"Distributed SQL" nghĩa là gì (không hoa mỹ)
"Distributed SQL" là một cơ sở dữ liệu trông và cảm giác giống cơ sở dữ liệu quan hệ truyền thống—bảng, hàng, join, giao dịch và SQL—nhưng được thiết kế để chạy như một cụm trên nhiều máy (và thường trên nhiều vùng) trong khi vẫn hành xử như một cơ sở dữ liệu logic duy nhất.
Sự kết hợp này quan trọng vì nó cố gắng mang lại ba điều cùng lúc:
- SQL và mô hình quan hệ: schema quen thuộc, ràng buộc và công cụ truy vấn.
- Mở rộng ngang: thêm node để tăng khả năng, thay vì "mua máy chủ mạnh hơn".
- Nhất quán mạnh: đọc và ghi tuân theo quy tắc giao dịch rõ ràng, ngay cả khi dữ liệu phân tán.
Nằm giữa RDBMS cổ điển và NoSQL
Một RDBMS cổ điển (như PostgreSQL hoặc MySQL) thường dễ vận hành nhất khi mọi thứ nằm trên một node chính. Bạn có thể scale đọc bằng replica, nhưng scale ghi và chịu được sự cố vùng thường đòi hỏi kiến trúc bổ sung (sharding, failover thủ công, và logic ứng dụng cẩn trọng).
Nhiều hệ thống NoSQL chọn chiều ngược lại: ưu tiên mở rộng và tính khả dụng cao trước, đôi khi bằng cách nới lỏng đảm bảo nhất quán hoặc cung cấp mô hình truy vấn đơn giản hơn.
Distributed SQL nhắm tới con đường ở giữa: giữ mô hình quan hệ và giao dịch ACID, nhưng phân phối dữ liệu tự động để xử lý tăng trưởng và lỗi.
Vấn đề nó cố giải quyết
Các cơ sở dữ liệu Distributed SQL được xây dựng cho các vấn đề như:
- Ứng dụng toàn cầu với người dùng ở nhiều vùng, nơi cả độ trễ và thời gian hoạt động đều quan trọng.
- Độ sẵn sàng cao mà không cần quy trình failover thủ công phức tạp.
- Tăng trưởng theo thời gian, khi bạn muốn mở rộng năng lực từng bước và giữ một giao diện cơ sở dữ liệu duy nhất.
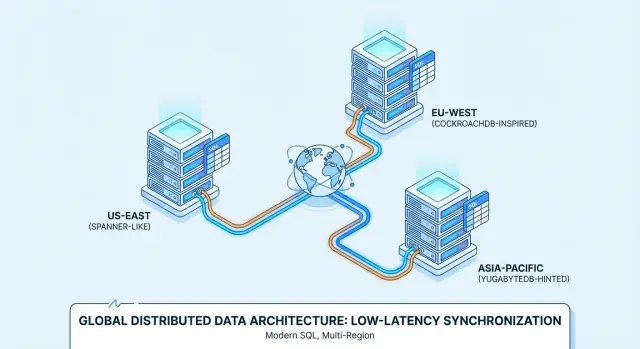
Đó là lý do tại sao các sản phẩm như Google Spanner, CockroachDB và YugabyteDB thường được đánh giá cho triển khai đa vùng và dịch vụ luôn bật.
Thiết lập kỳ vọng (không phải mặc định tốt hơn)
Distributed SQL không tự động "tốt hơn". Bạn đang chấp nhận nhiều thành phần chuyển động và thực tế hiệu năng khác nhau (bước mạng, consensus, độ trễ giữa vùng) để đổi lấy khả năng chịu lỗi và mở rộng.
Nếu workload của bạn vừa vặn trên một cơ sở dữ liệu được quản lý tốt với cấu hình replica đơn giản, RDBMS thông thường có thể đơn giản và rẻ hơn. Distributed SQL chỉ đáng khi phương án thay thế là sharding tùy chỉnh, failover phức tạp, hoặc yêu cầu kinh doanh đòi hỏi nhất quán và thời gian hoạt động đa vùng.
Hoạt động Distributed SQL bên trong như thế nào
Distributed SQL cố gắng cho cảm giác giống cơ sở dữ liệu SQL quen thuộc trong khi lưu trữ dữ liệu trên nhiều máy (và thường nhiều vùng). Khó khăn là phối hợp nhiều máy sao cho chúng hành xử như một hệ thống đáng tin cậy.
Sao chép + consensus: cách các node đồng ý
Mỗi mảnh dữ liệu thường được sao chép trên nhiều node (sao chép). Nếu một node chết, bản sao khác vẫn có thể phục vụ đọc và chấp nhận ghi.
