14 thg 10, 2025·8 phút
GraphQL là gì? Hướng dẫn rõ ràng về API và lấy dữ liệu
Tìm hiểu GraphQL là gì, cách truy vấn, mutation và schema hoạt động, khi nào nên dùng thay vì REST — kèm ưu/nhược điểm và ví dụ thực tế.
GraphQL là gì (và không phải là gì)
GraphQL là một ngôn ngữ truy vấn và runtime cho APIs. Nói ngắn gọn: đó là cách để một app (web, di động, hoặc dịch vụ khác) yêu cầu dữ liệu từ API bằng một yêu cầu rõ ràng, có cấu trúc — và server trả về phản hồi khớp với yêu cầu đó.
Vấn đề nó giải quyết
Nhiều API buộc client phải chấp nhận những gì endpoint cố định trả về. Điều này thường dẫn đến hai vấn đề:
- Lấy thừa (over-fetching): tải về những trường bạn không dùng.
- Lấy thiếu (under-fetching): phải gửi nhiều yêu cầu để ghép thành một màn hình.
Với GraphQL, client có thể yêu cầu chính xác các trường cần thiết, không hơn không kém. Điều này đặc biệt hữu ích khi các màn hình khác nhau (hoặc các app khác nhau) cần các “mảnh” khác nhau của cùng một dữ liệu nền.
GraphQL "sống" ở đâu
GraphQL thường nằm giữa các ứng dụng client và nguồn dữ liệu của bạn. Những nguồn dữ liệu đó có thể là:
- cơ sở dữ liệu
- dịch vụ REST hiện có
- API bên thứ ba
- microservices
Server GraphQL nhận một truy vấn, xác định cách lấy từng trường được yêu cầu từ nơi phù hợp, rồi ghép thành phản hồi JSON cuối cùng.
Một mô hình suy nghĩ nhanh
Hãy nghĩ về GraphQL như đặt hàng một phản hồi theo hình dạng tùy chỉnh:
- Client mô tả hình dạng dữ liệu nó muốn.
- Server trả dữ liệu theo đúng hình dạng đó (khi có thể).
GraphQL không phải là
GraphQL thường bị hiểu nhầm, nên đây là vài làm rõ:
- Nó không phải một cơ sở dữ liệu (nó không lưu trữ dữ liệu của bạn).
- Nó không tự động nhanh hơn (nó có thể giảm truyền dữ liệu không cần thiết, nhưng công việc trên server vẫn quan trọng).
- Nó không phải “REST 2.0” (nó là một cách tiếp cận API khác với lợi thế và đánh đổi riêng).
Nếu bạn giữ định nghĩa cốt lõi đó—ngôn ngữ truy vấn + runtime cho APIs—bạn sẽ có nền tảng đúng cho mọi thứ còn lại.
Tại sao GraphQL được tạo ra
GraphQL được tạo để giải quyết một vấn đề sản phẩm thiết thực: các nhóm tốn quá nhiều thời gian để làm API phù hợp với màn hình UI thực tế.
API truyền thống theo endpoint thường buộc lựa chọn giữa gửi dữ liệu bạn không cần hoặc thực hiện thêm các cuộc gọi để lấy đủ dữ liệu. Khi sản phẩm phát triển, ma sát đó biểu hiện thành trang chậm hơn, code client phức tạp hơn, và phải phối hợp nhiều hơn giữa frontend và backend.
Những điểm đau GraphQL nhắm tới
Over-fetching xảy ra khi một endpoint trả về một đối tượng “đầy đủ” ngay cả khi màn hình chỉ cần vài trường. Ví dụ, màn hình profile trên di động có thể chỉ cần tên và avatar, nhưng API trả về địa chỉ, sở thích, các trường audit, v.v. Điều đó lãng phí băng thông và có thể ảnh hưởng trải nghiệm người dùng.
