14 thg 7, 2025·8 phút
Chiến lược quản lý bộ nhớ: Hiệu năng và An toàn trong các ngôn ngữ
Tìm hiểu cách garbage collection, ownership và đếm tham chiếu ảnh hưởng tới tốc độ, độ trễ và bảo mật — và cách chọn ngôn ngữ phù hợp mục tiêu của bạn.
Tìm hiểu cách garbage collection, ownership và đếm tham chiếu ảnh hưởng tới tốc độ, độ trễ và bảo mật — và cách chọn ngôn ngữ phù hợp mục tiêu của bạn.
Quản lý bộ nhớ là tập hợp các quy tắc và cơ chế mà chương trình dùng để yêu cầu bộ nhớ, sử dụng nó và trả lại nó. Mọi chương trình đang chạy đều cần bộ nhớ cho biến, dữ liệu người dùng, bộ đệm mạng, ảnh và kết quả trung gian. Vì bộ nhớ có hạn và được chia sẻ với hệ điều hành cùng các ứng dụng khác, các ngôn ngữ phải quyết định ai chịu trách nhiệm giải phóng và khi nào việc đó xảy ra.
Những quyết định ấy hình thành hai kết quả mà hầu hết mọi người quan tâm: chương trình chạy có cảm giác nhanh như thế nào, và hành vi của nó có đáng tin cậy khi bị tải nặng hay không.
Hiệu năng không phải một con số đơn lẻ. Quản lý bộ nhớ có thể ảnh hưởng tới:
Một ngôn ngữ cấp phát nhanh nhưng đôi khi tạm dừng để dọn dẹp có thể trông rất tốt trên benchmark nhưng cảm giác giật trong ứng dụng tương tác. Một mô hình khác tránh tạm dừng có thể đòi hỏi thiết kế cẩn thận hơn để tránh rò rỉ và sai sót về thời hạn sống (lifetime).
An toàn liên quan đến việc ngăn ngừa lỗi liên quan bộ nhớ, chẳng hạn:
Nhiều vấn đề bảo mật nổi tiếng bắt nguồn từ sai lầm về bộ nhớ như use-after-free hoặc buffer overflow.
Hướng dẫn này là một chuyến tham quan không quá kỹ thuật về các mô hình bộ nhớ chính được dùng bởi các ngôn ngữ phổ biến, những gì chúng tối ưu hóa và các đánh đổi bạn chấp nhận khi chọn một ngôn ngữ.
Bộ nhớ là nơi chương trình giữ dữ liệu trong khi chạy. Hầu hết ngôn ngữ tổ chức quanh hai khu vực chính: stack và heap.
Hãy tưởng tượng stack như một chồng giấy ghi chú gọn gàng dùng cho nhiệm vụ hiện tại. Khi một hàm bắt đầu, nó có một “khung” nhỏ trên stack cho biến cục bộ. Khi hàm kết thúc, toàn bộ khung đó bị loại bỏ cùng lúc.
Điều này nhanh và có thể dự đoán—nhưng chỉ hoạt động với giá trị có kích thước biết trước và thời hạn sống kết thúc cùng lúc với cuộc gọi hàm.
Heap giống như một kho lưu trữ nơi bạn có thể giữ đối tượng bao lâu bạn cần. Nó phù hợp cho danh sách thay đổi kích thước, chuỗi, hoặc đối tượng chia sẻ giữa nhiều phần của chương trình.
Vì đối tượng trên heap có thể sống lâu hơn một hàm, câu hỏi then chốt là: ai chịu trách nhiệm giải phóng và khi nào? Trách nhiệm đó là “mô hình quản lý bộ nhớ” của một ngôn ngữ.
Một pointer hoặc reference là cách truy cập đối tượng gián tiếp—như có số kệ cho một hộp trong kho. Nếu hộp bị vứt đi nhưng bạn vẫn giữ số kệ, bạn có thể đọc dữ liệu rác hoặc gây sập (một lỗi use-after-free cổ điển).
Hãy tưởng tượng vòng lặp tạo một bản ghi khách hàng, format một thông điệp và loại bỏ nó:
Một số ngôn ngữ che giấu chi tiết này (dọn dẹp tự động), trong khi những ngôn ngữ khác phơi bày (bạn tự giải phóng bộ nhớ, hoặc phải theo quy tắc ai là chủ sở hữu). Phần còn lại của bài viết khám phá cách những lựa chọn đó ảnh hưởng tới tốc độ, tạm dừng và an toàn.
