04 juni 2025·8 min
Varför horisontell skalning är svårare än vertikal skalning
Vertikal skalning är ofta bara att lägga till CPU/RAM. Horisontell skalning kräver koordinering, partitionering, konsistens och mer driftarbete—därför är den svårare.
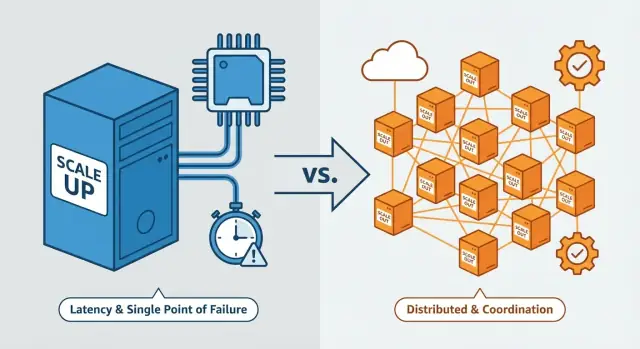
Vertikal skalning är ofta bara att lägga till CPU/RAM. Horisontell skalning kräver koordinering, partitionering, konsistens och mer driftarbete—därför är den svårare.
Skalning betyder "att hantera mer utan att falla ihop". Det där "mer" kan vara:
När folk pratar om skalning försöker de vanligtvis förbättra en eller flera av dessa:
Det mesta kokar ner till ett tema: att skala upp bevarar känslan av ett ”ensamt system”, medan att skala ut förvandlar ditt system till en koordinerad grupp av oberoende maskiner—och just den koordineringen är där svårigheten exploderar.
Vertikal skalning betyder att göra en maskin starkare. Du behåller samma grundarkitektur men uppgraderar servern (eller VM): fler CPU-kärnor, mer RAM, snabbare diskar, högre nätverksprestanda.
Tänk på det som att köpa en större lastbil: du har fortfarande en förare och ett fordon, det rymmer bara mer.
Horisontell skalning betyder att lägga till fler maskiner eller instanser och dela upp arbetet mellan dem—ofta bakom en lastbalanserare. Istället för en starkare server kör du flera servrar som samarbetar.
Det är som att använda fler lastbilar: du kan flytta mer gods totalt, men nu måste du hantera schemaläggning, ruttval och koordinering.
Vanliga utlösare inkluderar:
Team skalar ofta upp först eftersom det går snabbt (uppgradera boxen), sedan skalar ut när en enda maskin når sina gränser eller när högre tillgänglighet behövs. Mogna arkitekturer blandar vanligen båda: större noder OCH fler noder, beroende på flaskhalsen.
Vertikal skalning är lockande eftersom det håller systemet på ett ställe. Med en enstaka nod har du oftast en källa för sanning för minne och lokalt tillstånd. En process äger cache i minnet, jobbkön, sessionslagring (om sessioner finns i minnet) och temporära filer.
På en server är de flesta operationer okomplicerade eftersom det finns lite eller ingen koordinering mellan noder:
När du skalar upp drar du i bekanta spakar: lägg till CPU/RAM, använd snabbare lagring, förbättra index, tunna queries och konfigurationer. Du behöver inte designa om hur data distribueras eller hur flera noder enas om "vad som händer härnäst."
Vertikal skalning är inte ”gratis”—den håller bara komplexiteten begränsad.
Till slut når du gränser: den största instans du kan hyra, avtagande avkastning eller en brant kostnadskurva i den övre änden. Du kan också ha högre drift-risk: om den stora maskinen går ner eller behöver underhåll påverkas en stor del av systemet om du inte har lagt till redundans.
När du skalar ut får du inte bara "fler servrar." Du får fler oberoende aktörer som måste vara överens om vem som ansvarar för vilken del av arbetet, när det ska göras och med vilken data.
Med en maskin är koordinering ofta implicit: ett minnesutrymme, en process, ett ställe att leta efter tillstånd. Med många maskiner blir koordinering en funktion du måste designa.
Vanliga verktyg och mönster inkluderar:
Koordinationsbuggar ser sällan ut som rena krascher. Ofta ser du:
Dessa problem visar sig ofta bara under verklig belastning, vid deployment eller vid partiella fel (en nod är långsam, en switch tappar paket, en zon blippar). Systemet ser fint ut—tills det stressas.
