12 thg 9, 2025·8 phút
Gói khởi đầu observability cho giám sát ngày đầu trên production
Gói khởi đầu observability cho production ngày đầu: những logs, metrics và traces tối thiểu cần thêm, cùng một luồng triage đơn giản cho các báo cáo “nó chậm”.
Gói khởi đầu observability cho production ngày đầu: những logs, metrics và traces tối thiểu cần thêm, cùng một luồng triage đơn giản cho các báo cáo “nó chậm”.
Thứ hỏng đầu tiên hiếm khi là toàn bộ app. Thường là một bước bất ngờ bận, một truy vấn vốn ổn trong test, hoặc một dependency bắt đầu timeout. Người dùng thật mang đủ loại biến thể: điện thoại chậm hơn, mạng chập chờn, input kỳ lạ, và spike traffic vào lúc không tiện.
Khi ai đó nói “nó chậm”, họ có thể muốn nói nhiều thứ khác nhau. Trang có thể tải chậm, tương tác bị giật, một cuộc gọi API timeout, job nền tích tụ, hoặc một dịch vụ bên thứ ba kéo mọi thứ xuống.
Vì vậy bạn cần tín hiệu trước khi cần dashboard. Ngày đầu, bạn không cần biểu đồ hoàn hảo cho mọi endpoint. Bạn cần đủ logs, metrics và traces để trả lời một câu nhanh: thời gian đang đi đâu?
Cũng có rủi ro thực khi instrument quá sớm. Quá nhiều sự kiện tạo ra tiếng ồn, tốn tiền, và có thể làm app chậm hơn. Tệ hơn, teams ngừng tin vào telemetry vì nó lộn xộn và không đồng nhất.
Mục tiêu thực tế cho ngày đầu đơn giản: khi nhận báo cáo “nó chậm”, bạn có thể tìm ra bước chậm trong dưới 15 phút. Bạn nên biết cổ chai là ở client rendering, handler API và các dependency của nó, database hoặc cache, hay worker nền/ dịch vụ bên ngoài.
Ví dụ: flow thanh toán mới có cảm giác chậm. Ngay cả khi không có đống công cụ, bạn vẫn muốn có thể nói, “95% thời gian là ở cuộc gọi nhà cung cấp thanh toán,” hoặc “truy vấn cart đang quét quá nhiều hàng.” Nếu bạn build app nhanh với công cụ như Koder.ai, baseline ngày đầu này càng quan trọng, vì tốc độ shipping chỉ có ích khi bạn debug cũng nhanh.
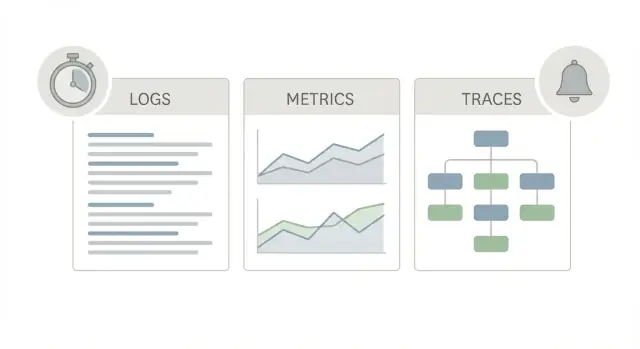
Một gói observability production tốt dùng ba “góc nhìn” khác nhau của cùng một app, vì mỗi cái trả lời một câu khác nhau.
Logs là câu chuyện. Chúng kể những gì đã xảy ra cho một request, một user, hoặc một job nền. Một dòng log có thể nói “payment failed for order 123” hoặc “DB timeout after 2s,” cùng các chi tiết như request ID, user ID, và thông báo lỗi. Khi ai đó báo một sự cố lẻ tẻ, logs thường là cách nhanh nhất để xác nhận nó đã xảy ra và ai bị ảnh hưởng.
Metrics là bảng điểm. Chúng là số bạn có thể theo dõi và đặt cảnh báo: tần suất request, tỉ lệ lỗi, phân vị latency, CPU, độ sâu queue. Metrics cho bạn biết điều gì là hiếm hay phổ biến, và có đang xấu đi không. Nếu latency nhảy cho mọi người lúc 10:05, metrics sẽ hiện ra.
