“Bên ngoài vs bên trong” nghĩa là gì theo ngôn ngữ đơn giản
Khi bạn xây ứng dụng, dễ tưởng tượng các yêu cầu đến gọn gàng, từng cái một, theo đúng thứ tự. Mạng thực tế không như vậy. Người dùng bấm “Thanh toán” hai lần vì màn hình treo. Kết nối di động rớt ngay sau khi bấm nút. Một webhook đến muộn, hoặc đến hai lần. Đôi khi nó không đến chút nào.
Ý tưởng của Pat Helland về dữ liệu bên ngoài vs bên trong là một cách tư duy gọn gàng để xử lý mớ hỗn độn đó.
Bên ngoài trông như thế nào
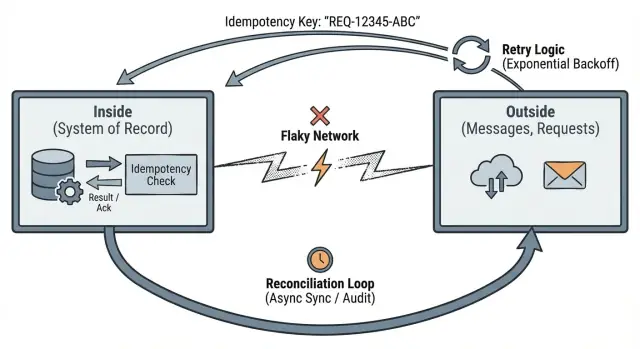
“Bên ngoài” là mọi thứ hệ thống của bạn không kiểm soát. Là nơi bạn nói chuyện với người khác và hệ thống khác, nơi giao hàng không chắc chắn: request HTTP từ trình duyệt và app di động, tin nhắn từ queue, webhook của bên thứ ba (thanh toán, email, vận chuyển), và các retry do client, proxy, hoặc job nền kích hoạt.
Ở bên ngoài, giả sử thông điệp có thể bị trễ, trùng lặp, hoặc đến sai thứ tự. Ngay cả khi điều gì đó “thường đáng tin”, hãy thiết kế cho ngày nó không còn như vậy.
Bên trong có nghĩa là gì
“Bên trong” là những gì hệ thống của bạn có thể làm cho đáng tin cậy. Là trạng thái bền bạn lưu, các quy tắc bạn áp dụng, và các sự kiện bạn có thể chứng minh sau này:
- Bản ghi trong cơ sở dữ liệu và lịch sử của chúng
- Quy tắc nghiệp vụ (ví dụ: “một đơn hàng chỉ được thanh toán một lần”)
- Một nguồn chân lý cho trạng thái (pending, paid, canceled)
Bên trong là nơi bạn bảo vệ các bất biến. Nếu bạn hứa “một thanh toán cho mỗi đơn”, lời hứa đó phải được thực thi bên trong, vì bên ngoài không đáng tin.
Tư duy cần thay đổi là: đừng giả định giao hàng hoàn hảo hoặc thời gian hoàn hảo. Xem mọi tương tác bên ngoài như một đề nghị không đáng tin có thể lặp lại, và khiến bên trong phản ứng an toàn.
Điều này quan trọng ngay cả với đội nhỏ và app đơn giản. Lần đầu tiên lỗi mạng tạo ra trừ tiền đôi hoặc đơn hàng kẹt, đó không còn là lý thuyết nữa mà thành hoàn tiền, ticket hỗ trợ và mất niềm tin.
Một ví dụ cụ thể: người dùng bấm “Đặt hàng”, app gửi request, nhưng kết nối rớt. Người dùng thử lại. Nếu bên trong bạn không có cách nhận ra “đây là cùng một lần thử”, bạn có thể tạo hai đơn, giữ tồn kho hai lần, hoặc gửi hai email xác nhận.
Bài học chính từ Pat Helland
Ý chính của Helland đơn giản: thế giới bên ngoài không chắc chắn, nhưng bên trong hệ thống của bạn phải giữ nhất quán. Mạng mất gói, điện thoại mất sóng, đồng hồ lệch, người dùng bấm refresh. App của bạn không thể kiểm soát những điều đó. Điều nó kiểm soát là những gì được chấp nhận là “đúng” sau khi dữ liệu vượt qua một ranh giới rõ ràng.
Thời gian và bất định trong một tình huống hàng ngày
Hình dung ai đó gọi cà phê trên điện thoại khi đi qua tòa nhà có Wi‑Fi kém. Họ bấm “Thanh toán”. Spinner quay. Mạng cắt. Họ bấm lại.
