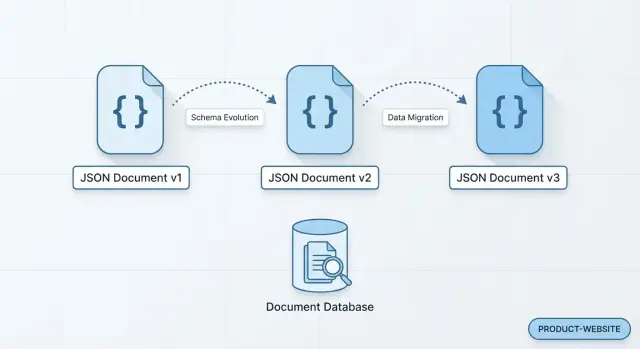
Bài viết này gọi “Cơ sở dữ liệu tài liệu” là gì
Một cơ sở dữ liệu tài liệu lưu trữ dữ liệu dưới dạng các “tài liệu” tự chứa, thường theo định dạng giống JSON. Thay vì phân tán một đối tượng nghiệp vụ qua nhiều bảng, một tài liệu duy nhất có thể chứa mọi thứ về đối tượng đó—các trường, trường con và mảng—giống cách nhiều app đã biểu diễn dữ liệu trong mã nguồn.
Tài liệu và collection (phiên bản dễ hiểu)
- Tài liệu: Một bản ghi bạn có thể đọc và ghi nguyên vẹn (ví dụ: một khách hàng, một đơn hàng, một ticket hỗ trợ).
- Collection: Một nhóm tài liệu tương tự (ví dụ: collection
users hoặc orders).
Các tài liệu trong cùng một collection không cần trông giống nhau hoàn toàn. Một tài liệu user có thể có 12 trường, tài liệu khác 18 trường, và cả hai đều có thể tồn tại cùng nhau.
“Mô hình dữ liệu thay đổi nhanh” trông như thế nào
Hãy tưởng tượng hồ sơ người dùng. Bạn bắt đầu với name và email. Tháng sau, marketing muốn preferred_language. Rồi bộ phận CS yêu cầu timezone và subscription_status. Sau đó bạn thêm social_links (một mảng) và privacy_settings (một object lồng nhau).
Trong cơ sở dữ liệu tài liệu, bạn thường có thể bắt đầu ghi các trường mới ngay. Các tài liệu cũ có thể giữ nguyên cho đến khi bạn quyết định backfill (hoặc không).
Tính linh hoạt—kèm theo đánh đổi
Tính linh hoạt này có thể tăng tốc công việc sản phẩm, nhưng nó chuyển trách nhiệm sang ứng dụng và đội ngũ: bạn sẽ cần các quy ước rõ ràng, luật xác thực tùy chọn và thiết kế truy vấn cẩn trọng để tránh dữ liệu lộn xộn, không nhất quán.
Bạn sẽ học gì trong bài này
Tiếp theo, chúng ta sẽ xem tại sao một vài mô hình thay đổi thường xuyên, cách schema linh hoạt giảm ma sát, cách tài liệu khớp với truy vấn thực tế của app, và những đánh đổi cần cân nhắc trước khi chọn lưu trữ dạng tài liệu thay vì quan hệ—hoặc dùng kết hợp.
Tại sao một số mô hình dữ liệu thay đổi liên tục
Mô hình dữ liệu hiếm khi đứng yên bởi vì sản phẩm hiếm khi đứng yên. Những gì bắt đầu là “chỉ lưu hồ sơ người dùng” nhanh chóng mở rộng thành preferences, notifications, metadata thanh toán, thông tin thiết bị, cờ đồng ý, và hàng tá chi tiết khác không tồn tại ở phiên bản đầu.
Tăng trưởng sản phẩm tạo ra thuộc tính mới
Hầu hết sự thay đổi model đơn giản là kết quả của học hỏi. Các đội thêm trường khi họ:\n
- Giới thiệu tính năng mới (ví dụ: bậc khách hàng, subscriptions, roles)\n- Chạy thử nghiệm cần thuộc tính theo dõi mới\n- Thu thập ngữ cảnh nhiều hơn để cá nhân hóa trải nghiệm
Những thay đổi này thường là từng bước và xảy ra thường xuyên—những bổ sung nhỏ khó lên lịch như các “di cư lớn”.
