05 thg 5, 2025·8 phút
Datadog và Chuyển dịch Sang Nền tảng: Telemetry, Tích hợp, Quy trình
Xem cách Datadog trở thành một nền tảng khi telemetry, tích hợp và workflow trở thành sản phẩm — cùng các ý tưởng thực tế bạn có thể áp dụng cho stack của mình.
Tại sao Observability trở thành một Nền tảng
Một công cụ observability giúp bạn trả lời các câu hỏi cụ thể về hệ thống—thường bằng các biểu đồ, log hoặc kết quả truy vấn. Đó là thứ bạn “sử dụng” khi có vấn đề.
Một nền tảng observability thì rộng hơn: nó chuẩn hoá cách thu telemetry, cách các đội khám phá dữ liệu, và cách xử lý sự cố từ đầu đến cuối. Nó trở thành thứ tổ chức bạn “vận hành” mỗi ngày, qua nhiều dịch vụ và đội.
Từ biểu đồ đến kết quả
Hầu hết đội bắt đầu với dashboard: biểu đồ CPU, đồ thị tỷ lệ lỗi, có thể vài truy vấn log. Điều đó hữu ích, nhưng mục tiêu thực sự không phải là biểu đồ đẹp hơn—mà là phát hiện nhanh hơn và khắc phục nhanh hơn.
Chuyển sang tư duy nền tảng xảy ra khi bạn ngừng hỏi “Chúng ta có thể vẽ cái này không?” và bắt đầu hỏi:
- Kỹ sư trực có thể tìm ra nguyên nhân gốc trong vài phút, không phải vài giờ chứ?\n- Chúng ta có thể tự động định tuyến cảnh báo đúng đến đội đúng không?\n- Chúng ta có thể biến các mẫu sự cố lặp lại thành playbook có thể dùng lại không?
Đó là những câu hỏi hướng kết quả, và chúng đòi hỏi hơn việc trực quan hoá. Cần có tiêu chuẩn dữ liệu chung, tích hợp nhất quán và quy trình kết nối telemetry với hành động.
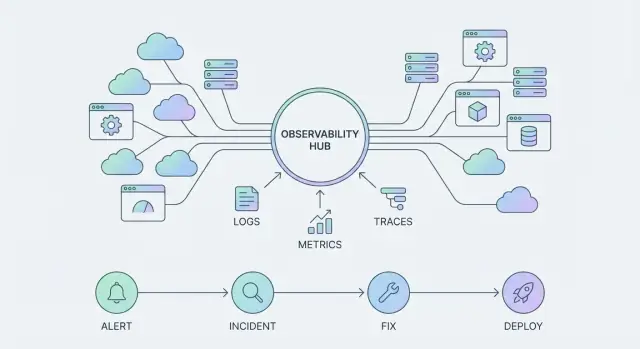
Ba trụ cột bạn thực sự mua
Khi các nền tảng như nền tảng quan sát của Datadog phát triển, “bề mặt sản phẩm” không chỉ là dashboard. Nó gồm ba trụ liên kết:
- Telemetry: logs, metrics và traces được thu thập nhất quán và gán nhãn đủ tin cậy để dùng.
- Integrations: các kết nối có sẵn giúp triển khai dễ và mở rộng phạm vi mà không cần keo tuỳ chỉnh.
- Workflows: phản ứng sự cố, định tuyến cảnh báo, sở hữu và theo dõi—để bài học được nhân lên.
Giá trị nền tảng nhân lên
Một dashboard đơn lẻ giúp một đội. Một nền tảng mạnh lên khi mỗi dịch vụ được onboard, mỗi tích hợp thêm vào và mỗi quy trình được chuẩn hoá. Qua thời gian, điều này nhân thành ít vùng mù hơn, ít công cụ trùng lặp và sự cố ngắn hơn—bởi vì mỗi cải tiến trở nên có thể tái sử dụng, không chỉ một lần.
Telemetry trở thành bề mặt sản phẩm
Khi observability chuyển từ “công cụ để truy vấn” sang “nền tảng để xây dựng”, telemetry không còn là chất thải thô mà bắt đầu là bề mặt sản phẩm. Những gì bạn chọn phát ra—và độ nhất quán khi phát ra—quyết định những gì đội bạn có thể thấy, tự động hoá và tin cậy.
Các loại telemetry cốt lõi (và để làm gì)
Hầu hết đội chuẩn hoá quanh một tập tín hiệu nhỏ:
- Metrics: xu hướng số theo thời gian (độ trễ, tỉ lệ lỗi, độ bão hoà).\n- Logs: bản ghi chi tiết, dễ đọc để điều tra và kiểm toán.\n- Traces: đường đi của yêu cầu qua các dịch vụ để tìm nơi mất thời gian và lỗi xảy ra.\n- Events: bản ghi rời rạc “có thay đổi” (deploy, feature flag, sự cố).\n- Profiles: hành vi CPU/memory để xác định đường dẫn mã tốn kém.
Từng tín hiệu đơn lẻ đều hữu ích. Khi kết hợp, chúng trở thành một giao diện duy nhất với hệ thống—những gì bạn thấy trong dashboard, cảnh báo, dòng thời gian sự cố và postmortem.
