10 thg 7, 2025·8 phút
Các mẫu hàng đợi công việc nền đơn giản cho email và webhook
Tìm hiểu các mẫu hàng đợi công việc nền đơn giản để gửi email, chạy báo cáo và gửi webhook với retry, backoff và xử lý dead-letter, mà không cần công cụ nặng.
Tìm hiểu các mẫu hàng đợi công việc nền đơn giản để gửi email, chạy báo cáo và gửi webhook với retry, backoff và xử lý dead-letter, mà không cần công cụ nặng.
Bất kỳ công việc nào có thể mất hơn một hoặc hai giây thì không nên chạy trong một request của người dùng. Gửi email, tạo báo cáo và gửi webhook đều phụ thuộc vào mạng, dịch vụ bên thứ ba, hoặc truy vấn chậm. Đôi khi chúng tạm ngưng, thất bại, hoặc mất nhiều thời gian hơn bạn mong đợi.
Nếu bạn làm việc đó trong khi người dùng chờ, mọi người sẽ nhận ra ngay. Trang treo, nút "Lưu" quay vòng, và request bị timeout. Retry cũng có thể xảy ra ở nơi sai: người dùng làm mới trang, load balancer retry, hoặc frontend gửi lại, và bạn kết thúc với email gửi trùng, webhook gọi hai lần, hoặc hai lần chạy báo cáo cạnh tranh nhau.
Công việc nền khắc phục điều này bằng cách giữ cho request nhỏ và dự đoán được: chấp nhận hành động, ghi một job để làm sau, trả về nhanh. Job chạy ngoài đường dẫn request, với các quy tắc do bạn kiểm soát.
Phần khó là độ tin cậy. Khi công việc ra khỏi đường dẫn request, bạn vẫn phải trả lời các câu hỏi như:
Nhiều đội phản ứng bằng cách thêm "cơ sở hạ tầng nặng": một message broker, các cụm worker riêng, dashboard, cảnh báo, và playbook. Những công cụ đó hữu ích khi bạn thực sự cần, nhưng chúng cũng thêm nhiều bộ phận chuyển động và cách hỏng mới.
Một mục tiêu bắt đầu tốt hơn là đơn giản hơn: job đáng tin cậy dùng những phần bạn đã có. Với hầu hết sản phẩm, đó là hàng đợi dựa trên cơ sở dữ liệu cộng với một tiến trình worker nhỏ. Thêm chiến lược retry và backoff rõ ràng, và một mẫu dead-letter cho các job liên tục thất bại. Bạn có hành vi dự đoán được mà không phải cam kết với một nền tảng phức tạp ngay ngày đầu.
Ngay cả khi bạn xây nhanh bằng công cụ chat như Koder.ai, sự tách biệt này vẫn quan trọng. Người dùng nên nhận được phản hồi nhanh bây giờ, và hệ thống của bạn nên hoàn thành công việc chậm, dễ bị lỗi một cách an toàn ở nền.
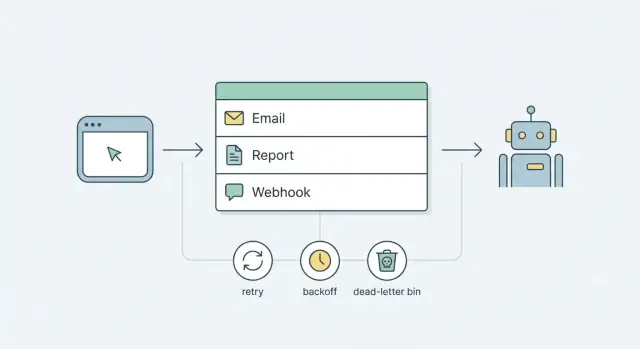
Hàng đợi là một dây chờ cho công việc. Thay vì làm các tác vụ chậm hoặc không đáng tin cậy trong request (gửi email, tạo báo cáo, gọi webhook), bạn đặt một bản ghi nhỏ vào hàng đợi và trả về nhanh. Sau đó, một tiến trình riêng lấy bản ghi đó và làm công việc.
Một vài từ bạn sẽ gặp thường xuyên:
Luồng đơn giản nhất trông như sau:
Enqueue: app của bạn lưu một bản ghi job (type, payload, thời gian chạy).
Claim: worker tìm job sẵn sàng tiếp theo và "khóa" nó để chỉ một worker chạy.
