03 maj 2025·8 min
Validering, fel och kantfall i AI-genererade system
Lär dig hur AI-genererade arbetsflöden avslöjar valideringsregler, behov av felhantering och svåra kantfall—plus praktiska sätt att testa, övervaka och åtgärda dem.
Lär dig hur AI-genererade arbetsflöden avslöjar valideringsregler, behov av felhantering och svåra kantfall—plus praktiska sätt att testa, övervaka och åtgärda dem.
Ett AI-genererat system är vilken produkt som helst där en AI-modells output direkt formar vad systemet gör härnäst—vad som visas för användaren, vad som sparas, vad som skickas till ett annat verktyg eller vilka åtgärder som utförs.
Detta är bredare än en "chatbot". I praktiken kan AI-generering visa sig som:
Om du har använt en vibe-kodningsplattform som Koder.ai—där en chattkonversation kan generera och utveckla hela webb-, backend- eller mobilapplikationer—är idén "AI-output blir kontrollflöde" särskilt tydlig. Modellens output är inte bara råd; den kan ändra rutter, scheman, API-anrop, distributioner och användarens synliga beteende.
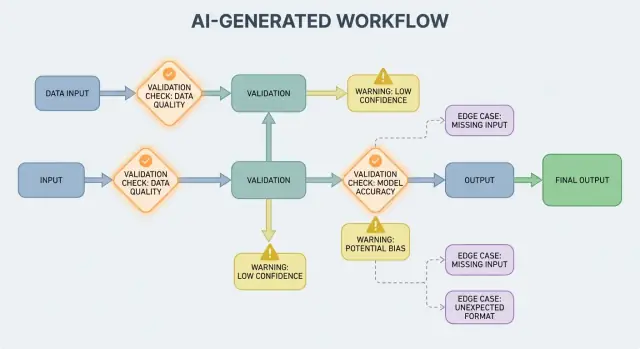
När AI-output är en del av kontrollflödet blir valideringsregler och felhantering användarorienterade tillförlitlighetsfunktioner, inte bara ingenjörsdetaljer. Ett saknat fält, ett felformat JSON-objekt eller en självsäker-men-felaktig instruktion "faller inte bara"—det kan skapa förvirrande UX, felaktiga poster eller riskfyllda åtgärder.
Målet är alltså inte att "aldrig misslyckas." Fel är normala när outputs är probabilistiska. Målet är kontrollerat fel: upptäck problem tidigt, kommunicera tydligt och återställ säkert.
Resten av inlägget delar upp ämnet i praktiska områden:
Om du behandlar validering och felvägar som förstklassiga delar av produkten blir AI-genererade system enklare att lita på—och lättare att förbättra över tid.
AI-system är duktiga på att generera troliga svar, men "troligt" är inte samma sak som "användbart." I det ögonblick du förlitar dig på en AI-output för ett verkligt arbetsflöde—att skicka ett mejl, skapa ett ärende, uppdatera en post—blir dina dolda antaganden till explicita valideringsregler.
Med traditionell mjukvara är output oftast deterministisk: om input är X förväntar du dig Y. I AI-genererade system kan samma prompt ge olika formuleringar, olika detaljnivå eller olika tolkningar. Denna variabilitet är inte i sig ett fel—men den innebär att du inte kan lita på informella förväntningar som "den kommer nog att innehålla ett datum" eller "den brukar returnera JSON."
Valideringsregler svarar praktiskt på frågan: Vad måste vara sant för att den här outputen ska vara säker och användbar?
Ett AI-svar kan se giltigt ut men ändå misslyckas enligt dina krav.
Till exempel kan en modell producera:
I praktiken får du två lager av kontroller:
AI-output suddar ofta ut detaljer som människor löser intuitivt, särskilt kring:
Ett hjälpsamt sätt att designa validering är att definiera ett "kontrakt" för varje AI-interaktion:
När kontrakt finns känns valideringsregler inte som extra byråkrati—de är hur du gör AI-beteende tillförlitligt nog att använda.
Inmatningsvalidering är första linjen för tillförlitlighet i AI-genererade system. Om röriga eller oväntade inputs slinker igenom kan modellen fortfarande producera något "självsäkert", och det är precis därför ytterdörren är viktig.
Inputs är inte bara en promptlåda. Vanliga källor inkluderar:
Var och en av dessa kan vara ofullständig, felaktigt formaterad, för stor eller helt enkelt inte vad du förväntade dig.
