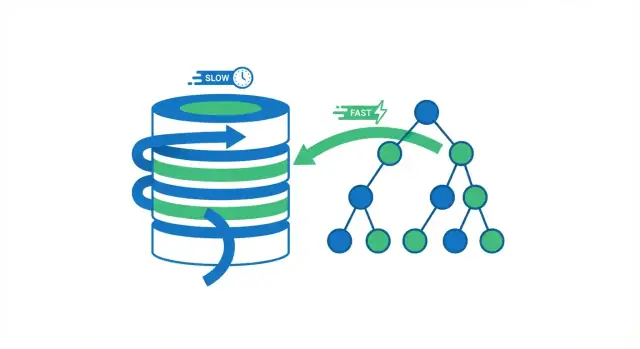
Vad databasindexering egentligen gör
Ett databasindex är en separat uppslagsstruktur som hjälper databasen att hitta rader snabbare. Det är inte en andra kopia av din tabell. Tänk på det som indexsidorna i en bok: du använder indexet för att hoppa nära rätt plats, och läser sedan den exakta sidan (raden) du behöver.
Utan index har databasen ofta bara ett säkert alternativ: läsa igenom många rader för att kontrollera vilka som matchar din fråga. Det kan vara okej när en tabell har några tusen rader. När tabellen växer till miljoner rader blir “kolla fler rader” fler diskläsningar, mer minnespress och mer CPU-arbete — så samma fråga som brukade kännas omedelbar börjar bli långsam.
Vad ett index ändrar (och vad det inte gör)
Index minskar mängden data databasen måste undersöka för att svara på frågor som “hitta ordern med ID 123” eller “hämta användare med den här e-posten.” Istället för att skanna allt följer databasen en kompakt struktur som snabbt begränsar sökningen.
Men indexering är inte en universallösning. Vissa frågor måste fortfarande bearbeta många rader (stora rapporter, filter med låg selektivitet, tunga aggregationer). Och index har verkliga kostnader: extra lagring och långsammare skrivningar, eftersom insert och update också måste uppdatera indexet.
Vad du lär dig i den här guiden
Du får se:
- varför undvikande av fullständiga tabellgenomsökningar är den stora hastighetsvinsten
- hur vanliga indexstrukturer (som B-träd) gör uppslag snabba
- vilka frågor som gynnas mest, och när de inte gör det
- hur du väljer komposit-/täckande index och validerar dem med en EXPLAIN-plan
- hur du underhåller index över tid så att prestandan inte tyst försämras
Kärnvinst: undvik fullständiga tabellgenomsökningar
När en databas kör en fråga har den två breda alternativ: skanna hela tabellen rad för rad, eller hoppa direkt till de rader som matchar. De flesta indexvinster kommer från att undvika onödiga läsningar.
Fullständig tabellgenomsökning vs. indexuppslag
En fullständig tabellgenomsökning är precis vad det låter som: databasen läser varje rad, kontrollerar om den matchar WHERE-villkoret och returnerar först därefter resultat. Det är acceptabelt för små tabeller, men blir långsammare på ett förutsägbart sätt när tabellen växer — fler rader betyder mer arbete.
Med ett index kan databasen ofta undvika att läsa de flesta rader. Istället konsulterar den först indexet (en kompakt struktur byggd för sökning) för att hitta var de matchande raderna finns, och läser sedan bara de specifika raderna.
En enkel analogi
Tänk på en bok. Om du vill ha varje sida som nämner “fotosyntes” kan du läsa hela boken från pärm till pärm (full skanning). Eller så kan du använda bokens index, hoppa till de listade sidorna och läsa bara de avsnitten (indexuppslag). Den andra metoden är snabbare eftersom du hoppar över nästan alla sidor.
Varför färre läsningar oftast betyder snabbare frågor
Databaser spenderar mycket tid på att vänta på läsningar — särskilt när data inte redan finns i minnet. Att minska antalet rader (och sidor) som databasen måste röra vid reducerar vanligtvis:
- disk-/SSD-läsningar
- CPU-tid för att utvärdera filter
- minnespress från att dra in onödig data i cache
När hastighetsvinsten syns
Indexering hjälper mest när data är stor och frågemönstret är selektivt (till exempel att hämta 20 matchande rader av 10 miljoner). Om din fråga ändå returnerar de flesta raderna, eller tabellen är liten nog att rymmas bekvämt i minnet, kan en fullständig skanning vara lika snabb — eller snabbare.
