23 sep. 2025·4 min
Välja API-komprimering: ZSTD vs Brotli vs GZIP
Jämför ZSTD, Brotli och GZIP för API:er: hastighet, kompressionsgrad, CPU-kostnad och praktiska standarder för JSON och binära payloads i produktion.
Jämför ZSTD, Brotli och GZIP för API:er: hastighet, kompressionsgrad, CPU-kostnad och praktiska standarder för JSON och binära payloads i produktion.
API-svarskomprimering innebär att din server kodar svarskroppen (ofta JSON) till en mindre byte-ström innan den skickas över nätverket. Klienten (webbläsare, mobilapp, SDK eller en annan tjänst) dekomprimerar sedan den. Över HTTP förhandlas detta via headers som Accept-Encoding (vad klienten stöder) och Content-Encoding (vad servern valde).
Komprimering ger i huvudsak tre fördelar:
Tidskostnaden är enkel: komprimering sparar bandbredd men kräver CPU (komprimera/dekomprimera) och ibland minne (buffrar). Om det är värt det beror på din flaskhals.
Komprimering fungerar särskilt bra när svaren är:
Om du returnerar stora JSON-listor (kataloger, sökresultat, analysdata) är komprimering ofta en enkel och effektiv förbättring.
Komprimering är ofta dålig användning av CPU när svaren är:
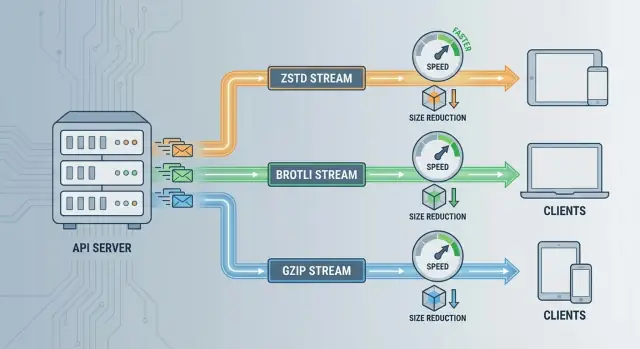
När du väljer mellan ZSTD vs Brotli vs GZIP för API-komprimering handlar det praktiskt sett oftast om:
Allt annat i den här artikeln handlar om att balansera dessa tre för ditt specifika API och trafikmönster.
Alla tre minskar payload-storleken, men de optimerar för olika begränsningar—hastighet, kompressionsgrad och kompatibilitet.
ZSTD-hastighet: Bra när ditt API är känsligt för tail-latens eller dina servrar är CPU-bundna. Den kan komprimera tillräckligt snabbt för att overhead ofta är försumbar jämfört med nätverkstid—särskilt för medelstora till stora JSON-svar.
Brotli-kompressionsgrad: Bäst när bandbredd är huvudbegränsning (mobilklienter, dyr egress, CDN-leverans) och svaren är mest text. Mindre payloads kan vara värda det även om komprimeringen tar längre tid.
GZIP-kompatibilitet: Bäst när du behöver maximal klientstöd med minimal förhandlingsrisk (äldre SDK:er, inbäddade klienter, legacy-proxies). Det är en säker baseline även om det inte är topprestanda.
Kompressionsnivåer är förinställningar som byter CPU-tid mot mindre output:
Dekomprimering är vanligtvis mycket billigare än komprimering för alla tre, men mycket höga nivåer kan fortfarande öka klientens CPU/batteripåverkan—viktigt för mobil.
Komprimering säljs ofta som “mindre svar = snabbare API”. Det är ofta sant på långsamma eller dyra nätverk—men det är inte automatiskt. Om komprimering lägger till tillräckligt med server-CPU-tid kan du få långsammare svar trots färre bytes på tråden.
Det hjälper att separera två kostnader:
En hög kompressionsgrad kan minska överföringstid, men om komprimering lägger till (säg) 15–30 ms CPU per svar kan du förlora mer än du tjänar—särskilt på snabba anslutningar.
Under belastning kan komprimering skada p95/p99-latens mer än p50. När CPU-belastningen ökar köas förfrågningar. Köning förstärker små per-förfrågningskostnader till stora förseningar—medelvärden ser ok ut, men de långsammaste användarna drabbas.
Gissa inte. Kör A/B-test eller stegvis utrullning och jämför:
Testa med realistiska trafikmönster och payloads. "Bästa" kompressionsnivån är den som minskar total tid, inte bara bytes.
Komprimering är inte "gratis"—den flyttar arbete från nätverket till CPU och minne på båda sidor. I API:er syns det som längre hanteringstid per förfrågan, större minnesavtryck och ibland klient-sidiga fördröjningar.
Största CPU-delen läggs på att komprimera svar. Komprimering hittar mönster, bygger state/dictionarier och skriver kodad output.
Dekomprimering är vanligtvis billigare, men fortfarande relevant:
Om ditt API redan är CPU-bundet (tunga app-servrar, dyr auth, komplexa frågor) kan hög kompressionsnivå öka tail-latens även om payloads blir mindre.
Komprimering kan öka minnesanvändning på flera sätt:
I containeriserade miljöer kan högre toppminne leda till fler OOM-killar eller hårdare gränser som minskar densiteten.
Komprimering lägger till CPU-cykler per svar, vilket minskar genomströmning per instans. Det kan trigga autoscaling tidigare och höja kostnader. Ett vanligt mönster: bandbredd minskar, men CPU-kostnaden ökar—så rätt val beror på vilken resurs som är knapp hos er.
På mobil eller lågpresterande enheter konkurrerar dekomprimering med rendering, JavaScript-exekvering och batteriförbrukning. Ett format som sparar några KB men tar längre tid att dekomprimera kan upplevas som långsammare, särskilt när "time to usable data" är viktig.
Zstandard (ZSTD) är ett modernt komprimeringsformat designat för att ge en stark kompressionsgrad utan att sakta ner ditt API. För många JSON-tunga API:er är det en stark "default": tydligt mindre svar än GZIP vid liknande eller lägre latens, plus mycket snabb dekomprimering på klienter.
ZSTD är mest värdefullt när du bryr dig om end-to-end-tid, inte bara minsta antal bytes. Det tenderar att komprimera snabbt och dekomprimera extremt snabbt—nyttigt för API:er där varje millisekund CPU-tid konkurrerar med annan request-hantering.
Det presterar också bra över ett brett spektrum av payloadstorlekar: små till medelstora JSON ser ofta meningsfulla vinster, medan stora svar kan få ännu större förbättringar.
För de flesta API:er, börja med låga nivåer (vanligtvis nivå 1–3). Dessa ger ofta bäst latens/storleks-avvägning.
Använd högre nivåer endast när:
Ett pragmatiskt angreppssätt är en låg global default och sedan selektivt öka nivån för ett fåtal "stora svar"-endpoints.
ZSTD stödjer streaming, vilket kan minska toppminne och börja skicka data tidigare för stora svar.
Dictionary-läge kan ge stor vinst för API:er som returnerar många liknande objekt (upprepade nycklar, stabila scheman). Det är mest effektivt när:
Serversidesstöd är enkelt i många stackar, men klientkompatibilitet kan vara avgörande. Vissa HTTP-klienter, proxys och gateways annonserar eller accepterar inte Content-Encoding: zstd som standard.
Om du servar tredjepartskonsumenter, behåll en fallback (vanligtvis GZIP) och aktivera ZSTD endast när Accept-Encoding tydligt inkluderar det.
Brotli är designat för att pressa text ordentligt. På JSON, HTML och andra "ordiga" payloads slår det ofta GZIP i kompressionsgrad—särskilt på högre nivåer.
Texttunga svar är Brotli:s styrka. Om ditt API skickar stora JSON-dokument (kataloger, sökresultat, konfigurationspaket) kan Brotli minska bytes märkbart, vilket hjälper på långsamma nätverk och kan reducera egresskostnader.
