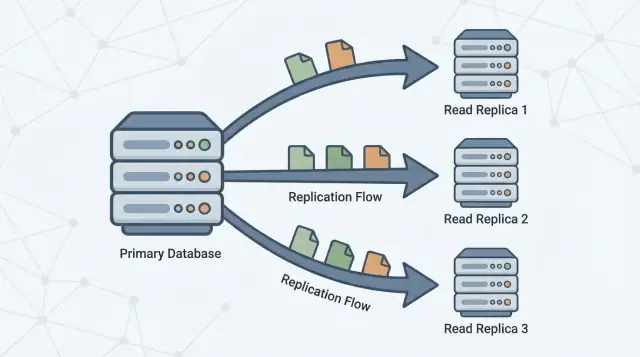
Bản sao chỉ đọc là gì (và không phải là gì)
Một bản sao chỉ đọc là một bản sao của cơ sở dữ liệu chính (thường gọi là primary) được cập nhật thường xuyên bằng cách nhận các thay đổi từ nó. Ứng dụng của bạn có thể gửi truy vấn chỉ đọc (như SELECT) tới replica, trong khi primary tiếp tục xử lý tất cả các ghi (như INSERT, UPDATE, DELETE).
Lời hứa cơ bản
Lời hứa rất đơn giản: tăng khả năng phục vụ đọc mà không đè nặng thêm lên primary.
Nếu ứng dụng của bạn có nhiều lưu lượng “lấy dữ liệu” — trang chủ, trang sản phẩm, hồ sơ người dùng, dashboard — chuyển một phần những lần đọc đó sang một hoặc nhiều replica có thể giải phóng primary để tập trung vào công việc ghi và các truy vấn quan trọng. Trong nhiều cấu hình, điều này có thể thực hiện với thay đổi ứng dụng tối thiểu: bạn giữ một cơ sở dữ liệu làm nguồn chân lý và thêm replica để truy vấn thêm.
Bản sao đọc không phải là
Replicas hữu ích, nhưng không phải nút bấm phép thuật về hiệu năng. Chúng không:
- Tăng khả năng ghi. Tất cả các ghi vẫn đến primary.\n- Sửa truy vấn chậm. Nếu truy vấn kém hiệu quả (thiếu chỉ mục, quét bảng lớn, mẫu join tệ), nó có khả năng chậm trên replica nữa—chỉ là chậm ở chỗ khác.\n- Thay thế thiết kế schema và dữ liệu tốt. Replicas không giải quyết điểm nóng, hàng ghi quá lớn, hay “bảng mọi thứ” quá cồng kềnh.\n- Loại bỏ nhu cầu giám sát. Replicas thêm các thành phần vận hành: độ trễ sao chép, giới hạn kết nối và hành vi failover.
Kỳ vọng cho phần còn lại của hướng dẫn
Hãy nghĩ về replicas như một công cụ mở rộng đọc có đánh đổi. Phần còn lại của bài viết giải thích khi nào chúng thực sự hữu ích, những cách phổ biến khiến chúng phản tác dụng, và cách các khái niệm như độ trễ sao chép và tính nhất quán cuối cùng ảnh hưởng đến trải nghiệm người dùng khi bạn bắt đầu đọc từ bản sao thay vì primary.
Tại sao có bản sao chỉ đọc
Một máy chủ cơ sở dữ liệu primary đơn thường ban đầu “đủ lớn”. Nó xử lý các ghi (insert, update, delete) và cũng trả lời mọi yêu cầu đọc (SELECT) từ ứng dụng, dashboard và công cụ nội bộ.
Khi mức sử dụng tăng lên, các truy vấn đọc thường tăng nhanh hơn ghi: mỗi lượt xem trang có thể kích hoạt nhiều truy vấn, màn hình tìm kiếm có thể tỏa ra nhiều tra cứu, và các truy vấn kiểu phân tích có thể quét rất nhiều dòng. Ngay cả khi lưu lượng ghi ở mức vừa phải, primary vẫn có thể trở thành nút thắt vì nó phải làm hai việc cùng lúc: chấp nhận thay đổi một cách an toàn và nhanh chóng, và phục vụ lượng đọc ngày càng tăng với độ trễ thấp.
