15 thg 6, 2025·8 phút
Để AI Thiết Kế Schema, API và Mô Hình Dữ Liệu cho Backend
Khám phá cách schema và API do AI sinh tăng tốc giao hàng, điểm yếu của chúng, và quy trình thực tiễn để review, test và quản trị thiết kế backend.
Khám phá cách schema và API do AI sinh tăng tốc giao hàng, điểm yếu của chúng, và quy trình thực tiễn để review, test và quản trị thiết kế backend.
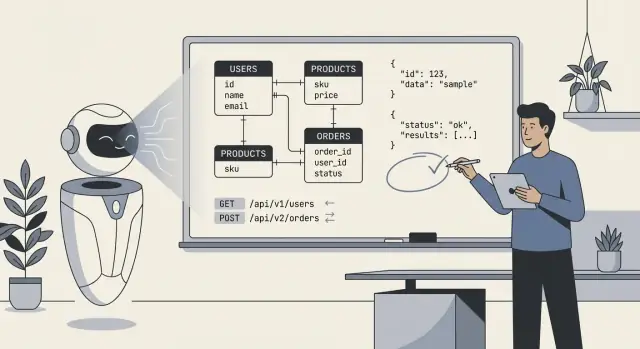
Khi người ta nói “AI thiết kế backend của chúng tôi,” thường họ ám chỉ mô hình đã đưa ra một bản nháp đầu tiên của bản vẽ kỹ thuật lõi: bảng cơ sở dữ liệu (hoặc collection), cách các phần đó liên kết, và các API đọc/ghi dữ liệu. Thực tế, đó ít khi là “AI xây mọi thứ” mà nhiều hơn là “AI đề xuất một cấu trúc để chúng ta triển khai và tinh chỉnh.”
Ở mức tối thiểu, AI có thể sinh ra:
users, orders, subscriptions, cùng các trường và kiểu cơ bản.AI có thể suy ra các mẫu “thông thường”, nhưng không thể chọn mô hình đúng khi yêu cầu mơ hồ hoặc đặc thù ngành. Nó sẽ không biết chính sách thực tế của bạn về:
cancelled khác refunded khác voided).Hãy coi output của AI như một khởi điểm nhanh và có cấu trúc—hữu ích để khám phá lựa chọn và phát hiện thiếu sót—nhưng không phải là một spec có thể phát hành mà không chỉnh sửa. Công việc của bạn là cung cấp các quy tắc rõ ràng và các trường hợp cạnh, rồi review output của AI như khi bạn review bản nháp đầu của một kỹ sư trẻ: hữu ích, đôi khi ấn tượng, nhưng thỉnh thoảng sai theo cách tinh tế.
AI có thể phác thảo schema hoặc API nhanh, nhưng nó không thể tự sáng tạo các sự thật còn thiếu khiến backend “phù hợp” với sản phẩm của bạn. Kết quả tốt nhất đến khi bạn đối xử với AI như một nhà thiết kế trẻ tốc độ: bạn đưa ra ràng buộc rõ ràng, và nó đề xuất các phương án.
Trước khi yêu cầu bảng, endpoint, hay model, hãy ghi rõ những điều thiết yếu:
Khi yêu cầu không rõ, AI có xu hướng “đoán” mặc định: trường nào cũng optional, cột trạng thái chung chung, sở hữu không rõ ràng, và đặt tên thiếu nhất quán. Điều đó thường dẫn đến schema trông hợp lý nhưng vỡ khi dùng thật—đặc biệt liên quan đến phân quyền, báo cáo và các edge case (hoàn tiền, hủy, giao hàng một phần, phê duyệt nhiều bước). Bạn sẽ trả giá bằng migrations, giải pháp tạm và API khó hiểu.
Dùng template này làm điểm khởi và dán vào prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
AI mạnh nhất khi bạn xem nó như một chiếc máy phác thảo nhanh: nó có thể phác thảo mô hình dữ liệu lần đầu và tập hợp endpoint tương ứng trong vài phút. Tốc độ này thay đổi cách làm việc của bạn—không phải vì output tự động “đúng” mà vì bạn có thứ cụ thể để lặp nhanh.
Lợi ích lớn nhất là loại bỏ khởi đầu lạnh. Cho AI mô tả ngắn về entity, luồng chính và ràng buộc, và nó có thể đề xuất bảng/collection, quan hệ và diện API cơ bản. Điều này đặc biệt hữu ích khi bạn cần demo nhanh hoặc khám phá yêu cầu chưa ổn định.
