Tại sao các đội hay bị vấp với tích hợp truyền thống
Hầu hết sản phẩm bắt đầu với các tích hợp điểm-điểm đơn giản: Hệ thống A gọi Hệ thống B, hoặc một script nhỏ sao chép dữ liệu từ chỗ này sang chỗ khác. Cách đó hoạt động cho tới khi sản phẩm lớn lên, đội tách ra, và số lượng kết nối tăng lên. Sớm thôi mọi thay đổi đều cần phối hợp giữa nhiều dịch vụ, vì một trường nhỏ hay thay đổi trạng thái có thể lan rộng qua chuỗi phụ thuộc.
Tốc độ thường là thứ đầu tiên gặp trục trặc. Thêm một tính năng mới nghĩa là cập nhật nhiều tích hợp, triển khai lại nhiều dịch vụ, và hy vọng không có thứ gì phụ thuộc vào hành vi cũ.
Rồi việc gỡ lỗi trở nên đau đầu. Khi UI trông sai, thật khó trả lời các câu hỏi cơ bản: chuyện gì đã xảy ra, theo thứ tự nào, và hệ thống nào đã ghi giá trị bạn đang thấy?
Thiếu một dấu vết kiểm toán thường là vấn đề. Nếu dữ liệu được đẩy trực tiếp từ một database sang database khác (hoặc biến đổi trên đường đi), bạn mất lịch sử. Bạn có thể thấy trạng thái cuối cùng, nhưng không thấy chuỗi sự kiện dẫn tới nó. Việc rà soát sự cố và hỗ trợ khách hàng đều chịu thiệt vì bạn không thể phát lại quá khứ để xác nhận điều gì đã thay đổi và vì sao.
Đây cũng là điểm bắt đầu của tranh luận “ai nắm giữ sự thật”. Một đội nói “Dịch vụ billing là nguồn sự thật.” Đội khác nói “Dịch vụ order mới là.” Thực tế là mỗi hệ thống có góc nhìn cục bộ, và tích hợp điểm-điểm biến sự bất đồng ấy thành ma sát hàng ngày.
Ví dụ đơn giản: một order được tạo, rồi thanh toán, rồi được hoàn tiền. Nếu ba hệ thống cập nhật lẫn nhau trực tiếp, mỗi bên có thể có một câu chuyện khác khi retry, timeout, hoặc sửa thủ công xảy ra.
Đó dẫn tới câu hỏi thiết kế cốt lõi phía sau Kafka event streaming: bạn chỉ cần chuyển công việc từ chỗ này sang chỗ khác (một hàng đợi), hay bạn cần một bản ghi bền, được chia sẻ về điều gì đã xảy ra để nhiều hệ thống có thể đọc, tua lại và tin tưởng (một nhật ký)? Câu trả lời thay đổi cách bạn xây dựng, gỡ lỗi và phát triển hệ thống.
Jay Kreps, Kafka, và ý tưởng về nhật ký
Jay Kreps góp phần định hình Kafka và, quan trọng hơn, cách nhiều đội nghĩ về việc di chuyển dữ liệu. Sự chuyển đổi tư duy hữu ích là: ngưng coi message như lần gửi một lần, và bắt đầu coi hoạt động hệ thống như một bản ghi.
Ý tưởng cốt lõi đơn giản. Mô hình hóa các thay đổi quan trọng như một luồng các sự kiện bất biến:
- Một order đã được tạo.
- Một thanh toán đã được ủy quyền.
- Một người dùng thay đổi email của họ.
Mỗi event là một sự thật không nên chỉnh sửa sau đó. Nếu có điều gì thay đổi sau này, bạn thêm một event mới nói sự thật mới. Theo thời gian, những sự kiện ấy tạo thành một nhật ký: lịch sử chỉ append của hệ thống.
Đây là điểm Kafka event streaming khác với nhiều thiết lập messaging cơ bản. Nhiều hàng đợi được xây quanh “gửi đi, xử lý, xóa”. Điều đó ổn khi công việc thuần là giao tiếp. Quan điểm nhật ký nói: “giữ lịch sử để nhiều consumer có thể dùng nó, bây giờ và sau này.”
Khả năng phát lại lịch sử là sức mạnh thực tế.