Các phiên bản của cùng một thực thể phải cùng tồn tại
Cơ sở dữ liệu thực tế chứa lịch sử. Bản ghi cũ giữ hình dạng khi chúng được ghi, trong khi bản ghi mới áp dụng hình dạng mới nhất. Bạn có thể có khách hàng tạo trước khi marketing_opt_in tồn tại, đơn hàng tạo trước khi delivery_instructions được hỗ trợ, hoặc sự kiện ghi trước khi trường source mới được định nghĩa.
Vậy bạn không chỉ “thay đổi một model”—bạn đang hỗ trợ nhiều phiên bản cùng lúc, đôi khi trong nhiều tháng.
Các đội song song và microservices khuếch đại thay đổi
Khi nhiều đội triển khai song song, mô hình dữ liệu trở thành một bề mặt chia sẻ. Đội thanh toán có thể thêm tín hiệu gian lận trong khi đội growth thêm dữ liệu attribution. Trong microservices, mỗi service có thể lưu khái niệm “customer” với nhu cầu khác nhau, và những nhu cầu đó tiến hóa độc lập.
Không có phối hợp, “schema hoàn hảo duy nhất” trở thành nút cổ chai.
Tích hợp và dữ liệu bán cấu trúc, lồng nhau
Hệ thống bên ngoài thường gửi payload một phần biết trước, lồng nhau hoặc không nhất quán: webhook events, metadata đối tác, form submissions, telemetry thiết bị. Ngay cả khi bạn chuẩn hóa các phần quan trọng, bạn vẫn thường muốn giữ cấu trúc gốc để audit, gỡ lỗi hoặc dùng cho mục đích tương lai.
Tất cả lực lượng này đẩy các đội về phía lưu trữ chấp nhận thay đổi một cách duyên dáng—đặc biệt khi tốc độ phát hành quan trọng.
Schema linh hoạt giảm ma sát khi yêu cầu thay đổi
Khi một sản phẩm vẫn đang tìm hình dạng, mô hình dữ liệu hiếm khi “hoàn thiện”. Trường mới xuất hiện, trường cũ trở nên tùy chọn, và các khách hàng khác nhau có thể cần thông tin hơi khác nhau. Cơ sở dữ liệu tài liệu phổ biến trong những thời điểm này vì chúng cho phép bạn phát triển dữ liệu mà không biến mọi thay đổi thành một dự án migration cơ sở dữ liệu.
Thêm trường khi cần (không cần migration bảng)
Với tài liệu JSON, thêm một thuộc tính mới có thể đơn giản như ghi nó trên các bản ghi mới. Các tài liệu hiện có có thể vẫn để nguyên cho đến khi bạn quyết định backfill. Điều đó có nghĩa một thử nghiệm nhỏ—như thu thập một tùy chọn mới—không yêu cầu phối hợp thay đổi schema, cửa sổ deploy và job backfill chỉ để bắt đầu thu thập dữ liệu.
Pha trộn “hình dạng” tài liệu khi hợp lý
Đôi khi bạn thực sự có biến thể: tài khoản “free” có ít cài đặt hơn tài khoản “enterprise”, hoặc một loại sản phẩm cần thuộc tính bổ sung. Trong cơ sở dữ liệu tài liệu, chấp nhận rằng các tài liệu trong cùng collection có hình dạng khác nhau là có thể chấp nhận, miễn là ứng dụng của bạn biết cách diễn giải chúng.
Thay vì ép mọi thứ vào một cấu trúc cứng nhắc, bạn có thể giữ:\n
- các trường chia sẻ nhất quán (như
id, userId, createdAt)\n- các trường biến chỉ có khi liên quan
Giá trị mặc định + logic ứng dụng xử lý trường thiếu
Schema linh hoạt không có nghĩa là “không có quy tắc”. Một mẫu phổ biến là xem các trường thiếu như “dùng giá trị mặc định”. Ứng dụng của bạn có thể áp dụng các giá trị mặc định hợp lý khi đọc (hoặc đặt chúng khi ghi), để các tài liệu cũ vẫn hoạt động đúng.