Run: worker thực hiện task (gửi, tạo, chuyển).
Finish: đánh dấu xong, hoặc ghi thất bại và đặt thời gian chạy tiếp theo.
Nếu khối lượng job vừa phải và bạn đã có cơ sở dữ liệu, hàng đợi dựa trên database thường là đủ. Nó dễ hiểu, dễ debug, và phù hợp nhu cầu phổ biến như xử lý email và đảm bảo giao webhook.
Các nền tảng streaming mới có ý nghĩa khi bạn cần throughput rất cao, nhiều consumer độc lập, hoặc khả năng replay lịch sử sự kiện lớn qua nhiều hệ thống. Nếu bạn chạy hàng chục dịch vụ với hàng triệu sự kiện mỗi giờ, các công cụ như Kafka có thể giúp. Cho tới lúc đó, một bảng database cộng với vòng lặp worker xử lý nhiều trường hợp thực tế.
Hàng đợi trong database chỉ giữ ổn nếu mỗi bản ghi job trả lời nhanh ba câu hỏi: làm gì, khi nào thử lại, và lần trước đã xảy ra gì. Làm đúng và vận hành trở nên nhàm chán (mục tiêu đó).
Lưu đầu vào nhỏ nhất cần thiết để làm công việc, không phải toàn bộ đầu ra đã render. Payload tốt là ID và vài tham số, như { "user_id": 42, "template": "welcome" }.
Tránh lưu các blob lớn (HTML email đầy đủ, dữ liệu báo cáo lớn, body webhook khổng lồ). Nó làm database phình nhanh và khó debug. Nếu job cần một tài liệu lớn, lưu tham chiếu thay vì: report_id, export_id, hoặc file key. Worker có thể fetch dữ liệu đầy đủ khi chạy.
Ít nhất, hãy dành chỗ cho:
job_type chọn handler (send_email, generate_report, deliver_webhook). payload chứa inputs nhỏ như ID và tuỳ chọn.queued, running, succeeded, failed, dead).attempt_count và max_attempts để dừng retry khi rõ ràng không thể thành công.created_at và next_run_at (khi job đủ điều kiện). Thêm started_at và finished_at nếu muốn thấy rõ job chậm.idempotency_key để ngăn hiệu ứng kép, và last_error để bạn thấy lý do thất bại mà không cần lục logs.Idempotency nghe có vẻ cao siêu, nhưng ý tưởng đơn giản: nếu cùng job chạy hai lần, lần thứ hai phải phát hiện và không gây hại. Ví dụ, job giao webhook có thể dùng idempotency key như webhook:order:123:event:paid để bạn không gửi cùng một event hai lần nếu retry trùng với timeout.
Cũng thu vài số cơ bản sớm. Bạn không cần dashboard lớn để bắt đầu, chỉ cần các truy vấn báo: bao nhiêu job đang queued, bao nhiêu thất bại, và tuổi của job queued lâu nhất.
Nếu bạn đã có database, bạn có thể khởi tạo hàng đợi nền mà không thêm cơ sở hạ tầng mới. Job là các dòng, worker là tiến trình liên tục lấy các dòng đến hạn và thực hiện công việc.
Giữ bảng nhỏ và đơn giản. Bạn muốn đủ trường để chạy, retry, và debug sau này.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Nếu bạn xây trên Postgres (phổ biến với backend Go), jsonb là cách thực tế để lưu dữ liệu job như { "user_id":123,"template":"welcome" }.
Khi một hành động của người dùng nên kích hoạt job (gửi email, fire webhook), hãy ghi dòng job trong cùng transaction cơ sở dữ liệu với thay đổi chính nếu có thể. Điều đó ngăn "người dùng được tạo nhưng job bị thiếu" nếu crash xảy ra ngay sau ghi chính.
Ví dụ: khi user đăng ký, insert dòng user và một job send_welcome_email trong cùng transaction.
Worker lặp chu kỳ: tìm một job đến hạn, claim nó để không ai khác lấy, process, rồi đánh dấu xong hoặc lên lịch retry.
Thực tế điều đó có nghĩa:
status='queued' và next_run_at <= now().SELECT ... FOR UPDATE SKIP LOCKED là cách phổ biến).status='running', locked_at=now(), locked_by='worker-1'.done/succeeded), hoặc ghi last_error và lên lịch lần thử tiếp theo.Nhiều worker có thể chạy cùng lúc. Bước claim ngăn việc lấy trùng.
Khi shutdown, ngừng nhận job mới, hoàn thành job hiện tại, rồi thoát. Nếu tiến trình chết giữa chừng, dùng quy tắc đơn giản: coi job running quá timeout là đủ điều kiện để re-queue bởi một tác vụ "reaper" định kỳ.
Nếu bạn xây trong Koder.ai, mẫu hàng đợi database này là mặc định vững chắc cho email, báo cáo và webhook trước khi thêm dịch vụ queue chuyên biệt.
Retry giữ cho hàng đợi ổn định khi thế giới thực lộn xộn. Không có quy tắc rõ ràng, retry biến thành vòng ồn ào spam người dùng, bắn phá API, và che lấp bug thật.
Bắt đầu bằng cách quyết định gì nên retry và gì nên fail nhanh.
Retry các lỗi tạm thời: network timeouts, 502/503, rate limit, hoặc kết nối DB chập chờn.
Fail nhanh khi job không thể thành công: thiếu địa chỉ email, 400 từ webhook vì payload sai, hoặc yêu cầu báo cáo cho tài khoản đã xoá.
Backoff là khoảng dừng giữa các lần thử. Linear backoff (5s, 10s, 15s) đơn giản, nhưng vẫn có thể tạo làn sóng traffic. Exponential backoff (5s, 10s, 20s, 40s) trải tải tốt hơn và an toàn cho webhooks và nhà cung cấp bên thứ ba. Thêm jitter (một độ trễ ngẫu nhiên nhỏ) để hàng nghìn job không retry cùng một giây sau sự cố.
Quy tắc thường hoạt động tốt trong production:
Max attempts nhằm giới hạn thiệt hại. Với nhiều đội, 5–8 lần là đủ. Sau đó, dừng retry và đưa job vào dead-letter để xem xét thay vì lặp vô hạn.
Timeouts ngăn job "zombie". Email có thể timeout ở 10–20 giây mỗi lần. Webhook thường cần ngắn hơn, 5–10 giây, vì receiver có thể down và bạn muốn chuyển sang job khác. Tạo báo cáo có thể cho phép vài phút, nhưng vẫn cần cutoff.
Nếu bạn xây trong Koder.ai, xem should_retry, next_run_at, và idempotency key như các trường quan trọng hàng đầu. Những chi tiết nhỏ đó giữ hệ thống im lặng khi có sự cố.
Trạng thái dead-letter là nơi job đi khi retry không còn an toàn hoặc hữu ích. Nó biến thất bại thầm lặng thành thứ bạn có thể thấy, tìm và hành động.
Lưu đủ để hiểu chuyện đã xảy ra và replay job mà không đoán mò, nhưng cẩn thận với secrets.
Giữ:
Nếu payload chứa token hoặc dữ liệu cá nhân, redact hoặc mã hoá trước khi lưu.
Khi job vào dead-letter, đưa ra quyết định nhanh: retry, fix, hoặc ignore.
Retry cho outage và timeout bên ngoài. Fix cho dữ liệu xấu (thiếu email, URL webhook sai) hoặc bug trong code. Ignore nên hiếm, nhưng hợp lý khi job không còn liên quan (ví dụ khách hàng đã xoá tài khoản). Nếu ignore, ghi lý do để job không có vẻ như biến mất.
Requeue thủ công an toàn nhất khi nó tạo job mới và giữ job cũ bất biến. Đánh dấu job dead-letter với ai requeued, khi nào và vì sao, rồi enqueue một bản sao mới với ID mới.
Về cảnh báo, theo dõi các tín hiệu thường báo đau thật: số lượng dead-letter tăng nhanh, cùng lỗi lặp qua nhiều job, và job queued cũ không ai claim.
Nếu bạn dùng Koder.ai, snapshot và rollback giúp khi một release xấu làm spike failures, vì bạn có thể quay lui nhanh trong khi điều tra.
Cuối cùng, thêm van an toàn cho outage vendor. Giới hạn tần suất gửi cho mỗi provider, và dùng circuit breaker: nếu endpoint webhook liên tục lỗi nặng, tạm dừng thử mới trong một cửa sổ ngắn để bạn không dội server họ (và của bạn).
Hàng đợi hiệu quả khi mỗi job type có quy tắc rõ: tính thành công là gì, cái gì nên retry, và cái gì không được xảy ra hai lần.