Nếu một báo cáo sai, bạn có thể chạy lại cùng chuỗi sự kiện qua một job analytics đã sửa và thấy chỗ số liệu lệch. Nếu một bug gửi email sai, bạn có thể phát lại các event vào môi trường test và tái tạo chính xác dòng thời gian. Nếu một tính năng mới cần dữ liệu cũ, bạn có thể xây một consumer mới bắt đầu từ đầu và bắt kịp theo tốc độ của nó.
Ví dụ cụ thể: tưởng tượng bạn thêm các kiểm tra gian lận sau khi đã xử lý hàng tháng thanh toán. Với nhật ký các sự kiện thanh toán và tài khoản, bạn có thể phát lại quá khứ để huấn luyện hoặc hiệu chỉnh quy tắc trên chuỗi thực, tính điểm rủi ro cho giao dịch cũ, và backfill các event “fraud_review_requested” mà không phải ghi đè database.
Chú ý điều này buộc bạn làm gì. Một cách tiếp cận dựa trên nhật ký thúc đẩy bạn đặt tên event rõ ràng, giữ chúng ổn định, và chấp nhận rằng nhiều đội và dịch vụ sẽ phụ thuộc vào chúng. Nó cũng đặt ra các câu hỏi hữu ích: Nguồn sự thật là gì? Event này có ý nghĩa lâu dài thế nào? Làm gì khi ta phạm sai lầm?
Giá trị không phải ở cá tính. Mà là nhận ra rằng một nhật ký chia sẻ có thể trở thành bộ nhớ của hệ thống bạn, và bộ nhớ là thứ cho phép hệ thống lớn lên mà không vỡ vụn mỗi khi bạn thêm consumer mới.
Hàng đợi vs nhật ký: mô hình tư duy đơn giản nhất
Một message queue giống như hàng việc cho phần mềm của bạn. Producer đặt công việc vào hàng, consumer lấy mục tiếp theo, làm xong, và mục đó biến mất. Hệ thống chủ yếu để mỗi tác vụ được xử lý một lần, càng sớm càng tốt.
Nhật ký khác. Đó là một bản ghi có thứ tự các sự kiện đã xảy ra, giữ theo một trình tự bền. Consumer không “lấy” event rồi xoá nó. Họ đọc nhật ký theo tốc độ của mình, và có thể đọc lại sau. Trong Kafka event streaming, nhật ký đó là ý tưởng lõi.
Cách thực tế để nhớ khác biệt:
- Queue = công việc cần làm. Khi worker xác nhận, nó biến mất.
- Log = lịch sử những gì đã xảy ra. Event tồn tại trong một khoảng retention.
Retention thay đổi thiết kế. Với queue, nếu sau này bạn cần một tính năng phụ thuộc vào tin nhắn cũ (analytics, kiểm tra gian lận, phát lại sau bug), bạn thường phải thêm một database riêng hoặc bắt đầu chụp bản sao ở chỗ khác. Với nhật ký, phát lại là bình thường: bạn có thể xây lại một view dẫn xuất bằng cách đọc từ đầu (hoặc từ checkpoint biết trước).
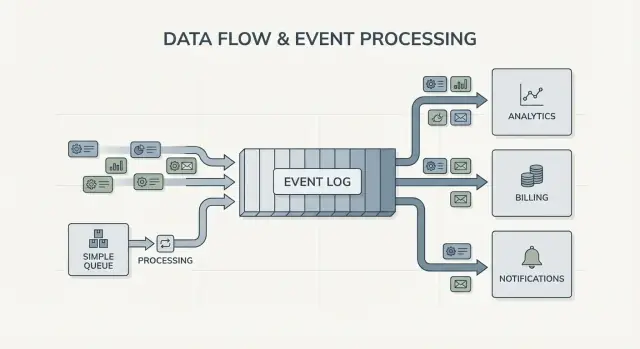
Fan-out là khác biệt lớn nữa. Tưởng tượng service checkout phát OrderPlaced. Với queue, bạn thường chọn một nhóm worker để xử lý, hoặc nhân bản công việc qua nhiều queue. Với nhật ký, billing, email, inventory, search indexing và analytics đều có thể đọc cùng luồng event độc lập. Mỗi đội có thể chạy theo tốc độ riêng, và thêm consumer mới sau này không bắt producer thay đổi.
Mô hình tư duy đơn giản: dùng queue khi bạn chuyển nhiệm vụ; dùng nhật ký khi bạn ghi lại sự kiện mà nhiều phần trong công ty có thể muốn đọc, bây giờ hoặc sau này.
Event streaming thay đổi gì trong thiết kế hệ thống
Event streaming đảo câu hỏi mặc định. Thay vì hỏi, “Tôi nên gửi message này cho ai?”, bạn bắt đầu bằng việc ghi lại “Điều gì vừa xảy ra?” Nghe có vẻ nhỏ, nhưng thay đổi cách bạn mô hình hệ thống.
Bạn publish các fact như OrderPlaced hoặc PaymentFailed, và các phần khác của hệ thống quyết định nếu, khi nào, và cách họ phản ứng.
Với Kafka event streaming, producer không cần một danh sách tích hợp trực tiếp. Một service checkout có thể publish một event, và nó không cần biết analytics, email, kiểm tra gian lận hay một service khuyến nghị trong tương lai có dùng hay không. Consumer mới có thể xuất hiện sau, consumer cũ có thể tạm dừng, và producer vẫn hành xử như trước.
Điều này cũng thay đổi cách bạn phục hồi lỗi. Trong thế giới chỉ messaging, khi một consumer bỏ lỡ hoặc có bug, dữ liệu thường “mất” trừ khi bạn xây backup tùy chỉnh. Với nhật ký, bạn sửa code và phát lại lịch sử để xây lại trạng thái đúng. Điều này thường tốt hơn sửa database thủ công hoặc script một lần mà không ai tin tưởng.
Trong thực tế, sự chuyển đổi thể hiện qua vài điểm đáng tin cậy: bạn coi event là bản ghi bền, thêm tính năng bằng cách subscribe thay vì sửa producer, bạn có thể rebuild read models (search index, dashboard) từ đầu, và có dòng thời gian rõ ràng hơn về những gì đã xảy ra xuyên dịch vụ.
Khả năng quan sát cải thiện vì event log trở thành tham chiếu chung. Khi có lỗi, bạn có thể theo dõi chuỗi nghiệp vụ: order tạo, inventory giữ, payment retry, shipment lên lịch. Dòng thời gian đó thường dễ hiểu hơn log ứng dụng rải rác vì nó tập trung vào các fact nghiệp vụ.
Ví dụ cụ thể: nếu một bug về giảm giá sai giá trong hai giờ, bạn có thể đưa bản sửa và phát lại các event liên quan để tính lại tổng, cập nhật hoá đơn và làm mới analytics. Bạn sửa kết quả bằng cách tái suy ra kết quả, không phải đoán bảng nào cần patch thủ công.
Khi nào hàng đợi đơn giản là đủ
Một queue đơn giản là công cụ phù hợp khi bạn chuyển công việc, không xây bản ghi dài hạn. Mục tiêu là giao một tác vụ cho worker, chạy nó, rồi quên. Nếu không ai cần phát lại quá khứ, kiểm tra event cũ, hoặc thêm consumer mới sau này, queue giữ mọi thứ đơn giản hơn.
Queue phù hợp cho các job nền: gửi email đăng ký, thay đổi kích thước ảnh sau khi tải lên, tạo báo cáo hàng đêm, hoặc gọi API bên ngoài chậm. Trong những trường hợp này message chỉ là vé công việc. Khi worker hoàn thành, vé cũng hoàn thành.
Queue cũng phù hợp mô hình ownership: một consumer group chịu trách nhiệm xử lý công việc, và các dịch vụ khác không mong đọc cùng message đó độc lập.
Queue thường đủ khi hầu hết điều sau đây đúng:
- Dữ liệu có giá trị trong thời gian ngắn.
- Một đội hoặc một dịch vụ sở hữu công việc từ đầu đến cuối.
- Không cần phát lại hay retention dài.
- Gỡ lỗi không phụ thuộc vào phát lại lịch sử.
Ví dụ: một sản phẩm upload ảnh người dùng. App ghi một task “resize image” vào queue. Worker A lấy, tạo thumbnails, lưu, và đánh dấu task xong. Nếu task chạy hai lần, kết quả giống nhau (idempotent), nên at-least-once delivery là ổn. Không có dịch vụ khác cần đọc task đó sau này.