Để ngăn các bản sao sai lệch, hệ thống Distributed SQL dùng các giao thức consensus—thường là Raft (CockroachDB, YugabyteDB) hoặc Paxos (Spanner). Ở mức cao, consensus nghĩa là:
- Một bản sao đóng vai trò "leader" cho một nhóm bản sao.
- Ghi được gửi tới leader.
- Leader chỉ xác nhận ghi sau khi đa số bản sao công nhận.
"Bỏ phiếu đa số" đó chính là thứ đem lại nhất quán mạnh: một khi giao dịch commit, các client khác sẽ không thấy phiên bản cũ của dữ liệu.
Sharding/partitioning: dữ liệu nằm ở đâu
Không có máy nào chứa được mọi thứ, nên bảng được chia thành những khúc nhỏ gọi là shard/partition (Spanner gọi là splits; CockroachDB gọi là ranges; YugabyteDB gọi là tablets).
Mỗi phân vùng được sao chép (bằng consensus) và đặt trên các node cụ thể. Việc đặt không ngẫu nhiên: bạn có thể tác động bằng chính sách (ví dụ giữ bản ghi khách hàng EU trong vùng EU, hoặc để phân vùng nóng trên node nhanh hơn). Đặt tốt giảm các chuyến đi qua mạng và giữ hiệu năng ổn định hơn.
Giao dịch qua các node (và tại sao nó làm tăng latency)
Với cơ sở dữ liệu một node, một giao dịch có thể commit chỉ với công việc đĩa cục bộ. Trong Distributed SQL, giao dịch có thể chạm nhiều phân vùng—có thể trên các node khác nhau.
Commit an toàn thường yêu cầu phối hợp thêm:
- Khóa hoặc xác thực dữ liệu trên các phân vùng liên quan
- Sao chép các ghi qua consensus (đa số xác nhận)
- Hoàn tất quyết định commit để tất cả thành phần đồng ý
Những bước đó tạo ra lượt chuyến mạng, đó là lý do giao dịch phân tán thường tăng độ trễ—đặc biệt khi dữ liệu trải qua các vùng.
Hành vi đa vùng: đọc/ghi theo địa phương
Khi triển khai qua nhiều vùng, hệ thống cố giữ các thao tác "gần" người dùng:
- Đọc theo địa phương có thể phục vụ từ các bản sao gần khi an toàn.
- Ghi theo địa phương có thể chuyển tới leader ở vùng được chọn, hoặc đặt leader gần nơi ghi chính.
Đây là cân bằng lõi cho đa vùng: bạn có thể tối ưu cho phản hồi cục bộ, nhưng nhất quán mạnh trên khoảng cách dài vẫn tốn chi phí mạng.
Khi nào thực sự cần (và khi nào không cần)
Trước khi quay sang distributed SQL, kiểm tra lại nhu cầu cơ bản. Nếu bạn có một vùng chính, tải dự đoán và đội ops nhỏ, cơ sở dữ liệu quan hệ thông thường (hoặc Postgres/MySQL được quản lý) thường là cách đơn giản nhất để phát tính năng nhanh. Bạn có thể kéo dài thiết lập một vùng với replica đọc, caching và tối ưu schema/index.
Dấu hiệu rõ: khi distributed SQL đáng giá
Distributed SQL đáng cân nhắc khi một (hoặc nhiều) điều sau đúng:
- Bạn có người dùng thực ở nhiều vùng và muốn DB gần họ mà không phải shard ứng dụng.
- Yêu cầu uptime cao (ví dụ cần sống sót qua sự cố zone/vùng) và một vùng chính là rủi ro không thể chấp nhận.
- Dung lượng dữ liệu hoặc throughput ghi vượt khả năng scale dọc, và bạn muốn mở rộng ngang trong khi giữ ngữ nghĩa SQL.
- Bạn cần nhất quán mạnh giữa node/vùng cho các giao dịch cốt lõi (đơn hàng, số dư, đặt chỗ) mà không ghép nhiều hệ thống.
- Tuân thủ buộc đặt theo địa lý (data residency) trong khi vẫn cần một cơ sở dữ liệu logic duy nhất.
Những trường hợp không nên
Hệ thống phân tán tăng độ phức tạp và chi phí. Hãy thận trọng nếu:
- Nhóm bạn nhỏ và không có thời gian học các chế độ hỏng mới và pattern vận hành.