Thử nghiệm nhanh hơn và feature flag
Feature flag thường giới thiệu các trường tạm thời và rollout từng phần. Schema linh hoạt giúp đưa thay đổi tới một nhóm nhỏ, lưu trạng thái bổ sung chỉ cho người dùng có flag, và lặp nhanh—không phải chờ công việc schema trước khi kiểm tra ý tưởng.
Tài liệu khớp cách nhiều app nghĩ về dữ liệu
Nhiều đội sản phẩm tự nhiên nghĩ theo hướng “một thứ người dùng nhìn thấy trên màn hình”. Một trang hồ sơ, trang chi tiết đơn hàng, dashboard dự án—mỗi cái thường map tới một đối tượng ứng dụng duy nhất với hình dạng dự đoán. Cơ sở dữ liệu tài liệu hỗ trợ mô hình tư duy đó bằng cách cho phép bạn lưu đối tượng đó như một tài liệu JSON duy nhất, ít bước chuyển giữa mã ứng dụng và lưu trữ hơn.
Từ đối tượng app sang JSON với ít chuyển giao
Với bảng quan hệ, cùng một tính năng thường bị chia ra nhiều bảng, khóa ngoại và logic join. Cấu trúc đó mạnh mẽ, nhưng đôi khi cảm thấy là nghi lễ thừa khi app đã giữ dữ liệu như một object lồng nhau.
Trong một cơ sở dữ liệu tài liệu, bạn có thể lưu đối tượng gần như nguyên trạng:\n
- Một tài liệu
user khớp với lớp/kiểu User trong mã của bạn\n- Một tài liệu project khớp với trạng thái Project của bạn
Ít chuyển đổi thường có nghĩa ít bug do mapping và lặp nhanh hơn khi các trường thay đổi.
Dữ liệu lồng nhau ở cạnh nhau
Dữ liệu thực tế hiếm khi phẳng. Địa chỉ, preferences, cài đặt thông báo, bộ lọc lưu, flag UI—tất cả đều lồng nhau một cách tự nhiên.
Lưu các object lồng trong tài liệu cha giữ các giá trị liên quan gần nhau, hữu ích cho truy vấn “một bản ghi = một màn hình”: fetch một tài liệu, render một view. Điều này giảm nhu cầu join và các bất ngờ về hiệu năng kèm theo.
Quyền sở hữu rõ ràng trong các đội
Khi mỗi đội tính năng sở hữu hình dạng tài liệu của mình, trách nhiệm trở nên rõ ràng hơn: đội phát hành tính năng cũng tiến hóa model dữ liệu đó. Điều này thường hoạt động tốt trong microservices hoặc kiến trúc mô-đun, nơi các thay đổi độc lập là bình thường, không phải ngoại lệ.
Mô hình triển khai và lặp sản phẩm nhanh hơn
Cơ sở dữ liệu tài liệu thường phù hợp với các đội phát hành thường xuyên vì các bổ sung dữ liệu nhỏ hiếm khi yêu cầu một thay đổi cơ sở dữ liệu phối hợp “dừng toàn bộ hệ thống”.
Lặp nhanh với ít thay đổi gây chặn
Nếu product manager yêu cầu “thêm một thuộc tính nữa” (ví dụ: preferredLanguage hoặc marketingConsentSource), mô hình tài liệu thường cho phép bạn bắt đầu ghi trường đó ngay. Bạn không luôn phải lên lịch migration, khóa bảng, hoặc thương lượng cửa sổ phát hành giữa nhiều service.
Điều này giảm số tác vụ có thể chặn một sprint: cơ sở dữ liệu vẫn dùng được trong khi ứng dụng tiến hóa.
Triển khai đơn giản hơn khi thêm trường
Thêm các trường tùy chọn vào tài liệu kiểu JSON thường tương thích ngược:\n
- Bản ghi cũ đơn giản là không có trường mới.\n- Bản ghi mới có nó.\n- Người đọc coi “thiếu” như một trường hợp bình thường.
Mẫu này làm cho các triển khai ít căng thẳng hơn: bạn có thể triển khai phía ghi trước (bắt đầu lưu trường mới), sau đó cập nhật phía đọc và UI sau—không cần cập nhật mọi tài liệu ngay lập tức.