Quản lý bộ nhớ thủ công nghĩa là chương trình (và nhà phát triển) rõ ràng yêu cầu cấp phát bộ nhớ và sau đó giải phóng. Thực tế có dạng malloc/free trong C, hoặc new/delete trong C++. Vẫn phổ biến trong lập trình hệ thống nơi cần kiểm soát chính xác thời điểm lấy và trả bộ nhớ.
Bạn thường cấp phát khi một đối tượng phải sống lâu hơn cuộc gọi hàm hiện tại, thay đổi kích thước động (ví dụ bộ đệm có thể thay đổi), hoặc cần layout cụ thể để tương tác với phần cứng, hệ điều hành hay giao thức mạng.
Khi không có garbage collector chạy nền, sẽ ít tạm dừng bất ngờ hơn. Việc cấp phát và giải phóng có thể được làm rất dự đoán, đặc biệt khi kết hợp với bộ cấp phát tùy chỉnh, pool hoặc bộ đệm kích thước cố định.
Kiểm soát thủ công cũng giảm overhead: không có giai đoạn dò vết, không có write barrier, và thường ít metadata cho mỗi đối tượng. Khi code được thiết kế cẩn thận, bạn có thể đạt được mục tiêu độ trễ chặt chẽ và giữ mức sử dụng bộ nhớ trong giới hạn.
Đổi lại, chương trình có thể mắc lỗi mà runtime không tự ngăn chặn:
Những lỗi này có thể gây sập, hỏng dữ liệu và lỗ hổng bảo mật.
Các nhóm giảm rủi ro bằng cách thu hẹp nơi cho phép cấp phát thô và dựa vào các mẫu như:
std::unique_ptr) để mã hóa ownershipQuản lý thủ công thường là lựa chọn tốt cho phần mềm nhúng, hệ thống thời gian thực, thành phần hệ điều hành và thư viện hiệu năng cao—những nơi kiểm soát chặt chẽ và độ trễ dự đoán quan trọng hơn sự tiện lợi cho nhà phát triển.
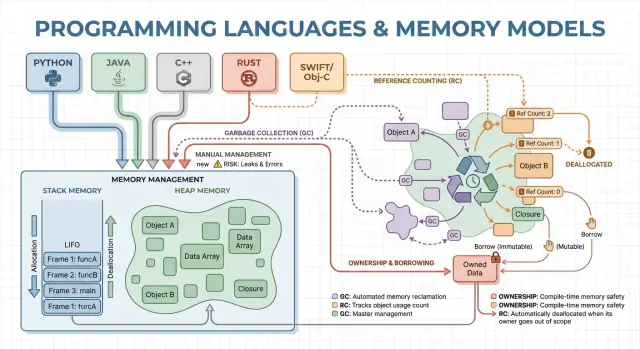
Garbage collection (GC) là dọn dẹp bộ nhớ tự động: thay vì bạn phải free thủ công, runtime theo dõi đối tượng và thu hồi những đối tượng không còn khả năng truy cập. Thực tế, điều này cho phép bạn tập trung vào hành vi và luồng dữ liệu trong khi hệ thống xử lý hầu hết các quyết định cấp phát và giải phóng.
Phần lớn collector hoạt động bằng cách xác định các đối tượng sống trước, rồi thu hồi phần còn lại.
Tracing GC bắt đầu từ “rễ” (như biến trên stack, tham chiếu toàn cục và thanh ghi), theo các tham chiếu để đánh dấu mọi thứ có thể truy cập, rồi quét heap để giải phóng các đối tượng không được đánh dấu. Nếu không có gì trỏ tới đối tượng, nó đủ điều kiện để thu hồi.
Generational GC dựa trên quan sát nhiều đối tượng chết non. Nó chia heap thành các thế hệ và thu gom phần trẻ thường xuyên, thường rẻ hơn và cải thiện hiệu quả tổng thể.
Concurrent GC chạy một phần quá trình thu gom song song với các luồng ứng dụng, nhằm giảm thời gian tạm dừng dài. Nó có thể tốn công bookkeeping hơn để giữ quan điểm bộ nhớ nhất quán khi chương trình tiếp tục chạy.
GC thường đánh đổi kiểm soát thủ công lấy công việc runtime. Một số hệ thống ưu tiên thông lượng ổn định (nhiều công việc mỗi giây) nhưng có thể gây stop-the-world pauses. Các hệ thống khác giảm tối đa pause cho ứng dụng nhạy độ trễ nhưng có thể thêm overhead trong khi chạy bình thường.
