03 thg 11, 2025·8 phút
Leslie Lamport và Hệ thống phân tán: Thời gian, Thứ tự, Tính đúng đắn
Tìm hiểu các ý tưởng then chốt của Lamport về hệ thống phân tán — đồng hồ logic, thứ tự, consensus và tính đúng đắn — và lý do chúng vẫn định hướng hạ tầng hiện đại.
Tại sao Lamport vẫn quan trọng với hệ thống phân tán hiện đại
Leslie Lamport là một trong số ít nhà nghiên cứu mà công trình “lý thuyết” của họ xuất hiện mỗi khi bạn ra mắt một hệ thống thực tế. Nếu bạn từng vận hành một cụm cơ sở dữ liệu, hàng đợi tin nhắn, engine workflow, hay bất cứ thứ gì retry yêu cầu và chịu được lỗi, thì bạn đang sống trong những vấn đề mà Lamport đã giúp đặt tên và giải quyết.
Điều làm cho các ý tưởng của ông bền vững là chúng không gắn với một công nghệ cụ thể. Chúng mô tả những sự thật khó chịu xuất hiện bất cứ khi nào nhiều máy cố gắng hành xử như một hệ thống: đồng hồ không đồng bộ, mạng trì hoãn và làm mất tin nhắn, và lỗi là bình thường — không phải ngoại lệ.
Ba chủ đề ta sẽ dùng xuyên suốt
Thời gian: Trong hệ thống phân tán, “bây giờ là mấy giờ?” không phải câu hỏi đơn giản. Đồng hồ vật lý trôi dần, và thứ tự bạn quan sát sự kiện có thể khác nhau giữa các máy.
Thứ tự: Khi bạn không thể tin một đồng hồ duy nhất, bạn cần cách khác để nói sự kiện nào xảy ra trước — và khi nào bạn phải ép mọi người tuân theo cùng một chuỗi.
Tính đúng đắn: “Nó thường hoạt động” không phải một thiết kế. Lamport đẩy lĩnh vực tới những định nghĩa rõ ràng (safety vs. liveness) và các đặc tả bạn có thể lý luận chứ không chỉ test.
Mong đợi gì (không nhiều toán học nặng)
Chúng ta sẽ tập trung vào khái niệm và trực giác: các vấn đề, các công cụ tối thiểu để suy nghĩ rõ ràng, và cách những công cụ đó hình thành thiết kế thực tế.
Bản đồ nội dung:
- Tại sao không có đồng hồ chung thì không có một câu chuyện toàn cục về sự kiện
- Cách nguyên lý nhân quả (“happened-before”) dẫn tới đồng hồ logic và Lamport timestamps
- Khi thứ tự từng phần không đủ và bạn cần một dòng thời gian duy nhất
- Consensus và Paxos liên quan thế nào đến việc đồng ý trên một thứ tự
- Tại sao nhân bản máy trạng thái hoạt động khi thứ tự chung tồn tại
- Cách nói về tính đúng đắn trong spec — và công cụ mô hình như TLA+ giúp thế nào
Vấn đề cốt lõi: Không có đồng hồ chung, không có thực tại duy nhất
Một hệ thống được gọi là “phân tán” khi nó gồm nhiều máy phối hợp qua mạng để làm một việc. Nghe có vẻ đơn giản cho tới khi bạn chấp nhận hai thực tế: máy có thể lỗi độc lập (lỗi từng phần), và mạng có thể trì hoãn, mất, sao chép, hoặc xáo trộn thứ tự tin nhắn.
Trong một chương trình đơn trên một máy, bạn thường có thể chỉ ra “cái gì xảy ra trước”. Trong hệ thống phân tán, các máy khác nhau có thể quan sát các chuỗi sự kiện khác nhau — và cả hai đều có thể đúng theo góc nhìn cục bộ của chúng.
Tại sao bạn không thể tin một đồng hồ toàn cục
Rất dễ bị cám dỗ giải quyết phối hợp bằng cách gắn dấu thời gian cho mọi thứ. Nhưng không có một đồng hồ duy nhất bạn có thể tin cậy giữa các máy:
- Đồng hồ phần cứng của mỗi máy trôi với tốc độ khác nhau.
- Đồng bộ hóa đồng hồ (như NTP) là nỗ lực tốt nhất, không phải đảm bảo.