Hỗ trợ nhiều phiên bản app tồn tại đồng thời
Hệ thống thực tế hiếm khi nâng cấp tất cả client cùng lúc. Bạn có thể có:\n
- Ứng dụng mobile ở phiên bản cũ trong vài tuần\n- Thử nghiệm A/B và canary\n- Nhiều microservice triển khai độc lập
Với cơ sở dữ liệu tài liệu, các đội thường thiết kế cho “phiên bản hỗn hợp” bằng cách coi các trường là bổ sung và tùy chọn. Writer mới hơn có thể thêm dữ liệu mà không phá vỡ reader cũ.
Thực hành phổ biến: ghi trường mới, đọc với fallback
Một mẫu triển khai thực tế như sau:\n
- Ghi trường mới trong phiên bản app/service mới nhất.\n2. Đọc dùng quy tắc fallback: “Nếu trường thiếu, dùng giá trị cũ hoặc mặc định.”\n3. Tuỳ chọn chạy backfill nền sau nếu cần có trường trên các tài liệu cũ.
Cách này giữ tốc độ cao đồng thời giảm chi phí phối hợp giữa thay đổi cơ sở dữ liệu và phát hành ứng dụng.
Mô hình dữ liệu thân thiện với truy vấn thực tế
Thử cách tiếp cận hybrid
Xây lõi quan hệ với các trường JSONB linh hoạt trong PostgreSQL mà không làm chậm phát hành.
Một lý do các đội thích cơ sở dữ liệu tài liệu là bạn có thể mô hình dữ liệu theo cách ứng dụng thường đọc nó. Thay vì trải một khái niệm qua nhiều bảng rồi ghép lại sau, bạn có thể lưu một đối tượng “toàn bộ” (thường dưới dạng tài liệu JSON) ở một nơi.
Denormalization: giữ dữ liệu liên quan cùng nhau
Denormalization nghĩa là nhân bản hoặc nhúng các trường liên quan để các truy vấn phổ biến có thể trả lời bằng một lần đọc tài liệu.\n
Ví dụ, một tài liệu order có thể bao gồm snapshot thông tin khách (tên, email tại thời điểm mua) và một mảng các line items. Thiết kế này giúp “hiển thị 10 đơn hàng gần nhất” nhanh và đơn giản, vì UI không cần nhiều lookup chỉ để render một trang.
Lợi ích hiệu năng điển hình (và vì sao xảy ra)
Khi dữ liệu cho một màn hình hoặc phản hồi API sống trong một tài liệu, bạn thường có:\n
- Ít round trip mạng giữa app và database hơn\n- Ít join ở máy chủ (hoặc các thao tác kiểu join) để lắp ghép kết quả
Điều này giảm độ trễ cho các đường đọc nặng—đặc biệt trong feeds sản phẩm, hồ sơ, giỏ hàng và dashboard.
Nhúng vs tham chiếu: quy tắc thực tế
Nhúng thường hữu ích khi:\n
- Dữ liệu nhúng thường được đọc cùng với cha\n- Dữ liệu nhúng có kích thước bị giới hạn (ví dụ: “tối đa 20 mục”)\n- Bạn chấp nhận cập nhật nó như một phần của tài liệu cha
Tham chiếu thường tốt hơn khi:\n
- Thực thể liên quan lớn hoặc không giới hạn (ví dụ: “tất cả bình luận từ trước đến nay”)\n- Nhiều cha trỏ tới cùng một child (dữ liệu chia sẻ)\n- Child thay đổi thường xuyên và bạn không muốn cập nhật nhiều tài liệu
Hiệu năng phụ thuộc vào pattern truy cập
Không có một “hình dạng” tài liệu tốt nhất cho mọi thứ. Mô hình tối ưu cho truy vấn này có thể làm truy vấn khác chậm hơn (hoặc tốn kém hơn khi cập nhật). Cách đáng tin cậy nhất là bắt đầu từ truy vấn thực tế của bạn—những gì app cần fetch—và tạo hình tài liệu xung quanh các đường đọc đó, rồi xem lại mô hình khi lưu lượng thay đổi.
Schema-on-read và xác thực tùy chọn
Schema-on-read nghĩa là bạn không phải định nghĩa mọi trường và hình dạng bảng trước khi lưu dữ liệu. Thay vào đó, ứng dụng (hoặc truy vấn phân tích) diễn giải cấu trúc tài liệu khi đọc. Thực tế, điều đó cho phép bạn phát hành một tính năng thêm preferredPronouns hoặc một trường shipping.instructions lồng nhau mà không cần phối hợp migration cơ sở dữ liệu trước.