Traces là bản đồ. Một trace theo dõi một request khi nó đi qua hệ thống của bạn (web -> API -> database -> third-party). Nó cho thấy thời gian được dành ở đâu, từng bước một. Điều này quan trọng vì “nó chậm” hiếm khi là một bí ẩn lớn duy nhất. Thường là một hop chậm.
Trong sự cố, một luồng thực tế trông như sau:
Một quy tắc đơn giản: nếu vài phút sau bạn vẫn không chỉ ra được một cổ chai, bạn không cần thêm alert. Bạn cần traces tốt hơn, và ID nhất quán để nối traces với logs.
Hầu hết sự cố “không tìm ra” không phải do thiếu data. Chúng xảy ra vì cùng một thứ được ghi khác nhau giữa các dịch vụ. Một vài quy ước chung vào ngày đầu giúp logs, metrics và traces khớp nhau khi bạn cần câu trả lời nhanh.
Bắt đầu bằng việc chọn một tên service cho mỗi đơn vị deploy và giữ nó ổn định. Nếu “checkout-api” thành “checkout” trên một nửa dashboard, bạn mất lịch sử và cảnh báo bị phá vỡ. Làm tương tự cho label môi trường. Chọn một bộ nhỏ như prod và staging, và dùng nó ở mọi nơi.
Tiếp theo, làm cho mỗi request dễ theo dõi. Sinh một request ID ở edge (API gateway, web server, hoặc handler đầu tiên) và truyền nó qua các cuộc gọi HTTP, message queue, và job nền. Nếu một ticket support nói “nó chậm lúc 10:42,” một ID duy nhất cho phép bạn kéo đúng logs và trace mà không đoán mò.
Một bộ quy ước phù hợp ngày đầu:
Đồng ý về đơn vị thời gian sớm. Chọn milliseconds cho latency API và seconds cho job dài hơn, rồi giữ nguyên. Đơn vị hỗn hợp tạo ra biểu đồ trông ổn nhưng kể câu chuyện sai.
Ví dụ cụ thể: nếu mỗi API log duration_ms, route, status, và request_id, thì một báo cáo như “checkout chậm cho tenant 418” trở thành một filter nhanh, không phải cuộc tranh luận về điểm bắt đầu.
Nếu chỉ làm một việc trong gói observability production, hãy làm logs dễ tìm kiếm. Bắt đầu bằng logs cấu trúc (thường JSON) và cùng các trường giữa mọi service. Logs plain-text ổn cho dev local, nhưng nhanh chóng trở thành tiếng ồn khi có traffic thật, retry, và nhiều instance.
Một quy tắc tốt: log những gì bạn thực sự sẽ dùng trong sự cố. Hầu hết team cần trả lời: Đây là request nào? Ai thực hiện? Nó hỏng ở đâu? Nó chạm vào gì? Nếu một dòng log không giúp với một trong những câu đó, có lẽ không nên tồn tại.
Ngày đầu, giữ một tập trường nhỏ, nhất quán để bạn có thể lọc và join event giữa các service:
Khi lỗi xảy ra, log nó một lần, có ngữ cảnh. Bao gồm error type (hoặc code), message ngắn, stack trace cho lỗi server, và dependency upstream liên quan (ví dụ: postgres, payment provider, cache). Tránh lặp cùng stack trace trên mỗi retry. Thay vào đó, gắn request_id để bạn có thể theo chuỗi.
Ví dụ: user báo không lưu được settings. Một lần tìm bằng request_id cho thấy 500 trên PATCH /settings, rồi timeout tới Postgres với duration_ms. Bạn không cần payload đầy đủ, chỉ route, user/session, và tên dependency.
Quyền riêng tư là một phần của logging, không phải việc để sau. Đừng log mật khẩu, token, header auth, body request đầy đủ, hoặc PII nhạy cảm. Nếu cần định danh user, log một ID ổn định (hoặc giá trị băm) thay vì email hay số điện thoại.
Nếu bạn build app trên Koder.ai (React, Go, Flutter), nên tích hợp sẵn những trường này vào mọi service sinh ra từ đầu để không phải “sửa logging” trong sự cố đầu tiên.
Một gói observability production tốt bắt đầu với một tập nhỏ metric trả lời nhanh một câu: hệ thống có khỏe ngay lúc này không, nếu không thì phần nào đang đau?
Hầu hết vấn đề production xuất hiện như bốn “tín hiệu vàng”: latency (phản hồi chậm), traffic (tải thay đổi), errors (thất bại), và saturation (tài nguyên chung bị đầy). Nếu bạn thấy bốn tín hiệu này cho từng phần chính của app, bạn có thể phân loại hầu hết sự cố mà không đoán mò.
Latency nên là các phân vị, không phải trung bình. Theo dõi p50, p95 và p99 để thấy khi một nhóm nhỏ user có trải nghiệm tệ. Với traffic, bắt đầu bằng requests per second (hoặc jobs per minute cho worker). Với lỗi, tách 4xx vs 5xx: 4xx tăng thường là thay đổi hành vi client hoặc validation; 5xx tăng chỉ tới app hoặc dependency của bạn. Saturation là tín hiệu “chúng ta sắp hết thứ gì đó” (CPU, memory, connection DB, backlog queue).
Tập tối thiểu bao phủ hầu hết app:
Ví dụ cụ thể: nếu user báo “nó chậm” và API p95 latency tăng trong khi traffic giữ ngang, kiểm tra saturation tiếp. Nếu sử dụng pool DB chạm ngưỡng max và timeout tăng, bạn tìm được nút thắt. Nếu DB ổn nhưng độ sâu queue tăng nhanh, công việc nền có thể đang chiếm tài nguyên chung.
Nếu bạn build app trên Koder.ai, coi checklist này như phần của tiêu chí “xong ngày một”. Dễ thêm metric lúc app nhỏ hơn là giữa một sự cố thật.
Khi user nói “nó chậm”, logs thường cho biết chuyện gì xảy ra, metrics cho biết tần suất. Traces cho biết thời gian đi đâu trong một request. Timeline đó biến một than phiền mơ hồ thành hướng sửa rõ ràng.
Bắt đầu ở phía server. Instrument request inbound ở edge của app (handler đầu tiên nhận request) để mỗi request có thể tạo một trace. Tracing phía client có thể chờ.
Một trace ngày đầu tốt có các span tương ứng với các phần thường gây chậm:
Để traces dễ tìm và so sánh, capture vài thuộc tính then chốt và giữ nhất quán giữa dịch vụ.
Với span inbound request, ghi route (dùng template như /orders/:id, không dùng full URL), HTTP method, status code, và latency. Với span database, ghi hệ quản trị DB (PostgreSQL, MySQL), loại thao tác (select, update), và tên bảng nếu dễ thêm. Với external call, ghi tên dependency (payments, email, maps), host đích, và status.
Sampling quan trọng ngày đầu, nếu không chi phí và tiếng ồn sẽ tăng nhanh. Dùng quy tắc head-based đơn giản: trace 100% lỗi và request chậm (nếu SDK hỗ trợ), và sample một phần nhỏ traffic bình thường (khoảng 1-10%). Bắt đầu cao hơn khi traffic thấp rồi giảm theo thời gian.
“Good” là một trace bạn có thể đọc câu chuyện từ trên xuống. Ví dụ: GET /checkout mất 2.4s, DB 120ms, cache 10ms, và cuộc gọi thanh toán ngoài mất 2.1s với retry. Giờ bạn biết vấn đề là dependency, không phải code của bạn. Đây là cốt lõi của gói khởi động observability production.
Khi ai đó nói “nó chậm”, chiến thắng nhanh nhất là biến cảm giác mơ hồ thành vài câu hỏi cụ thể. Luồng phân loại trong gói này hoạt động ngay cả khi app của bạn mới tinh.
Bắt đầu thu hẹp vấn đề, rồi theo bằng chứng theo thứ tự. Đừng nhảy thẳng vào database.
Sau khi ổn định, làm một cải tiến nhỏ: ghi lại những gì đã xảy ra và thêm một tín hiệu thiếu. Ví dụ, nếu bạn không biết chậm chỉ ở một vùng, thêm tag region vào metric latency. Nếu thấy span DB dài mà không biết truy vấn nào, thêm nhãn query cẩn trọng, hoặc một trường “query name”.
Ví dụ nhanh: nếu checkout p95 từ 400 ms lên 3 s và traces cho thấy span payment kéo 2.4 s, bạn có thể dừng việc nghi ngờ code và tập vào provider, retry, và timeouts.
Khi ai đó nói “nó chậm”, bạn có thể lãng phí một giờ chỉ để hiểu họ muốn nói gì. Gói observability production chỉ hữu ích nếu giúp bạn thu hẹp vấn đề nhanh.
Bắt đầu với ba câu hỏi làm rõ:
Rồi xem vài con số thường chỉ đường tiếp theo. Đừng đi tìm dashboard hoàn hảo. Bạn chỉ cần tín hiệu “tệ hơn bình thường”.
Nếu p95 tăng mà lỗi ổn, mở một trace cho route chậm trong 15 phút gần nhất. Một trace đơn thường cho biết thời gian nằm ở DB, gọi API ngoài, hay chờ lock.
Rồi làm một tìm kiếm log. Nếu có báo cáo user cụ thể, tìm theo request_id (hoặc correlation ID) và đọc timeline. Nếu không, tìm thông báo lỗi phổ biến trong cùng khung thời gian và xem có khớp với sự cố không.
Cuối cùng, quyết định là giảm nhẹ ngay hay điều tra sâu hơn. Nếu user bị block và bão hòa cao, một biện pháp nhanh (scale up, rollback, hoặc tắt feature không cần thiết) mua thời gian. Nếu tác động nhỏ và hệ thống ổn định, tiếp tục điều tra với traces và slow query logs.
Vài giờ sau release, support bắt đầu nhận ticket: “Checkout mất 20 đến 30 giây.” Không ai tái hiện được trên laptop, nên bắt đầu đoán mò. Đây là lúc gói observability trả lại giá trị.
Đầu tiên, vào metrics và xác nhận triệu chứng. Biểu đồ p95 latency cho HTTP requests hiện spike rõ, nhưng chỉ cho POST /checkout. Các route khác bình thường, tỉ lệ lỗi giữ ngang. Điều đó thu hẹp từ “cả site chậm” xuống “một endpoint chậm sau release”.
Tiếp theo, mở một trace cho request POST /checkout chậm. Thác trace làm thủ phạm hiển nhiên. Hai kết quả phổ biến:
Bây giờ xác thực với logs, dùng cùng request_id từ trace (hoặc trace_id nếu bạn lưu nó trong logs). Trong logs của request đó, bạn thấy cảnh báo lặp như “payment timeout reached” hoặc “context deadline exceeded,” cùng các retry được thêm trong release mới. Nếu thuộc đường DB, logs có thể hiển thị message chờ lock hoặc câu truy vấn chậm vượt ngưỡng.
Khi cả ba tín hiệu khớp, cách sửa trở nên rõ ràng:
Điểm mấu chốt là bạn không phải mò. Metrics chỉ ra endpoint, traces chỉ ra bước chậm, và logs xác nhận chế độ lỗi với request cụ thể.
Phần lớn thời gian sự cố bị mất vào những khoảng trống có thể tránh: dữ liệu có nhưng ồn, rủi ro, hoặc thiếu một chi tiết để nối triệu chứng với nguyên nhân. Gói observability chỉ hữu dụng nếu nó vẫn dùng được khi chịu áp lực.
Một bẫy phổ biến là log quá nhiều, đặc biệt là body request thô. Nghe có vẻ hữu ích cho tới khi bạn phải trả chi phí lưu trữ lớn, tìm kiếm chậm, và vô tình lưu mật khẩu, token, hoặc dữ liệu cá nhân. Ưu tiên trường cấu trúc (route, status code, latency, request_id) và chỉ log những phần input nhỏ được phép rõ ràng.
Một lãng phí thời gian khác là metric trông chi tiết nhưng không thể tổng hợp. Label có độ phân giải cao như full user IDs, email, hoặc số đơn có thể nở series metric và làm dashboard không đáng tin. Dùng label thô hơn (tên route, HTTP method, lớp status, tên dependency), và giữ thông tin user-specific trong logs.
Những sai lầm thường xuyên chặn chẩn đoán nhanh:
Ví dụ nhỏ: nếu checkout p95 từ 800ms lên 4s, bạn muốn trả lời hai câu trong vài phút: có bắt đầu ngay sau deploy không, và thời gian nằm trong app hay dependency (DB, payment, cache)? Với percentiles, tag release, và traces có route + tên dependency, bạn đến đó nhanh. Không có chúng, bạn lãng phí thời gian tranh luận.
Chiến thắng thật sự là tính nhất quán. Gói observability chỉ hữu ích nếu mọi service mới đều khởi chạy với những cơ bản giống nhau, đặt tên giống nhau, và dễ tìm khi có sự cố.
Biến lựa chọn ngày đầu của bạn thành một template ngắn team có thể tái sử dụng. Giữ nhỏ, nhưng cụ thể.
Tạo một “home” view mà ai cũng có thể mở khi có sự cố. Một màn hình nên hiển thị requests per minute, tỉ lệ lỗi, p95 latency, và metric bão hòa chính của bạn, với bộ lọc environment và version.
Giữ cảnh báo tối thiểu ban đầu. Hai cảnh báo che được nhiều: spike tỉ lệ lỗi trên route chính, và spike p95 latency trên cùng route. Nếu thêm nữa, đảm bảo mỗi cảnh báo có hành động rõ ràng.
Cuối cùng, đặt review định kỳ hàng tháng. Loại bỏ alert ồn, thắt chặt đặt tên, và thêm một tín hiệu thiếu mà lẽ ra đã cứu thời gian trong sự cố trước.
Để nhúng điều này vào quy trình build, thêm một “cổng observability” vào checklist release: không deploy nếu thiếu request IDs, version tags, home view, và hai cảnh báo cơ bản. Nếu bạn ship với Koder.ai, bạn có thể định nghĩa các tín hiệu ngày một trong chế độ planning trước khi deploy, rồi lặp an toàn bằng snapshot và rollback khi cần điều chỉnh nhanh.
Bắt đầu từ nơi người dùng vào hệ thống: web server, API gateway, hoặc handler đầu tiên.
request_id và truyền nó qua mọi cuộc gọi nội bộ.route, method, status, và duration_ms cho mỗi request.Chỉ vậy thôi thường giúp bạn nhanh chóng khoanh vùng endpoint và khung thời gian cụ thể.
Hướng đến mục tiêu mặc định này: bạn có thể xác định bước chậm trong dưới 15 phút.
Bạn không cần dashboard hoàn hảo ngày đầu. Bạn cần đủ tín hiệu để trả lời:
Dùng cả ba vì mỗi loại trả lời câu hỏi khác nhau:
Trong sự cố: xác nhận tác động bằng metrics, tìm cổ chai bằng traces, giải thích bằng logs.
Chọn vài quy ước nhỏ và áp dụng khắp nơi:
Ưu tiên structured logs (thường JSON) với cùng khóa ở mọi nơi.
Các trường tối thiểu mang lại giá trị ngay:
Bắt đầu với bốn “golden signals” cho mỗi phần chính:
Rồi thêm một checklist nhỏ theo thành phần:
Bắt đầu ở phía server. Instrument request vào tại edge của app để mỗi request có thể tạo trace.
Một trace ngày đầu hữu dụng có spans cho những phần thường gây chậm:
Để traces dễ tìm, gắn một vài thuộc tính nhất quán: route (dạng template), HTTP method, status code, latency, tên dependency (payments, postgres, cache).
Một mặc định đơn giản và an toàn:
Bắt đầu với tỉ lệ cao hơn khi traffic nhỏ, rồi giảm khi khối lượng tăng.
Mục tiêu là giữ traces hữu dụng mà không làm chi phí hay tiếng ồn tăng vọt, và vẫn có đủ ví dụ về đường đi chậm để chẩn đoán.
Dùng một luồng lặp lại theo bằng chứng:
Những sai lầm này tốn thời gian (và đôi khi tiền):
service_name, environment (ví dụ prod/staging) và version ổn địnhrequest_id sinh ở edge và lan truyền qua các cuộc gọi và jobroute, method, status_code, và tenant_id (nếu đa tenant)duration_ms)Mục tiêu là một bộ lọc có thể dùng xuyên dịch vụ thay vì phải bắt đầu lại mỗi lần.
timestamp, level, service_name, environment, versionrequest_id (và trace_id nếu có)route, method, status_code, duration_msuser_id hoặc session_id (một ID ổn định, không phải email)Log lỗi một lần với ngữ cảnh (loại/lỗi + message + tên dependency). Tránh lặp stack trace cùng một request trên mọi retry.
Sampling ngày đầu: trace 100% lỗi và request chậm (nếu SDK hỗ trợ), sample 1–10% traffic bình thường. Bắt đầu cao hơn khi traffic thấp rồi giảm khi lớn dần.
Ghi lại một tín hiệu thiếu đã làm chậm quá trình và thêm nó lần sau.
Giữ đơn giản: ID ổn định, percentiles, tên dependency rõ ràng, và tag version ở mọi nơi.