- Lưu lượng thấp hoặc không đều và bạn khó vượt giới hạn một cơ sở dữ liệu một vùng trong thời gian tới.
- Bạn có yêu cầu độ trễ cực thấp cho ghi một khoá và không thể chịu overhead phối hợp của nhất quán mạnh.
- Workload thiên về phân tích (scan lớn, báo cáo phức tạp). Có thể tốt hơn khi tách OLTP và analytics.
Checklist quyết định nhanh
Nếu bạn có thể trả “có” cho hai mục trở lên, distributed SQL có thể đáng để đánh giá:
- Bạn cần đa vùng với dữ liệu nhất quán?
- Bạn cần failover tự động giữa zone/vùng?
- Scale có trở thành cuộc khủng hoảng lặp đi lặp lại?
- Sharding sẽ thêm overhead kỹ thuật hơn là chính DB?
- Bạn cần thi hành cư trú dữ liệu với một mô hình vận hành?
Nhất quán, Khả dụng và Độ trễ: Những đánh đổi cốt lõi
Distributed SQL nghe như “có tất cả,” nhưng hệ thống thực tế buộc bạn phải chọn—đặc biệt khi vùng không thể nói chuyện đáng tin cậy.
CAP, giải thích cho quyết định sản phẩm
Hãy nghĩ một phân đoạn mạng là “liên kết giữa vùng bị chập chờn hoặc mất.” Trong khoảnh khắc đó, DB có thể ưu tiên:
- Nhất quán: mọi người thấy cùng một câu trả lời cập nhật (hoặc thao tác thất bại).
- Khả dụng: app tiếp tục chấp nhận đọc/ghi ở mỗi vùng (dù câu trả lời có thể phân kỳ tạm thời).
Hầu hết Distributed SQL xây dựng để ưu tiên nhất quán cho giao dịch. Đó thường là điều các đội muốn—cho tới khi một partition khiến một số thao tác phải chờ hoặc thất bại.
Nhất quán mạnh (và tại sao tiền và tồn kho quan trọng)
Nhất quán mạnh có nghĩa là khi một giao dịch commit, bất kỳ đọc tiếp theo nào cũng trả về giá trị đã commit—không có "đã thực hiện ở vùng này nhưng chưa ở vùng khác." Điều này quan trọng cho:
- Thanh toán và số dư (tránh double-spend hoặc tổng sai)
- Tồn kho / đặt chỗ (ngăn bán vượt số lượng)
Nếu cam kết sản phẩm của bạn là “khi chúng tôi xác nhận, là thực,” thì nhất quán mạnh là tính năng, không phải tùy chọn.
Read-your-writes và isolation trong ứng dụng thực tế
Hai hành vi thiết thực:
- Read-your-writes: sau khi người dùng cập nhật hồ sơ (hoặc đặt hàng), màn hình tiếp theo phải hiện trạng mới, không phải bản sao cũ.
- Transaction isolation: xác định cách hành động đồng thời tương tác. Isolation mạnh hơn giúp tránh lỗi tinh vi như hai khách hàng cùng đặt một ghế thành công.
Chi phí độ trễ của consensus xuyên vùng
Nhất quán mạnh giữa các vùng thường yêu cầu consensus (nhiều bản sao phải đồng ý trước khi commit). Nếu bản sao trải qua châu lục, tốc độ ánh sáng trở thành ràng buộc sản phẩm: mỗi ghi xuyên vùng có thể thêm hàng chục đến hàng trăm mili-giây.
Quy đổi đơn giản: an toàn và đúng đắn địa lý hơn thường có nghĩa là độ trễ ghi cao hơn, trừ khi bạn chọn cẩn thận nơi dữ liệu sống và nơi giao dịch được phép commit.
Spanner vs CockroachDB vs YugabyteDB: Tổng quan thực tế
Google Spanner là một cơ sở dữ liệu Distributed SQL chủ yếu được cung cấp như dịch vụ quản lý trên Google Cloud. Nó được thiết kế cho triển khai đa vùng khi bạn muốn một cơ sở dữ liệu logic duy nhất với dữ liệu sao chép trên node và vùng. Spanner hỗ trợ hai tùy chọn dialect SQL—GoogleSQL (dialect gốc) và một dialect tương thích PostgreSQL—vì vậy khả năng di chuyển khác nhau tùy chọn bạn chọn và tính năng ứng dụng dựa vào.
CockroachDB là một Distributed SQL hướng tới cảm giác quen thuộc với đội phát triển Postgres. Nó dùng PostgreSQL wire protocol và hỗ trợ phần lớn tập con SQL kiểu PostgreSQL, nhưng không phải là thay thế byte-for-byte cho Postgres (một số extension và hành vi cạnh rìa khác nhau). Bạn có thể chạy nó như dịch vụ quản lý (CockroachDB Cloud) hoặc tự host trên hạ tầng của bạn.
YugabyteDB là một cơ sở dữ liệu phân tán với API SQL tương thích PostgreSQL (YSQL) và API tương thích Cassandra (YCQL). Giống CockroachDB, nó được cân nhắc bởi các đội muốn ergonomics phát triển giống Postgres trong khi scale ngang. Có thể triển khai tự host hoặc managed (YugabyteDB Managed).
Managed vs tự host: điều gì thay đổi
Dịch vụ quản lý thường giảm công việc vận hành (nâng cấp, backup, tích hợp monitoring), trong khi tự host cho kiểm soát nhiều hơn về mạng, loại instance và nơi dữ liệu chạy. Spanner thường được dùng như managed trên GCP; CockroachDB và YugabyteDB thường xuất hiện ở cả hai mô hình, kể cả multi-cloud và on-prem.
Tương thích SQL trong thực tế
Cả ba đều “nói SQL,” nhưng tương thích hàng ngày phụ thuộc vào lựa chọn dialect (Spanner), phạm vi tính năng Postgres (CockroachDB/YugabyteDB), và việc app bạn phụ thuộc vào extension, function hay semantics giao dịch cụ thể của Postgres hay không.
Dành thời gian lập kế hoạch: test query, migration và hành vi ORM sớm thay vì giả định tương đương thẳng vào.
Trường hợp sử dụng: SaaS toàn cầu với người dùng theo vùng
Xây PoC Nhanh
Khởi chạy ứng dụng React + Go mẫu và biến PoC Distributed SQL của bạn thành một bề mặt sản phẩm hoạt động.
Một fit kinh điển cho Distributed SQL là sản phẩm SaaS B2B với khách hàng khắp Bắc Mỹ, Châu Âu và APAC—ví dụ công cụ hỗ trợ, nền tảng nhân sự, dashboard analytics hoặc marketplace.
Yêu cầu kinh doanh đơn giản: người dùng muốn trải nghiệm "ứng dụng cục bộ", trong khi công ty muốn một cơ sở dữ liệu logic luôn sẵn sàng.
Cư trú dữ liệu và đặt theo tenant
Nhiều đội SaaS có hỗn hợp yêu cầu:
- Khách hàng EU mong dữ liệu ở EU (GDPR, cam kết hợp đồng).
- Một số khách hàng yêu cầu lưu trong nước (ví dụ Đức, Úc, Singapore).
- Khách khác không quan tâm, nhưng vẫn muốn độ trễ thấp.
Distributed SQL có thể mô hình hóa điều này bằng locality theo tenant: đặt dữ liệu chính của mỗi tenant ở vùng cụ thể (hoặc tập vùng) trong khi giữ schema và mô hình truy vấn nhất quán trên toàn hệ thống. Điều đó giúp bạn tránh việc "một DB cho mỗi vùng" bị tách rời, đồng thời đáp ứng yêu cầu cư trú.
Giảm độ trễ: đọc vùng và đặt viết
Để giữ app nhanh, bạn thường cố gắng:
- Đọc theo vùng: phục vụ truy vấn nhiều đọc từ replica gần người dùng.
- Đặt viết: đặt leader ghi (hoặc primary replica set) ở vùng nơi tenant ghi nhiều nhất.
Điều này quan trọng vì lượt chuyến mạng xuyên vùng chiếm ưu thế lên độ trễ người dùng cảm nhận. Ngay cả với nhất quán mạnh, thiết kế locality tốt đảm bảo phần lớn request không phải trả giá mạng liên lục địa.
Thực tế vận hành
Lợi ích kỹ thuật chỉ có ý nghĩa nếu vận hành còn quản lý được. Với SaaS toàn cầu, hãy lên kế hoạch cho:
- Thay đổi schema online không khóa bảng xuyên vùng.
- Di chuyển tenant (chuyển tenant giữa vùng với downtime tối thiểu).
- Monitoring và alerting cho lag sao chép, hotspot, query chậm, và sự cố vùng.
Làm tốt, Distributed SQL cho bạn trải nghiệm sản phẩm duy nhất mà vẫn cảm giác là cục bộ—không chia đội kỹ sư thành "stack EU" và "stack APAC."
Trường hợp sử dụng: Quy trình tài chính và sổ cái
Hệ thống tài chính là nơi "eventually consistent" có thể dẫn tới mất tiền thật. Nếu khách hàng đặt hàng, một khoản thanh toán được ủy quyền, và số dư được cập nhật, các bước đó phải thống nhất một sự thật—ngay lúc đó.
Nhất quán mạnh quan trọng vì ngăn hai vùng (hoặc hai dịch vụ) đưa ra quyết định "hợp lý" khác nhau dẫn tới sổ cái sai.
Tại sao nhất quán mạnh là bắt buộc
Trong quy trình điển hình—tạo đơn → giữ tiền → capture thanh toán → cập nhật số dư/sổ cái—bạn muốn đảm bảo như:
- Một đơn không thể được gắn là "đã thanh toán" nếu capture thanh toán chưa xảy ra.
- Số dư không thể âm vì hai giao dịch tranh nhau.
- Hoàn tiền không thể áp dụng hai lần vì hai worker retry cùng job.
Distributed SQL phù hợp ở đây vì nó cung cấp giao dịch ACID và ràng buộc trên các node (và thường xuyên là trên vùng), nên invariants sổ cái giữ vững ngay cả khi lỗi.
Idempotency và mẫu "không tính phí hai lần"
Hầu hết tích hợp thanh toán nhiều retry: timeout, webhook retry, reprocess job là bình thường. DB nên giúp biến retry an toàn.
Cách thực tế: kết hợp idempotency key ở tầng ứng dụng với unique do DB thi hành:
- Lưu
idempotency_key cho mỗi khách hàng/lần thử.
- Thêm unique constraint trên
(account_id, idempotency_key).
- Gói "tạo bản ghi thanh toán + áp sổ cái" trong một giao dịch.
Vậy lần thử thứ hai trở thành no-op thay vì trừ phí hai lần.
Xử lý đột biến tải mà không phá vỡ tính đúng đắn
Sự kiện sale và chạy payroll có thể tạo đột biến ghi (authorization, capture, transfer). Với Distributed SQL, bạn có thể scale ngang bằng cách thêm node để tăng throughput ghi trong khi giữ mô hình nhất quán.
Chìa khóa là lên kế hoạch cho hot keys (ví dụ một merchant nhận toàn bộ traffic) và dùng pattern schema phân tán tải.
Tuân thủ, kiểm toán và lưu trữ
Quy trình tài chính thường yêu cầu audit trail bất biến, truy vết (ai/gì/khi nào), và chính sách lưu trữ predictable. Dù không nêu luật cụ thể, giả định bạn cần: entry sổ cái append-only, record có dấu thời gian, kiểm soát truy cập, và chính sách lưu/khôi phục không làm tổn hại auditability.
Trường hợp sử dụng: Tồn kho, Đặt chỗ và Reservation
Giữ Kiểm soát Stack
Giữ quyền kiểm soát stack của bạn để tiếp tục trong repo khi prototype sẵn sàng.
Tồn kho và đặt chỗ trông đơn giản cho đến khi nhiều vùng phục vụ cùng nguồn tài nguyên khan hiếm: ghế cuối cùng, sản phẩm "limited drop", hoặc phòng khách sạn cho đêm cụ thể.
Khó ở chỗ không phải đọc tính khả dụng—mà là ngăn hai người cùng thành công claim cùng một item gần như đồng thời.
Nơi xung đột sinh ra
Trong thiết lập đa vùng không nhất quán mạnh, mỗi vùng có thể tạm tin rằng còn hàng dựa trên dữ liệu hơi cũ. Nếu hai người checkout ở hai vùng khác nhau trong khoảng đó, cả hai giao dịch có thể được chấp nhận cục bộ và sau đó xung đột khi reconcile.
Đó là cách oversell xuyên vùng xảy ra: không phải vì hệ thống "sai", mà vì nó cho phép những sự thật khác nhau tạm thời.
Distributed SQL thường được chọn ở đây vì nó có thể đảm bảo một kết quả quyết định duy nhất cho ghi phân bổ—vậy "ghế cuối" thực sự chỉ được cấp một lần, dù request đến từ hai châu lục.
Ví dụ cụ thể
- Đặt ghế: Hai người cùng click một chỗ trên map. Với nhất quán mạnh, chỉ một giao dịch commit; giao dịch kia thất bại ngay và UI yêu cầu refresh.
- Limited drops: 500 món hàng mở bán và hàng nghìn người thử checkout. Bạn muốn decrement-and-allocate nguyên tử, không phải "nỗ lực tốt nhất" rồi refund sau.
- Đặt phòng khách sạn: Đơn vị tồn kho là room-night. Double-booking một khoảng ngày rất tốn kém và khó hoàn hồi.
Mẫu phổ biến phù hợp với Distributed SQL
Hold + confirm: Đặt hold tạm (bản ghi reservation) trong một giao dịch, sau đó confirm thanh toán ở bước hai.
Expiration: Hold nên tự hết hạn (ví dụ sau 10 phút) để tránh kho bị giữ nếu user bỏ giữa chừng.
Transactional outbox: Khi reservation confirm, ghi một hàng "sự kiện để gửi" trong cùng giao dịch, rồi gửi bất đồng bộ tới email, fulfillment, analytics hoặc message bus—không phải lo mất gap "booked nhưng không gửi xác nhận".
Kết luận: nếu doanh nghiệp bạn không thể chịu double-allocation xuyên vùng, đảm bảo giao dịch mạnh là tính năng sản phẩm, không phải thứ kỹ thuật thêm vào.
Trường hợp sử dụng: Độ sẵn sàng cao và DR
HA phù hợp với Distributed SQL khi downtime tốn kém, sự cố không thể chấp nhận và bạn muốn việc bảo trì thật nhàm chán.
Mục tiêu không phải "không bao giờ hỏng"—mà là đạt được SLO rõ ràng (ví dụ 99.9% hoặc 99.99%) ngay cả khi node chết, zone tối, hoặc khi cập nhật.
"Luôn bật" trong thực tế: SLO, bảo trì, sự cố
Bắt đầu bằng cách biến "luôn bật" thành kỳ vọng đo được: tối đa downtime hàng tháng, RTO và RPO.
Distributed SQL có thể tiếp tục phục vụ đọc/ghi qua nhiều lỗi phổ biến, nhưng chỉ khi topology phù hợp với SLO và app xử lý lỗi tạm thời (retry, idempotency) sạch sẽ.
Bảo trì có kế hoạch cũng quan trọng. Rolling upgrade và thay instance dễ hơn khi DB có thể di chuyển leader/replica khỏi node bị ảnh hưởng mà không làm cả cluster offline.
Khả năng dư thừa multi-zone vs multi-region
Multi-zone bảo vệ bạn khỏi outage AZ/zone đơn lẻ và nhiều lỗi phần cứng, thường với độ trễ và chi phí thấp hơn. Thường đủ nếu tuân thủ và user base chủ yếu trong một vùng.
Multi-region bảo vệ bạn khỏi outage vùng toàn bộ và hỗ trợ failover vùng. Đổi lại là độ trễ ghi cao hơn cho các giao dịch nhất quán mạnh xuyên vùng, cộng với kế hoạch dung lượng phức tạp hơn.
Kỳ vọng failover (và test bằng game days)
Đừng cho rằng failover là tức thì hoặc vô hình. Định nghĩa "failover" nghĩa là gì cho dịch vụ của bạn: tăng lỗi tạm thời? chế độ chỉ đọc? vài giây độ trễ cao hơn?
Chạy "game days" để chứng minh:
- Kill một node, rồi một zone; kiểm tra dashboard SLO và error budget.
- Mô phỏng partition mạng và kiểm tra hành vi leader/replica.
- Thực hành di tản vùng và đo RTO thực tế.
Sao chép không bằng backup
Ngay cả với sao chép đồng bộ, vẫn giữ backup và luyện restore. Backup bảo vệ chống thao tác nhầm (migration sai, xóa nhầm), bug ứng dụng và corruption có thể sao chép.
Xác thực point-in-time recovery (nếu có), tốc độ restore, và khả năng phục hồi vào môi trường sạch mà không chạm sản xuất.
Trường hợp sử dụng: Cư trú dữ liệu và kiến trúc tuân thủ
Yêu cầu cư trú xuất hiện khi quy định, hợp đồng hoặc chính sách nội bộ nói rằng một số bản ghi phải lưu (và đôi khi xử lý) trong một nước hoặc vùng cụ thể.
Điều này áp dụng cho dữ liệu cá nhân, y tế, thanh toán, workload chính phủ, hoặc bộ dữ liệu "thuộc khách hàng" nơi hợp đồng quy định nơi dữ liệu sống.
Distributed SQL thường được cân nhắc vì nó có thể giữ một cơ sở dữ liệu logic duy nhất trong khi vật lý đặt dữ liệu ở vùng khác nhau—không buộc bạn phải chạy một stack ứng dụng hoàn toàn riêng cho mỗi địa lý.