GC loại bỏ cả lớp lỗi về lifetime (đặc biệt use-after-free) vì đối tượng không bị thu hồi khi vẫn có thể truy cập. Nó cũng giảm rò rỉ do quên giải phóng (mặc dù bạn vẫn có thể “rò rỉ” bằng cách giữ tham chiếu lâu hơn cần thiết). Trong codebase lớn, khi ownership khó theo dõi thủ công, GC thường giúp tăng tốc độ phát triển.
Runtime có GC phổ biến trên JVM (Java, Kotlin), .NET (C#, F#), Go và các engine JavaScript trong trình duyệt và Node.js.
Đếm tham chiếu (reference counting) là chiến lược quản lý bộ nhớ nơi mỗi đối tượng theo dõi có bao nhiêu “chủ sở hữu” (tham chiếu) trỏ tới nó. Khi số đếm về 0, đối tượng được giải phóng ngay lập tức. Sự tức thời này dễ hiểu: ngay khi không ai có thể truy cập đối tượng, bộ nhớ được thu hồi.
Mỗi khi bạn sao chép hoặc lưu một tham chiếu đến đối tượng, runtime tăng bộ đếm; khi một tham chiếu biến mất, nó giảm. Chạm 0 thì kích hoạt dọn dẹp ngay lập tức.
Điều này làm cho quản lý tài nguyên trực quan: đối tượng thường trả lại bộ nhớ gần thời điểm bạn ngừng dùng nó, giúp giảm đỉnh bộ nhớ và tránh dọn dẹp trễ.
Đếm tham chiếu có xu hướng có overhead đều đặn, liên tục: các phép tăng/giảm xảy ra ở nhiều phép gán và cuộc gọi hàm. Overhead này thường nhỏ, nhưng xuất hiện khắp nơi.
Ưu điểm là bạn thường không gặp các pause toàn bộ lớn như một số tracing GC có thể gây ra. Độ trễ thường mượt hơn, dù vẫn có thể xảy ra đợt dọn dẹp khi một đồ thị đối tượng lớn mất chủ cuối cùng.
Đếm tham chiếu không thể thu hồi các đối tượng tham chiếu vòng (cycle). Nếu A tham chiếu B và B tham chiếu A, cả hai bộ đếm đều lớn hơn 0 ngay cả khi không ai khác trỏ tới chúng—tạo rò rỉ.
Các hệ sinh thái xử lý bằng vài cách:
Ownership và borrowing là mô hình bộ nhớ gắn liền nhất với Rust. Ý tưởng đơn giản: trình biên dịch áp các quy tắc làm cho khó tạo dangling pointer, double-free và nhiều race condition—mà không phụ thuộc vào garbage collector tại runtime.
Mỗi giá trị có đúng một “chủ” tại một thời điểm. Khi chủ ra khỏi scope, giá trị được dọn dẹp ngay và có thể dự đoán. Điều này cho bạn quản lý tài nguyên xác định (bộ nhớ, file handle, socket) tương tự như dọn thủ công nhưng với ít cách làm sai hơn.
Ownership cũng có thể được chuyển (move): gán giá trị cho biến mới hoặc truyền vào hàm có thể chuyển trách nhiệm. Sau một move, ràng buộc cũ không thể dùng nữa, ngăn use-after-free ngay từ thiết kế.
Borrowing cho phép bạn dùng giá trị mà không trở thành chủ.
Một shared borrow cho phép truy cập chỉ đọc và có thể sao chép tự do.
Một mutable borrow cho phép sửa đổi, nhưng phải độc quyền: khi nó tồn tại, không có ai khác được đọc hoặc ghi cùng giá trị đó. Quy tắc “một người ghi hoặc nhiều người đọc” này được kiểm tra ở thời điểm biên dịch.
Vì lifetimes được theo dõi, trình biên dịch có thể từ chối mã sẽ sống lâu hơn dữ liệu mà nó tham chiếu, loại bỏ nhiều lỗi dangling-reference. Cùng quy tắc này cũng ngăn nhiều loại race condition trong code đồng thời.
Đổi lại là đường cong học tập và một số hạn chế thiết kế. Bạn có thể cần tổ chức lại luồng dữ liệu, giới thiệu ranh giới ownership rõ hơn hoặc dùng kiểu chuyên biệt cho trạng thái chia sẻ có thể thay đổi.
