Vad “lättare att byta ut” betyder i verkliga projekt
"Lättare att byta ut" betyder sällan att man raderar en hel applikation och börjar om. I verkliga team sker byte i olika skala, och vad en "omskrivning" innebär beror på vad du byter ut.
Byta ut vs. skriva om: vad som faktiskt kan vara aktuellt
Ett byte kan vara:
- En modul (fakturaregler, PDF-generering, e-postmallar)
- En tjänst (rekommendations-API, background worker)
- En front-end-yta (en sida, ett funktionsområde eller hela UI:t)
- En fullständig app-omskrivning (sällsynt, dyrt, ibland nödvändigt)
När folk säger att en kodbas är "lättare att skriva om" menar de oftast att du kan starta om en del utan att behöva nysta upp allt annat, hålla verksamheten igång och migrera gradvis.
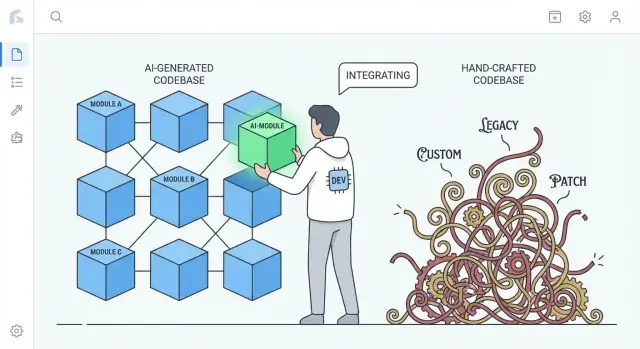
Den verkliga jämförelsen: AI-genererad vs. mycket handbyggd kod
Argumentet är inte "AI-kod är bättre". Det handlar om vanliga tendenser.
- Mycket handbyggd kod kan samla på sig unika mönster, smarta abstraktioner och enskilda "ramverk i appen." Det kan vara utmärkt ingenjörskonst, men det kan också skapa ett privat ekosystem som bara ett fåtal förstår.
- AI-genererad kod lutar ofta mot bekanta standarder: välkända bibliotek, konventionell lagringsstruktur och mönster som liknar många referensprojekt.
Den skillnaden spelar roll vid en omskrivning: kod som följer vedertagna konventioner kan ofta ersättas av en annan konventionell implementation med mindre förhandling och färre överraskningar.
Sätt förväntningar: AI-kod kan vara rörig
AI-genererad kod kan vara inkonsekvent, repetitiv eller dåligt testad. "Lättare att byta ut" är inte ett påstående om att den är renare—det är ett påstående om att den ofta är mindre "speciell". Om ett delsystem är byggt av vanliga ingredienser kan det bytas ut mer som en standarddel än som en specialbyggd maskin som måste reverse-engineeras.
Förhandstitt: varför standardisering sänker bytekostnader
Kärn idén är enkel: standardisering sänker bytekostnaderna. När koden består av igenkännliga mönster och tydliga skarvar kan du regenerera, refaktorera eller skriva om delar utan att vara rädd för att bryta dolda beroenden. Avsnitten nedan visar hur det yttrar sig i struktur, ansvar, tester och daglig ingenjörssnabbhet.
Standardmönster minskar kostnaden för att börja om
En praktisk fördel med AI-genererad kod är att den ofta defaultar till vanliga, igenkännliga mönster: välbekanta mappstrukturer, förutsägbara namn, mainstream-ramverkskonventioner och "läroboks"-metoder för routing, validering, felhantering och dataåtkomst. Även när koden inte är perfekt är den ofta läsbar på samma sätt som många tutorials och startprojekt.
Bekantskap slår originalitet när du måste skriva om
Omskrivningar är dyra till stor del eftersom folk först måste förstå vad som finns. Kod som följer välkända konventioner minskar den tiden. Nya ingenjörer kan koppla det de ser till mentala modeller de redan har: var konfiguration finns, hur förfrågningar flyter, hur beroenden kopplas och var tester bör läggas.
Det gör det snabbare att:
- identifiera skarvar för byte (moduler, tjänster, endpoints)
- replikera beteende i en ny implementation
- jämföra gammalt och nytt sida vid sida utan att översätta mellan stilar
Däremot speglar mycket handbyggda kodbaser ofta en djup personlig stil: unika abstraktioner, egna mini-ramverk, smarta "lim"-lösningar eller domänspecifika mönster som bara är meningsfulla med historiskt sammanhang. Dessa val kan vara eleganta—men de ökar kostnaden för att börja om eftersom en omskrivning först måste återupptäcka författarens synsätt.
