller objektlagring. Connect standardiserar också driftsfrågor som retries, offsets och parallelism.
Om Connect är för integration är Kafka Streams för beräkning. Det är ett bibliotek du lägger till i din applikation för att transformera strömmar i realtid—filtrera events, berika dem, göra joins och bygga aggregat (som “orders per minute”).
Eftersom Streams-appar läser från topics och skriver tillbaka till topics passar de naturligt i händelsestyrda system och kan skalas genom att lägga till fler instanser.
När flera team publicerar events blir konsekvens viktigt. Schemahantering (ofta via en schema registry) definierar vilka fält ett event ska ha och hur de kan utvecklas över tid. Det hjälper till att undvika fel som när en producer byter namn på ett fält som en consumer förlitar sig på.
Kafka är känsligt ur operationssynpunkt, så grundläggande övervakning är nödvändigt:
De flesta team använder också management-UI:er och automation för deploys, topic-konfiguration och åtkomstkontrollspolicys.
Kafka beskrivs ofta som “hållbar logg + consumers”, men vad team verkligen bryr sig om är: kommer jag att bearbeta varje event en gång, och vad händer när något går fel? Kafka ger byggstenar, och du väljer trade-offs.
At-most-once betyder att du kan förlora events, men du får inga dubbletter. Detta kan hända om en consumer committar sin position först och sedan kraschar innan arbetet är klart.
At-least-once betyder att du inte förlorar events, men dubbletter är möjliga (till exempel om consumer processar ett event, kraschar och sedan processar om det efter omstart). Detta är vanligaste standardläget.
Exactly-once syftar till att undvika både förlust och dubbletter end-to-end. I Kafka involverar detta vanligtvis transaktionella producers och kompatibel bearbetning (ofta via Kafka Streams). Det är kraftfullt men mer begränsat och kräver noggrann konfiguration.
I praktiken accepterar många system at-least-once och lägger till skydd:
En consumer offset är positionen för den senast processade posten i en partition. När du committar offsets säger du: “Jag är klar upp till här.” Commita för tidigt och du riskerar förlust; commita för sent och du ökar dubbletter efter fel.
Retries bör vara begränsade och synliga. Ett vanligt mönster är:
Detta hindrar ett “poison message” från att blockera hela consumer-gruppen samtidigt som datan bevaras för senare felsökning.
Kafka transporterar ofta affärskritiska events (orders, betalningar, användaraktivitet). Det gör säkerhet och styrning till en del av designen, inte något som läggs till i efterhand.
Autentisering svarar på “vem är du?” Auktorisation svarar på “vad får du göra?” I Kafka görs autentisering ofta med SASL (t.ex. SCRAM eller Kerberos), medan auktorisation upprätthålls med ACLs (access control lists) på topic-, consumer group- och klusternivå.
Ett praktiskt mönster är minst privilegium: producers kan bara skriva till de topics de äger, och consumers kan bara läsa de topics de behöver. Det minskar oavsiktlig dataexponering och begränsar skadeomfånget om uppgifter läcker.
TLS krypterar data när den rör sig mellan appar, brokers och verktyg. Utan TLS kan events fångas upp på interna nätverk, inte bara på öppna internet. TLS hjälper också till att förhindra “man-in-the-middle”-attacker genom att validera broker-identiteter.
När flera team delar ett kluster behövs styrregler. Tydliga topic-namngivningskonventioner (till exempel <team>.<domain>.<event>.<version>) gör ägarskap uppenbart och hjälper verktyg att tillämpa policys konsekvent.
Matcha namngivning med quotas och ACL-mallar så en bullrig arbetslast inte kväver andra, och så nya tjänster startar med säkra standardvärden.
Behandla Kafka som en system-of-record för eventhistorik bara om du avser det. Om events innehåller PII, använd dataminimering (skicka ID istället för fulla profiler), överväg fältnivå-kryptering och dokumentera vilka topics som är känsliga.
Retention-inställningar bör matcha juridiska och affärsmässiga krav. Om policyn säger “radera efter 30 dagar”, behåll inte 6 månader av events “för säkerhets skull”. Regelbundna granskningar och revisioner håller konfigurationer i fas när system förändras.
Att köra Apache Kafka är inte bara “installera och glömma”. Det beter sig mer som en delad tjänst: många team är beroende av den, och små misstag kan påverka downstream-appar.
Kafka-kapacitet är mest ett beräkningsproblem du återbesöker regelbundet. De största parametrarna är partitioner (parallellism), throughput (MB/s in och ut) och lagringstillväxt (hur länge du behåller data).
Om trafiken fördubblas kan du behöva fler partitioner för att sprida belastning över brokers, mer disk för retention och mer nätverk för replikering. En praktisk vana är att prognostisera peak write rate och multiplicera med retention för att uppskatta diskväxt, sedan lägga till buffert för replikering och “oväntad framgång”.
Räkna med rutinuppgifter utöver att hålla servrar uppe:
Kostnader drivs av disk, nätverksutgående trafik och antalet/storleken på brokers. Managed Kafka kan minska bemanningskostnader och förenkla uppgraderingar, medan egen drift kan bli billigare i skala om ni har erfarna operatörer. Trade-offen är återhämtningstid och on-call-börda.