När du skalar ut kan du ofta inte ha all data på ett ställe. Du delar den över maskiner (shards) så flera noder kan lagra och serva förfrågningar parallellt. Det är i den uppdelningen komplexiteten börjar: varje läsning och skrivning beror på "vilken shard håller den här posten?"
Range-partitionering grupperar data efter ett ordnat nyckelintervall (t.ex. användare A–F på shard 1, G–M på shard 2). Det är intuitivt och stödjer range-queries bra ("visa orders från förra veckan"). Nackdelen är ojämn last: om ett intervall blir populärt blir den sharden en flaskhals.
Hash-partitionering kör en nyckel genom en hashfunktion och distribuerar resultaten över shards. Det sprider trafiken jämnare men gör range-queries svårare eftersom relaterade poster sprids ut.
Lägger du till en nod vill du använda den—vilket betyder att viss data måste flyttas. Tar du bort en nod (planerat eller vid fel) måste andra shards ta över. Rebalansering kan trigga stora dataöverföringar, cache-warmups och tillfälliga prestandadipp. Under flytten måste du också förhindra föråldrade läsningar och felroutade skrivningar.
Även med hashing är verklig trafik inte uniform. Ett kändiskonto, en populär produkt eller tidsbaserade åtkomstmönster kan koncentrera läsningar/skrivningar på en shard. En het shard kan begränsa genomströmningen för hela systemet.
Sharding introducerar löpande ansvar: underhålla routing-regler, köra migreringar, göra backfills efter schemaändringar och planera splits/merges utan att bryta klienter.
När du skalar ut lägger du inte bara till fler servrar—du lägger till fler kopior av din applikation. Det svåra är state: allt din app "kommer ihåg" mellan förfrågningar eller medan arbete pågår.
Om en användare loggar in på Server A men nästa request hamnar på Server B—känner B igen användaren?
Cacher snabbar upp, men flera servrar betyder flera cacher. Nu måste du hantera:
Med många workers kan bakgrundsjobb köras två gånger om du inte designar för det. Du behöver oftast en kö, leases/lås eller idempotent jobblogik så att "skicka faktura" eller "debiter kort" inte sker två gånger—särskilt vid retries och omstarter.
Med en enda nod (eller en primär databas) finns oftast en tydlig "källa till sanning." När du skalar ut sprids data och förfrågningar över maskiner, och att hålla alla synkroniserade blir en ständig oro.
Eventuell konsistens är ofta snabbare och billigare i skala, men den introducerar överraskande kantfall.
Vanliga problem inkluderar:
Du kan inte eliminera fel, men du kan designa för dem:
En transaktion över tjänster (order + lager + betalning) kräver att flera system är överens. Om ett steg misslyckas mitt i krävs kompenserande åtgärder och noggrann bokföring. Klassisk "allt-eller-inget"-beteende är svårt när nätverk och noder kan falla oberoende.
Använd stark konsistens för saker som måste vara korrekta: betalningar, kontosaldon, lagersaldon, platsbokningar. För mindre kritisk data (analys, rekommendationer) är eventuell konsistens ofta OK.
När du skalar upp är många "anrop" funktionanrop i samma process: snabba och förutsägbara. När du skalar ut blir samma interaktion ett nätverksanrop—det lägger till latens, jitter och feltyper din kod måste hantera.
Nätverksanrop har fast overhead (serialisering, köer, hopp) och varierande overhead (kongestion, routing, noisy neighbors). Även om medellatensen är OK kan tail-latency (de långsammaste 1–5%) dominera användarupplevelsen eftersom ett enda långsamt beroende blockerar hela requesten.
Bandbredd och paketförlust blir också begränsningar: vid höga förfrågningsnivåer adderas små payloads ihop och retransmits ökar tyst belastningen.
Utan timeouts staplas långsamma anrop upp och trådar fastnar. Med timeouts och retries kan du återhämta dig—tills retries förstärker belastningen.
Ett vanligt felmönster är en retry-storm: en backend saktar ner, klienter timear ut och retryar, retries ökar belastningen och backend blir ännu långsammare.
Säkrare retries kräver oftast:
Med flera instanser måste klienter veta vart de ska skicka requests—via en lastbalanserare eller service discovery plus klient-sidig balansering. I båda fallen lägger du till rörliga delar: health checks, draining av connections, ojämn trafikfördelning och risken att routa till en halvsönder instans.