- Ảo hóa, tải CPU, hoặc tạm dừng có thể làm thời gian nhảy hoặc dừng.
Vì vậy “sự kiện A xảy ra lúc 10:01:05.123” trên một host không so sánh đáng tin với “10:01:05.120” trên host khác.
Cách độ trễ làm xoay vặn thực tại
Độ trễ mạng có thể đảo ngược thứ tự bạn tưởng mình đã thấy. Một ghi có thể được gửi trước nhưng tới sau. Một retry có thể tới sau bản gốc. Hai trung tâm dữ liệu có thể xử lý “cùng” một yêu cầu theo thứ tự ngược nhau.
Điều này khiến việc debug khó: log từ các máy khác nhau có thể mâu thuẫn, và “sắp xếp theo timestamp” có thể tạo ra một câu chuyện chưa từng xảy ra.
Hệ quả thực tế
Khi bạn giả định một dòng thời gian duy nhất mà thực tế không tồn tại, bạn nhận được lỗi cụ thể:
- Xử lý đôi (ví dụ thanh toán bị tính hai lần sau retry)
- Mâu thuẫn (hai người dùng đều “thành công” lấy món hàng cuối)
- Cảm giác mất dữ liệu (một cập nhật đến sau ghi đè lên một cập nhật mới hơn)
Ý tưởng then chốt của Lamport bắt đầu từ đây: nếu bạn không thể chia sẻ thời gian, bạn phải lý luận về thứ tự theo cách khác.
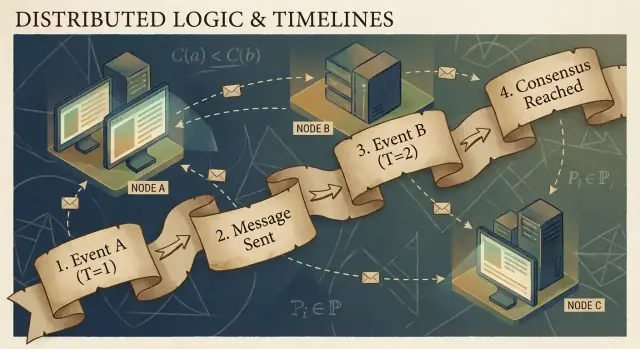
Nhân quả và quan hệ Happened-Before
Chương trình phân tán được tạo từ các sự kiện: điều gì đó xảy ra tại một nút (một process, server, hoặc thread). Ví dụ: “nhận một yêu cầu”, “ghi một dòng”, hoặc “gửi một thông điệp”. Một thông điệp là kết nối giữa các nút: một sự kiện là gửi, sự kiện khác là nhận.
Ý tưởng chính của Lamport là trong hệ thống không có đồng hồ đáng tin, điều đáng tin cậy nhất bạn có thể theo dõi là nhân quả — sự kiện nào có thể ảnh hưởng tới sự kiện khác.
Quan hệ happened-before (→)
Lamport định nghĩa một quy tắc đơn giản gọi là happened-before, viết A → B (sự kiện A xảy ra trước sự kiện B):
- Thứ tự cùng process: Nếu A và B xảy ra trên cùng một máy/process, và A được quan sát là xảy ra trước trong process đó, thì A → B.
- Thứ tự tin nhắn: Nếu A là “gửi thông điệp m” và B là “nhận thông điệp m”, thì A → B.
- Tính chuyển tiếp: Nếu A → B và B → C, thì A → C.
Quan hệ này cho bạn một thứ tự từng phần: nó nói rằng một số cặp có thứ tự, nhưng không phải tất cả.
Một câu chuyện cụ thể: người dùng → yêu cầu → DB → cache
Người dùng nhấn “Mua”. Click đó kích hoạt một yêu cầu tới API server (sự kiện A). Server ghi một hàng order vào cơ sở dữ liệu (sự kiện B). Sau khi ghi xong, server phát một thông điệp “order created” (sự kiện C), và một dịch vụ cache nhận và cập nhật cache (sự kiện D).
Ở đây, A → B → C → D. Ngay cả khi đồng hồ không khớp, cấu trúc tin nhắn và chương trình tạo ra các liên kết nhân quả thực.
“Đồng thời” thực ra nghĩa là gì
Hai sự kiện là đồng thời khi không sự kiện nào gây ra sự kiện kia: không (A → B) và không (B → A). Đồng thời không có nghĩa là “cùng một thời điểm” — nó nghĩa là “không có đường nhân quả nối chúng”. Đó là lý do hai dịch vụ có thể đều khẳng định họ hành động “trước”, và cả hai đều có thể đúng nếu bạn không thêm quy tắc sắp xếp.
Đồng hồ logic: Lamport timestamps giải thích đơn giản
Nếu bạn từng cố tái tạo “cái gì xảy ra trước” qua nhiều máy, bạn đã gặp bài toán cơ bản: máy không chia sẻ đồng hồ chính xác. Cách giải của Lamport là thôi đuổi theo thời gian hoàn hảo và thay vào đó theo dõi thứ tự.
Ý tưởng: một bộ đếm gắn vào mỗi sự kiện
Một Lamport timestamp chỉ là một số bạn gắn vào mỗi sự kiện quan trọng trong một process (một instance dịch vụ, một nút, một thread — tùy bạn chọn). Hãy coi nó như “bộ đếm sự kiện” cho phép bạn nói một cách nhất quán “sự kiện này xảy ra trước sự kiện kia”, ngay cả khi thời gian thực không đáng tin.
Hai quy tắc (thực sự đơn giản)
-
Tăng cục bộ: trước khi ghi một sự kiện (ví dụ “ghi DB”, “gửi request”, “append log entry”), tăng bộ đếm cục bộ lên.
-
Khi nhận, lấy max + 1: khi bạn nhận một tin nhắn có kèm timestamp của người gửi, đặt bộ đếm của bạn thành:
max(local_counter, received_counter) + 1
Rồi đóng dấu thời gian cho sự kiện nhận với giá trị đó.
Những quy tắc này đảm bảo timestamp tôn trọng nhân quả: nếu A có thể ảnh hưởng tới B (bởi thông tin chảy qua tin nhắn), thì timestamp của A sẽ nhỏ hơn của B.
Lamport timestamps có thể và không thể cho bạn biết gì
Chúng có thể cho bạn biết về thứ tự nhân quả:
- Nếu
TS(A) < TS(B), A có thể đã xảy ra trước B. - Nếu A gây ra B (trực tiếp hoặc gián tiếp), thì chắc chắn
TS(A) < TS(B).
Chúng không thể cho bạn biết về thời gian thực:
- Một timestamp nhỏ hơn không có nghĩa “sớm hơn theo giây.”
- Hai sự kiện có thể đồng thời (không nhân quả) và vẫn có timestamp khác nhau tùy mẫu tin nhắn.
Vì vậy Lamport timestamps rất tốt để sắp xếp, nhưng không để đo độ trễ hay trả lời “lúc mấy giờ?”
Ví dụ thực tế: sắp xếp log giữa các dịch vụ
Tưởng tượng Service A gọi Service B, và cả hai ghi audit log. Bạn muốn một cái nhìn log hợp nhất giữ được quan hệ nhân quả.
- Service A tăng bộ đếm, log “bắt đầu thanh toán”, gửi request đến B kèm timestamp 42.
- Service B nhận request có 42, đặt bộ đếm là
max(local, 42) + 1, giả sử là 43, và log “xác thực thẻ”. - B trả lời với 44; A nhận, cập nhật lên 45, và log “thanh toán hoàn thành”.
Khi gom log từ cả hai dịch vụ, sắp xếp theo (lamport_timestamp, service_id) cho bạn một timeline ổn định, giải thích được và khớp với chuỗi ảnh hưởng thực — ngay cả khi đồng hồ hệ thống trôi hoặc mạng trì hoãn.
Từ thứ tự từng phần tới thứ tự toàn phần: khi bạn cần một dòng thời gian duy nhất
Nhân quả cho bạn một thứ tự từng phần: một số sự kiện rõ ràng “trước” các sự kiện khác (vì có tin nhắn hoặc phụ thuộc), nhưng nhiều sự kiện đơn giản là đồng thời. Đó không phải lỗi — đó là hình dạng tự nhiên của thực tại phân tán.