Có thể request đầu đã đến server nhưng response không trả về. Hoặc có thể không request nào đến. Với người dùng, hai khả năng trông giống nhau.
Đó là thời gian và bất định: bạn chưa biết chuyện gì xảy ra, và có thể biết sau. Hệ thống của bạn cần hành xử hợp lý trong khi chờ.
Retry, trùng lặp và sai thứ tự
Khi bạn chấp nhận bên ngoài không đáng tin, vài hành vi “kỳ lạ” trở nên bình thường:
- Retry tạo trùng lặp (hai request “Thanh toán”).
- Tin nhắn đến sai thứ tự (một “hủy” đến trước “thanh toán”).
- Một request được xử lý nhưng client không thấy response.
Dữ liệu bên ngoài là một khẳng định, không phải là sự thật. “Tôi đã thanh toán” chỉ là một tuyên bố gửi qua kênh không đáng tin. Nó trở thành sự thật chỉ sau khi bạn ghi vào bên trong hệ thống một cách bền vững và nhất quán.
Điều này thúc đẩy ba thói quen thực tế: định nghĩa ranh giới rõ, làm cho retry an toàn bằng idempotency, và lên kế hoạch đối chiếu khi thực tế không khớp.
Ranh giới rõ: hệ thống của bạn sở hữu gì và không sở hữu gì
Ý tưởng “bên ngoài vs bên trong” bắt đầu bằng một câu hỏi thực tế: đâu là điểm bắt đầu và kết thúc của sự thật hệ thống bạn?
Bên trong ranh giới, bạn có thể đưa ra các đảm bảo mạnh vì bạn kiểm soát dữ liệu và quy tắc. Bên ngoài ranh giới, bạn làm nỗ lực tốt nhất và giả sử thông điệp có thể bị mất, trùng lặp, trễ, hoặc đến sai thứ tự.
Trong app thật, ranh giới thường xuất hiện ở những chỗ như:
- Một endpoint API ghi một bản ghi vào database của bạn
- Một consumer queue biến event thành thay đổi được lưu
- Một handler callback ghi lại điều provider nói đã xảy ra
- Một sender thông báo hệ thống khác sau khi bạn commit trạng thái của mình
Khi bạn vẽ đường đó, quyết định invariant nào là không thể thay đổi bên trong. Ví dụ:
- Một order ID là duy nhất trong database của bạn.
- Số dư không bao giờ âm.
- Trạng thái chỉ tiến về phía trước (created -> paid -> shipped).
- Mỗi request bên ngoài bạn chấp nhận có một audit trail được lưu.
Ranh giới cũng cần ngôn ngữ rõ ràng cho “chúng ta đang ở đâu.” Nhiều lỗi nằm giữa khoảng “chúng tôi đã nghe” và “chúng tôi hoàn thành.” Một mẫu hữu ích là tách ba nghĩa:
- Received: thông điệp đến rìa của bạn (chưa chắc đã lưu)
- Accepted: bạn đã lưu và có thể retry công việc sau
- Processed: công việc dự định hoàn thành và bạn đã ghi kết quả
Khi team bỏ qua điều này, họ gặp bug chỉ xuất hiện khi tải cao hoặc trong outage từng phần. Hệ thống A dùng “paid” để nghĩa là tiền được capture; hệ thống B dùng để nghĩa là thanh toán bắt đầu. Sự không khớp đó tạo trùng lặp, đơn hàng kẹt, và ticket hỗ trợ không ai chỉnh sửa được.
Idempotency: làm cho retry an toàn
Idempotency nghĩa là: nếu cùng một request được gửi hai lần, hệ thống xử lý như một request và trả cùng kết quả.
Retry là bình thường. Timeout xảy ra. Client lặp lại. Nếu bên ngoài có thể lặp, bên trong phải biến điều đó thành thay đổi trạng thái ổn định.
Ví dụ đơn giản: app di động gửi “pay $20” rồi kết nối rớt. App retry. Nếu không có idempotency, khách hàng có thể bị trừ hai lần. Với idempotency, request thứ hai trả kết quả giống lần đầu.
Các cách phổ biến để triển khai idempotency
Hầu hết team dùng một trong các pattern này (đôi khi kết hợp):
- Idempotency key: client gửi một key duy nhất cho hành động dự định (ví dụ
Idempotency-Key: ...). Server lưu key và response cuối cùng.
- Bảng de-duplication: lưu một hàng khoá bởi (client_id, key) hoặc (order_id, operation) và từ chối side effect lần hai.
- Natural keys: dùng định danh nghiệp vụ vốn đã duy nhất, nên “tạo payment” chỉ tồn tại một lần.