Hur indexstrukturer gör uppslag snabba
Index fungerar eftersom de organiserar värden så att databasen kan hoppa nära det du vill ha istället för att kontrollera varje rad.
B-trädindex: standardverktyget
Den vanligaste indexstrukturen i SQL-databaser är B-träd (skrivs ofta “B-tree” eller “B+tree”). Konceptuellt:
- värden hålls sorterade
- indexet är uppdelat i sidor (bitar) som pekar mot andra sidor, och slutligen mot matchande tabellrader
Eftersom det är sorterat är ett B-träd utmärkt för både likhetsuppslag (WHERE email = ...) och range-frågor (WHERE created_at >= ... AND created_at < ...). Databasen kan navigera till rätt område av värden och sedan skanna framåt i ordning.
Vad “logaritmisk” betyder (utan matematiken)
Man säger att B-träduppslag är “logaritmiska.” Praktiskt innebär det detta: när din tabell växer från tusentals till miljontals rader så ökar antalet steg för att hitta ett värde långsamt, inte proportionellt.
Istället för “dubbel data betyder dubbelt arbete” är det mer som “mycket mer data betyder bara några extra navigeringssteg,” eftersom databasen följer pekare genom ett litet antal nivåer i trädet.
Hash-index: snabbt för exakta träffar (med begränsningar)
Vissa motorer erbjuder också hash-index. Dessa kan vara mycket snabba för exakta likhetskontroller eftersom värdet transformeras till en hash och används för att hitta posten direkt.
Tricket: hash-index hjälper vanligtvis inte för ranges eller ordnade genomsökningar, och tillgänglighet/beteende skiljer mellan databaser.
Motor-specifika detaljer skiljer sig, idén består
PostgreSQL, MySQL/InnoDB, SQL Server och andra lagrar och använder index olika (sidorstorlek, clustering, inkluderade kolumner, visibility checks). Men kärnkonceptet är detsamma: index skapar en kompakt, navigerbar struktur som låter databasen lokalisera matchande rader med mycket mindre arbete än att skanna hela tabellen.
Frågor som gynnas mest av index
Index snabbar inte upp “SQL” i allmänhet — de snabbar upp specifika åtkomstmönster. När ett index matchar hur din fråga filtrerar, joinar eller sorterar kan databasen hoppa direkt till relevanta rader istället för att läsa hela tabellen.
De mest indexvänliga frågemönstren
1) WHERE-filter (särskilt på selektiva kolumner)
Om din fråga ofta krymper en stor tabell till ett litet antal rader är ett index oftast den första platsen att titta. Ett klassiskt exempel är att leta upp en användare via ett identifierare.
Utan ett index på users.email kan databasen behöva skanna varje rad:
SELECT * FROM users WHERE email = '[email protected]';
Med ett index på email kan den lokalisera matchande rad(er) snabbt och sluta.
2) JOIN-nycklar (foreign keys och refererade nycklar)
Joins är där “små ineffektiviteter” blir stora kostnader. Om du joinar orders.user_id mot users.id hjälper indexering av join-kolumnerna (vanligtvis orders.user_id och primärnyckeln users.id) databasen att matcha rader utan upprepad skanning.
3) ORDER BY (när du vill ha resultat redan sorterade)
Sortering är dyrt när databasen måste samla många rader och sortera dem i efterhand. Om du ofta kör:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
kan ett index som linjerar upp user_id och sortkolumnen låta motorn läsa rader i önskad ordning istället för att sortera ett stort mellanresultat.
4) GROUP BY (när gruppering stämmer överens med ett index)
Gruppering kan gynnas när databasen kan läsa data i grupperad ordning. Det är ingen garanti, men om du ofta grupperar efter en kolumn som också används för filtrering (eller som naturligt är klustrad i indexet) kan motorn göra mindre arbete.
Range-filter: en vanlig B-träd-vinst
B-träd-index är särskilt bra för range-villkor — tänk datum, priser och “mellan”-frågor:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
För dashboards, rapporter och vyer med “senaste aktivitet” är detta mönster vanligt, och ett index på range-kolumnen ger ofta omedelbar förbättring.