Du kan införa konventioner oavsett metod
Det här är ingen magi som bara gäller AI. Team kan (och bör) upprätthålla struktur och stil med templates, linters, formatters och scaffolding-verktyg. Skillnaden är att AI tenderar att vara "generisk som standard," medan människoskrivna system ibland driver mot skräddarsydda lösningar om konventioner inte aktivt bevaras.
Mindre specialbyggt “lim” kan innebära färre dolda beroenden
Mycket av smärtan vid omskrivningar orsakas inte av huvuddelen av affärslogiken. Den orsakas av specialbyggt lim—anpassade hjälpare, hembyggda mikro-ramverk, metaprogrammeringstrick och engångskonventioner som tyst binder ihop allt.
Vad räknas som “bespoke glue”
Bespoke glue är grejer som inte är en del av din produkt, men som produkten ändå inte kan fungera utan. Exempel: en egen dependency injection-container, en hemmagjord routinglayer, en magisk basklass som auto-registrerar modeller, eller hjälpare som muterar globalt tillstånd "för bekvämlighetens skull." Det börjar ofta som en tidsbesparing och blir till slut nödvändig kunskap för varje ändring.
Varför unikt lim ökar koppling (och omskrivningsrisk)
Problemet är inte att lim finns—det är att det blir osynlig koppling. När limmet är unikt för ditt team så:
- Skapas implicita beroenden (saker fungerar bara för att hjälparna körs i viss ordning)
- Antaganden sprids över filer (namngivningskonventioner blir beteenden)
- Gör "enkla" refaktorer riskabla (ändra limmet, bryt allt)
Under en omskrivning är detta lim svårt att reproducera korrekt eftersom reglerna sällan skrivs ner. Du upptäcker dem genom att bryta produktion.
Varför AI-genererad kod tenderar att undvika extrem finess
AI-outputar lutar ofta mot standardbibliotek, vanliga mönster och explicit koppling. Den hittar kanske inte på ett mikro-ramverk när ett enkelt modul- eller serviceobjekt räcker. Den återhållsamheten kan vara en fördel: färre magiska krokar betyder färre dolda beroenden, vilket gör det enklare att dra ut ett delsystem och ersätta det.
Avvägningen: ordentlighet framför finess
Nackdelen är att "plain" kod kan vara mer ordentlig—fler parametrar som skickas runt, mer direkt elektrikerplumbing, färre genvägar. Men ordentlighet är ofta billigare än mysterier. När du bestämmer dig för att skriva om vill du ha kod som är lätt att förstå, lätt att ta bort och svår att misstolka.
Förutsägbar struktur stöder inkrementella omskrivningar
"Förutsägbar struktur" handlar mindre om skönhet och mer om konsekvens: samma mappar, namngivningsregler och förfrågningsflöden återkommer överallt. AI-genererade projekt lutar ofta mot välkända defaults—controllers/, services/, repositories/, models/—med repetitiva CRUD-endpoints och liknande valideringsmönster.
Den uniformiteten är viktig eftersom den förvandlar en omskrivning från ett stup till en trappa.
Hur förutsägbarhet ser ut
Du ser mönster upprepas över funktioner:
- Tydliga mappgränser (API → service → data access)
- Konsekvent namngivning (
UserService, UserRepository, UserController)
- Liknande CRUD-flöde (list → get → create → update → delete)
- Standardiserad form för fel, loggning och request/response-objekt
När varje funktion byggs på samma sätt kan du ersätta en del utan att behöva "lära om" systemet varje gång.
Byta en del i taget
Inkrementella omskrivningar fungerar bäst när du kan isolera en gräns och bygga om bakom den. Förutsägbara strukturer skapar naturligt sådana skarvar: varje lager har ett snävt ansvar och de flesta anrop går genom ett litet antal gränssnitt.
Ett praktiskt tillvägagångssätt är "strangler"-stilen: håll det publika API:t stabilt och byt intern logik gradvis.
Exempel: ersätt dataåtkomstlagret utan att röra API:t
Antag att din app har controllers som kallar en service, och servicen kallar ett repository:
OrdersController → OrdersService → OrdersRepository
Du vill gå från direkta SQL-frågor till en ORM, eller från en databas till en annan. I en förutsägbar kodbas kan förändringen hållas begränsad:
- Skapa
OrdersRepositoryV2 (ny implementation)
- Behåll metodsignaturerna (
getOrder(id), listOrders(filters))
- Byt kopplingen på ett ställe (DI eller fabrik)
- Kör tester och rulla ut funktion-för-funktion
Controller- och servicekoden förblir mestadels opåverkad.
Kontrast: handbyggda arkitekturer
Mycket handbyggda system kan vara utmärkta—men de kodar ofta in unika idéer: egna abstraktioner, smart metaprogrammering eller tvärgående beteenden gömda i basklasser. Det gör att varje ändring kräver djupt historiskt sammanhang. Med förutsägbar struktur är frågan "var ändrar jag detta?" vanligtvis rak, vilket gör små omskrivningar möjliga vecka efter vecka.
Lägre “författar-anknytning” gör radering mer acceptabel
Ett tyst hinder i många omskrivningar är inte tekniskt—det är socialt. Team bär ofta på ägar-risk, där bara en person verkligen förstår hur systemet fungerar. När den personen skrev stora delar för hand börjar koden kännas som ett personligt artefakt: "min design," "min smarta lösning," "min workaround som räddade releasen." Denna anknytning gör radering emotionellt kostsamt, även när det är ekonomiskt rationellt.
AI-genererad kod kan dämpa den effekten. Eftersom utkastet ofta produceras av ett verktyg (och ofta följer bekanta mönster) känns koden mindre som en signatur och mer som en utbytbar implementation. Människor är generellt mer bekväma att säga "Låt oss ersätta denna modul" när det inte känns som att sudda ut någons hantverk—eller utmana deras status i teamet.
Varför detta ändrar omskrivningsbeteende
När författar-anknytningen är lägre tenderar team att:
- Fråga befintlig kod mer fritt ("Är det här fortfarande bästa tillvägagångssättet?")
- Ta bort stora sektioner utan att förhandla om stolthet eller politik
- Välja regenerering eller ersättning tidigare, istället för månader av försiktig lapning
- Sprida kunskap snabbare, eftersom ingen behandlar intern logik som "sitt territorium"
Ett praktiskt notis
Omskrivningsbeslut bör fortfarande drivas av kostnad och mål: leveranstider, risk, underhållbarhet och användarpåverkan. "Det är lätt att radera" är en användbar egenskap—inte en strategi i sig.
Prompts och generationstraces kan fungera som dokumentation
Kör ett pilotprojekt med en utbytbar modul
Bygg en utbytbar funktion i Koder.ai och se hur snabbt du kan byta den säkert.
En underskattad fördel med AI-genererad kod är att inmatningarna till genereringen kan fungera som en levande specifikation. En prompt, en mall och en generator-konfiguration kan beskriva avsikt i klartext: vad funktionen ska göra, vilka begränsningar som gäller (säkerhet, prestanda, stil) och vad "klart" betyder.
Prompts som levande specifikationer
När team använder återanvändbara prompts (eller promptbibliotek) och stabila templates skapar de en revisionsbar historik av beslut som annars vore implicita. En bra prompt kan ange saker som en framtida underhållare annars måste gissa:
- förväntad användarflöde och kantfall
- namngivningskonventioner och mappstruktur
- hur fel ska hanteras och loggas
- vad som måste testas (och vad som kan mockas)
Detta skiljer sig meningsfullt från många handbyggda kodbaser, där viktiga designval sprids över commit-meddelanden, tribal knowledge och små odokumenterade konventioner.
Genereringstraces hjälper dig återproducera beteende
Om du behåller generationstraces (prompt + modell/version + inputs + efterbehandlingssteg) börjar en omskrivning inte från noll. Du kan återanvända samma checklista för att återskapa beteendet under en renare struktur och sedan jämföra output. I praktiken kan detta förvandla en omskrivning till: "regenerera funktion X under nya konventioner, verifiera paritet" snarare än "reverse-engineera vad funktion X egentligen gjorde."
Viktig varning: behandla prompts som kod
Detta fungerar bara om prompts och konfigurationer hanteras med samma disciplin som källkod:
- versionera dem i repot (inte i någons anteckningar)
- kräva granskning för ändringar
- registrera vilken prompt/config som genererade vilka moduler
Utan det blir prompts ännu ett odokumenterat beroende. Med det kan de vara den dokumentation som handbyggda system ofta saknar.
