Kafka bằng ngôn ngữ đơn giản
Apache Kafka là một nền tảng streaming sự kiện phân tán. Nói một cách đơn giản, đó là một “ống” chung, bền bỉ cho phép nhiều hệ thống xuất bản các sự kiện về những gì đã xảy ra và cho phép hệ thống khác đọc những sự kiện đó—nhanh, ở quy mô lớn, và có thứ tự.
Các nhóm dùng Kafka khi dữ liệu cần di chuyển đáng tin cậy giữa các hệ thống mà không tạo sự phụ thuộc chặt. Thay vì một ứng dụng gọi trực tiếp ứng dụng khác (và thất bại khi nó bị down hoặc chậm), các producer ghi sự kiện vào Kafka. Các consumer đọc khi họ sẵn sàng. Kafka lưu sự kiện trong một khoảng thời gian có thể cấu hình, nên các hệ thống có thể phục hồi sau sự cố và thậm chí xử lý lại lịch sử.
Một vài thuật ngữ bạn sẽ gặp
- Event / Message: Một bản ghi về điều gì đó đã xảy ra (ví dụ: “OrderPlaced” hoặc “PaymentFailed”). Người dùng Kafka thường gọi là “message”, nhưng “event” nhấn mạnh rằng nó đại diện cho một thay đổi trong thế giới thực.
- Stream: Dòng chảy liên tục của các sự kiện theo thời gian.
- Log: Kafka tổ chức sự kiện như một log chỉ cho phép nối thêm—sự kiện mới được thêm vào cuối, và người đọc tiến lên theo tốc độ của riêng họ.
Ai là độc giả của hướng dẫn này (và bạn sẽ học gì)
Hướng dẫn này dành cho kỹ sư quan tâm sản phẩm, những người làm dữ liệu và lãnh đạo kỹ thuật muốn một mô hình tư duy thực tiễn về Kafka.
Bạn sẽ học các khối xây dựng cốt lõi (producers, consumers, topics, brokers), cách Kafka mở rộng bằng partitions, cách nó lưu trữ và phát lại sự kiện, và nơi nó phù hợp trong kiến trúc hướng sự kiện. Chúng tôi cũng sẽ đề cập các trường hợp sử dụng phổ biến, đảm bảo giao hàng, bảo mật cơ bản, kế hoạch vận hành, và khi nào Kafka phù hợp (hoặc không phù hợp).
Khái niệm cốt lõi: Producers, Consumers, Topics, Brokers
Kafka dễ hiểu nhất như một log sự kiện chung: ứng dụng ghi sự kiện vào đó, và ứng dụng khác đọc những sự kiện đó sau—thường là theo thời gian thực, đôi khi là vài giờ hoặc vài ngày sau.
Producers và consumers
Producers là những thành phần ghi. Một producer có thể xuất bản một sự kiện như “order placed”, “payment confirmed”, hoặc “temperature reading”. Producers không gửi sự kiện trực tiếp tới app cụ thể—họ gửi chúng tới Kafka.
Consumers là những thành phần đọc. Một consumer có thể cung cấp dữ liệu cho dashboard, kích hoạt workflow giao hàng, hoặc nạp dữ liệu vào hệ thống phân tích. Consumers quyết định làm gì với sự kiện, và họ có thể đọc theo tốc độ của riêng mình.
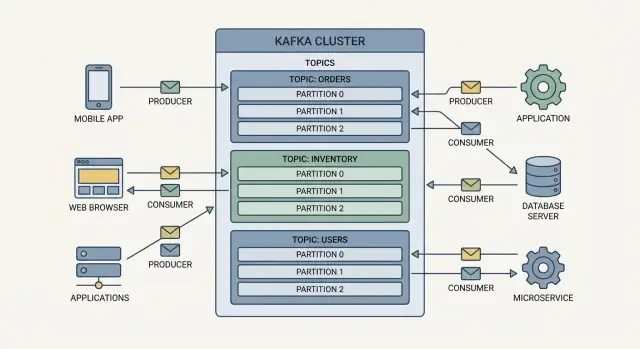
Topics: tổ chức sự kiện
Các sự kiện trong Kafka được nhóm vào topics, cơ bản là các danh mục có tên. Ví dụ:
orders cho các sự kiện liên quan đơn hàngpayments cho sự kiện thanh toáninventory cho thay đổi tồn kho
Một topic trở thành “nguồn chân lý” cho dòng sự kiện loại đó, giúp nhiều nhóm tái sử dụng cùng dữ liệu mà không phải xây dựng các tích hợp lẻ tẻ.
Brokers và cụm
Một broker là một máy chủ Kafka lưu trữ sự kiện và phục vụ chúng cho consumer. Trong thực tế, Kafka chạy như một cụm (nhiều broker phối hợp) để xử lý lưu lượng lớn hơn và tiếp tục hoạt động ngay cả khi một máy chủ hỏng.
Consumer groups: mở rộng người đọc mà không trùng lặp công việc
Consumers thường chạy trong một consumer group. Kafka phân phối công việc đọc qua nhóm, nên bạn có thể thêm nhiều instance consumer để mở rộng xử lý—mà không phải mọi instance đều làm cùng một việc.
Cách topics và partitions giúp Kafka mở rộng
Kafka mở rộng bằng cách chia công việc thành topics (dòng các sự kiện liên quan) rồi chia mỗi topic thành partitions (mảnh độc lập nhỏ hơn của dòng đó).
Partitions = song song và throughput
Một topic có một partition chỉ có thể được đọc bởi một consumer trong cùng một consumer group tại một thời điểm. Thêm partition, và bạn có thể thêm nhiều consumer để xử lý sự kiện song song. Đó là cách Kafka hỗ trợ streaming sự kiện với khối lượng lớn và pipeline dữ liệu thời gian thực mà không biến mọi hệ thống thành điểm nghẽn.
Partitions cũng giúp phân tán tải lên các broker. Thay vì một máy chịu tất cả ghi và đọc cho một topic, nhiều broker có thể lưu các partition khác nhau và chia sẻ lưu lượng.
Thứ tự: Kafka đảm bảo những gì (và không đảm bảo gì)
Kafka đảm bảo thứ tự trong một partition duy nhất. Nếu sự kiện A, B và C được ghi vào cùng một partition theo thứ tự đó, consumer sẽ đọc chúng A → B → C.
Thứ tự giữa các partition không được đảm bảo. Nếu bạn cần thứ tự nghiêm ngặt cho một thực thể cụ thể (như một khách hàng hoặc đơn hàng), bạn thường đảm bảo tất cả sự kiện cho thực thể đó vào cùng một partition.
Key quyết định sự kiện đi đâu
Khi producer gửi một sự kiện, họ có thể kèm một key (ví dụ order_id). Kafka dùng key để định tuyến nhất quán các sự kiện liên quan về cùng một partition. Điều đó cho bạn thứ tự dự đoán được cho key đó trong khi vẫn cho phép topic mở rộng trên nhiều partition.
Replica giữ dữ liệu luôn sẵn sàng
Mỗi partition có thể được replicate sang các broker khác. Nếu một broker bị hỏng, broker khác có replica có thể tiếp quản. Sao chép là lý do chính khiến Kafka được tin tưởng cho pub-sub messaging và hệ thống hướng sự kiện quan trọng: nó cải thiện tính khả dụng và hỗ trợ chịu lỗi mà không yêu cầu mọi ứng dụng phải tự xây dựng logic failover.
Lưu trữ, retention và phát lại sự kiện
Một ý tưởng then chốt của Apache Kafka là các sự kiện không chỉ được truyền đi rồi quên. Chúng được ghi vào đĩa theo một log có thứ tự, nên consumer có thể đọc bây giờ—hoặc sau này. Điều này làm Kafka hữu ích không chỉ để di chuyển dữ liệu, mà còn để giữ một lịch sử bền vững về những gì đã xảy ra.
Sự kiện được lưu, không chỉ “đang chuyển”
Khi producer gửi một sự kiện tới một topic, Kafka nối nó vào lưu trữ trên broker. Consumers sau đó đọc từ log đã lưu đó theo tốc độ của họ. Nếu một consumer offline một giờ, các sự kiện vẫn tồn tại và có thể bắt kịp khi nó phục hồi.
Retention: Kafka giữ dữ liệu bao lâu
Kafka giữ sự kiện theo chính sách retention:
- Retention theo thời gian: giữ sự kiện trong một khoảng thời gian xác định (ví dụ 7 ngày).
- Retention theo kích thước: giữ sự kiện cho đến khi log đạt kích thước cấu hình, rồi xóa dữ liệu cũ nhất.
Retention được cấu hình theo topic, cho phép bạn xử lý khác nhau giữa các topic “audit trail” và topic telemetry có lưu lượng cao.
Compaction: giữ giá trị mới nhất cho mỗi key
Một số topic giống như changelog hơn là kho lịch sử—ví dụ “cài đặt khách hàng hiện tại.” Log compaction giữ ít nhất bản ghi mới nhất cho mỗi key, trong khi các bản ghi cũ hơn có thể bị loại bỏ. Bạn vẫn có một nguồn chân lý bền vững cho trạng thái mới nhất, mà không làm tăng trưởng không giới hạn.
Phát lại sự kiện: xây dựng lại trạng thái và phục hồi sau lỗi
Vì sự kiện được lưu, bạn có thể phát lại chúng để tái tạo trạng thái:
- Xây dựng lại chỉ mục tìm kiếm hoặc materialized view từ đầu
- Phục hồi dịch vụ sau một bản triển khai sai bằng cách xử lý lại từ một điểm trước đó
- Onboard một consumer mới và cho nó đọc dữ liệu lịch sử
Trong thực tế, phát lại được điều khiển bằng nơi consumer “bắt đầu đọc” (offset), mang lại một lớp bảo vệ mạnh mẽ khi hệ thống phát triển.
Những điều cơ bản về độ tin cậy và chịu lỗi
Kafka được thiết kế để giữ dữ liệu chảy ngay cả khi một phần hệ thống gặp lỗi. Nó làm điều này bằng replication, các quy tắc rõ ràng về ai là “trưởng” của mỗi partition, và acknowledgments có thể cấu hình.
Replication: leader và follower (ở mức cao)
Mỗi partition có một broker leader và một hoặc nhiều follower replica trên các broker khác. Producers và consumers nói chuyện với leader cho partition đó.
Followers liên tục sao chép dữ liệu của leader. Nếu leader bị hỏng, Kafka có thể thăng một follower đã bắt kịp lên làm leader mới, giúp partition tiếp tục khả dụng.
Chuyện gì xảy ra khi broker thất bại (tóm tắt)
Nếu một broker chết, các partition mà nó đang làm leader sẽ tạm thời không khả dụng. Controller của Kafka (điều phối nội bộ) phát hiện lỗi và kích hoạt leader election cho các partition đó.
Nếu ít nhất một replica follower đủ bắt kịp, nó có thể tiếp quản làm leader và client tiếp tục produce/consume. Nếu không có replica nào đồng bộ, Kafka có thể tạm dừng ghi (tùy cấu hình) để tránh mất dữ liệu đã được xác nhận.
Durability: acknowledgments và replication factor
Hai nút điều chỉnh chính ảnh hưởng durability:
- Replication factor: có bao nhiêu bản sao của mỗi partition tồn tại (ví dụ 3 bản trên 3 broker).
- Acknowledgments (acks): khi nào producer coi một ghi là thành công.
Ở mức khái niệm:
- acks=0: producer không chờ—nhanh, nhưng bạn có thể mất message.
- acks=1: leader xác nhận ghi—tốt hơn, nhưng nếu leader chết trước khi followers sao chép dữ liệu, bạn có thể mất message vừa viết.
- acks=all (hoặc -1): leader chờ các replica “đang đồng bộ” xác nhận—an toàn hơn, thường chậm hơn một chút.
Để giảm trùng lặp khi retry, các nhóm thường kết hợp acks an toàn với producers idempotent và xử lý consumer chặt chẽ (được đề cập sau).
Thỏa hiệp độ trễ và an toàn
An toàn cao hơn thường nghĩa là chờ nhiều xác nhận hơn và giữ nhiều replica đồng bộ, điều này có thể làm tăng độ trễ và giảm throughput đỉnh.
Cấu hình độ trễ thấp có thể phù hợp cho telemetry hoặc clickstream nơi mất mát thỉnh thoảng chấp nhận được, nhưng thanh toán, tồn kho và audit logs thường đáng để đánh đổi cho an toàn cao hơn.
Vai trò của Kafka trong kiến trúc hướng sự kiện
Sở hữu codebase
Giữ toàn quyền kiểm soát bằng cách xuất mã nguồn khi bạn sẵn sàng đi xa hơn prototype.
Kiến trúc hướng sự kiện (EDA) là cách xây dựng hệ thống nơi các sự kiện doanh nghiệp—một đơn hàng được đặt, thanh toán được xác nhận, một gói được gửi—được biểu diễn như sự kiện mà các phần khác của hệ thống có thể phản ứng.
Xuất bản sự kiện, phản ứng bằng consumer
Kafka thường nằm ở trung tâm của EDA như “luồng sự kiện chung.” Thay vì Service A gọi Service B trực tiếp, Service A xuất bản một sự kiện (ví dụ OrderCreated) lên topic Kafka. Bất kỳ số lượng dịch vụ nào cũng có thể tiêu thụ sự kiện đó và hành động—gửi email, đặt giữ tồn kho, khởi chạy kiểm tra gian lận—mà không cần Service A biết tới họ tồn tại.
Giảm chặt coupling (ít phụ thuộc trực tiếp)
Vì các dịch vụ giao tiếp qua sự kiện, họ không phải phối hợp API request/response cho mọi tương tác. Điều này giảm sự phụ thuộc chặt giữa các nhóm và làm cho việc thêm tính năng mới dễ dàng hơn: bạn có thể thêm một consumer mới cho một sự kiện có sẵn mà không thay đổi producer.
Workflow bất đồng bộ và chống đột biến tải
EDA bản chất là bất đồng bộ: producers ghi sự kiện nhanh, và consumers xử lý chúng theo tốc độ của họ. Trong lúc tải đột biến, Kafka giúp đệm luồng để hệ thống hạ nguồn không bị quá tải ngay lập tức. Consumers có thể mở rộng để bắt kịp, và nếu một consumer tạm thời chết, nó có thể tiếp tục từ nơi đã dừng.
Mô hình tư duy thực tiễn
Hãy nghĩ về Kafka như “luồng hoạt động” của hệ thống. Producers xuất bản các thực tế; consumers đăng ký nhận các thực tế họ quan tâm. Mẫu này cho phép pipeline dữ liệu thời gian thực và workflow hướng sự kiện trong khi giữ các dịch vụ đơn giản và độc lập hơn.
Các trường hợp sử dụng Kafka phổ biến trong hệ thống hiện đại
Kafka xuất hiện khi các nhóm cần di chuyển nhiều “sự kiện nhỏ đã xảy ra” giữa các hệ thống—nhanh, đáng tin cậy và sao cho nhiều consumer có thể tái sử dụng.
Theo dõi hoạt động và audit logs
Ứng dụng thường cần một lịch sử append-only: đăng nhập người dùng, thay đổi quyền, cập nhật bản ghi, hoặc hành động admin. Kafka hoạt động tốt như một luồng trung tâm của các sự kiện này, để công cụ bảo mật, báo cáo và xuất dữ liệu tuân thủ có thể đọc cùng nguồn mà không tăng tải lên cơ sở dữ liệu sản xuất. Bởi vì sự kiện được giữ theo thời gian, bạn cũng có thể phát lại để xây dựng lại view audit sau lỗi hoặc thay đổi schema.
Giao tiếp microservices qua sự kiện
Thay vì các service gọi nhau trực tiếp, họ có thể xuất bản sự kiện như “order created” hoặc “payment received.” Các service khác đăng ký và phản ứng theo thời gian của riêng họ. Điều này giảm coupling chặt, giúp hệ thống hoạt động trong tình trạng lỗi từng phần, và làm cho việc thêm tính năng mới (ví dụ kiểm tra gian lận) đơn giản bằng cách tiêu thụ luồng sự kiện hiện có.
Pipeline dữ liệu tới analytics và kho dữ liệu
Kafka thường là xương sống để di chuyển dữ liệu từ hệ thống vận hành vào nền tảng analytics. Các nhóm có thể stream thay đổi từ cơ sở dữ liệu ứng dụng và chuyển tới warehouse hoặc data lake với độ trễ thấp, trong khi giữ ứng dụng sản xuất tách biệt khỏi các truy vấn phân tích nặng.
IoT và telemetry với lưu lượng đột biến
Cảm biến, thiết bị và telemetry ứng dụng thường tới theo từng cơn. Kafka có thể hấp thụ đột biến, đệm an toàn và cho phép xử lý phía sau bắt kịp—hữu ích cho giám sát, cảnh báo và phân tích dài hạn.
Hệ sinh thái Kafka: Connect, Streams và công cụ
Kafka không chỉ là brokers và topics. Hầu hết các nhóm phụ thuộc vào công cụ bổ trợ giúp Kafka thực tế cho việc di chuyển dữ liệu hàng ngày, xử lý stream và vận hành.
Kafka Connect: di chuyển dữ liệu mà không cần mã tùy chỉnh
Kafka Connect là framework tích hợp của Kafka để đưa dữ liệu vào Kafka (sources) và ra khỏi Kafka (sinks). Thay vì xây dựng và vận hành các pipeline tùy biến, bạn chạy Connect và cấu hình connector.
Ví dụ phổ biến: kéo thay đổi từ cơ sở dữ liệu, ingest sự kiện SaaS, hoặc đẩy dữ liệu Kafka vào data warehouse hoặc object storage. Connect cũng chuẩn hóa các vấn đề vận hành như retry, offset và phân luồng.
Kafka Streams: xử lý thời gian thực bên trong ứng dụng
Nếu Connect là cho tích hợp, Kafka Streams là cho tính toán. Đó là một thư viện bạn thêm vào ứng dụng để biến đổi luồng theo thời gian thực—lọc sự kiện, enrich, join luồng, và xây dựng các aggregate (như “orders per minute”).
Vì Streams apps đọc từ topic và ghi lại vào topic, chúng phù hợp tự nhiên trong hệ thống hướng sự kiện và có thể mở rộng bằng cách thêm instance.
Quản lý schema: giữ sự kiện nhất quán
Khi nhiều nhóm xuất bản sự kiện, tính nhất quán quan trọng. Quản lý schema (thường qua schema registry) định nghĩa các trường sự kiện và cách chúng tiến hóa theo thời gian. Điều này giúp tránh các lỗi như producer đổi tên trường mà consumer đang phụ thuộc.
Công cụ: giám sát các chỉ số quan trọng
Kafka nhạy cảm về vận hành, nên giám sát cơ bản là cần thiết:
- Consumer lag: consumer có đang tụt lại không?
- Throughput: bao nhiêu sự kiện mỗi giây đang chảy?
- Errors: fetch thất bại, produce errors, lỗi connector task
Hầu hết các nhóm cũng dùng UI quản lý và tự động hóa cho deployment, cấu hình topic và chính sách truy cập (xem /blog/kafka-security-governance).
Các mô hình giao hàng và xử lý
Gửi một dashboard cho consumer
Tạo một dashboard nội bộ nhẹ để đọc từ Kafka và hiển thị lag cùng throughput.
Kafka thường được mô tả là “log bền + consumers”, nhưng điều các nhóm thực sự quan tâm là: tôi sẽ xử lý mỗi sự kiện một lần không, và chuyện gì xảy ra khi có lỗi? Kafka cung cấp các khối xây dựng, và bạn chọn thỏa hiệp.
Cam kết giao hàng (ở mức cao)
At-most-once nghĩa là bạn có thể mất sự kiện, nhưng không xử lý trùng lặp. Điều này xảy ra nếu consumer commit vị trí trước rồi crash trước khi hoàn tất công việc.
At-least-once nghĩa là bạn sẽ không mất sự kiện, nhưng có thể có trùng lặp (ví dụ consumer xử lý xong một sự kiện, crash, rồi xử lý lại sau khi khởi động). Đây là mặc định phổ biến nhất.
Exactly-once nhằm tránh cả mất mát và trùng lặp end-to-end. Trong Kafka, điều này thường liên quan tới producer giao dịch (transactional producers) và xử lý tương thích (thường qua Kafka Streams). Nó mạnh mẽ nhưng bị ràng buộc hơn và yêu cầu thiết lập cẩn thận.
Idempotency và loại trùng
Trong thực tế, nhiều hệ thống chấp nhận at-least-once và thêm biện pháp an toàn:
- Ghi idempotent: làm cho bước “áp dụng sự kiện” an toàn khi lặp lại (ví dụ upsert, cập nhật có điều kiện, khóa duy nhất).
- Loại trùng: lưu ID sự kiện (hoặc business key) và bỏ qua lặp lại trong một cửa sổ thời gian.
Offsets của consumer: “dấu trang” của bạn
Offset là vị trí của bản ghi đã xử lý cuối cùng trong một partition. Khi bạn commit offset, bạn nói “Tôi đã xong tới đây.” Commit quá sớm thì rủi ro mất; commit quá muộn thì tăng khả năng trùng lặp sau lỗi.
Retry và poison messages
Retry nên có giới hạn và hiển thị. Một mẫu phổ biến:
- retry với backoff cho lỗi tạm thời,
- rồi chuyển bản ghi lỗi sang dead-letter topic để kiểm tra và phát lại sau.
Cách này giữ cho một “poison message” không làm tắc toàn bộ consumer group trong khi vẫn bảo toàn dữ liệu để sửa sau.
Bảo mật và quản trị
Kafka thường mang các sự kiện quan trọng của doanh nghiệp (đơn hàng, thanh toán, hoạt động người dùng). Điều này làm cho bảo mật và quản trị là một phần thiết kế, không phải việc làm sau.
Xác thực và phân quyền
Xác thực trả lời “bạn là ai?” Phân quyền trả lời “bạn được phép làm gì?” Trong Kafka, xác thực thường dùng SASL (ví dụ SCRAM hoặc Kerberos), trong khi phân quyền được áp dụng bằng ACL ở mức topic, consumer group và cluster.
Một mẫu thực tế là least privilege: producers chỉ được ghi vào các topic họ sở hữu, và consumers chỉ được đọc các topic họ cần. Điều này giảm lộ dữ liệu tình cờ và giới hạn phạm vi hư hại nếu credential bị lộ.
Mã hóa khi truyền (TLS)
TLS mã hóa dữ liệu khi di chuyển giữa app, broker và công cụ. Nếu không có TLS, sự kiện có thể bị chặn trên mạng nội bộ, không chỉ internet công cộng. TLS cũng giúp ngăn tấn công “man-in-the-middle” bằng cách xác thực danh tính broker.
Kafka đa tenant và quy ước đặt tên
Khi nhiều nhóm chia sẻ một cụm, cần có guardrails. Quy ước đặt tên topic rõ ràng (ví dụ <team>.<domain>.<event>.<version>) làm rõ quyền sở hữu và giúp công cụ áp dụng chính sách nhất quán.
Kết hợp quy ước tên với quota và mẫu ACL để một workload ồn ào không làm nghẽn những workload khác, và để dịch vụ mới bắt đầu với cấu hình an toàn.
Quản trị dữ liệu: PII, retention và tuân chỉnh
Xử lý Kafka như một hệ thống lưu trữ lịch sử sự kiện chỉ khi bạn có ý định. Nếu sự kiện chứa PII, dùng giảm thiểu dữ liệu (gửi ID thay vì profile đầy đủ), cân nhắc mã hóa trường, và ghi rõ topic nào nhạy cảm.
Cài đặt retention nên khớp với yêu cầu pháp lý và doanh nghiệp. Nếu chính sách yêu cầu “xóa sau 30 ngày”, đừng giữ 6 tháng “phòng trường hợp”. Đánh giá và kiểm tra định kỳ giúp cấu hình phù hợp khi hệ thống thay đổi.
Vận hành Kafka: Những gì nhóm cần lên kế hoạch
Scaffold producers và consumers
Để Koder.ai scaffold dịch vụ xung quanh các topic Kafka của bạn, sau đó lặp cải tiến chi tiết.
Chạy Apache Kafka không chỉ là “cài và quên”. Nó hoạt động như một tiện ích chia sẻ: nhiều nhóm phụ thuộc vào nó, và sai sót nhỏ có thể lan sang các ứng dụng hạ nguồn.
Những điều cơ bản về hoạch định năng lực
Năng lực Kafka phần lớn là bài toán tính toán bạn cần xem lại định kỳ. Các con đòn lớn nhất là partitions (song song), throughput (MB/s vào và ra), và tăng trưởng lưu trữ (bao lâu bạn giữ dữ liệu).
Nếu lưu lượng tăng gấp đôi, bạn có thể cần thêm partition để phân tán tải trên các broker, thêm đĩa để chứa retention, và băng thông mạng lớn hơn cho replication. Thói quen thực tế là dự báo tốc độ ghi đỉnh và nhân với retention để ước tính tăng trưởng đĩa, sau đó cộng đệm cho replication và “thành công bất ngờ”.
Công việc vận hành hàng ngày
Mong đợi công việc định kỳ ngoài việc giữ server sống:
- Nâng cấp: lên kế hoạch nâng cấp rolling, kiểm tra tương thích client, và lịch thay đổi khi lưu lượng thấp.
- Rebalancing: consumer group rebalance có thể gây gián đoạn ngắn; bạn cần mẫu triển khai an toàn và quyền sở hữu rõ ràng.
- Ứng phó sự cố: có playbook cho broker thất bại, đĩa đầy, và producer cấu hình sai làm tràn topic.
Các yếu tố chi phí và lựa chọn triển khai
Chi phí bị chi phối bởi đĩa, băng thông mạng, và số lượng/kích thước broker. Managed Kafka có thể giảm gánh nặng nhân sự và đơn giản hóa nâng cấp, trong khi tự quản lý có thể rẻ hơn ở quy mô nếu bạn có đội vận hành giàu kinh nghiệm. Sự đánh đổi là thời gian phục hồi và gánh nặng on-call.
Những gì cần đo (để không đoán mò)
Các nhóm thường giám sát:
- Độ trễ end-to-end (produce tới consume)
- Consumer lag (khoảng cách consumer bị tụt)
- Sức khỏe broker (sử dụng đĩa, under-replicated partitions, tỉ lệ lỗi yêu cầu)
Dashboard và cảnh báo tốt biến Kafka từ “hộp bí ẩn” thành dịch vụ có thể hiểu được.
Khi nào nên dùng Kafka (và khi nào không)
Kafka phù hợp khi bạn cần di chuyển nhiều sự kiện một cách đáng tin cậy, giữ chúng trong một thời gian, và cho phép nhiều hệ thống phản ứng cùng dữ liệu theo tốc độ riêng. Nó đặc biệt hữu ích khi dữ liệu cần phát lại (cho backfill, audit, hoặc tái tạo dịch vụ) và khi bạn dự kiến thêm nhiều producer/consumer theo thời gian.
Thời điểm Kafka tỏa sáng
Kafka thường phù hợp khi bạn có:
- Luồng sự kiện throughput cao (clicks, orders, sensor data)
- Nhiều consumer cần cùng một sự kiện (analytics, monitoring, fraud, notifications)
- Nhu cầu phát lại và lưu lịch sử dài hạn, không chỉ “gửi một lần rồi quên”
- Công việc tích hợp nơi tách rời các nhóm và dịch vụ là quan trọng
Khi Kafka có thể quá nặng
Kafka có thể quá thừa nếu nhu cầu của bạn đơn giản:
- Một hàng đợi dung lượng thấp giữa hai dịch vụ
- Tác vụ ngắn hạn (background jobs) nơi phát lại không có giá trị
- Nhóm không có thời gian để vận hành và giám sát một hệ thống phân tán
Trong các trường hợp này, chi phí vận hành (định cỡ cluster, nâng cấp, giám sát, trực) có thể lớn hơn lợi ích.