Team övervakar typiskt:
Bra dashboards och alerting gör Kafka från en “mystery box” till en förståelig tjänst.
Kafka passar bra när du behöver flytta många events pålitligt, behålla dem en tid och låta flera system reagera på samma data i egen takt. Det är särskilt användbart när data måste kunna spelas upp (för backfills, revisioner eller återuppbyggnad av en ny tjänst) och när du förväntar dig fler producers/consumers över tid.
Kafka gör sig bra när du har:
Kafka kan vara overkill om dina behov är enkla:
I dessa fall kan driftkostnaden (klusterstorlek, uppgraderingar, övervakning, on-call) överväga fördelarna.
Kafka kompletterar också—inte ersätter—databaser (system of record), cacher (snabba läsningar) och batch ETL-verktyg (stora periodiska transformationer).
Fråga dig:
Om du svarar “ja” på de flesta av dessa är Kafka oftast ett rimligt val.
Kafka passar bäst när du behöver en delad “källa till sanning” för realtids eventströmmar: många system som producerar fakta (orders skapade, betalningar auktoriserade, lager ändrat) och många system som konsumerar dessa fakta för pipelines, analytics och reaktiva funktioner.
Börja smalt med ett högvärdigt flöde—till exempel att publicera “OrderPlaced”-events för downstream-tjänster (e-post, fraud-kontroller, fulfilment). Undvik att göra Kafka till en catch-all-kö första dagen.
Skriv ner:
Håll tidiga scheman enkla och konsekventa (tidsstämplar, ID:n och ett tydligt event-namn). Bestäm om ni ska kräva scheman direkt eller utveckla dem varsamt över tid.
Kafka lyckas när någon äger:
Lägg till övervakning omedelbart (consumer lag, brokerhälsa, throughput, fel). Om ni inte har ett plattforms-team än, börja med ett managed erbjudande och tydliga begränsningar.
Producera events från ett system, konsumera dem på ett ställe och bevisa slut-till-slut-loopen. Expandera sedan till fler consumers, partitioner och integrationer.
Om du vill gå snabbt från idé till en fungerande händelsestyrd tjänst kan verktyg som Koder.ai hjälpa dig prototypa kringliggande applikationer snabbt (React UI, Go-backend, PostgreSQL) och iterativt lägga till Kafka producers/consumers via en chattdriven workflow. Det är särskilt användbart för att bygga interna dashboards och lätta tjänster som konsumerar topics, med funktioner som planning mode, export av källkod, deployment/hosting och snapshots med rollback.
Om du kartlägger detta i en händelsestyrd strategi, se blogginlägget om event-driven architecture. För planering av kostnader och miljöer, se prisinformation.
Kafka är en distribuerad plattform för händelseströmning som lagrar events i hållbara, append-only-loggar.
Producers skriver events till topics, och consumers läser dem oberoende (ofta i realtid, men också senare) eftersom Kafka behåller data under en konfigurerbar period.
Använd Kafka när flera system behöver samma ström av events, du vill ha lös koppling och du kanske behöver kunna spela upp historik.
Det är särskilt användbart för:
En topic är en namngiven kategori av events (som orders eller payments).
En partition är en skiva av en topic som möjliggör:
Kafka garanterar ordning endast inom en enskild partition.
Kafka använder recordens key (till exempel order_id) för att konsekvent routa relaterade events till samma partition.
Praktisk regel: om du behöver ordning per entitet (alla events för en order/kund i sekvens), välj en key som representerar den entiteten så att dessa events hamnar i en partition.
En consumer group är en uppsättning consumer-instanser som delar arbetet för en topic.
Inom en grupp:
Om du behöver att två olika appar båda får varje event, ska de använda olika consumer-grupper.
Kafka behåller events på disk enligt topic-policyer, så consumers kan komma ikapp efter stillestånd eller läsa om historik.
Vanliga retention-typer:
Retention är per-topic, så viktiga audit-strömmar kan sparas längre än högvolym-telemetri.
Log compaction behåller åtminstone det senaste registret per key och tar bort äldre ersatta poster över tid.
Det är användbart för “nuvarande tillstånd”-strömmar (som inställningar eller profiler) där du bryr dig om senaste värdet per key snarare än varje historisk förändring—samtidigt som du behåller en hållbar källa för sista tillståndet.
Det vanligaste mönstret i Kafka är at-least-once: du förlorar sällan events, men dubbletter kan uppstå.
För att hantera detta säkert:
Offsets är en consumers “bokmärke” per partition.
Om du committar offsets för tidigt kan du förlora arbete vid krasch; committa för sent ökar sannolikheten för att du processar om och skapar dubbletter.
Ett vanligt operativt mönster är begränsade retries med backoff, och därefter publicera misslyckade poster till en dead-letter-topic så att ett enskilt trasigt meddelande inte blockerar hela consumer-gruppen.
Kafka Connect flyttar data in och ut ur Kafka med hjälp av connectors (sources och sinks) istället för att bygga anpassad pipelinekod.
Kafka Streams är ett bibliotek för att transformera och aggregera strömmar i realtid inne i dina applikationer (filtrera, join, berika, aggregera), läsa från topics och skriva resultat tillbaka till topics.
Connect är vanligtvis för integration; Streams är för beräkning.