07 thg 11, 2025·8 phút
Giải thích những đột phá mạng nơ-ron của Geoffrey Hinton
Hướng dẫn rõ ràng về những ý tưởng then chốt của Geoffrey Hinton — từ backprop và Boltzmann machines đến deep nets và AlexNet — và cách chúng định hình AI hiện đại.
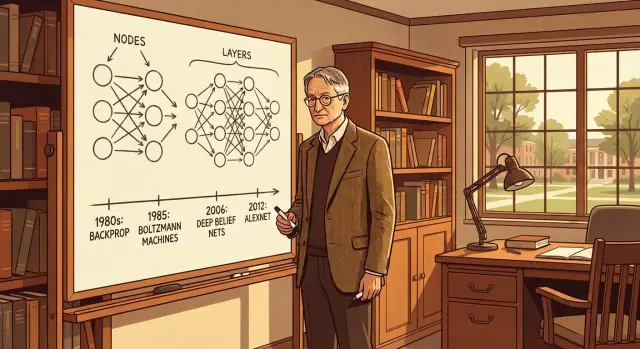
Hướng dẫn rõ ràng về những ý tưởng then chốt của Geoffrey Hinton — từ backprop và Boltzmann machines đến deep nets và AlexNet — và cách chúng định hình AI hiện đại.
Hướng dẫn này dành cho độc giả tò mò, không chuyên, những người thường nghe rằng “mạng nơ-ron làm thay đổi mọi thứ” và muốn một giải thích rõ ràng, thực tế về ý đó nghĩa là gì—không cần đạo hàm hay lập trình.
Bạn sẽ có một chuyến tham quan bằng tiếng thường về những ý tưởng Geoffrey Hinton góp phần thúc đẩy, tại sao chúng quan trọng vào thời điểm đó, và cách chúng liên kết với các công cụ AI mà mọi người dùng ngày nay. Hãy coi đây như một câu chuyện về những cách tốt hơn để dạy máy nhận diện quy luật—văn bản, hình ảnh, âm thanh—bằng cách học từ ví dụ.
Hinton không “phát minh ra AI”, và không một cá nhân nào tạo ra machine learning hiện đại. Tầm quan trọng của ông là ông liên tục giúp làm cho mạng nơ-ron hoạt động trong thực tế khi nhiều nhà nghiên cứu tin rằng chúng là ngõ cụt. Ông đóng góp các khái niệm then chốt, các thí nghiệm, và một văn hóa nghiên cứu coi việc học biểu diễn (các đặc trưng nội bộ hữu ích) là vấn đề trung tâm—thay vì viết tay từng quy tắc.
Ở các phần sau, chúng ta sẽ giải thích:
Trong bài này, một đột phá là một thay đổi khiến mạng nơ-ron hữu dụng hơn: huấn luyện ổn định hơn, học đặc trưng tốt hơn, tổng quát với dữ liệu mới chính xác hơn, hoặc mở rộng cho các nhiệm vụ lớn hơn. Ít liên quan đến một demo hào nhoáng—nhiều hơn là biến một ý tưởng thành một phương pháp đáng tin cậy.
Mạng nơ-ron không được sinh ra để “thay thế lập trình viên.” Lời hứa ban đầu cụ thể hơn: xây dựng máy có thể học các biểu diễn nội bộ hữu ích từ các đầu vào lộn xộn của thế giới thực—hình ảnh, giọng nói và văn bản—mà không cần kỹ sư viết tay mọi quy tắc.
Một bức ảnh chỉ là triệu triệu giá trị pixel. Một bản ghi âm là một luồng đo áp suất. Thách thức là biến những con số thô đó thành khái niệm mà con người quan tâm: cạnh, hình dạng, âm vị, từ, đối tượng, ý định.
Trước khi mạng nơ-ron khả thi, nhiều hệ thống dựa vào các đặc trưng do con người thiết kế—những phép đo được may đo như “bộ dò cạnh” hoặc “mô tả kết cấu.” Điều đó hoạt động trong các thiết lập hẹp, nhưng thường thất bại khi ánh sáng thay đổi, giọng nói khác nhau hoặc môi trường phức tạp hơn.
Mạng nơ-ron hướng tới giải quyết vấn đề này bằng cách học các đặc trưng tự động, từng lớp một, từ dữ liệu. Nếu hệ thống có thể tự khám phá các khối xây dựng trung gian phù hợp, nó sẽ tổng quát tốt hơn và thích nghi với nhiệm vụ mới với ít công sức thủ công hơn.
Ý tưởng hấp dẫn, nhưng một số rào cản khiến mạng nơ-ron chưa thể hiện được trong thời gian dài:
Ngay cả khi mạng nơ-ron không được ưa chuộng—đặc biệt trong những phần của thập niên 1990 và đầu 2000—những nhà nghiên cứu như Geoffrey Hinton vẫn tiếp tục theo đuổi học biểu diễn. Ông đề xuất các ý tưởng (từ giữa thập niên 1980) và trở lại các ý tưởng cũ (như mô hình dựa trên năng lượng) cho tới khi phần cứng, dữ liệu và phương pháp chín muồi.
Sự kiên trì đó giúp giữ mục tiêu cốt lõi sống: máy học các biểu diễn đúng đắn, không chỉ kết quả cuối cùng.
Backpropagation (thường gọi tắt là “backprop”) là phương pháp cho phép mạng nơ-ron cải thiện bằng cách học từ lỗi. Mạng đưa ra một dự đoán, ta đo xem nó sai bao nhiêu, rồi điều chỉnh các “nút vặn” bên trong của mạng (các trọng số) để lần sau làm tốt hơn.
Hãy tưởng tượng một mạng cố gắng gắn nhãn một bức ảnh là “mèo” hay “chó.” Nó đoán “mèo”, nhưng đáp án đúng là “chó.” Backprop bắt đầu từ lỗi cuối cùng đó và làm việc ngược qua các lớp của mạng, xác định mức độ mỗi trọng số góp phần vào câu trả lời sai.
Cách nghĩ thực dụng:
Những điều chỉnh này thường dùng một thuật toán kèm theo gọi là gradient descent, nghĩa là “đi những bước nhỏ xuống dốc lỗi.”
Trước khi backprop phổ biến, huấn luyện mạng nhiều lớp không đáng tin cậy và chậm. Backprop làm cho việc huấn luyện mạng sâu hơn khả thi vì nó cung cấp một cách có hệ thống, có thể lặp lại để tinh chỉnh nhiều lớp cùng lúc—thay vì chỉ chỉnh lớp cuối hoặc phán đoán cách sửa.
Sự thay đổi này quan trọng cho các đột phá sau này: khi bạn có thể huấn luyện nhiều lớp hiệu quả, mạng có thể học đặc trưng phong phú hơn (cạnh → hình dạng → đối tượng, ví dụ).
Backprop không phải là mạng “suy nghĩ” hay “hiểu” như con người. Nó là một phương pháp toán học: cách điều chỉnh tham số để khớp ví dụ tốt hơn.
Cũng không phải backprop là một mô hình duy nhất—nó là phương pháp huấn luyện có thể dùng cho nhiều loại mạng nơ-ron khác nhau.
Nếu bạn muốn tìm hiểu sâu hơn về cấu trúc mạng, xem /blog/neural-networks-explained.
Boltzmann machines là một trong những bước then chốt của Geoffrey Hinton hướng tới việc làm cho mạng nơ-ron học các biểu diễn nội bộ hữu ích, không chỉ đưa ra đáp án.
Boltzmann machine là một mạng các đơn vị đơn giản có thể bật/tắt (hoặc, trong các phiên bản hiện đại, nhận giá trị thực). Thay vì dự đoán đầu ra trực tiếp, nó gán một năng lượng cho toàn bộ cấu hình các đơn vị. Năng lượng thấp hơn nghĩa là “cấu hình này hợp lý.”
Một phép ẩn dụ hữu ích là một mặt bàn phủ đầy các hõm và thung lũng nhỏ. Nếu bạn thả một viên bi lên bề mặt, nó sẽ lăn và dừng lại ở chỗ lõm thấp. Boltzmann machines cố gắng làm điều tương tự: với thông tin phần nào cho trước (như một số nút hiển thị được đặt theo dữ liệu), mạng “rung động” các nút nội bộ cho tới khi nó dừng ở các trạng thái có năng lượng thấp—những trạng thái mà nó học được là có khả năng.
Huấn luyện Boltzmann machines cổ điển đòi hỏi lấy mẫu lặp đi lặp lại nhiều trạng thái để ước tính những gì mô hình tin tưởng so với dữ liệu. Việc lấy mẫu này có thể rất chậm, nhất là với mạng lớn.