Tốc độ mang lại lợi ích nhất cho:
Con người mệt mỏi và trôi drift; AI thì không—vì vậy nó tuyệt với việc lặp lại convention trên toàn backend:
createdAt, updatedAt, customerId)/resources, /resources/:id) và payloadsSự nhất quán này giúp backend dễ tài liệu hoá, test và chuyển giao.
AI cũng giỏi về đầy đủ bề mặt. Nếu bạn yêu cầu đầy đủ CRUD và các thao tác phổ biến (tìm kiếm, list, cập nhật hàng loạt), nó thường sinh diện mặt API khởi điểm rộng hơn bản nháp vội của con người.
Một lợi thế nhanh là chuẩn hóa lỗi: một envelope lỗi đồng nhất (code, message, details) khắp endpoints. Dù bạn chỉnh sau này, có một dạng chung từ đầu sẽ tránh hỗn độn.
Tâm thái chính: để AI làm 80% đầu nhanh, rồi dành thời gian cho 20% cần xét đoán—quy tắc nghiệp vụ, edge cases và “tại sao” đằng sau mô hình.
Schema do AI sinh thường trông “gọn” lúc đầu: bảng ngăn nắp, tên hợp lý và quan hệ phù hợp với happy path. Vấn đề xuất hiện khi dữ liệu thật, người dùng thật và luồng thật tác động lên hệ thống.
AI có thể dao động giữa hai cực:
Thử nghiệm nhanh: nếu trang phổ biến nhất cần 6+ join, có thể bạn quá chuẩn hóa; nếu cập nhật buộc thay cùng một giá trị ở nhiều hàng, có thể bạn thiếu chuẩn hóa.
AI thường bỏ sót các yêu cầu “nhàm” nhưng quan trọng:
tenant_id trên bảng, hoặc không áp dụng phạm vi tenant trong unique constraint.deleted_at nhưng không cập nhật ràng buộc unique hoặc mẫu truy vấn để loại bỏ bản ghi đã xóa.created_by/updated_by, lịch sử thay đổi, hoặc event log bất biến.AI có thể đoán:
invoice_number)Các lỗi này thường dẫn đến migration khó xử và giải pháp ở mức ứng dụng.
Hầu hết schema sinh ra không phản ánh cách bạn sẽ truy vấn:
tenant_id + created_at),Nếu mô hình không mô tả 5 truy vấn hàng đầu của ứng dụng, nó không thể thiết kế schema phù hợp cho chúng.
AI thường khá tốt trong việc tạo API trông “chuẩn.” Nó sẽ mô phỏng các pattern quen thuộc từ framework và public API, điều này giúp tiết kiệm thời gian. Rủi ro là nó tối ưu cho vẻ hợp lý hơn là đúng với sản phẩm, dữ liệu và thay đổi tương lai của bạn.
Mô hình tài nguyên cơ bản. Với domain rõ ràng, AI có xu hướng chọn danh từ và cấu trúc URL hợp lý (ví dụ /customers, /orders/{id}, /orders/{id}/items). Nó cũng lặp lại convention đặt tên đồng nhất khắp endpoints.
Scaffolding endpoint phổ biến. AI hay bao gồm essentials: list vs detail, create/update/delete, và request/response dự đoán.
Quy ước nền tảng. Nếu bạn yêu cầu rõ, nó có thể thống nhất phân trang, lọc và sắp xếp. Ví dụ: ?limit=50&cursor=... (cursor pagination) hoặc ?page=2&pageSize=25 (page-based), cùng ?sort=-createdAt và các filter như ?status=active.
Leaky abstractions. Thất bại điển hình là phơi bày bảng nội bộ trực tiếp như “resource,” đặc biệt khi schema có join table, field denormalized, hoặc cột audit. Bạn sẽ có endpoint như /user_role_assignments phản ánh chi tiết triển khai hơn là khái niệm người dùng mong muốn (“roles for a user”). Điều này làm API khó dùng và khó thay đổi.
Xử lý lỗi không nhất quán. AI có thể trộn kiểu: đôi khi trả 200 kèm body lỗi, đôi khi dùng 4xx/5xx. Bạn cần hợp đồng rõ:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })Versioning là thứ để sau cùng. Nhiều thiết kế AI bỏ qua chiến lược versioning cho đến khi đau đầu. Quyết định ngay từ đầu dùng path versioning (/v1/...) hay header-based, và định nghĩa điều gì là breaking change. Dù bạn không bump version, có luật sẽ ngăn thay đổi vô ý.
Dùng AI cho tốc độ và nhất quán, nhưng coi thiết kế API là giao diện sản phẩm. Nếu endpoint phản chiếu DB thay vì tư duy theo người dùng, đó là dấu hiệu AI tối ưu cho dễ sinh chứ không cho khả năng sử dụng lâu dài.
