Joe Armstrong và Erlang: Let It Crash để xây nền tảng đáng tin cậy
Khám phá cách Joe Armstrong định hình đồng thời, supervision và tư duy “let it crash” của Erlang—ý tưởng vẫn được dùng để xây nền tảng thời gian thực đáng tin cậy.
Nội dung bài viết (và lý do nó vẫn quan trọng)
Joe Armstrong không chỉ tham gia tạo ra Erlang—ông còn là người giải thích rõ ràng và thuyết phục nhất về nó. Qua các bài nói, bài báo và quan điểm thực dụng, ông phổ biến một ý tưởng đơn giản: nếu bạn muốn phần mềm luôn hoạt động, hãy thiết kế để đối phó với lỗi thay vì giả vờ có thể tránh được chúng.
Bài này là một chuyến tham quan có hướng dẫn về tư duy Erlang và lý do nó vẫn quan trọng khi bạn xây dựng nền tảng thời gian thực đáng tin cậy—những thứ như hệ thống chat, định tuyến cuộc gọi, thông báo trực tiếp, phối hợp multiplayer và hạ tầng cần phản hồi nhanh và nhất quán ngay cả khi một số phần hoạt động không ổn.
“Thời gian thực” theo cách dễ hiểu
Thời gian thực không phải lúc nào cũng là “microgiây” hay “deadline cứng.” Trong nhiều sản phẩm nó có nghĩa là:
- phản hồi nhanh để người dùng cảm nhận được (không có những khoảng treo khó hiểu)
- hành vi dự đoán được khi tải tăng (có thể chậm lại nhưng không bị xoắn vòng)
- dịch vụ tiếp tục trong các lỗi cục bộ (một thành phần xấu không kéo cả hệ xuống)
Erlang được xây dựng cho hệ thống viễn thông, nơi những kỳ vọng này là bất khả nhượng—và áp lực đó đã định hình những ý tưởng có ảnh hưởng nhất của nó.
Ba trụ cột chúng ta sẽ tập trung
Thay vì đi sâu vào cú pháp, ta sẽ tập trung vào các khái niệm làm Erlang nổi tiếng và tiếp tục xuất hiện trong thiết kế hệ thống hiện đại:
- Mặc định là đồng thời: xây dựng phần mềm từ nhiều worker nhỏ, cô lập thay vì vài phần lớn.\n2. Khả năng chịu lỗi là mục tiêu thiết kế: giả định có lỗi, timeout và crash—và lên kế hoạch cho bước tiếp theo.\n3. “Let it crash”: đừng bảo vệ mọi dòng mã quá mức; thất bại nhanh và phục hồi gọn bằng cấu trúc (không phải bằng anh hùng cứu nguy).
Trên đường đi, chúng ta sẽ liên hệ những ý tưởng này với actor model và message passing, giải thích supervision trees và OTP bằng ngôn ngữ dễ hiểu, và chỉ ra vì sao BEAM VM khiến cả phương pháp này khả thi.
Ngay cả khi bạn không dùng Erlang (và có thể sẽ không bao giờ dùng), điểm mấu chốt vẫn đúng: cách trình bày của Armstrong cung cấp một checklist mạnh mẽ để xây dựng hệ thống giữ được phản hồi và sẵn sàng khi thực tế trở nên lộn xộn.
Động lực của Joe Armstrong: xây hệ thống luôn hoạt động
Switch viễn thông và nền tảng định tuyến cuộc gọi không thể “dừng để bảo trì” như nhiều website khác. Chúng được kỳ vọng xử lý cuộc gọi, sự kiện thanh toán và lưu lượng tín hiệu suốt ngày đêm—thường với yêu cầu khắt khe về tính sẵn sàng và thời gian phản hồi dự đoán được.
Erlang bắt nguồn từ Ericsson cuối những năm 1980 như một nỗ lực đáp ứng những thực tế đó bằng phần mềm, không chỉ bằng phần cứng chuyên dụng. Joe Armstrong và đồng nghiệp không theo đuổi sự tinh tế chỉ vì vẻ đẹp; họ cố gắng xây hệ thống mà người vận hành có thể tin cậy trong điều kiện tải liên tục, lỗi cục bộ và môi trường đời thực lộn xộn.
“Đáng tin cậy” nghĩa là gì trong thực tế
Một chuyển đổi tư duy quan trọng là: độ tin cậy không bằng “không bao giờ thất bại.” Trong các hệ thống lớn chạy lâu, sẽ có điều gì đó thất bại: một process gặp input bất ngờ, một node khởi động lại, một liên kết mạng giật, hoặc một phụ thuộc chững lại.
