27 thg 8, 2025·8 phút
Worker pool trong Go cho công việc nền: thử lại, hủy và dừng an toàn
Worker pool trong Go giúp đội nhỏ chạy công việc nền với retry, hủy và dừng sạch bằng các pattern đơn giản trước khi thêm hạ tầng nặng.
Tại sao công việc nền nhanh chóng trở nên lộn xộn
Trong một dịch vụ Go nhỏ, công việc nền thường bắt đầu với một mục tiêu đơn giản: trả HTTP response nhanh, rồi làm phần chậm sau. Đó có thể là gửi email, thay đổi kích thước ảnh, đồng bộ tới API khác, dựng lại chỉ mục tìm kiếm, hoặc chạy báo cáo hàng đêm.
Vấn đề là những job này là công việc sản xuất thực sự, chỉ là thiếu các hàng rào bạn có khi xử lý request. Một goroutine khởi từ HTTP handler có vẻ ổn cho tới khi deploy xảy ra giữa chừng, một API upstream chậm lại, hoặc cùng một request được retry khiến job chạy hai lần.
Các điểm đau đầu tiên thường dự đoán được:
- Job bị kẹt: một lần gọi treo, và các worker ngừng tiến triển.
- Trùng lặp công việc: retry ở tầng HTTP chạy lại cùng job.
- Không có kế hoạch tắt: process thoát và công việc bị mất hoặc dở dang.
- Lỗi im lặng: lỗi chỉ được log một lần (hoặc không bao giờ) rồi biến mất.
- Cơn bão retry: job lỗi retry ngay lập tức và làm quá tải phụ thuộc.
Đây là lúc một pattern nhỏ, rõ ràng như worker pool trong Go hữu ích. Nó biến concurrency thành một lựa chọn (N workers), biến “làm sau” thành một kiểu job rõ ràng, và cho bạn một chỗ để xử lý retry, timeout, và hủy.
Ví dụ: một ứng dụng SaaS cần gửi hóa đơn. Bạn không muốn 500 gửi đồng thời sau một import hàng loạt, và không muốn gửi lại cùng một hóa đơn chỉ vì request bị retry. Worker pool cho phép giới hạn throughput và coi “gửi hóa đơn #123” như một đơn vị công việc được theo dõi.
Worker pool không phải công cụ phù hợp khi bạn cần đảm bảo bền bỉ giữa các process. Nếu job phải sống sót qua crash, được lên lịch cho tương lai, hoặc được xử lý bởi nhiều service, bạn có thể cần một hàng đợi thực sự cộng với lưu trữ trạng thái job bền vững.
Mô hình worker pool nói đơn giản
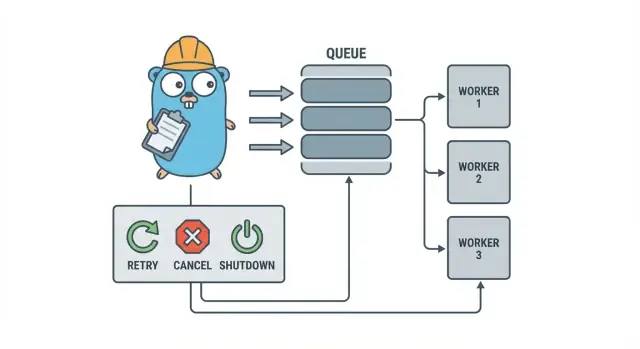
Worker pool trong Go là cố ý nhàm chán: bỏ công việc vào hàng đợi, có một tập worker cố định lấy công việc, và đảm bảo toàn bộ có thể dừng sạch.
Các thuật ngữ cơ bản:
- Job: một đơn vị công việc, như “thay đổi kích thước ảnh này” hoặc “gửi email hóa đơn này”.
- Queue: nơi job chờ.
- Worker: một goroutine lặp lại lấy job rồi chạy nó.
- Dispatcher: phần nhận job và đưa vào queue.
Trong nhiều thiết kế chạy trong tiến trình, một channel Go chính là queue. Channel có buffer có thể giữ một số job giới hạn trước khi producer bị block. Việc block đó là backpressure, và thường giúp dịch vụ bạn không nhận vô hạn công việc và hết bộ nhớ khi traffic tăng vọt.
Kích thước buffer thay đổi cảm nhận của hệ thống. Buffer nhỏ khiến áp lực hiện ra nhanh (caller phải chờ sớm hơn). Buffer lớn làm mượt các bùng phát ngắn nhưng có thể che dấu quá tải tới sau. Không có con số hoàn hảo, chỉ có con số phù hợp với mức độ chờ đợi bạn chấp nhận.
Bạn cũng chọn pool là cố định hay có thể thay đổi. Pool cố định dễ lý giải và giữ tài nguyên dự đoán được. Tự động tăng giảm worker giúp với tải không đều, nhưng thêm quyết định bạn phải duy trì (khi nào scale, tăng bao nhiêu, và khi nào giảm).
Cuối cùng, “ack” trong pool nội tiến trình thường chỉ có nghĩa là “worker hoàn thành job và không trả về lỗi.” Không có broker ngoài để xác nhận giao hàng, nên code của bạn định nghĩa “xong” nghĩa là gì và chuyện gì xảy ra khi job lỗi hoặc bị hủy.
Mục tiêu thiết kế: thử lại, hủy và dừng sạch
Worker pool về cơ khí là đơn giản: chạy số worker cố định, cung cấp job cho họ, và xử lý. Giá trị nằm ở kiểm soát: concurrency dự đoán được, xử lý lỗi rõ ràng, và đường dẫn shutdown không để lại công việc dở.
Ba mục tiêu giữ cho đội nhỏ tỉnh táo:
- Giới hạn concurrency để một cơn spike không làm tan chảy database hoặc API ngoài.
- Tránh mất công việc (hoặc ít nhất biết chính xác cái gì bị bỏ và vì sao).
- Dễ gỡ lỗi: mỗi job nên có thể truy vết qua logs và vài bộ đếm.
Đa số lỗi là bình thường, nhưng bạn vẫn muốn phân biệt:
- Lỗi tạm thời (mạng chập chờn, giới hạn tần suất) nên được retry.
- Lỗi vĩnh viễn (input sai, bản ghi thiếu) không nên retry.
- Timeout (phụ thuộc treo) phải bị cắt để worker không bị nghẽn.
Hủy không giống với “lỗi”. Đó là một quyết định: người dùng hủy, deploy thay process, hoặc service đang tắt. Trong Go, xem hủy là tín hiệu quan trọng bằng cách dùng context cancellation, và đảm bảo mỗi job kiểm tra nó trước khi bắt đầu phần tốn kém và ở vài điểm an toàn trong khi thực thi.
Dừng sạch là nơi nhiều pool vỡ vụn. Hãy quyết định sớm “an toàn” nghĩa là gì cho job của bạn: bạn có hoàn tất công việc đang chạy không, hay dừng nhanh và chạy lại sau? Một flow thực tế là:
- Dừng nhận job mới.
- Bảo worker dừng sau job hiện tại (hoặc dừng ngay).
- Chờ tới một deadline, rồi ép thoát.
Nếu bạn định nghĩa những quy tắc này sớm, retry, hủy và shutdown sẽ nhỏ và dự đoán được thay vì biến thành một framework tự chế lớn.
Từng bước: xây một worker pool cơ bản
Worker pool chỉ là một nhóm goroutine kéo job từ channel và làm việc. Phần quan trọng là khiến các cơ bản dự đoán được: job trông như thế nào, worker dừng ra sao, và làm sao biết khi nào tất cả công việc đã xong.
Bắt đầu với một kiểu Job đơn giản. Cho nó một ID (để log), payload (cái cần xử lý), bộ đếm attempt (hữu ích cho retry), dấu thời gian, và chỗ chứa dữ liệu context theo job.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Một vài lựa chọn thực tế bạn sẽ phải đưa ra ngay:
- Chọn kích thước queue dựa trên mức chờ bạn chấp nhận.
- Quyết định backpressure nghĩa là gì với caller: block, trả lỗi, hay drop.
- Giữ
Stop()vàWait()tách biệt để bạn có thể dừng intake trước, rồi đợi công việc đang chạy xong.
Thêm retry nhưng không biến thành framework
Retry hữu ích, nhưng cũng là nơi worker pool trở nên lộn xộn. Giữ mục tiêu hẹp: chỉ retry khi lần thử tiếp theo có cơ hội thành công thực sự, và dừng nhanh khi không.
Bắt đầu bằng việc quyết định cái gì có thể retry. Vấn đề tạm thời (mạng chập chờn, timeout, response "thử lại sau") thường nên retry. Vấn đề vĩnh viễn (input sai, bản ghi thiếu, từ chối quyền) thì không.
Chính sách retry nhỏ thường là đủ:
- Đánh dấu lỗi là retryable hay không (ví dụ, bọc lỗi với helper
Retryable(err)). - Đặt số lần thử tối đa (thường 3 đến 5). Qua đó thường là phí thời gian.
- Dùng exponential backoff với jitter để job không retry đồng bộ.
- Giới hạn delay (ví dụ, không sleep quá 30 giây).
- Log retry kèm số lần thử, delay tiếp theo, và job ID.
Backoff không cần phức tạp. Hình dạng phổ biến: delay = min(base * 2^(attempt-1), max), sau đó thêm jitter (ngẫu nhiên +/- 20%). Jitter quan trọng vì nếu không, nhiều worker thất bại cùng lúc và retry cùng lúc.
Delay nên nằm ở đâu? Với hệ thống nhỏ, sleep bên trong worker ổn, nhưng chiếm một slot worker. Nếu retry hiếm, điều đó chấp nhận được. Nếu retry phổ biến hoặc delay dài, cân nhắc re-enqueue job với timestamp "chạy sau" để worker vẫn bận với công việc khác.
Khi thất bại cuối cùng xảy ra, hãy rõ ràng. Lưu job thất bại (và lỗi cuối), log đủ context để replay, hoặc đẩy vào danh sách dead bạn kiểm tra định kỳ. Tránh drop im lặng. Một pool che giấu lỗi còn tệ hơn không có retry.
Hủy và timeout thật sự dừng công việc
Generate a worker pool starter
Describe your jobs and get a Go + PostgreSQL scaffold to start fast.
Worker pool chỉ an toàn khi bạn có thể dừng chúng. Quy tắc đơn giản nhất: truyền context.Context qua mọi layer có thể block. Điều đó nghĩa là submit, thực thi, và cleanup.
Một setup thực tế dùng hai giới hạn thời gian:
- Một timeout mỗi job để một task không chiếm worker mãi mãi.
- Một timeout shutdown để process có thể exit ngay cả khi vài job không hợp tác.
Dùng context đầu cuối
Cho mỗi job context riêng phát sinh từ context của worker. Rồi mọi gọi chậm (DB, HTTP, queues, I/O file) phải dùng context đó để có thể return sớm.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Nếu Run gọi DB hoặc API, truyền context vào những gọi đó (ví dụ QueryContext, NewRequestWithContext, hoặc các phương thức client chấp nhận context). Nếu bạn bỏ qua ở chỗ nào đó, hủy sẽ chỉ là “nỗ lực tốt nhất” và thường thất bại khi bạn cần nhất.
Công việc dở dang và các bước "an toàn khi retry"
Hủy có thể xảy ra giữa chừng, nên coi công việc dở dang là bình thường. Hướng đến các bước idempotent để chạy lại không tạo duplicate. Các cách thường gặp: dùng key duy nhất cho insert (hoặc upsert), viết marker tiến trình (started/done), lưu kết quả trước khi tiếp tục, và kiểm tra ctx.Err() giữa các bước.
Xem shutdown như một deadline: dừng nhận job mới, cancel context của worker, và chờ tối đa timeout shutdown cho công việc đang chạy kết thúc.
Dừng sạch: làm gì khi process phải thoát
Dừng sạch có một mục tiêu: dừng nhận việc mới, báo công việc đang chạy dừng, và thoát mà không để hệ thống ở trạng thái lạ.
Bắt đầu với signal. Trong hầu hết môi trường bạn sẽ thấy SIGINT cục bộ và SIGTERM từ process manager hoặc container runtime. Dùng một shutdown context bị cancel khi signal đến, và truyền nó vào pool và handler job.
Tiếp theo, dừng nhận job mới. Đừng để caller block mãi cố gắng submit vào channel không còn người đọc. Giữ việc submit phía sau một hàm duy nhất kiểm tra flag đã đóng hoặc chọn trên shutdown context trước khi gửi.
Rồi quyết định chuyện với công việc đang queued:
- Drain: hoàn tất cái đã queued, nhưng từ chối submit mới.
- Drop: loại bỏ mọi thứ chưa bắt đầu.
Drain an toàn hơn cho thanh toán và email. Drop hợp lý cho tác vụ “đẹp thì có” như tính lại cache.
Chuỗi shutdown thực tế:
- Bắt SIGINT/SIGTERM và cancel một shared context.
- Dừng submit (close đường submit, không nhất thiết đóng channel work ngay lập tức).
- Cho worker hoàn thành hoặc abort dựa trên context.
- Đợi worker bằng WaitGroup.
- Ép deadline, rồi exit.
Deadline quan trọng. Ví dụ, cho job đang chạy 10 giây để dừng. Sau đó log cái còn chạy và exit. Điều này giữ deploy dự đoán được và tránh process bị kẹt.
Logging và các metrics đơn giản cho worker pool
Add logging and basic metrics
Generate logs and a few counters to track queue depth, latency, and failures.
Khi worker pool hỏng, hiếm khi nó vỡ to. Job chậm lại, retry chồng chất, và ai đó báo là “không có gì xảy ra”. Logging và vài bộ đếm cơ bản biến câu chuyện đó thành hình ảnh rõ ràng.
Cho mỗi job một ID ổn định (hoặc sinh khi submit) và đưa nó vào mọi dòng log. Giữ log nhất quán: một dòng khi job bắt đầu, một khi kết thúc, và một khi lỗi. Nếu retry, log số attempt và delay tiếp theo.
Một dạng log đơn giản:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Metrics có thể rất tối giản nhưng vẫn hữu ích. Theo dõi độ dài queue, số job đang chạy, tổng success và failure, và latency job (ít nhất trung bình và max). Nếu queue length liên tục tăng và in-flight luôn đạt worker count, bạn bị saturate. Nếu submitter block khi gửi vào channel jobs, backpressure đã đến caller. Điều đó không luôn xấu, nhưng nên là có chủ đích.
Khi “job bị kẹt”, kiểm tra xem process vẫn nhận job không, độ dài queue có tăng không, worker có còn alive không, và job nào chạy lâu nhất. Thời gian chạy dài thường do thiếu timeout, phụ thuộc chậm, hoặc vòng retry vô hạn.
Ví dụ thực tế: hàng đợi nền cho một SaaS nhỏ
Hãy tưởng tượng một SaaS nhỏ nơi một đơn hàng chuyển sang trạng thái PAID. Ngay sau thanh toán, bạn cần gửi PDF hóa đơn, email khách, và thông báo cho đội nội bộ. Bạn không muốn việc đó block web request. Đây là fit tốt cho worker pool vì công việc thực sự quan trọng nhưng hệ thống còn nhỏ.
Payload job có thể tối giản: đủ để lấy phần còn lại từ DB. Handler API ghi một dòng như jobs(status='queued', type='send_invoice', payload, attempts=0) trong cùng transaction với update order, rồi một vòng nền poll các job queued và đẩy vào channel worker.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Khi worker lấy job, đường đi thuận lợi là: load order, generate invoice, gọi nhà cung cấp email, rồi đánh dấu job xong.
Retry là lúc mọi thứ thực sự quan trọng. Nếu nhà cung cấp email gặp outage tạm thời, bạn không muốn 1.000 job fail mãi hoặc búa tới nhà cung cấp mỗi giây. Cách thực tế:
- Xem lỗi mạng và response 5xx là retryable.
- Dùng exponential backoff với max delay (ví dụ 5s, 15s, 45s, 2m).
- Giới hạn attempts (ví dụ 10) rồi đánh dấu job failed.
- Lưu lỗi cuối để support biết chuyện gì xảy ra.
Trong outage, job di chuyển từ queued sang in_progress, rồi quay lại queued với run time trong tương lai. Khi nhà cung cấp trở lại, worker tự nhiên drain backlog.
Giờ tưởng tượng deploy. Bạn gửi SIGTERM. Process nên dừng nhận việc mới nhưng hoàn tất những gì đang chạy. Dừng poll, dừng đẩy vào channel worker, và đợi worker với deadline. Job hoàn thành thì đánh dấu done. Job còn chạy khi deadline hết nên đánh dấu lại queued (hoặc để in_progress với một watchdog) để được nhặt sau khi phiên bản mới khởi.
Sai lầm phổ biến và bẫy
Hầu hết bug trong xử lý nền không nằm ở logic job. Chúng đến từ sai phối hợp chỉ hiện dưới tải cao hoặc khi shutdown.
Một bẫy kinh điển là đóng channel từ nhiều nơi. Kết quả là panic khó tái hiện. Chọn một owner cho mỗi channel (thường là producer), và chỉ nó gọi close(jobs).
Retry là khu vực khác nơi ý định tốt gây outage. Nếu bạn retry mọi thứ, bạn sẽ retry cả lỗi vĩnh viễn. Điều đó lãng phí thời gian, tăng tải, và biến vấn đề nhỏ thành sự cố. Phân loại lỗi và giới hạn retry với chính sách rõ ràng.
Trùng lặp sẽ xảy ra ngay cả với thiết kế cẩn thận. Worker crash giữa chừng, timeout firing sau khi công việc đã xong, hoặc bạn requeue trong khi deploy. Nếu job không idempotent, duplicate gây hậu quả: hai hóa đơn, hai email chào mừng, hai hoàn tiền.
Những sai lầm hay gặp nhất:
- Đóng cùng một channel từ nhiều goroutine.
- Retry lỗi vĩnh viễn thay vì đưa ra mặt.
- Không có idempotency key, nên duplicates gây side effect đôi.
- Queue trong bộ nhớ không giới hạn tăng tới khi bộ nhớ tăng vọt.
- Bỏ qua
context.Context, nên công việc tiếp tục sau khi bắt đầu shutdown.
Queue không giới hạn đặc biệt khó phát hiện. Một spike công việc có thể âm thầm chất đống trong RAM. Ưu tiên channel có buffer giới hạn và quyết định chuyện gì xảy ra khi nó đầy: block, drop, hay trả lỗi.
Checklist nhanh trước khi đưa vào production
Prototype an invoice job pipeline
Generate the paid-to-invoice pipeline and background worker loop from a single spec.
Trước khi đưa worker pool vào production, bạn nên mô tả được lifecycle job thành lời. Nếu ai đó hỏi “job này đang ở đâu bây giờ?”, câu trả lời không nên là đoán mò.
Checklist thực tế trước chạy:
- Bạn có thể gọi tên mỗi trạng thái và chuyển đổi: queued, picked up, running, finished, failed (và cái gì di chuyển giữa chúng).
- Concurrency là một nút duy nhất (như
workerCount), và thay đổi nó không cần viết lại code. - Retry có giới hạn: max attempts rõ ràng, backoff tăng dần, và lỗi vĩnh viễn đi tới nơi có chủ ý.
- Hành vi shutdown đã được chứng minh: dừng intake, cho in-flight hoàn thành, và vẫn có hard timeout.
- Logs trả lời cơ bản: job ID, số attempt, duration, và lý do lỗi.
Làm một drill thực tế trước release: enqueue 100 job “send receipt email”, ép 20 cái fail, rồi restart service giữa chừng. Bạn nên thấy retry chạy như mong đợi, không có duplicate side effect, và hủy thực sự dừng công việc khi deadline tới.
Nếu mục nào mơ hồ, siết chặt nó ngay. Sửa nhỏ giờ đây tiết kiệm ngày sau.
Bước tiếp theo: khi nào thêm hạ tầng nặng hơn (và khi nào không)
Một in-process pool đơn giản thường đủ khi sản phẩm còn trẻ. Nếu job là “đẹp thì có” (gửi email, refresh cache, generate report) và bạn có thể chạy lại chúng, worker pool giữ hệ thống dễ hiểu.
Dấu hiệu bạn đã vượt quá khả năng pool nội tiến trình
Để ý các điểm sau:
- Bạn chạy nhiều instance app và chỉ muốn một trong số đó lấy job.
- Bạn cần độ bền (job phải sống sót qua crash và deploy).
- Bạn cần audit trail: ai queue cái gì, khi nào chạy, và kết quả chính xác.
- Bạn cần kiểm soát backpressure giữa các service, không chỉ trong một process.
- Bạn cần lịch trình nghiêm ngặt hoặc delay dài (giờ hoặc ngày) với wake-up đáng tin.
Nếu không có điều nào đúng, công cụ nặng hơn có thể thêm quá nhiều phần chuyển động mà không tăng giá trị.
Di chuyển dần dần mà không rewrite
Tấm chắn tốt nhất là interface job ổn định: payload nhỏ, ID, và handler trả về kết quả rõ ràng. Khi đó bạn có thể đổi backend queue sau này (từ in-memory channel sang bảng database, rồi sang queue chuyên dụng) mà không đổi business code.
Một bước trung gian thực tế là một service Go nhỏ đọc job từ PostgreSQL, claim chúng bằng lock, và cập nhật trạng thái. Bạn có được độ bền và audit cơ bản trong khi giữ logic worker giống nhau.
Nếu muốn prototype nhanh, Koder.ai (koder.ai) có thể tạo starter Go + PostgreSQL từ prompt chat, gồm bảng background jobs và vòng worker, và snapshot cùng rollback của nó có thể hữu ích khi tune retry và shutdown behavior.