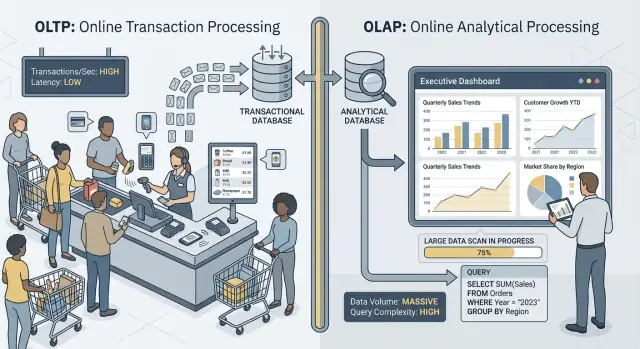
OLTP vs OLAP: Vad de är (utan jargong)
När folk säger “OLTP” och “OLAP” pratar de om två väldigt olika sätt en databas används.
OLTP: databasen som driver verksamheten
OLTP (Online Transaction Processing) är arbetsbelastningen bakom dagliga åtgärder som måste vara snabba och korrekta varje gång. Tänk: “spara den här ändringen nu.”
Typiska OLTP-uppgifter inkluderar att skapa en order, uppdatera lager, registrera en betalning eller ändra en kundadress. Dessa operationer är vanligtvis små (några rader), frekventa och måste svara inom millisekunder eftersom en person eller ett annat system väntar.
OLAP: databasen som förklarar verksamheten
OLAP (Online Analytical Processing) är arbetsbelastningen som används för att förstå vad som hände och varför. Tänk: “skanna mycket data och summera det.”
Typiska OLAP-uppgifter inkluderar dashboards, trendrapporter, kohortanalys, prognoser och "slice-and-dice"-frågor som: “Hur förändrades intäkterna per region och produktkategori under de senaste 18 månaderna?” Dessa frågor läser ofta många rader, utför tunga aggregeringar och kan köra i sekunder (eller minuter) utan att det är “fel”.
Samma data, olika mål — och olika behov
Huvudidén är enkel: OLTP optimerar för snabba, konsekventa skrivningar och små läsningar, medan OLAP optimerar för stora läsningar och komplexa beräkningar. Eftersom målen skiljer sig åt gör också de bästa databasinställningarna, indexen, lagringsupplägget och skalningsstrategierna ofta det.
Notera också ordvalet: sällan, inte aldrig. Vissa små team kan dela en databas en tid, särskilt med måttlig datavolym och disciplinerade frågor. Senare avsnitt tar upp vad som går sönder först, vanliga separationsmönster och hur du säkert flyttar rapportering bort från produktion.
Snabba exempel
- Checkout (OLTP): en kund klickar “Pay” och din app skriver en order, betalningsstatus och lagerändringar.
- Rapportdashboard (OLAP): en chef öppnar en dashboard som aggregerar tusentals (eller miljoner) order för att visa konverteringsgrad, genomsnittligt ordervärde och veckotrender.
Olika mål, olika framgångsmått
OLTP och OLAP kan båda “använda SQL”, men de optimerar för olika jobb — och det syns i vad de anser vara framgång.
OLTP: snabbhet, samtidighet och korrekthet
OLTP (transaktionella) system driver dagliga operationer: checkout-flöden, kontouppdateringar, reservationer, supportverktyg. Prioriteringarna är tydliga:
- Snabba responstider för små läsningar/skrivningar (tänk millisekunder)
- Många samtidiga användare utan nedgång i prestanda
- Korrekthet och konsistens, eftersom fel balans eller dubblettorder är ett verkligt affärsproblem
Framgång mäts ofta med latensmått som p95/p99 request time, felprocent och hur systemet beter sig under toppsamtidighet.
OLAP: skanning, aggregering och flexibilitet
OLAP (analys) system svarar på frågor som “Vad förändrades detta kvartal?” eller “Vilken segment churnade efter den nya prisplanen?” Dessa frågor:
- Skannar stora mängder data över många rader
- Utför aggregeringar (SUM, COUNT, percentiler) och joins
- Förändras ofta när analytiker utforskar och förfinar frågorna
Framgång här handlar mer om frågegenomströmning, tid-till-insikt och möjligheten att köra komplexa frågor utan att hand-tuna varje rapport.
Varför “ett system för allt” skapar avvägningar
När du tvingar båda arbetsbelastningarna in i en databas ber du den vara samtidigt bra på små, högvolymtransaktioner och på stora, utforskande skanningar. Resultatet blir ofta ett kompromiss: OLTP får oförutsägbar latens, OLAP blir nedprioriterad för att skydda produktion, och teamen börjar bråka om vilka frågor som är “tillåtna.” Olika mål förtjänar olika framgångsmått — och oftast separata system.
Resurskonkurrens: när analys stjäl från transaktioner
När OLTP (appens dagliga transaktioner) och OLAP (rapportering och analys) körs i samma databas tävlar de om samma begränsade resurser. Resultatet är inte bara “långsammare rapporter.” Det är ofta långsammare checkout, fastkörda inloggningar och oförutsägbara apphickups.
CPU och minne: långa frågor vs korta frågor
Analytiska frågor tenderar att vara långa och tunga: joins över stora tabeller, aggregeringar, sortering och gruppering. De kan monopolera CPU-kärnor och, lika viktigt, minne för hash-joins och sortbuffrar.
Samtidigt är transaktionella frågor vanligtvis små men latenskänsliga. Om CPU:n är mättad eller minnespress tvingar bort data ur cache börjar de korta frågorna vänta bakom de stora — även om varje transaktion bara behöver några millisekunders arbete.
Disk-I/O: stora skanningar vs många små läsningar/skrivningar
Analys triggar ofta stora tabelsskanningar och läser många sidor sekventiellt. OLTP gör tvärtom: många små, slumpmässiga läsningar plus kontinuerliga skrivningar till index och loggar.
Sätt ihop dem och lagringssubsystemet måste jonglera inkompatibla åtkomstmönster. Cacher som hjälpte OLTP kan "tvättas bort" av analys, och skrivlatensen kan skena när disken strömmar data för rapporter.
Connection pool-press och köbildning
Ett par analytiker som kör breda frågor kan binda upp anslutningar i flera minuter. Om din applikation använder en fast poolstorlek bygger sig köer upp för att få en fri anslutning. Denna köeffekt kan få ett i övrigt friskt system att kännas trasigt: medellatens kan se okej ut, men tail-latenser (p95/p99) blir plågsamma.
Vad användare faktiskt märker
Utifrån syns detta som timeouts, långsamma checkout-flöden, fördröjda sökresultat och allmänt instabilt beteende — ofta “bara under rapportering” eller “bara i slutet av månaden.” Appteamet ser fel; analysteamet ser långsamma frågor; det verkliga problemet är delad konkurrens under ytan.
OLTP och OLAP använder inte bara databasen olika — de premierar motsatta fysiska designer. När du försöker tillfredsställa båda i en plats slutar du ofta med en kompromiss som både är dyr och underpresterar.
OLTP: optimerat för snabba, selektiva uppslag
Transaktionell arbetsbelastning domineras av korta frågor som berör en liten del av datat: hämta en order, uppdatera en lager-rad, lista de senaste 20 händelserna för en användare.
Det gör att OLTP-scheman lutar mot radorienterad lagring och index som stödjer punktuppslag och små rangesökningar (ofta på primärnycklar, främmande nycklar och några få högvärdes sekundära index). Målet är förutsägbar, låg latens — särskilt för skrivningar.
OLAP: optimerat för skanning, gruppering och summering
Analys behöver ofta läsa många rader men bara några kolumner: “intäkter per vecka per region”, “konverteringsgrad per kampanj”, “topp-produkter efter marginal.”
OLAP-system gynnas av kolumnlagring (för att läsa endast nödvändiga kolumner), partitionering (för att snabbt pruna bort gammal eller irrelevant data) och föraggregering (materialized views, rollups, summeringstabeller) så att rapporter inte räknar om samma totals varje gång.
Varför “indexa för allt” slår tillbaka
En vanlig reaktion är att lägga till index tills varje dashboard blir snabb. Men varje extra index ökar skrivkostnaden: inserts, updates och deletes måste uppdatera fler strukturer. Det ökar också lagringen och kan sakta ner underhållsjobb som vacuuming, reindexing och backup.
Frågeplanerare och statistikdrift (enkelt uttryckt)
Databaser väljer frågeplaner baserat på statistik — uppskattningar av hur många rader som matchar ett filter, hur selektivt ett index är och hur data är fördelad. OLTP ändrar data konstant. När fördelningen skiftar kan statistiken driva fel planval, och planaren kan välja en plan som var bra igår men dålig idag.
Blanda in tunga OLAP-frågor som skannar och joinar stora tabeller, och du får ännu mer variabilitet: den "bästa planen" blir svårare att förutsäga, och tuning för en arbetsbelastning gör ofta den andra sämre.
Låsning, MVCC och underhålls-bieffekter
Även om din databas “stödjer samtidighet” skapar blandad tung rapportering och live-transaktioner subtila fördröjningar som är svåra att förutsäga — och ännu svårare att förklara för en kund som stirrar på en snurrande checkout.
Långkörande frågor skapar ändå låsproblem
OLAP-liknande frågor skannar ofta många rader, joinar flera tabeller och kör i sekunder eller minuter. Under den tiden kan de hålla lås (t.ex. på schemaobjekt, eller när de behöver sortera/aggregera i temp-strukturer) och de ökar ofta indirekt låskonkurrens genom att hålla många rader “i spel.”
Även med MVCC (multi-version concurrency control) måste databasen spåra flera versioner av samma rad så att läsare och skrivare inte blockerar varandra. Det hjälper, men eliminerar inte konkurrens — särskilt när frågor rör heta tabeller som transaktioner uppdaterar konstant.
MVCC har en dold kostnad: städning blir svårare
MVCC betyder att gamla radversioner ligger kvar tills databasen säkert kan ta bort dem. En långkörande rapport kan hålla en gammal snapshot öppen, vilket förhindrar att städning återtar utrymme.
Det påverkar:
- Vacuum/garbage collection: städning kan inte ta bort döda tuples/versioner lika snabbt.
- Bloat/fragmentering: lagringen växer, index blir mindre effektiva och cache blir mindre användbar.
- Kompakteringspress: vissa motorer svarar med tyngre bakgrundsarbete, vilket stjäl I/O och CPU från transaktioner.
Resultatet är en dubbel effekt: rapportering får databasen att jobba hårdare och gör systemet långsammare över tid.
Isoleringsnivåer förstärker latensvariabilitet
Rapportverktyg begär ofta högre isolation (eller hamnar oavsiktligt i en lång transaktion). Högre isolation kan öka väntetider på lås och mängden versioner som motorn måste hantera. Från OLTP-sidan ser du detta som oförutsägbara spikar: de flesta order skriver snabbt, men ett fåtal stannar plötsligt.
Praktiskt exempel: månadsslutets rapporter saktar orderflödet
I slutet av månaden kör ekonomi en "intäkt per produkt"-fråga som skannar order och orderrader för hela månaden. Medan den kör accepteras nya order, men vacuum kan inte återta gamla versioner och index churnar. Order-API:et börjar se sporadiska timeouts — inte för att det är "nere", utan för att konkurrens och städ-overhead tyst skjuter upp latensen över era gränser.
Arbetsbelastningens ryckighet och oförutsägbar latens
Utveckla mot CDC när du är redo
Börja enkelt, och exportera sedan kod när du lägger till ELT-modeller och analystjänster.
OLTP-system lever och dör på förutsägbarhet. En checkout, supportticket eller saldouppdatering är inte “mestadels bra” om den är snabb 95 % av tiden — användare märker de långsamma ögonblicken. OLAP är ofta burstigt: ett fåtal tunga frågor kan vara tysta i timmar och sedan plötsligt konsumera mycket CPU, minne och I/O.
Analystrafik tenderar att klumpa sig kring rutiner:
- Morgonens "standup-dashboards" där många uppdaterar samma diagram samtidigt
- Schemalagda rapporter som alla startar i början av timmen
- Månadsslut och kvartalsgenomgångar som triggar långa skanningar och joins
Samtidigt är OLTP-trafik oftare jämnare. När båda delar samma databas översätts analys-spikar till oförutsägbar latens för transaktioner — timeouts, långsamma sidladdningar och retries som i sin tur lägger på ännu mer belastning.
Varför begränsningar och schemaläggning hjälper — men inte löser konflikten
Du kan minska skadan med taktiker som att köra rapporter på natten, begränsa samtidighet, införa statement timeouts eller sätta kostnadstak för frågor. Dessa är värdefulla skyddsåtgärder, särskilt för “rapportering på produktion.”
Men de tar inte bort den grundläggande spänningen: OLAP-frågor är designade för att använda mycket resurser för att besvara stora frågor, medan OLTP behöver små, snabba resursbitar hela dagen. Så fort en oväntad dashboard-uppdatering, ad-hoc-fråga eller backfill slinker igenom är den delade databasen utsatt igen.
Noisy neighbor-problemet
På delad infrastruktur kan en "högljudd" analysanvändare eller jobb monopoliserar cache, mätta disk eller pressa CPU-schemaläggning — utan att göra något fel. OLTP-arbetsbelastningen blir collateral damage, och det svåraste är att felen ser slumpmässiga ut: latensspikar istället för tydliga, upprepbara fel.
Operativ komplexitet: backup, säkerhet och kapacitetsplanering
Att blanda OLTP och OLAP skapar inte bara prestandahuvudvärk — det försvårar även den dagliga driften. Databasen blir en enda "allt-i-ett-låda" och varje operativt jobb ärvt riskerna från båda arbetsbelastningarna.
Backups, återställningar och disaster recovery blir långsammare
Analystabeller tenderar att växa brett och snabbt (mer historik, fler kolumner, fler aggregat). Denna extra volym förändrar din återställningsberättelse.
En full backup tar längre tid, använder mer lagring och ökar risken att ni missar backup-fönstret. Återställningar är värre: när du behöver återhämta snabbt återställer du inte bara transaktionell data som appen behöver, utan även stora analytiska dataset som inte krävs för att få verksamheten igång. Disaster recovery-test tar längre tid och genomförs mer sällan — precis tvärtom mot vad du vill.
Kapacitetsplanering blir gissningslek
Transaktionell tillväxt är oftast förutsägbar: fler kunder, fler order, fler rader. Analysväxt är ofta ojämn: en ny dashboard, en ändrad retention-policy eller ett team som bestämmer sig för att spara "bara ett år till" av råa events.
När båda lever tillsammans kan du inte lätt svara på:
- Växer vi för att produkten är framgångsrik, eller för att rapporterna sparar mer historik?
- Behöver vi snabbare lagring för transaktioner, eller billigare lagring för analys?
Denna osäkerhet leder till överprovisionering (betala för kapacitet ni inte behöver) eller underprovisionering (överraskningsavbrott).
Guardrails är svårare att upprätthålla rättvist
I en delad databas kan en "oskyldig" fråga bli en incident. Ni inför skyddsåtgärder som statement timeouts, kvoter, schemalagda rapportfönster eller workload management-regler. Dessa hjälper, men är sköra: appen och analytikerna konkurrerar om samma gränser, och policyändringar för en grupp kan bryta den andra.
Säkerhet och åtkomstkontroll blir rörigt
Applikationer behöver ofta snäva, syftesbestämda behörigheter. Analytiker behöver ofta bred läsåtkomst över många tabeller för att utforska och validera. Att lägga båda i samma databas ökar pressen att ge vidare behörigheter "bara för att få rapporten att fungera", vilket ökar felmarginalen och breddar vem som kan se känslig driftdata.
Skalning och kostnad: du betalar dubbelt (eller värre)
Återhämta dig snabbt från schemaändringar
Använd snapshots och rollback när en migration eller frågeändring orsakar överraskningar.
Att försöka köra OLTP och OLAP i samma databas ser ofta billigare ut — tills ni börjar skala. Problemet är inte bara prestanda. Det är att det “rätta” sättet att skala varje arbetsbelastning skjuter dig mot olika infrastruktur, och att kombinera dem tvingar dyra kompromisser.
OLTP-skalning är skrivdriven (och ofta smärtsam)
Transaktionella system begränsas av skrivningar: många små uppdateringar, strikt latens och toppar som måste absorberas direkt. Att skala OLTP innebär ofta vertikal skalning (större CPU, snabbare disks, mer minne) eftersom skrivtunga arbetsflöden inte enkelt kan fan-outas.
När de vertikala gränserna nås tittar ni på sharding eller andra skrivskalningsmönster. Det lägger engineering-överhead och kräver ofta noggranna ändringar i applikationen.
OLAP-skalning är compute-driven (och ofta elastisk)
Analysarbetsbelastningar skalar annorlunda: långa skanningar, tunga aggregeringar och mycket läsgenomströmning. OLAP-system skalar ofta genom att lägga till distribuerad compute, och många moderna uppsättningar separerar compute från storage så du kan skala fråge-hästkrafter utan att duplicera data.
Om OLAP delar OLTP-databasen kan ni inte skala analysen självständigt. Ni skalar hela databasen — även om transaktionerna redan är tillräckliga.
Den dolda räkningen: betala OLTP-priser för analys
För att hålla transaktioner snabba medan rapporter körs över-provisionerar team produktionsdatabasen: extra CPU-headroom, high-end storage och större instanser "utifall att". Det betyder att ni betalar OLTP-priser för att stödja OLAP-beteende.
Separation minskar överprovisionering eftersom varje system kan dimensioneras för sitt jobb: OLTP för förutsägbara låglatens-skrivningar, OLAP för burstiga tunga läsningar. Resultatet blir ofta billigare totalt — även om det är "två system" — eftersom ni slutar köpa premium transaktionell kapacitet för att köra rapportering i produktion.
Vanliga arkitekturer som håller OLTP och OLAP isär
De flesta team separerar transaktionell arbetsbelastning (OLTP) från analysarbetsbelastning (OLAP) genom att lägga till ett andra "läsorienterat" system istället för att tvinga en databas att göra allt.
Mönster 1: Read replica för rapportering
Ett vanligt första steg är en read replica (eller follower) av OLTP-databasen, där BI-verktyg kör sina frågor.
Fördelar: minimala app-ändringar, bekant SQL, snabbt att ställa in.
Nackdelar: det är fortfarande samma motor och schema, så tunga rapporter kan mätta replica-CPU/I/O; vissa rapporter kräver funktioner som inte finns på repliker; och replikationslagg betyder att siffrorna kan vara minuter (eller mer) fördröjda. Lagg skapar också förvirring i incidenter: "varför stämmer det inte med produktion?"
Bäst för: små team, måttlig datavolym, där "nära realtid" är trevligt men inte kritiskt, och där rapportfrågor är kontrollerade.
Mönster 2: Dedikerat data warehouse / analysdatabas
Här hålls OLTP optimerat för skrivningar och punktläsningar, medan analys går till ett data warehouse (eller kolumnorienterad analys-DB) designat för skanning, kompression och tunga aggregeringar.
Fördelar: förutsägbar OLTP-prestanda, snabbare dashboards, bättre samtidighet för analytiker och tydligare kostnads-/prestandatuning.
Nackdelar: ni driver ytterligare ett system och behöver en datamodell (ofta stjärnschema) som är analysvänlig.
Bäst för: växande datamängder, många intressenter, komplex rapportering eller strikta OLTP-latenskrav.
Mönster 3: CDC-baserad pipeline till analys
Istället för periodisk ETL streamar ni förändringar med CDC (Change Data Capture) från OLTP-loggen in i lagret (ofta med ELT).
Fördelar: färskare data med mindre påverkan på OLTP, enklare inkrementell bearbetning och bättre audit-spårning.
Nackdelar: fler rörliga delar och noggrann hantering av schemaändringar.
Bäst för: större volymer, höga krav på färskhet och team redo för datapipelines.
Att få data från OLTP till OLAP säkert
Att flytta data från transaktionella databasen (OLTP) till ett analysystem (OLAP) handlar mindre om att "kopiera tabeller" och mer om att bygga en pålitlig, lågpåverkande pipeline. Målet är enkelt: analysen får det den behöver utan att hota produktionstrafiken.
ETL vs ELT (på enkelt språk)
ETL (Extract, Transform, Load) betyder att du rengör och formar data innan den landar i lagret. Det är användbart när warehouse-beräkningar är dyra eller om du vill strikt styra vad som sparas.
ELT (Extract, Load, Transform) laddar rådata först och transformerar i lagret. Detta är ofta snabbare att sätta upp och lättare att utveckla: du kan behålla historiken och justera transformationer när kraven ändras.
En praktisk regel: om affärslogiken ändras ofta minskar ELT omarbete; om styrning kräver endast kuraterad data kan ETL passa bättre.
CDC-grunder: fånga förändring utan tunga frågor
Change Data Capture (CDC) strömmar inserts/updates/deletes från OLTP (ofta från databassloggen) till ditt analysystem. Istället för att upprepade gånger skanna stora tabeller låter CDC dig flytta endast det som ändrats.
Vad det möjliggör:
- Nästan realtidsrapportering utan stora läsningar på produktion
- Replays och backfills när du behöver bygga om analys-tabeller
- Historikspårning (vem ändrade vad och när), om du sparar change events
Datans färskhet: realtid vs nära realtid vs dagligen
Färskhet är ett affärsbeslut med teknisk kostnad.
- Realtid (sekunder): bäst för operativa dashboards, men svårast att hålla stabilt; små pipeline-hiccup syns omedelbart.
- Nästa realtid (minuter): en vanlig sweet spot — bra för beslutsfattande utan extrem komplexitet.
- Dagliga batcher: enklast och billigast, utmärkt för finansrapportering där "igår" räcker.
Sätt ett tydligt SLA (t.ex. “data är högst 15 minuter efter”) så intressenter vet vad "färskt" betyder.
Datakvalitetskontroller som förhindrar tysta fel
Pipelines går ofta sönder tyst — tills någon upptäcker att siffrorna inte stämmer. Lägg in lätta kontroller för:
- Schemaändringar: nya kolumner, omdöpta fält eller typändringar som kan nolla data.
- Senanlända events: orders eller betalningar som dyker upp timmar senare; hantera med ett "lookback window".
- Deduplicering: retries och replays kan ge dubbelräkning; använd stabila ID:n och idempotent lastning.
Dessa skydd gör OLAP pålitligt samtidigt som OLTP skyddas.
När det kan vara acceptabelt att dela en databas
Tipsa en kollega och tjänar på det
Ta med kollegor med en referral och få krediter när nya användare ansluter.
Att hålla OLTP och OLAP tillsammans är inte automatiskt fel. Det kan vara en rimlig tillfällig lösning när appen är liten, rapporteringsbehoven snäva och ni kan införa hårda gränser så att analys inte överraskar era kunder med långsamma checkouts, misslyckade betalningar eller timeouts.
Situationer där det kan fungera
Små appar med lätt analys och strikta frågegränser klarar sig ofta med en databas — särskilt tidigt. Nyckeln är att vara ärlig om vad "lätt" betyder: ett fåtal dashboards, måttliga raddata och ett tydligt tak på frågetid och samtidighet.
För en snäv uppsättning återkommande rapporter kan materialized views eller summeringstabeller minska analyskostnaden. Istället för att skanna råtransaktioner prekompilerar du dagliga totalsummor, toppkategorier eller per-kund-rollups. Det håller de flesta frågor korta och förutsägbara.
Om användarna kan acceptera fördröjda siffror hjälper off-peak rapportfönster. Schemalägg tyngre jobb nattetid eller under lågtrafik, och överväg en dedikerad rapporteringsroll med stramare behörigheter och resursbegränsningar.
Guardrails du bör lägga till
- Sätt statement timeouts och avbryt runaway-frågor.
- Begränsa samtidighet för rapportanvändare.
- Övervaka p95/p99-latens för kärntransaktioner separat från rapporteringsmått.
Tydliga varningstecken att det är dags att dela
Om du ser ökande transaktionslatens, återkommande incidenter under rapportkörningar, connection pool-exhaustion eller historier om “en fråga tog ner produktion” är du förbi säkerhetszonen. Då blir separation (eller åtminstone read replicas) inte längre en optimering utan grundläggande drift-hygien.
Praktisk migrationschecklista: från delad till separerad
Att flytta analys bort från produktionsdatabasen handlar mindre om en stor omskrivning och mer om att göra arbetet synligt, sätta mål och migrera i kontrollerade steg.
1) Inventera vad som verkligen händer idag
Börja med bevis, inte antaganden. Ta fram en lista över:
- Topp OLTP-endpoints/frågor efter frekvens och p95/p99-latens (checkout, login, skapa order etc.)
- Topp OLAP-rapporter/dashboards efter körruntime, skanningsvolym och affärsvikt
Inkludera "dold" analys: ad-hoc SQL från BI-verktyg, schemalagda exports och CSV-nedladdningar.
2) Definiera mål: OLTP SLO:er och analysfärskhet
Skriv ner de mål ni ska optimera för:
- OLTP SLO:er: p95/p99-latens, felprocent och toppgenomströmning ni måste klara
- Analysfärskhet: hur gammal data får vara (5 minuter, 1 timme, nästa dag), plus tid att bygga om om pipelinen går sönder
Detta förhindrar gräl som “det är långsamt” vs “det är okej” och hjälper er välja rätt arkitektur.
3) Välj en separationsväg
Välj enklaste alternativet som möter målen:
- Read replica: snabb att anta för lästung rapportering, men kan fortfarande stressas av dyra frågor och ger replikationslagg
- Warehouse: bäst för stora skanningar, många joins och lång historik; vanligtvis rätt hem för BI
- CDC-pipeline (ETL/ELT): bäst när ni behöver nära realtid utan att slå mot produktion
4) Rulla ut säkert (parallellt först)
- Validera definitioner (tidszoner, refunds, “aktiv användare” etc.) så siffrorna stämmer.
- Kör gamla och nya dashboards parallellt under en full affärscykel.
- Skifta över rapport för rapport, börja med de mest smärtsamma frågorna.
- Lås ner direkt "rapportering på produktion" när intressenter litar på den nya källan.
5) Lägg in skydd så ni inte backar tillbaka
Sätt upp övervakning för replica-lagg/pipeline-förseningar, dashboard-körtider och warehouse-kostnader. Lägg in frågebudgetar (timeouts, samtidighetsgränser) och ha en incident-playbook: vad gör vi när färskhet glider, belastning spikar eller nyckelmått divergerar?
Ett praktiskt tips om ni bygger appen själva
Om ni är tidigt i produkten och rör er snabbt är den största risken att av misstag bygga analys direkt i samma databasväg som kärntransaktioner (t.ex. dashboard-frågor som tyst blir "produktion-kritiska"). Ett sätt att undvika det är att designa separationen från början — även om ni börjar med en enkel read replica — och baka in det i er arkitekturchecklista.
Plattformar som Koder.ai kan hjälpa eftersom ni kan prototypa OLTP-sidan (React app + Go services + PostgreSQL) och skissa rapporterings-/warehouse-gränsen i planeringsläge innan ni släpper. När produkten växer kan ni exportera koden, utveckla schemat och lägga till CDC/ELT-komponenter utan att göra "rapportering i produktion" till en permanent vana.