Vậy mục tiêu trở thành:
- tiếp tục phục vụ người dùng ngay cả khi một số phần hoạt động sai
- phát hiện lỗi nhanh
- phục hồi tự động, với ít can thiệp của con người
- cô lập lỗi để một bug không làm gục toàn bộ
Tư duy này khiến các ý tưởng như supervision trees và “let it crash” trở nên hợp lý: bạn thiết kế cho thất bại như một sự kiện bình thường, không phải thảm họa đặc biệt.
Ít thần thoại, nhiều giải quyết vấn đề
Dễ có xu hướng tường thuật như một bước đột phá của một thiên tài. Góc nhìn hữu ích hơn là đơn giản: ràng buộc viễn thông buộc phải chọn các đánh đổi khác. Erlang ưu tiên đồng thời, cô lập và phục hồi vì đó là công cụ thực tế cần để giữ dịch vụ chạy khi thế giới thay đổi xung quanh.
Việc lấy vấn đề làm trọng tâm cũng là lý do bài học của Erlang vẫn dịch được sang ngày nay—bất cứ nơi nào tính uptime và phục hồi nhanh quan trọng hơn ngăn ngừa hoàn hảo.
Đồng thời như mặc định: nhiều worker nhỏ
Ý tưởng cốt lõi trong Erlang là “làm nhiều việc cùng lúc” không phải là tính năng đặc biệt thêm vào sau—nó là cách bạn cấu trúc hệ thống.
Các process nhẹ, giải thích đơn giản
Trong Erlang, công việc được chia thành nhiều “process” rất nhỏ. Hãy tưởng tượng chúng như những worker nhỏ, mỗi người chịu trách nhiệm một việc: xử lý một cuộc gọi, theo dõi một phiên chat, giám sát một thiết bị, thử lại một thanh toán, hoặc theo dõi một queue.
Chúng nhẹ, có nghĩa bạn có thể có số lượng lớn mà không cần phần cứng khổng lồ. Thay vì một worker nặng gắng gượng xử mọi thứ, bạn có một nhóm worker tập trung có thể khởi động nhanh, dừng nhanh và thay thế nhanh.
Tại sao “một chương trình lớn” hỏng theo cách khác
Nhiều hệ thống được thiết kế như một chương trình lớn với nhiều phần liên kết chặt. Khi hệ thống kiểu đó gặp bug nghiêm trọng, sự cố bộ nhớ hoặc thao tác chặn, lỗi có thể lan rộng—giống như bật ngắt một cầu dao và cả toà nhà mất điện.
Erlang đẩy theo hướng ngược lại: cô lập trách nhiệm. Nếu một worker nhỏ hoạt động sai, bạn có thể thải và thay worker đó mà không làm sập các công việc không liên quan.
Message passing như “gửi giấy nhắn”
Các worker phối hợp thế nào? Họ không mò vào trạng thái nội bộ của nhau. Họ gửi tin nhắn—gần giống như chuyền giấy nhắn hơn là dùng một bảng trắng lộn xộn.
Một worker có thể nói, “Có yêu cầu mới,” “Người dùng này đã ngắt kết nối,” hoặc “Thử lại sau 5 giây.” Worker nhận đọc giấy nhắn và quyết định hành động.
Lợi ích then chốt là hạn chế lây lan: vì worker cô lập và giao tiếp bằng tin nhắn, lỗi ít có khả năng lan khắp hệ thống.
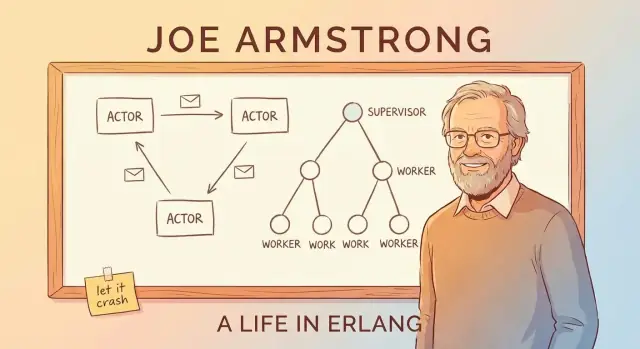
Message passing và actor model (không cầu kỳ thuật ngữ)
Một cách đơn giản hiểu actor model của Erlang là tưởng tượng hệ thống làm từ nhiều worker độc lập nhỏ.