Under-fetching là ngược lại: không có endpoint đơn lẻ nào chứa mọi thứ một view cần, nên client phải gửi nhiều yêu cầu và ghép kết quả. Điều này tăng độ trễ và khả năng xảy ra lỗi một phần.
Phát triển API mà không liên tục tăng version
Nhiều API theo kiểu REST phản ứng với thay đổi bằng cách thêm endpoint mới hoặc versioning (v1, v2, v3). Versioning đôi khi cần thiết, nhưng nó tạo ra công việc bảo trì kéo dài: client cũ tiếp tục dùng phiên bản cũ, trong khi tính năng mới nằm ở chỗ khác.
Cách tiếp cận của GraphQL là phát triển schema bằng cách thêm trường và type theo thời gian, trong khi giữ trường hiện có ổn định. Điều này thường giảm áp lực phải tạo “phiên bản mới” chỉ để hỗ trợ nhu cầu UI mới.
Một API, nhiều client
Sản phẩm hiện đại hiếm khi chỉ có một consumer. Web, iOS, Android và các tích hợp đối tác đều cần các hình dạng dữ liệu khác nhau.
GraphQL được thiết kế để mỗi client có thể yêu cầu chính xác các trường nó cần — mà backend không cần tạo endpoint riêng cho từng màn hình hay thiết bị.
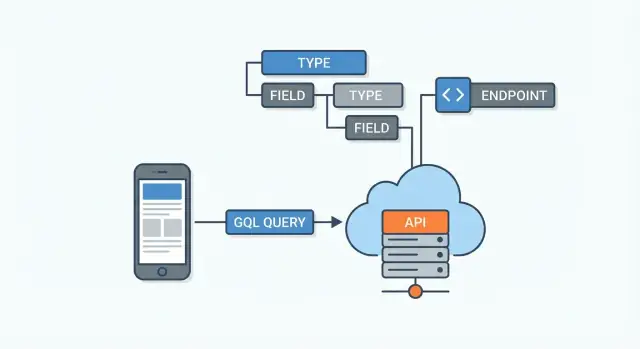
Schema GraphQL: Hợp đồng API
Một API GraphQL được định nghĩa bởi schema. Hãy nghĩ nó như thỏa thuận giữa server và mọi client: liệt kê dữ liệu nào tồn tại, nó kết nối ra sao, và có thể được yêu cầu hoặc thay đổi thế nào. Client không đoán endpoint — họ đọc schema và yêu cầu trường cụ thể.
Những điều cơ bản về schema: types, fields, mối quan hệ
Schema gồm các type (như User hoặc Post) và fields (như name hoặc title). Fields có thể trỏ tới các type khác, đó là cách GraphQL mô hình hoá mối quan hệ.
Dưới đây là ví dụ đơn giản bằng Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Kiểu chặt = xác thực trước khi thực thi
Vì schema kiểu chặt, GraphQL có thể xác thực một yêu cầu trước khi chạy nó. Nếu client yêu cầu một trường không tồn tại (ví dụ Post.publishDate khi schema không có trường đó), server có thể từ chối hoặc chỉ thực hiện một phần với lỗi rõ ràng — không có hành vi mơ hồ "có thể chạy được".
Phát triển an toàn theo thời gian
Schema được thiết kế để mở rộng. Bạn thường có thể thêm trường mới (ví dụ User.bio) mà không phá vỡ client hiện có, vì client chỉ nhận những gì họ yêu cầu. Việc xoá hoặc thay đổi trường nhạy cảm hơn, nên các đội thường deprecate trường trước rồi migrate client dần dần.
Queries: Yêu cầu chính xác những gì bạn cần
Một API GraphQL thường được expose qua một endpoint duy nhất (ví dụ /graphql). Thay vì có nhiều URL cho các tài nguyên khác nhau (như /users, /users/123, /users/123/posts), bạn gửi một truy vấn tới một nơi và mô tả chính xác dữ liệu bạn muốn nhận lại.