Đối xử với AI như một nhà thiết kế trẻ nhanh: giỏi ở việc tạo bản nháp, không chịu trách nhiệm cuối. Mục tiêu là tận dụng tốc độ mà vẫn giữ kiến trúc có chủ đích, có thể review và test.
Nếu bạn dùng công cụ vibe-coding như Koder.ai, tách biệt trách nhiệm càng quan trọng: nền tảng có thể nhanh chóng phác thảo và triển khai backend (ví dụ service Go với PostgreSQL), nhưng bạn vẫn cần định nghĩa các invariant, ranh giới authorization và quy tắc migration mà bạn chấp nhận.
Bắt đầu với prompt chặt chẽ mô tả domain, ràng buộc và “thành công là gì.” Yêu cầu mô hình khái niệm trước (entities, relationships, invariants), không phải bảng.
Rồi lặp theo vòng:
Vòng lặp này hiệu quả vì nó biến “gợi ý AI” thành artefact có thể chứng minh hoặc bác bỏ.
Giữ ba lớp riêng:
Yêu cầu AI xuất các phần này thành các mục riêng. Khi có thay đổi (ví dụ thêm trạng thái mới), cập nhật lớp khái niệm trước, rồi đối chiếu schema và API. Điều này giảm coupling vô tình và làm refactor bớt đau.
Mỗi lần lặp nên để lại dấu vết. Dùng tóm tắt theo kiểu ADR (một trang hoặc ít hơn) ghi:
deleted_at”).Khi bạn dán phản hồi vào AI, kèm theo các ghi chú quyết định nguyên văn để tránh mô hình “quên” lựa chọn trước đó và giúp đội hiểu backend sau này.
AI dễ dàng điều hướng khi bạn coi prompt như bài viết spec: định nghĩa domain, nêu ràng buộc và yêu cầu output cụ thể (DDL, bảng endpoint, ví dụ). Mục tiêu không phải “sáng tạo” mà là “chính xác.”
Yêu cầu mô hình dữ liệu và các quy tắc giữ nó nhất quán.
Nếu bạn đã có conventions, nói rõ: kiểu ID (UUID vs bigint), nullable policy, phong cách đặt tên, và kỳ vọng indexing.
Yêu cầu một bảng API với hợp đồng rõ ràng, không chỉ danh sách route.
Thêm hành vi nghiệp vụ: kiểu phân trang, trường sắp xếp, và cách lọc hoạt động.
Hãy bắt model nghĩ theo release.
billing_address to Customer. Provide a safe migration plan: forward migration SQL, backfill steps, feature-flag rollout, and a rollback strategy. API must remain compatible for 30 days; old clients may omit the field.”Prompt mơ hồ sinh hệ thống mơ hồ.
Khi muốn output tốt hơn, thắt chặt prompt: nêu luật, edge cases, và định dạng deliverable.
AI có thể phác thảo backend tốt, nhưng việc đưa nó vào sản xuất vẫn cần kiểm tra con người. Hãy coi checklist này là “cửa kiểm soát phát hành”: nếu bạn không thể trả lời mục nào tự tin, dừng lại và sửa trước khi thành dữ liệu sản xuất.
(tenant_id, slug))._id, timestamps) và áp dụng đồng nhất.Ghi rõ quy tắc hệ thống:
Trước khi merge, chạy review “happy path + worst path”: một request bình thường, một request không hợp lệ, một request không được phép, một kịch bản tải cao. Nếu hành vi API làm bạn bất ngờ, nó sẽ làm người dùng của bạn bất ngờ.
AI có thể sinh schema và diện API có vẻ hợp lý nhanh, nhưng không thể chứng minh backend hoạt động đúng dưới tải thật, dữ liệu thật và thay đổi tương lai. Hãy neo output của AI bằng các test để khoá hành vi.
Bắt đầu với contract tests xác minh request, response và semantics lỗi—không chỉ happy path. Chạy bộ nhỏ này trên instance thực (hoặc container).
Tập trung vào:
Nếu bạn xuất OpenAPI spec, sinh test từ đó—nhưng cũng thêm test tay cho những phần mà spec không biểu đạt (quy tắc authorization, ràng buộc nghiệp vụ).
Schema do AI sinh thường thiếu chi tiết vận hành: default an toàn, backfill, và khả năng đảo ngược. Thêm test migration:
Giữ kịch bản rollback có thể chạy cho production: nếu migration chậm, khoá bảng, hay phá tương thích, cần làm gì.
