14 thg 11, 2025·8 phút
Craig McLuckie và Cloud-Native: Tư duy nền tảng chiến thắng
Nhìn thực tế về vai trò của Craig McLuckie trong việc thúc đẩy cloud-native và cách tư duy nền tảng biến container thành hạ tầng tin cậy cho production.
Nhìn thực tế về vai trò của Craig McLuckie trong việc thúc đẩy cloud-native và cách tư duy nền tảng biến container thành hạ tầng tin cậy cho production.
Các đội không gặp khó vì không biết khởi động một container. Họ gặp khó vì phải vận hành hàng trăm container một cách an toàn, cập nhật mà không downtime, khôi phục khi hỏng, và vẫn giao tính năng đúng tiến độ.
Câu chuyện “cloud-native” của Craig McLuckie quan trọng vì nó không phải lời tự khen về các demo bóng bẩy. Nó là ghi chép về cách container trở nên có thể vận hành trong môi trường thực—nơi có sự cố, có quy định, và doanh nghiệp cần giao hàng dự đoán được.
“Cloud-native” không chỉ là “chạy trên đám mây.” Đó là cách xây dựng và vận hành phần mềm để có thể triển khai thường xuyên, mở rộng khi nhu cầu thay đổi, và sửa chữa nhanh khi một phần bị lỗi.
Trong thực tế thường bao gồm:
Việc áp dụng container ban đầu thường giống như một hộp công cụ: các đội lấy Docker, ghép vài script lại và hy vọng đội vận hành theo kịp. Tư duy nền tảng lật ngược điều đó. Thay vì mỗi đội tự sáng chế con đường lên production, bạn xây những “con đường lát sẵn”—một nền tảng khiến cách an toàn, tuân thủ và dễ quan sát cũng là cách dễ làm nhất.
Sự chuyển đổi này là cây cầu từ “chúng ta có thể chạy container” sang “chúng ta có thể dựa vào chúng để chạy doanh nghiệp”.
Dành cho người chịu trách nhiệm về kết quả, không chỉ sơ đồ kiến trúc:
Nếu mục tiêu của bạn là giao hàng đáng tin cậy ở quy mô, lịch sử này có bài học thực tế.
Craig McLuckie là một trong những cái tên gắn liền với phong trào cloud-native ban đầu. Bạn sẽ thấy ông được nhắc trong các cuộc thảo luận về Kubernetes, Cloud Native Computing Foundation (CNCF), và ý tưởng rằng hạ tầng nên được xử lý như một sản phẩm—không phải một đống ticket và kiến thức truyền miệng.
Cần rõ ràng: McLuckie không một mình “phát minh cloud-native”, và Kubernetes chưa bao giờ là dự án của một người. Kubernetes được tạo ra bởi một nhóm tại Google, và McLuckie là một phần của nỗ lực ban đầu đó.
Người ta thường ghi nhận ông vì đã giúp biến một khái niệm kỹ thuật thành thứ ngành công nghiệp rộng lớn hơn có thể áp dụng được: xây dựng cộng đồng, đóng gói rõ ràng hơn, và thúc đẩy thực hành vận hành lặp lại.
Qua Kubernetes và thời kỳ CNCF, thông điệp của McLuckie ít về kiến trúc thời thượng và nhiều về làm cho production trở nên dự đoán được. Điều đó có nghĩa:
Nếu bạn đã nghe cụm từ “paved roads”, “golden paths”, hay “platform as a product”, bạn đang vòng quanh cùng một ý tưởng: giảm tải nhận thức cho đội bằng cách làm cho việc đúng đắn trở nên dễ dàng.
Bài này không phải tiểu sử. McLuckie là điểm tham chiếu hữu ích vì công việc của ông nằm ở giao điểm của ba lực đã thay đổi việc giao phần mềm: container, orchestration, và xây dựng hệ sinh thái. Bài học ở đây không về cá tính—mà về lý do tại sao tư duy nền tảng lại là chìa khóa để chạy container trong production thực sự.
Container là ý tưởng hấp dẫn ngay từ khi chưa có nhãn “cloud-native”. Nói đơn giản, container là cách đóng gói ứng dụng cùng các file và thư viện cần thiết để nó chạy giống nhau trên máy khác nhau—như gửi một sản phẩm trong hộp kín với đủ phụ tùng.