Email. Hầu hết lỗi email là tạm thời: timeout nhà cung cấp, rate limit, hoặc outage ngắn. Xử lý như retryable với backoff. Rủi ro lớn hơn là gửi trùng, nên làm email job idempotent. Lưu key dedupe ổn định như user_id + template + event_id và từ chối gửi nếu key đã được đánh dấu là đã gửi.
Cũng nên lưu tên template và phiên bản (hoặc hash của subject/body đã render). Nếu cần rerun job, bạn có thể chọn gửi nội dung giống hệt hay render lại từ template mới. Nếu provider trả về message ID, lưu nó để support có thể tra cứu.
Báo cáo. Báo cáo lỗi khác. Chúng có thể chạy vài phút, gặp giới hạn phân trang, hoặc out of memory nếu làm mọi thứ một lần. Chia nhỏ công việc. Mẫu phổ biến: một job "report request" tạo nhiều job "page" (hoặc "chunk"), mỗi job xử lý một lát dữ liệu.
Lưu kết quả để tải xuống sau thay vì bắt người dùng chờ. Có thể là bảng database theo report_run_id, hoặc tham chiếu file cộng metadata (status, row count, created_at). Thêm trường tiến độ để UI hiển thị "processing" vs "ready" mà không đoán mò.
Webhooks. Webhook là về độ tin cậy giao, không phải tốc độ. Ký mọi request (ví dụ HMAC với secret chung) và bao gồm timestamp để tránh replay. Retry chỉ khi receiver có thể thành công sau này.
Bộ quy tắc đơn giản:
Thứ tự và ưu tiên. Hầu hết job không cần ordering nghiêm ngặt. Khi order quan trọng, thường là theo key (theo user, theo invoice, theo endpoint webhook). Thêm group_key và chỉ chạy một job đang in-flight cho mỗi key.
Về ưu tiên, tách công việc gấp khỏi công việc chậm. Tồn backlog báo cáo lớn không nên trì hoãn email đặt lại mật khẩu.
Ví dụ: sau mua hàng, bạn enqueue (1) email xác nhận đơn, (2) webhook đối tác, và (3) job cập nhật báo cáo. Email retry nhanh, webhook retry lâu hơn với backoff, và báo cáo chạy sau ở ưu tiên thấp.
Người dùng đăng ký app của bạn. Ba việc nên xảy ra, nhưng không cái nào nên làm chậm trang đăng ký: gửi email chào mừng, thông báo CRM bằng webhook, và đưa user vào báo cáo hoạt động hàng đêm.
Ngay sau khi tạo record user, ghi ba dòng job vào hàng đợi database. Mỗi dòng có type, payload (ví dụ user_id), status, attempt count, và next_run_at.
Vòng đời điển hình:
queued: tạo và chờ workerrunning: worker đã claimsucceeded: xong, không cần làm nữafailed: thất bại, lên lịch lại hoặc hết retrydead: thất bại quá nhiều lần và cần người xemJob email chào mừng có idempotency key như welcome_email:user:123. Trước khi gửi, worker kiểm tra bảng idempotency keys đã hoàn thành (hoặc áp một unique constraint). Nếu job chạy hai lần do crash, lần thứ hai thấy key và bỏ qua gửi. Không có email chào mừng gửi hai lần.
Giả sử endpoint CRM webhook đang down. Job webhook thất bại với timeout. Worker lên lịch retry theo backoff (ví dụ: 1 phút, 5 phút, 30 phút, 2 giờ) cộng chút jitter để nhiều job không retry cùng giây.
Sau tối đa attempts, job thành dead. Người dùng vẫn đăng ký, nhận email chào mừng, và job báo cáo đêm vẫn chạy bình thường. Chỉ thông báo CRM bị kẹt và có thể thấy.
Sáng hôm sau, support (hoặc người trực) xử lý mà không phải lục logs hàng giờ:
webhook.crm).Nếu bạn xây app trên nền như Koder.ai, cùng mẫu áp dụng: giữ flow người dùng nhanh, đẩy side effects vào job, và làm cho lỗi dễ kiểm tra và chạy lại.
Cách nhanh nhất để phá hàng đợi là coi nó tùy chọn. Các đội thường bắt đầu với "gửi email trong request lần này" vì cảm thấy đơn giản. Rồi nó lan: đặt lại mật khẩu, hoá đơn, webhook, export báo cáo. Ứng dụng nhanh chóng chậm đi, timeout tăng, và bất kỳ trục trặc bên thứ ba nào đều thành outage của bạn.