Nhất quán thắng số lượng
Một chế độ thất bại phổ biến là thu thập “mọi thứ” nhưng đặt tên không nhất quán. Nếu một dịch vụ dùng userId, dịch vụ khác dùng uid, và dịch vụ thứ ba không log gì, bạn không thể cắt lát dữ liệu đáng tin cậy, nối các tín hiệu hay tạo monitor tái sử dụng.
Các đội nhận được giá trị hơn khi đồng ý vài chuẩn mực—tên dịch vụ, tag môi trường, request ID và một tập thuộc tính tiêu chuẩn—hơn là nhân đôi khối lượng ingest.
High-cardinality thực sự nghĩa là gì (và vì sao nó quan trọng)
High-cardinality là các trường có nhiều giá trị có thể khác nhau (như user_id, order_id, session_id). Chúng mạnh trong việc gỡ lỗi các vấn đề “chỉ xảy ra với một khách hàng”, nhưng cũng có thể làm tăng chi phí và làm truy vấn chậm nếu dùng khắp nơi.
Cách tiếp cận nền tảng là có chủ đích: giữ high-cardinality ở nơi mang lại giá trị điều tra rõ ràng, và tránh ở những nơi dùng cho tổng hợp toàn cục.
Ngữ cảnh thống nhất giảm công việc tương quan
Lợi tức là tốc độ. Khi metrics, logs, traces, events và profiles chia sẻ cùng ngữ cảnh (service, version, region, request ID), kỹ sư mất ít thời gian hơn để ghép bằng chứng và nhiều thời gian hơn để sửa vấn đề thực tế. Thay vì nhảy giữa nhiều công cụ và đoán mò, bạn theo một sợi dây từ triệu chứng tới nguyên nhân gốc.
Từ thu thập dữ liệu đến chiến lược telemetry
Hầu hết đội bắt đầu observability bằng cách “đưa dữ liệu vào”. Điều đó cần thiết, nhưng chưa phải là chiến lược. Một chiến lược telemetry là thứ giữ cho việc onboard nhanh và làm cho dữ liệu đủ nhất quán để hỗ trợ dashboard chung, cảnh báo đáng tin và SLO có ý nghĩa.
Các đường ingest phổ biến (và điểm mạnh của chúng)
Datadog thường nhận telemetry qua vài con đường thực tế:
- Agent trên host/VM: cách nhanh nhất để thu metrics hạ tầng, logs và APM với ít thay đổi mã.\n- Collectors và gateway (ví dụ OpenTelemetry Collector): hữu ích khi bạn muốn kiểm soát trung tâm, định tuyến đến nhiều đích, khử nhạy cảm hoặc xử lý chuẩn.\n- APIs và SDK trực tiếp: phù hợp cho event tùy chỉnh, metric nghiệp vụ, hoặc khi agent không khả thi.\n- Tích hợp serverless: tiện cho runtime được quản lý nơi bạn không kiểm soát host dưới, nhưng bạn cần cân nhắc kỹ những gì phát ra.
Tốc độ vs. chuẩn hoá: quyết định tối ưu cho gì
Ban đầu, tốc độ thắng: đội cài agent, bật vài tích hợp và ngay lập tức thấy giá trị. Rủi ro là mỗi đội tự sáng tạo tag, tên service và định dạng log—làm view xuyên dịch vụ lộn xộn và cảnh báo khó tin cậy.
Một quy tắc đơn giản: cho phép onboarding nhanh, nhưng yêu cầu chuẩn hoá trong 30 ngày. Điều đó cho đội đà tiến mà không khoá vào sự lộn xộn.
Một quy ước đặt tên và gán tag nhẹ nhàng
Bạn không cần một taxonomy khổng lồ. Bắt đầu với một tập nhỏ mà mọi tín hiệu (logs, metrics, traces) phải mang:
service: ngắn, ổn định, chữ thường (ví dụcheckout-api)\n-env:prod,staging,dev\n-team: định danh đội sở hữu (ví dụpayments)\n-version: phiên bản deploy hoặc git SHA
Nếu muốn thêm một trường nhanh thấy lợi, thêm tier (frontend, backend, data) để đơn giản hoá lọc.
Sampling, retention và mặc định tiết kiệm chi phí
Vấn đề chi phí thường đến từ cấu hình mặc định quá hào phóng:
- Traces: bắt đầu với sampling head-based cho endpoint lưu lượng lớn; giữ 100% cho luồng quan trọng.\n- Logs: mặc định là “error + event nghiệp vụ quan trọng”, rồi thêm info/debug có thời hạn khi cần.\n- Retention: giữ dữ liệu độ phân giải cao trong thời gian ngắn hơn (vài ngày), lưu trữ tổng hợp hoặc các chỉ số chính lâu hơn (vài tuần/tháng).
Mục tiêu không phải thu ít hơn—mà là thu đúng dữ liệu nhất quán, để bạn có thể mở rộng sử dụng mà không bị bất ngờ.
Tích hợp như kênh phân phối thực sự
Nhiều người nghĩ observability là “thứ bạn cài”. Thực tế, nó lan rộng trong tổ chức giống cách các connector tốt lan rộng: từng tích hợp một.