Ban đầu, nhiều đội dùng container cho dự án phụ, demo và luồng làm việc của nhà phát triển. Chúng rất tốt để thử dịch vụ mới nhanh, dựng môi trường test và tránh “chạy được trên máy tôi” khi chuyển giao.
Nhưng chuyển từ vài container sang một hệ thống production chạy 24/7 là chuyện khác. Công cụ có đó, nhưng câu chuyện vận hành chưa đầy đủ.
Vấn đề phổ biến hiện lên nhanh:
Container giúp phần mềm di động hơn, nhưng di động không đồng nghĩa với tin cậy. Các đội vẫn cần thực hành triển khai nhất quán, ownership rõ ràng và rào chắn vận hành—để ứng dụng container không chỉ chạy một lần, mà chạy đều đặn mỗi ngày.
Tư duy nền tảng là khi một công ty ngừng xem hạ tầng là dự án một lần và bắt đầu coi nó như sản phẩm nội bộ. “Khách hàng” là nhà phát triển, đội dữ liệu và bất kỳ ai giao phần mềm. Mục tiêu sản phẩm không phải thêm server hay nhiều YAML hơn—mà là con đường mượt mà từ ý tưởng đến production.
Nền tảng thực sự có lời hứa rõ: “Nếu bạn xây và triển khai theo những đường này, bạn sẽ có độ tin cậy, bảo mật và giao hàng dự đoán được.” Lời hứa đó đòi hỏi thói quen sản phẩm—tài liệu, hỗ trợ, versioning và vòng phản hồi. Nó cũng đòi hỏi trải nghiệm người dùng có dụng ý: mặc định hợp lý, paved roads và cửa thoát khi đội thực sự cần khác biệt.
Tiêu chuẩn hóa loại bỏ mệt mỏi khi phải quyết định và ngăn phức tạp vô tình. Khi các đội chia sẻ cùng mẫu triển khai, logging và kiểm soát truy cập, sự cố trở nên lặp lại—vì thế có thể giải quyết. Nhân trực ca tốt hơn vì các sự cố trông quen thuộc. Đánh giá bảo mật nhanh hơn vì nền tảng đã nhúng rào chắn thay vì để từng đội tự làm lại.
Đây không phải ép mọi người vào cùng một khuôn. Mà là đồng ý về 80% nên trở nên nhàm chán, để đội dành năng lượng cho 20% tạo khác biệt cho doanh nghiệp.
Trước khi có tư duy nền tảng, hạ tầng thường dựa vào kiến thức đặc biệt: vài người biết server nào đã vá, cài đặt nào an toàn, script nào là “tốt”. Tư duy nền tảng thay thế bằng các mẫu lặp lại: template, provisioning tự động và môi trường nhất quán từ dev đến production.
Làm tốt, nền tảng tạo quản trị tốt hơn với ít giấy tờ hơn. Chính sách trở thành kiểm tra tự động, phê duyệt thành workflow có audit, và chứng cứ compliance được sinh ra khi đội deploy—vậy tổ chức kiểm soát mà không làm chậm mọi người.
Container làm việc đóng gói và gửi app dễ hơn. Phần khó là chuyện sau khi gửi: chọn nơi chạy, giữ cho nó khỏe, và thích nghi khi lưu lượng hoặc hạ tầng thay đổi.
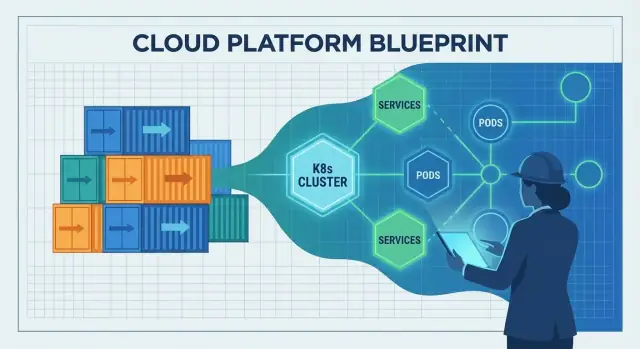
Đó là khoảng trống Kubernetes lấp đầy. Nó biến “một đống container” thành thứ bạn có thể vận hành ngày qua ngày, ngay cả khi node chết, release diễn ra, và lưu lượng tăng đột biến.