Nếu nhu cầu bắt đầu chuyển sang các fact được chia sẻ (nhiều consumer), phát lại, audit, hoặc “hệ thống tin gì tuần trước?”, đó là lúc Kafka event streaming và cách tiếp cận dựa trên nhật ký bắt đầu có lợi.
Khi nào cách tiếp cận dựa trên nhật ký đáng giá
Một hệ thống dựa trên nhật ký có lợi khi event không còn là tin nhắn một lần mà bắt đầu là lịch sử được chia sẻ. Thay vì “gửi rồi quên”, bạn giữ một bản ghi có thứ tự mà nhiều đội có thể đọc, bây giờ hoặc sau, theo tốc độ riêng.
Tín hiệu rõ nhất là nhiều consumer. Một event như OrderPlaced có thể cung cấp dữ liệu cho billing, email, kiểm tra gian lận, indexing tìm kiếm và analytics. Với nhật ký, mỗi consumer đọc cùng luồng độc lập. Bạn không phải xây pipeline fan-out tùy chỉnh hay phối hợp ai nhận message trước.
Một lợi ích khác là khả năng trả lời “Chúng ta biết gì lúc đó?” Nếu khách hàng tranh chấp một khoản, hoặc đề xuất sai, lịch sử append-only cho phép bạn phát lại các fact theo thứ tự đến để điều tra. Dấu vết kiểm toán đó khó thêm vào queue đơn giản về sau.
Bạn cũng có một cách thực tế để thêm tính năng mà không phải viết lại thứ cũ. Nếu bạn thêm trang “trạng thái vận chuyển” vài tháng sau, một service mới có thể subscribe và backfill từ lịch sử có sẵn để xây trạng thái thay vì yêu cầu hệ thống upstream xuất dữ liệu.
Một cách tiếp cận dựa trên nhật ký thường đáng giá khi bạn nhận ra một hoặc nhiều nhu cầu sau:
- Cùng một events phải cấp dữ liệu cho nhiều hệ thống (analytics, search, billing, công cụ hỗ trợ).\n- Cần phát lại, kiểm toán, hoặc điều tra dựa trên fact quá khứ.\n- Dịch vụ mới cần backfill từ lịch sử mà không tạo job một lần.\n- Thứ tự quan trọng theo thực thể (theo order, theo user).\n- Định dạng event sẽ tiến hoá và bạn cần cách kiểm soát versioning.
Một mô hình phổ biến là sản phẩm bắt đầu với orders và emails. Sau này finance muốn báo cáo doanh thu, product muốn funnels, ops muốn dashboard trực tiếp. Nếu mỗi nhu cầu mới buộc bạn copy dữ liệu qua pipeline mới, chi phí sẽ tăng nhanh. Một event log chung cho phép các đội xây trên cùng nguồn sự thật, ngay cả khi hệ thống lớn và cấu trúc event thay đổi.
Cách quyết định, từng bước
Chọn giữa queue đơn giản và cách tiếp cận dựa trên nhật ký dễ hơn khi bạn coi đó là quyết định sản phẩm. Bắt đầu từ những gì bạn cần đúng sau một năm, không chỉ điều phù hợp trong tuần này.
5 bước thực tế để quyết định
-
Vẽ sơ đồ publishers và readers. Ghi ra ai tạo event và ai đọc hôm nay, rồi thêm các consumer có thể có trong tương lai (analytics, indexing, kiểm tra gian lận, thông báo khách hàng). Nếu bạn kỳ vọng nhiều đội sẽ đọc cùng event độc lập, nhật ký bắt đầu có ý nghĩa.
-
Hỏi liệu bạn sẽ cần đọc lại lịch sử. Hãy cụ thể vì sao: phát lại sau bug, backfills, hoặc consumer đọc ở tốc độ khác nhau. Queue tốt để giao công việc một lần. Log tốt khi bạn muốn một bản ghi có thể phát lại.
-
Xác định “done” nghĩa là gì. Với một vài workflow, done là “job chạy xong” (gửi email, resize ảnh). Với workflow khác, done là “event là một sự thật bền” (một order được đặt, một thanh toán được ủy quyền). Sự thật bền đẩy bạn về phía nhật ký.