Một “tích hợp” thực sự nghĩa là gì
Một tích hợp không chỉ là ống dữ liệu. Nó thường có ba phần:
- Nguồn dữ liệu: kéo metrics, logs, traces, events và topology từ hệ thống bạn đang chạy (dịch vụ đám mây, Kubernetes, DB, CI/CD, SaaS).\n- Enrichment: thêm ngữ cảnh để telemetry sẵn sàng dùng—tên service, môi trường, tag sở hữu, routing đội, phiên bản deploy và metadata đám mây.\n- Hành động: làm điều gì đó với những gì bạn học được—tạo ticket, paging on-call, chú thích deploy, mở rộng tài nguyên, hoặc kích hoạt runbook.
Phần cuối biến tích hợp thành phân phối. Nếu công cụ chỉ đọc, nó là điểm đến dashboard. Nếu nó cũng viết, nó trở thành một phần công việc hàng ngày.
Tại sao tích hợp thúc đẩy áp dụng nhanh
Tích hợp tốt giảm thời gian thiết lập vì chúng đi kèm mặc định hợp lý: dashboard dựng sẵn, monitor khuyên dùng, quy tắc parsing và tag phổ biến. Thay vì mỗi đội tự tạo “CPU dashboard” hay “cảnh báo Postgres”, bạn có một điểm khởi đầu tiêu chuẩn phù hợp best practice.
Các đội vẫn tuỳ chỉnh—nhưng họ tuỳ chỉnh từ cùng một baseline. Sự chuẩn hoá này quan trọng khi hợp nhất công cụ: tích hợp tạo mẫu lặp lại mà dịch vụ mới có thể sao chép, giúp tăng trưởng có thể quản lý.
Ưu tiên tích hợp hai chiều
Khi đánh giá, hỏi: nó có thể nhận tín hiệu và thực hiện hành động không? Ví dụ: mở sự cố trong hệ thống ticket, cập nhật kênh sự cố, hoặc đính kèm link trace vào PR hay view deploy. Thiết lập hai chiều là nơi quy trình bắt đầu cảm thấy “nguyên sinh”.
Phương pháp danh sách rút gọn đơn giản
Bắt đầu nhỏ và dễ dự đoán:
- Hạ tầng quan trọng trước (nhà cung cấp cloud, Kubernetes, load balancer, DB lõi).\n2. Rồi pipeline deploy (CI/CD, feature flags, tracking release) để telemetry khớp với thay đổi.\n3. Thêm SaaS theo đội (queue, cache, auth, thanh toán) khi tagging và quy tắc sở hữu ổn định.
Quy tắc ngón tay cái: ưu tiên tích hợp cải thiện phản ứng sự cố ngay, không chỉ thêm biểu đồ.
View chuẩn: Dịch vụ, Dashboard và Monitor
View chuẩn là nơi một nền tảng observability trở nên hữu dụng hàng ngày. Khi các đội chia sẻ cùng mô hình tư duy—“service” là gì, “khỏe” trông như thế nào, và nên click vào đâu trước—gỡ lỗi nhanh hơn và chuyển giao rõ ràng hơn.
Bắt đầu với golden signals (và làm cho chúng hiển thị)
Chọn một tập nhỏ “golden signals” và gán mỗi tín hiệu vào một dashboard cụ thể, có thể tái sử dụng. Với hầu hết dịch vụ, đó là:
- Latency (p95/p99 cho endpoint chính)\n- Traffic (request per second, job đã xử lý)\n- Errors (tỉ lệ và loại lỗi hàng đầu)\n- Saturation (CPU, memory, độ dài hàng đợi, kết nối DB)
Chìa khoá là nhất quán: một layout dashboard cho nhiều dịch vụ tốt hơn mười dashboard cá nhân tinh tế.
Danh mục dịch vụ tạo quyền sở hữu chung
Một danh mục dịch vụ (ngay cả nhẹ) biến “ai đó nên xem” thành “đội X sở hữu nó”. Khi dịch vụ có tag chủ sở hữu, môi trường và phụ thuộc, nền tảng có thể trả lời ngay: Monitor nào áp dụng cho dịch vụ này? Dashboard nào nên mở? Ai được paging?
Sự rõ ràng đó giảm ping-pong trên Slack trong sự cố và giúp kỹ sư mới tự phục vụ.
Các thành phần xây dựng có thể mở rộng
Xem những thứ này như tài sản chuẩn, không phải tùy chọn:
- Dashboard cho golden signals và phụ thuộc chính\n- Monitors gắn với SLO hoặc triệu chứng ảnh hưởng người dùng\n- Notebooks cho điều tra và dòng thời gian post-incident\n- Runbooks (đính kèm từ monitor) cho 5–10 phút đầu phản ứng
Những mẫu xấu cần tránh
Vanity dashboard (biểu đồ đẹp nhưng không dẫn đến quyết định), cảnh báo one-off (tạo vội vàng, không điều chỉnh), và truy vấn không tài liệu (chỉ một người hiểu bộ lọc kỳ diệu) đều tạo ra ồn nền trên nền tảng. Nếu một truy vấn quan trọng, hãy lưu nó, đặt tên và đính kèm vào view dịch vụ để người khác tìm được.
Workflows: Nơi Observability mang lại giá trị doanh nghiệp
Ra mắt Trung tâm Runbook
Biến các sự cố lặp lại thành thư viện runbook đơn giản mà đội của bạn thực sự sử dụng được.
Observability chỉ trở nên “thực” với doanh nghiệp khi nó rút ngắn khoảng cách giữa vấn đề và sửa chữa tự tin. Điều đó xảy ra qua workflows—con đường lặp lại đưa bạn từ tín hiệu đến hành động, và từ hành động đến bài học.
Hành trình sự cố: alert → triage → communicate → mitigate → learn
Một workflow có thể mở rộng hơn việc paging ai đó.
Một alert nên mở một vòng triage tập trung: xác nhận tác động, xác định dịch vụ bị ảnh hưởng, và kéo ngữ cảnh liên quan nhất (deploy gần nhất, sức khoẻ phụ thuộc, spike lỗi, tín hiệu bão hoà). Từ đó, truyền thông biến sự kiện kỹ thuật thành phản ứng phối hợp—ai đang chịu trách nhiệm, người dùng thấy gì, và khi nào cập nhật tiếp theo.
Mitigation là nơi bạn muốn có “biện pháp an toàn” sẵn sàng: feature flags, chuyển traffic, rollback, giới hạn tỷ lệ, hoặc một giải pháp tạm thời đã biết. Cuối cùng, học hỏi đóng vòng bằng một review nhẹ ghi lại những gì đã thay đổi, gì hiệu quả và điều gì nên được tự động hoá tiếp theo.
Công cụ sự cố + ChatOps = hợp tác, không là người hùng
Các nền tảng như nền tảng quan sát của Datadog tạo giá trị khi hỗ trợ công việc chung: kênh sự cố, cập nhật trạng thái, bàn giao và dòng thời gian nhất quán. Tích hợp ChatOps có thể biến alert thành cuộc hội thoại có cấu trúc—tạo sự cố, phân vai, và đăng biểu đồ/truy vấn chính trực tiếp trong luồng để mọi người nhìn thấy cùng bằng chứng.
Một runbook tốt thực sự chứa gì
Một runbook hữu dụng ngắn gọn, có quan điểm và an toàn. Nó nên gồm: mục tiêu (khôi phục dịch vụ), chủ sở hữu/luân phiên on-call rõ ràng, các bước kiểm tra từng bước, liên kết tới dashboard/monitor đúng, và “hành động an toàn” giảm rủi ro (kèm bước rollback). Nếu không an toàn để chạy lúc 3 giờ sáng thì nó chưa hoàn thiện.
Liên kết sự cố với deploys và thay đổi
Nguyên nhân gốc rõ hơn khi sự cố tự động tương quan với deploy, thay đổi config và bật/tắt feature flag. Hãy đưa “đã thay đổi gì?” thành view hàng đầu để triage bắt đầu với bằng chứng, không phải đoán mò.
SLO và Error Budget như hệ điều hành của đội
SLO là gì (và vì sao vượt trội hơn dashboard “xanh”)
Một SLO (Service Level Objective) là lời hứa đơn giản về trải nghiệm người dùng trong một cửa sổ thời gian—ví dụ “99.9% request thành công trong 30 ngày” hoặc “p95 tải trang dưới 2 giây”.
Nó tốt hơn dashboard “xanh” vì dashboard thường chỉ hiển thị sức khoẻ hệ thống (CPU, memory, độ dài hàng đợi) hơn là tác động tới người dùng. Một dịch vụ có thể trông xanh nhưng vẫn làm người dùng thất vọng (ví dụ một phụ thuộc timeout, hoặc lỗi tập trung ở một vùng). SLO buộc đội đo những gì người dùng thực sự cảm nhận.
Error budget: cách chia sẻ rủi ro
Một error budget là lượng không đáng tin cậy được phép theo SLO của bạn. Nếu bạn hứa 99.9% thành công trong 30 ngày, bạn “được phép” khoảng 43 phút lỗi trong khoảng đó.
Điều này tạo ra một hệ điều hành thực tế cho quyết định:
- Ngân sách khỏe: phát hành tính năng, chạy thử nghiệm, chấp nhận rủi ro hợp lý.\n- Ngân sách đang bị tiêu: chậm phát hành, tập trung sửa độ tin cậy, giảm thay đổi.\n- Ngân sách cạn: tạm dừng deploy rủi ro và xử lý các nguồn lỗi hàng đầu.
Thay vì tranh luận chủ quan trong cuộc họp release, bạn tranh luận một con số mà mọi người đều thấy.
Cảnh báo theo burn rate, không phải mọi spike
Cảnh báo SLO hiệu quả nhất khi bạn cảnh báo theo burn rate (tốc độ tiêu thụ error budget), không phải số lỗi thô. Điều đó giảm ồn:
- Một spike ngắn tự phục hồi có thể không page ai.\n- Một vấn đề kéo dài có thể làm cạn ngân sách và kích hoạt cảnh báo rõ ràng, hành động được.
Nhiều đội dùng hai cửa sổ: fast burn (page nhanh) và slow burn (ticket/thông báo).
