26 nov. 2025·8 min
Varför grafdatabaser briljerar på relationer — inte allt
Grafdatabaser är utmärkta när kopplingar driver dina frågor. Lär dig bästa användningsområden, avvägningar och när relations- eller dokumentdatabaser passar bättre.
Grafdatabaser är utmärkta när kopplingar driver dina frågor. Lär dig bästa användningsområden, avvägningar och när relations- eller dokumentdatabaser passar bättre.
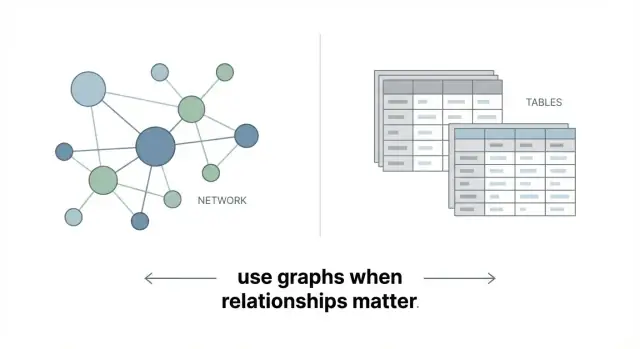
En grafdatabas lagrar data som ett nätverk i stället för som en uppsättning tabeller. Kärn-idén är enkel:
Det är allt: en grafdatabas är byggd för att direkt representera sammanlänkad data.
I en grafdatabas är relationer inte en eftertanke — de sparas som verkliga, frågbara objekt. En relation kan ha egna egenskaper (till exempel kan en KÖPTE-relation lagra datum, kanal och rabatt), och du kan traversera från en nod till nästa effektivt.
Det här spelar roll eftersom många affärsfrågor naturligt handlar om stigar och kopplingar: “Vem är kopplad till vem?”, “Hur många steg bort är den här entiteten?” eller “Vilka gemensamma länkar finns mellan dessa två saker?”
Relationsdatabaser är utmärkta för strukturerade poster: kunder, order, fakturor. Relationer finns där också, men representeras oftast indirekt via foreign keys, och att koppla flera hopp innebär ofta att skriva JOINs över flera tabeller.
Grafer håller kopplingarna intill datan, så att utforska flerstegsrelationer tenderar att vara enklare att modellera och fråga.
Grafdatabaser är fantastiska när relationerna är huvudpoängen — rekommendationer, bedrägeriringar, beroendekartor, knowledge graphs. De är inte automatiskt bättre för enkel rapportering, summeringar eller starkt tabulära arbetsbelastningar. Målet är inte att ersätta alla databaser, utan att använda graf där konnektivitet driver värdet.
De flesta affärsfrågor handlar inte om enstaka poster — de handlar om hur saker är kopplade.
En kund är inte bara en rad; hen är länkad till order, enheter, adresser, supportärenden, hänvisningar och ibland andra kunder. En transaktion är inte bara en händelse; den är kopplad till en handlar, en betalningsmetod, en plats, ett tidsfönster och en kedja av relaterad aktivitet. När frågan är “vem/vad är kopplat till vad, och hur?”, blir relationsdata huvudpersonen.
Grafdatabaser är designade för traverseringar: du börjar vid en nod och “går” i nätverket genom att följa kanter.
I stället för att ständigt göra JOINs uttrycker du vägen du bryr dig om: Kund → Enhet → Inloggning → IP-adress → Andra kunder. Denna steg-för-steg-ram stämmer överens med hur människor naturligt undersöker bedrägerier, spårar beroenden eller förklarar rekommendationer.
Skillnaden syns tydligt när du behöver flera hopp (två, tre, fem steg bort) och du inte vet i förväg var de intressanta kopplingarna dyker upp.
I en relationsmodell blir flerstegsfrågor ofta långa kedjor av JOINs plus extra logik för att undvika dupliceringar och kontrollera stiglängd. I en graf är “hitta alla vägar upp till N hopp” ett normalt, läsbart mönster — särskilt i property graph-modellen som många grafdatabaser använder.
Kanter är inte bara linjer; de kan bära data:
De egenskaperna låter dig ställa bättre frågor: “kopplade inom de senaste 30 dagarna”, “starkaste band”, eller “vägar som inkluderar högrisktransaktioner” — utan att tvinga allt in i separata uppslagstabeller.