Starka tester förvandlar omskrivningar till rutinuppgifter
"Lättare att byta ut" handlar inte om huruvida koden skrevs av en människa eller ett verktyg. Det handlar om huruvida du kan ändra den med trygghet. En omskrivning blir rutin när tester snabbt och pålitligt säger att beteendet är oförändrat.
AI-genererad kod kan hjälpa här—när du ber om det. Många team ber modeller att generera grundläggande tester tillsammans med funktioner (enklare enhetstester, happy-path integrationstester, enkla mocks). De testerna är inte perfekta, men de skapar ett initialt säkerhetsnät som ofta saknas i handbyggda system där tester skjutits upp.
Prioritera kontraktstester vid skarvar
Om du vill kunna byta ut saker, lägg testfokus på skarvarna där delar möts:
- Externa API:er: requests, responses, felkoder, retries, pagination
- Adaptrar: betalningsleverantörer, e-posttjänster, fil-lagring, köer
- Datamodeller: migrationer, serialisering, valideringsregler
Kontraktstester låser vad som måste vara sant även om du byter ut intern logik. Det innebär att du kan skriva om en modul bakom ett API eller ersätta en adapterimplementation utan att omförhandla affärslogiken.
Använd täckning som kompass, inte trofé
Täckningssiffror kan peka ut riskområden, men att jaga 100% ger ofta sköra tester som hindrar refaktorer. Istället:
- Lägg till tester där fel skulle vara dyra (pengar, dataförlust, användarförtroende)
- Föredra färre, högsignalstester framför många ytliga
- Vid omskrivning, jämför gammal och ny implementation med samma kontraktstester
Med starka tester blir omskrivningar inte hjältedåd utan en serie säkra, reversibla steg.
Vanliga brister i AI-kod är ofta lätta att upptäcka och isolera
Skriv specifikationen först
Gör din prompt till en tydlig plan så att regenerering utgår från avsikt, inte gissningar.
AI-genererad kod tenderar att falla på förutsägbara sätt. Du ser ofta duplicerad logik (samma hjälpare implementerad tre gånger), "nästan samma" grenar som hanterar kantfall olika, eller funktioner som växer genom att modellen lägger till fixar. Det är inte idealiskt—men det har en fördel: problemen är vanligtvis synliga.
Uppenbara fel slår subtila smarta buggar
Handbyggda system kan dölja komplexitet bakom smarta abstraktioner, mikro-optimeringar eller tätt kopplat "så här måste det vara"-beteende. De buggarna är plågsamma eftersom de ser korrekta ut och klarar ytliga granskningar.
AI-kod är mer benägen att vara tydligt inkonsekvent: en parameter ignoreras i en väg, en validering finns i en fil men inte i en annan, eller felhantering skiftar stil varannan funktion. Dessa mismatch syns lätt under granskning och statisk analys, och de är enklare att isolera eftersom de sällan beror på djupa avsiktliga invariants.
Omskrivningskandidater framkommer via upprepning
Upprepning är tecknet. När du ser samma sekvens—parse input → normalize → validate → map → return—över endpoints eller tjänster, har du hittat en naturlig skarv för ersättning. AI löser ofta en ny förfrågan genom att återge en tidigare lösning med små ändringar, vilket skapar kluster av nära-duplikat.
Ett praktiskt tillvägagångssätt är att markera upprepade bitar som kandidater för extraktion eller ersättning, särskilt när:
- Det finns i 3+ ställen med små skillnader
- Skillnaderna främst är kantfallshantering eller felmeddelanden
- Koden saknar tydlig ägare och ständigt patchas
Tumregel: konsolidera upprepningar till en testad modul
Om du kan namnge beteendet i en mening bör det förmodligen vara en enda modul.
Ersätt de upprepade bitarna med en vältestad komponent (utility, delad tjänst eller bibliotekfunktion), skriv tester som låser kantfallen, och ta sedan bort kopiorna. Du har förvandlat många sköra kopior till ett ställe att förbättra—och ett ställe att skriva om senare om det behövs.