Temat är enkelt: index hjälper mest när de speglar hur du söker och sorterar. Om dina frågor stämmer överens med dessa åtkomstmönster kan databasen göra riktade läsningar istället för breda skanningar.
Selektivitet: varför vissa index inte hjälper
Ett index hjälper mest när det tydligt krymper hur många rader databasen måste röra vid. Den egenskapen kallas selektivitet.
Vad selektivitet betyder i praktiken
Selektivitet är i princip: hur många rader matchar ett givet värde? En högselektiv kolumn har många distinkta värden, så varje uppslag matchar få rader.
- Hög selektivitet:
email, user_id, order_number (ofta unika eller nära unika)
- Låg selektivitet:
is_active, is_deleted, status med några vanliga värden
Med hög selektivitet kan ett index hoppa direkt till en liten mängd rader. Med låg selektivitet pekar indexet på en stor del av tabellen — så databasen måste ändå läsa och filtrera mycket.
Varför boolean-index ofta är besvikelse
Tänk dig en tabell med 10 miljoner rader och en kolumn is_deleted där 98% är false. Ett index på is_deleted sparar inte mycket för:
SELECT * FROM orders WHERE is_deleted = false;
Matchmängden är fortfarande nästan hela tabellen. Att använda indexet kan till och med vara långsammare än en sekventiell skanning eftersom motorn gör extra hopp mellan indexposter och tabellsidor.
Varför databasen kan ignorera ditt index
Frågeplanerare uppskattar kostnader. Om ett index inte minskar arbetet tillräckligt — eftersom för många rader matchar, eller för att frågan behöver de flesta kolumner — kan den välja en fullständig tabellgenomsökning.
Selektivitet ändras över tid
Datadistribution är inte statisk. En status-kolumn kan börja jämnt fördelad och sedan driva så att ett värde dominerar. Om statistiken inte uppdateras kan planläggaren fatta dåliga beslut, och ett index som tidigare hjälpte slutar kanske att vara lönsamt.
Komposit- och täckande index (och kolumnordning)
Enkolumnsindex är en bra start, men många verkliga frågor filtrerar på en kolumn och sorterar eller filtrerar på en annan. Där glänser kompositindex: ett index kan täcka flera delar av frågan.
Kolumnordning: vänster-till-höger-regeln
De flesta databaser (särskilt med B-träd) kan bara använda ett kompositindex effektivt från de vänsterställda kolumnerna framåt. Tänk på indexet som sorterat först efter kolumn A, sedan inom det efter kolumn B, osv.
Det innebär:
- ett index på (account_id, created_at) är perfekt för frågor som filtrerar på
account_id och sedan sorterar eller filtrerar på created_at
- samma index hjälper vanligtvis inte för en fråga som bara filtrerar på
created_at (eftersom det inte är vänsterkolumn)
Ett praktiskt mönster: tidslinjer per konto
Ett vanligt arbetsflöde är “visa de senaste händelserna för detta konto.” Detta frågemönster:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
gynnar ofta enormt av:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
Databasen kan hoppa direkt till ett kontos del av indexet och läsa rader i tidsordning, istället för att skanna och sortera en stor mängd.
Täckande index: när indexet är svaret
Ett täckande index innehåller alla kolumner frågan behöver, så databasen kan returnera resultat från indexet utan att slå upp tabellraderna (färre läsningar, mindre slumpmässig I/O).
Var försiktig: att lägga till extra kolumner kan göra ett index stort och dyrt.
Bygg inte breda kompositer “för säkerhets skull”
Breda kompositindex kan sakta ner skrivningar och använda mycket lagring. Lägg till dem bara för specifika högvärdesfrågor, och verifiera med en EXPLAIN-plan och verkliga mätningar före och efter.
Index beskrivs ofta som “gratis snabbhet”, men de är inte gratis. Indexstruktur måste underhållas varje gång den underliggande tabellen ändras, och de förbrukar verkliga resurser.
Långsammare INSERT/UPDATE/DELETE (eftersom varje index måste uppdateras)
När du INSERT-ar en ny rad skriver databasen inte bara raden en gång — den lägger också till motsvarande poster i varje index på tabellen. Detsamma gäller för DELETE och många UPDATE-operationer.