Kubernetes thường được mô tả là “orchestrator container”, nhưng vấn đề thực tế cụ thể hơn:
Không có orchestrator, các đội sẽ script những hành vi này và xử lý ngoại lệ thủ công—cho đến khi script không còn khớp thực tế nữa.
Kubernetes phổ biến ý tưởng về một control plane chung: một nơi bạn khai báo bạn muốn gì (“chạy 3 bản sao của dịch vụ này”) và nền tảng liên tục làm cho thế giới thực khớp với mục tiêu đó.
Đây là chuyển đổi lớn về trách nhiệm:
Kubernetes không xuất hiện vì container đang thịnh. Nó lớn lên từ bài học khi vận hành đội lớn: xem hạ tầng như hệ thống có vòng phản hồi, không phải tập hợp các tác vụ server một lần. Tư duy vận hành đó là lý do nó trở thành cây cầu từ “chúng ta có thể chạy container” đến “chúng ta có thể chạy chúng tin cậy trong production.”
Cloud-native không chỉ giới thiệu công cụ mới—nó thay đổi nhịp độ giao phần mềm. Các đội chuyển từ “server thủ công và runbook tay” sang hệ thống vận hành qua API, tự động hóa và cấu hình khai báo.
Một thiết lập cloud-native giả định hạ tầng có thể lập trình. Cần database, load balancer hay môi trường mới? Thay vì chờ thiết lập thủ công, đội mô tả họ muốn gì và để tự động hóa tạo ra.
Sự thay đổi then chốt là cấu hình khai báo: bạn định nghĩa trạng thái mong muốn (“chạy 3 bản sao dịch vụ này, expose cổng này, giới hạn bộ nhớ X”) và nền tảng liên tục làm cho trạng thái thực khớp. Điều này làm cho thay đổi có thể review, lặp lại và dễ rollback hơn.
Giao hàng truyền thống thường vá server trực tiếp. Theo thời gian, mỗi máy khác đi—configuration drift chỉ lộ ra khi có sự cố.
Cloud-native thúc đẩy triển khai bất biến: build artifact một lần (thường là container image), triển khai nó, và nếu cần thay đổi, deploy phiên bản mới thay vì chỉnh trên hệ thống đang chạy. Kết hợp với rollout tự động và health checks, cách này giảm các “outage bí ẩn” do sửa một-off.
Container làm cho việc đóng gói nhiều dịch vụ nhỏ nhất quán dễ hơn, khuyến khích kiến trúc microservice. Microservice lại tăng nhu cầu về triển khai nhất quán, mở rộng và khám phá dịch vụ—những lĩnh vực orchestration tỏa sáng.
Đánh đổi: nhiều dịch vụ hơn nghĩa là overhead vận hành lớn hơn (giám sát, mạng, versioning, phản ứng sự cố). Cloud-native giúp quản lý phức tạp đó nhưng không xóa nó đi.
Tính di động được cải thiện vì các đội tiêu chuẩn hóa trên primitives và API chung. Tuy nhiên, “chạy ở đâu cũng được” vẫn cần công sức—khác biệt về bảo mật, lưu trữ, mạng và dịch vụ quản lý vẫn quan trọng. Cloud-native nên hiểu là giảm khóa và friction, không phải loại bỏ hoàn toàn.
Kubernetes không lan rộng chỉ vì nó mạnh. Nó lan rộng vì nó có một ngôi nhà trung lập, quản trị rõ ràng, và nơi các công ty đối đầu có thể hợp tác mà không có một vendor chi phối.
Cloud Native Computing Foundation (CNCF) tạo ra quản trị chia sẻ: quyết định mở, quy trình dự đoán và roadmap công khai. Điều đó quan trọng với các đội đặt cược vào hạ tầng cốt lõi. Khi quy tắc minh bạch và không gắn với mô hình kinh doanh của một công ty, việc áp dụng ít rủi ro hơn—và đóng góp trở nên hấp dẫn.