Thứ tự từng phần: đủ cho nhiều câu hỏi
Nếu bạn đang debug “cái gì có thể ảnh hưởng tới điều này?”, hoặc thực thi quy tắc như “phản hồi phải theo sau yêu cầu”, thứ tự từng phần là chính xác những gì bạn cần. Bạn chỉ cần tôn trọng các cạnh happened-before; phần còn lại có thể coi là độc lập.
Thứ tự toàn phần: cần khi hệ thống phải chọn một câu chuyện duy nhất
Một số hệ thống không thể chấp nhận “cả hai thứ tự đều ổn”. Họ cần một dãy đơn các thao tác, đặc biệt cho:
- Ghi vào một đối tượng chia sẻ (“set balance”, “update profile”, “append to log”)
- Các lệnh phải được áp dụng giống nhau ở mọi nơi (state machine replication)
- Giải quyết xung đột nơi “ghi cuối cùng thắng” phải có cùng ý nghĩa với mọi nút
Không có thứ tự toàn phần, hai bản sao có thể cả hai đúng theo cục bộ nhưng phân kỳ toàn cục: một bản áp dụng A rồi B, bản khác áp dụng B rồi A, và kết quả khác nhau.
Làm sao để có một dòng thời gian duy nhất?
Bạn đưa vào một cơ chế tạo thứ tự:
- Một sequencer/leader gán vị trí tăng dần cho mỗi lệnh.
- Hoặc consensus (ví dụ các cách kiểu Paxos) để cụm đồng ý về entry tiếp theo của log ngay cả khi có độ trễ và lỗi.
Những đánh đổi không tránh được
Một thứ tự toàn phần mạnh mẽ nhưng tốn giá:
- Độ trễ: bạn có thể phải chờ phối hợp trước khi commit.
- Thông lượng: một log được sắp xếp đơn lẻ có thể trở thành cổ chai.
- Khả năng sẵn sàng khi lỗi: nếu bạn không thể đạt đủ số nút để đồng ý, tiến trình có thể tạm dừng để bảo vệ tính đúng đắn.
Lựa chọn thiết kế đơn giản: khi tính đúng đắn đòi hỏi một câu chuyện chung, bạn trả chi phí phối hợp để có nó.
Consensus: đồng ý trong điều kiện độ trễ và lỗi
Viết spec trước, rồi triển khai
Dùng Chế độ Lập kế hoạch để viết ra các đảm bảo về an toàn và tiến triển, rồi xây theo spec.
Consensus là bài toán khiến nhiều máy đồng ý một quyết định — một giá trị để commit, một leader để theo, một cấu hình để kích hoạt — dù mỗi máy chỉ thấy sự kiện cục bộ và những tin nhắn mà nó nhận được.
Nghe có vẻ đơn giản cho tới khi bạn nhớ điều hệ thống phân tán cho phép: tin nhắn có thể bị trì hoãn, sao chép, xáo trộn, hoặc mất; máy có thể crash và khởi động lại; và hiếm khi có tín hiệu “nút này chắc chắn chết”. Consensus là về làm cho việc đồng ý an toàn trong những điều kiện đó.
Tại sao đồng ý khó
Nếu hai nút tạm thời không thể nói chuyện (partition mạng), mỗi phía có thể cố “tiếp tục” riêng. Nếu cả hai phía đều quyết định giá trị khác nhau, bạn có thể gặp split-brain: hai leader, hai cấu hình khác nhau, hoặc hai lịch sử tranh chấp.
Ngay cả không có partition, chỉ độ trễ cũng gây rắc rối. Khi một nút nghe về một đề xuất, các nút khác có thể đã đi tiếp. Không có đồng hồ chung, bạn không thể nói chắc “đề xuất A xảy ra trước đề xuất B” chỉ vì A có timestamp nhỏ hơn — thời gian vật lý không phải thẩm quyền ở đây.
Bạn gặp consensus ở đâu trong hệ thống thực tế
Bạn có thể không gọi nó là “consensus” hàng ngày, nhưng nó xuất hiện trong các tác vụ hạ tầng phổ biến:
- Bầu lãnh đạo (hiện ai quản lý?)
- Nhật ký nhân bản (entry tiếp theo của lịch sử chung là gì?)
- Thay đổi cấu hình (tập nút nào được quyền vote/commit?)