Grafdatabaser glänser när dina frågor beror på sammanlänkning: “vem är kopplat till vem, genom vad och hur många steg bort?” Om värdet i din data bor i relationsdata (inte bara rader med attribut) kan en grafmodell göra både datamodellering och frågeställning mer naturligt.
Allt som formas som ett nätverk — vänner, följare, kollegor, team, hänvisningar — kartläggs enkelt med noder och relationer. Typiska frågor är “gemensamma kontakter”, “kortaste vägen till en person” eller “vem förbinder dessa två grupper?” Dessa frågor blir ofta klumpiga (eller långsamma) när de pressas in i många join-tabeller.
Rekommendationsmotorer bygger ofta på flerstegs-kopplingar: användare → objekt → kategori → liknande objekt → andra användare. Grafdatabaser passar bra för “personer som gillade X gillade också Y”, “objekt som ofta ses ihop” och “hitta produkter kopplade genom delade attribut eller beteenden”. Detta är särskilt användbart när signalerna är mångsidiga och du lägger till nya relationstyper över tid.
Bedrägerigrafer fungerar bra eftersom misstänkt beteende sällan är isolerat. Konton, enheter, transaktioner, telefonnummer, e-postadresser och adresser bildar nät av delade identifierare. En graf gör det enklare att se ringar, upprepade mönster och indirekta länkar (t.ex. två “oavhängiga” konton som använder samma enhet via en kedja av aktiviteter).
För tjänster, värdar, API:er, anrop och ägarskap är huvudfrågan beroende: “vad går sönder om detta ändras?” Grafer stödjer konsekvensanalys, rotorsaksundersökning och "blast radius"-frågor när system är sammankopplade.
Knowledge graphs kopplar entiteter (personer, företag, produkter, dokument) till fakta och referenser. Detta hjälper sökning, entitetsupplösning och att spåra varför ett faktum är känt (proveniens) över många länkade källor.
Grafdatabaser glänser när frågan verkligen handlar om kopplingar: vem är kopplad till vem, genom vilken kedja, och vilka mönster upprepar sig. I stället för att JOINa tabeller om och om igen ställer du relationsfrågan direkt och håller frågan läsbar i takt med att nätverket växer.
Typiska frågor:
Det här är användbart för kundsupport (“varför föreslog vi detta?”), efterlevnad (“visa ägarkedjans kedja”) och undersökningar (“hur spreds detta?”).
Grafer hjälper dig upptäcka naturliga grupperingar:
Du kan använda detta för att segmentera användare, hitta bedrägerigrupper eller förstå hur produkter köps ihop. Nyckeln är att “gruppen” definieras av hur saker kopplas, inte av en enskild kolumn.
Ibland handlar frågan inte bara om “vem är kopplat”, utan “vem är viktigast” i nätet:
Dessa centrala noder pekar ofta på påverkare, kritisk infrastruktur eller flaskhalsar värda att bevaka.
Grafer är bra på att söka efter återkommande former:
I Cypher (ett vanligt graffrågespråk) kan ett triangelmönster se ut så här:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
Även om du aldrig skriver Cypher själv illustrerar det varför grafer är tillgängliga: frågan speglar bilden i ditt huvud.
Relationsdatabaser är utmärkta för det de byggdes för: transaktioner och välstrukturerade poster. Om din data passar snyggt i tabeller (kunder, order, fakturor) och du mest hämtar den via ID:n, filter och aggregat, är relationssystem ofta det enklaste, säkraste valet.
Joins är okej när de är tillfälliga och grunda. Friktionen börjar när dina viktigaste frågor kräver många joins, hela tiden, över flera tabeller.
Exempel:
I SQL kan dessa bli långa queries med upprepade self-joins och komplex logik. De blir också svårare att tunna när relationsdjupet växer.
Grafdatabaser lagrar relationer explicit, så flerstegstraverseringar över kopplingar är en naturlig operation. I stället för att sy ihop tabeller vid frågetid traverserar du sammankopplade noder och kanter.
Det betyder ofta:
Om ditt team ofta ställer flerstegsfrågor — “kopplat till”, “genom”, “i samma nätverk som”, “inom N steg” — är en grafdatabas värd att överväga.