Tách đọc và ghi
Replicas tồn tại để tách khối lượng đó. Primary giữ nhiệm vụ xử lý ghi và duy trì “nguồn chân lý”, trong khi một hoặc nhiều replica xử lý các truy vấn chỉ đọc. Khi ứng dụng có thể chuyển một số truy vấn sang replica, bạn giảm áp lực CPU, bộ nhớ và I/O trên primary. Điều này thường cải thiện độ phản hồi tổng thể và để lại không gian cho các đợt ghi đột biến.
Sao chép tóm gọn trong một câu
Replication là cơ chế giữ cho replicas cập nhật bằng cách sao chép các thay đổi từ primary sang các máy chủ khác. Primary ghi lại các thay đổi, và replicas áp dụng chúng để có thể trả lời truy vấn sử dụng dữ liệu gần như cùng thời điểm.
Mẫu này phổ biến trên nhiều hệ quản trị cơ sở dữ liệu và dịch vụ được quản lý (ví dụ PostgreSQL, MySQL và các biến thể trên đám mây). Triển khai cụ thể thì khác nhau, nhưng mục tiêu giống nhau: tăng khả năng phục vụ đọc mà không buộc primary phải scale dọc mãi.
Cách replication hoạt động (mô hình tư duy đơn giản)
Hãy tưởng tượng primary là “nguồn chân lý”. Nó chấp nhận mọi ghi — tạo đơn hàng, cập nhật hồ sơ, ghi nhận thanh toán — và gán một thứ tự xác định cho những thay đổi đó.
Một hoặc nhiều replica sau đó theo dõi primary, sao chép các thay đổi để có thể trả lời truy vấn đọc (như “hiển thị lịch sử đơn hàng của tôi”) mà không làm tăng tải cho primary.
Luồng cơ bản
- Primary chấp nhận ghi và ghi chúng vào một nhật ký bền (tên cụ thể tùy theo cơ sở dữ liệu).\n2. Replicas luồng hoặc lấy các mục nhật ký đó từ primary.\n3. Replicas phát lại các thay đổi đó theo cùng thứ tự, dần dần bắt kịp.
Đọc có thể được phục vụ từ replicas, nhưng ghi vẫn đến primary.
Sao chép đồng bộ vs không đồng bộ (ở mức cao)
Replication có thể xảy ra theo hai chế độ chính:
- Đồng bộ: primary chờ một replica (hoặc một đa số) xác nhận đã nhận thay đổi trước khi xem ghi là “cam kết”. Điều này giảm đọc lỗi thời, nhưng có thể tăng độ trễ ghi và làm ghi nhạy hơn với sự cố replica/mạng.\n- Không đồng bộ: primary cam kết ghi ngay lập tức, và replicas bắt kịp sau. Điều này giữ ghi nhanh và bền hơn, nhưng replicas có thể tạm thời bị tụt lại phía sau.
Độ trễ sao chép và “tính nhất quán cuối cùng”
Độ trễ đó—replica bị trễ so với primary—gọi là replication lag. Đây không phải luôn luôn là lỗi; thường là đánh đổi bình thường bạn chấp nhận để mở rộng đọc.
Với người dùng cuối, lag xuất hiện như tính nhất quán cuối cùng: sau khi bạn thay đổi một thứ gì đó, hệ thống sẽ nhất quán ở mọi nơi, nhưng không nhất thiết ngay lập tức.
Ví dụ: bạn cập nhật email và làm mới trang hồ sơ. Nếu trang được phục vụ từ replica bị trễ vài giây, bạn có thể tạm thời thấy email cũ — cho đến khi replica áp dụng bản cập nhật và “bắt kịp”.
Khi nào bản sao đọc thực sự hữu ích
Replicas hữu ích khi primary vẫn khỏe để xử lý ghi nhưng bị quá tải khi phục vụ lưu lượng đọc. Chúng hiệu quả nhất khi bạn có thể chuyển một phần đáng kể tải SELECT sang replica mà không cần thay đổi cách ghi dữ liệu.