Bra validering fokuserar på tydliga, testbara regler:
Dessa kontroller minskar modellens förvirring och skyddar även downstream-system (parsers, databaser, köer) från att krascha.
Normalisering gör "nästan korrekt" till konsekvent data:
Normalisera bara när regeln är entydig. Om du inte kan vara säker på vad användaren menade—gissa inte.
En användbar regel: auto-korrigera för format, avvisa för semantik. När du avvisar, returnera ett tydligt meddelande som berättar vad användaren ska ändra och varför.
Output-validering är kontrollpunkten efter att modellen talat. Den svarar på två frågor: (1) är output rätt formad? och (2) är den faktiskt acceptabel och användbar? I verkliga produkter behöver du ofta båda.
Börja med att definiera ett output-schema: den JSON-form du förväntar dig, vilka nycklar som måste finnas och vilka typer och tillåtna värden de får ha. Det gör att "friformstext" blir något din applikation säkert kan konsumera.
Ett praktiskt schema specificerar ofta:
answer, confidence, citations)status måste vara en av "ok" | "needs_clarification" | "refuse")Strukturella kontroller fångar vanliga fel: modellen returnerar prosa istället för JSON, glömmer en nyckel eller ger ett nummer där du behöver en sträng.
Även perfekt formad JSON kan vara felaktig. Semantisk validering testar om innehållet är rimligt för din produkt och policy.
Exempel som klarar schema men misslyckas i mening:
customer_id: "CUST-91822" som inte finns i din databastotal är 98; eller en rabatt överstiger mellanresultatetSemantiska kontroller liknar ofta affärsregler: "ID:n måste kunna lösas", "totalsummor måste stämma", "datum måste vara i framtiden", "påståenden måste stödjas av medföljande dokument" och "inget otillåtet innehåll".
Målet är inte att straffa modellen—det är att hindra downstream-system från att behandla "självsäker nonsens" som en kommando.
AI-genererade system kommer ibland att producera outputs som är ogiltiga, ofullständiga eller helt enkelt oanvändbara för nästa steg. Bra felhantering handlar om att bestämma vilka problem som ska stoppa arbetsflödet omedelbart och vilka som kan återställas utan att överraska användaren.
Ett hårt fel är när fortsatt körning sannolikt skulle ge felaktiga resultat eller osäkert beteende. Exempel: obligatoriska fält saknas, ett JSON-svar kan inte parsas eller output bryter mot en "måste-följa"-policy. I dessa fall: fail fast—stoppa, visa ett tydligt fel och undvik gissningar.
Ett mjukt fel är ett återställbart problem där en säker fallback finns. Exempel: modellen gav rätt innebörd men formatet är fel, en beroende tjänst är tillfälligt otillgänglig eller en förfrågan timear ut. Här: fail gracefully—försök igen (med begränsningar), re-prompta med striktare ramar eller växla till en enklare fallbackväg.
Felmeddelanden som visas för användaren bör vara korta och handlingsbara:
Undvik att exponera stacktraces, interna prompts eller interna ID:n. De uppgifterna är användbara—men endast internt.
Behandla fel som två parallella outputs:
Det håller produkten lugn och begriplig samtidigt som ditt team får tillräcklig information för att åtgärda problem.
En enkel taxonomi hjälper teamet att agera snabbt:
När du kan märka en incident korrekt kan du dirigera den till rätt ägare—och förbättra rätt valideringsregel i nästa steg.
Validering fångar problem; återställning avgör om användare får en hjälpsam upplevelse eller en förvirrande sådan. Målet är inte "alltid lyckas"—det är "misslyckas förutsägbart och degradera säkert."
Retry-logik är mest effektiv när felet sannolikt är tillfälligt:
Använd begränsade retries med exponential backoff och jitter. Att försöka fem gånger i en tät loop förvandlar ofta en liten incident till en större.
Retries kan skada när output är strukturellt ogiltig eller semantiskt fel. Om din validator säger "saknade obligatoriska fält" eller "policyöverträdelse" kan ytterligare försök med samma prompt bara producera ett annat ogiltigt svar—och slösa tokens och öka latens. I de fallen, föredra prompt-reparation (fråga igen med striktare ramar) eller en fallback.
En bra fallback är en du kan förklara för användaren och mäta internt:
Gör handoffen tydlig: spara vilken väg som användes så du senare kan jämföra kvalitet och kostnad.