Detta är anledningen till att “fler index” kan märkbart sakta ner skrivintensiva arbetsflöden. En UPDATE som rör en indexerad kolumn kan vara särskilt dyr: databasen kan behöva ta bort den gamla indexposten och lägga till en ny (och i vissa motorer kan detta trigga extra siduppdelningar eller intern ombalansering). Om din applikation gör mycket skrivningar — orderhändelser, sensordata, auditloggar — kan indexera allt göra databasen trög även om läsningar är snabba.
Varje index tar diskutrymme. På stora tabeller kan index konkurrera med (eller överträffa) tabellens storlek, särskilt om du har flera överlappande index.
Det påverkar också minnet. Databaser förlitar sig mycket på cache; om din arbetsmängd inkluderar flera stora index måste cachen hålla fler sidor för att förbli snabb. Annars ser du mer disk‑I/O och mindre förutsägbar prestanda.
Praktisk balans
Indexering handlar om att välja vad som ska accelereras. Om din arbetsbelastning är lästung kan fler index vara värt det. Om den är skrivtung, prioritera index som stödjer dina viktigaste frågor och undvik dubbletter. En användbar regel: lägg till ett index bara när du kan namnge frågan det hjälper — och verifiera att läs‑hastighetsvinsten väger upp för skriv‑ och underhållskostnaden.
Hur du bevisar att ett index hjälper: EXPLAIN och mätningar
Att lägga till ett index verkar som det borde hjälpa — men du kan (och bör) verifiera det. De två verktygen som gör detta konkret är frågeplanen (EXPLAIN) och verkliga före-/efter-mätningar.
Läs planen: används indexet verkligen?
Kör EXPLAIN (eller EXPLAIN ANALYZE) på den exakta frågan du bryr dig om.
- Skantyp: En Seq Scan / Full Table Scan betyder att databasen läser hela tabellen. En Index Scan / Index Seek (eller Index Range Scan) antyder att den använder ett index för att begränsa rader.
- Beräknade vs. faktiska rader (särskilt i
EXPLAIN ANALYZE): Om planen beräknade 100 rader men faktiskt rörde 100 000, gjorde optimeraren en dålig gissning — ofta för att statistiken är inaktuell eller filtret är mindre selektivt än väntat.
- Sortsteg: Om du ser en explicit Sort-operation sorterar databasen resultat efter att ha hämtat dem. Om ett nytt index matchar
ORDER BY kan den sorteringen försvinna, vilket kan ge stor vinst.
Mät korrekt: före/efter, under samma förhållanden
Benchmärk frågan med samma parametrar, på representativ datamängd, och fånga både latency och rader som skannats.
Var försiktig med caching: första körningen kan vara långsammare eftersom data inte är i minnet; upprepade körningar kan verka “fixade” även utan index. För att inte lura dig själv, jämför flera körningar och fokusera på om planen ändras (index används, färre rader lästa) utöver rå tid.
Om EXPLAIN ANALYZE visar färre rader rörda och färre kostsamma steg (som sortering), har du bevisat att indexet hjälper — inte bara hoppats att det gör det.
Vanliga misstag som slår ut indexvinster
Du kan lägga till “rätt” index och ändå inte se någon förbättring om frågan är skriven så att databasen inte kan använda det. Dessa problem är ofta subtila, eftersom frågan fortfarande returnerar korrekta resultat — den tvingas bara till en långsammare plan.
Anti‑mönster som blockerar indexanvändning
1) Ledande wildcard
När du skriver:
WHERE name LIKE '%term'
kan databasen inte använda ett vanligt B-trädindex för att hoppa till rätt startpunkt, eftersom den inte vet var i det sorterade ordet “%term” börjar. Den faller ofta tillbaka till att skanna många rader.
Alternativ:
- Använd prefixsökning om möjligt:
WHERE name LIKE 'term%'.
- Om du verkligen behöver “innehåller”-sökning, överväg en specialiserad indextyp (t.ex. fulltext/trigram) i stället för att förvänta dig att ett standardindex hjälper.
2) Funktioner på indexerade kolumner
Det här ser oskyldigt ut:
WHERE LOWER(email) = '[email protected]'
Men LOWER(email) ändrar uttrycket, så indexet på email kan inte användas direkt.
Alternativ:
- Spara normaliserad data (t.ex. gemener för e-post) och fråga
WHERE email = ....
- Eller skapa ett uttrycks-/funktion‑index (beroende på databas) specifikt för
LOWER(email).
Dolda indexblockerare folk missar
Implicit typomvandling: Jämförelse mellan olika datatyper kan tvinga databasen att kasta ena sidan, vilket kan inaktivera ett index. Exempel: jämföra en integer-kolumn med en strängliteral.
Mismatcher i kollation/encoding: Om jämförelsen använder en annan kollation än indexet byggdes med (vanligt vid textkolumner över olika lokaler) kan optimeraren undvika indexet.
Snabbchecklista: "Varför används inte mitt index?"
- Börjar villkoret med en wildcard (
LIKE '%x')?
- Använder du en funktion på den indexerade kolumnen (
LOWER(col), DATE(col), CAST(col))?
- Är typerna identiska på båda sidor (inga implicita kast)?
- Är kollation/locale konsekventa för jämförelsen?
- Är predikatet tillräckligt selektivt (matchar det inte en stor del av tabellen)?
- Filtrerar/sorterar du på de vänsterställda kolumnerna i ett kompositindex?
- Har du kollat planen med
EXPLAIN för att bekräfta vad databasen faktiskt valde?
Indexunderhåll: statistik, bloat och långsiktig hälsa
Index är inte “ställ in och glöm.” Med tiden förändras data, frågemönster skiftar och den fysiska formen av tabeller och index driver isär. Ett välvalt index kan långsamt bli mindre effektivt — eller till och med skadligt — om du inte underhåller det.
Statistik: planerarens karta kan bli inaktuell
De flesta databaser använder en frågeplanerare (optimizer) för att välja hur en fråga ska köras: vilket index att använda, vilken join‑ordning som är bäst, och om ett indexuppslag är värt det. För att fatta dessa beslut använder planaren statistik — sammanfattningar om värdefördelningar, antal rader och snedfördelning.
När statistiken är inaktuell kan planerarens raduppskattningar vara helt fel. Det leder till dåliga planval, som att välja ett index som returnerar långt fler rader än väntat eller att hoppa över ett index som hade varit snabbare.
Lösning: schemalägg regelbundna uppdateringar av statistik (ofta kallat “ANALYZE” eller liknande). Efter stora dataimporter, stora borttagningar eller mycket churn, uppdatera statistiken tidigare.
Bloat och fragmentering: när strukturer blir röriga
När rader insertas, uppdateras och tas bort kan index samla på sig bloat (extra sidor som inte längre innehåller användbar data) och fragmentering (data spridd på ett sätt som ökar I/O). Resultatet är större index, fler läsningar och långsammare genomsökningar — särskilt för range-frågor.
Rutinåtgärd: bygg om eller reorganisera tunga index när de vuxit oproportionerligt eller när prestanda försämrats. Exakt verktyg och påverkan skiljer sig åt mellan databaser, så behandla detta som en mätt operation, inte en generell regel.
Övervaka över tid, inte bara en gång
Sätt upp övervakning för:
- långsamma frågor (latency, frekvens och värsta fall)
- indexanvändning (index som aldrig används vs. "heta" index)
- indexstorlekstillväxt och plötsliga planförändringar
Den feedback-loopen hjälper dig fånga när underhåll behövs — och när ett index bör justeras eller tas bort. För mer om att validera förbättringar, se /blog/how-to-prove-an-index-helps-explain-and-measurements.
Ett praktiskt arbetsflöde för att lägga till rätt index
Att lägga till ett index bör vara en genomtänkt förändring, inte en gissning. Ett lättviktigt arbetsflöde håller dig fokuserad på mätbara vinster och förhindrar “indexsprawl.”
1) Identifiera den verkliga problemfrågan
Börja med bevis: loggar för långsamma frågor, APM-spår eller användarrapporter. Välj en fråga som både är långsam och frekvent — en sällsynt 10‑sekundersrapport betyder mindre än en vanlig 200 ms-uppslagning.