Đừng benchmark endpoint generic. Capture pattern truy vấn đại diện (top list views, search, join, aggregation) và test tải những pattern đó.
Đo:
Đây là nơi thiết kế AI thường thất bại: các bảng “hợp lý” nhưng tạo ra nhiều join tốn kém dưới tải.
Thêm kiểm tra tự động cho:
Các test bảo mật cơ bản ngăn ngừa lớp lỗi AI tốn kém nhất: endpoint hoạt động nhưng phơi bày quá nhiều.
AI có thể phác thảo schema “version 0” tốt, nhưng backend của bạn sống tới version 50. Sự khác biệt giữa backend lâu bền và sụp đổ nằm ở cách bạn tiến hoá nó: migrations, refactor có kiểm soát, và tài liệu ý định rõ ràng.
Xem mỗi thay đổi schema như một migration, ngay cả khi AI gợi ý “alter table.” Dùng bước rõ ràng, có thể đảo ngược: thêm cột mới trước, backfill, rồi siết ràng buộc. Ưu tiên thay đổi bổ sung (thêm field, thêm bảng) hơn thay đổi phá hủy (rename/drop) cho đến khi chứng minh không có phụ thuộc.
Khi bạn yêu cầu AI cập nhật schema, kèm schema hiện tại và quy tắc migration bạn tuân theo (ví dụ: “không drop cột; dùng expand/contract”). Điều này giảm nguy cơ nó đề xuất thay đổi đúng về mặt lý thuyết nhưng rủi ro ở production.
Breaking change hiếm khi là một khoảnh khắc; đó là một chuyển đổi.
AI hữu ích khi sinh kế hoạch từng bước (kèm SQL snippet và thứ tự rollout), nhưng bạn vẫn phải kiểm tra tác động runtime: locks, transaction dài, và khả năng resume backfill.
Refactor nên mục tiêu cô lập thay đổi. Nếu cần chuẩn hóa, tách bảng, hoặc giới thiệu event log, giữ các lớp tương thích: view, code dịch, hoặc “shadow” table. Yêu cầu AI đề xuất refactor giữ nguyên hợp đồng API, và liệt kê những gì cần thay đổi ở query, index, và constraint.
Phần lớn drift dài hạn xảy ra vì prompt tiếp theo quên ý định ban đầu. Giữ một “hợp đồng mô hình dữ liệu” ngắn: quy tắc đặt tên, chiến lược ID, ngữ nghĩa timestamps, chính sách soft-delete, và invariant (“order total là derived, không lưu”). Đặt nó trong tài liệu nội bộ và tái sử dụng trong prompt sau để hệ thống thiết kế trong cùng ranh giới.
AI có thể phác thảo bảng và endpoint nhanh, nhưng nó không chịu rủi ro cho bạn. Đưa bảo mật và quyền riêng tư vào prompt từ đầu, rồi kiểm tra trong review—đặc biệt với dữ liệu nhạy cảm.
Trước khi chấp nhận bất kỳ schema nào, gán nhãn trường theo mức nhạy cảm (public, internal, confidential, regulated). Phân loại này quyết định trường nào cần mã hóa, che bớt, hoặc tối thiểu hóa.
Ví dụ: password không bao giờ được lưu nguyên (chỉ hash đã salt), token có thời hạn ngắn và mã hóa ở rest, PII như email/phone có thể cần che khi admin xem và trong export. Nếu một trường không cần cho giá trị sản phẩm, đừng lưu—AI thường thêm thuộc tính “nice to have” làm tăng bề mặt rủi ro.
API do AI sinh thường mặc định kiểm tra theo vai trò. RBAC dễ lý giải nhưng sụt khi có quy tắc ownership (“user chỉ xem invoice của mình”) hoặc quy tắc theo ngữ cảnh (“support chỉ xem khi ticket mở”). ABAC xử lý tốt hơn nhưng đòi hỏi chính sách rõ ràng.
Rõ ràng mô hình bạn dùng và đảm bảo mọi endpoint áp dụng nó nhất quán—đặc biệt list/search, nơi dễ bị rò rỉ.
Code sinh có thể log body request, headers, hoặc hàng DB đầy đủ khi lỗi. Điều này có thể lộ password, token và PII vào logs và APM. Thiết lập mặc định như: logs có cấu trúc, whitelist trường được log, redact secrets (Authorization, cookies, reset tokens), và tránh log raw payload trên validation failure.
Thiết kế khả năng xóa từ ngày đầu: xóa do user yêu cầu, đóng tài khoản, và quy trình “right to be forgotten”. Xác định cửa sổ lưu giữ theo lớp dữ liệu (audit events vs marketing events) và đảm bảo có bằng chứng đã xóa khi cần.
Nếu giữ audit log, lưu minimal identifier, bảo vệ chúng với quyền truy cập chặt chẽ hơn, và ghi lại cách export hoặc xóa dữ liệu khi được yêu cầu.
AI tốt nhất khi bạn coi nó như kiến trúc sư trẻ nhanh: tạo bản nháp tốt, yếu trong các tradeoff quan trọng ngành. Câu hỏi đúng không phải “AI có thể thiết kế backend cho tôi không?” mà là “phần nào AI có thể phác thảo an toàn, phần nào cần người chuyên trách?”.
AI tiết kiệm thời gian khi bạn xây:
Ở đây AI có giá trị về tốc độ, nhất quán và bao phủ—đặc biệt khi bạn đã biết hành vi mong muốn và có thể nhận ra lỗi.
Cẩn trọng (hoặc chỉ dùng AI như nguồn cảm hứng) khi làm việc trong:
Ở những lĩnh vực này, chuyên môn ngành vượt trội hơn tốc độ AI. Yêu cầu tinh tế—pháp lý, lâm sàng, kế toán—thường không có trong prompt, và AI sẽ tự tin lấp đầy khoảng trống.
Quy tắc thực tế: để AI đề xuất, nhưng yêu cầu review cuối cùng cho invariant mô hình dữ liệu, ranh giới authorization, và chiến lược migration. Nếu bạn không thể nêu ai chịu trách nhiệm cho schema và hợp đồng API, đừng đưa backend do AI thiết kế vào chạy thật.
Nếu bạn đang đánh giá workflow và guardrail, xem các hướng dẫn liên quan trong /blog. Nếu muốn trợ giúp áp dụng các thực hành này cho đội, xem /pricing.
Nếu bạn thích workflow end-to-end nơi bạn có thể lặp qua chat, sinh app hoạt động, và vẫn giữ quyền kiểm soát qua export source code và snapshot rollback, Koder.ai được thiết kế cho kiểu build-and-review này.
Nó thường có nghĩa là mô hình đã tạo ra một bản nháp đầu tiên gồm:
Một đội ngũ con người vẫn cần kiểm tra các quy tắc nghiệp vụ, ranh giới bảo mật, hiệu năng truy vấn và an toàn khi migration trước khi đưa vào chạy thật.
Cung cấp những đầu vào cụ thể mà AI không thể đoán an toàn:
Rõ ràng các ràng buộc càng nhiều, AI sẽ ít “điền” bằng các giả định dễ gãy.
Bắt đầu bằng một mô hình khái niệm (các khái niệm nghiệp vụ + tính bất biến), sau đó sinh:
Giữ các lớp này tách biệt giúp dễ thay đổi lưu trữ mà không phá API — hoặc chỉnh API mà không vô tình làm sai luật nghiệp vụ.
Các vấn đề phổ biến gồm:
tenant_id và ràng buộc unique tổ hợp)deleted_at)Yêu cầu AI thiết kế quanh những truy vấn hàng đầu của bạn rồi xác minh:
tenant_id + created_at)Nếu bạn không thể liệt kê 5 truy vấn/endpoint hàng đầu, coi kế hoạch indexing là chưa đầy đủ.
AI tốt ở scaffolding chuẩn, nhưng cần chú ý:
200 kèm body lỗi, hoặc không thống nhất 4xx/5xx)Xem API như giao diện sản phẩm: thiết kế endpoint theo khái niệm người dùng, không phải theo cấu trúc DB.
Dùng một vòng lặp lặp lại:
Sử dụng mã trạng thái HTTP phù hợp và một envelope lỗi duy nhất, ví dụ:
Ưu tiên các test khóa hành vi:
Test là cách bạn “sở hữu” thiết kế thay vì thừa hưởng giả định của AI.
Dùng AI cho bản nháp khi pattern rõ ràng (MVP CRUD, internal tools). Thận trọng khi:
Quy tắc thực tế: AI gợi ý phương án, nhưng bắt buộc có review của con người cho invariant, authorization và chiến lược rollout.
Một schema có thể trông “sạch” nhưng vẫn sập khi gặp workflow và tải thật.
Cách này biến output của AI thành artefact có thể kiểm chứng thay vì chỉ tin vào văn bản.
400, 401, 403, 404, 409, 422, 429{"error":{"code":"...","message":"...","details":[...]}}
Đảm bảo thông điệp lỗi không lộ thông tin nội bộ (SQL, stack trace, secret) và nhất quán mọi endpoint.