Tại sao quy tắc cư trú thay đổi thiết kế DB
Nếu regulator hoặc khách hàng yêu cầu "dữ liệu ở trong vùng", chỉ có replica gần không đủ. Bạn có thể cần đảm bảo:
- Bản sao chính (hoặc tất cả bản sao) của dữ liệu cụ thể chỉ lưu ở vùng được phê duyệt
- Backup và snapshot tuân thủ cùng quy tắc
- Operator và dịch vụ ngoài vùng không thể truy cập dữ liệu thô
Điều này đẩy đội về kiến trúc nơi vị trí là mối quan tâm cấp một, không phải suy nghĩ sau cùng.
Đặt theo khách hàng và kiểm soát truy cập (tổng quan)
Mô hình phổ biến trong SaaS là đặt theo tenant. Ví dụ: dữ liệu khách EU bị ghim vào vùng EU, khách US vào US.
Bạn thường kết hợp:
- Quy tắc đặt dữ liệu (nơi dữ liệu tenant được phép tồn tại)
- Identity và access control (dịch vụ và con người nào được đọc)
- Mã hóa và quản lý khóa (đôi khi khóa ràng buộc vùng)
Mục tiêu là khó vô tình phạm quy thông qua truy cập vận hành, restore backup hay sao chép xuyên vùng.
Yêu cầu pháp lý khác nhau—hãy tham vấn pháp lý
Yêu cầu cư trú và tuân thủ khác nhau theo quốc gia, ngành và hợp đồng. Chúng cũng thay đổi theo thời gian.
Xem topology DB như một phần chương trình tuân thủ của bạn, và xác nhận giả định với cố vấn pháp lý đủ điều kiện (và nếu cần, với kiểm toán viên).
Multi-region topology ảnh hưởng báo cáo và analytics thế nào
Topology thân thiện cư trú có thể phức tạp hóa "cái nhìn toàn cầu". Nếu dữ liệu khách được giữ riêng theo vùng, analytics có thể:
- Cần pipeline báo cáo vùng (compute chạy nơi dữ liệu nằm)
- Dùng export tổng hợp (chỉ metric được phép ra khỏi vùng)
- Chấp nhận độ trễ cao hơn cho dashboard toàn cầu, vì truy vấn toàn cầu có thể trải vùng hoặc dựa trên dataset sao chép/derive
Trong thực tế, nhiều đội tách workloads vận hành (nhất quán mạnh, tuân thủ) khỏi analytics (warehouse vùng hoặc dataset aggregate có quản trị) để giữ tuân thủ mà không làm chậm báo cáo sản phẩm hàng ngày.
Lập kế hoạch chi phí và hiệu năng cho Distributed SQL
Biến Lý thuyết Thành Số
Biến ý tưởng bài viết thành một app benchmark đo được mà bạn có thể chạy và tối ưu.
Distributed SQL có thể cứu bạn khỏi các outage đau đớn và giới hạn vùng, nhưng hiếm khi tiết kiệm tiền mặc định. Lập kế hoạch trước giúp tránh trả cho "bảo hiểm" bạn không cần.
Các yếu tố chi phí chính
Hầu hết ngân sách chia thành bốn khoản:
- Nodes (compute): Bạn trả cho việc giữ nhiều replica online—thường 3+ mỗi vùng—cộng thêm dung lượng dự phòng cho failover. Thiết kế đa vùng thường cần dự phòng nhiều hơn so với Postgres một vùng.
- Storage: Sao chép nhân lên kích thước dữ liệu. Dataset 2 TB với ba replica là ~6 TB trước backup, index và overhead.
- Traffic giữa vùng: Sao chép xuyên vùng, đọc và traffic client có thể là khoản chi đáng kể. Đây thường là "bất ngờ" đầu tiên khi bạn active-active.
- Thời gian ops: Dù managed, vẫn cần làm: tuning schema/query, phản ứng incident, capacity planning, test upgrade, và quản trị (đặc biệt về cư trú/tuân thủ).
Ước tính ảnh hưởng độ trễ lên hành trình người dùng thực
Distributed SQL thêm việc phối hợp—đặc biệt cho các ghi nhất quán mạnh yêu cầu quorum.
Cách thực tế ước lượng:
- Chọn 2–3 hành trình chính (checkout, booking, "lưu thay đổi").
- Đếm bao nhiêu giao dịch ghi và đọc-sau-ghi xảy ra trong đường dẫn quan trọng.
- Với mỗi bước, giả định một lượt chuyến đa vùng nơi cần phối hợp. Nếu RTT xuyên vùng là 80–120 ms, hai bước ghi tuần tự có thể thêm 160–240 ms.