Chọn trường (kể cả dữ liệu lồng nhau)
Một truy vấn về cơ bản là "danh sách mua sắm" các trường. Bạn có thể yêu cầu các trường đơn giản (như id và name) và cả dữ liệu lồng nhau (như các bài viết gần đây của user) trong cùng một yêu cầu — mà không tải về các trường bạn không cần.
Ví dụ nhỏ:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Hình dạng phản hồi dễ dự đoán
Phản hồi GraphQL dự đoán được: JSON trả về phản chiếu cấu trúc truy vấn. Điều đó giúp frontend dễ làm việc hơn, vì bạn không phải đoán dữ liệu sẽ nằm ở đâu hay phân tích nhiều định dạng phản hồi khác nhau.
Ví dụ phản hồi đơn giản có thể trông như:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Nếu bạn không yêu cầu một trường, nó sẽ không xuất hiện. Nếu bạn yêu cầu, bạn có thể mong nó xuất hiện ở vị trí tương ứng — khiến truy vấn GraphQL là cách rõ ràng để lấy đúng dữ liệu mỗi màn hình hoặc tính năng cần.
Mutations: Ghi dữ liệu an toàn
Queries để đọc; mutations là cách bạn thay đổi dữ liệu trong API GraphQL — tạo, cập nhật, hoặc xoá bản ghi.
Luồng mutation điển hình
Hầu hết mutations theo cùng một mẫu:
- Inputs: client gửi một input có cấu trúc (thường là một object
input) như các trường cần cập nhật. - Xác thực & phân quyền: server kiểm tra các trường bắt buộc, định dạng dữ liệu, tính duy nhất, và xem user có quyền thực hiện hành động không.
- Ghi: server thực hiện thay đổi database (hoặc gọi dịch vụ khác).
- Payload/kiểu trả về: server trả về một kết quả có cấu trúc để UI có thể cập nhật.
Tại sao mutation trả về dữ liệu
Mutations GraphQL thường trả về dữ liệu có mục đích, thay vì chỉ success: true. Trả về đối tượng đã cập nhật (hoặc ít nhất id và các trường chính) giúp UI:
- cập nhật màn hình ngay mà không cần round-trip thêm
- làm mới cache an toàn (thường dùng với client như Apollo Client)
- hiển thị lỗi theo trường trong ngữ cảnh
Một thiết kế phổ biến là dùng một kiểu "payload" bao gồm cả entity đã cập nhật và bất kỳ lỗi nào.
Ví dụ mutation cơ bản
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Với API hướng UI, quy tắc tốt là: trả về những gì bạn cần để render trạng thái tiếp theo (ví dụ user đã cập nhật cùng bất kỳ errors). Điều đó giữ client đơn giản, tránh phải đoán thay đổi, và giúp xử lý lỗi mượt mà hơn.
Resolvers: GraphQL tạo kết quả như thế nào
Giữ quyền sở hữu mã nguồn đầy đủ
Sở hữu triển khai của bạn bằng cách xuất toàn bộ mã nguồn khi sẵn sàng.
Schema mô tả những gì có thể được hỏi. Resolvers mô tả làm thế nào để thực sự lấy nó. Resolver là một hàm gắn với trường cụ thể trong schema. Khi client yêu cầu trường đó, GraphQL gọi resolver để lấy hoặc tính giá trị.
Resolvers là hàm ở mức trường
GraphQL thực thi một truy vấn bằng cách đi qua hình dạng được yêu cầu. Với mỗi trường, nó tìm resolver tương ứng và chạy nó. Một số resolver chỉ trả một thuộc tính từ một object đã có trong bộ nhớ; số khác gọi database, một dịch vụ khác, hoặc kết hợp nhiều nguồn.
Ví dụ, nếu schema có User.posts, resolver posts có thể truy vấn table posts theo userId, hoặc gọi một Posts service riêng.