Dù vậy, cách tiếp cận có ảnh hưởng vì nó:
Hầu hết sản phẩm ngày nay dựa trên mạng feedforward sâu huấn luyện bằng backprop vì chúng nhanh hơn và dễ mở rộng hơn.
Di sản của Boltzmann machines là nhiều về khái niệm hơn là thực tiễn: ý tưởng rằng mô hình tốt học các “trạng thái ưu thích” của thế giới—và việc học có thể được xem như di chuyển khối lượng xác suất về những thung lũng năng lượng thấp đó.
Mạng nơ-ron không chỉ tốt hơn trong việc khớp đường cong—chúng giỏi hơn trong việc sáng tạo các đặc trưng đúng đắn. Đó là ý nghĩa của “học biểu diễn”: thay vì con người mã hóa tay những gì cần tìm, mô hình học các mô tả nội bộ (biểu diễn) giúp nhiệm vụ dễ dàng hơn.
Biểu diễn là cách mô hình tóm tắt đầu vào thô. Nó chưa phải là nhãn như “mèo”; đó là cấu trúc hữu ích trên đường tới nhãn—những mẫu nắm bắt điều gì thường quan trọng. Lớp sớm có thể phản ứng với tín hiệu đơn giản, trong khi các lớp sau kết hợp chúng thành khái niệm có ý nghĩa hơn.
Trước sự chuyển dịch này, nhiều hệ thống phụ thuộc vào các đặc trưng do chuyên gia thiết kế: bộ dò cạnh cho hình ảnh, tín hiệu âm thanh cho giọng nói, hay thống kê văn bản được chế tác tỉ mỉ. Những đặc trưng đó hoạt động, nhưng thường vỡ khi điều kiện thay đổi (ánh sáng, giọng, cách diễn đạt).
Học biểu diễn cho phép mô hình điều chỉnh đặc trưng cho chính dữ liệu, từ đó cải thiện độ chính xác và khiến hệ thống bền vững hơn trước dữ liệu thực tế lộn xộn.
Sợi chỉ chung là thứ bậc: các mẫu đơn giản kết hợp thành những mẫu phong phú hơn.
Trong nhận dạng ảnh, mạng có thể đầu tiên học các mẫu giống cạnh (thay đổi sáng-tối). Sau đó nó kết hợp các cạnh thành góc và đường cong, rồi thành các bộ phận như bánh xe hoặc mắt, và cuối cùng thành đối tượng toàn bộ như “xe đạp” hoặc “khuôn mặt.”
Các đột phá của Hinton giúp làm cho việc xây dựng đặc trưng theo lớp này trở nên khả thi—và đó là lý do lớn khiến học sâu bắt đầu chiến thắng trong các tác vụ mà người ta thực sự quan tâm.
Deep belief networks (DBNs) là một bước đệm quan trọng trên đường đến các mạng sâu mà chúng ta biết ngày nay. Ở mức cao, DBN là một chồng lớp nơi mỗi lớp học cách biểu diễn lớp dưới nó—bắt đầu từ đầu vào thô và dần xây dựng những “khái niệm” trừu tượng hơn.
Hãy tưởng tượng dạy một hệ thống nhận diện chữ viết tay. Thay vì cố gắng học mọi thứ một lần, một DBN trước tiên học các mẫu đơn giản (như cạnh và nét), rồi tổ hợp của những mẫu đó (vòng, góc), và cuối cùng các hình dạng cao hơn giống một phần của chữ số.
Ý tưởng then chốt là mỗi lớp cố gắng mô hình hóa các mẫu trong đầu vào của nó mà chưa được cho đáp án. Sau khi chồng lớp học xong những biểu diễn ngày càng hữu ích này, bạn có thể tinh chỉnh toàn bộ mạng cho nhiệm vụ cụ thể như phân loại.
Trước đó, các mạng sâu thường gặp khó khi khởi tạo ngẫu nhiên. Tín hiệu huấn luyện có thể yếu hoặc không ổn định khi truyền qua nhiều lớp, và mạng dễ rơi vào các trạng thái không hữu ích.
Huấn luyện lớp-đơn vị cho mạng một “khởi đầu ấm.” Mỗi lớp có một hiểu biết hợp lý về cấu trúc dữ liệu, nên toàn bộ mạng không phải tìm kiếm mù quáng.
Pretraining không giải quyết mọi vấn đề, nhưng nó làm cho việc có chiều sâu trở nên thực tế vào thời điểm dữ liệu, sức mạnh tính toán và mẹo huấn luyện còn hạn chế so với nay.
DBN chứng minh rằng học các biểu diễn tốt xuyên nhiều lớp có thể hoạt động—và rằng chiều sâu không chỉ là lý thuyết mà là con đường khả dụng.
Mạng nơ-ron có thể “học thuộc lòng” dữ liệu huấn luyện một cách kỳ lạ: chúng ghi nhớ thay vì học quy luật nền tảng. Vấn đề đó gọi là overfitting, xuất hiện khi mô hình trông rất tốt trên các ví dụ đã biết nhưng thất vọng trên dữ liệu mới, thực tế.
Hãy tưởng tượng bạn ôn thi lái xe bằng cách ghi nhớ chính xác lộ trình của giám khảo lần trước—mỗi rẽ, mỗi biển báo, mỗi ổ gà. Nếu bài thi dùng cùng lộ trình, bạn sẽ hoàn toàn giỏi. Nhưng nếu lộ trình thay đổi, bạn thất bại vì bạn không học kỹ năng lái chung; bạn học một kịch bản cụ thể.
Đó là overfitting: độ chính xác cao trên ví dụ quen thuộc, hiệu năng yếu trên cái mới.
Dropout được phổ biến bởi Geoffrey Hinton và cộng sự như một mẹo huấn luyện đơn giản nhưng hiệu quả. Trong khi huấn luyện, mạng ngẫu nhiên “tắt” (drop out) một số nút trong mỗi lần chạy dữ liệu.
Điều này buộc mô hình không phụ thuộc vào bất kỳ đường dẫn hay bộ đặc trưng “ưa thích” nào. Thay vào đó, nó phải lan truyền thông tin qua nhiều kết nối và học các mẫu vẫn đúng ngay cả khi một phần mạng bị mất.
Một hình dung: giống như học mà thỉnh thoảng mất quyền truy cập vào vài trang ghi chú—bạn bị thúc ép hiểu khái niệm thay vì học thuộc một cách diễn đạt duy nhất.
Lợi ích chính là tổng quát hóa tốt hơn: mạng hoạt động đáng tin cậy hơn trên dữ liệu chưa thấy trước. Thực tế, dropout giúp việc huấn luyện các mạng lớn dễ hơn mà không rơi vào việc học thuộc lòng, và trở thành công cụ tiêu chuẩn trong nhiều thiết lập học sâu.
Trước AlexNet, “nhận dạng ảnh” không chỉ là demo hay—đó là một cuộc đua có thể đo lường. Các benchmark như ImageNet đặt câu hỏi đơn giản: cho một ảnh, hệ thống của bạn có thể gọi tên thứ gì trong đó?
Khó khăn là quy mô: hàng triệu ảnh và hàng nghìn hạng mục. Quy mô đó phân biệt các ý tưởng nghe có vẻ hay trong thí nghiệm nhỏ với những phương pháp chịu đựng được khi thế giới trở nên lộn xộn.
Tiến bộ trên các bảng xếp hạng này thường là từng bước. Rồi AlexNet (do Alex Krizhevsky, Ilya Sutskever và Geoffrey Hinton xây dựng) xuất hiện và khiến kết quả trông như một bước nhảy thay vì leo dần.
AlexNet chỉ ra rằng một mạng tích chập sâu có thể đánh bại các pipeline thị giác máy tính truyền thống khi ba yếu tố kết hợp:
Đây không chỉ là “mô hình lớn hơn.” Đó là một công thức thực tế để huấn luyện mạng sâu hiệu quả trên các nhiệm vụ thực tế.
Hãy tưởng tượng trượt một “cửa sổ” nhỏ trên bức ảnh—như di chuyển một tem thư trên hình. Bên trong cửa sổ đó, mạng tìm một mẫu đơn giản: một cạnh, một góc, một sọc. Trình kiểm tra cùng một mẫu được tái sử dụng ở mọi vị trí trên ảnh, nên nó có thể tìm “các kiểu giống cạnh” dù chúng ở trái, phải, trên hay dưới.
Đắp đủ các lớp như vậy lên, bạn có một hệ thống phân cấp: cạnh trở thành kết cấu, kết cấu thành bộ phận (như bánh xe), và bộ phận thành đối tượng (như xe đạp).
AlexNet khiến học sâu trở nên đáng tin cậy và đáng đầu tư. Nếu mạng sâu thống trị một benchmark công khai khó, chúng có thể cải thiện sản phẩm—tìm kiếm, gắn thẻ ảnh, tính năng camera, công cụ trợ năng, và hơn thế nữa.
Nó giúp biến mạng nơ-ron từ “nghiên cứu hứa hẹn” thành hướng rõ ràng cho các đội xây dựng hệ thống thực tế.
Học sâu không “xuất hiện qua đêm.” Nó bắt đầu trông đột phá khi vài thành phần cuối cùng khớp lại—sau nhiều năm công trình trước đó cho thấy ý tưởng hứa hẹn nhưng khó mở rộng.
Nhiều dữ liệu. Web, smartphone và các bộ dữ liệu lớn có gán nhãn (như ImageNet) cho phép mạng học từ hàng triệu ví dụ thay vì hàng nghìn. Với dữ liệu nhỏ, mô hình lớn thường chỉ ghi nhớ.
Nhiều tính toán (đặc biệt GPU). Huấn luyện mạng sâu nghĩa là thực hiện cùng phép toán hàng tỷ lần. GPU làm cho điều đó rẻ và nhanh tới mức có thể lặp thử nghiệm. Những gì trước kia mất tuần có thể rút xuống còn ngày—hoặc giờ—giúp các nhà nghiên cứu thử nhiều kiến trúc hơn, siêu tham số hơn và thất bại nhanh hơn.
Mẹo huấn luyện tốt hơn. Những cải tiến thực dụng giảm bớt tính ngẫu nhiên “nó huấn luyện… hoặc nó không”:
Không có yếu tố nào thay đổi ý tưởng cốt lõi của mạng nơ-ron; chúng thay đổi độ tin cậy để triển khai nó.
Khi tính toán và dữ liệu đạt ngưỡng, các cải tiến bắt đầu cộng dồn. Kết quả tốt hơn thu hút thêm đầu tư, vốn tài trợ cho bộ dữ liệu lớn hơn và phần cứng nhanh hơn, điều này lại tạo điều kiện cho kết quả tốt hơn nữa. Từ bên ngoài, trông như một bước nhảy; từ bên trong, đó là sự cộng hưởng.
Phóng to mang lại chi phí thực: tiêu thụ năng lượng nhiều hơn, chi phí huấn luyện đắt hơn, và nhiều nỗ lực để triển khai hiệu quả. Nó cũng làm tăng khoảng cách giữa những gì một nhóm nhỏ có thể thử nghiệm và những gì chỉ các phòng thí nghiệm có tài chính mới có thể huấn luyện từ đầu.
Những ý tưởng chủ chốt của Hinton—học biểu diễn từ dữ liệu, huấn luyện mạng sâu ổn định, và ngăn overfitting—không phải là “tính năng” bạn có thể chỉ ra trong một app. Chúng là lý do tại sao nhiều tính năng hàng ngày cảm thấy nhanh hơn, chính xác hơn và ít gây ức chế hơn.
Hệ thống tìm kiếm hiện đại không chỉ khớp từ khóa. Chúng học biểu diễn của truy vấn và nội dung nên cụm từ “tai nghe chống ồn tốt nhất” có thể hiển thị trang không lặp lại đúng cụm đó. Cùng ý tưởng học biểu diễn giúp feed gợi ý hiểu hai món là “tương tự” ngay cả khi mô tả khác nhau.
Dịch máy cải thiện mạnh khi mô hình học các mẫu theo lớp (từ ký tự tới từ tới ý nghĩa). Dù kiểu mô hình nền thay đổi, bộ công thức huấn luyện—bộ dữ liệu lớn, tối ưu cẩn thận và regularization—vẫn định hình cách các đội xây dựng tính năng ngôn ngữ đáng tin cậy.
Trợ lý giọng nói và gõ bằng giọng nói dựa trên mạng nơ-ron biến âm thanh lộn xộn thành văn bản sạch. Backprop là công cụ chính tinh chỉnh các mô hình này, trong khi kỹ thuật như dropout giúp chúng tránh ghi nhớ đặc điểm kỳ quặc của một người nói hay micro cụ thể.
Ứng dụng ảnh có thể nhận diện khuôn mặt, nhóm cảnh tương tự và cho phép bạn tìm “bãi biển” mà không cần gắn nhãn thủ công. Đó là học biểu diễn: hệ thống học các đặc trưng thị giác (cạnh → kết cấu → đối tượng) để gắn thẻ và truy hồi ở quy mô.