Dấu hiệu bạn bị ràng buộc bởi đọc (chứ không phải ghi)
Tìm các dấu hiệu như:
- CPU primary cao trong các đỉnh lưu lượng, trong khi throughput ghi không bất thường\n- Tỷ lệ
SELECT rất cao so với INSERT/UPDATE/DELETE\n- Truy vấn đọc chậm hơn trong đỉnh dù ghi vẫn ổn định\n- Hồ bơi kết nối bị bão hòa do các endpoint đọc nặng (trang sản phẩm, feed, kết quả tìm kiếm)
Cách xác nhận đọc là vấn đề (các số liệu cần kiểm tra)
Trước khi thêm replicas, hãy xác nhận bằng vài tín hiệu cụ thể:
- CPU vs I/O: Primary có đang full CPU khi độ trễ đọc tăng? Hay giới hạn là đọc đĩa?\n- Tỷ lệ truy vấn: Phần trăm thời gian dành cho
SELECT (từ slow query log/APM).\n- p95/p99 độ trễ đọc: Theo dõi điểm cuối đọc và độ trễ truy vấn riêng biệt.\n- Tỷ lệ trúng buffer/cache: Tỷ lệ thấp nghĩa là đọc buộc phải truy cập đĩa.\n- Top truy vấn theo tổng thời gian: Một truy vấn tốn thời gian có thể chiếm phần lớn “tải đọc”.
Đừng bỏ qua các sửa chữa rẻ hơn
Thường bước khởi đầu tốt nhất là tinh chỉnh: thêm chỉ mục đúng, viết lại một truy vấn, giảm các lần gọi N+1, hoặc cache các lần đọc nóng. Những thay đổi này có thể nhanh và rẻ hơn vận hành replicas.
Bảng kiểm nhanh: replicas hay tinh chỉnh
Chọn replicas nếu:
- Phần lớn tải là đọc, và các truy vấn đọc đã được tối ưu tương đối\n- Bạn có thể chịu được thỉnh thoảng đọc lỗi thời cho các truy vấn được chuyển đi\n- Bạn cần thêm khả năng nhanh mà không thay đổi schema/truy vấn rủi ro
Chọn tinh chỉnh trước nếu:
- Một vài truy vấn chiếm phần lớn thời gian đọc\n- Thiếu chỉ mục hoặc join kém hiển nhiên\n- Đọc chậm ngay cả ở lưu lượng thấp (dấu hiệu vấn đề thiết kế truy vấn)
Những trường hợp phù hợp nhất
Replicas giá trị nhất khi primary đang bận xử lý ghi (thanh toán, đăng ký, cập nhật), nhưng một phần lớn lưu lượng là đọc nặng. Trong kiến trúc primary–replica, đẩy các truy vấn phù hợp sang replicas cải thiện hiệu năng mà không thay đổi tính năng ứng dụng.
1) Dashboard và phân tích không nên làm chậm giao dịch
Dashboard thường chạy các truy vấn lâu: group, lọc theo khoảng thời gian lớn, hoặc join nhiều bảng. Những truy vấn đó có thể cạnh tranh tài nguyên CPU, bộ nhớ và cache với công việc giao dịch.
Replica là nơi tốt để:
- Các công việc báo cáo nội bộ\n- Dashboard quản trị\n- Các view số liệu hàng ngày/tuần
Bạn giữ primary tập trung vào giao dịch nhanh, có thể dự đoán, trong khi các truy vấn phân tích mở rộng độc lập.
2) Trang tìm kiếm và duyệt với lưu lượng đọc lớn
Duyệt danh mục, hồ sơ người dùng và feed nội dung có thể sinh ra nhiều truy vấn đọc tương tự. Khi áp lực mở rộng đọc là nút thắt, replicas có thể hấp thụ lưu lượng và giảm các đột biến độ trễ.
Điều này đặc biệt hiệu quả khi các truy vấn thường xuyên không trúng cache (nhiều truy vấn độc nhất) hoặc khi bạn không thể chỉ dựa vào cache ứng dụng.