Ánh xạ fields tới nguồn dữ liệu
Resolvers là phần keo nối giữa schema và hệ thống thực tế của bạn:
- Database: truy vấn SQL/NoSQL, stored procedures, ORM
- Services: gọi REST/gRPC, microservices nội bộ, API bên thứ ba
- Fields tính toán: tổng, định dạng, giá trị suy ra
Ánh xạ này linh hoạt: bạn có thể thay đổi triển khai backend mà không thay đổi hình dạng truy vấn client — miễn là schema giữ nhất quán.
Hiệu năng: tránh chuỗi resolver chậm (N+1)
Vì resolvers có thể chạy cho từng trường và từng mục trong danh sách, dễ vô tình gây nhiều cuộc gọi nhỏ (ví dụ lấy posts cho 100 users bằng 100 truy vấn riêng). Mẫu "N+1" này có thể làm chậm phản hồi.
Các cách khắc phục phổ biến gồm batching và caching (ví dụ thu thập ID rồi fetch trong một truy vấn) và cố ý giới hạn các trường lồng nhau tốn kém mà bạn khuyến khích client yêu cầu.
Nơi đặt auth và validation
Phân quyền thường được áp dụng trong resolvers (hoặc middleware dùng chung) vì resolvers biết ai đang yêu cầu (qua context) và dữ liệu gì họ đang truy cập. Validation thường diễn ra ở hai mức: GraphQL xử lý kiểm tra kiểu/hình dạng tự động, trong khi resolvers thực thi các quy tắc nghiệp vụ (ví dụ “chỉ admin mới được đặt trường này”).
Lỗi và kết quả một phần
Một điều làm nhiều người mới với GraphQL ngạc nhiên là một yêu cầu có thể “thành công” mà vẫn chứa lỗi. Đó là vì GraphQL hướng theo trường: nếu một vài trường có thể được giải quyết và vài trường khác không, bạn có thể nhận dữ liệu một phần.
Lỗi trông như thế nào
Một phản hồi GraphQL điển hình có thể chứa cả data và một mảng errors:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Điều này hữu ích: client vẫn có thể render phần dữ liệu sẵn có (ví dụ profile user) trong khi xử lý trường bị thiếu.
Lỗi ở mức trường so với lỗi ở mức yêu cầu
- Lỗi ở mức trường xảy ra trong quá trình thực thi (resolver ném lỗi, kiểm tra quyền thất bại, dịch vụ downstream timeout). Các trường khác vẫn có thể resolve.
- Lỗi ở mức yêu cầu ngăn việc thực thi (JSON không hợp lệ, truy vấn bị sai định dạng, lỗi xác thực với schema). Trong trường hợp này,
datathường lànull.
Thông điệp thân thiện mà không lộ chi tiết nội bộ
Viết thông báo lỗi cho người dùng cuối, không phải để debug. Tránh lộ stack trace, tên database, hoặc ID nội bộ. Mẫu tốt là:
- Một
messagengắn, an toàn extensions.codeđọc được máy và ổn định- Metadata an toàn tuỳ chọn (ví dụ
retryable: true)
Log lỗi chi tiết ở server kèm request ID để điều tra mà không phơi bày nội bộ.
Mẹo để xử lý nhất quán trên nhiều client
Định nghĩa một "hợp đồng" lỗi nhỏ mà web và mobile cùng dùng: giá trị extensions.code chung (như UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), khi nào hiện toast so với lỗi theo trường, và cách xử lý dữ liệu một phần. Nhất quán ở đây ngăn mỗi client tự nghĩ ra quy tắc riêng.
Subscriptions cho cập nhật thời gian thực
Xuất bản với tên miền của bạn
Ra mắt app với tên miền tùy chỉnh khi bạn sẵn sàng chia sẻ.
Subscriptions là cách GraphQL đẩy dữ liệu đến client khi nó thay đổi, thay vì client phải hỏi lặp lại. Chúng thường dùng kết nối bền (thường là WebSockets), để server có thể gửi event ngay khi chuyện gì đó xảy ra.