Trong mỗi trường hợp, hệ thống cần một kết quả duy nhất mà mọi người có thể hội tụ, hoặc ít nhất một quy tắc ngăn hai kết quả xung đột cùng được coi là hợp lệ.
Paxos — câu trả lời của Lamport
Paxos của Lamport là giải pháp nền tảng cho bài toán “đồng ý an toàn” này. Ý tưởng chính không phải timeout thần kỳ hay leader hoàn hảo — mà là một tập quy tắc đảm bảo chỉ một giá trị có thể được chọn, ngay cả khi tin nhắn tới muộn và nút lỗi.
Paxos tách an toàn (“không bao giờ chọn hai giá trị khác nhau”) khỏi tiến triển (“cuối cùng chọn được cái gì đó”), làm nó thành một khuôn mẫu thực tế: bạn có thể điều chỉnh hiệu năng trong thế giới thực trong khi giữ đảm bảo lõi.
Paxos, không đau đầu: trực giác an toàn then chốt
Paxos bị tiếng là khó đọc, nhưng phần lớn là vì “Paxos” không phải một thuật toán 1 câu liền mạch. Nó là một họ các mẫu liên quan chặt chẽ để khiến một nhóm đồng ý, ngay cả khi tin nhắn bị trễ, sao chép, hoặc máy tạm thời lỗi.
Các vai: proposer, acceptor và quorum
Mô hình tư duy hữu ích là tách “người gợi ý” ra khỏi “người xác thực”.
- Proposers cố gắng khiến một giá trị được chọn (ví dụ: “entry tiếp theo là X”).
- Acceptors bỏ phiếu cho đề xuất.
- Quorum là “đủ acceptor” để tiến triển — thường là đa số.
Ý tưởng cấu trúc: hai đa số bất kỳ luôn chồng lấp nhau. Chính phần chồng lấp này giữ an toàn.
Mục tiêu an toàn: không bao giờ quyết định hai giá trị khác nhau
An toàn của Paxos nói đơn giản: một khi hệ thống quyết định một giá trị, nó không được quyết định giá trị khác — không split-brain.
Trực giác then chốt là đề xuất mang theo số (như ballot ID). Acceptors hứa bỏ qua các đề xuất có số cũ khi họ đã thấy số mới hơn. Khi một proposer thử với số mới, nó trước tiên hỏi một quorum xem họ đã từng chấp nhận gì. Vì quorum chồng lấp, proposer mới sẽ nghe ít nhất một acceptor “ghi nhớ” giá trị gần nhất. Quy tắc: nếu ai đó trong quorum đã accept, bạn phải đề xuất giá trị đó (hoặc giá trị mới nhất trong số đó). Ràng buộc này ngăn không cho hai giá trị khác nhau được chọn.
Liveness, nhìn chung
Liveness nghĩa là hệ thống cuối cùng quyết định cái gì đó trong điều kiện hợp lý (ví dụ, một leader ổn định xuất hiện, và mạng cuối cùng chuyển tin nhắn). Paxos không hứa tốc độ trong hỗn loạn; nó hứa đúng đắn, và tiến triển khi mọi thứ dịu lại.
Nhân bản máy trạng thái: tính đúng đắn qua thứ tự chung
Thử nghiệm với consensus
Thiết kế dịch vụ bầu lãnh đạo và test các trường hợp lỗi nhanh bằng snapshot và rollback.
Nhân bản máy trạng thái (SMR) là mô hình làm việc đằng sau nhiều hệ thống “độ sẵn sàng cao”: thay vì một server quyết định, bạn chạy nhiều replica và tất cả thực thi cùng một chuỗi lệnh.
Ý tưởng nhật ký nhân bản
Trung tâm là một nhật ký nhân bản: một danh sách có thứ tự các lệnh như “put key=K value=V” hoặc “transfer $10 từ A sang B”. Client không gửi lệnh tới mọi replica và hy vọng; họ gửi lệnh tới cụm, và hệ thống đồng ý trên một thứ tự cho các lệnh đó, rồi mỗi replica áp dụng cục bộ.
Tại sao thứ tự cho bạn tính đúng đắn
Nếu mọi replica bắt đầu từ cùng trạng thái khởi tạo và thực thi cùng lệnh theo cùng thứ tự, chúng sẽ kết thúc ở cùng trạng thái. Đó là trực giác an toàn cốt lõi: bạn không cố giữ nhiều máy “đồng bộ” bằng thời gian; bạn làm cho chúng giống hệt bằng tính quyết định và thứ tự chung.