För att förhindra att överbelastning sprider sig behöver du backpressure: begränsade köer, circuit breakers och rate limiting. Målet är att misslyckas snabbt och förutsägbart istället för att låta en liten nedgång bli ett systemomfattande incident.
Vertikal skalning tenderar att misslyckas på ett tydligt sätt: en större maskin är fortfarande en enda felpunkt. Om den saktar ner eller kraschar är påverkan uppenbar.
Horisontell skalning ändrar matematiken. Med många noder är det normalt att vissa maskiner är ohälsosamma medan andra är okej. Systemet är "up", men användare ser ändå fel, långsamma sidor eller inkonsekvent beteende. Detta är partiellt fel, och det blir standardtillståndet du designar för.
I en skalad setup beror tjänster på andra tjänster: databaser, cacher, köer, downstream-APIer. Ett litet problem kan spridas:
För att överleva partiella fel lägger system till redundans:
Detta ökar tillgängligheten men introducerar kantfall: split-brain, föråldrade repliker och beslut om vad som görs när quorum inte uppnås.
Vanliga mönster inkluderar:
Med en enda maskin lever "systemhistorien" på ett ställe: en uppsättning loggar, en CPU-graf, en process att inspektera. Med horisontell skalning är historien utspridd.
Varje extra nod lägger till en ström av loggar, metrics och traces. Det svåra är inte att samla data—det är att korrelera den. Ett checkout-fel kan börja i en web-node, anropa två tjänster, träffa en cache och läsa från en specifik shard, vilket lämnar ledtrådar på olika platser och tider.
Problem blir också selektiva: en nod har fel config, en shard är het, en zon har högre latens. Felsökning kan kännas slumpmässig eftersom det "fungerar bra" mestadels.
Distribuerad tracing är som att fästa ett spårningsnummer på en request. Ett korrelations-ID är det numret. Du för det genom tjänster och inkluderar det i loggar så du kan plocka ett ID och se hela resan end-to-end.
Fler komponenter betyder oftast fler larm. Utan justering får team alert fatigue. Sikta på handlingsbara larm som klargör:
Kapacitetsproblem syns ofta innan fel. Bevaka saturation-signaler som CPU, minne, ködjup och användning av connection pools. Om saturation syns bara på en underuppsättning noder, misstänk balansering, sharding eller konfigurationsdrift—inte bara "mer trafik".
När du skalar ut är en deploy inte längre "ersätt en box." Det är att koordinera ändringar över många maskiner och samtidigt hålla tjänsten tillgänglig.
Horisontella deployer använder ofta rolling updates (ersätt noder gradvis), canaries (skicka en liten procent av trafiken till ny version) eller blue/green (växla trafik mellan två fulla miljöer). De minskar blast radius men kräver: trafikskiftning, health checks, dränering av connections och en definition av "tillräckligt bra för att fortsätta."
Under en gradvis deploy körs gamla och nya versioner sida vid sida. Denna versionsskew betyder att systemet måste tolerera blandat beteende:
API:er behöver bakåt-/framåtkompatibilitet, inte bara korrekthet. Databaseschema-ändringar bör vara additiva när möjligt (lägg till nullable-kolumner innan de görs obligatoriska). Meddelandeformat bör versionshanteras så konsumenter kan läsa både gamla och nya event.
Att rulla tillbaka kod är enkelt; att rulla tillbaka data är inte. Om en migration tar bort eller skriver om fält kan äldre kod krascha eller hantera poster felaktigt. "Expand/contract"-migreringar hjälper: deploya kod som stödjer båda scheman, migrera data, ta bort gamla vägar senare.
Med många noder blir konfigurationshantering en del av deploy. En enda nod med föråldrad konfig, fel feature flags eller utgångna credentials kan skapa fladdriga, svårreproducerade fel.
Horisontell skalning kan se billigare ut i kalkylen: många små instanser, vardera med lågt timpris. Men total kostnad är inte bara compute. Att lägga till noder betyder också mer nätverk, mer övervakning, mer koordinering och mer tid för att hålla allt synkront.
Vertikal skalning koncentrerar kostnaden till färre maskiner—ofta färre hosts att patcha, färre agenter att köra, färre loggar att skicka, färre metrics att samla.
Med skala ut kan per-enhet-priset vara lägre, men du betalar ofta för:
För att hantera toppar säkert kör distribuerade system ofta underfullt. Du behåller reservkapacitet på flera nivåer (web, workers, DB, cache), vilket kan bli kostsamt över dussintals eller hundratals instanser.
Skala ut ökar on-call-krav och kräver mogna verktyg: larm-tuning, runbooks, incidentövningar och träning. Team spenderar också tid på ansvarsfördelning (vem äger vilken tjänst?) och incidentkoordinering.
Resultatet: "billigare per enhet" kan ändå bli dyrare totalt när du räknar in personkostnad, operativ risk och arbetet som krävs för att få många maskiner att bete sig som ett system.
Att välja mellan att skala upp (större maskin) och skala ut (fler maskiner) handlar inte bara om pris. Det handlar om arbetsbelastningens natur och hur mycket operativ komplexitet ditt team kan ta.
Börja med arbetsbelastningen:
En vanlig och rimlig väg:
Många team håller databasen vertikal (eller lätt klustrad) medan de skalar app-tier stateless horisontellt. Det minskar smärtan med sharding samtidigt som du snabbt kan lägga till web-kapacitet.
Du är närmare när du har bra övervakning och larm, testad failover, loadtester och repeterbara deployer med säkra rollbacks.
Mycket av skalningssmärtan är inte bara "arkitektur"—det är den operativa loopen: iterera säkert, deploya pålitligt och rulla tillbaka snabbt när verkligheten inte följer planen.
Om du bygger webb-, backend- eller mobilsystem och vill röra dig snabbt utan att tappa kontrollen kan Koder.ai hjälpa dig att prototypa och skicka snabbare medan du tar skalningsbeslut. Det är en vibe-coding-plattform där du bygger applikationer via chatt, med en agentbaserad arkitektur under huven. I praktiken betyder det att du kan:
Eftersom Koder.ai körs globalt på AWS kan det också stödja distributioner i olika regioner för att möta latens- och dataöverföringsbegränsningar—nyttigt när multi-zone eller multi-region tillgänglighet blir en del av din skalningsberättelse.
Vertikal skalning betyder att göra en enda maskin större (mer CPU/RAM/snabbare disk). Horisontell skalning betyder att lägga till fler maskiner och fördela arbetet mellan dem.
Vertikal känns ofta enklare eftersom din app fortfarande beter sig som “ett system”, medan horisontell kräver att flera system koordinerar och håller sig konsistenta.
För att du så fort du har flera noder behöver uttrycklig koordinering:
En enda maskin undviker många av dessa distribuerade system-problem som standard.
Det är tiden och logiken som krävs för att få flera maskiner att bete sig som ett:
Även om varje nod är enkel blir systemsbeteendet svårare att förstå under belastning och fel.
Sharding (partitionering) delar data över noder så ingen enskild maskin behöver lagra/leverera allt. Det är svårt eftersom du måste:
Det ökar också det operativa arbetet (migreringar, backfills, shard-kartor).
State är allt din app ”kommer ihåg” mellan förfrågningar eller medan arbete pågår (sessioner, in-memory-cacher, temporära filer, jobbförlopp).
Med horisontell skalning kan förfrågningar hamna på olika servrar, så du behöver vanligtvis delad state (t.ex. Redis/db) eller acceptera kompromisser som sticky sessions.
Om flera workers kan plocka upp samma jobb (eller jobbet retrys) riskerar du dubbelbokföring eller dubbelexekvering.
Vanliga åtgärder:
Stark konsistens betyder att när en skrivning lyckas ser alla läsare direkt den senaste värdet. Eventuell konsistens betyder att uppdateringar sprids över tid, så vissa läsare kan se gamla värden en kort stund.
Använd stark konsistens för kritiska saker (betalningar, saldon, lager). Eventuell konsistens är ofta acceptabel för mindre kritiska data (analytics, rekommendationer).
I ett distribuerat system blir anrop nätverksanrop, vilket tillför latens, jitter och nya felmöjligheter.
Grundläggande regler:
Partiellt fel innebär att vissa komponenter är trasiga eller långsamma medan andra fungerar. Systemet kan vara ”up” men ändå ge fel, timeout eller inkonsekvent beteende.
Designade svar inkluderar replikering, quorums, multi-zone-deploys, circuit breakers och graceful degradation så att fel inte sprider sig.
När många maskiner är inblandade är bevisen splittrade: loggar, metrics och traces finns på olika noder.
Praktiska steg: