15 nov. 2025·8 min
Skapa en webbapp för lagerprognoser och behovsplanering
Planera och bygg en webbapp för lagerprognoser och behovsplanering: datainställning, prognosmetoder, UX, integrationer, testning och driftsättning.
Planera och bygg en webbapp för lagerprognoser och behovsplanering: datainställning, prognosmetoder, UX, integrationer, testning och driftsättning.
En webbapp för lagerprognoser och behovsplanering hjälper ett företag att avgöra vad som ska köpas, när det ska köpas och hur mycket som ska köpas—baserat på förväntad framtida efterfrågan och aktuell lagerposition.
Lagerprognoser förutspår försäljning eller förbrukning för varje SKU över tid. Behovsplanering förvandlar dessa prognoser till beslut: beställningspunkter, beställningskvantiteter och tidpunkter som stämmer med service‑mål och kassaflödesbegränsningar.
Utan ett tillförlitligt system förlitar sig team ofta på kalkylblad och magkänsla. Det leder vanligtvis till två kostsamma utfall:
En väl utformad webbapp för lagerprognoser skapar en gemensam sanning för efterfrågeförväntningar och rekommenderade åtgärder—så beslut blir konsekventa över platser, kanaler och team.
Trovärdighet och noggrannhet byggs över tid. Din MVP för behovsplanering kan börja med:
När användarna anammar arbetsflödet kan du successivt förbättra noggrannheten med bättre data, segmentering, hantering av kampanjer och smartare modeller. Målet är inte en "perfekt" prognos—det är en repeterbar beslutsprocess som blir bättre för varje cykel.
Typiska användare inkluderar:
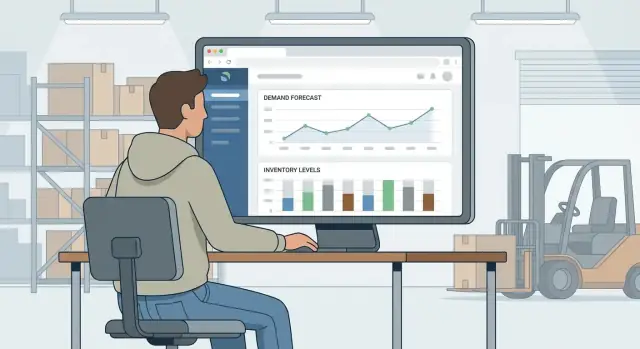
Bedöm appen efter affärsresultat: färre lagerslut, lägre överskott och tydligare inköpsbeslut—allt synligt i en lagerplaneringspanel som gör nästa åtgärd uppenbar.
En webbapp för lagerprognoser vinner eller förlorar på tydlighet: vilka beslut ska den stödja, för vem och på vilken detaljnivå? Innan modeller och diagram, definiera den minsta uppsättning beslut som ditt MVP måste förbättra.
Skriv dem som åtgärder, inte funktioner:
Om du inte kan knyta en vy till en av dessa frågor bör det sannolikt vänta till senare faser.
Välj en horisont som matchar ledtider och inköpsrytm:
Välj sedan uppdateringsfrekvens: dagligen om försäljningen ändrar sig snabbt, veckovis om inköp sker i fasta cykler. Din frekvens bestämmer också hur ofta appen kör jobb och uppdaterar rekommendationer.
Den "rätta" nivån är den nivå människor faktiskt kan köpa och flytta lager på:
Gör framgång mätbar: servicegrad / lagerslutsfrekvens, lageromsättning och prognosfel (t.ex. MAPE eller WAPE). Knyt mätvärden till affärsutfall som att förebygga lagerslut och minska överlager.
MVP: en prognos per SKU(‑plats), en enkel beräkning av beställningspunkt, ett enkelt godkänn/export‑arbetsflöde.
Senare: multi‑echelon‑optimering, leverantörsbegränsningar, kampanjer och scenarioplanering.
Prognoser är bara lika användbara som de ingångar de bygger på. Innan du väljer modeller eller bygger vyer, klargör vad du har för data, var den finns och vad som är "tillräckligt bra" för ett MVP.
Minst behöver lagerprognoser en konsekvent vy av:
De flesta team hämtar från en mix av system:
Bestäm hur ofta appen uppdateras (timvis, dagligen) och vad som händer när data kommer sent eller redigeras. Ett praktiskt mönster är att behålla oförändrad transaktionshistorik och applicera justeringsposter istället för att skriva över gårdagens siffror.
Tilldela en ägare för varje dataset (t.ex. lager: lagerdrift; ledtider: inköp). Ha en kort datadictionary: fältets betydelse, enheter, tidszon och tillåtna värden.
Räkna med problem som saknade ledtider, enhetskonverteringar (styck vs låda), returer och avbeställningar, dubblett‑SKU:er och inkonsekventa platskoder. Flagga dem tidigt så ditt MVP antingen kan rätta, använda standardvärden eller exkludera dem—tydligt och synligt.
En prognosapp vinner eller förlorar på om alla litar på siffrorna. Det förtroendet börjar med en datamodell som gör "vad som hände" (försäljning, mottagningar, överföringar) entydigt och gör "vad som är sant nu" (on‑hand, on‑order) konsekvent.
Definiera ett litet set entiteter och håll dig till dem i hela appen:
Välj daglig eller veckovis som din kanoniska tidsgrovlek. Tvinga sedan varje input att matcha den: orders kan vara tidsstämplade, lagerräkningar är slutet‑på‑dagen och fakturor kan postas senare. Gör din regler för inplacering explicit (t.ex. "försäljning hör till leveransdatum, bucketerad per dag").
Om du säljer i styck/förpackning/kg, spara både originalenhet och en normaliserad enhet för prognoser (t.ex. "styck"). Om du prognostiserar intäkter, behåll originalvaluta plus en normaliserad rapporteringsvaluta med valutakälla.
Spåra lager som en sekvens av händelser per SKU‑plats‑tid: on‑hand‑snapshots, on‑order, mottagningar, överföringar och justeringar. Det gör förklaringar av lagerslut och revisionsspår mycket enklare.
För varje nyckelmetrik (enhetsförsäljning, on‑hand, ledtid) bestäm en auktoritativ källa och dokumentera den i schemat. När två system motsäger varandra ska din modell visa vilken som vinner—och varför.
Ett prognos‑UI är bara lika bra som datan som matas in. Om siffror ändrar sig utan förklaring tappar användarna förtroendet—även om modellen i sig är bra. Din ETL bör göra data förutsägbar, felsökningsbar och spårbar.
Börja med att skriva ner "sanningens källa" för varje fält (orders, leveranser, on‑hand, ledtider). Implementera sedan ett repeterbart flöde:
Behåll två lager:
När en planner frågar "Varför ändrades förra veckans efterfrågan?" ska du kunna peka på raw‑posten och transformen som berörde den.
Minst ska du validera:
Avbryt körningen (eller karantänsätt den berörda partitionen) istället för att tyst publicera dåliga data.
Om inköp sker veckovis räcker vanligtvis en daglig batch. Använd nära realtid bara när operativa beslut kräver det (samma‑dags påfyllning, kraftiga e‑handelsvängningar), eftersom det ökar komplexitet och larmvolym.
Dokumentera vad som händer vid fel: vilka steg försöker igen automatiskt, hur många gånger och vem som notifieras. Skicka larm när extraktioner bryter, rader minskar kraftigt eller valideringar misslyckas—och behåll en körlogg så du kan revidera varje prognosingång.
Prognosmetoder är inte "bättre" i abstrakt mening—de är bättre för din data, dina SKU:er och din planeringsrytm. En bra webbapp gör det enkelt att börja enkelt, mäta resultat och senare gå vidare till avancerade modeller där det faktiskt lönar sig.
Baslinjer är snabba, förklarliga och utmärkta som sundhetstest. Inkludera åtminstone:
Rapportera alltid prognosnoggrannhet jämfört med dessa baslinjer—om en komplex modell inte kan slå dem bör den inte vara i produktion.
När MVP:n är stabil, lägg till några "step‑up"‑modeller:
Du kan leverera snabbare med en standardmodell och några parametrar. Men ofta får du bättre resultat med per‑SKU‑modellval (välj bästa modellfamilj baserat på backtests), särskilt när katalogen blandar stabila bästsäljare, säsongsvaror och långsvansprodukter.
Om många SKU:er har många nollor, behandla det som en egen kategori. Lägg till metoder lämpade för intermittent efterfrågan (t.ex. Croston‑approacher) och utvärdera med mått som inte bestraffar nollor orättvist.
Planners behöver overrides för lanseringar, kampanjer och kända störningar. Bygg ett override‑arbetsflöde med skäl, utgångsdatum och revisionsspår, så manuella ändringar förbättrar beslut utan att dölja vad som hänt.
Prognosnoggrannhet bygger ofta på features: den extra kontext du tillför utöver "försäljning förra veckan". Målet är inte att lägga till hundratals signaler—det är att lägga till ett litet set som speglar hur verksamheten beter sig och som planners kan förstå.
Efterfrågan har ofta en rytm. Lägg till några kalenderfunktioner som fångar den rytmen utan att överanpassa:
Om kampanjer är röriga, börja med en enkel "på kampanj"‑flagga och raffinera senare.
Lagerprognoser handlar inte bara om efterfrågan—även tillgänglighet spelar roll. Användbara, förklarliga signaler inkluderar prisändringar, ledtidsuppdateringar och leverantörsbegränsningar. Överväg att lägga till:
En dag med lagerslut och noll försäljning betyder inte noll efterfrågan. Om du matar in de nollorna lär sig modellen att efterfrågan försvann.
Vanliga metoder:
Nya artiklar saknar historik. Definiera tydliga regler:
Håll featuresen få och namnge dem i affärstermer i appen (t.ex. “Helgvecka” istället för “x_reg_17”) så planners kan lita på—och ifrågasätta—vad modellen gör.
En prognos är bara användbar när den berättar för någon vad som ska göras härnäst. Din webbapp bör omvandla predicerad efterfrågan till specifika, granskbara inköpsåtgärder: när beställa, hur mycket köpa och hur mycket buffert att hålla.
Börja med tre outputs per SKU (eller SKU‑plats):
En praktisk struktur är:
Om du kan mäta det, inkludera ledtidsvariabilitet (inte bara medelvärde). Även en enkel standardavvikelse per leverantör kan märkbart minska lagerslut.
Inte varje artikel förtjänar samma skydd. Låt användare välja servicegradsmål efter ABC‑klass, marginal eller kritikalitet:
Rekommendationer måste vara genomförbara. Lägg in hantering för:
Varje föreslaget köp bör inkludera en kort förklaring: prognostiserad efterfrågan under ledtid, aktuell lagerposition, vald servicegrad och vilka begränsningar som applicerats. Det bygger förtroende och gör undantag lätta att godkänna.
En prognosapp är lättare att underhålla när du behandlar den som två produkter: en webupplevelse för människor och en prognosmotor som körs i bakgrunden. Den separationen håller UI snabbt, förhindrar timeout och gör resultat reproducerbara.
Börja med fyra byggstenar:
Nyckelbeslut: prognoskörningar bör aldrig köras inom ett UI‑anrop. Placera dem på en kö (eller schemalagda jobb), returnera ett run ID och streama progress i UI.
Om du vill snabba upp MVP‑bygget kan en vibe‑kodningsplattform som Koder.ai vara ett praktiskt val för denna arkitektur: du kan prototypa en React‑UI, en Go‑API med PostgreSQL och bakgrundsflöden från en enda chattdriven byggloop—och exportera källkoden när du är redo att hårdlansera eller self‑hosta.
Behåll "system of record"‑tabeller (tenants, SKUs, platser, run‑konfig, run‑status, godkännanden) i din primära databas. Spara stora outputs—per‑dag prognoser, diagnostik och exportfiler—in i tabeller optimerade för analys eller i objektlagring, och referera dem via run ID.
Om du tjänar flera affärsenheter eller kunder, upprätthåll tenant‑gränser i API‑lagret och i databasens schema. Ett enkelt tillvägagångssätt är tenant_id på varje tabell, samt rollbaserad åtkomst i UI. Även ett single‑tenant MVP vinner på detta eftersom det förhindrar oavsiktlig datablandning senare.
Sikta på en liten, tydlig yta:
POST /data/upload (eller connectors), GET /data/validationPOST /forecast-runs (starta), GET /forecast-runs/:id (status)GET /forecasts?run_id=... och GET /recommendations?run_id=...POST /approvals (acceptera/överskugga), GET /audit-logsPrognoser kan bli kostsamma. Begränsa tunga retrains genom att cachea features, återanvända modeller när konfigurationer inte ändras och schemalägga fulla retrains (t.ex. veckovis) medan du kör lätta dagliga uppdateringar. Det håller UI responsivt och budgeten stabil.
En prognosmodell är bara värdefull om planners kan agera snabbt och tryggt. Bra UX förvandlar "siffror i en tabell" till tydliga beslut: vad som ska köpas, när och vad som kräver uppmärksamhet nu.
Börja med ett litet set skärmar som speglar dagliga planeringsuppgifter:
Behåll navigeringen konsekvent så användare kan hoppa från ett undantag till SKU‑detalj och tillbaka utan att tappa kontext.
Planners segmenterar data konstant. Gör filtrering omedelbar och förutsägbar för datumintervall, plats, leverantör och kategori. Använd vettiga standardinställningar (t.ex. senaste 13 veckor, primärt lager) och kom ihåg användarens senaste val.
Bygg förtroende genom att visa varför en prognos ändrats:
Undvik tung matematik i UI; fokusera på vardagligt språk och verktygstips.
Lägg till lättviktssamarbete: inline‑anteckningar, ett godkännande‑steg för stora ordrar och ändringshistorik (vem ändrade override, när och varför). Det stödjer auditbarhet utan att bromsa rutinbeslut.
Även moderna team delar filer. Erbjud rena CSV‑exporter och en utskriftsvänlig orderöversikt (artiklar, kvantiteter, leverantör, totalsummor, önskat leveransdatum) så inköp kan utföra utan omformatering.
Prognoser är bara användbara i den mån systemen de kan uppdatera—and de människor som kan lita på dem. Planera integrationer, åtkomstkontroll och revisionsspår tidigt så din app kan gå från "intressant" till "operationell".
Börja med kärnobjekten som styr lagerbeslut:
Var tydlig med vilket system som är sanningskälla för varje fält. T.ex. SKU‑status och UOM från ERP, men prognosöverstyrningar från din app.
De flesta team behöver en väg som fungerar nu och en som skalar senare:
Oavsett väg, spara importloggar (radantal, fel, tidsstämplar) så användare kan diagnostisera saknad data utan hjälp från utveckling.
Definiera behörigheter utifrån hur verksamheten fungerar—vanligtvis per plats och/eller avdelning. Vanliga roller är Viewer, Planner, Approver och Admin. Se till att känsliga åtgärder (ändra parametrar, godkänna PO:er) kräver rätt roll.
Spåra vem som ändrade vad, när och varför: prognosöverstyrningar, ändringar av beställningspunkter, ledtidsjusteringar och godkännande‑beslut. Behåll diffar, kommentarer och länkar till berörda rekommendationer.
Om du publicerar KPI:er för prognoser, länka definitionerna i appen eller hänvisa till dokumentation om prognosnoggrannhet. För rollout‑planering kan en enkel stegvis åtkomstmodell kopplas till prissättningen.
En prognosapp är bara användbar om du kan bevisa att den presterar—och om du snabbt kan se när den slutar prestera. Testning är inte bara "fungerar koden" utan "förbättrar prognoserna och rekommendationerna utfallet?"
Börja med ett litet set mått som alla förstår:
Rapportera dessa per SKU, kategori, plats och prognoshorisont (nästa vecka vs nästa månad beter sig ofta olika).
Backtesting bör spegla hur appen körs i produktion:
Lägg larm när noggrannheten plötsligt sjunker eller när ingångar ser felaktiga ut (saknad försäljning, dubbletter, ovanliga spikar). En liten övervakningspanel i ditt adminområde kan förhindra veckor av dåliga inköpsbeslut.
Innan full lansering, kör en pilot med ett litet grupp planners/inköpare. Spåra om rekommendationerna accepterades eller avvisades, och varför. Den feedbacken blir träningsdata för regeljusteringar, undantag och bättre standardvärden.
Prognosappar berör ofta mycket känsliga delar av en verksamhet: försäljningshistorik, leverantörspriser, lagerpositioner och kommande inköpsplaner. Behandla säkerhet och drift som produktfunktioner—en läckt export eller ett brutet nattjobb kan radera månaders förtroende.
Skydda känslig affärsdata med principen om minsta privilegium. Börja med roller som Viewer, Planner, Approver och Admin, och dölj åtgärder (inte bara sidor): visa kostnader, ändra parametrar, godkänna rekommendationer och exportera data.
Om du integrerar med en identitetsleverantör (SSO), mappa grupper till roller så avstängning blir automatisk.
Kryptera data i transit och där det är möjligt i vila. Använd HTTPS överallt, rotera API‑nycklar och lagra hemligheter i en hanterad källare snarare än i miljöfiler på servrar. För databaser, aktivera kryptering i vila och begränsa nätverksåtkomst till endast appen och jobbrunners.
Logga åtkomst och kritiska åtgärder (exporter, ändringar, godkännanden). Behåll strukturerade loggar för:
Det här är inte byråkrati—det är hur du felsöker överraskningar i en lagerplaneringspanel.
Definiera retention för uppladdningar och historiska körningar. Många team behåller raw‑uppladdningar kort (t.ex. 30–90 dagar) och behåller aggregerade resultat längre för trendanalys.
Förbered en incident‑ och backupplan: vem är på larm, hur återkallas åtkomst och hur återställer man databasen. Testa återställningar regelbundet och dokumentera återställningstider för API, jobb och lagring så din behovsplaneringsmjukvara förblir tillförlitlig under stress.
Börja med att definiera de beslut appen måste förbättra: hur mycket att beställa, när att beställa och för vilken plats/kanal (SKU, lager, kanal). Välj därefter en praktisk planeringshorisont (t.ex. 4–12 veckor) och en enda tidsgrovlek (daglig eller veckovis) som matchar hur verksamheten köper och fyller på.
Ett bra MVP brukar innehålla:
Spara resten (kampanjer, scenarioplanering, multiechelon‑optimering) till senare faser.
Minimalt behöver du:
Skapa en datadictionary och tvinga konsistens i:
I pipelinen: lägg automatiska kontroller för saknade nycklar, negativa lager, dubbletter och avvikare—kvalificera eller karantänsätt istället för att publicera felaktiga data.
Behandla lager som en samling händelser och ögonblicksbilder:
Detta gör det enkelt att spåra vad som hände och håller "vad som är sant nu" konsekvent. Det förenklar också förklaringar vid lagerslut och rekonsiliering mellan ERP, WMS och POS/e‑handelskällor.
Börja med enkla, förklarliga baslinjer och behåll dem alltid:
Använd backtester för att bevisa att en avancerad modell faktiskt slår dessa. Lägg till komplexitet först när du kan mäta förbättring och har tillräckligt ren historik och drivare.
Låt inte stockout‑nollor gå rakt in i träningsmålet. Vanliga metoder:
Det viktiga är att inte lära modellen att efterfrågan försvann när problemet var tillgänglighet.
Använd explicita cold‑start‑regler, t.ex.:
Visa dessa regler i UI så planners vet när en prognos är proxy‑baserad kontra datadriven.
Konvertera prognoser till tre konkreta outputs:
Applicera sedan verkliga begränsningar som MOQ och förpackningsstorlekar (avrunda), budgetgränser (prioritering) och kapacitetsbegränsningar (plats/pallar). Visa alltid "varför" bakom varje rekommendation.
Separera UI från prognosmotorn:
Kör aldrig en prognos i ett UI‑anrop—använd en kö eller schemaläggare, returnera ett run ID och visa status/progress i appen. Spara stora outputs (prognoser, diagnostik) i analysvänligt lagringsformat och referera dem via run ID.
Om något av detta är opålitligt, gör luckan synlig (standardvärden, flaggor, undantag) istället för att gissa tyst.