Đó là lý do consensus (như Paxos/Raft) thường được ghép với SMR: consensus quyết định entry tiếp theo của log, và SMR biến quyết định đó thành trạng thái nhất quán trên các replica.
Nơi bạn thấy nó trong hệ thống thực tế
- Dịch vụ điều phối (ví dụ để cấu hình và bầu leader)
- Cơ sở dữ liệu với write-ahead log nhân bản
- Hệ thống tin nhắn cần thứ tự nghiêm ngặt theo phân vùng
Các vấn đề thực tiễn kỹ sư không thể bỏ qua
Nhật ký sẽ dài mãi trừ khi bạn quản lý nó:
- Snapshot: định kỳ chụp trạng thái hiện tại để node mới có thể bắt kịp mà không cần replay toàn bộ lịch sử.
- Nén nhật ký: an toàn loại bỏ các entry cũ khi chúng đã được phản ánh trong snapshot và không còn cần.
- Thay đổi thành viên: thêm/bớt replica phải được order hoá, nếu không các node khác nhau có thể bất đồng về ai “thuộc nhóm”, dẫn đến split-brain.
SMR không phải phép thuật; đó là cách kỷ luật để biến “đồng ý về thứ tự” thành “đồng ý về trạng thái”.
Tính đúng đắn: Safety, Liveness và viết một spec rõ ràng
Hệ thống phân tán lỗi theo những cách kỳ lạ: tin nhắn tới muộn, node khởi động lại, đồng hồ không khớp, và mạng chia. “Tính đúng đắn” không phải cảm giác — đó là một tập các hứa hẹn bạn có thể phát biểu chính xác và sau đó kiểm tra trong mọi tình huống, kể cả lỗi.
Safety vs. liveness (với ví dụ cụ thể)
Safety nghĩa là “không có điều xấu nào xảy ra”. Ví dụ: trong một kho key-value nhân bản, không được commit hai giá trị khác nhau cho cùng một index của log. Hoặc: dịch vụ khóa không bao giờ cấp cùng một khóa cho hai client cùng lúc.
Liveness nghĩa là “cuối cùng điều tốt sẽ xảy ra”. Ví dụ: nếu đa số replica đang hoạt động và mạng cuối cùng chuyển tin nhắn, một request ghi sẽ hoàn thành. Một yêu cầu khóa cuối cùng nhận được có/không chứ không bị treo vô hạn.
Safety ngăn mâu thuẫn; liveness ngăn đứng yên vĩnh viễn.
Invariant: những điều không thể mặc cả
Một invariant là điều kiện phải luôn đúng, trong mọi trạng thái có thể đạt tới. Ví dụ:
- “Mỗi index của log có nhiều nhất một giá trị được commit.”
- “Số term của leader không bao giờ giảm.”
Nếu một invariant có thể bị vi phạm trong crash, timeout, retry, hoặc partition, thì nó chưa được thực thi thật sự.
“Bằng chứng” nghĩa là gì ở đây
Một bằng chứng là một lập luận bao phủ mọi thực thi có thể, không chỉ đường đi “bình thường”. Bạn lý luận về mọi trường hợp: mất tin nhắn, sao chép, xáo trộn; node crash và khởi động lại; leader cạnh tranh; client retry.
Spec ngăn bất ngờ
Một spec rõ ràng định nghĩa trạng thái, các hành động cho phép, và các thuộc tính cần thiết. Điều đó ngăn những yêu cầu mơ hồ như “hệ thống nên nhất quán” biến thành kỳ vọng mâu thuẫn. Spec buộc bạn nói điều gì xảy ra trong partition, “commit” nghĩa gì, và client có thể dựa vào gì — trước khi production dạy bạn bài học đau đớn.
Từ lý thuyết đến thực hành: mô hình hóa với TLA+
Một trong những bài học thực tế nhất của Lamport là bạn có thể (và thường nên) thiết kế giao thức phân tán ở mức cao hơn code. Trước khi lo thread, RPC và vòng retry, bạn có thể ghi ra các quy tắc của hệ thống: hành động nào được phép, trạng thái nào có thể thay đổi, và điều gì không được xảy ra.
TLA+ để làm gì
TLA+ là ngôn ngữ đặc tả và bộ công cụ model-checking để mô tả hệ thống đồng thời và phân tán. Bạn viết một mô hình đơn giản, giống toán, của hệ thống — trạng thái và chuyển tiếp — cộng với các thuộc tính bạn quan tâm (ví dụ “tối đa một leader” or “entry commit không bao giờ biến mất”).
Rồi model checker khám phá các xen kẽ, độ trễ tin nhắn, và lỗi để tìm ví dụ phản chứng: một chuỗi bước cụ thể phá vỡ thuộc tính của bạn. Thay vì tranh luận các trường hợp biên trong cuộc họp, bạn có một lập luận thi hành được.
Một lỗi mô hình có thể bắt được
Xét một bước “commit” trong nhật ký nhân bản. Trong code, dễ vô tình cho phép hai node đánh dấu hai entry khác nhau là commit tại cùng một index trong một timing hiếm.
Một mô hình TLA+ có thể tiết lộ một trace như:
- Node A commit entry X ở index 10 sau khi nghe từ một quorum.
- Node B (dữ liệu cũ) cũng tạo quorum và commit entry Y ở index 10.
Đó là duplicate commit — vi phạm safety có thể chỉ xuất hiện một lần một tháng trong production, nhưng sẽ hiện ra nhanh dưới phép tìm kiếm toàn diện. Các mô hình tương tự thường bắt được cập nhật mất, áp dụng đôi, hoặc “ack nhưng không bền”.
Khi nào nên mô hình hóa
TLA+ giá trị nhất cho logic điều phối quan trọng: bầu lãnh đạo, thay đổi thành viên, luồng giống consensus, và bất kỳ giao thức nào mà thứ tự và xử lý lỗi tương tác. Nếu một bug có thể làm hỏng dữ liệu hoặc cần phục hồi thủ công, một mô hình nhỏ thường rẻ hơn so với debug sau này.
Nếu bạn xây công cụ nội bộ quanh các ý tưởng này, workflow thực tế là viết spec nhẹ (thậm chí không chính thức), rồi implement và tạo test từ các invariant của spec. Nền tảng như Koder.ai có thể giúp đẩy nhanh vòng build-test: bạn mô tả hành vi ordering/consensus bằng ngôn ngữ tự nhiên, lặp nhanh scaffold dịch vụ (React frontends, Go backends với PostgreSQL, hoặc Flutter clients), và giữ “những gì không được phép xảy ra” hiển thị khi bạn ship.
Bài học thực hành để xây và vận hành hệ thống tin cậy
Trực quan hóa quan hệ happened-before
Tạo chế độ xem timeline sắp xếp sự kiện theo Lamport timestamp để debug dễ hơn.
Món quà lớn của Lamport cho người thực hành là một tư duy: coi thời gian và thứ tự là dữ liệu bạn mô hình, không phải giả định lấy từ đồng hồ tường. Tư duy đó chuyển thành một tập thói quen áp dụng ngay hôm sau.
Biến lý thuyết thành thực hành hàng ngày
Nếu tin nhắn có thể bị trì hoãn, sao chép, hoặc tới sai thứ tự, hãy thiết kế mỗi tương tác để an toàn trong điều kiện đó.
- Idempotency mặc định: làm cho “làm lại” vô hại. Dùng idempotency key cho thanh toán, provisioning, hay bất kỳ ghi nào có thể retry.
- Retry + deduplication: retry là cần thiết, nhưng không dedup bạn sẽ gây double-write. Lưu request ID và đánh dấu “đã xử lý”.
- Giao thức ít nhất một lần + hiệu ứng đúng một lần: chấp nhận mạng có thể gửi hai lần; đảm bảo thay đổi trạng thái của bạn không bị lặp.
Cẩn trọng với timeout và đồng hồ
Timeout không phải sự thật; chúng là chính sách. Một timeout chỉ báo “tôi không nghe lại kịp thời”, không phải “bên kia không hành động”. Hai hệ quả cụ thể:
- Đừng coi timeout là thất bại chắc chắn. Thiết kế đường bù trừ và con đường hòa giải.
- Tránh dùng thời gian cục bộ để order sự kiện giữa các nút. Dùng sequence number, counter đơn điệu, hoặc metadata nhân quả rõ ràng (ví dụ “cập nhật này thay thế version X”).
Observability tôn trọng nhân quả
Công cụ debug tốt mã hóa thứ tự, không chỉ timestamp.
- Trace ID mọi nơi: truyền một correlation/trace ID qua mỗi hop và mỗi dòng log.
- Manh mối nhân quả trong log: log ID tin nhắn, parent request ID, và “tôi tin phiên bản mới nhất là gì” khi quyết định.
- Replay có quyết định được: ghi lại input (lệnh) để bạn replay và xác nhận bug là do timing hay logic.
Câu hỏi thiết kế trước khi ship
Trước khi thêm tính năng phân tán, bắt buộc rõ với vài câu hỏi:
- Điều gì xảy ra nếu cùng một request được xử lý hai lần?
- Chúng ta cần thứ tự nào (nếu có), và nó được thực thi ở đâu?
- Những lỗi nào là “an toàn” (không gây trạng thái xấu) so với “ồn ào” (hiển thị cho user) so với “lặng lẽ” (hỏng dữ liệu)?
- Con đường phục hồi sau outage từng phần hoặc partition là gì?
- Chúng ta sẽ log gì để tái tạo câu chuyện happened-before trong production?
Những câu hỏi này không cần bằng tiến sĩ — chỉ cần kỷ luật coi thứ tự và tính đúng đắn là các yêu cầu sản phẩm hàng đầu.
Kết luận và bước tiếp theo đề xuất
Di sản bền của Lamport là một cách nghĩ rõ ràng khi hệ thống không chia sẻ đồng hồ và không tự đồng ý “cái gì đã xảy ra”. Thay vì đuổi theo thời gian hoàn hảo, bạn theo dấu nhân quả (cái gì có thể ảnh hưởng cái gì), biểu diễn nó bằng thời gian logic (Lamport timestamps), và – khi sản phẩm đòi hỏi lịch sử đơn nhất — xây sự đồng ý (consensus) để mọi replica áp dụng cùng một chuỗi quyết định.
Sợi chỉ đó dẫn tới tư duy kỹ thuật thực tế:
Viết spec trước, rồi xây
Ghi ra quy tắc bạn cần: những gì không bao giờ được xảy ra (safety) và những gì cuối cùng phải xảy ra (liveness). Rồi implement theo spec, và test hệ thống dưới độ trễ, partition, retry, tin nhắn lặp, và restart node. Nhiều “outage bí ẩn” thực ra là thiếu các phát biểu như “một request có thể được xử lý hai lần” hoặc “leader có thể đổi bất cứ lúc nào.”
Học tiếp, với các bước gợi ý
Nếu bạn muốn đi sâu mà không chìm trong hình thức:
- Đọc Lamport “Time, Clocks, and the Ordering of Events in a Distributed System” để nắm happened-before.
- Lướt “Paxos Made Simple” để nắm trực giác an toàn: một khi một giá trị được chọn, tiến trình sau đó không thể mâu thuẫn.
- Xem một talk giới thiệu TLA+, rồi mô hình một giao thức nhỏ (dịch vụ khóa hoặc một register hai replica) và check nó.
Thử một bài thực hành
Chọn một thành phần bạn chịu trách nhiệm và viết một “hợp đồng lỗi” một trang: bạn giả định gì về mạng và lưu trữ, thao tác nào idempotent, và bạn cung cấp các đảm bảo thứ tự nào.
Nếu muốn làm bài thực tế hơn, xây một “demon thứ tự”: API nhận lệnh append vào log, một worker nền áp dụng chúng, cùng một view admin hiển thị metadata nhân quả và các lần retry. Thực hiện điều này trên Koder.ai có thể là cách nhanh để lặp — đặc biệt nếu bạn muốn scaffold nhanh, deploy/host, snapshot/rollback cho thử nghiệm, và xuất mã nguồn khi hài lòng.
Làm tốt, những ý tưởng này giảm sự cố vì ít hành vi bị ngầm hiểu hơn. Chúng cũng đơn giản hóa lý luận: bạn ngừng tranh cãi về thời gian và bắt đầu chứng minh thứ tự, sự đồng ý và tính đúng đắn có ý nghĩa gì cho hệ thống của mình.