Actors: worker nhỏ chỉ giao tiếp bằng tin nhắn
Một actor là một đơn vị tự chứa với trạng thái riêng và hộp thư. Nó làm ba việc cơ bản:
- nhận tin nhắn (mỗi lần một tin) từ mailbox
- cập nhật trạng thái nội bộ
- gửi tin nhắn cho actor khác
Chỉ vậy thôi. Không có biến chia sẻ ẩn, không thể “vò” vào bộ nhớ của worker khác. Nếu một actor cần thứ gì, nó hỏi bằng cách gửi tin nhắn.
Tại sao tránh trạng thái chia sẻ loại bỏ nhiều lỗi
Khi nhiều thread chia sẻ cùng dữ liệu, bạn có thể gặp race condition: hai tác vụ thay đổi cùng một giá trị gần như cùng lúc và kết quả phụ thuộc vào thứ tự thời gian. Đó là nơi bug trở nên ngắt quãng và khó tái hiện.
Với message passing, mỗi actor sở hữu dữ liệu của nó. Actor khác không thể thay đổi trực tiếp. Điều này không xoá hết mọi bug, nhưng giảm đáng kể các vấn đề do truy cập đồng thời cùng một mẩu trạng thái.
Back-pressure, giải thích như hàng đợi ở quán cà phê
Tin nhắn không tới “miễn phí.” Nếu một actor nhận tin nhắn nhanh hơn khả năng xử lý, mailbox của nó (hàng đợi) sẽ tăng. Đó là back-pressure: hệ thống gián tiếp nói với bạn rằng phần đó đang quá tải.
Trong thực tế, bạn giám sát kích thước mailbox và xây giới hạn: từ chối bớt tải, gom nhóm, lấy mẫu, hoặc chuyển công việc sang nhiều actor hơn thay vì để queue phình mãi.
Ví dụ cụ thể: thông báo chat
Hãy tưởng tượng một app chat. Mỗi người dùng có thể có một actor chịu trách nhiệm giao thông báo. Khi người dùng offline, tin nhắn tiếp tục tới—mailbox tăng. Hệ thống thiết kế tốt có thể giới hạn hàng đợi, bỏ những thông báo không quan trọng, hoặc chuyển sang chế độ tóm tắt, thay vì để một người dùng chậm làm giảm toàn bộ dịch vụ.
“Let It Crash” giải thích: thất bại nhanh, phục hồi nhanh hơn
“Let it crash” không phải khẩu hiệu cho kỹ thuật tắc trách. Đó là một chiến lược độ tin cậy: khi một thành phần rơi vào trạng thái xấu hoặc bất ngờ, nó nên dừng ngay và báo rõ thay vì lê lết.
Ý nghĩa thực sự
Thay vì viết mã cố gắng xử mọi trường hợp cạnh trong cùng một process, Erlang khuyến khích giữ mỗi worker nhỏ và tập trung. Nếu worker gặp điều nó không thể xử lý (trạng thái hỏng, giả thiết bị phá vỡ, input bất ngờ), nó thoát. Một phần khác của hệ thống chịu trách nhiệm khởi động lại nó.
Điều này chuyển câu hỏi chính từ “Làm sao ngăn lỗi?” sang “Làm sao phục hồi sạch khi lỗi xảy ra?”.
Đánh đổi: ít kiểm tra phòng thủ hơn, logic rõ ràng hơn
Lập trình phòng thủ khắp nơi có thể biến luồng đơn giản thành mê cung các điều kiện, thử lại và trạng thái nửa vời. “Let it crash” đánh đổi bớt độ phức tạp trong process cho:
- luồng mã đơn giản, dễ đọc hơn
- phát hiện giả thiết sai nhanh hơn
- phục hồi nhất quán (vì được tập trung)
Ý tưởng lớn là phục hồi cần dự đoán và lặp lại được, không phải xử lý ngẫu hứng trong mọi hàm.
Khi phù hợp—và khi không
Nó phù hợp nhất khi lỗi có thể phục hồi và cô lập: vấn đề mạng tạm thời, yêu cầu xấu, worker bị kẹt, timeout từ bên thứ ba.