Khi trùng lặp đến, hành xử tốt nhất thường không phải là "409 conflict" hay lỗi chung chung. Là trả về cùng kết quả bạn đã trả lần đầu, bao gồm cùng resource ID và trạng thái. Đó là thứ làm cho retry an toàn cho client và job nền.
Lưu bản ghi ở đâu (và giữ bao lâu)
Bản ghi idempotency phải nằm bên trong ranh giới của bạn, trong storage bền, không phải trong memory. Nếu API restart và quên, bảo đảm biến mất.
Giữ bản ghi đủ lâu để bao phủ retry thực tế và giao hàng trễ. Cửa sổ phụ thuộc rủi ro nghiệp vụ: vài phút đến vài giờ cho create rủi ro thấp, vài ngày cho thanh toán/email/vận chuyển nơi trùng lặp tốn kém, và lâu hơn nếu partner có thể retry trong thời gian dài.
Cách tránh bẫy “giao dịch phân tán”
Giao dịch phân tán nghe có vẻ an tâm: một commit lớn qua dịch vụ, queue và database. Thực tế, chúng thường không sẵn sàng, chậm, hoặc quá mong manh để phụ thuộc. Một khi có một hop mạng, bạn không thể giả định mọi thứ commit cùng lúc.
Cái bẫy phổ biến là dựng workflow chỉ hoạt động nếu mọi bước thành công ngay lập tức: lưu order, charge thẻ, reserve tồn kho, gửi xác nhận. Nếu bước 3 timeout, nó thất bại hay thành công? Nếu bạn retry, sẽ trừ tiền đôi hay giữ tồn kho đôi?
Hai cách tiếp cận thực tế tránh điều này:
- Outbox/inbox: ghi một intent bền trong database của bạn (một hàng outbox) trong cùng transaction với thay đổi trạng thái, rồi worker gửi message. Bên nhận giữ một inbox khoá bởi message ID để xử lý an toàn nếu cùng message đến lại.
- Saga-style với bù đắp: tách workflow thành các bước nhỏ hoàn thành độc lập. Nếu bước sau thất bại, chạy một hành động bù đắp (ví dụ, thả tồn kho hoặc huỷ đơn chưa thanh toán) thay vì cố rollback lịch sử.
Chọn một kiểu cho mỗi workflow và tuân thủ. Trộn “thỉnh thoảng dùng outbox” với “thỉnh thoảng giả sử thành công đồng bộ” tạo các edge case khó test.
Một quy tắc đơn giản: nếu bạn không thể commit nguyên tử qua ranh giới, thiết kế cho retry, trùng lặp và trì hoãn.
Đối chiếu: cách hệ thống thực tế phục hồi khỏi sự không khớp
Đối chiếu thừa nhận một chân lý cơ bản: khi app bạn nói chuyện với hệ thống khác qua mạng, đôi khi bạn sẽ không đồng ý về chuyện đã xảy ra. Request timeout, callback đến muộn, người ta retry. Đối chiếu là cách bạn phát hiện khác biệt và sửa chúng theo thời gian.
Xem hệ thống bên ngoài là nguồn chân lý độc lập. App của bạn giữ bản ghi nội bộ, nhưng cần so sánh bản ghi đó với những gì partner, provider và người dùng thực sự đã làm.
Cơ chế đối chiếu phổ biến
Hầu hết team dùng một bộ công cụ đơn giản (đơn giản là tốt): một worker retry các hành động pending và kiểm tra lại trạng thái bên ngoài, một quét định kỳ tìm bất nhất, và một hành động sửa nhỏ cho hỗ trợ để retry, cancel, hoặc đánh dấu đã xem xét.
So sánh gì và ghi lại gì
Đối chiếu chỉ hiệu quả nếu bạn biết so sánh gì: sổ cái nội bộ vs sổ cái provider (thanh toán), trạng thái đơn vs trạng thái vận chuyển (fulfillment), trạng thái subscription vs billing.
Làm cho trạng thái có thể sửa chữa được. Thay vì nhảy thẳng từ “created” sang “completed,” dùng trạng thái giữ như pending, on hold, hoặc needs review. Điều đó giúp an toàn khi nói “chúng tôi chưa chắc” và cho đối chiếu một nơi rõ ràng để đặt xuống.