Bẫy phổ biến khác là bỏ qua idempotency. Nếu job có thể chạy hai lần, nó không được tạo hai kết quả. Thiếu idempotency, retry tạo email trùng, event webhook lặp, hoặc tệ hơn.
Vấn đề thứ ba là thiếu khả năng quan sát. Nếu bạn chỉ biết lỗi từ ticket support, hàng đợi đã làm hại người dùng. Ngay cả view nội bộ cơ bản cho số job theo status và last_error có thể tiết kiệm nhiều thời gian.
Một vài vấn đề xuất hiện sớm, ngay cả ở hàng đợi đơn giản:
Backoff ngăn tự gây outage. Ngay cả lịch cơ bản như 1 phút, 5 phút, 30 phút, 2 giờ cũng an toàn hơn. Đồng thời đặt max attempts để job hỏng dừng và hiện ra.
Nếu bạn xây trên nền như Koder.ai, nên deploy những điều cơ bản này cùng tính năng, không để thành dự án dọn dẹp vài tuần sau.
Trước khi thêm công cụ, đảm bảo các nền tảng cơ bản đã vững. Hàng đợi dựa trên DB hoạt động tốt khi mỗi job dễ claim, dễ retry, và dễ kiểm tra.
Checklist độ tin cậy nhanh:
Tiếp theo, chọn ba loại job đầu tiên và viết ra quy tắc của chúng. Ví dụ: email đặt lại mật khẩu (retry nhanh, max thấp), báo cáo hàng đêm (ít retry, timeout dài hơn), giao webhook (nhiều retry, backoff dài hơn, dừng khi 4xx cố định).
Nếu không chắc khi nào hàng đợi DB không đủ, theo dõi tín hiệu như contention ở cấp dòng khi nhiều worker, ordering nghiêm ngặt giữa nhiều job type, fan-out lớn (một event tạo hàng ngàn job), hoặc tiêu thụ cross-service khi nhiều đội quản lý worker khác nhau.
Nếu bạn muốn prototype nhanh, có thể phác thảo flow trong Koder.ai (koder.ai) ở chế độ planning, sinh bảng jobs và vòng lặp worker, và lặp với snapshot và rollback trước khi deploy.
If a task can take more than a second or two, or depends on a network call (email provider, webhook endpoint, slow query), move it to a background job.
Keep the user request focused on validating input, writing the main data change, enqueueing a job, and returning a fast response.
Start with a database-backed queue when:
Add a broker/streaming tool later when you need very high throughput, many independent consumers, or cross-service event replay.
Track the basics that answer: what to do, when to try next, and what happened last time.
A practical minimum:
Store inputs, not big outputs.
Good payloads:
user_id, template, report_id)Avoid:
The key is an atomic “claim” step so two workers can’t take the same job.
Common approach in Postgres:
FOR UPDATE SKIP LOCKED)running and set locked_at/locked_byThen your workers can scale horizontally without double-processing the same row.
Assume jobs will run twice sometimes (crashes, timeouts, retries). Make the side effect safe.
Simple patterns:
idempotency_key like welcome_email:user:123This is especially important for emails and webhooks to prevent duplicates.
Use a clear default policy and keep it boring:
Fail fast on permanent errors (like missing email address, invalid payload, most 4xx webhook responses).
Dead-letter means “stop retrying and make it visible.” Use it when:
max_attemptsStore enough context to act:
Handle “stuck running” jobs with two rules:
running jobs older than a threshold and re-queues them (or marks them failed)This lets the system recover from worker crashes without manual cleanup.
Use separation so slow work can’t block urgent work:
If ordering matters, it’s usually “per key” (per user, per webhook endpoint). Add a group_key and ensure only one in-flight job per key to preserve local ordering without forcing global ordering.
job_type, payloadstatus (queued, running, succeeded, failed, dead)attempts, max_attemptsnext_run_at, plus created_atlocked_at, locked_bylast_erroridempotency_key (or another dedupe mechanism)If the job needs big data, store a reference (like report_run_id or a file key) and fetch the real content when the worker runs.
last_error and last status code (for webhooks)When you replay, prefer creating a new job and keeping the dead one immutable.