Điều này không phải là "đừng làm", mà là bạn nên thiết kế hành trình giảm ghi tuần tự (gộp, retry idempotent, ít giao dịch chatty hơn).
Độ phức tạp so với lựa chọn đơn giản hơn
Nếu user chủ yếu ở một vùng, Postgres một vùng với replica đọc, backup tốt và plan failover kiểm tra có thể rẻ và đơn giản hơn—và nhanh.
Distributed SQL xứng đáng khi bạn thực sự cần ghi đa vùng, RPO/RTO chặt, hoặc đặt dữ liệu theo cư trú.
Một khung ROI đơn giản
Xem chi tiêu như một đánh đổi:
- Rủi ro tránh được: ít outage ảnh hưởng doanh thu, ít mất dữ liệu, ít cuối tuần incident toàn cầu.
- Doanh thu bảo vệ: chuyển đổi cao hơn nhờ độ trễ thấp cho người dùng vùng, vị thế enterprise (SLA, tuân thủ).
- Chi phí: cluster baseline + overhead replication + traffic + thời gian engineer.
Nếu tổn thất tránh được (downtime + churn + rủi ro tuân thủ) lớn hơn phí duy trì, thiết kế đa vùng được biện minh. Nếu không, bắt đầu đơn giản—và giữ đường tiến hóa lên sau.
Checklist áp dụng và bước tiếp theo
Áp dụng distributed SQL không chỉ là "lift-and-shift" DB mà là chứng minh workload của bạn hoạt động tốt khi dữ liệu và consensus phân tán (và có thể là đa vùng). Một kế hoạch nhẹ giúp tránh bất ngờ.
PoC tập trung
Chọn một workload đại diện cho đau đầu thực sự: ví dụ checkout/booking, provisioning account, hoặc posting ledger.
Đặt chỉ số thành công trước:
- Đúng: không double-booking, không mất cập nhật, hành vi giao dịch predictible
- SLO độ trễ: p50/p95 cho 3 truy vấn hàng đầu (bao gồm target xuyên vùng nếu cần)
- Throughput: QPS đỉnh + biên an toàn (thường 2–3×)
- Khả năng chịu lỗi: hành vi khi mất node và (nếu liên quan) mất vùng
- Công sức vận hành: thời gian phát hiện, chẩn đoán và phục hồi từ incident mô phỏng
Nếu muốn nhanh ở giai đoạn PoC, có thể xây một app nhỏ "thực tế" (API + UI) thay vì chỉ benchmark tổng hợp. Ví dụ, các đội đôi khi dùng Koder.ai để khởi tạo một app React + Go + PostgreSQL baseline qua chat, rồi đổi lớp DB sang CockroachDB/YugabyteDB (hoặc kết nối đến Spanner) để test patterns giao dịch, retry và hành vi lỗi end-to-end. Ý tưởng không phải starter stack—mà là rút ngắn vòng lặp từ "ý tưởng" tới "workload đo được".
Checklist thiết kế (những thứ gây đau sau này)
- Schema: chọn primary key phân tán ghi; tránh khoá tuần tự "hot"
- Indexes: giữ vừa đủ; hiểu amplification ghi do secondary index
- Partitioning/placement: quyết partition key (và rules geo/zone) theo access pattern
- Hot spots: xác định "celebrity rows" (counters toàn cầu, bảng single-tenant) và thiết kế lại sớm
- Migrations: lên kế hoạch thay đổi schema online và backfill; test rollback
Những cơ bản vận hành ngày 1
Monitoring và runbook quan trọng như SQL:
- Dashboard cho latency, retry, contention, replication/consensus health, disk và compactions
- Runbook incident: query chậm, restart node, replica failing, load lệch
- Load test giống production (mix read/write, burst, long transaction)
- Backup + drill restore (bao gồm point-in-time nếu hỗ trợ)
Bước tiếp theo
Bắt đầu với sprint PoC, rồi dự trù thời gian đánh giá sẵn sàng production và cắtover dần (dual writes hoặc shadow reads khi có thể).
Nếu cần giúp ước tính chi phí hoặc tiers, xem /pricing. Để biết walkthrough thực tế và pattern migration, xem /blog.
Nếu bạn ghi lại kết quả PoC, tradeoffs kiến trúc, hoặc bài học migration, cân nhắc chia sẻ với đội (và công khai nếu có thể): nền tảng như Koder.ai đôi khi có cách để kiếm credits bằng cách tạo nội dung giáo dục hoặc referral, có thể bù đắp chi phí thử nghiệm khi bạn đánh giá lựa chọn.