Nó không phù hợp khi một crash có thể gây hại không thể đảo ngược, ví dụ:
- mất dữ liệu nếu không có nguồn chân thực bền vững
- vận hành an toàn-kritical nơi “thử lại” không chấp nhận được
Khởi động lại nhanh và trạng thái biết là tốt
Crash chỉ có ích nếu khởi động lại nhanh và an toàn. Thực tế là khởi động worker vào trạng thái biết là tốt—thường bằng cách load lại cấu hình, rebuild cache trong bộ nhớ từ lưu trữ bền, và tiếp tục công việc mà không giả vờ rằng trạng thái hỏng chưa từng tồn tại.
Supervision Trees: thiết kế cho thất bại có chủ ý
Ý tưởng “let it crash” chỉ hoạt động vì crashes không bị bỏ mặc. Mẫu then chốt là supervision tree: một cây phân cấp nơi supervisors đóng vai quản lý và workers làm công việc thực tế (xử lý cuộc gọi, theo dõi phiên, tiêu thụ queue, v.v.). Khi worker hoạt động sai, quản lý nhận ra và khởi động lại nó.
Quản lý khởi động lại workers
Supervisor không cố “sửa” worker trong chỗ. Thay vào đó, nó áp quy tắc đơn giản: nếu worker chết, khởi tạo một worker mới. Điều đó làm cho đường phục hồi dự đoán được và giảm nhu cầu xử lý lỗi rải rác khắp mã.
Quan trọng không kém, supervisor cũng quyết định khi không khởi động lại—nếu cái gì đó crash quá thường, có thể là dấu hiệu vấn đề sâu hơn, và khởi động lại liên tục có thể làm tệ thêm.
Chiến lược khởi động lại (khái quát)
Supervision không phải một kích thước phù hợp cho tất cả. Các chiến lược phổ biến gồm:
- One-for-one: chỉ khởi lại worker thất bại. Phù hợp với tác vụ độc lập nơi một lỗi không ảnh hưởng người khác.
- Khởi động lại nhóm: nếu một worker thất bại, một nhóm liên quan được khởi lại cùng nhau. Phù hợp với các thành phần chặt chẽ cần giữ đồng bộ.
Phụ thuộc: phần bạn phải nghĩ kỹ
Thiết kế supervision tốt bắt đầu với bản đồ phụ thuộc: thành phần nào phụ thuộc thành phần nào, và “khởi động lại mới” thực sự có ý nghĩa gì với chúng.
Nếu một session handler phụ thuộc cache process, khởi lại chỉ handler có thể để nó nối với trạng thái xấu. Gom chúng dưới supervisor phù hợp (hoặc khởi lại cùng nhau) biến các chế độ lỗi lộn xộn thành hành vi phục hồi nhất quán và lặp lại được.
OTP: bộ phận tái sử dụng để xây dịch vụ đáng tin cậy
Nếu Erlang là ngôn ngữ, OTP (Open Telecom Platform) là bộ công cụ biến “let it crash” thành thứ bạn có thể vận hành trong production hàng năm.
OTP như hộp công cụ các mẫu đã được kiểm chứng
OTP không phải một thư viện đơn lẻ—nó là một tập hợp quy ước và thành phần sẵn có (gọi là behaviours) giải quyết các phần nhàm chán nhưng quan trọng khi xây dịch vụ:
gen_servercho worker chạy dài giữ trạng thái và xử lý yêu cầu từng cái mộtsupervisorcho việc khởi động lại tự động theo quy tắc rõ ràngapplicationcho định nghĩa cách một dịch vụ khởi động, dừng và đóng gói vào release
Đây không phải “phép thuật.” Đó là khuôn mẫu có callback rõ ràng, để mã của bạn cắm vào một hình dạng đã biết thay vì phát minh hình dạng mới cho mỗi dự án.
Tại sao mẫu chuẩn tốt hơn framework tự chế
Nhóm thường tự xây worker nền, hook giám sát, và logic khởi động lại một lần. Nó hoạt động—cho tới khi không. OTP giảm rủi ro đó bằng cách hướng mọi người tới cùng một ngôn ngữ và vòng đời. Khi kỹ sư mới vào, họ không phải học framework nội bộ của bạn; họ biết các mẫu phổ biến trong hệ sinh thái Erlang.
OTP hướng dẫn kiến trúc hằng ngày thế nào
OTP khuyến khích bạn nghĩ theo vai trò process và trách nhiệm: cái gì là worker, cái gì là coordinator, cái gì nên khởi động lại cái gì, và cái gì không nên tự khởi động lại.
Nó cũng khuyến khích vệ sinh tốt: đặt tên rõ, thứ tự khởi động rõ ràng, tắt máy dự đoán, và các tín hiệu giám sát có sẵn. Kết quả là phần mềm được thiết kế để chạy liên tục—dịch vụ có thể phục hồi từ lỗi, tiến hoá theo thời gian và tiếp tục làm việc mà không cần chăm sóc liên tục.
BEAM VM: runtime làm cho mô hình khả thi
Những ý tưởng lớn của Erlang—process nhỏ, message passing, và “let it crash”—sẽ khó dùng trong production nếu không có BEAM virtual machine. BEAM là runtime khiến các mẫu này trở nên tự nhiên, không mong manh.
Lập lịch: công bằng hơn so với “một thread lớn”
BEAM được xây để chạy số lượng lớn process nhẹ. Thay vì dựa nhiều vào vài thread OS và hy vọng ứng dụng cư xử, BEAM tự quản lý lịch cho các process Erlang.
Lợi ích thực tế là phản hồi dưới tải: công việc được chia nhỏ và quay vòng công bằng, nên không có worker bận rộn nào chiếm hệ thống quá lâu. Điều này phù hợp với dịch vụ làm từ nhiều tác vụ độc lập—mỗi tác vụ làm một chút rồi nhường.
Cô lập và thu gom rác per-process
Mỗi process Erlang có heap riêng và garbage collection riêng. Chi tiết then chốt: dọn dẹp bộ nhớ trong một process không yêu cầu tạm dừng toàn chương trình.
Quan trọng không kém, process được cô lập. Nếu một process crash, nó không làm hỏng bộ nhớ process khác và VM vẫn sống. Cô lập này là nền tảng để supervision trees thực tế: lỗi được cô lập, rồi supervisor xử lý bằng cách khởi động lại phần đã thất bại thay vì phá toàn hệ.
Phân tán: nhiều node, một hệ thống
BEAM cũng hỗ trợ phân tán một cách trực tiếp: bạn có thể chạy nhiều Erlang node (instance VM) và để chúng giao tiếp bằng gửi tin nhắn. Nếu bạn hiểu “process giao tiếp bằng messaging,” phân tán là mở rộng của cùng ý tưởng—chỉ có điều một số process sống trên node khác.
BEAM không hứa hẹn tốc độ thô. Nó làm cho đồng thời, cô lập lỗi và phục hồi là mặc định, nên câu chuyện độ tin cậy mang tính thực dụng hơn là lý thuyết.
Nâng cấp mà không dừng hệ thống (hot code, cẩn thận)
Một trong những mánh của Erlang là hot code swapping: cập nhật một phần hệ thống đang chạy với downtime tối thiểu (khi runtime và công cụ hỗ trợ). Lời hứa thực tế không phải là “không bao giờ khởi động lại,” mà là “triển khai bản sửa mà không biến một lỗi nhỏ thành outage lâu.”
“Hot code” thực sự nghĩa là gì
Trong Erlang/OTP, runtime có thể giữ hai phiên bản của một module cùng lúc. Process hiện tại có thể hoàn tất công việc dùng phiên bản cũ trong khi cuộc gọi mới dùng phiên bản mới. Điều này cho bạn không gian vá lỗi, tung tính năng, hoặc chỉnh hành vi mà không phải kick mọi người ra khỏi hệ thống.
Thực hiện tốt, điều này hỗ trợ mục tiêu độ tin cậy trực tiếp: ít khởi động lại toàn bộ, cửa sổ bảo trì ngắn hơn, và phục hồi nhanh khi thứ gì đó trượt vào production.
Những ràng buộc không nên bỏ qua
Không phải thay đổi nào cũng an toàn để swap live. Một vài ví dụ cần thận trọng hoặc cần khởi động lại:
- thay đổi cấu trúc trạng thái (process mong dữ liệu ở dạng này, mã mới mong dạng khác)
- thay đổi giao thức hoặc định dạng tin nhắn phải tương thích giữa dịch vụ
- migration schema mất thời gian hoặc cần phối hợp
Erlang cung cấp cơ chế chuyển đổi có kiểm soát, nhưng bạn vẫn phải thiết kế lộ trình nâng cấp.
Tư duy: nâng cấp và rollback là bình thường
Hot upgrade hiệu quả nhất khi nâng cấp và rollback được coi là thao tác thường xuyên, không phải khủng hoảng hiếm hoi. Điều đó nghĩa là lên kế hoạch versioning, tương thích và đường lui ngay từ đầu. Trong thực tế, các đội kết hợp kỹ thuật nâng cấp live với rollout theo giai đoạn, health checks và phục hồi dựa trên supervision.
Ngay cả khi bạn không dùng Erlang, bài học vẫn chuyển: thiết kế hệ thống để thay đổi an toàn là yêu cầu ưu tiên, không phải suy nghĩ sau cùng.
Nơi ý tưởng Erlang tỏa sáng trong nền tảng thời gian thực
Nền tảng thời gian thực ít liên quan đến thời gian chính xác và nhiều hơn đến việc duy trì phản hồi khi mọi thứ liên tục hỏng: mạng lắc, phụ thuộc chậm, và đột biến lưu lượng. Thiết kế của Erlang—được Joe Armstrong ủng hộ—phù hợp thực tế này vì nó giả định lỗi và coi đồng thời là bình thường.
Các trường hợp sử dụng “thời gian thực” thường gặp
Bạn thấy tư duy kiểu Erlang tỏa sáng ở nơi có nhiều hoạt động độc lập diễn ra cùng lúc:
- Messaging và chat: hàng triệu cuộc hội thoại nhỏ, mỗi cuộc có trạng thái và vòng thử lại riêng.\n- Truyền thông thời gian thực: signaling thoại/video, cập nhật presence và điều phối phiên.\n- Phối hợp IoT: đàn thiết bị check-in, rời đi và xuất hiện không dự đoán.\n- Quy trình thanh toán: nhiều bước, trong đó vài bước chậm hoặc cần hành động bù trừ.
“Soft real-time” thường nghĩa là gì
Hầu hết sản phẩm không cần cam kết cứng như “mỗi hành động hoàn thành trong 10 ms.” Họ cần soft real-time: độ trễ thấp nhất quán cho các yêu cầu phổ biến, phục hồi nhanh khi phần hỏng, và sẵn sàng cao để người dùng hiếm khi nhận thấy sự cố.
Thất bại là bình thường: hãy thiết kế cho nó
Hệ thống thực tế gặp các vấn đề như:
- Mất kết nối (mạng di động, chuyển Wi‑Fi)\n- Timeouts khi dịch vụ hạ nguồn chậm\n- Sự cố cục bộ nơi một vùng hoặc phụ thuộc bị suy giảm
Mô hình Erlang khuyến khích cô lập từng hoạt động (phiên người dùng, thiết bị, cố gắng thanh toán) để lỗi không lan. Thay vì xây một thành phần khổng lồ “cố xử lý mọi thứ,” nhóm có thể nghĩ theo đơn vị nhỏ: mỗi worker làm một việc, giao tiếp bằng tin nhắn, và nếu nó vỡ, nó được khởi động lại gọn.
Sự chuyển đổi tư duy—từ “ngăn mọi lỗi” sang “cô lập và phục hồi nhanh”—thường là điều làm cho nền tảng thời gian thực cảm thấy ổn định dưới áp lực.
Những hiểu lầm phổ biến và giới hạn thực tế
Danh tiếng Erlang có thể nghe như cam kết: hệ thống không bao giờ sập vì chúng chỉ khởi động lại. Thực tế thực dụng hơn và hữu ích hơn. “Let it crash” là công cụ để xây dịch vụ đáng tin cậy, không phải giấy phép bỏ qua các vấn đề khó.
Khởi động lại không phải miếng dán vết thương
Một sai lầm phổ biến là xem supervision như cách che đi bug sâu. Nếu một process crash ngay sau khi khởi động, supervisor có thể liên tục khởi lại, dẫn đến vòng lặp crash—tiêu hao CPU, spam log, và có thể gây outage lớn hơn bug gốc.
Hệ thống tốt thêm backoff, giới hạn tần suất khởi động lại và hành vi “từ bỏ và báo cáo.” Khởi động lại nên khôi phục hoạt động lành mạnh, không che giấu bất thường.
Trạng thái là phần khó nhất
Khởi động lại process thường dễ; phục hồi trạng thái đúng thì không. Nếu trạng thái chỉ nằm trong bộ nhớ, bạn phải quyết định thế nào là “đúng” sau crash:
- Có nên rebuild từ store bền không?\n- Có thể replay sự kiện một cách an toàn (idempotency)?\n- Chuyện gì xảy ra với công việc đang diễn ra hoặc cập nhật nửa chừng?
Khả năng chịu lỗi không thay thế thiết kế dữ liệu cẩn thận. Nó buộc bạn phải minh bạch về điều đó.
