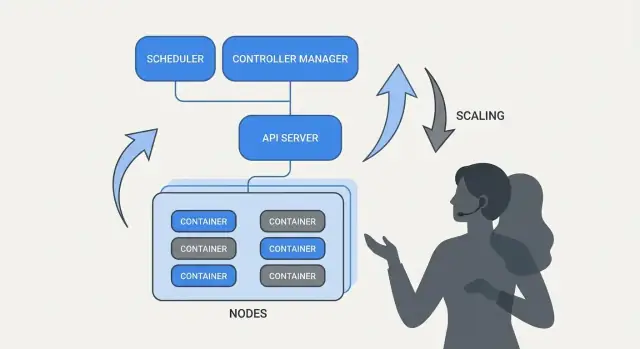
Tại sao Kubernetes thay đổi công việc vận hành hàng ngày
Kubernetes không chỉ giới thiệu một công cụ mới — nó thay đổi cách nhìn về “vận hành hàng ngày” khi bạn chạy hàng chục (hoặc hàng trăm) dịch vụ. Trước khi có orchestration, các đội thường ghép nối script, runbook thủ công và kiến thức truyền miệng để trả lời cùng một loạt câu hỏi: Dịch vụ này nên chạy ở đâu? Làm sao để triển khai thay đổi an toàn? Chuyện gì xảy ra khi một node chết lúc 2 giờ sáng?
Orchestration giải quyết vấn đề gì thực sự
Ở cốt lõi, orchestration là lớp phối hợp giữa ý định của bạn (“chạy dịch vụ này theo điều kiện này”) và thực tế lộn xộn: máy hỏng, lưu lượng thay đổi, và triển khai liên tục. Thay vì coi từng máy là riêng biệt, orchestration xem compute như một pool và workloads là các đơn vị có thể lên lịch và di chuyển.
Kubernetes phổ biến mô hình nơi các đội mô tả những gì họ muốn, và hệ thống liên tục cố gắng làm cho thực tế khớp với mô tả đó. Sự chuyển đổi này quan trọng vì nó làm cho vận hành ít dựa vào hành động anh hùng và hơn vào quy trình lặp được.
Ba kết quả mà các đội cảm nhận ngay lập tức
Kubernetes chuẩn hoá các kết quả vận hành mà hầu hết đội dịch vụ cần:
- Deployment: cách nhất quán để khai báo cái gì nên chạy, cập nhật nó và xác minh nó khỏe mạnh.
- Scaling: con đường thực tế từ một instance tới nhiều instance, mà không phải thiết kế lại dịch vụ hay cung cấp máy thủ công.
- Service operations: cách ổn định để dịch vụ tìm thấy nhau, định tuyến traffic và tiếp tục hoạt động khi các instance thay đổi.
Ghi chú về phạm vi và nguồn tin
Bài viết này tập trung vào các ý tưởng và mẫu liên quan tới Kubernetes (và những người lãnh đạo như Brendan Burns), không phải tiểu sử cá nhân. Khi nói về “bắt đầu thế nào” hay “tại sao thiết kế như vậy”, các khẳng định nên dựa trên nguồn công khai — bài nói tại hội nghị, tài liệu thiết kế và docs upstream — để câu chuyện có thể kiểm chứng thay vì trở thành truyền thuyết.
Brendan Burns trong câu chuyện khởi sinh Kubernetes (Nhìn tổng quát)
Brendan Burns được công nhận là một trong ba đồng sáng lập ban đầu của Kubernetes, cùng với Joe Beda và Craig McLuckie. Trong các công việc ban đầu về Kubernetes tại Google, Burns góp phần định hình cả hướng kỹ thuật lẫn cách giải thích dự án cho người dùng — đặc biệt về “cách bạn vận hành phần mềm” hơn là chỉ “cách bạn chạy container.” (Nguồn: Kubernetes: Up & Running, O’Reilly; danh sách AUTHORS/maintainers của dự án Kubernetes)
Hợp tác mã nguồn mở định hình thiết kế
Kubernetes không chỉ đơn thuần “phát hành” một hệ thống nội bộ đã hoàn thiện; nó được xây dựng công khai với ngày càng nhiều đóng góp, trường hợp sử dụng và ràng buộc. Tính mở này đẩy dự án về phía các giao diện có thể tồn tại trong nhiều môi trường khác nhau:
- API rõ ràng, có phiên bản thay vì chi tiết triển khai ẩn
- hành vi di động giữa các nhà cung cấp cloud và môi trường on-prem
- điểm mở rộng để lõi giữ nhỏ trong khi vẫn hỗ trợ nhiều nhu cầu
Áp lực hợp tác này quan trọng vì nó ảnh hưởng tới những gì Kubernetes tối ưu: các primitive chung và mẫu lặp được mà nhiều đội có thể đồng ý, ngay cả khi họ khác nhau về công cụ.
“Chuẩn hoá” có ý nghĩa gì ở đây
Khi người ta nói Kubernetes “chuẩn hoá” triển khai và vận hành, họ thường không có ý làm cho mọi hệ thống giống hệt nhau. Họ có nghĩa là Kubernetes cung cấp từ vựng chung và tập workflow có thể lặp lại cho các đội:
- “deployment”, “service”, “ingress”, “job”, “namespace” như các thuật ngữ chung
- mô hình nhất quán để khai báo điều bạn muốn (và để hệ thống thực hiện)
- cách có thể đoán trước để rollout thay đổi, scale và phục hồi khi lỗi
Mô hình chung này giúp tài liệu, tooling và thực hành đội chuyển giao dễ dàng giữa các công ty.
Dự án Kubernetes khác với hệ sinh thái
Nên tách biệt Kubernetes (dự án mã nguồn mở) khỏi hệ sinh thái Kubernetes.
Dự án là lõi API và các thành phần control plane thực thi nền tảng. Hệ sinh thái là mọi thứ phát triển xung quanh nó — bản phân phối, dịch vụ quản lý, add-on và các dự án CNCF liên quan. Nhiều “tính năng Kubernetes” mà người dùng tin cậy (stack observability, policy engine, công cụ GitOps) nằm trong hệ sinh thái, không phải trong lõi dự án.
Ý tưởng cốt lõi: Trạng thái mong muốn khai báo (Declarative Desired State)
Cấu hình khai báo là một thay đổi đơn giản trong cách bạn mô tả hệ thống: thay vì liệt kê các bước phải làm, bạn nêu ra kết quả cuối cùng bạn muốn.
Với Kubernetes, bạn không nói nền tảng “chạy container, mở cổng rồi restart nếu crash.” Bạn khai báo “phải có 3 bản sao của app này chạy, có thể truy cập cổng này, dùng image này.” Kubernetes chịu trách nhiệm làm cho thực tế khớp với mô tả đó.
Trạng thái mong muốn khác với script mệnh lệnh
Vận hành mệnh lệnh giống runbook: chuỗi lệnh đã chạy thành công lần trước, chạy lại khi có thay đổi.
Trạng thái mong muốn giống hợp đồng hơn. Bạn ghi lại kết quả mong muốn trong file cấu hình, và hệ thống liên tục làm việc để đạt được kết quả đó. Nếu có drift — một instance chết, node biến mất, thay đổi thủ công trượt vào — nền tảng phát hiện sai lệch và sửa chữa.
Trước/sau: lệnh runbook so với YAML
Trước (tư duy runbook mệnh lệnh):
- SSH vào server
- Pull image mới
- Dừng tiến trình cũ
- Khởi động tiến trình mới
- Cập nhật rule load balancer
- Nếu traffic tăng, lặp trên các server khác
Cách này khả thi nhưng dễ dẫn tới các server “snowflake” và checklist dài chỉ một vài người tin tưởng.
Sau (trạng thái khai báo):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Bạn thay file (ví dụ cập nhật image hoặc replicas), apply nó, và các controller của Kubernetes sẽ reconcile cái đang chạy với cái đã khai báo.
Tại sao giảm công việc lặp và drift
Trạng thái khai báo giảm toil vận hành bằng cách biến “làm 17 bước này” thành “giữ nó như này.” Nó cũng giảm drift vì nguồn chân thực rõ ràng và có thể review — thường trong version control — nên bất ngờ dễ dàng phát hiện, audit và rollback nhất quán.
Controller và Reconciliation: Hệ thống giữ mọi thứ đúng
Kubernetes cảm thấy “tự quản” vì nó xây trên một mẫu đơn giản: bạn mô tả cái bạn muốn, và hệ thống liên tục cố gắng làm cho thực tế khớp. Động cơ của mẫu này là controller.
Controller là gì (nói đơn giản)
Controller là một vòng lặp quan sát trạng thái cluster, so sánh với trạng thái mong muốn bạn khai báo trong YAML (hoặc qua API). Khi thấy khoảng cách, nó hành động để thu hẹp khoảng cách đó.
Nó không phải là script chạy một lần hay chờ người bấm nút. Nó chạy lặp đi lặp lại — quan sát, quyết định, hành động — để phản ứng với thay đổi bất cứ lúc nào.
Reconciliation: Kubernetes “giữ mọi thứ đúng” như thế nào
Hành vi so sánh và sửa chữa lặp lại này gọi là reconciliation. Đó là cơ chế đằng sau lời hứa “self-healing.” Hệ thống không ngăn mọi lỗi xảy ra; nó nhận ra drift và sửa lại.
Drift có thể xảy ra vì lý do bình thường:
- một tiến trình crash
- một node biến mất
- ai đó scale lên hoặc xuống
- một deployment được cập nhật
Reconciliation nghĩa là Kubernetes coi những sự kiện đó như tín hiệu để kiểm tra lại ý định và khôi phục nó.
Kết quả mà người ta quan tâm thực sự
Controller chuyển thành các kết quả vận hành quen thuộc:
- Thay thế Pod thất bại: nếu một Pod chết, controller nhận ra bạn vẫn muốn nó và lên lịch tạo Pod mới.
- Giữ số replica ổn định: nếu bạn yêu cầu 5 replica mà chỉ chạy 4, Kubernetes sẽ tạo bản thiếu.
- Duy trì tiến độ rollout: trong khi cập nhật, controller đưa hệ thống về phiên bản mới trong khi cố giữ độ sẵn sàng.
Điểm then chốt là bạn không đi săn triệu chứng bằng tay. Bạn khai báo mục tiêu, và các vòng điều khiển làm công việc “giữ cho đúng” liên tục.
Tại sao cách này mở rộng vượt ra ngoài một tính năng
Cách tiếp cận này không giới hạn ở một loại tài nguyên. Kubernetes dùng cùng ý tưởng controller-and-reconciliation trên nhiều object — Deployment, ReplicaSet, Job, Node, endpoint, v.v. Sự nhất quán này là lý do lớn khiến Kubernetes trở thành nền tảng: một khi hiểu mẫu, bạn có thể dự đoán hành vi khi thêm khả năng mới (bao gồm custom resource tuân theo cùng vòng lặp).
Scheduling là một tính năng sản phẩm, không phải nhiệm vụ thủ công
Plan the rollout first
Dùng Planning Mode để vẽ sơ đồ dịch vụ, API và kế hoạch rollout trước khi thay đổi mã.
Nếu Kubernetes chỉ "chạy container" thì vẫn còn phần khó nhất: quyết định workload chạy ở đâu. Scheduling là hệ thống tích hợp đặt Pod lên node phù hợp tự động, dựa trên nhu cầu tài nguyên và quy tắc bạn định nghĩa.
Điều này quan trọng vì quyết định đặt ảnh hưởng trực tiếp tới uptime và chi phí. Một API web nằm trên node quá tải có thể chậm hoặc chết. Một job batch cạnh dịch vụ nhạy về độ trễ có thể gây noisy-neighbor. Kubernetes biến việc này thành khả năng sản phẩm có thể lặp lại thay vì routine spreadsheet-and-SSH.
Scheduler tối ưu cho điều gì
Ở mức cơ bản, scheduler tìm node có thể đáp ứng yêu cầu của Pod.
- CPU/memory requests: requests giữ chỗ cho quyết định placement. Nếu bạn yêu cầu 500m CPU và 1Gi memory, Kubernetes chỉ xem xét node có đủ dung lượng trống.
Thói quen quan trọng này — đặt requests thực tế — thường giảm bất ổn “ngẫu nhiên” vì dịch vụ quan trọng không còn cạnh tranh với mọi thứ khác.
Ràng buộc phổ biến các đội thường dùng
Ngoài tài nguyên, hầu hết cluster production dùng vài quy tắc thực tế:
- Affinity / anti-affinity: “đặt cùng nhau” (để locality cache) hoặc “giữ tách” (để tránh một lỗi node làm mất mọi replica).
- Taints và tolerations: đánh dấu node là đặc biệt (GPU, node hệ thống, node tuân thủ) và cho phép chỉ workloads được phê duyệt lên đó.
Cách này giảm outage
Các tính năng scheduling giúp đội mã hóa ý định vận hành:
- Trải replica qua nhiều node để sống sót khi một node chết.
- Cô lập job có dạng spiky khỏi dịch vụ hướng tới khách hàng.
- Ngăn node đắt tiền (như GPU) bị chiếm bởi workload không đúng.
Bài học thực tế: coi quy tắc scheduling như yêu cầu sản phẩm — ghi lại, review và áp dụng nhất quán — để độ tin cậy không phụ thuộc vào người nhớ “node đúng” lúc 2 giờ sáng.
Scaling: Từ một instance tới hàng nghìn mà không cần viết lại
Một ý tưởng thực tế của Kubernetes là scaling không nên yêu cầu thay đổi code ứng dụng hay phát minh cách triển khai mới. Nếu app chạy được như một container, cùng định nghĩa workload thường có thể mở rộng thành hàng trăm hoặc hàng nghìn bản sao.
Scaling có hai lớp
Kubernetes tách scaling thành hai quyết định liên quan:
- Chạy bao nhiêu pod (nhiều bản sao hơn để tăng throughput hoặc độ dự phòng).
- Bạn có bao nhiêu capacity cluster (đủ node — và đúng kích thước — để đặt các pod đó).
Sự tách này quan trọng: bạn có thể yêu cầu 200 pod, nhưng nếu cluster chỉ có chỗ cho 50, “scaling” trở thành hàng đợi các pod pending.
Autoscaling, khái niệm (HPA, VPA, Cluster Autoscaler)
Kubernetes thường dùng ba autoscaler, mỗi cái tập trung trên một đòn bẩy khác nhau:
- Horizontal Pod Autoscaler (HPA): thay đổi số pod dựa trên tín hiệu như CPU, memory hoặc metrics ứng dụng tuỳ chỉnh.
- Vertical Pod Autoscaler (VPA): điều chỉnh requests/limits của pod để mỗi pod có nhiều hoặc ít CPU/memory hơn.
- Cluster Autoscaler: thêm hoặc loại bỏ node để scheduler có đủ chỗ đặt pod bạn yêu cầu.
Kết hợp lại, điều này biến scaling thành chính sách: “giữ latency ổn định” hoặc “giữ CPU quanh X%,” thay vì routine phải gọi người.
"Good scaling" phụ thuộc vào gì
Scaling chỉ hiệu quả khi các đầu vào tốt:
- Metrics: CPU dễ đo nhưng không luôn phản ánh; tỉ lệ yêu cầu, độ dài hàng đợi và latency thường phù hợp hơn với tải thực.
- Resource requests/limits: cho scheduler biết pod cần gì. Thiếu chúng, placement và autoscaling trở thành phỏng đoán.
- Mẫu tải: traffic nhọn, warm-up chậm và job nền nặng thay đổi cách scaling nên phản ứng.
Cạm bẫy phổ biến
Hai lỗi lặp lại: scale theo metric sai (CPU thấp nhưng request timeout) và thiếu resource requests (autoscaler không dự đoán dung lượng, pod bị đóng gói quá chặt và performance không ổn định).
Triển khai an toàn: Rollouts, Probes và Rollbacks
Một thay đổi lớn mà Kubernetes phổ biến là coi “triển khai” như bài toán điều khiển liên tục, không phải script một lần chạy lúc 5 giờ chiều Thứ Sáu. Rollouts và rollbacks là hành vi quan trọng: bạn khai báo phiên bản muốn, và Kubernetes di chuyển hệ thống về nó trong khi liên tục kiểm tra liệu thay đổi có an toàn hay không.
Rollout như chuyển tiếp có kiểm soát
Với một Deployment, rollout là thay thế dần các Pod cũ bằng Pod mới. Thay vì dừng hết rồi khởi động lại, Kubernetes cập nhật theo bước—giữ dung lượng trong khi phiên bản mới chứng minh nó chịu được traffic thực.
Nếu phiên bản mới bắt đầu lỗi, rollback không còn là thủ tục khẩn cấp. Đó là thao tác bình thường: bạn có thể revert về ReplicaSet trước (phiên bản tốt gần nhất) và để controller khôi phục trạng thái cũ.
Probes: tránh release “chạy nhưng không đúng”
Health checks biến rollout từ “hy vọng” thành đo lường được.
- Readiness probes quyết định Pod có nên nhận traffic hay không. Container có thể đang chạy nhưng chưa sẵn sàng (warm cache, chờ phụ thuộc). Readiness ngăn traffic đi tới instance chưa đáp ứng.
- Liveness probes phát hiện khi container bị treo hoặc hỏng và cần restart. Điều này tránh chế độ lỗi chậm khi một tiến trình còn sống nhưng không hoạt động.
Dùng probes đúng, bạn giảm các thành công ảo — deployment trông ổn vì Pod khởi nhưng thực tế request bị lỗi.
Chiến lược triển khai: rolling, blue/green, canary
Kubernetes hỗ trợ rolling update mặc định, nhưng các đội thường xếp thêm các mẫu khác:
- Blue/green: giữ hai môi trường đầy đủ và chuyển traffic từ blue sang green khi green đã được xác minh.
- Canary: gửi một phần nhỏ traffic tới phiên bản mới, theo dõi metrics rồi mở rộng dần.
An toàn có thể đo lường (và tự động hóa)
Triển khai an toàn dựa trên tín hiệu: error rate, latency, saturation và tác động tới người dùng. Nhiều đội liên kết quyết định rollout với SLOs và error budgets — nếu canary tiêu quá nhiều budget, việc promote sẽ dừng.
Mục tiêu là trigger rollback tự động dựa trên chỉ báo thực (failed readiness, tăng 5xx, spike latency), để “rollback” trở thành phản ứng hệ thống dự đoán được — không phải pha hành động anh hùng nửa đêm.
Service Operations: Khám phá, Định tuyến và Mạng ổn định
Launch the web app
Tạo giao diện React khớp với ranh giới dịch vụ và nhịp độ phát hành của bạn.
Một nền tảng container chỉ cảm thấy “tự động” nếu các phần khác của hệ thống vẫn có thể tìm tới app của bạn sau khi nó di chuyển. Trong cluster production thực tế, pod được tạo, xoá, reschedule và scale liên tục. Nếu mỗi thay đổi bắt buộc cập nhật IP trong config, vận hành sẽ thành công việc luẩn quẩn—và outage sẽ là chuyện thường.
Tại sao khám phá dịch vụ quan trọng
Service discovery là cách để client có đường tới các backend đang thay đổi. Trong Kubernetes, chuyển đổi then chốt là bạn thôi không target từng instance (“gọi 10.2.3.4”) mà thay vào đó target một tên service (“gọi checkout”). Nền tảng xử lý việc pod nào đang phục vụ tên đó.
Services, selectors và endpoints (ngôn ngữ đơn giản)
Một Service là cửa trước ổn định cho một nhóm pod. Nó có tên và địa chỉ ảo nhất quán trong cluster, ngay cả khi pod bên dưới thay đổi.
Một selector là cách Kubernetes quyết định pod nào “đứng sau” cửa trước đó. Thường là match theo label, như app=checkout.
Endpoints (hoặc EndpointSlices) là danh sách sống các IP pod hiện tại khớp selector. Khi pod scale, rollout hoặc được reschedule, danh sách này cập nhật tự động — client vẫn dùng cùng tên Service.
Địa chỉ ổn định, load balancing và định tuyến traffic
Về mặt vận hành, điều này cung cấp:
- Địa chỉ ổn định: app gọi tên DNS của Service thay vì đuổi IP Pod.
- Load balancing: traffic được phân phối trên các pod khỏe mạnh phía sau Service.
- Định tuyến có thể dự đoán: bạn tách “ai nên nhận traffic” (labels/selectors) khỏi “pod thực sự chạy ở đâu.”
Với traffic từ ngoài vào (north–south), Kubernetes thường dùng Ingress hoặc cách tiếp cận mới hơn Gateway. Cả hai cho điểm vào có kiểm soát, nơi bạn có thể định tuyến theo hostname hoặc path, và thường tập trung các mối quan tâm như TLS termination. Ý tưởng quan trọng vẫn vậy: giữ truy cập ngoài ổn định trong khi backend thay đổi bên dưới.
Self-Healing: Ý nghĩa thực tế trong production
“Self-healing” trong Kubernetes không phải phép màu. Đó là tập hợp các phản ứng tự động với lỗi: restart, reschedule và replace. Nền tảng quan sát thứ bạn nói là mong muốn (desired state) và liên tục thúc đẩy thực tế trở về nó.
Restart: khi container crash
Nếu process exit hoặc container không khỏe, Kubernetes có thể restart trên cùng node. Điều này thường do:
- Liveness probes: “Container vẫn hoạt động không?” Nếu không, restart.
- Restart policies: quy tắc khi nào restart được phép.
Mô hình production phổ biến: một container crash → Kubernetes restart nó → Service tiếp tục route chỉ tới Pod khỏe.
Reschedule và replace: khi node chết
Nếu một node toàn bộ sập (lỗi phần cứng, kernel panic, mất mạng), Kubernetes đánh dấu node không ready và bắt đầu dời workload đi nơi khác. Ở mức cao:
- Node được đánh dấu không khỏe/không ready.
- Các Pod từng chạy ở đó bị coi như mất.
- Controller tạo Pod thay thế trên node khỏe khác để khôi phục số replica mong muốn.
Đây là self-healing ở cấp cluster: hệ thống thay thế capacity thay vì chờ người ssh vào sửa.
Observability: làm sao biết nó đang tự chữa
Self-healing chỉ hữu ích nếu bạn có thể xác minh. Đội thường theo dõi:
- Logs (log ứng dụng và event nền tảng) để thấy cái gì restart và vì sao
- Metrics như restart counts, failed probes và node readiness
- Alerts khi healing không hoạt động (ví dụ CrashLoopBackOff lặp, thiếu replica, hoặc quá nhiều eviction)
Cấu hình sai phá vỡ self-healing
Ngay cả với Kubernetes, “healing” có thể thất bại nếu các rào chắn sai:
- Liveness/readiness probes sai hoặc thiếu (false positive hoặc Pod mãi không ready)
- Thiếu resource requests/limits, dẫn tới scheduling không đoán trước được hoặc OOM kill
- Quá ít replica (một Pod đơn không đảm bảo tính liên tục)
- Thời gian probe quá hung hãn gây restart storm
- Workload dựa vào state node-local mà không có chiến lược lưu trữ bền
Khi self-healing được thiết lập tốt, outage nhỏ hơn và ngắn hơn — và quan trọng hơn, có thể đo lường.
API chuẩn và khả năng mở rộng: Tại sao Kubernetes trở thành nền tảng
Ship a clean backend
Tạo API Go với các model PostgreSQL phù hợp các quy trình triển khai lặp lại.
Kubernetes không thắng chỉ vì nó chạy container. Nó thắng vì cung cấp API chuẩn cho nhu cầu vận hành phổ biến nhất — deploy, scale, networking và observability. Khi các đội đồng ý về cùng “hình dạng” của object (như Deployment, Service, Job), tools có thể chia sẻ trong các tổ chức, đào tạo đơn giản hơn và việc bàn giao giữa dev và ops không còn dựa vào kiến thức truyền miệng.
Tại sao API chuẩn thay đổi workflow đội
API nhất quán nghĩa là pipeline deploy không phải biết quirks của từng app. Nó có thể áp dụng cùng hành động — create, update, rollback, check health — dùng cùng khái niệm Kubernetes.
Nó cũng cải thiện sự đồng bộ: team security có thể biểu đạt guardrail dưới dạng policy; SRE chuẩn hoá runbook quanh tín hiệu sức khỏe chung; dev có thể suy nghĩ về release với từ vựng chung.
Mở rộng Kubernetes: CRDs và Operators
Chuyển sang “nền tảng” rõ rệt với Custom Resource Definitions (CRDs). CRD cho phép bạn thêm kiểu object mới vào cluster (ví dụ Database, Cache, Queue) và quản lý nó theo cùng API như tài nguyên tích hợp.
Một Operator ghép các object tùy chỉnh đó với controller liên tục reconcile thực tế về trạng thái mong muốn — xử lý những tác vụ từng là thủ công, như backup, failover hay nâng cấp phiên bản. Lợi ích chính không phải tự động thần kỳ; mà là tái sử dụng cùng vòng điều khiển mà Kubernetes áp dụng cho mọi thứ khác.
Phù hợp với GitOps, CI/CD và kiểm tra policy
Vì Kubernetes điều khiển bằng API, nó tích hợp tốt với workflow hiện đại:
- GitOps: trạng thái mong muốn nằm trong Git; thay đổi được review như code.
- CI/CD: pipeline apply manifest, chờ ready và promote phiên bản.
- Policy checks: admission controller có thể chặn config rủi ro trước khi vào production.
Nếu bạn muốn hướng dẫn triển khai và vận hành thực tế hơn dựa trên những ý tưởng này, hãy tham khảo /blog.
Những gì các đội có thể áp dụng hôm nay (Ngay cả ngoài Kubernetes)
Những ý tưởng lớn của Kubernetes — nhiều cái liên quan tới khung sớm của Brendan Burns — chuyển sang môi trường VM, serverless hay setup container nhỏ tốt.
Mẫu cải thiện vận hành hàng ngày
Ghi lại “trạng thái mong muốn” và để tự động hoá thực thi nó. Dù là Terraform, Ansible hay pipeline CI, coi cấu hình như nguồn chân thực. Kết quả là ít bước deploy thủ công và ít bất ngờ “chạy trên máy tôi”.
Dùng reconciliation, không phải script một lần. Thay vì script chạy một lần rồi chờ kết quả, xây vòng lặp kiểm tra liên tục các thuộc tính chính (version, config, số instance, sức khỏe). Đây là cách bạn đạt vận hành lặp lại và phục hồi dự đoán.
Biến scheduling và scaling thành tính năng sản phẩm rõ ràng. Định nghĩa khi nào và vì sao tăng capacity (CPU, độ dài hàng đợi, SLO latency). Dù không có autoscaling Kubernetes, đội vẫn có thể chuẩn hoá quy tắc scale để tăng trưởng không cần viết lại app hay đánh thức ai đó.
Chuẩn hoá rollout. Rolling update, health checks và thủ tục rollback nhanh giảm rủi ro thay đổi. Bạn có thể thực hiện bằng load balancer, feature flags và pipeline deploy ràng buộc release theo tín hiệu thực.
Checklist áp dụng an toàn
- Xác định trạng thái mong muốn của service: version, config, dependencies và số instance tối thiểu
- Thêm endpoint health (tương đương liveness và readiness) và nối chúng vào load balancer hoặc pipeline deploy
- Tự động hóa các bước rollout: deploy, verify, chuyển traffic, rollback khi thất bại
- Tạo một “reconciler” nhỏ: các kiểm tra định kỳ sửa drift (config sai, instance thiếu)
- Thêm trigger scaling với giới hạn rõ ràng (max instances, cooldown, quy tắc phê duyệt)
Những thứ mẫu này không tự giải quyết
Những mẫu trên không sửa được thiết kế app kém, migration dữ liệu không an toàn, hay kiểm soát chi phí. Bạn vẫn cần API có version, kế hoạch migration, ngân sách/giới hạn và observability liên kết deploy tới tác động khách hàng.
Bước tiếp theo
Chọn một dịch vụ hướng tới khách hàng và triển khai checklist end-to-end, rồi mở rộng.
Nếu bạn đang xây dịch vụ mới và muốn ra “cái gì đó có thể deploy” nhanh hơn, Koder.ai có thể giúp tạo ứng dụng web/backend/mobile đầy đủ từ một đặc tả qua chat — thường React frontend, Go với PostgreSQL backend và Flutter cho mobile — rồi xuất mã nguồn để bạn áp dụng các mẫu Kubernetes đã thảo luận ở đây (cấu hình khai báo, rollout lặp được và vận hành dễ rollback). Nếu đội bạn đánh giá chi phí và quản trị, bạn cũng có thể xem /pricing.