Bộ SLO khởi đầu nhẹ cho dịch vụ web điển hình
Bắt đầu nhỏ—hai đến bốn SLO bạn thực sự dùng:
- Availability: % request thành công (HTTP 2xx/3xx) trong 30 ngày.\n- Latency: p95 latency dưới ngưỡng (tách read và write nếu cần).\n- Checkout / endpoint quan trọng: tỉ lệ thành công cho đường dẫn quan trọng nhất của doanh nghiệp.\n- Freshness (nếu có): job nền hoàn thành trong X phút.
Khi những cái này ổn định, bạn có thể mở rộng—nếu không bạn chỉ xây thêm một bức tường dashboard. Để tham khảo thêm, xem /blog/slo-monitoring-basics.
Cảnh báo mở rộng mà không làm kiệt quệ con người
Làm cho postmortem lặp lại được
Tạo mẫu review sau sự cố để ghi lại những gì đã thay đổi và điều gì nên được tự động hoá tiếp theo.
Cảnh báo là nơi nhiều chương trình observability đình trệ: dữ liệu có, dashboard đẹp, nhưng trải nghiệm on-call đầy ồn và không tin cậy. Nếu mọi người học cách bỏ qua cảnh báo, nền tảng mất khả năng bảo vệ doanh nghiệp.
Tại sao mệt mỏi cảnh báo xảy ra (và vì sao tín hiệu bị nhân bản)
Nguyên nhân phổ biến rất giống nhau:
- Quá nhiều cảnh báo “FYI” không cần hành động.\n- Ngưỡng sao chép giữa các dịch vụ mà không có ngữ cảnh (cùng một rule CPU cho workloads khác nhau).\n- Nhiều công cụ hoặc đội cùng cảnh báo cùng triệu chứng—ví dụ monitor APM báo error-rate và monitor log cũng paging cho cùng sự cố.\n- Metrics ồn (percentile latency dao động, autoscaling) kích hoạt biến động thay vì vấn đề thực.
Trong ngôn ngữ Datadog, tín hiệu nhân bản thường xuất hiện khi monitor được tạo từ các “bề mặt” khác nhau (metrics, logs, traces) mà không chỉ định cái nào là nguồn chính để paging.
Định tuyến: sở hữu, mức độ nghiêm trọng và giờ im lặng
Mở rộng cảnh báo bắt đầu với quy tắc định tuyến có ý nghĩa với con người:
- Sở hữu: mỗi monitor cần có chủ sở hữu rõ ràng (service/đội) và đường leo thang.\n- Mức độ nghiêm trọng: chỉ page cho vấn đề cấp cứu, ảnh hưởng người dùng; dùng ticket/chat cho mức thấp hơn.\n- Maintenance windows: deploy có kế hoạch, migration và load test không nên tạo page.
Quy tắc đơn giản giữ cảnh báo có thể hành động
Mặc định hữu dụng: cảnh báo theo triệu chứng, không phải mọi thay đổi metric. Page khi người dùng cảm nhận (tỉ lệ lỗi, checkout thất bại, latency kéo dài, SLO burn), không phải các “đầu vào” (CPU, số pod) trừ khi chúng dự báo đáng tin cậy về tác động.
Chu kỳ review hiệu quả
Làm vệ sinh cảnh báo thành một phần vận hành: prune và tinh chỉnh monitor hàng tháng. Xoá monitor không bao giờ kích hoạt, điều chỉnh ngưỡng quá thường xuyên, và gộp trùng để mỗi sự cố chỉ có một page chính kèm ngữ cảnh hỗ trợ.
Làm tốt, cảnh báo trở thành quy trình mọi người tin tưởng—không phải tiếng ồn nền.
Quản trị: Làm sao nền tảng vẫn hữu dụng khi tăng trưởng
Gọi observability là “nền tảng” không chỉ là có logs, metrics, traces và nhiều tích hợp ở một nơi. Nó còn ngụ ý quản trị: các tiêu chuẩn và rào chắn giúp hệ thống vẫn hữu dụng khi số đội, dịch vụ, dashboard và cảnh báo tăng lên.
Không có quản trị, Datadog (hoặc bất kỳ nền tảng nào) có thể trôi vào một scrapbook ồn ào—hàng trăm dashboard hơi khác nhau, tag không nhất quán, quyền sở hữu mơ hồ và cảnh báo không ai tin tưởng.
Quản trị là vấn đề con người và quy trình
Quản trị tốt làm rõ ai quyết định gì, và ai chịu trách nhiệm khi nền tảng lộn xộn:
- Đội nền tảng: định nghĩa chuẩn (tagging, đặt tên, mẫu dashboard), cung cấp thành phần chia sẻ và duy trì tích hợp.\n- Chủ sở hữu dịch vụ: chịu trách nhiệm chất lượng telemetry cho dịch vụ và giữ monitor có ý nghĩa.\n- Bảo mật & tuân thủ: đặt quy tắc xử lý dữ liệu (PII, retention, ranh giới truy cập) và rà soát tích hợp rủi ro cao.\n- Lãnh đạo: căn chỉnh quản trị với ưu tiên doanh nghiệp (mục tiêu độ tin cậy, kỳ vọng phản ứng sự cố) và cấp ngân sách.