Brotli är också bra när du kan komprimera en gång och servera många gånger (cachebara svar, versionsstyrda resurser). I de fallen kan höga nivåer av Brotli vara värda det eftersom CPU-kostnaden fördelas över många träffar.
För dynamiska API-svar (genereras på varje request) kräver Brotli:s bästa ratio ofta högre nivåer som kan vara CPU-krävande och lägga till latens. När du räknar in komprimeringstid kan den verkliga vinsten över ZSTD (eller en väl-tunad GZIP) bli mindre än väntat.
Det är också mindre lockande för payloads som inte komprimerar väl (redan komprimerat binärt data). I de fallen bränner du bara CPU.
Webbläsare stödjer generellt Brotli väl över HTTPS, vilket förklarar dess popularitet för webbtrafik. För icke-webbläsar-API-klienter (mobila SDK:er, IoT-enheter, äldre HTTP-stackar) kan stödet vara inkonsekvent—förhandla korrekt via Accept-Encoding och behåll en fallback (typiskt GZIP).
Aktivera svarskomprimering när svaren är texttunga (JSON/GraphQL/XML/HTML), medelstora till stora och dina användare finns på långsamma eller dyra nätverk eller när du betalar betydande egresskostnader. Hoppa över komprimering (eller använd hög tröskel) för små svar, redan komprimerad media (JPEG/MP4/ZIP/PDF) och CPU-bundna tjänster där extra arbete per förfrågan försämrar p95/p99-latens.
För att komprimering ska göra en förfrågan snabbare byter den bort bandbredd mot CPU (och ibland minne). Komprimeringstid kan fördröja när servern börjar skicka bytes (TTFB) och under belastning kan det förstärka köbildning—det gör ofta att tail-latens blir sämre även om medelvärdet förbättras. Det bästa inställningen är den som minskar sluttill-sluttid, inte bara payload-storleken.
Ett praktiskt prioriteringsförslag för många API:er är:
zstd först (snabbt, bra ratio)br (ofta minst för text, kan kosta mer CPU)gzip (bredast kompatibilitet)Basera slutgiltigt val på vad klienten annonserar i , och ha alltid en säker fallback (vanligtvis eller ).
Börja lågt och mät.
Använd en minsta svarsstorlek så att du inte slösar CPU på pyttesmå payloads.
Tuna per endpoint genom att jämföra sparade bytes vs tillagd server-tid och påverkan på p50/p95/p99.
Fokusera på innehållstyper som är strukturerade och repetitiva:
Komprimering ska följa HTTP-förhandling:
Accept-Encoding (t.ex. zstd, br, gzip)Content-EncodingOm klienten inte skickar är det säkraste ofta . Returnera aldrig som klienten inte annonserade, annars riskerar du att klienten misslyckas med att läsa kroppen.
Lägg till:
Vary: Accept-EncodingDetta förhindrar att CDN:er/proxies cachar (t.ex.) en gzip-variant och felaktigt skickar den till en klient som inte bad om eller inte kan dekoda gzip (eller zstd/br). Om du stödjer flera encodings är den här headern avgörande för korrekt caching.
Vanliga fel i produktion inkluderar:
Rulla ut det som en prestandafunktion:
Accept-EncodinggzipidentityHögre nivåer ger oftast avtagande marginalnytta i storleksminskning men kan spika CPU och försämra p95/p99.
Ett vanligt tillvägagångssätt är att aktivera komprimering endast för textliknande Content-Type och stänga av det för redan komprimerade format.
Accept-EncodingContent-EncodingContent-Encoding säger gzip men kroppen är inte gzip)Accept-Encoding)Content-Length vid streaming/komprimeringNär du felsöker, fånga råa responsheaders och verifiera dekomprimering med ett känt bra verktyg/klient.
Om tail-latens ökar under belastning, sänk nivån, höj tröskeln eller byt till en snabbare codec (ofta ZSTD).