Bằng cách lưu trữ Kubernetes và các dự án liên quan, CNCF giúp biến “một công cụ open-source phổ biến” thành nền tảng dài hạn với hỗ trợ thể chế. Nó cung cấp:
Với nhiều contributor (nhà cung cấp đám mây, startup, doanh nghiệp, kỹ sư độc lập), Kubernetes tiến nhanh và theo hướng thực tế hơn: mạng, lưu trữ, bảo mật và vận hành ngày-2. API mở và chuẩn giúp công cụ dễ tích hợp, giảm khóa và tăng tự tin cho sử dụng production.
CNCF cũng thúc đẩy bùng nổ hệ sinh thái: service mesh, ingress controller, CI/CD, policy engine, stack quan sát và hơn thế nữa. Sự phong phú đó là sức mạnh—nhưng cũng tạo chồng chéo.
Với hầu hết đội, thành công đến từ việc chọn một bộ nhỏ thành phần được hỗ trợ tốt, ưu tiên khả năng tương tác và rõ ràng về ownership. Cố gắng “tốt nhất mọi thứ” thường dẫn đến gánh nặng bảo trì hơn là cải thiện giao hàng.
Container và Kubernetes giải quyết phần lớn câu hỏi “làm sao chạy phần mềm?”. Chúng không tự động trả lời câu khó hơn: “làm sao giữ nó chạy khi người dùng thực xuất hiện?”. Lớp thiếu là độ tin cậy vận hành—kỳ vọng rõ ràng, thực hành chia sẻ và hệ thống làm cho hành vi đúng thành mặc định.
Một đội có thể ship nhanh nhưng vẫn chỉ cần một deploy sai là hỗn loạn nếu baseline production không rõ. Tối thiểu bạn cần:
Không có baseline này, mỗi dịch vụ tự đặt quy tắc và độ tin cậy phụ thuộc vào may rủi.
DevOps và SRE giới thiệu thói quen quan trọng: ownership, tự động hóa, đo lường độ tin cậy và học từ sự cố. Nhưng thói quen đơn lẻ không mở rộng tốt qua hàng chục đội và trăm dịch vụ.
Nền tảng làm cho những thực hành đó lặp lại được. SRE đặt mục tiêu (như SLO) và vòng phản hồi; nền tảng cung cấp paved roads để đạt được chúng.
Giao hàng đáng tin cậy thường cần một bộ năng lực nhất quán:
Nền tảng tốt nhúng các mặc định này vào template, pipeline và chính sách runtime: dashboard chuẩn, quy tắc alert chung, rào chắn triển khai và cơ chế rollback. Đó là cách độ tin cậy ngừng là tùy chọn—và bắt đầu là kết quả dự đoán của việc ship phần mềm.
Công cụ cloud-native có thể mạnh nhưng vẫn cảm thấy “quá nhiều” với hầu hết đội sản phẩm. Platform engineering tồn tại để thu hẹp khoảng cách đó. Sứ mệnh đơn giản: giảm tải nhận thức cho đội ứng dụng để họ có thể ship tính năng mà không phải thành chuyên gia hạ tầng bán thời gian.
Đội nền tảng tốt xem hạ tầng nội bộ như sản phẩm. Điều đó có nghĩa người dùng rõ (devs), kết quả rõ (triển khai an toàn, lặp lại được) và vòng phản hồi. Thay vì giao một đống primitives Kubernetes, nền tảng cung cấp cách có quan điểm để xây, deploy và vận hành dịch vụ.
Một thước đo thực tế: “Nhà phát triển có thể đi từ ý tưởng tới dịch vụ chạy được mà không phải mở chục ticket không?” Các công cụ nén quy trình đó—vẫn giữ rào chắn—phù hợp với mục tiêu nền tảng cloud-native.
Phần lớn nền tảng là tập các “paved roads” tái sử dụng mà đội có thể chọn làm mặc định:
Mục tiêu không phải che giấu Kubernetes—mà là đóng gói nó thành mặc định hợp lý để tránh phức tạp vô ý.
Trong tinh thần đó, Koder.ai có thể được dùng như lớp “gia tốc DX” cho đội muốn dựng công cụ nội bộ hoặc tính năng sản phẩm nhanh qua chat, rồi xuất source khi cần tích hợp vào nền tảng chính. Với đội nền tảng, chế độ lập kế hoạch và snapshot/rollback tích hợp có thể phản ánh cùng tư thế ưu tiên độ tin cậy bạn muốn trong luồng làm việc production.