Kiểm soát thực tiễn ngăn “bành trướng observability”
Một vài kiểm soát nhẹ nhàng hiệu quả hơn tài liệu dài:
- Mẫu mặc định: dashboard và gói monitor khởi tạo theo kiểu service (API, worker, DB) để đội bắt đầu nhất quán.\n- Chính sách tagging: một tập bắt buộc nhỏ (ví dụ
service,env,team,tier) và quy tắc rõ ràng cho tag tuỳ chọn. Thực thi trong CI khi có thể.\n- Quyền truy cập và sở hữu: dùng role-based access cho dữ liệu nhạy cảm và yêu cầu owner cho dashboard/monitor.\n- Luồng phê duyệt cho thay đổi tác động cao: monitor page người, pipeline log ảnh hưởng chi phí, tích hợp kéo dữ liệu nhạy cảm nên có bước review.
Tái sử dụng đánh bại phát minh lại
Cách nhanh nhất để mở rộng chất lượng là chia sẻ thứ đang chạy:
- Thư viện chia sẻ: package nội bộ hoặc snippet chuẩn hoá trường log, attribute trace và metric phổ biến.\n- Dashboard và monitor tái sử dụng: catalog trung tâm các dashboard “vàng” và mẫu monitor để đội clone và điều chỉnh.\n- Chuẩn phiên bản: đối xử với tài sản chính như code—ghi chép thay đổi, deprecate pattern cũ và thông báo cập nhật ở một nơi.
Nếu muốn điều này bền, hãy làm con đường được quản trị thành con đường dễ dàng—ít click hơn, thiết lập nhanh hơn và quyền sở hữu rõ ràng.
Chi phí, giá trị và bánh đà nền tảng
Một khi observability hành xử như nền tảng, nó theo kinh tế nền tảng: càng nhiều đội áp dụng, càng nhiều telemetry được tạo, và càng hữu ích hơn.
Điều này tạo bánh đà:
- Nhiều dịch vụ onboard → tầm nhìn xuyên dịch vụ và tương quan tốt hơn\n- Tầm nhìn tốt hơn → chuẩn đoán nhanh hơn, ít sự cố lặp lại, tăng tin cậy vào công cụ\n- Tin cậy hơn → nhiều đội instrument và tích hợp → nhiều dữ liệu hơn
Điểm cần chú ý là vòng lặp cũng làm tăng chi phí. Nhiều host, container, logs, traces, synthetics và metric tuỳ chỉnh có thể tăng nhanh hơn ngân sách nếu bạn không quản lý có chủ đích.
Công cụ điều chỉnh chi phí thực tế (không làm mất tín hiệu)
Bạn không cần “tắt mọi thứ.” Bắt đầu bằng cách định hình dữ liệu:
- Sampling: giữ traces độ trung thực cao cho endpoint quan trọng, sample mạnh hơn ở nơi khác.\n- Retention tiers: giữ raw logs thời gian ngắn; lưu các luồng security/audit đã chọn lâu hơn.\n- Lọc và parsing log: loại bỏ tiếng ồn sớm (health check, request tài nguyên tĩnh) và chuẩn hoá parsing để bạn có thể định tuyến theo thuộc tính.\n- Tổng hợp metric: ưu tiên percentiles, rates và rollup hơn cardinality không giới hạn (ví dụ per-user IDs).
KPI kết nối chi phí với kết quả
Theo dõi một tập nhỏ chỉ số cho thấy nền tảng có đang thu hồi vốn:
- MTTD (thời gian trung bình để phát hiện)\n- MTTR (thời gian trung bình để khắc phục)\n- Số sự cố và sự cố lặp lại (cùng nguyên nhân gốc)\n- Tần suất deploy (và tỉ lệ thất bại thay đổi nếu bạn theo dõi)
Chạy review “giá trị vs chi phí” hàng quý (không truy cứu lỗi)
Làm nó như review sản phẩm, không phải kiểm toán. Mời chủ sở hữu nền tảng, vài đội dịch vụ và tài chính. Xem xét:
- Các trình điều khiển chi phí hàng đầu theo loại dữ liệu (logs/metrics/traces) và theo đội\n- Các thắng lợi chính: sự cố rút ngắn, outage tránh được, toil loại bỏ\n- 2–3 hành động đồng thuận (ví dụ điều chỉnh sampling, thêm retention tiering, sửa tích hợp ồn)
Mục tiêu là quyền sở hữu chung: chi phí trở thành đầu vào cho quyết định instrument tốt hơn, không phải lý do để dừng quan sát.
Điều này có ý nghĩa gì cho stack công cụ observability của bạn
Đặt SLO lên hàng đầu
Nguyên mẫu dashboard SLO hiển thị burn rate và giữ cảnh báo liên quan đến ảnh hưởng người dùng.
Nếu observability biến thành nền tảng, “stack công cụ” của bạn ngừng là một tập hợp giải pháp điểm và bắt đầu hành xử như hạ tầng chia sẻ. Sự chuyển đổi này làm bành trướng công cụ không chỉ là phiền toái: nó tạo ra instrumentation trùng lặp, định nghĩa không nhất quán (cái nào là lỗi?) và tải on-call cao hơn vì tín hiệu không đồng bộ giữa logs, metrics, traces và incident.