Ngay cả khi bạn không huấn luyện mô hình từ đầu, những nguyên tắc này xuất hiện trong công việc sản phẩm hàng ngày: bắt đầu với biểu diễn tốt (thường qua mô hình được pretrained), ổn định huấn luyện và đánh giá, và dùng regularization khi hệ thống bắt đầu “ghi nhớ điểm chuẩn”.
Đó cũng là lý do các công cụ “vibe-coding” hiện nay có cảm giác mạnh mẽ. Các nền tảng như Koder.ai đặt trên LLM và quy trình agent thế hệ hiện tại giúp đội biến mô tả ngôn ngữ thô thành ứng dụng web, backend hoặc mobile—thường nhanh hơn pipeline truyền thống—và vẫn cho phép xuất mã nguồn và triển khai như đội engineering bình thường.
Nếu bạn muốn trực giác huấn luyện ở mức cao, xem /blog/backpropagation-explained.
Các đột phá lớn thường bị biến thành câu chuyện đơn giản. Điều đó làm cho chúng dễ nhớ—nhưng cũng tạo ra hiểu lầm che giấu điều thực sự đã xảy ra và những gì vẫn còn quan trọng ngày nay.
Hinton là một nhân vật trung tâm, nhưng mạng nơ-ron hiện đại là kết quả của nhiều thập kỷ đóng góp từ nhiều nhóm: những người phát triển phương pháp tối ưu, những người xây bộ dữ liệu, kỹ sư làm cho GPU khả dụng cho huấn luyện, và các đội chứng minh ý tưởng ở quy mô. Trong công việc của Hinton, học trò và cộng tác viên của ông cũng đóng vai trò lớn. Câu chuyện thực tế là một chuỗi đóng góp xếp hàng lại.
Mạng nơ-ron được nghiên cứu từ giữa thế kỷ 20, có những giai đoạn hào hứng và thất vọng. Thay đổi không phải là ý tưởng xuất hiện, mà là khả năng huấn luyện mô hình lớn đáng tin cậy và cho thấy thắng lợi rõ rệt trên các vấn đề thực tế. “Kỷ nguyên học sâu” là sự phục hưng chứ không phải phát minh đột ngột.
Mô hình sâu hơn có thể giúp, nhưng không phải là phép màu. Thời gian huấn luyện, chi phí, chất lượng dữ liệu và lợi suất giảm dần là những giới hạn thực tế. Đôi khi mô hình nhỏ hơn cho kết quả tốt hơn vì dễ tinh chỉnh, ít nhạy với nhiễu, hoặc phù hợp hơn với nhiệm vụ.
Backprop là phương pháp thực dụng để điều chỉnh tham số dựa trên phản hồi có nhãn. Con người học từ ít ví dụ hơn nhiều, dùng kiến thức nền phong phú và không dựa trên cùng loại tín hiệu lỗi rõ ràng. Mạng nơ-ron có thể được cảm hứng từ sinh học mà không phải là bản sao chính xác của não.
Câu chuyện của Hinton không chỉ là danh sách phát minh. Nó là một mô típ: giữ một ý tưởng học tập đơn giản, thử nghiệm không ngừng, và nâng cấp các thành phần xung quanh (dữ liệu, tính toán và mẹo huấn luyện) cho tới khi nó hoạt động ở quy mô.
Những thói quen dễ áp dụng nhất là thực dụng:
Dễ bị cám dỗ khi hiểu sai bài học tiêu đề là “mô hình lớn hơn thắng.” Điều đó không đầy đủ.
Chạy theo kích thước mà không có mục tiêu rõ ràng thường dẫn tới:
Một mặc định tốt hơn là: bắt đầu nhỏ, chứng minh giá trị, rồi mở rộng—và chỉ phóng to phần thực sự giới hạn hiệu năng.
Nếu bạn muốn biến những bài học này thành thực hành hàng ngày, những bài tiếp theo hữu ích là:
Từ quy tắc học cơ bản của backprop, đến các biểu diễn nắm bắt ý nghĩa, tới các mẹo thực dụng như dropout, tới một demo đột phá như AlexNet—mạch truyện nhất quán: học các đặc trưng hữu ích từ dữ liệu, làm cho việc huấn luyện ổn định, và kiểm chứng tiến bộ bằng kết quả thực tế.
Đó là sổ tay nên giữ lại.
Geoffrey Hinton quan trọng vì ông nhiều lần giúp làm cho mạng nơ-ron hoạt động trong thực tế khi nhiều nhà nghiên cứu cho rằng chúng là ngõ cụt.
Thay vì “phát minh ra AI”, ảnh hưởng của ông đến từ việc thúc đẩy học biểu diễn, cải tiến phương pháp huấn luyện, và góp phần xây dựng văn hóa nghiên cứu chú trọng việc học các đặc trưng từ dữ liệu thay vì viết tay các quy tắc.
Một “đột phá” ở đây có nghĩa là mạng nơ-ron trở nên đáng tin cậy và hữu dụng hơn: chúng huấn luyện ổn định hơn, học được những đặc trưng nội bộ tốt hơn, tổng quát hơn với dữ liệu mới, hoặc mở rộng được cho các bài toán khó hơn.
Nó ít là về một demo hào nhoáng và nhiều là việc biến một ý tưởng thành một phương pháp lặp lại được mà các đội có thể tin tưởng.
Mạng nơ-ron nhằm biến các đầu vào thô lộn xộn (pixels, sóng âm, token văn bản) thành các biểu diễn hữu ích—những đặc trưng nội bộ nắm bắt những gì quan trọng.
Thay vì kỹ sư thiết kế mọi đặc trưng bằng tay, mô hình học các lớp đặc trưng từ ví dụ, điều này thường bền vững hơn khi điều kiện thay đổi (ánh sáng, giọng, cách diễn đạt).
Backpropagation là một phương pháp huấn luyện giúp cải thiện mạng bằng cách học từ lỗi:
Nó thường hoạt động cùng với các thuật toán như gradient descent, tức là đi từng bước nhỏ xuống dốc lỗi theo thời gian.
Backprop giúp có thể điều chỉnh nhiều lớp cùng lúc theo một cách có hệ thống.
Điều này quan trọng vì mạng sâu có thể xây dựng hệ thống phân cấp đặc trưng (ví dụ: cạnh → hình dạng → đối tượng). Nếu không có cách huấn luyện đáng tin cậy cho nhiều lớp, sâu thường không mang lại lợi ích thực tế.
Boltzmann machines học bằng cách gán một năng lượng (một điểm số) cho toàn bộ cấu hình các nút; năng lượng thấp nghĩa là “cấu hình này hợp lý”.
Chúng có ảnh hưởng vì:
Ngày nay chúng ít được dùng trực tiếp trong sản phẩm vì huấn luyện truyền thống rất chậm để mở rộng.
Học biểu diễn có nghĩa là mô hình tự học các đặc trưng nội bộ giúp nhiệm vụ trở nên dễ hơn, thay vì dựa vào các đặc trưng do con người thiết kế.
Trong thực tế, điều này thường làm tăng độ bền: đặc trưng học được thích nghi với biến thể dữ liệu thật (nhiễu, các loại camera khác nhau, người nói khác nhau) tốt hơn các pipeline đặc trưng cứng nhắc do con người thiết kế.
Deep belief networks (DBNs) giúp làm cho mô hình sâu thực tế bằng cách huấn luyện từng lớp một.
Mỗi lớp trước tiên học cấu trúc trong đầu vào của nó (thường không cần nhãn), đem lại cho toàn bộ mạng một “khởi đầu ấm”. Sau đó toàn bộ chồng lớp được tinh chỉnh cho nhiệm vụ cụ thể như phân loại.
Dropout chống overfitting bằng cách ngẫu nhiên “tắt” một số đơn vị trong quá trình huấn luyện.
Điều này ngăn mô hình phụ thuộc quá nhiều vào một đường dẫn duy nhất và buộc nó học các đặc trưng vẫn có hiệu quả ngay cả khi một phần của mô hình bị thiếu—thường cải thiện khả năng tổng quát hóa trên dữ liệu mới, thực tế.
AlexNet cho thấy một công thức thực tế có thể mở rộng: mạng tích chập sâu + GPU + nhiều dữ liệu gán nhãn (ImageNet).
Nó không chỉ là “một mô hình lớn hơn”—mà chứng minh deep learning có thể nhất quán đánh bại các pipeline thị giác máy tính truyền thống trên một benchmark khó, công khai, điều này kích hoạt làn sóng đầu tư trong ngành.