3) Các job nền quét nhiều dữ liệu
Export, backfill, tính lại tóm tắt và các job “tìm mọi bản ghi thỏa X” có thể làm primary bị xóc. Chạy các quét này trên replica thường an toàn hơn.
Chỉ đảm bảo job chịu được eventual consistency: với replication lag, nó có thể không thấy các cập nhật mới nhất.
4) Đọc đa vùng để giảm độ trễ (với caveat về lỗi thời)
Nếu bạn phục vụ người dùng toàn cầu, đặt replica gần họ có thể giảm thời gian phản hồi. Đổi lại là tăng khả năng đọc lỗi thời khi lag hoặc sự cố mạng xảy ra, nên cách này phù hợp cho các trang chấp nhận “gần như mới” (duyệt, gợi ý, nội dung công khai).
Nơi replicas có thể phản tác dụng
Nhận tín dụng khi triển khai
Chia sẻ những gì bạn xây với Koder.ai và nhận tín dụng qua chương trình nội dung.
Replicas tốt khi “gần đúng” là đủ. Chúng phản tác dụng khi sản phẩm của bạn giả định mọi lần đọc luôn phản ánh ghi mới nhất.
Triệu chứng kinh điển: “Tôi vừa cập nhật, sao không thấy thay đổi?”
Người dùng sửa hồ sơ, gửi form hoặc thay đổi cài đặt — và lần tải trang tiếp theo lấy từ replica bị trễ vài giây. Ghi đã thành công, nhưng người dùng thấy dữ liệu cũ và làm lại thao tác, gửi nhầm, hoặc mất niềm tin.
Điều này đặc biệt đau đầu trong các luồng mà người dùng mong đợi xác nhận ngay: thay đổi email, bật/tắt tùy chọn, tải tài liệu lên, hoặc đăng bình luận rồi được chuyển hướng lại.
Màn hình “phải luôn mới” (không nên mạo hiểm)
Một số lần đọc không thể chấp nhận lỗi thời, dù là thoáng qua:
- Giỏ hàng và tổng thanh toán\n- Số dư ví, điểm thưởng, tồn kho\n- Màn hình “Thanh toán có thành công không?”
Nếu replica bị trễ, bạn có thể hiện tổng giỏ hàng sai, bán quá mức tồn kho, hoặc hiển thị số dư lỗi thời. Dù hệ thống sau đó sửa lại, trải nghiệm người dùng (và lượng hỗ trợ) sẽ bị ảnh hưởng.
Công cụ admin và vận hành cần dữ liệu mới nhất
Dashboard nội bộ thường dẫn đến quyết định thực tế: điều tra gian lận, hỗ trợ khách hàng, xử lý đơn, moderation, phản ứng sự cố. Nếu công cụ admin đọc từ replica, bạn có thể hành động trên dữ liệu không đầy đủ — ví dụ hoàn tiền một đơn đã hoàn tiền, hoặc bỏ lỡ trạng thái mới nhất.
Sửa thực tế: định tuyến “read-your-writes” về primary
Một mẫu phổ biến là định tuyến có điều kiện:
- Sau khi người dùng ghi, gửi các lần đọc xác nhận của họ về primary trong một cửa sổ ngắn (vài giây đến vài phút).\n- Giữ các đọc nền, ẩn danh hoặc không quan trọng trên replicas.
Điều này giữ lợi ích của replicas mà không biến tính nhất quán thành trò đoán mò.
Hiểu độ trễ sao chép và đọc lỗi thời
Replication lag là độ trễ giữa khi một ghi được cam kết trên primary và khi cùng thay đổi đó xuất hiện trên replica. Nếu ứng dụng đọc từ replica trong thời gian đó, nó có thể trả về kết quả “lỗi thời” — dữ liệu đúng trước đó nhưng không còn chính xác ngay lúc này.
Tại sao lag xảy ra
Lag là bình thường, và thường tăng khi áp lực tăng. Nguyên nhân phổ biến:
- Đột biến tải trên primary: nhiều ghi hơn nghĩa là nhiều thay đổi để gửi và áp dụng.\n- Replica quá yếu hoặc bận: replica không thể áp dụng thay đổi nhanh bằng tốc độ tới (CPU, I/O đĩa).\n- Độ trễ hoặc nhiễu mạng: trì hoãn luồng replication.\n- Giao dịch lớn / cập nhật hàng loạt: một thay đổi lớn có thể mất thời gian để serialize, truyền và replay.