Các lựa chọn thay thế và bổ trợ
- RabbitMQ: tốt cho work queues cổ điển và các mẫu routing.
- NATS: messaging nhẹ, độ trễ thấp.
- Cloud pub/sub: phù hợp khi bạn muốn hạ tầng managed và đơn giản hơn vận hành.
Kafka cũng bổ trợ—không thay thế—cơ sở dữ liệu (hệ thống ghi chính), cache (đọc nhanh), và công cụ ETL theo lô (chuyển đổi định kỳ lớn).
Danh sách kiểm tra quyết định nhanh
Hỏi:
- Chúng tôi có cần nhiều consumer và phát lại không?
- Throughput có sẽ tăng đáng kể không?
- Chúng tôi có cần lịch sử sự kiện/retention như một tính năng không?
- Chúng tôi có thể chịu trách nhiệm vận hành (hoặc dùng managed Kafka) không?
- Chúng tôi đang stream sự kiện, không chỉ gửi lệnh/nhiệm vụ?
Nếu bạn trả lời “có” cho đa số, Kafka thường là lựa chọn hợp lý.
Bắt đầu: con đường tiếp cận đơn giản
Kafka phù hợp nhất khi bạn cần một “nguồn chân lý” chia sẻ cho các luồng sự kiện thời gian thực: nhiều hệ thống tạo facts (order created, payment authorized, inventory changed) và nhiều hệ thống tiêu thụ các facts đó để cung cấp pipeline, analytics và tính năng phản ứng.
Bước 1: Chọn một trường hợp sử dụng cụ thể
Bắt đầu với một luồng hẹp, có giá trị cao—như xuất bản sự kiện “OrderPlaced” cho các dịch vụ hạ nguồn (email, fraud checks, fulfillment). Tránh biến Kafka thành hàng đợi tổng hợp trong ngày đầu.
Bước 2: Định nghĩa sự kiện và topics
Ghi ra:
- Events: điều gì đã xảy ra, bằng ngôn ngữ nghiệp vụ đơn giản
- Topics: nơi các sự kiện đó nằm (thường một topic cho mỗi loại sự kiện hoặc miền)
- Consumers: nhóm nào/dịch vụ nào cần sự kiện và vì sao
Giữ schema ban đầu đơn giản và nhất quán (timestamps, IDs, tên sự kiện rõ ràng). Quyết định bạn sẽ bắt buộc schema ngay từ đầu hay tiến hóa cẩn trọng theo thời gian.
Bước 3: Thiết lập quyền sở hữu và điều kiện vận hành cơ bản
Kafka thành công khi có người sở hữu:
- Tạo topic và quy ước đặt tên
- Chính sách retention và truy cập
- Trách nhiệm on-call và runbook
Thêm giám sát ngay từ đầu (consumer lag, sức khỏe broker, throughput, tỉ lệ lỗi). Nếu bạn chưa có team platform, bắt đầu với managed offering và giới hạn rõ ràng.
Bước 4: Xây pipeline “mỏng” đầu tiên
Produce sự kiện từ một hệ thống, tiêu thụ chúng ở một nơi, và chứng minh vòng lặp end-to-end hoạt động. Sau đó mới mở rộng tới nhiều consumer, partition và tích hợp.
Nếu bạn muốn đi nhanh từ “ý tưởng” tới dịch vụ hướng sự kiện hoạt động, các công cụ như Koder.ai có thể giúp bạn prototype phần ứng dụng xung quanh nhanh chóng (giao diện React, backend Go, PostgreSQL) và thêm producers/consumers Kafka theo workflow hướng chat. Nó hữu ích cho việc xây dựng dashboard nội bộ và dịch vụ nhẹ tiêu thụ topic, với các tính năng như planning mode, xuất mã nguồn, triển khai/hosting, và snapshot với rollback.
Nếu bạn đang chuyển sang kiến trúc hướng sự kiện, xem /blog/event-driven-architecture. Để lập kế hoạch chi phí và môi trường, xem /pricing.