Ghi lại một audit trail nhỏ cho những thay đổi quan trọng:
- Khi bạn gửi request và khi lần cuối bạn nghe lại
- Correlation ID nối bản ghi của bạn với event/tham chiếu bên ngoài
- Trạng thái bên ngoài biết cuối cùng (và nguồn của nó)
- Lý do cho override thủ công (ai, gì, tại sao)
Ví dụ: nếu app yêu cầu nhãn vận chuyển và mạng rớt, nội bộ bạn có thể không có nhãn trong khi hãng vận chuyển thực ra đã tạo. Một worker recon có thể tìm theo correlation ID, phát hiện nhãn tồn tại, và đẩy đơn tiếp (hoặc đánh dấu để xem xét nếu chi tiết không khớp).
Từng bước: thiết kế workflow sống sót khi mạng lỗi
Khi bạn giả định mạng sẽ lỗi, mục tiêu thay đổi. Bạn không cố làm mọi bước thành công trong một lần. Bạn cố làm mọi bước an toàn để lặp và dễ sửa.
Một workflow thực tế
-
Viết một câu ranh giới ngắn gọn. Rõ ràng về những gì hệ thống bạn sở hữu (nguồn chân lý), những gì nó phản chiếu, và những gì nó chỉ yêu cầu từ bên ngoài.
-
Liệt kê các chế độ lỗi trước happy path. Tối thiểu: timeout (không biết đã thành công hay chưa), request trùng, thành công một phần (bước trước xảy ra, bước sau không), và event đến sai thứ tự.
-
Chọn chiến lược idempotency cho mỗi đầu vào. Với API đồng bộ, thường là idempotency key cộng kết quả đã lưu. Với message/event, thường là message ID duy nhất và một bản ghi “tôi đã xử lý chưa?”.
-
Persist intent, rồi hành động. Đầu tiên lưu cái gì đó bền như “PaymentAttempt: pending” hoặc “ShipmentRequest: queued,” rồi gọi bên ngoài, rồi lưu kết quả. Trả về một reference ID ổn định để retry trỏ vào cùng intent thay vì tạo mới.
-
Xây đối chiếu và đường sửa, và làm cho chúng hiển thị. Recon có thể là job quét các bản ghi "pending quá lâu" và kiểm tra lại trạng thái. Đường sửa có thể là hành động admin an toàn như “retry,” “cancel,” hoặc “mark resolved,” kèm ghi chú audit. Thêm observability cơ bản: correlation ID, trường trạng thái rõ, và vài số liệu (pending, retries, failures).
Ví dụ: nếu checkout timeout ngay sau khi bạn gọi provider thanh toán, đừng đoán. Lưu attempt, trả về attempt ID, và cho phép người dùng retry với cùng idempotency key. Sau đó, đối chiếu xác nhận provider có trừ hay không và cập nhật attempt mà không trừ đôi.
Ví dụ kịch bản: luồng đơn hàng với retry và callback trễ
Khách hàng bấm “Đặt hàng.” Dịch vụ của bạn gửi request thanh toán đến provider, nhưng mạng lỏng. Provider có sự thật riêng, database của bạn có sự thật của bạn. Chúng sẽ lệch nhau trừ khi bạn thiết kế cho điều đó.
Điều xảy ra bên ngoài (sự kiện bạn không kiểm soát)
Từ góc nhìn của bạn, bên ngoài là luồng thông điệp có thể trễ, lặp hoặc mất:
- “Submit order” đến API của bạn.
- Request thanh toán của bạn tới provider.
- Provider gửi webhook nói “authorized.”
- Provider retry webhook và gửi callback giống hệt lần trước.
- Client timeout và retry “Place order.”
Không bước nào trong số đó đảm bảo “exactly once.” Chúng chỉ đảm bảo “có thể xảy ra.”
Những gì bạn giữ bên trong (bản ghi bạn kiểm soát)
Bên trong ranh giới, lưu sự thật bền và tối thiểu cần để nối event bên ngoài tới các sự thật đó.
Khi khách đặt hàng lần đầu, tạo một bản ghi order trong trạng thái rõ ràng như pending_payment. Cũng tạo một bản ghi payment_attempt với tham chiếu provider duy nhất cộng idempotency_key liên kết với hành động khách.
Nếu client timeout và retry, API của bạn không nên tạo đơn thứ hai. Nó nên tìm idempotency_key và trả về cùng order_id và trạng thái hiện tại. Lựa chọn đó ngăn trùng khi mạng lỗi.
Bây giờ webhook đến hai lần. Callback đầu cập nhật payment_attempt thành authorized và chuyển đơn sang paid. Callback thứ hai vào cùng handler, nhưng bạn phát hiện đã xử lý event provider đó (bằng cách lưu provider event ID, hoặc kiểm tra trạng thái hiện tại) và không làm gì. Bạn vẫn có thể trả 200 OK, vì kết quả đã đúng.
Cuối cùng, đối chiếu xử lý các trường hợp lộn xộn. Nếu đơn vẫn pending_payment sau một khoảng, job nền gọi API provider bằng tham chiếu đã lưu. Nếu provider nói “authorized” nhưng bạn đã bỏ lỡ webhook, bạn cập nhật bản ghi. Nếu provider nói “failed” nhưng bạn đã đánh dấu paid, bạn đánh dấu để xem lại hoặc kích hoạt hành động bù đắp như hoàn tiền.
Sai lầm phổ biến gây trùng lặp và trạng thái kẹt
Hầu hết bản ghi trùng và workflow “kẹt” bắt nguồn từ việc lẫn lộn giữa điều đã xảy ra bên ngoài (request đến, message nhận được) và điều bạn đã commit an toàn bên trong.
Một lỗi kinh điển: client gửi “place order”, server bắt đầu xử lý, mạng rớt, client retry. Nếu bạn coi mỗi retry là sự thật mới, bạn sẽ có trừ tiền đôi, đơn trùng, hoặc nhiều email.
Nguyên nhân thường gặp:
- Tin vào request đến quá sớm: gửi email hoặc log “order created” trước khi commit database là bền.
- Retry tạo dòng mới: sinh order ID mới cho mỗi lần thay vì map retry vào một kết quả.
- Giả sử “exactly once” delivery: queue và callback không hứa điều đó. Trùng, trễ, và sai thứ tự xảy ra.
- Không có định danh ổn định: nếu bạn không thể trả lời “tôi đã thấy intent này trước chưa?”, bạn không thể ngăn trùng.
- Chỉ có thành công/thất bại, không có trạng thái trung gian: thiếu trạng thái pending khiến timeout thành bí ẩn.
Một vấn đề làm mọi thứ tệ hơn: không có audit trail. Nếu bạn ghi đè trường và chỉ giữ trạng thái mới nhất, bạn mất bằng chứng cần thiết để đối chiếu sau này.
Một kiểm tra hợp lý: “Nếu tôi chạy handler này hai lần, kết quả có giống nhau không?” Nếu câu trả lời là không, trùng lặp không phải là edge case hiếm. Nó là điều chắc chắn xảy ra.
Checklist nhanh và bước tiếp theo thực tế
Nếu chỉ nhớ một điều: app của bạn phải đúng ngay cả khi thông điệp đến muộn, đến hai lần, hoặc không đến chút nào.
Dùng checklist này để phát hiện điểm yếu trước khi chúng biến thành bản ghi trùng, cập nhật thiếu, hoặc workflow kẹt:
- Nguồn chân lý rõ ràng: với mỗi workflow, bạn chỉ ra một nơi là “sự thật” (thường là database).
- Mỗi ghi có thể retry an toàn: mỗi command/API có idempotency key (hoặc key nghiệp vụ tự nhiên).
- ID ổn định và correlation ID xuyên suốt: bạn có thể truy vết một hành động nghiệp vụ qua logs, bảng và callback.
- Đối chiếu chạy tự động: bạn định kỳ so sánh “những gì chúng tôi tin” vs “những gì đã xảy ra” và sửa hoặc raise alert rõ ràng.
- Rollback không làm hỏng trạng thái: thay đổi có audit và tương thích qua các phiên bản.
Nếu bạn không trả lời nhanh một trong các điều trên, đó thường là dấu ranh giới mơ hồ hoặc một chuyển trạng thái thiếu.
Bước tiếp theo thực tế:
-
Phác thảo ranh giới và trạng thái trước. Định nghĩa một tập trạng thái nhỏ cho mỗi workflow (ví dụ: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
-
Thêm idempotency nơi rủi ro cao nhất. Bắt đầu với các ghi rủi ro cao: tạo order, capture payment, issue refund. Lưu idempotency key trong PostgreSQL với ràng buộc unique để trùng bị từ chối an toàn.
-
Xem đối chiếu là một tính năng bình thường. Lên lịch job tìm các bản ghi "pending quá lâu", kiểm tra hệ thống ngoài lại, và sửa trạng thái local.
-
Lặp an toàn. Điều chỉnh chuyển trạng thái và quy tắc retry, rồi test bằng cách gửi lại cùng request và xử lý lại cùng event.
Nếu bạn xây nhanh trên nền tảng điều khiển bằng chat như Koder.ai (koder.ai), vẫn đáng để nhúng các quy tắc này vào dịch vụ sinh ra sớm: tốc độ đến từ tự động hóa, nhưng độ tin cậy đến từ ranh giới rõ ràng, handler idempotent, và đối chiếu.