Đọc lỗi thời biểu hiện ra sản phẩm thế nào
Lag không chỉ ảnh hưởng độ tươi — nó ảnh hưởng tính đúng đắn từ góc nhìn người dùng:\n\n- Người dùng cập nhật hồ sơ, làm mới và thấy giá trị cũ.\n- Badge “chưa đọc” hoặc số thông báo trôi vì đếm dựa trên hàng cũ.\n- Dashboard/admin bỏ qua đơn hàng, hoàn tiền hoặc thay đổi trạng thái mới nhất.
Cách xử lý thực tế
Bắt đầu bằng việc quyết định tính năng của bạn có thể chịu được bao lâu:\n\n- Thêm cửa sổ chịu đựng: “Dữ liệu có thể cũ tới 30 giây” chấp nhận được cho nhiều dashboard.\n- Định tuyến read-after-write về primary: sau khi người dùng thay đổi, đọc thực thể đó từ primary trong khoảng thời gian ngắn.\n- Thông báo giao diện: đặt kỳ vọng (“Đang cập nhật…”, “Có thể mất vài giây để xuất hiện”).\n- Logic thử lại: nếu một đọc quan trọng thiếu bản ghi vừa ghi, thử lại trên primary hoặc thử sau một khoảng ngắn.
Cần giám sát và cảnh báo gì
Theo dõi độ trễ replica (thời gian/số bytes phía sau), tốc độ áp dụng trên replica, lỗi replication và CPU/disk I/O của replica. Cảnh báo khi lag vượt ngưỡng chấp nhận được (ví dụ 5s, 30s, 2m) và khi lag liên tục tăng theo thời gian (dấu hiệu replica sẽ không bắt kịp nếu không can thiệp).
Mở rộng đọc so với mở rộng ghi (điểm đánh đổi chính)
Lên kế hoạch kiến trúc sẵn sàng cho replica
Dùng Koder.ai để phác thảo kế hoạch primary-replica trước khi viết dòng backend nào.
Replicas là công cụ cho mở rộng đọc: thêm nhiều nơi để phục vụ SELECT. Chúng không phải công cụ cho mở rộng ghi: tăng số lượng INSERT/UPDATE/DELETE hệ thống có thể chấp nhận.
Mở rộng đọc: replicas phù hợp với việc gì
Khi thêm replicas, bạn thêm năng lực đọc. Nếu ứng dụng bị nghẽn ở các endpoint đọc (trang sản phẩm, feed, tra cứu), bạn có thể trải các truy vấn đó trên nhiều máy.
Điều này thường cải thiện:\n\n- Độ trễ truy vấn khi tải cao (ít cạnh tranh trên primary)\n- Throughput cho đọc (nhiều CPU/bộ nhớ/I/O cho SELECT)\n- Cô lập các truy vấn nặng, như báo cáo, để không ảnh hưởng giao dịch
Mở rộng ghi: replicas không làm được gì
Hiểu nhầm phổ biến là “nhiều replica = nhiều throughput ghi.” Trong cấu hình primary-replica điển hình, tất cả ghi vẫn tới primary. Thậm chí, nhiều replica hơn có thể làm primary phải làm chút việc thêm, vì nó phải tạo và gửi dữ liệu nhân bản tới mọi replica.
Nếu vấn đề của bạn là throughput ghi, replicas sẽ không khắc phục. Bạn thường cần các cách khác (tối ưu truy vấn/chỉ mục, gom lô, phân vùng/sharding, hoặc thay đổi mô hình dữ liệu).
Giới hạn kết nối và pooling: nút thắt ẩn
Ngay cả khi replicas cho bạn thêm CPU đọc, bạn vẫn có thể chạm tới giới hạn kết nối đầu tiên. Mỗi node có giới hạn số kết nối đồng thời, và thêm replica có thể nhân số nơi ứng dụng có thể kết nối — mà không giảm tổng cầu.