Fånga den exakta SQL och parameter-mönstret (till exempel: WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Små skillnader förändrar vilket index som hjälper.
2) Mät en baseline
Spela in aktuell latency (p50/p95), rader som skannats och CPU/IO-påverkan. Spara den nuvarande planoutputen (t.ex. EXPLAIN / EXPLAIN ANALYZE) så du kan jämföra senare.
3) Designa det minsta användbara indexet
Välj kolumner som matchar hur frågan filtrerar och sorterar. Föredra minimalt index som får planen att sluta skanna stora områden.
Testa i staging med produktionslik volym. Index kan se bra ut på små dataset och bli besvikelse i skala.
4) Skapa det säkert
På stora tabeller, använd online‑alternativ där det stöds (t.ex. PostgreSQL CREATE INDEX CONCURRENTLY). Schemalägg ändringar under lägre trafik om din databas kan låsa skrivningar.
5) Validera med före/efter-bevis
Kör om samma fråga och jämför:
- planens form (bytte den från full skanning till indexåtkomst?)
- exekveringstid och antal skannade rader
- påverkan på skrivningar (insert/update-latency)
6) Ha en återställningsplan
Om indexet ökar skrivkostnad eller blåser upp minnet, ta bort det ordentligt (t.ex. DROP INDEX CONCURRENTLY där det finns). Håll migrationen reversibel.
7) Dokumentera “varför”
I migrationen eller schemanoteringarna: skriv vilken fråga indexet tjänar och vilken mätning som förbättrades. Framtida du (eller en kollega) vet då varför det finns och när det är säkert att ta bort.
Var Koder.ai passar in i detta arbetsflöde
Om du bygger en ny tjänst och vill undvika “indexsprawl” tidigt kan Koder.ai hjälpa dig iterera snabbare genom hela loopen ovan: generera en React + Go + PostgreSQL-app från chatten, justera schema/index-migrationer när krav ändras, och exportera källkoden när du är redo att ta över manuellt. I praktiken gör det enklare att gå från “det här endpointet är långsamt” till “här är EXPLAIN-planen, det minimala indexet och en reversibel migration” utan att vänta på en fullständig traditionell pipeline.
När indexering inte räcker (och vad du gör härnäst)
Index är en stor hävstång, men inte en magisk "gör allt snabbt"-knapp. Ibland händer det långsamma i en förfrågan efter att databasen hittat rätt rader — eller ditt frågemönster gör indexering till fel första steg.
Fall där index inte är bästa åtgärden
Om din fråga redan använder ett bra index men ändå känns långsam, leta efter dessa vanliga orsaker:
- Saknad (eller felaktig) paginering: Att hämta sida 1000 med
OFFSET 999000 kan vara långsamt även med index. Föredra keyset-paginering (t.ex. “ge mig rader efter sista sedda id/timestamp”).
- Returnerar för mycket data: Att välja breda rader (
SELECT *) eller returnera tiotusentals poster kan bli en flaskhals i nätverk, JSON-serialisering eller applikationsbearbetning.
- Schemat mismatcher: Över-normaliserade joins, lagra sökbara värden i JSON/text-blobs, eller använda fel datatyper kan tvinga dyra operationer som index inte kan maskera helt.
Kompletterande optimeringar som ofta betyder mer
- Skriv om frågan: Ta bort onödiga joins, undvik funktioner på indexerade kolumner i WHERE-satser och förenkla OR‑tunga predikat.
- Begränsa kolumner och rader: Välj bara det du behöver, lägg till vettiga
LIMIT och sidindela med eftertanke.
- Caching: Cachade heta läsningar på applikationsnivå eller read-through cache för dyra, upprepade frågor.
- Partitionering: Om de flesta frågor träffar “senaste data”, partitionera efter tid (eller annan naturlig gräns) för att krympa sökutrymmet.
Om du vill ha en djupare metod för att diagnostisera flaskhalsar, kombinera detta med arbetsflödet i /blog/how-to-prove-an-index-helps.
Prioritera: åtgärda den största flaskhalsen först
Gissa inte. Mät var tiden spenderas (databasexekvering vs. rader som returneras vs. applikationskod). Om databasen är snabb men API:et är långsamt hjälper fler index inte.
Snabbchecklista