Läsbarhet och konsekvens kan väga tyngre än handoptimeringar
AI-genererad kod brukar glänsa när du ber den optimera för tydlighet snarare än finess. Med rätt prompts och lintregler väljer den ofta bekant kontrollflöde, konventionella namn och "tråkiga" moduler framför nyskapande lösningar. Det kan vara en större långsiktig fördel än några procents snabbhetsvinst från handoptimerade trick.
Varför läsbar kod är lättare att skriva om
Omskrivningar lyckas när nya personer snabbt kan bygga en korrekt mental modell av systemet. Läsbar, konsekvent kod minskar tiden det tar att svara på frågor som "Var går en förfrågan in?" och "Vilken form har datan här?" Om varje tjänst följer liknande mönster (layout, felhantering, loggning, konfiguration) kan ett nytt team ersätta en del i taget utan att ständigt återlära lokala konventioner.
Konsekvens minskar också rädsla. När koden är förutsägbar kan ingenjörer ta bort och bygga om delar med förtroende eftersom ytan är lättare att förstå och "blast radien" känns mindre.
Avvägningen med handbyggda prestandahack
Högoptimerad handkod kan vara svår att skriva om eftersom prestandatekniker ofta läcker igenom överallt: egna caching-lager, mikro-optimeringar, hembyggda samtidighetsmönster eller tät koppling till specifika datastrukturer. Dessa val kan vara giltiga, men de skapar ofta subtila begränsningar som inte är uppenbara förrän något går sönder.
Varning: prestanda spelar fortfarande roll—mät den
Läsbarhet är inte en ursäkt för att bli långsam. Målet är att förtjäna prestanda med bevis. Innan en omskrivning, fånga baslinjemått (latenspercentiler, CPU, minne, kostnad). Efter att ha ersatt en komponent, mät igen. Om prestandan försämras, optimera den specifika hot-spotten—utan att förvandla hela kodbasen till ett pussel.
Regenerera vs. refaktorera vs. skriva om: välja rätt återställning
När en AI-assisterad kodbas börjar kännas "off" behöver du inte automatiskt en full omskrivning. Bästa återställningen beror på hur mycket av systemet som är fel kontra bara rörigt.
Tre återställningsalternativ
Regenerera innebär att återskapa en del av koden från en spec eller prompt—ofta från en mall eller ett känt mönster—och sedan återapplicera integrationspunkter (routes, kontrakt, tester). Det är inte "radera allt", utan "bygga om den här biten från en tydligare beskrivning."
Refaktorera behåller beteende men ändrar intern struktur: byt namn, dela upp moduler, förenkla villkor, ta bort duplicering, förbättra tester.
Skriva om ersätter en komponent eller ett system med en ny implementation, vanligtvis för att den nuvarande designen inte kan bli hälsosam utan att man ändrar beteenden, gränser eller dataflöden.
När regenerering passar bra
Regenerering är utmärkt när koden mest är boilerplate och värdet lever i gränssnitten snarare än i smart intern logik:
- CRUD-skärmar och adminpaneler
- API-adaptrar och tunna integrationslager
- scaffolding: routing, serialisers, DTOs, enkel validering, gemensam felhantering
Om specen är tydlig och modulgränsen ren är regenerering ofta snabbare än att reda ut småändringar.
När regenerering är riskabelt (eller misslyckas)
Var försiktig när koden innehåller hårt vunnen domänkunskap eller subtila korrekthetskrav:
- domändrivna affärsregler med många kantfall
- knepig samtidighet (köer, lås, retries, idempotens)
- regelefterlevnad (audit trails, retention, integritet)
I dessa områden kan "nästan rätt" vara dyrt—regenerering kan hjälpa, men bara om du kan bevisa ekvivalens med starka tester och noggrann granskning.
Granskningsportar och små utplaceringar
Behandla regenererad kod som ett nytt beroende: kräva manuell granskning, kör hela testsviten och lägg till riktade tester för problem du sett tidigare. Rulla ut i små skivor—en endpoint, en sida, en adapter—bakom feature-flaggor eller gradvis release om möjligt.
Ett användbart default är: regenerera skalet, refaktorera skarvarna, skriv om bara där antaganden fortsätter att bryta.
Risker och styrning för "replaceable by design"-kod
Håll din arkitektur tråkig
Generera en konventionell struktur som du kan skriva om bit för bit utan att behöva återupptäcka anpassade kopplingar.
"Lätt att byta ut" förblir bara en fördel om team behandlar byte som en ingenjörsaktivitet, inte som en knapp för att starta om. AI-skapade moduler kan bytas ut snabbare—men de kan också gå sönder snabbare om du litar på dem mer än du verifierar dem.
Nyckelrisker att bevaka
AI-genererad kod ser ofta komplett ut även när den inte är det. Det kan skapa falsk trygghet, särskilt när happy-path-demoer fungerar.
En annan risk är saknade kantfall: ovanliga inputs, timeouts, samtidighetsproblem och felhantering som inte omfattades i prompten eller testdata.
Slutligen finns licens/IP-osäkerhet. Även om risken ofta är låg bör team ha en policy för vilka källor och verktyg som är acceptabla och hur proveniens spåras.
Skydd som håller omskrivningar säkra
Sätt byten bakom samma grindar som andra förändringar:
- Kodgranskning med ett uttalat "genererad kod"-perspektiv: tydlighet, felmoder, inputvalidering och loggning.
- Säkerhetskontroller (SAST, dependency scanning, secrets-detektion) och en regel att genererad kod inte får kringgå dem.
- Beroendepolicyer: föredra få, välkända bibliotek; pinna versioner; undvik att dra in ett nytt ramverk bara för att en prompt föreslog det.
- Revisionsspår: spara prompts, modell-/verktygs-versioner och genereringsanteckningar i repot så ändringar kan förklaras senare.
Dokumentera gränser innan byte
Innan du ersätter en komponent, skriv ner dess gräns och invariants: vilka inputs den accepterar, vad den garanterar, vad den aldrig får göra (t.ex. "får aldrig radera kunddata") och förväntningar på prestanda/latens. Detta kontrakt är vad du testar mot—oavsett vem (eller vad) som skriver koden.
En lätt checklista
- Definiera modulkontrakt (in/ut, invariants).
- Lägg till/bekräfta tester för kantfall.
- Kör säkerhets- och beroendeskanningar.
- Granska för läsbarhet och felhantering.
- Spela in prompt/tool-metadata.
- Skicka bakom flagga och övervaka.
Praktiska slutsatser och en enkel plan för nästa steg
AI-genererad kod är ofta lättare att skriva om eftersom den tenderar att följa bekanta mönster, undvika djup "hantverks-personalisering" och vara snabbare att regenerera när krav ändras. Den förutsägbarheten minskar de sociala och tekniska kostnaderna för att ta bort och ersätta delar av systemet.
Målet är inte att "slänga kod," utan att göra byte till ett normalt, lågfriktionsalternativ—stödd av kontrakt och tester.
Åtgärder du kan genomföra den här veckan
Börja med att standardisera konventioner så att all regenererad eller omskriven kod följer samma mall:
- Säkra konventioner: formatering, mappstruktur, namngivning, felhantering och API-form. Skriv ner dem i en kort CONTRIBUTING.md.
- Lägg till kontraktstester vid gränser: fokusera på in/ut för moduler och tjänster (HTTP-endpoints, kö-meddelanden, DB-lager). Dessa tester ska passera även om implementationen byts.
- Spåra prompts och specs: spara prompts, kravanteckningar och genereringstraces tillsammans med koden så framtida omskrivningar kan reproducera avsikt, inte bara text.
Om du använder en vibe-coding-workflow, sök verktyg som gör dessa rutiner enkla: att spara "planeringsläge"-specs tillsammans med repot, fånga generationstraces och stöd för säker rollback. Till exempel är Koder.ai designat kring chattdriven generering med snapshots och rollback, vilket passar en "replaceable by design"-metod—regenerera en skiva, behåll kontraktet stabilt och återställ snabbt om paritetstester misslyckas.
Kör ett litet pilotprojekt för en "utbytbar modul"
Välj en modul som är viktig men säkert isolerad—rapportgenerering, notifieringsleverans eller ett enda CRUD-område. Definiera dess publika gränssnitt, lägg till kontraktstester, och tillåt dig att regenerera/refaktorera/skriva om intern logik tills den är tråkig. Mät cykeltid, felfrekvens och granskningsarbete; använd resultaten för att sätta teamregler.
För att operationalisera detta, håll en checklista i ditt interna playbook (eller dela via /blog) och gör "kontrakt + konventioner + traces" till ett krav för nytt arbete. Om du utvärderar verktygsstöd kan du också dokumentera vad du behöver från en lösning innan du tittar på /pricing.