-
Chọn mong đợi giao nhận và quyết định cách xử lý trùng lặp. At-least-once delivery là phổ biến, nghĩa là trùng lặp có thể xảy ra. Nếu trùng lặp gây hại (double-charge), lên kế hoạch idempotency: lưu event ID đã xử lý, dùng ràng buộc duy nhất, hoặc làm cập nhật an toàn khi lặp lại.
-
Bắt đầu với một lát mỏng. Chọn một chủ đề event dễ hiểu và mở rộng dần. Nếu bạn dùng Kafka event streaming, giữ topic đầu tiên tập trung, đặt tên event rõ ràng, và tránh trộn lẫn các loại event không liên quan.
Ví dụ cụ thể: nếu OrderPlaced sau này sẽ cấp dữ liệu cho shipping, invoicing, support và analytics, một nhật ký cho phép mỗi đội đọc theo tốc độ riêng và phát lại sau lỗi. Nếu bạn chỉ cần worker nền gửi email biên nhận, queue đơn giản thường đủ.
Ví dụ: các event đơn hàng trong sản phẩm đang lớn lên
Tưởng tượng một cửa hàng trực tuyến nhỏ. Ban đầu chỉ cần nhận order, charge thẻ, và tạo yêu cầu vận chuyển. Phiên bản dễ nhất là một background job chạy sau checkout: “process order.” Nó gọi API thanh toán, cập nhật hàng trong database, rồi gọi dịch vụ vận chuyển.
Kiểu queue đó ổn khi chỉ có một workflow rõ ràng, chỉ cần một consumer (worker), và retry cùng dead letter xử lý hầu hết lỗi.
Nó bắt đầu gây khó khi cửa hàng phát triển. Support muốn cập nhật “đơn hàng của tôi ở đâu?” tự động. Finance cần số liệu doanh thu hàng ngày. Product muốn email khách hàng. Cần kiểm tra gian lận trước khi giao hàng. Với một job “process order” duy nhất, bạn sẽ sửa worker liên tục, thêm nhiều nhánh, và dễ gây bug trong luồng lõi.
Với cách tiếp cận dựa trên nhật ký, checkout phát các fact nhỏ dưới dạng event, và mỗi đội xây trên chúng. Các event tiêu biểu:
OrderPlaced\n- PaymentConfirmed\n- ItemShipped\n- RefundIssued
Thay đổi quan trọng là ownership. Service checkout sở hữu OrderPlaced. Service payments sở hữu PaymentConfirmed. Shipping sở hữu ItemShipped. Sau này, consumer mới có thể xuất hiện mà không cần thay producer: một service gian lận đọc OrderPlaced và PaymentConfirmed để chấm điểm rủi ro, một service email gửi biên nhận, analytics xây funnel, và công cụ hỗ trợ giữ timeline.
Đây là lúc Kafka event streaming phát huy: nhật ký giữ lịch sử, nên consumer mới có thể tua và bắt kịp từ đầu (hoặc từ một điểm biết trước) thay vì yêu cầu upstream thêm webhook.
Nhật ký vẫn không thay thế database. Bạn vẫn cần database cho trạng thái hiện tại: trạng thái order mới nhất, hồ sơ khách hàng, số lượng tồn kho, và các quy tắc giao dịch (như “không giao cho tới khi thanh toán xác nhận”). Hãy coi nhật ký như bản ghi các thay đổi và database là nơi bạn truy vấn “bây giờ cái gì là đúng”.
Những sai lầm và bẫy thường gặp
Event streaming có thể khiến hệ thống cảm thấy sạch hơn, nhưng vài sai lầm phổ biến có thể xóa lợi ích rất nhanh. Phần lớn xuất phát từ việc coi event log như một chiếc điều khiển từ xa thay vì là một bản ghi.
Một bẫy thường gặp là viết event như các command, kiểu “SendWelcomeEmail” hoặc “ChargeCardNow.” Điều đó làm consumer bị couple chặt với ý định của bạn. Event hiệu quả hơn khi là fact: “UserSignedUp” hoặc “PaymentAuthorized.” Fact dễ dùng lại sau này.
Trùng lặp và retry là nguồn đau kế tiếp. Trong hệ thống thực tế, producer retry và consumer xử lý lại. Nếu bạn không chuẩn bị, sẽ có double charge, double email, và vé hỗ trợ phàn nàn. Cách sửa không phức tạp nhưng cần có kế hoạch: handler idempotent, event ID ổn định, và quy tắc nghiệp vụ phát hiện “đã áp dụng”.
Các lỗi phổ biến:
- Dùng event kiểu command ra lệnh service phải làm gì thay vì ghi điều đã xảy ra.\n- Xây consumer mà vỡ khi thấy cùng event hai lần.\n- Chia stream quá sớm, khiến một luồng nghiệp vụ bị tán ra nhiều topic.\n- Bỏ qua quy tắc schema cho tới khi một thay đổi nhỏ làm vỡ consumer cũ.\n- Coi streaming là thay thế cho thiết kế database tốt.
Schema và versioning cần được chú ý đặc biệt. Dù bạn bắt đầu với JSON, bạn vẫn cần hợp đồng rõ ràng: trường bắt buộc, trường tuỳ chọn, và cách rollout thay đổi. Một thay đổi nhỏ như đổi tên trường có thể âm thầm làm vỡ analytics, billing, hoặc app mobile cập nhật chậm.
Một bẫy khác là phân tách quá mức. Các đội đôi khi tạo một stream mới cho mỗi tính năng. Một tháng sau, không ai trả lời được “Trạng thái hiện tại của order là gì?” vì câu chuyện bị trải khắp nơi.
Event streaming không loại bỏ nhu cầu về mô hình dữ liệu vững chắc. Bạn vẫn cần database biểu diễn sự thật hiện tại. Nhật ký là lịch sử, không phải toàn bộ ứng dụng.
Checklist nhanh và các bước tiếp theo
Nếu bạn phân vân giữa queue và Kafka event streaming, bắt đầu với vài kiểm tra nhanh. Chúng sẽ cho bạn biết bạn cần một handoff đơn giản giữa worker hay một nhật ký có thể tái sử dụng trong nhiều năm.
Kiểm tra nhanh
- Bạn có cần phát lại (cho backfills, sửa lỗi, hoặc tính năng mới), và cần lùi bao xa?\n- Hơn một consumer sẽ cần cùng event ngay bây giờ hoặc sớm (analytics, search, email, fraud, billing)?\n- Bạn có cần retention để các đội đọc lại lịch sử mà không yêu cầu producer gửi lại?\n- Thứ tự quan trọng tới mức nào, và ở mức nào: theo thực thể (theo order, theo user) hay toàn cục?\n- Consumer có thể idempotent không (an toàn khi thử lại cùng event mà không bị double-charge, double-email, hay double-update)?
Nếu bạn trả lời “không” cho phát lại, “một consumer duy nhất”, và “tin nhắn sống ngắn”, queue cơ bản thường đủ. Nếu bạn trả lời “có” cho phát lại, nhiều consumer, hoặc retention dài, cách tiếp cận dựa trên nhật ký có xu hướng có lợi vì nó biến một luồng fact thành nguồn chung để hệ thống khác xây dựng lên.
Các bước tiếp theo
Biến trả lời thành kế hoạch nhỏ, có thể thử nghiệm.
- Liệt kê 5–10 event cốt lõi bằng ngôn ngữ đơn giản (ví dụ: OrderPlaced, PaymentAuthorized, OrderShipped) và ghi ai publish và ai consume mỗi event.\n- Quyết định khoá sắp xếp (thường theo thực thể, như orderId) và ghi rõ “thứ tự đúng” nghĩa là gì.\n- Định nghĩa quy tắc idempotency cho mỗi consumer (ví dụ: lưu last processed event ID cho mỗi order).\n- Chọn retention phù hợp (vài ngày cho workflow kiểu queue, vài tuần/tháng khi phát lại quan trọng).\n- Chạy một lát end-to-end trong sandbox trước khi cam kết toàn bộ hệ thống.
Nếu bạn prototype nhanh, bạn có thể phác thảo luồng event trong chế độ planning của Koder.ai và lặp trên thiết kế trước khi khoá tên event và quy tắc retry. Vì Koder.ai hỗ trợ xuất mã nguồn, snapshot và rollback, nó cũng là cách thực tế để thử một producer-consumer slice và điều chỉnh event shape mà không biến thí nghiệm đầu thành nợ kỹ thuật.