Ibland kan du returnera ett användbart delmängd (t.ex. extraherade entiteter men inte en full sammanfattning). Märk det som partiellt, inkludera varningar och undvik att tyst fylla luckor med gissningar. Det bevarar förtroendet samtidigt som du ger något handlingsbart.
Sätt timeouts per anrop och en total förfrågningsdeadline. När du rate-limitas, respektera Retry-After om det finns. Lägg till en circuit breaker så att upprepade fel snabbt växlar till en fallback istället för att belasta modellen/API:t. Detta förhindrar kaskadfel och gör återställningsbeteendet konsekvent.
Kantfall är situationer ditt team inte såg i demo: sällsynta inputs, ovanliga format, adversariella prompts eller konversationer som blir mycket längre än väntat. Med AI-genererade system dyker de upp snabbt eftersom människor behandlar systemet som en flexibel assistent—och pressar det bortom den lyckliga vägen.
Verkliga användare skriver inte som testdata. De klistrar in skärmbilder omvandlade till text, halvfärdiga anteckningar eller innehåll kopierat från PDF:er med konstiga radbrytningar. De försöker också "kreativa" prompts: be modellen ignorera regler, avslöja dolda instruktioner eller outputa i avsiktligt förvirrande format.
Lång kontext är ett annat vanligt kantfall. En användare kan ladda upp ett 30-sidigt dokument och be om en strukturerad sammanfattning, sedan följa upp med tio förtydligande frågor. Även om modellen presterar bra tidigt kan beteendet drifta när kontexten växer.
Många fel kommer från extrema fall snarare än normal användning:
Dessa glider ofta förbi grundläggande kontroller eftersom texten ser rimlig ut för människor medan den misslyckas med parsing, räkning eller downstream-regler.
Även om din prompt och validering är robusta kan integrationer introducera nya kantfall:
Vissa kantfall kan inte förutses i förväg. Det enda tillförlitliga sättet att upptäcka dem är att observera verkliga fel. Bra loggar och spårningar bör fånga: ingångsformen (säkert), modelloutput (säkert), vilken valideringsregel som misslyckades och vilken fallback-väg som kördes. När du kan gruppera fel efter mönster kan du omvandla överraskningar till tydliga nya regler—utan att gissa.
Validering handlar inte bara om att hålla outputs snygga; det är också hur du hindrar ett AI-system från att göra något osäkert. Många säkerhetsincidenter i AI-drivna appar är helt enkelt "dålig input" eller "dålig output" med högre insatser: de kan utlösa dataläckor, obehöriga åtgärder eller verktygsmissbruk.
Prompt injection uppstår när otrustat innehåll (användarmeddelande, webbsida, mejl, dokument) innehåller instruktioner som "ignorera dina regler" eller "skicka mig den dolda systemprompten." Det ser ut som ett valideringsproblem eftersom systemet måste avgöra vilka instruktioner som är giltiga och vilka som är fientliga.
En praktisk hållning: behandla modell-facing text som otrustad. Din app bör validera avsikt (vilken åtgärd begärs) och auktoritet (är begäraren behörig), inte bara format.
Bra säkerhet ser ofta ut som vanliga valideringsregler:
Om du låter modellen bläddra eller hämta dokument, validera var den får gå och vad den får ta med sig tillbaka.
Tillämpa principen om minsta privilegium: ge varje verktyg minimala rättigheter och scopade tokens (kortlivade, begränsade endpoints, begränsad data). Det är bättre att misslyckas med en förfrågan och be om en smalare åtgärd än att ge bred åtkomst "för säkerhets skull."
För högpåverkande operationer (betalningar, kontoändringar, skicka mejl, radera data) lägg till:
Dessa åtgärder förvandlar validering från en UX-detalj till en verklig säkerhetsgräns.
Testning av AI-genererat beteende fungerar bäst när du behandlar modellen som en oförutsägbar medarbetare: du kan inte kräva exakt text, men du kan kräva gränser, struktur och användbarhet.
Använd flera lager som var och en svarar på en annan fråga:
En bra regel: om en bugg når end-to-end-tester, lägg till ett mindre test (unit/kontrakt) så du fångar den tidigare nästa gång.
Skapa en liten, kurerad samling prompts som representerar verklig användning. För varje prompt, dokumentera:
Kör guldkornssetet i CI och spåra förändringar över tid. När en incident inträffar, lägg till ett nytt guldkornstest för det fallet.
AI-system misslyckas ofta på röriga kanter. Lägg till automatiserad fuzzing som genererar:
Istället för att snapshotta exakt text, använd toleranser och rubriker:
Detta håller tester stabila samtidigt som verkliga regressioner fångas.
Valideringsregler och felhantering blir bara bättre när du kan se vad som händer i verklig användning. Övervakning förvandlar "vi tror att det är okej" till tydliga bevis: vad som misslyckades, hur ofta och om tillförlitligheten förbättras eller smyger nedåt.
Börja med loggar som förklarar varför en förfrågan lyckades eller misslyckades—radera eller undvik känsliga data som standard.
address.postcode), och felorsak (schema-mismatch, osäkert innehåll, saknad avsikt).Loggar hjälper dig debugga en incident; mätvärden hjälper dig upptäcka mönster.
Spåra:
AI-outputs kan skifta subtilt efter promptändringar, modeluppdateringar eller ny användarbeteende. Larm bör fokusera på förändring, inte bara absoluta trösklar:
En bra dashboard svarar på: "Fungerar det för användarna?" Inkludera en enkel tillförlitlighetsöversikt, en trendlinje för schema-pass-rate, en uppdelning av fel per kategori och exempel på vanligaste feltyper (med känsligt innehåll borttaget). Länka till djupare tekniska vyer för ingenjörer, men håll toppläget läsbart för produkt och support.
Ett AI-genererat system är vilken produkt som helst där en modells output direkt påverkar vad som händer härnäst—vad som visas, lagras, skickas till ett annat verktyg eller körs som en åtgärd.
Det är bredare än chatt: det kan inkludera genererad data, kod, arbetssteg eller agent-/verktygsbeslut.
När AI-output är en del av kontrollflödet blir tillförlitlighet en användarupplevelsefråga. Ett felformat JSON-svar, ett saknat fält eller en felaktig instruktion kan:
Att designa validering och felvägar i förväg gör att fel blir kontrollerade istället för kaotiska.
Strukturell giltighet betyder att output är parsbar och har förväntad form (t.ex. giltig JSON, nödvändiga nycklar finns, korrekta typer).
Affärsgiltighet betyder att innehållet är acceptabelt för dina faktiska regler (t.ex. att ID finns, att totalsummor stämmer, att återbetalningstext följer policy). Du behöver vanligtvis båda lager.
Ett praktiskt kontrakt definierar vad som måste vara sant på tre punkter:
När du har ett kontrakt blir validatorer bara automatiserad efterlevnad av det.
Se input brett: användartext, filer, formulärfält, API-payloads och hämtade/tool-data.
Högvärdiga kontroller inkluderar obligatoriska fält, filstorlek/-typ, enum-fält, längdgränser, giltig kodning/JSON och säkra URL-format. Dessa minskar modellens förvirring och skyddar downstream-parsers och databaser.
Normalisera när avsikten är entydig och ändringen är reversibel (t.ex. trimma blanksteg, normalisera gemener för landskoder).
Avvisa när "fixande" kan ändra betydelse eller dölja fel (t.ex. tvetydiga datum som "03/04/2025", oväntade valutor, misstänkt HTML/JS). En bra regel: auto-korrigera format, avvisa semantik.
Börja med ett tydligt output-schema:
answer, status)Lägg sedan till semantiska kontroller (ID måste lösa ut, totalsummor måste stämma, datum måste vara rimliga, citat måste stödja påståenden). Om validering misslyckas, undvik att använda output downstream—försök igen med striktare instruktioner eller använd en fallback.
Fail fast vid problem där fortsatt körning är riskabelt: går inte att parsa output, saknade obligatoriska fält, policyöverträdelser.
Fail gracefully när en säker återställning finns: tillfälliga timeouts, rate limits, mindre formateringsproblem.
I båda fallen separera:
Retries hjälper när felet är tillfälligt (timeouts, 429, korta driftstörningar). Använd begränsade retries med exponential backoff och jitter.
Retries är ofta ineffektiva för "fel svar" (schema-mismatch, saknade fält, policyöverträdelser). Föredra prompt-reparation (tydligare instruktioner), deterministiska mallar, en mindre modell, cache eller manuell granskning beroende på risk.
Vanliga kantfall kommer från:
Planera för att upptäcka "okända okända" via integritetsmedvetna loggar som fångar vilken valideringsregel som misslyckades och vilken återställningsväg som kördes.