Mô hình này phù hợp cho mã hệ thống—dịch vụ, nhúng, mạng và thành phần nhạy hiệu năng—nơi bạn muốn dọn dẹp xác định và độ trễ thấp mà không muốn pause của GC.
Khi bạn tạo nhiều đối tượng sống ngắn—node AST trong parser, thực thể trong frame game, dữ liệu tạm trong một request—chi phí cấp phát và giải phóng từng đối tượng có thể chiếm phần lớn thời gian. Arenas (còn gọi là regions) và pools là mẫu đánh đổi việc giải phóng từng đối tượng lấy quản lý hàng loạt nhanh.
Arena là một “vùng” bộ nhớ nơi bạn cấp phát nhiều đối tượng theo thời gian, rồi giải phóng tất cả chúng cùng lúc bằng cách reset hoặc drop arena.
Thay vì theo dõi lifetime từng đối tượng, bạn gắn lifetime vào một ranh giới rõ ràng: “tất cả cấp cho request này”, hoặc “tất cả cấp khi biên dịch hàm này”.
Arenas thường nhanh vì:
Điều này có thể tăng thông lượng và giảm spike độ trễ do free thường xuyên hoặc tranh chấp allocator.
Arenas/pools xuất hiện trong:
Quy tắc chính: đừng để tham chiếu chạy khỏi region sở hữu bộ nhớ. Nếu cái gì đó cấp trong arena được lưu global hoặc trả ra ngoài lifetime của arena, bạn có nguy cơ use-after-free.
Ngôn ngữ và thư viện xử lý khác nhau: một số dựa vào kỷ luật và API, số khác mã hóa ranh giới region vào kiểu.
Arenas/pools không thay thế GC hoặc ownership—thường là bổ sung. Ngôn ngữ GC vẫn dùng pool cho các đường nóng; ngôn ngữ ownership có thể dùng arena để nhóm cấp phát và làm lifetime rõ ràng. Dùng cẩn thận, chúng đem lại “cấp phát nhanh mặc định” mà không mất sự rõ ràng khi giải phóng bộ nhớ.
Mô hình bộ nhớ của ngôn ngữ chỉ là một phần của câu chuyện hiệu năng và an toàn. Compiler hiện đại và runtime viết lại chương trình của bạn để cấp phát ít hơn, giải phóng sớm hơn và tránh bookkeeping thừa. Đó là lý do các quy tắc như “GC chậm” hay “thủ công luôn nhanh nhất” thường thất bại trong ứng dụng thực tế.
Nhiều cấp phát chỉ tồn tại để truyền dữ liệu giữa hàm. Với escape analysis, compiler có thể chứng minh một đối tượng không sống quá scope hiện tại và giữ nó trên stack thay vì heap.
Điều đó loại bỏ hoàn toàn một cấp phát heap, cùng với chi phí liên quan (theo dõi GC, cập nhật đếm tham chiếu, khóa allocator). Trong ngôn ngữ quản lý, đây là lý do lớn khiến các đối tượng nhỏ có thể rẻ hơn bạn tưởng.
Khi compiler inline một hàm (thay cuộc gọi bằng thân hàm), nó có thể “nhìn xuyên” qua lớp trừu tượng. Tầm nhìn này cho phép tối ưu như:
API được thiết kế tốt có thể trở thành “zero-cost” sau tối ưu, dù mã nguồn trông có vẻ tạo nhiều cấp phát.
Một runtime JIT có thể tối ưu dựa trên dữ liệu thực: đường dẫn nóng, kích thước đối tượng điển hình, mô hình cấp phát. Điều này thường cải thiện thông lượng, nhưng có thể thêm thời gian khởi động và các pause đôi khi để biên dịch lại hay GC.
AOT phải đoán nhiều hơn trước, nhưng đem lại khởi động dự đoán và độ trễ ổn định hơn.
Runtime dùng GC exposes các cài đặt như kích thước heap, mục tiêu thời gian pause và ngưỡng thế hệ. Chỉ điều chỉnh khi bạn có bằng chứng đo được (ví dụ spike độ trễ hoặc áp lực bộ nhớ), không phải là bước đầu tiên.
Hai triển khai của cùng một “thuật toán” có thể khác nhau về số lượng cấp phát ẩn, đối tượng tạm, và truy vấn con trỏ. Những khác biệt đó tương tác với tối ưu hóa, allocator và hành vi cache—vì vậy so sánh hiệu năng cần profiling chứ không phải giả định.
Lựa chọn quản lý bộ nhớ không chỉ thay đổi cách bạn viết code—nó thay đổi khi công việc diễn ra, bao nhiêu bộ nhớ cần dành trước và cảm giác hiệu năng với người dùng.
Thông lượng là “bao nhiêu công việc trên một đơn vị thời gian.” Nghĩ tới job batch đêm xử lý 10 triệu bản ghi: nếu GC hoặc đếm tham chiếu thêm overhead nhỏ nhưng giúp lập trình nhanh, bạn vẫn có thể hoàn thành nhanh nhất.
Độ trễ là “một thao tác mất bao lâu.” Với request web, một phản hồi chậm làm trải nghiệm tệ ngay cả khi thông lượng trung bình cao. Runtime đôi khi tạm dừng để thu hồi bộ nhớ có thể chấp nhận được cho batch nhưng rõ rệt trong ứng dụng tương tác.
Dấu chân bộ nhớ lớn hơn tăng chi phí cloud và có thể làm chương trình chậm. Khi working set không vừa cache CPU, CPU phải chờ dữ liệu từ RAM. Một số chiến lược đánh đổi bộ nhớ thêm để lấy tốc độ (ví dụ giữ đối tượng đã giải phóng trong pool), trong khi khác giảm bộ nhớ nhưng tăng bookkeeping.
Phân mảnh xảy ra khi vùng trống bị chia thành nhiều khoảng nhỏ—như cố gắng đậu một chiếc van trong bãi có nhiều chỗ nhỏ rải rác. Allocator có thể tốn thời gian tìm chỗ và bộ nhớ có thể tăng dù về lý thuyết còn đủ.
Locality cache nghĩa dữ liệu liên quan nằm gần nhau. Cấp phát pool/arena thường cải thiện locality (đối tượng cấp cùng lúc gần nhau), trong khi heap lâu đời với nhiều kích thước có thể trôi vào bố cục ít thân thiện cache.
Nếu bạn cần thời gian phản hồi nhất quán—game, audio, trading, nhúng hoặc bộ điều khiển thời gian thực—“nhanh phần lớn thời gian nhưng thỉnh thoảng chậm” có thể tệ hơn “chậm hơn một chút nhưng ổn định.” Đây là nơi các mô hình dọn dẹp có thể dự đoán và kiểm soát cấp phát quan trọng.
Lỗi bộ nhớ không chỉ là “lỗi lập trình.” Trong nhiều hệ thống thực tế, chúng trở thành vấn đề bảo mật: sập đột ngột (Denial of Service), rò rỉ dữ liệu (đọc bộ nhớ đã giải phóng hoặc chưa khởi tạo), hoặc điều kiện có thể bị kẻ tấn công điều khiển để chạy mã trái phép.
Các chiến lược quản lý bộ nhớ khác nhau có xu hướng thất bại theo cách khác nhau:
Đồng thời thay đổi mô hình đe dọa: bộ nhớ “ổn” trong một luồng có thể nguy hiểm khi luồng khác giải phóng hoặc sửa đổi. Các mô hình bắt buộc quy tắc chia sẻ (hoặc yêu cầu đồng bộ rõ ràng) giảm khả năng race condition dẫn đến trạng thái bị hỏng, rò rỉ dữ liệu và sập không ổn định.
Không mô hình nào loại bỏ mọi rủi ro—lỗi logic (nhầm auth, cấu hình không an toàn, validate sai) vẫn xảy ra. Các nhóm mạnh áp nhiều lớp bảo vệ: sanitizers trong testing, thư viện chuẩn an toàn, review kỹ, fuzzing và giới hạn chặt chẽ mã unsafe/FFI. An toàn bộ nhớ làm giảm lớn bề mặt tấn công, không phải là đảm bảo tuyệt đối.
Vấn đề bộ nhớ dễ sửa khi bạn bắt được gần thời điểm thay đổi gây ra. Chìa khóa là đo trước, rồi thu hẹp vấn đề bằng công cụ phù hợp.
Bắt đầu bằng việc quyết định bạn đang săn tốc độ hay tăng trưởng bộ nhớ.
Với hiệu năng, đo thời gian thực, thời gian CPU, tốc độ cấp phát (bytes/sec) và thời gian GC/allocator. Với bộ nhớ, theo dõi peak RSS, steady-state RSS và số lượng đối tượng theo thời gian. Chạy cùng workload với input nhất quán; biến thể nhỏ có thể che giấu churn cấp phát.
Dấu hiệu phổ biến: một request đơn cấp phát nhiều hơn dự kiến, hoặc bộ nhớ tăng theo traffic dù thông lượng ổn định. Sửa thường gồm tái sử dụng buffer, chuyển sang arena/pool cho đối tượng sống ngắn, và đơn giản hóa đồ thị đối tượng để ít đối tượng sống qua chu kỳ hơn.
Tái tạo với input tối giản, bật kiểm tra runtime nghiêm ngặt nhất (sanitizers/GC verification), rồi chụp:
Xem fix đầu tiên như một thí nghiệm; chạy lại đo để xác nhận thay đổi giảm cấp phát hay ổn định bộ nhớ—mà không dời vấn đề nơi khác. For more on interpreting trade-offs, see /blog/performance-trade-offs-throughput-latency-memory-use.
Chọn ngôn ngữ không chỉ vì cú pháp hay hệ sinh thái—mô hình bộ nhớ định hình tốc độ phát triển hàng ngày, rủi ro vận hành và mức độ dự đoán của hiệu năng dưới tải thực.
Ghép nhu cầu sản phẩm với chiến lược bộ nhớ bằng cách trả lời vài câu thực tế:
Nếu bạn chuyển mô hình, hãy chuẩn bị cho friction: gọi thư viện hiện có (FFI), quy ước bộ nhớ trộn lẫn, tooling và thị trường tuyển dụng. Prototype giúp khám phá chi phí ẩn (pause, tăng bộ nhớ, overhead CPU) sớm.
Một cách thực tế là prototype cùng tính năng trong các môi trường bạn cân nhắc và so sánh tốc độ cấp phát, tail latency, và peak memory dưới tải đại diện. Các đội đôi khi làm kiểu “so sánh táo với táo” trên Koder.ai: bạn có thể nhanh chóng dựng front-end React nhỏ kèm backend Go + PostgreSQL, rồi thử các dạng request và cấu trúc dữ liệu để thấy dịch vụ GC hoạt xử thế nào dưới traffic thực tế (và export source khi sẵn sàng tiếp tục).
Xác định 3–5 ràng buộc hàng đầu, xây prototype mỏng, và đo sử dụng bộ nhớ, tail latency và chế độ lỗi.
| Model | Safety by default | Latency predictability | Developer speed | Typical pitfalls |
|---|---|---|---|---|
| Manual | Low–Medium | High | Medium | leaks, use-after-free |
| GC | High | Medium | High | pauses, heap growth |
| RC | Medium–High | High | Medium | cycles, overhead |
| Ownership | High | High | Medium | learning curve |
Memory management is how a program allocates memory for data (like objects, strings, buffers) and then releases it when it’s no longer needed.
It impacts:
The stack is fast, automatic, and tied to function calls: when a function returns, its stack frame is removed all at once.
The heap is flexible for dynamic or long-lived data, but it needs a strategy for when and who frees it.
A common rule of thumb: stack is great for short-lived, fixed-size locals; heap is used when lifetimes or sizes are less predictable.
A reference/pointer lets code access an object indirectly. The danger is when the object’s memory is released but a reference to it is still used.
That can lead to:
You explicitly allocate and free memory (e.g., malloc/free, new/delete).
It’s useful when you need:
The cost is higher bug risk if ownership and lifetimes aren’t managed carefully.
Manual management can have very predictable latency if the program is designed well, because there’s no background GC cycle that might pause execution.
You can also optimize with:
But it’s easy to accidentally create expensive patterns too (fragmentation, allocator contention, lots of tiny alloc/free calls).
Garbage collection automatically finds objects that are no longer reachable and reclaims their memory.
Most tracing GCs work like this:
This usually improves safety (fewer use-after-free bugs) but adds runtime work and can introduce pauses depending on the collector design.
Reference counting frees an object when its “owner count” drops to zero.
Pros:
Cons:
Ownership/borrowing (notably Rust’s model) uses compile-time rules to prevent many lifetime mistakes.
Core ideas:
This can deliver predictable cleanup without GC pauses, but it often requires restructuring data flow to satisfy the compiler’s lifetime rules.
An arena/region allocates many objects into a “zone,” then frees them all at once by resetting or dropping the arena.
It’s effective when you have a clear lifetime boundary, like:
The key safety rule: don’t let references escape beyond the arena’s lifetime.
Start with real measurements under realistic load:
Then use targeted tools:
Many ecosystems use weak references or a cycle detector to mitigate cycles.
Tune runtime settings (like GC parameters) only after you can point to a measured problem.