Mỗi con đường lát sẵn là một đánh đổi: nhiều nhất quán và vận hành an toàn hơn, nhưng ít tùy biến hơn. Đội nền tảng làm tốt khi cung cấp:
Bạn thấy thành công nền tảng qua các chỉ số: onboarding kỹ sư mới nhanh hơn, ít script triển khai bespoke, ít cụm “snowflake”, và ownership rõ hơn khi sự cố xảy ra. Nếu đội trả lời được “ai sở hữu dịch vụ này và làm sao chúng ta ship?” mà không cần cuộc họp, nền tảng đang làm tốt việc của nó.
Cloud-native có thể làm giao hàng nhanh hơn và vận hành êm hơn—nhưng chỉ khi các đội rõ ràng về mục tiêu họ muốn cải thiện. Nhiều chậm trễ xảy ra khi Kubernetes và hệ sinh thái được xem như mục tiêu, không phải phương tiện.
Lỗi phổ biến là áp dụng Kubernetes vì đó là “xu hướng hiện đại”, mà không có mục tiêu cụ thể như rút ngắn lead time, giảm sự cố, hay đồng nhất môi trường. Kết quả là nhiều công việc di cư mà không có lợi ích thấy rõ.
Nếu tiêu chí thành công không được xác định trước, mọi quyết định trở nên chủ quan: chọn công cụ nào, tiêu chuẩn hóa đến đâu, và khi nào nền tảng “xong”.
Kubernetes là nền tảng, không phải nền tảng đầy đủ. Các đội thường thêm add-on nhanh—service mesh, ingress controller đa dạng, operator tuỳ chỉnh, policy engine—mà không rõ ranh giới hay ownership.
Tùy biến quá mức là bẫy khác: YAML bespoke, template tự viết và ngoại lệ chỉ người tạo hiểu. Độ phức tạp tăng, onboarding chậm, và nâng cấp trở nên rủi ro.
Cloud-native làm dễ tạo tài nguyên—và dễ quên chúng. Sprawl cluster, namespace không dùng, workload cấp dư làm tăng chi phí lặng lẽ.
Lỗ hổng bảo mật cũng phổ biến:
Bắt đầu nhỏ với một hoặc hai dịch vụ có phạm vi rõ. Xác định tiêu chuẩn sớm (golden paths, base image được phê duyệt, quy tắc nâng cấp) và giữ bề mặt platform có ý.
Đo các kết quả như tần suất triển khai, mean time to recovery và thời gian nhà phát triển tới deploy đầu tiên—và coi bất cứ thứ gì không cải thiện những số đó là tùy chọn.
Bạn không “áp dụng cloud-native” chỉ trong một động tác. Các đội thành công theo cùng ý tưởng thời McLuckie: xây nền tảng làm cho cách đúng là dễ làm.
Bắt đầu nhỏ, rồi ghi nhận những gì hiệu quả.
Nếu thử nghiệm workflow mới, một mẫu hữu ích là prototype trải nghiệm “con đường vàng” end-to-end trước khi chuẩn hóa nó. Ví dụ, đội có thể dùng Koder.ai để nhanh tạo web app (React), backend (Go) và database (PostgreSQL) qua chat, rồi coi code kết quả là điểm khởi đầu cho template và quy ước CI/CD của nền tảng.
Trước khi thêm công cụ, hỏi:
Đo kết quả, không phải việc dùng công cụ:
Nếu bạn muốn ví dụ về gói platform MVP tốt trông thế nào, xem phần blog. Để lập ngân sách và kế hoạch triển khai, bạn cũng có thể tham khảo trang giá.
Bài học lớn từ thập kỷ qua đơn giản: container không “thắng” vì đóng gói hay. Chúng thắng vì tư duy nền tảng làm cho chúng đáng tin cậy—triển khai lặp lại, rollout an toàn, kiểm soát bảo mật nhất quán và vận hành dự đoán.
Chương tiếp theo không phải về một công cụ đột phá duy nhất. Làm cho cloud-native trở nên nhàm chán theo nghĩa tốt: ít bất ngờ, ít sửa một-off, và con đường từ code tới production mượt hơn.