Om din kärnarbeidsbelastning är högvolymstransaktioner, strikt schema, rapportering och enkla joins, är relationsdatabasen vanligtvis bättre som standard. Många system använder båda; verklig arkitektur kombinerar ofta graf tillsammans med andra databaser när det behövs.
Grafdatabaser glänser när relationer är “huvudnumret”. Om värdet i din app inte beror på att traversera kopplingar (vem-vet-vem, hur saker relaterar, stigar, grannskap), kan en graf lägga till komplexitet utan mycket nytta.
Om de flesta förfrågningar är “hämta användare via ID”, “uppdatera profil”, “skapa order” och datan du behöver bor i en post (eller ett förutsägbart, litet set tabeller), är en grafdatabas ofta onödig. Du kommer att lägga tid på att modellera noder och kanter, tunna traverseringar och lära ett nytt frågesätt — medan en relationsdatabas hanterar mönstret effektivt med kända verktyg.
Dashboardar byggda på summor, medelvärden och grupperade mått (intäkter per månad, order per region, konverteringsgrad per kanal) passar ofta SQL och kolumnorienterad analys bättre än graf-frågor. Grafmotorer kan svara på vissa aggregatfrågor, men de är sällan enklaste eller snabbaste vägen för tunga OLAP-arbetsbelastningar.
När du förlitar dig på mogna SQL-funktioner — komplexa joins med strikta begränsningar, avancerade indexeringsstrategier, stored procedures eller väletablerade ACID-mönster — är relationssystem ofta det naturliga valet. Många grafdatabaser stödjer transaktioner, men omgivande ekosystem och driftmönster kanske inte matchar vad ditt team redan använder.
Om din data mestadels är en uppsättning oberoende entiteter (ärenden, fakturor, sensormätningar) med minimal korslänkning kan en grafmodell kännas påtvingad. I dessa fall fokusera på ett rent relationsschema (eller dokumentmodell) och överväg graf senare om relationsintensiva frågor blir centrala.
En bra regel: om du kan beskriva dina viktigaste frågor utan ord som “kopplad”, “stig”, “grannskap” eller “rekommendera”, är en grafdatabas kanske inte rätt första val.
Grafdatabaser glänser när du behöver följa kopplingar snabbt — men den styrkan har ett pris. Innan du bestämmer dig är det bra att förstå var grafer tenderar att vara mindre effektiva, dyrare eller helt enkelt annorlunda att drifta dagligen.
Grafdatabaser lagrar och indexerar relationer så att "hopp" blir snabba (t.ex. från kund till deras enheter till deras transaktioner). Trade-offen är att de kan kosta mer i minne och lagring än en motsvarande relationslösning, särskilt när du lägger till index för vanliga uppslag och håller relationsdata lättillgänglig.
Om din arbetsbelastning ser ut som ett kalkylblad — stora tabelliknande skanningar, rapportfrågor över miljontals rader eller tunga aggregat — kan en grafdatabas vara långsammare eller dyrare för samma resultat. Grafer är optimerade för traverseringar ("vem är kopplad till vad?"), inte för att knäcka stora mängder oberoende rader.
Operativ komplexitet kan vara en verklig faktor. Backuper, skalning och övervakning skiljer sig från vad många team är vana vid med relationssystem. Vissa grafplattformar skalar bäst genom att skala upp (större maskiner), medan andra stödjer skalning ut men kräver noggrann planering kring konsistens, replikering och frågemönster.
Ditt team kan behöva tid för att lära nya modelleringsmönster och frågetillvägagångssätt (t.ex. property graph-modellen och språk som Cypher). Inlärningskurvan är hanterbar, men det är ändå en kostnad — särskilt om du ersätter mogna SQL-baserade rapporteringsflöden.
En praktisk metod är att använda graf där relationer är produkten, och behålla befintliga system för rapportering, aggregering och tabellanalys.
Ett användbart sätt att tänka kring grafmodellering är enkelt: noder är saker, och kanter är relationer mellan saker. Personer, konton, enheter, order, produkter, platser — det är noder. “Köpte”, “loggade in från”, “arbetar med”, “är förälder till” — det är kanter.
De flesta produktfokuserade grafdatabaser använder property graph-modellen: både noder och kanter kan ha egenskaper (nyckel–värdefält). Till exempel kan en kant PURCHASED lagra date, amount och channel. Det gör det naturligt att modellera “relationer med detaljer”.
RDF representerar kunskap som tripplar: subject – predicate – object. Det är bra för interoperabla vokabulärer och att länka data över system, men det flyttar ofta “relationsdetaljer” till ytterligare noder/tripplar. Praktiskt sett tenderar RDF att driva dig mot standardontologier och SPARQL-mönster, medan property graphs känns närmare applikationsdatamodellering.
Du behöver inte memorera syntax tidigt — det som betyder något är att graffrågor vanligtvis uttrycks som vägar och mönster, inte som att sammanfoga tabeller.
Grafer är ofta schemaflexibla, vilket betyder att du kan lägga till en ny nodelabel eller egenskap utan tung migration. Men flexibilitet behöver disciplin: definiera namngivningskonventioner, obligatoriska egenskaper (t.ex. id) och regler för relationstyper.
Välj relationstyper som förklarar mening (“FRIEND_OF” vs “CONNECTED”). Använd riktning för att klargöra semantik (t.ex. FOLLOWS från följare till skapare), och lägg till kant-egenskaper när relationen har egna fakta (tid, konfidens, roll, vikt).
Ett problem är “relationsdrivet” när det svåra inte är att lagra poster — det är att förstå hur saker kopplas och hur kopplingarna ändrar betydelsen beroende på vilken väg du tar.
Börja med att skriva dina topp 5–10 frågor i klartext — de som intressenterna ständigt ställer och som ditt nuvarande system svarar långsamt eller inkonsekvent på. Bra grafkandidater innehåller ofta fraser som “kopplat till”, “genom”, “lika med”, “inom N steg” eller “vem mer”.
Exempel:
När du har frågorna, kartlägg substantiv och verb:
Bestäm sedan vad som måste vara en relation kontra en nod. En praktisk regel: om något behöver sina egna attribut och du kommer koppla flera parter till det, gör det till en nod (t.ex. en “Order” eller ett “Login”-händelse kan vara en nod när det bär detaljer och kopplar många entiteter).
Lägg till egenskaper som låter dig avgränsa resultat och ranka relevans utan extra joins eller efterbearbetning. Typiska högt värderade egenskaper inkluderar tid, belopp, status, kanal och konfidenspoäng.
Om de flesta av dina viktiga frågor kräver flerstegskopplingar plus filtrering med dessa egenskaper, har du sannolikt ett relationsdrivet problem där grafdatabaser glänser.
De flesta team ersätter inte allt med en grafdatabas. En mer praktisk metod är att behålla din “system of record” där det redan fungerar bra (ofta SQL), och använda en grafdatabas som en specialiserad motor för relationsintensiva frågor.
Använd din relationsdatabas för transaktioner, begränsningar och kanoniska entiteter (kunder, order, konton). Projicera sedan en relationsvy in i en grafdatabas — endast de noder och kanter du behöver för sammanlänkade frågor.
Detta håller revision och datastyrning enkel samtidigt som du får snabba traverseringsfrågor.
En grafdatabas glänser när du kopplar den till ett tydligt avgränsat feature, till exempel:
Börja med en feature, ett team och ett mätbart utfall. Du kan expandera senare om det visar värde.
Om din flaskhals är att leverera prototypen (inte att debattera modellen), kan en vibe-coding-plattform som Koder.ai hjälpa dig att snabbt stå upp en enkel grafdriven app: du beskriver funktionen i chatten, genererar ett React UI och en Go/PostgreSQL-backend, och itererar medan ditt datateam validerar graf-schemat och frågorna.
Hur färsk behöver grafen vara?
Ett vanligt mönster är: skriv transaktioner till SQL → publicera change events → uppdatera grafen.
Grafer blir röriga när ID:n driver iväg.
Definiera stabila identifierare (t.ex. customer_id, account_id) som matchar över system och dokumentera vem som “äger” varje fält och relation. Om två system kan skapa samma kant (säg “knows”), bestäm vilket system som vinner.
Om du planerar en pilot, använd en stegvis rollout-approach och definiera tydliga checkpoints.
En grafpilot ska kännas som ett experiment, inte en omskrivning. Målet är att bevisa (eller motbevisa) att relationsintensiva frågor blir enklare och snabbare — utan att satsa hela datastacken.
Börja med en snäv dataset som redan orsakar problem: för många JOINs, bräcklig SQL eller långsamma “vem är kopplat till vad?”-frågor. Håll det begränsat till ett arbetsflöde (t.ex. kund ↔ konto ↔ enhet, eller användare ↔ produkt ↔ interaktion) och definiera ett fåtal frågor du vill besvara end-to-end.
Mät mer än hastighet:
Om du inte kan namnge “före”-siffrorna kommer du inte att lita på “efter”.
Det är frestande att modellera allt som noder och kanter. Motstå det. Håll utkik efter “graph sprawl”: för många nod-/kant-typer utan en tydlig fråga som behöver dem. Varje ny label eller relation ska förtjäna sin plats genom att möjliggöra en verklig fråga.
Planera för integritet, åtkomstkontroll och datapolicy från början. Relationsdata kan avslöja mer än individuella poster (t.ex. kopplingar som antyder beteende). Definiera vem som får fråga vad, hur resultat auditeras och hur data tas bort när det krävs.
Använd en enkel synk (batch eller streaming) för att mata grafen medan ditt befintliga system förblir sanningskällan. När piloten visar värde kan du expandera — försiktigt, use case för use case.
Om du väljer en databas, börja inte med tekniken — börja med frågorna du behöver svara. Grafdatabaser glänser när dina svåraste problem handlar om kopplingar och stigar, inte bara att lagra poster.
Använd denna checklista för att sanity-checka fit innan du investerar:
Om du svarade “ja” på de flesta av dessa är en graf ofta en stark match — särskilt när du behöver flerstegs mönstermatchning som:
Om ditt arbete mest är enkla uppslag (via ID/email) eller aggregat (“totala försäljningar per månad”), är en relationsdatabas eller key-value-/dokumentstore vanligtvis enklare och billigare att köra.
Skriv ner dina topp 10 affärsfrågor som vanliga meningar, testa dem på verklig data i en liten pilot. Tidssätt frågorna, notera vad som är svårt att uttrycka och för en kort logg över modelländringar du behövde. Om din pilot mest blir “fler joins” eller “mer caching” är det en signal att en graf kan löna sig. Om det mest handlar om räkningar och filter, kommer det troligen inte att göra det.
En grafdatabas lagrar data som noder (entiteter) och relationer (kopplingar) där både noder och relationer kan ha egenskaper. Den är optimerad för frågor som “hur är A kopplat till B?” och “vem finns inom N steg?” snarare än primärt för tabellbaserade rapporter.
Det betyder att relationer sparas som verkliga, frågbara objekt (inte bara som foreign keys). Du kan traversera flera hopp effektivt och fästa egenskaper direkt på relationen (t.ex. date, amount, risk_score), vilket gör relationsintensiva frågor enklare att modellera och fråga.
Relationsdatabaser representerar relationer indirekt (via foreign keys) och kräver ofta flera JOINs för frågor som går över flera hopp. Grafdatabaser håller kopplingarna intill datan, så variabla-djup traverseringar (t.ex. 2–6 hopp) blir vanligtvis enklare att uttrycka och underhålla.
Använd grafdatabas när dina kärnfrågor handlar om vägar, grannskap och mönster:
Vanliga grafvänliga frågor inkluderar:
Ofta när din arbetsbelastning mest består av:
I de fallen är en relations- eller analysdatabas vanligtvis enklare och billigare.
Modellera en relation som en kant när den främst kopplar två entiteter och kan bära egna egenskaper (tid, roll, vikt). Modellera det som en nod när det är en händelse eller entitet med flera attribut som kopplas till många parter (t.ex. en Order eller ett Login-händelse som länkar användare, enhet, IP och tid).
Typiska avvägningar inkluderar:
Property graphs låter noder och relationer ha egenskaper (nyckel–värde) och är vanliga för applikationsnära modellering. RDF representerar kunskap som tripplar (subject–predicate–object) och passar delade vokabulärer och SPARQL. Välj efter om du behöver applikationscentrerade relations-egenskaper (property graph) eller interoperabel semantisk modellering (RDF).
Behåll ditt befintliga system (ofta SQL) som sanningskälla och projicera sedan den relationella vyn in i en graf för ett avgränsat feature (rekommendationer, bedömning, identitetsupplösning). Synka via batch eller streaming, använd stabila identifierare över systemen och mät framgång (latens, frågekomplexitet, utvecklartid) innan du går vidare.