Schema-on-read trong ngày làm việc
Hầu hết các đội vẫn có “hình dạng mong đợi” trong đầu—chỉ là được thực thi muộn hơn và có chọn lọc. Một tài liệu khách hàng có thể có phone, tài liệu khác thì không. Một đơn hàng cũ có thể lưu discountCode dưới dạng chuỗi, trong khi đơn hàng mới lưu một object discount phong phú hơn.
Ngăn dữ liệu xấu mà không cần migration nặng
Linh hoạt không có nghĩa là hỗn loạn. Các cách tiếp cận phổ biến:\n
- Quy tắc xác thực ở DB (nếu được hỗ trợ): yêu cầu các trường khóa như
id, createdAt, hoặc status, và hạn chế kiểu cho các trường rủi ro cao.\n- Kiểm tra ở tầng ứng dụng: xác thực đầu vào khi ghi (tầng API), từ chối hoặc chuẩn hóa giá trị bất ngờ.\n- Công việc “vệ sinh dữ liệu” nền: quét định kỳ các ngoại lệ và sửa hoặc đánh dấu chúng.
Quản trị nhẹ mà có thể mở rộng
Một chút nhất quán có tác dụng lớn:\n
- Quy ước đặt tên (ví dụ:
camelCase, timestamp ISO-8601)\n- Một tập nhỏ trường bắt buộc xuyên suốt tài liệu\n- Phiên bản tài liệu (ví dụ: schemaVersion: 3) để người đọc xử lý an toàn các hình dạng cũ và mới
Khi nào nên thắt chặt xác thực
Khi mô hình ổn định—thường sau khi bạn biết trường nào thực sự là cốt lõi—hãy giới thiệu xác thực nghiêm ngặt hơn cho những trường đó và các quan hệ quan trọng. Giữ các trường tùy chọn hoặc thử nghiệm linh hoạt, để DB vẫn hỗ trợ lặp nhanh mà không phải migration liên tục.
Xử lý lịch sử thay đổi và sự kiện tiến hóa
Phát hành trường bổ sung an toàn
Tạo API Go đọc trường mới với giá trị mặc định an toàn cho các bản ghi cũ.
Khi sản phẩm thay đổi hàng tuần, không chỉ hình dạng hiện tại của dữ liệu là quan trọng. Bạn còn cần câu chuyện tin cậy về cách nó đến đó. Cơ sở dữ liệu tài liệu phù hợp tự nhiên để lưu lịch sử thay đổi vì chúng lưu các bản ghi tự chứa có thể tiến hóa mà không buộc phải ghi đè mọi thứ trước đó.
Tài liệu sự kiện append-only
Một cách phổ biến là lưu thay đổi như một luồng sự kiện: mỗi sự kiện là một tài liệu mới bạn append (thay vì cập nhật hàng cũ tại chỗ). Ví dụ: UserEmailChanged, PlanUpgraded, hoặc AddressAdded.
Vì mỗi sự kiện là tài liệu JSON riêng, bạn có thể bắt trọn bối cảnh đầy đủ ở thời điểm đó—ai làm, điều gì kích hoạt, và metadata bạn cần sau này.
Thêm trường mới mà không ghi đè lịch sử
Định nghĩa sự kiện hiếm khi ổn định. Bạn có thể thêm source="mobile", experimentVariant, hoặc một object lồng mới như paymentRiskSignals. Với lưu trữ tài liệu, các sự kiện cũ đơn giản là không có những trường đó, và sự kiện mới có thể bao gồm chúng.
Người đọc (các service, job, dashboard) có thể mặc định an toàn cho các trường thiếu, thay vì backfill và migrate hàng triệu bản ghi lịch sử chỉ để thêm một thuộc tính.
Phiên bản hóa cho di cư dần
Để giữ người tiêu thụ ổn định, nhiều đội thêm schemaVersion (hoặc eventVersion) trong mỗi tài liệu. Điều đó cho phép rollout dần:\n
- Producer bắt đầu viết sự kiện version 2\n- Consumer đọc cả v1 và v2 trong một thời gian\n- Bạn migrate hoặc loại bỏ các phiên bản cũ khi thuận tiện
Phân tích và gỡ lỗi tốt hơn theo thời gian
Lịch sử bền vững của “điều gì đã xảy ra” hữu ích hơn audit. Đội analytics có thể xây dựng lại trạng thái tại bất kỳ thời điểm nào, và kỹ sư hỗ trợ có thể truy vết lỗi bằng cách replay sự kiện hoặc kiểm tra payload chính xác gây ra lỗi. Qua nhiều tháng, điều này làm phân tích nguyên nhân gốc nhanh hơn và báo cáo đáng tin cậy hơn.
Những đánh đổi cần biết trước khi chọn cơ sở dữ liệu tài liệu
Cơ sở dữ liệu tài liệu làm cho thay đổi dễ dàng hơn, nhưng chúng không loại bỏ công việc thiết kế—chúng chỉ chuyển đổi công việc đó. Trước khi cam kết, nên rõ ràng về những gì bạn đánh đổi để lấy tính linh hoạt đó.
Giao dịch trên nhiều thực thể có thể phức tạp hơn
Nhiều cơ sở dữ liệu tài liệu hỗ trợ transaction, nhưng transaction đa thực thể (nhiều tài liệu) có thể bị giới hạn, chậm hơn hoặc tốn kém hơn so với DB quan hệ—đặc biệt ở quy mô lớn. Nếu workflow cốt lõi của bạn yêu cầu cập nhật “tất cả hoặc không” trên nhiều bản ghi (ví dụ: cập nhật đơn hàng, tồn kho và sổ cái cùng lúc), hãy kiểm tra cách DB xử lý và chi phí về hiệu năng hoặc độ phức tạp.
Tính linh hoạt có thể tạo hình dạng không đồng nhất
Vì các trường tùy chọn, đội có thể vô tình tạo nhiều “phiên bản” của cùng một khái niệm trong production (ví dụ: address.zip vs address.postalCode). Điều đó có thể phá vỡ tính năng hạ nguồn và khiến bug khó phát hiện.
Giải pháp thực tế là định nghĩa hợp đồng chia sẻ cho các loại tài liệu chính (dù nhẹ) và thêm quy tắc xác thực ở những chỗ quan trọng—như trạng thái thanh toán, giá cả, hoặc quyền truy cập.
Báo cáo ad-hoc có thể khó hơn nếu không chuẩn hoá
Nếu tài liệu thay đổi tự do, truy vấn analytics có thể trở nên lộn xộn: nhà phân tích phải viết logic cho nhiều tên trường và giá trị thiếu. Với các đội phụ thuộc nhiều vào báo cáo, bạn có thể cần kế hoạch như:\n
- chuẩn hóa các trường thân thiện cho báo cáo\n- xuất sang kho dữ liệu\n- duy trì các read model được tuyển chọn cho analytics
Denormalization có thể gây nhân bản và độ phức tạp cập nhật
Nhúng dữ liệu liên quan (như snapshot khách hàng trong đơn hàng) tăng tốc đọc, nhưng nhân bản thông tin. Khi một phần dữ liệu chia sẻ thay đổi, bạn phải quyết định: cập nhật khắp nơi, giữ lịch sử hay chấp nhận nhất thời không nhất quán. Quyết định đó nên có chủ đích—nếu không bạn sẽ gặp drift dữ liệu tinh tế.
Cơ sở dữ liệu tài liệu rất phù hợp khi thay đổi thường xuyên, nhưng chúng thưởng cho những đội coi modeling, đặt tên và xác thực là công việc sản phẩm liên tục—không phải thiết lập một lần.
Các trường hợp sử dụng điển hình mà cơ sở dữ liệu tài liệu tỏa sáng
Cơ sở dữ liệu tài liệu lưu trữ dữ liệu dưới dạng tài liệu JSON, làm cho chúng phù hợp khi các trường là tùy chọn, thay đổi thường xuyên hoặc khác nhau theo khách hàng, thiết bị hoặc dòng sản phẩm. Thay vì ép mọi bản ghi vào một bảng cứng, bạn có thể phát triển mô hình dần dần trong khi giữ nhịp đội.
Catalog thương mại điện tử với thuộc tính luôn thay đổi
Dữ liệu sản phẩm hiếm khi đứng yên: kích thước mới, vật liệu, cờ tuân thủ, gói, mô tả theo vùng và các trường theo marketplace liên tục xuất hiện. Với dữ liệu lồng trong JSON, một “product” có thể giữ các trường cốt lõi (SKU, price) đồng thời cho phép các thuộc tính theo danh mục mà không cần thiết kế lại schema trong nhiều tuần.
Hồ sơ người dùng và preferences với trường tuỳ chọn
Hồ sơ bắt đầu nhỏ rồi mở rộng: cài đặt thông báo, consent marketing, câu trả lời onboarding, feature flag và tín hiệu cá nhân hóa. Trong cơ sở dữ liệu tài liệu, người dùng có thể có các tập trường khác nhau mà không làm hỏng đọc hiện có. Tính linh hoạt này cũng hỗ trợ phát triển linh hoạt, nơi các thử nghiệm có thể thêm và bỏ trường nhanh chóng.
Quản lý nội dung tiến hóa theo thời gian
Nội dung CMS hiện đại không chỉ là “một trang”. Nó là hỗn hợp các block và component—hero, FAQ, carousels sản phẩm, embed—mỗi loại có cấu trúc riêng. Lưu trang dưới dạng tài liệu JSON cho phép editor và dev thêm kiểu component mới mà không phải migrate mọi trang lịch sử ngay lập tức.
IoT và telemetry với payload theo thiết bị
Telemetry thường khác nhau theo phiên bản firmware, gói cảm biến hoặc nhà sản xuất. Cơ sở dữ liệu tài liệu xử lý mô hình dữ liệu tiến hóa tốt: mỗi event có thể chỉ bao gồm những gì thiết bị biết, trong khi schema-on-read cho phép công cụ analytics diễn giải các trường khi có.
Nếu bạn đang quyết định giữa NoSQL vs SQL, đây là những kịch bản nơi cơ sở dữ liệu tài liệu thường giúp lặp nhanh hơn với ít ma sát.
Mẹo mô hình thực tế cho các mô hình thay đổi nhanh
Học và được thưởng
Chia sẻ những gì bạn xây với Koder.ai và nhận credits khi bạn cải thiện nó.
Khi mô hình dữ liệu còn chưa ổn định, “đủ tốt và dễ thay đổi” thắng “hoàn hảo trên giấy”. Những thói quen thực tế này giúp bạn giữ nhịp mà không biến DB thành ngăn kéo rác.
1) Bắt đầu từ pattern truy cập, không phải thực thể
Bắt đầu mỗi tính năng bằng việc ghi lại các truy vấn đọc/ghi hàng đầu bạn mong đợi trong production: các màn hình bạn render, phản hồi API bạn trả về, và các cập nhật bạn thực hiện thường xuyên.
Nếu một hành động người dùng thường cần “order + items + shipping address”, mô hình một tài liệu có thể phục vụ truy vấn đó với ít fetch phụ. Nếu hành động khác cần “tất cả orders theo status”, đảm bảo bạn có thể truy vấn hoặc index cho đường đó.
2) Quyết định nhúng vs tham chiếu sớm
Nhúng (nesting) dữ liệu tốt khi:\n
- dữ liệu con thường được đọc cùng cha\n- tập con bị giới hạn (ví dụ: 1–20 mục)
Tham chiếu an toàn hơn khi:\n
- tập child có thể lớn hoặc không giới hạn\n- child được chia sẻ giữa các cha (ví dụ: một sản phẩm catalog)\n
Bạn có thể kết hợp: nhúng một snapshot cho tốc độ đọc, tham chiếu nguồn chân để cập nhật.
3) Thêm hàng rào tối thiểu: xác thực + phiên bản
Ngay cả với schema linh hoạt, thêm quy tắc nhẹ cho các trường bạn phụ thuộc (kiểu, ID bắt buộc, status cho phép). Bao gồm schemaVersion (hoặc docVersion) để ứng dụng xử lý tài liệu cũ một cách an toàn và migrate theo thời gian.
4) Lên kế hoạch dọn dẹp và migration như thói quen
Xem migration như bảo trì định kỳ, không phải sự kiện một lần. Khi model trưởng thành, lập lịch backfill và dọn dẹp nhỏ (trường không dùng, đổi tên khóa, snapshot denormalized) và đo tác động trước và sau. Một checklist đơn giản và script migration nhẹ giúp nhiều.
Cách quyết định: Tài liệu hay quan hệ (và hybrid)
Chọn giữa cơ sở dữ liệu tài liệu và quan hệ không phải về “cái nào tốt hơn” mà là về loại thay đổi sản phẩm bạn gặp thường xuyên.
Chọn cơ sở dữ liệu tài liệu khi tính linh hoạt và tốc độ quan trọng
Cơ sở dữ liệu tài liệu phù hợp khi hình dạng dữ liệu thay đổi liên tục, các bản ghi khác nhau có thể có trường khác nhau, hoặc các đội cần phát hành tính năng mà không phải phối hợp migration mỗi sprint.
Chúng cũng phù hợp khi ứng dụng của bạn làm việc theo “toàn bộ đối tượng” như một order (thông tin khách + items + ghi chú giao hàng) hoặc một hồ sơ user (settings + preferences + info thiết bị) lưu chung dưới dạng tài liệu JSON.
Chọn cơ sở dữ liệu quan hệ khi cần nhất quán nghiêm ngặt và joins
Cơ sở dữ liệu quan hệ tỏa sáng khi bạn cần:\n
- cấu trúc mạnh mẽ, được thi hành (mỗi bản ghi phải theo cùng quy tắc)\n- báo cáo phức tạp qua nhiều thực thể (nhiều join)\n- giao dịch trải nhiều bảng và cần độ nhất quán tuyệt đối
Nếu công việc của đội bạn phần lớn tối ưu truy vấn chéo bảng và analytics, SQL thường là nơi đơn giản lâu dài hơn.
Xem xét cách tiếp cận hybrid khi thực tế hỗn hợp
Nhiều đội dùng cả hai: quan hệ cho “core system of record” (billing, inventory, entitlements) và store dạng tài liệu cho các view tối ưu đọc hoặc thay đổi nhanh (profiles, metadata content, catalogs). Trong microservices, điều này phù hợp tự nhiên: mỗi service chọn mô hình lưu trữ phù hợp ranh giới của nó.
Cũng đáng nhớ rằng “hybrid” có thể tồn tại bên trong một DB quan hệ. Ví dụ, PostgreSQL có thể lưu trường bán cấu trúc bằng JSON/JSONB bên cạnh các cột typed—hữu ích khi bạn muốn tính nhất quán giao dịch và nơi an toàn cho các thuộc tính tiến hóa.
Nơi Koder.ai phù hợp khi bạn lặp nhanh
Nếu schema thay đổi hàng tuần, nút cổ chai thường là vòng lặp end-to-end: cập nhật model, API, UI, migration (nếu có) và rollout an toàn thay đổi. Koder.ai được thiết kế cho kiểu lặp này. Bạn có thể mô tả tính năng và hình dạng dữ liệu trong chat, sinh một implementation web/backend/mobile hoạt động, rồi tinh chỉnh khi yêu cầu thay đổi.
Thực tế, các đội thường bắt đầu với lõi quan hệ (stack backend của Koder.ai là Go với PostgreSQL) và dùng pattern kiểu tài liệu khi hợp lý (ví dụ: JSONB cho thuộc tính linh hoạt hoặc payload sự kiện). Snapshots và rollback của Koder.ai cũng hữu ích khi một hình dạng dữ liệu thử nghiệm cần revert nhanh.
Bước tiếp theo: quyết định bằng pilot nhỏ
Chạy đánh giá ngắn trước khi cam kết:\n
- Ghi lại 5–10 truy vấn thực tế mà sản phẩm cần (không phải giả thuyết).\n2. Mô hình cùng một tính năng theo cả hai cách.\n3. Đo tốc độ lặp: thay đổi thứ hai khó khăn đến mức nào?\n4. Xác thực yêu cầu vận hành (backup, monitoring, access control).
Nếu bạn so sánh các lựa chọn, giữ phạm vi chặt và giới hạn thời gian—rồi mở rộng khi thấy mô hình nào giúp bạn phát hành ít bất ngờ hơn. Để biết thêm về đánh giá các đánh đổi lưu trữ, xem /blog/document-vs-relational-checklist.