Tổng hợp không có nghĩa là “một nhà cung cấp cho mọi thứ” mặc định. Nó có nghĩa là ít hệ thống lưu trữ telemetry hơn, quyền sở hữu rõ ràng và ít nơi người ta phải nhìn vào khi outage.
Những gì hợp nhất có thể giải quyết
Bành trướng công cụ thường che giấu chi phí ở ba nơi: thời gian chuyển giữa UI, tích hợp giòn bạn phải duy trì, và quản trị phân mảnh (tên, tag, retention, quyền truy cập).
Một cách tiếp cận nền tảng có thể giảm chuyển ngữ cảnh, chuẩn hoá view dịch vụ và làm cho quy trình sự cố lặp lại được.
Checklist quyết định (nhanh nhưng thực tế)
Khi đánh giá stack (bao gồm Datadog hoặc lựa chọn khác), thử thách các điểm sau:
- Tích hợp bắt buộc: cloud provider, Kubernetes, CI/CD, quản lý incident, paging, và kho dữ liệu then chốt—cùng bất kỳ hệ thống doanh nghiệp “không thể triển khai nếu thiếu”.\n- Quy trình: bạn có thể đi từ alert → owner → runbook → timeline → postmortem mà không copy/paste thủ công không?\n- Quản trị: tiêu chuẩn tagging, kiểm soát truy cập, retention và rào chắn cho bành trướng dashboard/monitor.\n- Mô hình giá: gì là yếu tố chính tạo chi phí (host, container, logs ingest, trace index)? Bạn có dự báo tăng trưởng mà không bị bất ngờ không?
Chạy pilot với chỉ số thành công rõ ràng
Chọn một hoặc hai dịch vụ có lưu lượng thực. Đặt một chỉ số thành công như “thời gian xác định nguyên nhân gốc giảm từ 30 phút xuống 10” hoặc “giảm cảnh báo ồn 40%”. Instrument chỉ những gì cần, và review sau hai tuần.
Giữ tài liệu nội bộ tập trung để bài học nhân lên—liên kết pilot runbook, quy tắc tagging và dashboard ở một nơi (ví dụ, /blog/observability-basics làm điểm bắt đầu nội bộ).
Kế hoạch áp dụng thực tế bạn có thể sao chép
Bạn không “triển khai Datadog” một lần. Bạn bắt đầu nhỏ, đặt tiêu chuẩn sớm, rồi mở rộng những gì hiệu quả.
Triển khai 30/60/90 ngày
Ngày 0–30: Onboard (chứng minh giá trị nhanh)
Chọn 1–2 dịch vụ quan trọng và một hành trình khách hàng hướng ngoại. Instrument logs, metrics và traces nhất quán, và kết nối tích hợp bạn đang dùng (cloud, Kubernetes, CI/CD, on-call).
Ngày 31–60: Chuẩn hoá (biến thành lặp lại được)
Biến những gì học được thành mặc định: tên service, tagging, mẫu dashboard, đặt tên monitor và quyền sở hữu. Tạo view “golden signals” (latency, traffic, errors, saturation) và tập SLO tối thiểu cho các endpoint quan trọng nhất.
Ngày 61–90: Mở rộng (tăng mà không hỗn loạn)
Onboard thêm đội dùng cùng mẫu. Giới thiệu quản trị (quy tắc tag, metadata bắt buộc, quy trình review monitor mới) và bắt đầu theo dõi chi phí so với sử dụng để nền tảng khỏe mạnh.
Koder.ai phù hợp ở đâu (một cách thực tế)
Khi bạn coi observability như nền tảng, thường sẽ cần các app “keo” nhỏ xung quanh nó: UI danh mục dịch vụ, hub runbook, trang dòng thời gian sự cố, hoặc portal nội bộ liên kết owner → dashboard → SLO → playbook.
Đây là loại công cụ nội bộ nhẹ bạn có thể xây nhanh trên Koder.ai—một nền tảng vibe-coding cho phép sinh web app qua chat (thường React frontend, Go + PostgreSQL backend), kèm xuất mã nguồn và hỗ trợ triển khai/hosting. Thực tế, các đội dùng nó để prototype và ra mắt các bề mặt vận hành giúp quản trị và workflow dễ hơn mà không kéo đội sản phẩm chính khỏi roadmap.
Chiến thắng nhanh để giao trong tuần đầu
- 10 monitor hàng đầu cho availability, tỉ lệ lỗi, latency, saturation và phụ thuộc chính\n- Markers deploy (từ CI/CD) trên dashboard và traces để ngay lập tức tương quan thay đổi\n- Mẫu sự cố: điều gì xảy ra, tác động, dòng thời gian, chủ sở hữu, liên kết dashboard/truy vấn, hành động tiếp theo
Đào tạo thực sự hiệu quả
Chạy hai buổi 45 phút: (1) “Cách chúng ta truy vấn ở đây” với mẫu truy vấn chung (theo service, env, region, version), và (2) “Playbook khắc phục” với luồng đơn giản: xác nhận tác động → kiểm tra marker deploy → thu hẹp service → xem traces → xác nhận sức khoẻ phụ thuộc → quyết định rollback/mitigation.