Quy tắc thực tế: dùng connection pooling (hoặc pooler) và giữ số kết nối cho từng dịch vụ có chủ đích. Nếu không, replicas có thể chỉ trở thành “nhiều cơ sở dữ liệu dễ quá tải”.
Đánh đổi chi phí: tài nguyên không miễn phí
Replicas thêm chi phí thực tế:\n\n- Thêm node (chi phí compute)\n- Thêm lưu trữ (mỗi replica thường lưu một bản sao đầy đủ)\n- Thêm công tác vận hành (giám sát lag, chiến lược backup/restore, thay đổi schema, ứng phó sự cố)
Đổi lại: replicas mua cho bạn headroom đọc và cô lập, nhưng tăng độ phức tạp và không nâng trần ghi.
Sẵn sàng cao và Failover: Replicas có thể làm gì
Replicas có thể cải thiện khả dụng cho đọc: nếu primary quá tải hoặc tạm thời không khả dụng, bạn vẫn có thể phục vụ một số nội dung chỉ đọc từ replicas. Điều đó giúp các trang hướng đến khách hàng vẫn phản hồi (với dữ liệu chấp nhận được lỗi thời nhẹ) và giảm vùng ảnh hưởng của sự cố primary.
Những gì replicas không cung cấp là một kế hoạch sẵn sàng cao hoàn chỉnh tự thân. Replica thường không sẵn sàng nhận ghi tự động, và “có bản sao đọc” khác với “hệ thống có thể nhanh chóng an toàn chấp nhận ghi lại”.
Failover thường nghĩa là: phát hiện primary lỗi → chọn một replica → promote nó thành primary mới → chuyển hướng ghi (và thường là đọc) sang node được promote.
Một số dịch vụ được quản lý tự động hóa phần lớn việc này, nhưng ý chính vẫn là: bạn đang thay đổi ai được phép chấp nhận ghi.
Rủi ro chính cần lên kế hoạch
- Dữ liệu replica lỗi thời: replica có thể bị trễ. Nếu bạn promote nó, bạn có thể mất các ghi mới nhất chưa kịp nhân bản.\n- Tránh split-brain: phải ngăn hai node cùng nhận ghi cùng lúc. Vì vậy promotion thường được quản lý bởi một authority (control plane được quản lý, hệ thống quorum, hoặc quy trình vận hành nghiêm ngặt).\n- Định tuyến và cache: ứng dụng cần cách chuyển mục tiêu đáng tin — connection string, DNS, proxy, hoặc router cơ sở dữ liệu. Đảm bảo lưu lượng ghi không “vô tình” tiếp tục tới primary cũ.
Thử nó như một tính năng
Xem failover như thứ bạn luyện tập. Chạy bài test game-day trong staging (và cẩn thận trong production vào cửa sổ rủi ro thấp): mô phỏng mất primary, đo thời gian phục hồi, xác minh định tuyến, và chắc chắn ứng dụng xử lý giai đoạn chỉ đọc và kết nối lại ổn.
Mẫu định tuyến thực tế (tách đọc/ghi)
Replicas chỉ hữu ích nếu lưu lượng thực sự đến được chúng. “Tách đọc/ghi” là tập hợp quy tắc gửi ghi tới primary và các đọc đủ điều kiện tới replicas — mà không phá vỡ tính đúng đắn.
Mẫu 1: Tách trong ứng dụng
Cách đơn giản nhất là định tuyến rõ ràng trong lớp truy cập dữ liệu của bạn:\n\n- Tất cả ghi (INSERT/UPDATE/DELETE, thay đổi schema) đi tới primary.\n- Chỉ một số truy vấn đọc được phép dùng replica.
Cách này dễ hiểu và dễ hoàn tác. Bạn cũng có thể mã hóa quy tắc nghiệp vụ như “sau khi thanh toán, luôn đọc trạng thái đơn hàng từ primary trong một khoảng thời gian ngắn.”
Mẫu 2: Tách qua proxy hoặc driver
Một số đội thích dùng proxy cơ sở dữ liệu hoặc driver thông minh hiểu điểm cuối primary vs replica và định tuyến dựa trên loại truy vấn hoặc cấu hình kết nối. Điều này giảm thay đổi mã ứng dụng, nhưng cẩn trọng: proxy không thể biết chắc truy vấn nào “an toàn” từ góc độ sản phẩm.
Chọn truy vấn nào an toàn để gửi tới replica
Ứng viên tốt:\n\n- Phân tích, báo cáo, workloads dashboard\n- Trang tìm kiếm/duyệt nơi dữ liệu hơi lỗi thời chấp nhận được\n- Job nền có logic thử lại và không cần giá trị mới nhất
Tránh định tuyến các lần đọc ngay sau ghi của người dùng (ví dụ, “cập nhật hồ sơ → tải lại hồ sơ”) trừ khi bạn có chiến lược nhất quán.
Giao dịch và nhất quán phiên
Trong một giao dịch, giữ mọi lần đọc trên primary.
Ngoài giao dịch, cân nhắc “read-your-writes” theo phiên: sau khi ghi, ghim user/session đó vào primary trong TTL ngắn, hoặc định tuyến truy vấn tiếp theo cụ thể về primary.
Bắt đầu nhỏ và đo lường
Thêm một replica, định tuyến một tập endpoint/truy vấn giới hạn, và so sánh trước/sau:\n\n- CPU primary và read IOPS\n- Sử dụng replica\n- Tỷ lệ lỗi và các phần trăm độ trễ\n- Sự cố liên quan đến đọc lỗi thời
Mở rộng định tuyến chỉ khi tác động rõ ràng và an toàn.
Giám sát và vận hành cơ bản
Triển khai và lặp nhanh
Đưa ứng dụng lên hosting và triển khai nhanh, rồi lặp lại khi lưu lượng tăng.
Replicas không phải “cài rồi quên”. Chúng là các máy chủ cơ sở dữ liệu thêm với giới hạn hiệu năng, chế độ lỗi và công việc vận hành riêng. Một chút kỷ luật giám sát thường tạo khác biệt giữa “replicas giúp được” và “replicas gây rối”.
Những gì cần theo dõi (vài chỉ số quan trọng)
Tập trung vào các chỉ báo giải thích triệu chứng người dùng:
- Replica lag: replica đang phía sau primary bao nhiêu (giây, bytes, hoặc vị trí WAL/LSN tùy DB). Đây là cảnh báo sớm cho đọc lỗi thời.\n- Lỗi replication: mất kết nối, lỗi xác thực, đầy đĩa, hoặc vấn đề replication slot. Xử lý những việc này như sự cố, không phải “nhiễu”.\n- Độ trễ truy vấn (p50/p95) trên replica vs primary: replica có thể chậm ngay cả khi primary ổn (do trạng thái cache khác, phần cứng khác, báo cáo lâu).\n- Tỷ lệ trúng cache: replica liên tục thiếu cache có thể hiển thị độ trễ cao sau restart hoặc khi lưu lượng thay đổi.
Lập kế hoạch dung lượng: cần bao nhiêu replica?
Bắt đầu với một replica nếu mục tiêu là giảm tải đọc. Thêm khi bạn có giới hạn rõ ràng:\n\n- Throughput đọc: một replica không chịu được QPS đỉnh hoặc truy vấn phân tích nặng.\n- Cô lập: dành replica cho workload báo cáo để dashboard không ăn tài nguyên của traffic người dùng.\n- Địa lý: một replica mỗi vùng có thể giảm độ trễ đọc, nhưng tăng độ phức tạp vận hành.
Quy tắc thực tế: chỉ scale replicas sau khi xác nhận đọc là nút thắt (không phải chỉ mục, truy vấn chậm, hay cache ứng dụng).
Nhiệm vụ vận hành phổ biến
- Sao lưu: quyết định chỗ chạy backup. Lấy backup từ replica có thể giảm tải cho primary, nhưng xác minh yêu cầu tính nhất quán và replica phải khỏe.\n- Thay đổi schema: test migration với replication trong đầu (DDL chạy lâu có thể tăng lag). Phối hợp rollout để app và schema tương thích trong quá trình nhân bản.\n- Cửa sổ bảo trì: vá hoặc khởi động lại replica tạm thời giảm năng lực đọc. Lên kế hoạch luân phiên để không giảm dưới mức cần thiết.
Checklist xử lý: “replica chậm”
- Kiểm tra replica lag: nếu cao, người dùng có thể retry hoặc thấy dữ liệu cũ.\n2. So sánh slow query logs trên replica vs primary: các truy vấn báo cáo thường hiện lên ở đây.\n3. Xác minh CPU, bộ nhớ, I/O đĩa, và mạng trên host replica.\n4. Tìm đợi khóa hoặc các transaction lâu trên primary làm chậm replication.\n5. Xác nhận định tuyến đọc không quá tải một replica (cân bằng tải không đều).\n6. Kiểm tra chỉ mục trên replica (phải giống primary) và thống kê đã cập nhật.
Các lựa chọn thay thế và khung quyết định đơn giản
Replicas là một công cụ mở rộng đọc, nhưng hiếm khi là cần kéo đầu tiên. Trước khi thêm độ phức tạp vận hành, kiểm tra liệu một sửa đơn giản hơn có cho kết quả tương tự không.
Các lựa chọn thay thế nên thử trước
Caching có thể loại bỏ hoàn toàn các lần đọc khỏi DB. Với các trang “chủ yếu đọc” (chi tiết sản phẩm, hồ sơ công khai, cấu hình), cache ứng dụng hoặc CDN có thể giảm tải đáng kể — mà không đưa vào độ trễ replication.
Chỉ mục và tối ưu truy vấn thường hơn replicas cho trường hợp phổ biến: vài truy vấn tốn nhiều CPU. Thêm chỉ mục đúng, giảm cột SELECT, tránh N+1, sửa join xấu có thể biến “cần replicas” thành “chỉ cần kế hoạch tốt hơn”.
Materialized view / tiền tính toán hữu ích khi workload vốn nặng (phân tích, dashboard). Thay vì chạy lại các truy vấn phức tạp, bạn lưu kết quả đã tính và làm mới định kỳ.
Khi xem xét phân mảnh/phân vùng (sharding/partitioning)
Nếu ghi là nút thắt (hàng nóng, cạnh tranh khóa, giới hạn IOPS ghi), replicas sẽ ít giúp. Khi đó cân nhắc phân vùng theo thời gian/tenant, hoặc sharding theo customer ID để trải tải ghi và giảm cạnh tranh. Đây bước lớn hơn về kiến trúc, nhưng giải quyết nút thắt thực sự.
Khung quyết định đơn giản
Hỏi bốn câu:\n\n1. Mục tiêu là gì? Giảm độ trễ đọc, tách workload báo cáo, hay cải thiện khả dụng?\n2. Dữ liệu phải tươi tới mức nào? Nếu không thể chấp nhận đọc lỗi thời, replicas có thể gây vấn đề.\n3. Ngân sách ra sao? Replicas thêm chi phí hạ tầng và vận hành.\n4. Bạn chịu được bao nhiêu độ phức tạp? Tách đọc/ghi, xử lý eventual consistency và kiểm thử failover đều không đơn giản.
Nếu đang thử nghiệm sản phẩm hoặc dựng dịch vụ nhanh, tốt khi nạp các ràng buộc này vào kiến trúc sớm. Ví dụ, các đội xây trên Koder.ai (nền tảng tạo app React với backend Go + PostgreSQL từ giao diện chat) thường bắt đầu với một primary để đơn giản, rồi chuyển sang replicas khi dashboard, feed hoặc báo cáo nội bộ bắt đầu cạnh tranh với traffic giao dịch. Dùng quy trình planning-first giúp dễ quyết định endpoint nào chấp nhận eventual consistency và endpoint nào phải “read-your-writes” từ primary.
Nếu bạn muốn trợ giúp chọn con đường, xem trang Bảng giá để biết tùy chọn, hoặc duyệt các hướng dẫn liên quan trong trang Blog.