Bạn vẫn cần quan sát hệ thống
Crash chỉ hữu ích nếu bạn phát hiện sớm và hiểu nguyên nhân. Điều đó nghĩa là đầu tư vào logging, metrics và tracing—không chỉ “nó đã khởi động lại nên ổn.” Bạn muốn thấy tần suất khởi động lại tăng, hàng đợi lớn dần, và phụ thuộc chậm trước khi người dùng cảm nhận được.
Giới hạn vận hành thực tế vẫn tồn tại
Dù BEAM mạnh, hệ thống vẫn có thể fail theo các cách bình thường:
- Tăng bộ nhớ do leak, cache hoặc heap lớn\n- Mailboxes dồn khi producer nhanh hơn consumer (độ trễ và timeout)\n- Lỗi phụ thuộc (DB, API bên thứ ba, DNS) mà khởi động lại mã bạn không khắc phục
Mô hình Erlang giúp bạn cô lập và phục hồi, nhưng không xoá tất cả sự cố.
Áp dụng bài học hôm nay (ngay cả khi bạn không dùng Erlang)
Món quà lớn nhất của Erlang không phải cú pháp—mà là tập thói quen để xây dịch vụ tiếp tục chạy khi một phần không tránh khỏi sẽ hỏng. Bạn có thể áp các thói quen đó vào hầu hết stack.
Chuyển các ý tưởng thành hành động cụ thể
Bắt đầu bằng cách làm rõ ranh giới thất bại. Phân hệ thống thành các thành phần có thể thất bại độc lập, và đảm bảo mỗi thành phần có hợp đồng rõ (input, output và thế nào là “xấu”).
Rồi tự động hoá phục hồi thay vì cố ngăn mọi lỗi:
- Cô lập thành phần: chạy công việc rủi ro trong process/container/thread riêng để một crash không đầu độc cả hệ.\n- Định nghĩa ranh giới: timeouts, retry với backoff, circuit breakers và bulkheads để tránh lỗi lan truyền.\n- Làm cho phục hồi trở nên thường xuyên: health checks, auto-restarts và mặc định an toàn để hệ thống quay về trạng thái biết là tốt nhanh.
Một cách thực tế để làm các thói quen này thành hiện thực là tích hợp chúng vào tooling và vòng đời, không chỉ mã. Ví dụ, khi nhóm dùng Koder.ai để vibe-code web, backend hoặc mobile apps qua chat, workflow tự nhiên khuyến khích lập kế hoạch rõ ràng (Planning Mode), triển khai lặp có thể lặp lại, và thay đổi an toàn với snapshots và rollback—những khái niệm phù hợp với tư duy vận hành mà Erlang phổ biến: giả định thay đổi và lỗi sẽ xảy ra, và làm cho phục hồi trở nên tẻ nhạt.
Điểm bắt đầu ngoài Erlang
Bạn có thể xấp xỉ các mẫu “supervision” bằng công cụ quen thuộc:
- Supervisors: systemd, Kubernetes Deployments, hoặc process manager (restart-on-failure, readiness probes).\n- Cô lập process: dịch vụ worker riêng cho công việc nặng CPU hoặc không đáng tin cậy.\n- Message passing: hàng đợi/stream (RabbitMQ, SQS, Kafka) để tách rời producer và consumer và làm phẳng các đột biến.
Checklist quyết định nhanh
Trước khi sao chép mẫu, quyết định bạn cần gì:
- Chế độ lỗi mong đợi: quá tải, sự cố cục bộ, phụ thuộc chậm, input xấu, leak bộ nhớ.\n- Nhu cầu độ trễ: bạn cần phản hồi thời gian thực hay xử lý dần được?\n- Mục tiêu phục hồi: khởi động lại nhanh, giảm dần có đạo đức, hay can thiệp thủ công?\n- Kỹ năng đội và tooling: ai đứng on-call, observability và phản ứng sự cố?
Nếu bạn muốn bước tiếp thực tế, hãy xem thêm hướng dẫn trong /blog, hoặc duyệt chi tiết triển khai trong /docs (và kế hoạch trong /pricing nếu bạn đang đánh giá công cụ).
Câu hỏi thường gặp
Why is Joe Armstrong’s Erlang mindset still relevant today?
Erlang phổ biến hóa một tư duy thực dụng về độ tin cậy: giả định rằng một số phần sẽ thất bại và thiết kế trước hành động tiếp theo.
Thay vì cố gắng ngăn mọi crash, nó nhấn mạnh cô lập lỗi, phát hiện nhanh, và phục hồi tự động, phù hợp với các nền tảng thời gian thực như chat, định tuyến cuộc gọi, thông báo và dịch vụ điều phối.
What does “real-time” mean in the post’s plain terms?
Trong ngữ cảnh này, “thời gian thực” thường có nghĩa là soft real-time:
- phản hồi cảm nhận được là nhanh và nhất quán
- hành vi giữ được tính dự đoán dưới tải
- hệ thống tiếp tục hoạt động khi có lỗi cục bộ
Nó ít liên quan đến các ngưỡng microsecond và nhiều hơn đến việc tránh tắc nghẽn, vòng xoáy, và sự cố lan tỏa.
What does “concurrency by default” mean in Erlang-style design?
Concurrency-by-default nghĩa là cấu trúc hệ thống thành nhiều worker nhỏ, cô lập, thay vì vài thành phần lớn, phụ thuộc chặt chẽ.
Mỗi worker xử lý một trách nhiệm hẹp (phiên, thiết bị, cuộc gọi, vòng thử lại), giúp mở rộng và cô lập lỗi dễ dàng hơn.
What are Erlang “lightweight processes,” and why do they matter?
Lightweight processes là các worker nhỏ, độc lập mà bạn có thể tạo ra với số lượng lớn.
Thực tế, chúng có lợi vì:
- bạn có thể mô hình hoá một process cho mỗi “thứ” (người dùng/phiên/thiết bị)
- lỗi chỉ ảnh hưởng cục bộ đến một worker
- khởi động lại công việc rẻ hơn so với khởi động lại một monolith
Why does Erlang prefer message passing over shared state?
Message passing là phối hợp bằng cách gửi thông điệp thay vì chia sẻ trạng thái có thể thay đổi.
Điều này giúp giảm những loại lỗi đồng thời (race conditions) vì mỗi worker sở hữu trạng thái nội bộ; người khác chỉ có thể yêu cầu thay đổi thông qua tin nhắn.
What is back-pressure in an actor/message system, and how do you handle it?
Back-pressure xảy ra khi một worker nhận tin nhắn nhanh hơn khả năng xử lý, làm hàng đợi (mailbox) tăng lên.
Cách xử lý thực tế gồm:
- giám sát kích thước mailbox/hàng đợi
- áp các giới hạn (bỏ, lấy mẫu, hoặc giới hạn)
- phân tán tải sang nhiều worker hơn
- giảm chất lượng phục vụ (ví dụ chuyển sang digest cho thông báo không quan trọng)
What does “let it crash” actually mean (and what doesn’t it mean)?
“Let it crash” nghĩa là: nếu một worker rơi vào trạng thái không hợp lệ hoặc bất ngờ, nó nên thất bại nhanh thay vì cố gắng lê lết.
Phục hồi được xử lý theo cấu trúc (qua supervision), giúp luồng mã đơn giản hơn và phục hồi dự đoán được—với điều kiện khởi động lại phải an toàn và nhanh.
What are supervision trees, and why are they central to fault tolerance?
Supervision tree là một cây phân cấp nơi supervisors giám sát workers và khởi động lại chúng theo các quy tắc định sẵn.
Thay vì rải rác xử lý phục hồi, bạn tập trung:
- quyết định cái gì được khởi động lại khi có lỗi
- ngăn vòng lặp crash vô tận bằng backoff và giới hạn
- khởi động lại nhóm khi các thành phần cần đồng bộ
What is OTP, and how does it help build reliable services?
OTP là tập hợp các mẫu chuẩn (behaviours) và quy ước giúp hệ thống Erlang vận hành lâu dài.
Các khối phổ biến gồm:
gen_servercho worker dài hạn giữ trạng tháisupervisorcho chính sách khởi động lạiapplicationcho việc khởi/dừng và đóng gói release
Ưu điểm là quy trình sống chung được hiểu rộng rãi thay vì framework riêng lẻ mỗi dự án.
How can I apply Erlang’s lessons if I’m not using Erlang?
Bạn có thể ứng dụng cùng nguyên tắc trong các stack khác bằng cách coi lỗi và phục hồi là ưu tiên:
- cô lập công việc rủi ro (process/service/container riêng)
- thêm timeouts, retry với backoff, circuit breakers, bulkheads
- tự động phục hồi (health checks + restart-on-failure)
- dùng hàng đợi/luồng để tách rời producer và consumer
Ngoài ra, bài viết gợi ý tham khảo thêm hướng dẫn trong /blog và chi tiết triển khai trong /docs (và kế hoạch trong /pricing) để đánh giá công cụ và quy trình.