Checklist copy/paste
- Quy tắc đặt tên service + tagging được ghi chép\n- [ ] Mẫu dashboard + monitor được xuất bản\n- [ ] Top 10 monitor đã bật và có owner\n- [ ] 1–3 SLO định nghĩa cho các đường dẫn quan trọng\n- [ ] Mẫu sự cố và workflow đồng thuận\n- [ ] Hai buổi đào tạo đã thực hiện + ghi âm chia sẻ\n- [ ] Đặt lịch review quản trị hàng tháng (tags, monitors, chi phí)
Câu hỏi thường gặp
What’s the difference between an observability tool and an observability platform?
An observability tool là thứ bạn tham khảo khi có vấn đề (dashboard, tìm kiếm log, một truy vấn). An observability platform là thứ bạn vận hành liên tục: nó chuẩn hoá telemetry, tích hợp, quyền truy cập, quyền sở hữu, cảnh báo và quy trình sự cố giữa các đội để cải thiện kết quả (phát hiện và khắc phục nhanh hơn).
Why do teams outgrow “just dashboards”?
Bởi vì lợi ích lớn nhất đến từ kết quả, chứ không phải hình ảnh:
- tìm nguyên nhân gốc nhanh hơn
- chuyển cảnh báo chính xác đến chủ sở hữu đúng
- biến sự cố lặp lại thành playbook có thể lặp lại
Biểu đồ giúp, nhưng bạn cần tiêu chuẩn và quy trình chung để liên tục giảm MTTD/MTTR.
What telemetry tags should we standardize first?
Bắt đầu bằng một nền tảng bắt buộc mà mọi tín hiệu phải mang theo:
serviceenv(prod,staging, )
What does high-cardinality mean, and when should we use it?
Các trường high-cardinality (như user_id, order_id, session_id) rất tốt để gỡ lỗi khi “chỉ một khách hàng bị ảnh hưởng”, nhưng chúng có thể làm tăng chi phí và làm chậm truy vấn nếu dùng khắp nơi.
Sử dụng một cách có chủ ý:
- giữ chúng trong logs/traces nơi bạn điều tra từng yêu cầu
- tránh dùng trong các metric tổng hợp toàn cục
Which telemetry types matter most in a Datadog-style platform approach?
Hầu hết đội chuẩn hoá trên:
- metrics cho xu hướng (độ trễ, tỉ lệ lỗi, độ bão hoà)
- logs để điều tra chi tiết và audit
- traces để thấy đường đi của yêu cầu qua các dịch vụ
- events cho “cái gì đó thay đổi” (deploys, feature flags)
What are the common ingestion paths, and how do we choose between them?
Một mặc định thực tế là:
- agents trên host/VM để thu thập nhanh metrics + logs + APM
- OpenTelemetry Collector (hoặc gateway) khi bạn cần kiểm soát tập trung, khử nhạy cảm, hoặc định tuyến đến nhiều đích
- SDKs/APIs cho sự kiện/metric nghiệp vụ tuỳ chỉnh
- tích hợp serverless cho runtime được quản lý, kèm quy tắc sampling/volume rõ ràng
Chọn con đường phù hợp với nhu cầu kiểm soát của bạn, rồi áp dụng cùng quy tắc đặt tên/tag trên tất cả.
How do we balance fast onboarding with long-term standardization?
Làm cả hai:
- cho phép quick start để đội thấy giá trị nhanh
- yêu cầu chuẩn hoá trong vòng 30 ngày (tên service, tags, định dạng log, dashboard/monitor cơ bản)
Cách này ngăn mỗi đội tự phát triển schema riêng đồng thời giữ đà áp dụng.
Why do integrations act like a distribution channel for observability?
Bởi vì tích hợp không chỉ là đường ống dữ liệu — chúng bao gồm:
- enrichment (tag chủ sở hữu, metadata đám mây, phiên bản)
- mặc định (dashboard, monitor, rule parsing)
- hành động (ticket, paging, tạo sự cố, chú thích)
Ưu tiên tích hợp hai chiều: vừa nhận tín hiệu vừa kích hoạt hành động, để observability trở thành một phần công việc hàng ngày chứ không chỉ một UI để xem.
What should “standard views” include so engineers can debug quickly?
Gắn vào sự nhất quán và tái sử dụng:
- một layout “golden signals” cho mỗi loại service (độ trễ, lưu lượng, lỗi, bão hoà)
- danh mục dịch vụ với quyền sở hữu rõ ràng
- monitor liên kết tới ảnh hưởng người dùng hoặc SLO, với runbook kèm theo
Tránh vanity dashboard và cảnh báo one-off. Nếu một truy vấn quan trọng, hãy lưu nó, đặt tên và đính kèm vào view dịch vụ để người khác dễ tìm.
How do SLOs and burn-rate alerting reduce noise compared to traditional alerts?
Cảnh báo theo burn rate (tốc độ tiêu thụ error budget), không phải mỗi spike thoáng qua. Mẫu phổ biến:
- fast burn: page nhanh cho sự cố nghiêm trọng, kéo dài
- slow burn: thông báo hoặc tạo ticket cho suy giảm độ tin cậy
Giữ bộ SLO khởi đầu nhỏ (2–4 SLO cho mỗi service) và chỉ mở rộng khi đội thực sự dùng chúng. Để tham khảo cơ bản, xem /blog/slo-monitoring-basics.