Subscriptions là gì (và hoạt động ra sao)
Subscription trông giống một truy vấn, nhưng kết quả không phải một phản hồi đơn. Đó là luồng kết quả — mỗi mục là một sự kiện.
Ở tầng dưới, client “subscribe” tới một chủ đề (ví dụ messageAdded trong chat). Khi server publish event, các subscriber kết nối sẽ nhận payload khớp selection set của subscription.
Trường hợp dùng phổ biến
Subscriptions phù hợp khi người dùng mong đợi thay đổi ngay lập tức:
- Tin nhắn chat xuất hiện trong phòng mà không cần refresh
- Thông báo (mentions, thay đổi trạng thái đơn hàng, cảnh báo)
- Dashboard trực tiếp (tình trạng hệ thống, logistics, giao dịch, tỉ số thể thao)
Subscriptions so với polling
Với polling, client hỏi “Có gì mới không?” mỗi N giây. Nó đơn giản nhưng có thể lãng phí request (đặc biệt khi không có gì thay đổi) và vẫn có cảm giác trễ.
Với subscriptions, server gửi cập nhật ngay lập tức. Điều này giảm traffic không cần thiết và cải thiện cảm nhận nhanh — đổi lại là phải giữ kết nối mở và quản lý hạ tầng thời gian thực.
Khi subscriptions là độ phức tạp không cần thiết
Subscriptions không phải lúc nào cũng đáng dùng. Nếu cập nhật thưa thớt, không cần thời gian thực, hoặc dễ gom, thì polling (hoặc refetch sau hành động người dùng) thường đủ.
Chúng cũng tăng chi phí vận hành: scale kết nối, auth cho session lâu dài, retry và giám sát. Nguyên tắc tốt: chỉ dùng subscriptions khi thời gian thực là yêu cầu sản phẩm, không phải chỉ vì hay ho.
Ưu, nhược và các đánh đổi thực tế
GraphQL thường được mô tả là “quyền lực cho client”, nhưng quyền lực đó có chi phí. Biết trước các đánh đổi giúp bạn quyết định khi nào GraphQL phù hợp — và khi nào nó là quá tay.
Nơi GraphQL tỏa sáng
Lợi ích lớn nhất là lấy dữ liệu linh hoạt: client yêu cầu chính xác trường cần, giảm over-fetching và giúp thay đổi UI nhanh hơn.
Một lợi thế khác là hợp đồng mạnh từ schema GraphQL. Schema trở thành nguồn chân lý duy nhất cho types và thao tác có thể, cải thiện hợp tác và tooling.
Các đội thường thấy năng suất client tốt hơn vì frontend dev có thể iterate mà không phải chờ endpoint mới, và công cụ như Apollo Client có thể sinh types và đơn giản hóa lấy dữ liệu.
Nhược điểm phổ biến cần lên kế hoạch
GraphQL có thể làm cache phức tạp hơn. Với REST, cache thường theo URL. Với GraphQL, nhiều truy vấn dùng cùng một endpoint, nên cache phụ thuộc vào hình dạng truy vấn, cache chuẩn hóa, và cấu hình cẩn trọng server/client.
Phía server có những cạm bẫy hiệu năng. Một truy vấn nhỏ nhìn có vẻ đơn giản có thể kích hoạt nhiều cuộc gọi backend nếu không thiết kế resolver cẩn thận (batching, tránh N+1, kiểm soát các trường tốn kém).
Cũng có đường cong học tập: schema, resolvers, và pattern client có thể lạ với các đội quen làm API theo endpoint.
Bảo mật và vận hành
Vì client có thể yêu cầu nhiều thứ, API GraphQL nên áp dụng giới hạn độ sâu và độ phức tạp truy vấn để tránh yêu cầu quá lớn do vô tình hoặc lạm dụng.
Xác thực và phân quyền nên được thực thi từng trường, không chỉ ở cấp route, vì các trường khác nhau có thể có quy tắc truy cập khác nhau.
Về vận hành, đầu tư vào logging, tracing và monitoring hiểu GraphQL: theo dõi tên thao tác, variables (cẩn thận), thời gian resolver, và tỷ lệ lỗi để phát hiện truy vấn chậm và suy giảm sớm.
GraphQL và REST: Khác nhau thế nào
GraphQL và REST đều giúp app giao tiếp với server, nhưng chúng cấu trúc cuộc trao đổi đó theo cách rất khác nhau.
REST thường hoạt động thế nào
REST là dựa trên tài nguyên. Bạn lấy dữ liệu bằng cách gọi các endpoint (URL) đại diện cho "things" như /users/123 hoặc /orders?userId=123. Mỗi endpoint trả một hình dạng dữ liệu cố định do server quyết định.
REST cũng dựa vào ngữ nghĩa HTTP: các phương thức như GET/POST/PUT/DELETE, mã trạng thái, và quy tắc cache. Điều này làm REST cảm thấy tự nhiên khi bạn làm CRUD đơn giản hoặc tận dụng cache trình duyệt/edge.
GraphQL hoạt động ra sao
GraphQL là dựa trên schema. Thay vì nhiều endpoint, bạn thường có một endpoint, và client gửi một truy vấn mô tả chính xác các trường muốn. Server xác thực truy vấn đó với schema GraphQL và trả về phản hồi khớp với hình dạng truy vấn.
Khả năng "client chọn trường" này là lý do GraphQL giảm over-fetching và under-fetching, đặc biệt cho các màn hình UI cần dữ liệu từ nhiều model liên quan.
Khi REST đơn giản hơn
REST thường phù hợp hơn khi:
- Bạn xử lý tải/tải lên file (streaming, content types, range requests).
- API chủ yếu CRUD đơn giản với payload dự đoán được.
- Bạn dựa nhiều vào HTTP caching ở edge và muốn tương thích tối đa với tooling hiện có.
Các cách tiếp cận hybrid phổ biến
Nhiều đội kết hợp cả hai:
- Dùng GraphQL cho lấy dữ liệu hướng UI (web/mobile).
- Giữ REST cho dịch vụ cụ thể như callback auth, webhooks, xử lý file, hoặc endpoint microservice nội bộ.
Câu hỏi thực tế không phải "Cái nào tốt hơn?" mà là "Cái nào phù hợp với use case này với độ phức tạp ít nhất?".
Thiết kế API GraphQL (Checklist cho người mới)
Từ types đến resolvers
Mô tả types và quan hệ, và để Koder.ai hỗ trợ tạo schema cùng mã resolver.
Thiết kế API GraphQL dễ nhất khi bạn coi nó là sản phẩm cho người xây dựng màn hình, không phải là phản chiếu database. Bắt đầu nhỏ, xác thực với use case thực, và mở rộng khi cần.
1) Bắt đầu từ màn hình UI (không phải bảng)
Liệt kê các màn hình chính của bạn (ví dụ “Danh sách Sản phẩm”, “Chi tiết Sản phẩm”, “Thanh toán”). Với mỗi màn hình, ghi ra các trường chính xác nó cần và các tương tác hỗ trợ.
Điều này giúp tránh "god queries", giảm over-fetching, và làm rõ nơi cần lọc, sắp xếp, và phân trang.
2) Mô hình hóa domain types, rồi thêm operation dần dần
Định nghĩa types lõi trước (ví dụ User, Product, Order) và quan hệ của chúng. Sau đó thêm:
- một tập nhỏ queries khớp với màn hình thực
- một tập nhỏ mutations khớp với hành động người dùng ("addToCart", "placeOrder")
Ưu tiên đặt tên theo ngôn ngữ nghiệp vụ hơn tên database. “placeOrder” truyền đạt ý hơn “createOrderRecord”.
3) Quy tắc đặt tên và phân trang cơ bản
Giữ tên nhất quán: số ít cho item (product), số nhiều cho collection (products). Với phân trang, thường chọn một trong hai:
- Cursor-based: tốt cho danh sách thay đổi và "infinite scroll" (ổn định hơn)
- Offset-based: đơn giản hơn, nhưng có thể bị bỏ sót/trùng khi dữ liệu thay đổi
Quyết định sớm vì nó ảnh hưởng cấu trúc phản hồi API.
4) Document khi xây
GraphQL hỗ trợ mô tả trực tiếp trong schema — dùng chúng cho fields, arguments, và những trường hợp biên. Rồi thêm vài ví dụ copy-paste trong docs (bao gồm phân trang và kịch bản lỗi thường gặp). Schema được mô tả tốt làm cho introspection và API explorer hữu ích hơn nhiều.
Bắt đầu: Công cụ, test và bước tiếp theo
Bắt đầu với GraphQL chủ yếu là chọn một vài công cụ được hỗ trợ tốt và thiết lập workflow bạn tin cậy. Bạn không cần áp dụng mọi thứ cùng lúc — làm cho một truy vấn chạy end-to-end, rồi mở rộng.
Chọn framework server
Chọn server dựa trên stack và mức độ "batteries included" bạn muốn:
- Apollo Server: lựa chọn phổ biến với hệ sinh thái lớn và docs tốt.
- GraphQL Yoga: nhẹ, mặc định hiện đại, trải nghiệm dev dễ chịu.
- NestJS: lý tưởng nếu bạn đã dùng Nest và muốn tích hợp GraphQL với modules, DI, và patterns của nó.
Bước thực tế đầu tiên: định nghĩa schema nhỏ (vài types + một query), implement resolvers, và kết nối nguồn dữ liệu thật (ngay cả khi là danh sách in-memory stub).
Nếu muốn đi nhanh từ ý tưởng tới API, một nền tảng vibe-coding như Koder.ai có thể giúp scaffold một app full-stack nhỏ (React frontend, Go + PostgreSQL backend) và lặp schema/resolvers qua chat — rồi xuất mã nguồn khi bạn sẵn sàng tự quản lý.
Chọn cách tiếp cận client
Phía frontend, lựa chọn thường phụ thuộc bạn muốn convention rõ ràng hay linh hoạt:
- Apollo Client: dùng nhiều, cache mạnh và devtools tốt.
- Relay: pattern nghiêm ngặt hơn, thường dùng trong app lớn cần nhất quán.
- urql: nhỏ hơn, composable, phù hợp đội muốn kiểm soát.
Nếu bạn đang migrate từ REST, bắt đầu bằng GraphQL cho một màn hình hoặc tính năng, giữ REST cho phần còn lại cho tới khi phương pháp chứng minh được.
Test: schema + resolvers + integration
Đặt schema như hợp đồng API. Các lớp test hữu ích bao gồm:
- Xác thực schema (build schema trong CI; fail nhanh nếu type sai)
- Unit test resolver (mock nguồn dữ liệu và kiểm tra edge cases, quy tắc auth)
- Integration test (chạy GraphQL operation thực tế trên test server và database)
Bước tiếp theo
Để hiểu sâu hơn, tiếp tục với:
- /blog/graphql-vs-rest
- /blog/graphql-schema-design
Câu hỏi thường gặp
GraphQL là gì, nói đơn giản?
GraphQL là một ngôn ngữ truy vấn và runtime cho APIs. Client gửi truy vấn mô tả chính xác các trường cần, và server trả về JSON phản ánh đúng cấu trúc đó.
Nên nghĩ GraphQL như một lớp giữa client và một hoặc nhiều nguồn dữ liệu (database, dịch vụ REST, API bên thứ ba, microservices).
GraphQL giải quyết vấn đề gì so với các endpoint REST cố định?
GraphQL chủ yếu giải quyết:
- Over-fetching: nhận về nhiều trường hơn màn hình cần.
- Under-fetching: phải gửi nhiều yêu cầu để ghép thành một view.
Bằng cách cho phép client chỉ yêu cầu các trường cụ thể (kể cả trường lồng nhau), GraphQL giảm bớt dữ liệu thừa và đơn giản hóa code phía client.
GraphQL không phải là gì?
GraphQL không phải:
- Một cơ sở dữ liệu (nó không lưu trữ dữ liệu).
- Tự động nhanh hơn (nó có thể giảm truyền dữ liệu không cần thiết, nhưng công việc trên server vẫn quan trọng).
- “REST 2.0” (nó là một phong cách API khác với những lợi thế và đánh đổi riêng).
Hãy xem nó như hợp đồng API + engine thực thi, không phải phép màu về lưu trữ hoặc hiệu năng.
Tại sao GraphQL thường dùng một endpoint duy nhất?
Hầu hết API GraphQL chỉ cung cấp một endpoint duy nhất (thường là /graphql). Thay vì nhiều URL, bạn gửi các thao tác khác nhau (queries/mutations) tới cùng một điểm này.
Ý nghĩa thực tế: cache và observability thường căn cứ vào tên thao tác + biến, chứ không phải URL.
Schema GraphQL là gì, và tại sao nó quan trọng?
Schema là hợp đồng API. Nó định nghĩa:
- Các type (ví dụ:
User,Post) - Các trường trên các type đó (ví dụ:
User.name) - Mối quan hệ (ví dụ:
User.posts)
Vì schema , server có thể kiểm tra truy vấn trước khi thực thi và trả lỗi rõ ràng khi trường không tồn tại.
Truy vấn GraphQL hoạt động như thế nào?
Truy vấn (queries) là các thao tác đọc. Bạn chỉ định các trường cần, và JSON trả về sẽ khớp với cấu trúc truy vấn.
Mẹo:
- Đặt tên thao tác (ví dụ
query GetUserWithPosts) để dễ gỡ lỗi và giám sát. - Dùng đối số để điều chỉnh kết quả (ví dụ
posts(limit: 2)).
Mutations hoạt động ra sao, và tại sao thường trả về dữ liệu?
Mutations là thao tác ghi (tạo/cập nhật/xóa). Mẫu phổ biến:
- Gửi một đối tượng
input - Server kiểm tra + xác thực
- Thực hiện ghi
- Trả về payload bao gồm dữ liệu đã cập nhật và bất kỳ lỗi nào
Trả về dữ liệu (không chỉ success: true) giúp UI cập nhật ngay và giữ cache nhất quán.
Resolvers là gì, và nơi nào thường đặt quy tắc auth và nghiệp vụ?
Resolvers là hàm ở mức trường cho biết cách lấy hoặc tính giá trị cho từng trường.
Thực tế, resolvers có thể:
- Truy vấn database
- Gọi service nội bộ
- Gọi API bên thứ ba
- Tính giá trị dẫn xuất
Các quy tắc xác thực thường được áp dụng trong resolvers (hoặc middleware dùng chung) vì chúng biết ai đang yêu cầu và trường nào đang được truy cập.
Làm sao tránh các vấn đề hiệu năng phổ biến như N+1?
Rất dễ tạo ra mẫu N+1 (ví dụ: load posts riêng cho mỗi trong 100 users).
Các biện pháp thường dùng:
- Batching (gộp ID rồi truy vấn một lần)
- Caching (trong phạm vi request hoặc chia sẻ)
- Hạn chế khuyến khích client yêu cầu các trường lồng nhau tốn kém
Đo thời gian resolver và theo dõi các lời gọi lặp lại để phát hiện vấn đề.
Tại sao phản hồi GraphQL có thể gồm cả data và errors?
GraphQL có thể trả dữ liệu một phần cùng với mảng errors. Điều này xảy ra khi một số trường resolve thành công còn một số khác thất bại (ví dụ: field bị cấm truy cập, timeout dịch vụ phụ).
Thực hành tốt: