04 apr. 2025·8 min
Hur du bygger en webbapp för att spåra intern verktygspålitlighet
Lär dig hur du designar och bygger en webbapp som spårar intern verktygspålitlighet med SLIs/SLOs, incidentflöden, dashboards, aviseringar och rapportering.
Sätt mål och avgränsning för pålitlighetsspårning
Innan ni väljer mätvärden eller bygger dashboards, bestäm vad er pålitlighetsapp ansvarar för — och vad den inte gör. En tydlig omfattning förhindrar att verktyget blir en allt‑täcker “ops‑portal” som ingen litar på.
Definiera vad ni spårar
Börja med att lista de interna verktyg appen ska omfatta (t.ex. ticketing, löner, CRM‑integrationer, datapipelines) och de team som äger eller är beroende av dem. Var tydlig med gränser: “kundvända webbplatsen” kan vara utanför, medan “intern adminkonsol” är inom.
Kom överens om vad “pålitlighet” betyder här
Olika organisationer använder ordet olika. Skriv ner er arbetande definition på enkelt språk — vanligtvis en blandning av:
- Tillgänglighet: kan folk komma åt det när det behövs?
- Latens: är det tillräckligt snabbt för att vara användbart?
- Fel: misslyckas det på sätt användare märker (timeouts, jobbfel, dåliga svar)?
Om teamen inte är överens kommer appen att jämföra äpplen och päron.
Bestäm vilka utfall ni vill ha
Välj 1–3 primära utfall, som till exempel:
- Snabbare upptäckt av problem (kortare “time to notice”)\n- Tydligare rapportering för chefer och intressenter\n- Färre upprepade incidenter genom bättre uppföljning
Dessa utfall styr senare vad ni mäter och hur ni presenterar det.
Identifiera användare och roller
Lista vem som använder appen och vilka beslut de fattar: ingenjörer som utreder incidenter, support som eskalerar, chefer som granskar trender och intressenter som behöver statusuppdateringar. Detta påverkar terminologi, behörigheter och detaljnivån för varje vy.
Välj de pålitlighetsmått som spelar roll (SLI/SLO)
Pålitlighetsspårning fungerar bara om alla är överens om vad som är “bra”. Börja med att skilja mellan tre liknande termer.
SLIs vs SLOs vs SLAs (enkelt språk)
En SLI (Service Level Indicator) är en mätning: “Hur stor andel förfrågningar lyckades?” eller “Hur lång tid tog sidorna att ladda?”
En SLO (Service Level Objective) är målet för den mätningen: “99,9% lyckade under 30 dagar.”
Ett SLA (Service Level Agreement) är ett löfte med konsekvenser, vanligtvis externt (krediter, påföljder). För interna verktyg sätter ni ofta SLO:er utan formella SLA:er — tillräckligt för att skapa samsyn utan att göra pålitlighet till kontraktsrätt.
Välj en liten, konsekvent uppsättning SLI:er per verktyg
Håll det jämförbart mellan verktyg och lätt att förklara. En praktisk bas är:
- Uptime/tillgänglighet: var verktyget nåbart?\n- Responstid: hur snabbt svarade viktiga sidor eller endpoints?\n- Felkvot: hur stor andel kontroller eller förfrågningar misslyckades (5xx, timeouts, kända felstatusar)?
Undvik att lägga till fler tills ni kan svara: “Vilket beslut kommer denna mätning att driva?”
Välj tidsfönster som matchar hur folk tänker
Använd rullande fönster så scorecards uppdateras kontinuerligt:
- 7 dagar: fånga regressioner snabbt\n- 30 dagar: månadsrapportering och trender\n- 90 dagar: stabilitet över kvartal
Definiera incidenter med tydliga sevritetsnivåer
Appen ska göra om mätvärden till handling. Definiera sevritetsnivåer (t.ex. Sev1–Sev3) och explicita triggers såsom:
- Sev1: verktyget är nere eller ett kritiskt arbetsflöde blockerat under X minuter\n- Sev2: större degradering (t.ex. felkvot över Y% under Z minuter)\n- Sev3: mindre problem eller intermittenta fel
Dessa definitioner gör aviseringar, incidenttidslinjer och error‑budget‑spårning konsekventa mellan team.
Planera datakällor och ingest‑strategi
En tracking‑app är bara så trovärdig som datan bakom den. Innan ni bygger pipelines, mappa varje signal ni kommer att betrakta som “sanning” och skriv ner vilken fråga den svarar på (tillgänglighet, latens, fel, deploy‑påverkan, incidentrespons).
Mappa befintliga datakällor
De flesta team kan täcka grunderna med en mix av:
- Statuskontroller / syntetiska probes (uptime och grundläggande responstid)\n- Metrics (latenspercentiler, felkvoter, saturation)\n- Logs (antal fel, mest frekventa misslyckade endpoints)\n- Traces (var latens spenderas över beroenden)\n- Ticketing/incident‑verktyg (incident start/slut, sevritet, ägare, postmortem‑länkar)
Var tydlig med vilka system som är auktoritativa. Till exempel kan er “uptime SLI” enbart komma från syntetiska probes, inte serverloggar.
Bestäm push vs pull (och hur ofta)
- Pull fungerar bra för API:er (Prometheus, cloud monitoring, ticketing): er app pollar enligt schema.\n- Push är bättre för hög‑volymhändelser (deploys, incidenter, alerts): system skickar webhooks/händelser till appen.
Sätt uppdateringsfrekvens efter användningsfall: dashboards kan uppdateras var 1–5 minuter, medan scorecards kan beräknas timvis/dagligen.
Normalisera identifierare och ägarskap
Skapa konsekventa ID:n för verktyg/tjänster, miljöer (prod/stage) och ägare. Kom överens om namngivningsregler tidigt så att “Payments‑API”, “payments_api” och “payments” inte blir tre separata entiteter.
Retention och integritet
Planera vad ni sparar och hur länge (t.ex. råa events 30–90 dagar, dagliga aggregeringar 12–24 månader). Undvik att ta in känsliga payloads; lagra bara metadata som behövs för analyser (tidsstämplar, statuskoder, latenskategorier, incidenttaggar).
Designa datamodellen och databasschemat
Ert schema bör göra två saker enkla: besvara vardagsfrågor (“är detta verktyg friskt?”) och återskapa vad som hände under en incident (“när började symptom, vem ändrade vad, vilka alerts gick av?”). Börja med ett litet set kärn‑entiteter och gör relationerna explicita.
Kärn‑entiteter (börja minimalt)
- Tool/Service: det interna verktyget som spåras (namn, beskrivning, miljö, kritikalitet).\n- Check: en specifik uptime eller syntetisk kontroll kopplad till ett verktyg (typ, mål‑URL, schema, aktiverad).\n- Metric: tidsseriedatapunkter (latens, framgångsgrad, antal fel) associerade med ett verktyg eller check.\n- SLO: målet och utvärderingsfönstret (t.ex. 99,9% över 30 dagar) plus inställningar för error budget.\n- Incident: en pålitlighets‑påverkande händelse (sevritet, status, start/slut, sammanfattning).\n- Event: en tidslinjepost för incidenter (statusändringar, noteringar, mottagen alert, applicerad mildring).\n- Owner: ett team eller en individ ansvarig för verktyget.
Relationer som förenklar frågor
Ett praktiskt baseline är:
- Tool har många Checks (och kan ha flera SLO:er).\n- Check har många Metrics (eller metric‑strömmar).\n- Incident tillhör Tool, och Incident har många Events för tidslinjen.\n- Tool tillhör Owner (eller många‑till‑många om delat ägarskap är vanligt).
Denna struktur stöder dashboards (“tool → aktuell status → senaste incidenter”) och drill‑down (“incident → events → relaterade checks och metrics”).
Audit‑fält och taggning
Lägg till auditfält där ni behöver ansvarstagande och historik:\n\n- created_by, created_at, updated_at\n- status plus statusändringsspårning (antingen i Event‑tabellen eller en dedikerad historiktabell)
Slutligen, inkludera flexibla taggar för filtrering och rapportering (t.ex. team, kritikalitet, system, compliance). En tool_tags join‑tabell (tool_id, key, value) håller taggning konsekvent och gör scorecards och rollups mycket enklare senare.
Välj tech‑stack och driftsmodell
Ert tracker‑system bör vara tråkigt på bästa sätt: lätt att köra, lätt att ändra och lätt att underhålla. Den “rätta” stacken är oftast den ert team kan underhålla utan hjältedåd.
Börja med det teamet redan levererar
Välj ett mainstream webbramverk teamet kan väl — Node/Express, Django eller Rails är alla stabila alternativ. Prioritera:\n\n- Klara konventioner (så nya bidragsgivare inte går vilse)\n- Bra bibliotek för auth, bakgrundsjobb och diagram\n- Förutsägbara uppgraderingsvägar
Om ni integrerar med interna system (SSO, ticketing, chat) välj det ekosystem där integrationerna är enklast för er.
Om ni vill snabba upp första iterationen kan en vibe‑kodningsplattform som Koder.ai vara ett praktiskt startsteg: beskriv era entiteter (tools, checks, SLO:er, incidenter), arbetsflöden (alert → incident → postmortem) och dashboards i chatten, och generera snabbt en fungerande appstomme. Eftersom Koder.ai ofta riktar sig mot React för frontend och Go + PostgreSQL för backend, matchar det väl det “tråkiga, underhållsbara” standardstack som många team föredrar — och ni kan exportera källkoden senare om ni vill byta till en helmanuell pipeline.
Databas först, lägg till stödfunktioner senare
För de flesta interna pålitlighetstjänster är PostgreSQL ett rätt default: hanterar relationell rapportering, tidsbaserade frågor och auditing bra.
Lägg till extra komponenter bara när de löser ett verkligt problem:\n\n- Cache (t.ex. Redis) om dashboards är långsamma eller ni är rate‑begränsade av upstream API:er\n- Kö/bakgrundsjobb (Redis + worker, Sidekiq, Celery, BullMQ) för polling av uptime, skicka notifikationer och generera rapporter
Hosting och driftsval
Väg mellan:\n\n- Intern moln/Kubernetes när ni behöver tajtare nätverksåtkomst till interna tjänster\n- PaaS när ni vill ha enklare drift och snabbare iteration
Oavsett val, standardisera dev/stage/prod och automatisera deployment (CI/CD) så förändringar inte tyst ändrar pålitlighetssiffror. Om ni använder en plattformsapproach (inklusive Koder.ai), leta efter funktioner som miljöseparation, hosting och snabb rollback (snapshots) så ni kan iterera säkert utan att bryta trackern själv.
Konfigurationshantering ni litar på
Dokumentera konfiguration på ett ställe: miljövariabler, hemligheter och feature flags. Ha en tydlig “hur kör jag lokalt”‑guide och ett minimalt runbook (vad göra om ingestion slutar, kön backar upp, eller databasen når gränser). En kort sida i /docs räcker ofta.
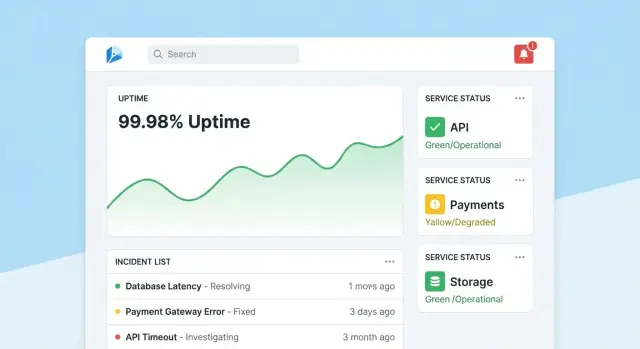
Designa UX: dashboards, drill‑downs och arbetsflöden
Skissa ditt MVP för pålitlighetsspårning
Beskriv verktyg, SLI:er och arbetsflöden i chatten och få en fungerande app‑stomme snabbt.
En pålitlighetsspårningsapp lyckas när folk kan svara två frågor på sekunder: “Är vi okej?” och “Vad gör jag näst?” Designa skärmar runt dessa beslut, med tydlig navigering från översikt → specifikt verktyg → specifik incident.
Startsida: snabb hälsoläsning
Gör startsidan till ett kompakt kommandocenter. Led med en övergripande hälsosummering (t.ex. antal verktyg som uppfyller SLO:er, aktiva incidenter, största nuvarande risker), och visa sedan senaste incidenter och alerts med status‑badges.
Håll standardvyn lugn: lyft bara det som kräver uppmärksamhet. Ge varje ruta direkt drill‑down till berört verktyg eller incident.
Verktygssida: från status till handling
Varje verktygssida bör svara “Är detta verktyg tillräckligt pålitligt?” och “Varför/varför inte?” Inkludera:\n\n- Aktuell SLO‑status med enkel godkänd/icke‑godkänd‑indikator och kvarvarande error budget\n- Diagram för uptime, latens eller felkvot över valbara tidsintervall\n- Senaste förändringar (deploys, konfigändringar, check‑uppdateringar) så mönster blir uppenbara\n- Runbooks och ägare: en framträdande “Vad göra”‑sektion med länkar och kontakter
Designa diagram för icke‑experter: märk enheter, markera SLO‑trösklar och lägg till små förklaringar (tooltips) istället för täta tekniska kontroller.
Incidentssida: delad kontext och tidslinje
En incidentssida är ett levande dokument. Inkludera en tidslinje (autoinspelade händelser som alert skickad, bekräftad, mildrad), mänskliga uppdateringar, påverkade användare och vidtagna åtgärder.
Gör uppdateringar enkla: en textbox, fördefinierade statusar (Investigating/Identified/Monitoring/Resolved) och valfria interna noteringar. När incidenten stängs bör en “Starta postmortem”‑åtgärd förifylla fakta från tidslinjen.
Adminsidor: ägarskap och konsistens
Admins behöver enkla vyer för att hantera verktyg, checks, SLO‑mål och ägare. Optimera för korrekthet: vettiga standardvärden, validering och varningar när ändringar påverkar rapportering. Lägg till en synlig “senast redigerad”‑spårning så folk litar på siffrorna.
Implementera autentisering, behörigheter och revisionsspår
Pålitlighetsdata förblir användbar bara om folk litar på den. Det betyder att varje ändring måste knytas till en identitet, begränsa vem som kan göra högpåverkande ändringar och ha en tydlig historik att hänvisa till vid granskningar.
Autentisering: använd vad företaget redan har
För ett internt verktyg, defaulta till SSO (SAML) eller OAuth/OIDC via er identitetsprovider (Okta, Azure AD, Google Workspace). Det minskar lösenordshantering och gör onboard/offboard automatiskt.
Praktiska detaljer:\n\n- Tvinga MFA via IdP (implementera inte det igen).\n- Mappa IdP‑grupper till approller vid inloggning.\n- Sätt korta sessionslivslängder och stöd manuell utloggning.
Behörigheter: rollbaserat med “skyddade åtgärder”
Börja med enkla roller och lägg till mer finmaskiga regler bara vid behov:\n\n- Visare (Viewer): skrivskyddade dashboards och scorecards för intressenter.\n- Redigerare (Editor): skapa/uppdatera checks, incidenter och noteringar.\n- Admin: hantera SLO‑definitioner, trösklar, integrationer och användar/roll‑mappning.
Skydda åtgärder som kan ändra pålitlighetsresultat eller rapporteringsberättelser:\n\n- Endast Admins kan ändra SLO‑mål, alert‑thresholds eller datakälla‑mappningar.\n- Begränsa vem som kan stänga incidenter eller markera dem som “resolved” och kräva en sammanfattande lösningsrapport.
Revisionsspår: oföränderlig historik över ändringar
Logga varje redigering av SLO:er, checks och incidentfält med:\n\n- vem gjorde det (användare + roll)\n- när det hände (tidsstämpel)\n- vad som ändrades (före/efter‑värden)\n- var det kom från (UI, API, automation)
Gör revisionsloggar sökbara och synliga från relevanta detaljsidor (t.ex. incidentsidan visar sin fullständiga ändringshistorik). Det håller granskningar faktabaserade och minskar fram och tillbaka i postmortems.
Bygg övervakningschecks och uptime‑insamling
Övervakning är appens “sensorlager”: det gör verkligt beteende till data ni kan lita på. För interna verktyg är syntetiska checks ofta snabbaste vägen eftersom ni kontrollerar vad “friskt” betyder.
Definiera syntetiska checks per verktyg
Börja med en liten uppsättning checktyper som täcker de flesta interna appar:\n\n- HTTP ping: verifiera att tjänsten svarar (statuskod, TLS, grundläggande headers).\n- Endpoint‑validering: träffa en känd URL och validera något meningsfullt (förväntad JSON‑struktur, nyckelsträng i HTML eller hälsosvars‑payload).\n- Login‑fritt “smoke”‑flöde: om möjligt, testa ett läs‑endast flux som speglar användarupplevelsen (t.ex. ladda dashboard‑sidan och verifiera att den renderas).
Håll checks deterministiska. Om en validering kan misslyckas pga förändligt innehåll skapar ni brus och förtroendet minskar.
Samla uptime och latens (och lagra klokt)
För varje checkkörning fånga:\n\n- Tidsstämpel (start och slut)\n- Resultat: up/down/unknown\n- Latens: total körningstid (och valfritt DNS/connect/TTFB om ni mäter det)\n- Orsak: felkod, timeout, valideringsfel eller undantagsmeddelande
Spara data antingen som tidsserie‑events (en rad per checkkörning) eller som aggregerade intervall (t.ex. per‑minuts rollups med räkningar och p95‑latens). Eventdata är bra för felsökning; rollups är bra för snabba dashboards. Många team gör båda: behåll råa events 7–30 dagar och rollups för längre historik.
Behandla driftstopp vs saknad data uttryckligen
Ett saknat checkresultat ska inte automatiskt betyda “nere”. Lägg till ett explicit unknown‑tillstånd för fall som:\n\n- checker‑worker är stoppad\n- nätverkspartition mellan checker och mål\n- konfiguration borttagen mitt i körning
Detta förhindrar uppblåst driftstopp och gör “övervakningsluckor” synliga som egna operationella problem.
Kör checks enligt schema med bakgrundsjobb
Använd bakgrundsprocesser (cron‑liknande schemaläggning, köer) för att köra checks i fasta intervaller (t.ex. var 30–60:e sekund för kritiska verktyg). Bygg in timeouts, retries med backoff och samtidighetsgränser så er checker inte överbelastar interna tjänster. Persist varje körningsresultat — även fel — så er uptime‑dashboard kan visa både aktuell status och en pålitlig historik.
Skapa aviseringar och notifikationsflöden
Lägg till mobila statusvyer
Skapa en webapp nu och utöka till Flutter‑mobila skärmar när teamen behöver status på språng.
Alerts är där spårning blir till handling. Målet är enkelt: meddela rätt personer, med rätt kontext, vid rätt tid — utan att dränka alla i meddelanden.
Knyt aviseringar till SLO:er (inte bara thresholds)
Börja med att definiera rules som mappar direkt till era SLIs/SLOs. Två praktiska mönster:\n\n- Burn‑rate alerts: pinga när error‑budget förbrukas så snabbt att ni missar SLO:t om inget händer.\n- Tröskelöverskridanden: varna när en metric passerar en tydlig gräns (t.ex. tillgänglighet < 99,5% över 15 minuter).
För varje regel, lagra “varför” tillsammans med “vad”: vilken SLO påverkas, utvärderingsfönstret och avsedd sevritet.
Gör notifikationer handlingsbara
Skicka notiser via de kanaler teamen redan använder (e‑post, Slack, Microsoft Teams). Varje meddelande bör innehålla:\n\n- En enradig summering (service + symptom + sevritet)\n- En direkt länk till relevant dashboard‑vy (t.ex. /services/payments?window=1h)\n- En länk till incident‑sidan om en sådan skapats (t.ex. /incidents/123)
Undvik att dumpa råa metrics. Ge en kort “nästa steg” som “Kolla senaste deploys” eller “Öppna logs.”
Minska brus med dedupe, gruppering och tysta tider
Implementera:\n\n- Deduplikation (samma alert‑fingerprint → uppdatera befintlig tråd)\n- Gruppering (en incident kan samla flera relaterade alerts)\n- Tysta tider och routing‑regler så lågsevritets‑alerts inte väcker on‑call
Stöd eskalering och on‑call‑routing
Även för interna verktyg behöver folk kontroll. Lägg in manuell eskalering (knapp på alert/incident‑sidan) och integrera med on‑call‑verktyg om ni har (PagerDuty/Opsgenie‑ekvivalenter), eller åtminstone en konfigurerbar rotationslista sparad i appen.
Lägg till incidenthantering och postmortem‑funktioner
Incidenthantering gör “vi såg en alert” till ett delat, spårbart svar. Bygg detta i appen så folk kan gå från signal till samordning utan att hoppa mellan verktyg.
Enklicksskapande av incidenter
Gör det möjligt att skapa en incident direkt från en alert, en service‑sida eller ett uptime‑diagram. Förifyll nyckelfält (service, miljö, alert‑källa, först upptäckt tid) och tilldela ett unikt incident‑ID.
Ett bra standardsätt av fält håller det lättviktigt: sevritet, kundpåverkan (interna team som påverkas), nuvarande ägare och länkar till den utlösande alerten.
Statuslivscykel och samarbete
Använd en enkel livscykel som matchar hur team faktiskt jobbar:\n\n- Open → Investigating → Mitigated → Resolved
Varje statusändring ska spela in vem gjorde ändringen och när. Lägg till tidslinjeuppdateringar (korta, tidsstämplade notiser), stöd för bilagor och länkar till runbooks och tickets (t.ex. /runbooks/payments-retries eller /tickets/INC-1234). Detta blir tråden för “vad hände och vad gjorde vi”.
Postmortems med åtgärdspunkter
Postmortems ska vara snabba att starta och konsekventa att granska. Erbjud mallar med:\n\n- Sammanfattning, påverkan, upptäckt och rotorsak\n- Bidragande faktorer (inklusive processluckor)\n- Vad fungerade / vad gjorde inte det\n- Uppföljningar med ägare och förfallodatum
Knyt åtgärder tillbaka till incidenten, följ upp slutförande och lyft försenade items på team‑dashboards. Om ni stöder “lärande‑granskningar”, tillåt ett “blameless”‑läge som fokuserar på system och processer snarare än individuella misstag.
Rapportering och pålitlighetsscorecards
Börja med Go och Postgres
Generera en underhållbar backend med PostgreSQL‑scheman anpassade till verktyg, checks, SLO:er och incidenter.
Rapportering är där spårning blir beslutsstöd. Dashboards hjälper operatörer; scorecards hjälper ledningen förstå om interna verktyg blir bättre, vilka områden behöver investering och vad “bra” betyder.
Vad att inkludera i ett scorecard
Bygg en konsekvent, upprepbar vy per verktyg (och eventuellt per team) som snabbt svarar:\n\n- SLO‑efterlevnad över tid: visa aktuell period (vecka/månad/kvartal) och trendlinje mot SLO‑målet.\n- Mest opålitliga verktyg: ranka efter missade SLO:er, flest driftstopp‑minuter eller högst error‑budget‑förbrukning.\n- MTTR: median och p90 time‑to‑restore, så en lång incident inte döljer ett mönster.\n- Incidentantal: totala incidenter plus sevritetsfördelning (t.ex. Sev1–Sev3), med jämförelse mot föregående period.
Där det går, lägg till lätt kontext: “SLO missad pga 2 deploys” eller “Mest downtime från dependency X”, utan att göra rapporten till en fullständig incidentanalys.
Filtrering som gör ledningsrapportering användbar
Ledare vill sällan ha “allt”. Lägg till filter för team, verktygskritikalitet (t.ex. Tier 0–3) och tidsfönster. Säkerställ att samma verktyg kan ingå i flera rollups (plattformsteam äger det, finans är beroende av det).
Summeringar och export
Erbjud veckovisa och månatliga sammanfattningar som kan delas utanför appen:\n\n- Enklicks CSV‑export för kalkylblad\n- Ren PDF‑export för statusmöten
Behåll narrativet konsekvent (“Vad ändrades sedan förra perioden?” “Var är vi över budget?”). Om ni behöver en primer för intressenter, hänvisa till en kort guide som /blog/sli-slo-basics.
Säkerhet, datakvalitet och operativ hårdning
En tracker blir snart en sanningskälla. Behandla den som ett produktionssystem: säkert som standard, motståndskraftigt mot dålig data och lätt att återställa när något går snett.
Skydda appens yta
Lås ner varje endpoint — även “endast internt”‑ändpunkter.
- Validera input vid gränsen (typer, intervall, tillåtna enum, max‑payload) och avvisa okända fält.\n- Lägg på rate limiting per användare/service‑token för att förhindra att bullriga klienter överbelastar ingestion eller dashboards.\n- Använd parameteriserade frågor och säkra ORM‑mönster för att undvika injektionsproblem.
Hemligheter och åtkomstkontroll
Håll credentials utanför koden och utanför loggar.
Spara hemligheter i en secret manager och rotera dem. Ge webbappen least‑privilege databasåtkomst: separata read/write‑roller, begränsa åtkomst till endast nödvändiga tabeller och använd kortlivade creds när möjligt. Kryptera trafik (TLS) mellan browser↔app och app↔databas.
Datakvalitets‑guardrails
Pålitlighetsmått är bara användbara om underliggande events är tillförlitliga.
Lägg in server‑sida‑kontroller för tidsstämplar (tidszon/klockskew), obligatoriska fält och idempotensnycklar för att deduplicera retries. Spåra ingestfel i en dead‑letter‑kö eller “karantän”‑tabell så dåliga events inte förgiftar dashboards.
Operativa grunder (hoppa inte över)
Automatisera databasmigrationer och test rollback. Schemalägg backups, återställ‑testa dem regelbundet och dokumentera en minimal DR‑plan (vem, vad, hur länge).
Slutligen, gör själva pålitlighetsspåraren pålitlig: lägg till health checks, grundläggande monitorering för kö‑lags och DB‑latens, och alert när ingestion tystnar till noll.
Rullout‑plan och iterativ roadmap
En pålitlighetsspårningsapp lyckas när folk litar på den och faktiskt använder den. Behandla första releasen som en lärloop, inte en “big bang”.
Börja med ett fokuserat pilot
Välj 2–3 interna verktyg som används brett och har tydliga ägare. Implementera ett litet set checks (t.ex. startsidans tillgänglighet, inloggningens framgång och en viktig API‑endpoint) och publicera en dashboard som svarar: “Är den uppe? Om inte, vad ändrades och vem äger det?”
Håll piloten synlig men begränsad: ett team eller en liten grupp power‑users räcker för att validera flödet.
Samla feedback där det gör ont
Under de första 1–2 veckorna, samla aktivt feedback kring:\n\n- Vad som känns förvirrande (metriknamn, diagram, filter, definitioner)\n- Vad som är bullrigt (alerts som inte motsvarar användarpåverkan)\n- Vad som saknas (ägarskap, runbooks, länkar till incidenter)
Gör feedback till konkreta backlog‑items. En enkel “Rapportera ett problem med denna metrik”‑knapp på varje diagram ger ofta de snabbaste insikterna.
Iterera med integrationer och automation
Foga värde i lager: koppla till er chat för notiser, sedan till ert incidentverktyg för automatisk ticket‑skapande, och därefter CI/CD för deploy‑markörer. Varje integration ska minska manuellt arbete eller förkorta tid‑till‑diagnos — annars är det bara komplexitet.
Om ni prototypar snabbt, överväg att använda Koder.ai:s planning‑läge för att mappa initial omfattning (entiteter, roller och arbetsflöden) innan ni genererar första bygget. Det är ett enkelt sätt att hålla MVP:en tight — och eftersom ni kan snapshotta och rulla tillbaka, kan ni iterera på dashboards och ingestion säkert när teamen förfinar definitioner.
Definiera framgångsmått och expandera
Innan ni rullar ut till fler team, definiera framgångsmått som veckovisa dashboard‑användare, minskad time‑to‑detect, färre dubblett‑alerts eller konsekventa SLO‑granskningar. Publicera en lätt roadmap i /blog/reliability-tracking-roadmap och expandera verktyg‑för‑verktyg med tydliga ägare och utbildningssessioner.
Vanliga frågor
Vad är första steget innan man bygger dashboards för pålitlighetsspårning?
Börja med att definiera omfattningen (vilka verktyg och miljöer som inkluderas) och er arbetande definition av pålitlighet (tillgänglighet, latens, fel). Välj sedan 1–3 utfall ni vill förbättra (t.ex. snabbare upptäckt, tydligare rapportering) och designa de första skärmarna kring de centrala besluten användarna behöver fatta: “Är vi okej?” och “Vad gör jag härnäst?”
Vad är skillnaden mellan SLIs, SLOs och SLAs för interna verktyg?
En SLI är vad du mäter (t.ex. % lyckade förfrågningar, p95‑latens). En SLO är målet för den mätningen (t.ex. 99,9% över 30 dagar). Ett SLA är ett formellt åtagande med konsekvenser (ofta externt). För interna verktyg ger SLO:er vanligtvis samstämmighet utan tyngden av SLA‑liknande avtal.
Vilka mått bör jag mäta för de flesta interna verktyg?
Använd en liten basuppsättning som är jämförbar över verktyg:
- Tillgänglighet/uptime (nås när det behövs)
- Latens/responstid (tillräckligt snabb för att vara användbar)
- Felkvot (timeouts, 5xx, jobb‑fel, kända feltilstånd)
Lägg till mer först när du kan säga vilken beslutspunkt metrisken kommer att driva (avisering, prioritering, kapacitetsarbete osv.).
Vilka tidsfönster fungerar bäst för SLO‑rapportering?
Rullande fönster håller scorecards uppdaterade kontinuerligt:
- 7 dagar: upptäcker regressioner snabbt
- 30 dagar: månatlig rapportering
- 90 dagar: kvartalssstabilitet
Välj fönster som matchar hur er organisation granskar prestanda så att siffrorna känns intuitiva och används.
Hur definierar jag incidenter och sevritetsnivåer på ett konsekvent sätt?
Definiera explicita triggerregler kopplade till användarpåverkan och duration, till exempel:
- Sev1: verktyget är nere eller ett kritiskt arbetsflöde blockerat i X minuter
- Sev2: större degradering (felkvot över Y% under Z minuter)
- Sev3: mindre/ intermittenta problem
Skriv ner dessa regler i appen så avisering, incidentstidslinjer och rapportering förblir konsekventa mellan team.
Vilka datakällor bör en pålitlighetsspårningsapp ta in?
Kartlägg vilket system som är “sanningskälla” för varje fråga:
- Syntetiska checks för uptime och grundläggande responstid
- Metrics för latenspercentiler och felkvoter
- Logs/traces för debug‑kontext
- Ticketing/incidentverktyg för incident‑metadata
Var tydlig (t.ex. “uptime SLI kommer endast från probes”), annars blir det lätt argument om vilka siffror som räknas.
När ska jag använda push kontra pull för ingestion?
Använd pull för system du kan polla regelbundet (övervaknings‑API:er, ticketing‑API:er). Använd push (webhooks/händelser) för hög‑volym eller near‑real‑time‑händelser (deploys, alerts, incidentuppdateringar). En vanlig uppdelning är att dashboards uppdateras var 1–5 minut medan scorecards beräknas timvis eller dagligen.
Vad är ett praktiskt databasschema för pålitlighetsspårning?
Du behöver typiskt:
Hur lägger jag till rättigheter och revisionsspår som folk kommer att lita på?
Logga varje hög‑påverkan‑ändring med vem, när, vad som ändrades (före/efter) och varifrån den kom (UI/API/automation). Kombinera detta med rollbaserad åtkomst:
- Viewer: skrivskyddad
- Editor: skapa/uppdatera checks och incidentuppdateringar
- Admin: ändra SLO‑mål, thresholds, integrationer
Dessa skydd hindrar tysta ändringar som undergräver förtroendet för era pålitlighetssiffror.
Hur ska jag hantera saknad övervakningsdata i uptime‑beräkningar?
Behandla saknad monitoreringsdata som ett separat unknown‑tillstånd, inte automatiskt som driftstopp. Saknade data kan bero på:
- checker‑processen stoppad
- nätverkspartition mellan checker och mål
- konfig ändrad mitt i en körning
Att göra “unknown” synligt förhindrar uppblåst downtime och synliggör övervakningsluckor som ett eget operativt problem.