Policy-as-code trở thành mặc định. Thay vì xem xét mọi deployment thủ công, đội mã hóa quy tắc cho bảo mật, mạng và compliance để rào chắn tự động và có audit.
Trải nghiệm nhà phát triển (DX) được coi là sản phẩm. Mong đợi nhiều hơn vào paved roads: template, môi trường tự phục vụ, và golden paths rõ ràng giảm tải nhận thức mà không cản tự chủ.
Vận hành đơn giản hơn, không nhiều dashboard hơn. Nền tảng tốt nhất sẽ ẩn đi độ phức tạp: mặc định có quan điểm, ít thành phần chuyển động, và các mẫu độ tin cậy được nhúng sẵn thay vì gắn vào.
Tiến bộ cloud-native chậm lại khi đội chạy theo tính năng hơn là kết quả. Nếu bạn không giải thích được công cụ mới giảm lead time, hạ tần suất sự cố, hoặc cải thiện posture bảo mật như thế nào, rất có thể nó không phải ưu tiên.
Đánh giá điểm đau hiện tại trong quá trình giao và ánh xạ chúng tới nhu cầu nền tảng:
Xem các câu trả lời như backlog nền tảng của bạn—và đo thành công bằng những kết quả mà đội cảm nhận được mỗi tuần.
Cloud-native là cách tiếp cận để xây dựng và vận hành phần mềm nhằm bạn có thể triển khai thường xuyên, tự động mở rộng khi nhu cầu thay đổi, và khôi phục nhanh khi có lỗi xảy ra.
Trong thực tế thường bao gồm container, tự động hóa, dịch vụ nhỏ hơn, và các cách tiêu chuẩn để quan sát, bảo mật và quản lý những gì đang chạy.
Một container giúp bạn phân phối phần mềm nhất quán, nhưng nó không giải quyết được các vấn đề sản xuất phức tạp như nâng cấp an toàn, khám phá dịch vụ, kiểm soát bảo mật, và quan sát bền vững.
Khoảng cách hiện lên khi bạn chuyển từ vài container sang hàng trăm container chạy 24/7.
“Tư duy nền tảng” là xem hạ tầng nội bộ như một sản phẩm nội bộ với người dùng rõ ràng (devs) và lời hứa rõ ràng (triển khai an toàn, lặp lại được).
Thay vì mỗi đội tự may đường lên production, tổ chức xây những con đường lát sẵn (paved roads / golden paths) với mặc định hợp lý và hỗ trợ.
Kubernetes cung cấp lớp vận hành biến “một đống container” thành hệ thống bạn có thể chạy hàng ngày:
Nó cũng mang đến một control plane chung, nơi bạn khai báo trạng thái mong muốn và hệ thống làm cho hiện thực khớp với khai báo đó.
Cấu hình khai báo nghĩa là bạn mô tả bạn muốn gì (trạng thái mong muốn) thay vì liệt kê từng bước thực hiện.
Lợi ích thực tế gồm:
Triển khai bất biến nghĩa là không sửa máy đang chạy. Bạn xây một artifact một lần (thường là image container) và triển khai đúng artifact đó.
Để thay đổi, bạn ship phiên bản mới thay vì chỉnh trên hệ thống đang chạy. Cách này giúp giảm lệch cấu hình và làm cho sự cố dễ tái tạo và hoàn tác hơn.
CNCF cung cấp một ngôi nhà quản trị trung lập cho Kubernetes và các dự án liên quan, giảm rủi ro khi đặt cược vào hạ tầng cốt lõi.
Nó hỗ trợ:
Production baseline là tập tối thiểu các năng lực và thực hành để làm cho độ tin cậy trở nên dự đoán được, ví dụ:
Không có baseline, mỗi dịch vụ tự đặt quy tắc và độ tin cậy phụ thuộc vào may mắn.
Kỹ thuật nền tảng (platform engineering) tập trung giảm tải nhận thức cho nhà phát triển bằng cách đóng gói các nguyên thủy cloud-native thành mặc định có quan điểm:
Mục tiêu không phải che giấu Kubernetes mà là làm cho con đường an toàn là con đường dễ nhất.
Các cạm bẫy phổ biến:
Cách giảm thiểu: