18 thg 8, 2025·8 phút
LLVM của Chris Lattner: Động cơ âm thầm đứng sau các chuỗi công cụ hiện đại
Tìm hiểu cách LLVM của Chris Lattner trở thành nền tảng trình biên dịch mô-đun phía sau nhiều ngôn ngữ và công cụ—hỗ trợ tối ưu, chẩn đoán tốt hơn và tốc độ build nhanh.
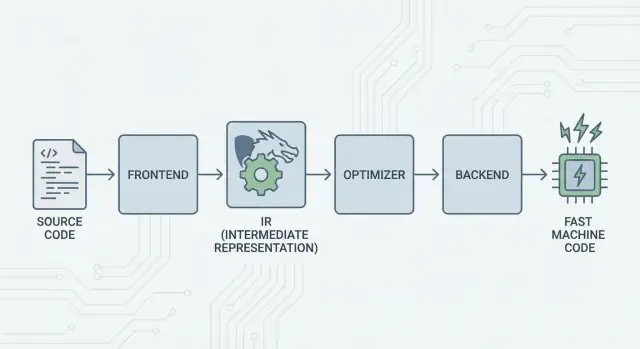
LLVM là gì, nói theo cách dễ hiểu
LLVM tốt nhất nên được nghĩ như “phòng máy” mà nhiều trình biên dịch và công cụ phát triển cùng dùng chung.
Khi bạn viết mã bằng C, Swift hoặc Rust, cần có thứ dịch mã đó thành các lệnh mà CPU có thể chạy. Trình biên dịch truyền thống thường tự xây mọi phần của đường ống. LLVM chọn cách khác: nó cung cấp một lõi có chất lượng cao, có thể tái sử dụng, xử lý những phần khó và tốn kém—tối ưu hoá, phân tích và sinh mã máy cho nhiều loại bộ xử lý.
Một nền tảng chung cho nhiều ngôn ngữ
LLVM không phải là một trình biên dịch duy nhất mà bạn “dùng trực tiếp” trong hầu hết các trường hợp. Nó là cơ sở hạ tầng trình biên dịch: những viên gạch xây dựng mà các nhóm ngôn ngữ có thể lắp thành một chuỗi công cụ. Một đội có thể tập trung vào cú pháp, ngữ nghĩa và tính năng dành cho nhà phát triển, rồi giao phần nặng cho LLVM.
Nền tảng chung này là lý do lớn tại sao các ngôn ngữ hiện đại có thể phát hành chuỗi công cụ an toàn, hiệu quả mà không phải tái phát minh cả chục năm công việc trình biên dịch.
Tại sao nó quan trọng ngay cả khi bạn không phải người chuyên về trình biên dịch
LLVM hiện diện trong trải nghiệm nhà phát triển hàng ngày:
- Tốc độ: nó chuyển mã cấp cao thành mã máy hiệu quả trên nhiều nền tảng.
- Lỗi và gỡ lỗi tốt hơn: hệ sinh thái xung quanh LLVM cho phép chẩn đoán phong phú hơn và công cụ tốt hơn.
- Không chỉ “biên dịch”: phân tích tĩnh, sanitizer, thu thập độ phủ mã và các trợ giúp khác thường xây trên cùng biểu diễn trung gian và thư viện.
Bài viết này sẽ (và không) nói gì
Đây là một chuyến tham quan có hướng dẫn về những ý tưởng Chris Lattner khởi xướng: cấu trúc của LLVM, tại sao lớp giữa lại quan trọng, và nó cho phép tối ưu hóa và hỗ trợ đa nền tảng ra sao. Đây không phải sách giáo khoa—we sẽ giữ trọng tâm vào trực giác và tác động thực tế thay vì lý thuyết hình thức.
Tầm nhìn ban đầu của Chris Lattner
Chris Lattner là một nhà khoa học máy tính và kỹ sư, người khi còn là nghiên cứu sinh đầu những năm 2000 đã bắt đầu LLVM từ một nỗi bực bội thực tế: công nghệ trình biên dịch mạnh nhưng khó tái sử dụng. Nếu bạn muốn một ngôn ngữ mới, tối ưu tốt hơn hoặc hỗ trợ CPU mới, thường phải tinh chỉnh một trình biên dịch “tất cả trong một” chặt chẽ, nơi mỗi thay đổi đều gây hệ quả phụ.
Vấn đề ông muốn giải quyết
Khi đó, nhiều trình biên dịch được xây như một cái máy lớn đơn lẻ: phần hiểu ngôn ngữ, phần tối ưu, và phần sinh mã máy dính nhau sâu. Điều đó làm chúng hiệu quả cho mục đích ban đầu, nhưng tốn kém để điều chỉnh.
Mục tiêu của Lattner không phải là “một trình biên dịch cho một ngôn ngữ.” Mà là một nền tảng chung có thể cung cấp sức mạnh cho nhiều ngôn ngữ và nhiều công cụ—mà không bắt mọi người viết lại cùng những phần phức tạp. Ông đặt cược rằng nếu tiêu chuẩn hóa được phần giữa của pipeline, thì có thể đổi mới nhanh hơn ở các rìa.
Tại sao “hạ tầng mô-đun” là một ý tưởng mới mẻ
Sự thay đổi then chốt là xem quá trình biên dịch như các khối xây tách rời với ranh giới rõ ràng. Trong thế giới mô-đun:
- đội ngôn ngữ tập trung vào parsing và tính năng dành cho nhà phát triển,
- đội tối ưu có thể cải thiện hiệu năng một lần và chia sẻ rộng rãi,
- hỗ trợ phần cứng có thể được thêm vào mà không phải thiết kế lại mọi thứ ở phía trên.
Sự tách bạch này nghe thì hiển nhiên bây giờ, nhưng lúc đó đi ngược lại cách nhiều trình biên dịch sản xuất đã phát triển.
Mở mã nguồn, được xây để người khác dùng
LLVM được phát hành mã nguồn mở từ sớm, điều này quan trọng vì hạ tầng chung chỉ hoạt động nếu nhiều nhóm có thể tin tưởng, kiểm tra và mở rộng nó. Theo thời gian, các trường đại học, công ty và đóng góp độc lập đã hình thành dự án bằng cách thêm các target, sửa các góc cạnh, cải thiện hiệu năng và xây các công cụ mới quanh nó.
Khía cạnh cộng đồng này không chỉ là thiện chí—nó là một phần của thiết kế: làm lõi hữu ích rộng rãi, và nó trở nên đáng để cùng duy trì.
Ý tưởng lớn: Frontend, lõi chung và backend
Ý tưởng cốt lõi của LLVM đơn giản: tách trình biên dịch thành ba phần lớn để nhiều ngôn ngữ có thể chia sẻ phần khó nhất.
1) Frontend: “Người lập trình muốn nói gì?”
Một frontend hiểu một ngôn ngữ cụ thể. Nó đọc mã nguồn, kiểm tra quy tắc (cú pháp và kiểu), và biến nó thành một biểu diễn có cấu trúc.
Điểm then chốt: frontend không cần biết mọi chi tiết CPU. Nhiệm vụ của nó là chuyển các khái niệm ngôn ngữ—hàm, vòng lặp, biến—thành thứ gì đó phổ quát hơn.
2) Lớp giữa chung: một lõi chung thay vì N×M công việc
Truyền thống, xây một trình biên dịch nghĩa là làm đi làm lại cùng một việc:
- Với N ngôn ngữ và M mục tiêu chip, bạn kết thúc với N×M tổ hợp phải hỗ trợ.
LLVM giảm điều đó xuống:
- N frontend dịch vào một dạng chung
- M backend dịch từ dạng chung đó sang mã máy
Dạng chung đó là tâm điểm của LLVM: một pipeline chung nơi các tối ưu và phân tích tồn tại. Đây là yếu tố đơn giản hóa lớn. Cải tiến ở giữa (như tối ưu tốt hơn hay thông tin gỡ lỗi tốt hơn) có thể mang lại lợi ích cho nhiều ngôn ngữ cùng lúc, thay vì phải cài đặt lại trong mọi trình biên dịch.
3) Backend: “Làm sao để chạy nhanh trên CPU đó?”
Một backend lấy biểu diễn chung và tạo ra đầu ra máy cụ thể: lệnh cho x86, ARM, v.v. Ở đây chi tiết như thanh ghi, quy ước gọi hàm và lựa chọn lệnh trở nên quan trọng.
Một hình ảnh trực quan về pipeline
Hãy nghĩ biên dịch như một tuyến đường đi:
- Mã nguồn bắt đầu ở một quốc gia theo ngôn ngữ cụ thể (frontend).
- Nó qua biên giới vào một “ngôn ngữ giữa” chuẩn hóa (lõi biểu diễn trung gian của LLVM và các pass).
- Rồi nó đi bằng hệ thống tàu địa phương tới thành phố đích (backend cho máy mục tiêu).
Kết quả là một chuỗi công cụ mô-đun: ngôn ngữ tập trung vào cách biểu đạt ý tưởng, còn lõi chung của LLVM tập trung vào làm cho ý tưởng đó chạy hiệu quả trên nhiều nền tảng.
LLVM IR: Lớp giữa cho phép tái sử dụng
LLVM IR (Intermediate Representation) là “ngôn ngữ chung” nằm giữa ngôn ngữ lập trình và mã máy CPU chạy.
Một frontend (như Clang cho C/C++) dịch mã nguồn của bạn thành dạng chung này. Sau đó các bộ tối ưu và sinh mã của LLVM làm việc trên IR, không làm việc trực tiếp trên ngôn ngữ ban đầu. Cuối cùng, một backend biến IR thành lệnh cho target cụ thể (x86, ARM, v.v.).
Một ngôn ngữ chung giữa công cụ và CPU
Hãy coi LLVM IR như một cây cầu được thiết kế cẩn thận:
- Bên trên: nhiều ngôn ngữ nguồn có thể cắm vào (C, C++, Rust, Swift, Julia, v.v.).
- Bên dưới: nhiều CPU có thể được nhắm tới.
- Ở giữa: cùng bộ công cụ phân tích và tối ưu có thể tái sử dụng.
Đây là lý do người ta thường mô tả LLVM là “cơ sở hạ tầng trình biên dịch” hơn là “một trình biên dịch.” IR là hợp đồng chung làm cho cơ sở hạ tầng đó có thể tái sử dụng.
Tại sao IR cho phép tái sử dụng (và tiết kiệm công sức)
Khi mã ở dạng LLVM IR, hầu hết các pass tối ưu không cần biết nó khởi nguồn từ template C++, iterator Rust hay generic Swift. Chúng quan tâm những ý tưởng phổ quát như:
- “Giá trị này là hằng.”
- “Phép tính này lặp lại; có thể tái dùng kết quả không?”
- “Lần đọc nhớ này có thể được di chuyển hoặc loại bỏ an toàn.”
Vì vậy các đội ngôn ngữ không phải xây (và duy trì) toàn bộ stack tối ưu của riêng họ. Họ có thể tập trung vào frontend—parsing, kiểm tra kiểu, quy tắc ngôn ngữ—rồi giao việc nặng cho LLVM.
Về mặt khái niệm nó trông như thế nào
LLVM IR đủ thấp để ánh xạ rõ ràng sang mã máy, nhưng vẫn đủ có cấu trúc để phân tích. Về mặt khái niệm, nó gồm các lệnh đơn giản (add, compare, load/store), luồng điều khiển rõ ràng (nhánh), và các giá trị kiểu cứng—gần giống assembly được sắp xếp tốt dành cho trình biên dịch hơn là thứ con người thường viết.
Cách tối ưu hoạt động (không cần toán học)
Khi nghe “tối ưu trình biên dịch”, nhiều người tưởng tượng thủ thuật bí ẩn. Trong LLVM, hầu hết tối ưu được hiểu hơn như những việc viết lại cơ học, an toàn chương trình—biến đổi giữ nguyên nghĩa nhưng nhằm chạy nhanh hơn (hoặc nhỏ hơn).
Hãy nghĩ như chỉnh sửa, không sáng tạo
LLVM lấy mã của bạn (ở LLVM IR) và lặp đi lặp lại áp dụng các cải tiến nhỏ, giống như mài mòn một bản thảo:
- Loại bỏ công việc trùng lặp: Nếu một giá trị được tính hai lần và không có gì thay đổi giữa đó, LLVM có thể tính một lần và tái sử dụng.
- Đơn giản hóa logic rõ ràng: Biểu thức hằng có thể được gộp sớm (ví dụ
3 * 4thành12), để CPU làm ít hơn khi chạy. - Tinh giản vòng lặp: Các pass liên quan vòng lặp có thể giảm các kiểm tra lặp đi lặp lại, đưa công việc không đổi ra ngoài vòng lặp, hoặc nhận dạng các mẫu chạy hiệu quả hơn.
Những thay đổi này được làm một cách thận trọng. Một pass chỉ thực hiện viết lại khi nó có thể chứng minh việc đó không thay đổi nghĩa chương trình.
Ví dụ dễ hình dung
Nếu chương trình của bạn về cơ bản làm những việc sau:
- Đọc cùng một giá trị cấu hình trong mỗi lần lặp của vòng lặp
- Thực hiện cùng một phép tính trên cùng dữ liệu ở nhiều nơi
- Kiểm tra điều kiện luôn đúng/hoặc sai trong ngữ cảnh cho trước
…LLVM cố gắng biến chúng thành “làm thiết lập một lần”, “tái sử dụng kết quả” và “xóa nhánh chết.” Ít huyền bí hơn là dọn dẹp nhà cửa mã.
Đánh đổi thực tế: thời gian biên dịch vs. thời gian chạy
Tối ưu không miễn phí: nhiều phân tích và nhiều pass thường nghĩa là thời gian biên dịch lâu hơn, dù chương trình cuối cùng chạy nhanh hơn. Đó là lý do các toolchain cung cấp các mức như “tối ưu nhẹ” hay “tối ưu mạnh”.
Profiles giúp ở đây. Với profile-guided optimization (PGO), bạn chạy chương trình, thu dữ liệu sử dụng thực tế, rồi biên dịch lại để LLVM tập trung tối ưu vào những đường đi thực sự quan trọng—làm cho đánh đổi dễ dự đoán hơn.
Backend: với nhiều CPU mà không phải viết lại mọi thứ
Lặp an toàn
Lưu trạng thái trước thay đổi lớn để có thể phục hồi bằng tự tin.
Trình biên dịch có hai nhiệm vụ rất khác nhau. Thứ nhất, nó cần hiểu mã nguồn của bạn. Thứ hai, nó cần sinh mã máy mà CPU cụ thể có thể thực thi. Backend của LLVM tập trung vào nhiệm vụ thứ hai.
Backend thực tế làm gì
Hãy coi LLVM IR như “công thức chung” cho những gì chương trình nên làm. Backend biến công thức đó thành những lệnh chính xác cho dòng vi xử lý cụ thể—x86-64 cho desktop/server, ARM64 cho điện thoại và laptop mới, hoặc target đặc biệt như WebAssembly.
Cụ thể, backend chịu trách nhiệm:
- Lựa chọn lệnh: ánh xạ các phép toán IR sang lệnh CPU thực tế
- Phân bổ thanh ghi: chọn giá trị nào nằm ở thanh ghi nhanh của CPU so với bộ nhớ
- Lên lịch: sắp xếp lệnh để CPU chạy hiệu quả
- Xuất assembly/object: tạo mã mà linker và OS hiểu
Tại sao hạ tầng chung làm việc thêm phần cứng dễ hơn
Nếu không có lõi chung, mỗi ngôn ngữ phải triển khai lại mọi thứ này cho từng CPU muốn hỗ trợ—một khối lượng công việc khổng lồ và gánh nặng bảo trì liên tục.
LLVM đảo ngược điều đó: các frontend (như Clang) sinh LLVM IR một lần, và backend đảm nhận “dặm cuối” cho mỗi target. Thêm hỗ trợ CPU mới thường nghĩa là viết một backend (hoặc mở rộng backend có sẵn), không phải viết lại mọi trình biên dịch.
Khả năng di động cho các đội phát hành đa nền tảng
Với các dự án phải chạy trên Windows/macOS/Linux, trên x86 và ARM, hoặc thậm chí trong trình duyệt, mô hình backend của LLVM là một lợi thế thực tế. Bạn có thể giữ một codebase và hầu như một pipeline build, rồi chuyển target bằng cách chọn backend khác (hoặc cross-compile).
Khả năng di động này là lý do LLVM xuất hiện ở khắp nơi: không chỉ vì tốc độ—mà còn vì tránh công việc trình biên dịch đặc thù từng nền tảng làm chậm đội.
Clang: nơi nhiều nhà phát triển lần đầu gặp LLVM
Clang là frontend cho C, C++ và Objective-C kết nối vào LLVM. Nếu LLVM là động cơ chung tối ưu và sinh mã, Clang là phần đọc file nguồn, hiểu quy tắc ngôn ngữ, và biến những gì bạn viết thành dạng LLVM có thể làm việc.
Tại sao Clang được chú ý
Nhiều nhà phát triển không khám phá LLVM bằng việc đọc bài báo—họ gặp nó lần đầu khi thay trình biên dịch và phản hồi bất ngờ được cải thiện.
Thông báo lỗi của Clang nổi tiếng dễ đọc và cụ thể hơn. Thay vì lỗi mơ hồ, nó thường chỉ đúng token gây vấn đề, hiển thị dòng liên quan và giải thích điều nó mong đợi. Điều đó quan trọng trong công việc hàng ngày vì vòng lặp “biên dịch, sửa, lặp” bớt khó chịu hơn.
Clang cũng cung cấp giao diện sạch và tài liệu tốt (đặc biệt qua libclang và hệ sinh thái Clang tooling). Điều đó giúp editor, IDE và công cụ khác tích hợp hiểu sâu ngôn ngữ mà không phải viết lại parser C/C++.
Nó xuất hiện trong quy trình làm việc hàng ngày ra sao
Khi một công cụ có thể phân tích mã tin cậy, bạn bắt đầu nhận các tính năng như làm việc với chương trình có cấu trúc hơn là chỉ chỉnh sửa văn bản:
- Điều hướng mã chính xác (“đi tới định nghĩa”, “tìm tham chiếu”) ngay cả trong dự án C++ lớn và nhiều macro
- Hỗ trợ refactor hiểu được symbol và scope, không chỉ tìm-thay-thế
- Gợi ý inline và sửa nhanh nhờ thông tin cú pháp và kiểu
Đó là lý do Clang thường là “điểm chạm” đầu tiên với LLVM: ở đó cải thiện trải nghiệm nhà phát triển thực tế bắt nguồn. Ngay cả khi bạn không nghĩ đến LLVM IR hay backend, bạn vẫn được lợi khi autocomplete thông minh hơn, kiểm tra tĩnh chính xác hơn và lỗi build dễ xử lý hơn.
Tại sao nhiều ngôn ngữ hiện đại xây quanh LLVM
LLVM hấp dẫn các đội ngôn ngữ vì lý do đơn giản: nó cho phép họ tập trung vào ngôn ngữ thay vì mất nhiều năm để tái xây một trình biên dịch tối ưu hoàn chỉnh.
Ra mắt nhanh hơn
Xây một ngôn ngữ mới đã bao gồm parsing, kiểm tra kiểu, chẩn đoán, công cụ gói, tài liệu và hỗ trợ cộng đồng. Nếu bạn còn phải tạo một optimizer sản xuất, generator mã và hỗ trợ nền tảng từ đầu, việc ra mắt bị trì hoãn—đôi khi hàng năm.
LLVM cung cấp lõi biên dịch sẵn: phân bổ thanh ghi, lựa chọn lệnh, các pass tối ưu đã trưởng thành và các target cho CPU phổ biến. Các đội có thể cắm frontend xuống LLVM IR, rồi tin tưởng pipeline hiện có để sinh mã native cho macOS, Linux và Windows.
Hiệu năng cao (không cần “xem giỏi”)
Bộ tối ưu và backend của LLVM là kết quả của kỹ sư lâu dài và thử nghiệm thực tế liên tục. Điều đó chuyển thành hiệu năng cơ bản mạnh cho các ngôn ngữ dùng nó—thường đủ tốt ngay từ đầu, và có thể cải thiện theo LLVM.
Đó là lý do một số ngôn ngữ nổi tiếng chọn xung quanh nó:
- Swift dùng LLVM để sinh binary native tối ưu trên các nền tảng Apple.
- Rust dựa vào LLVM cho sinh mã và nhiều target kiến trúc.
- Julia dùng LLVM để cho code số nhanh, bao gồm biên dịch runtime cho các workload chuyên biệt.
Không phải ngôn ngữ nào cũng cần LLVM
Chọn LLVM là một đánh đổi, không phải bắt buộc. Một số ngôn ngữ ưu tiên binary nhỏ, biên dịch cực nhanh, hoặc kiểm soát hoàn toàn toolchain. Một số khác đã có compiler sẵn (như hệ sinh thái dựa trên GCC) hoặc thích backend đơn giản hơn.
LLVM phổ biến vì nó là lựa chọn mặc định mạnh—không phải vì đó là con đường duy nhất hợp lệ.
JIT và biên dịch runtime: vòng phản hồi nhanh
Sử dụng tên miền của bạn
Đăng app của bạn lên tên miền tùy chỉnh khi đã sẵn sàng chia sẻ.
“Just-in-time” (JIT) dễ hiểu nhất là biên dịch khi chạy. Thay vì dịch toàn bộ trước khi chạy, engine JIT chờ cho đến khi một phần mã cần thiết, rồi biên dịch phần đó ngay lập tức—thường dùng thông tin runtime thực (như kiểu dữ liệu và kích thước chính xác) để chọn phương án tốt hơn.
Tại sao JIT có cảm giác nhanh
Bởi vì bạn không phải biên dịch mọi thứ upfront, hệ thống JIT có thể mang lại phản hồi nhanh cho công việc tương tác. Bạn viết hoặc sinh một đoạn mã, chạy ngay, và hệ thống chỉ biên dịch phần cần thiết ngay lúc đó. Nếu mã đó chạy nhiều lần, JIT có thể cache kết quả biên dịch hoặc biên dịch lại các đoạn “nóng” mạnh hơn.
Nơi biên dịch runtime hữu dụng trong thực tế
JIT tỏa sáng khi workload động hoặc tương tác:
- REPL và notebook: đánh giá đoạn mã ngay lập tức nhưng vẫn đạt tốc độ native cho vòng lặp nặng.
- Plugin và extension: ứng dụng có thể nạp mã người dùng khi chạy và biên dịch cho CPU host.
- Workload động: khi đầu vào thay đổi nhiều, profiling runtime chỉ ra đường đi nào xứng đáng tối ưu.
- Tính toán khoa học: kernel sinh (cho kích thước ma trận cụ thể, hình dáng mô hình hoặc tính năng phần cứng) được biên dịch theo nhu cầu.
Vai trò của LLVM (không bị thổi phồng)
LLVM không biến mọi chương trình nhanh hơn một cách kỳ diệu, và nó không phải một JIT hoàn chỉnh tự thân. Những gì nó cung cấp là một bộ công cụ: một IR rõ ràng, nhiều pass tối ưu, và sinh mã cho nhiều CPU. Dự án có thể xây engine JIT trên các viên gạch đó, chọn đánh đổi phù hợp giữa thời gian khởi động, hiệu năng đỉnh và độ phức tạp.
Hiệu năng, tính dự đoán và đánh đổi trong thực tế
Toolchain dựa trên LLVM có thể sinh mã rất nhanh—nhưng “nhanh” không phải là một thuộc tính duy nhất, cố định. Nó phụ thuộc phiên bản compiler, CPU mục tiêu, cài đặt tối ưu, và thậm chí những gì bạn cho compiler được phép giả định về chương trình.
Tại sao “cùng nguồn, kết quả khác nhau” xảy ra
Hai compiler có thể đọc cùng mã nguồn và vẫn sinh mã máy khác nhau rõ rệt. Một phần đó là cố ý: mỗi compiler có bộ pass tối ưu, heuristic và cài đặt mặc định riêng. Ngay trong LLVM, Clang 15 và Clang 18 có thể đưa ra quyết định inline khác nhau, vector hóa khác nhau hoặc lên lịch lệnh khác.
Nó cũng có thể do hành vi không xác định và không được chỉ định trong ngôn ngữ. Nếu chương trình vô tình dựa vào điều tiêu chuẩn không đảm bảo (như tràn số nguyên có dấu trong C), compiler khác nhau—hoặc flag khác nhau—có thể “tối ưu” theo cách làm thay đổi kết quả.
Tính xác định, build debug và build release
Mọi người thường mong biên dịch là xác định: cùng input, cùng output. Thực tế, bạn sẽ đến gần, nhưng không phải lúc nào cũng giống hệt. Đường dẫn build, timestamp, thứ tự link, dữ liệu profile và lựa chọn LTO đều có thể ảnh hưởng artifact cuối cùng.
Phân biệt thực tế hơn là debug vs release. Build debug thường tắt nhiều tối ưu để giữ trải nghiệm gỡ lỗi từng bước và stack trace dễ đọc. Build release bật các biến đổi mạnh mẽ có thể sắp xếp lại mã, inline hàm và loại bỏ biến—tốt cho hiệu năng nhưng khó gỡ lỗi hơn.
Lời khuyên thực tế: đo lường, đừng phỏng đoán
Xử lý hiệu năng như một vấn đề đo lường:
- Chạy benchmark trên phần cứng đại diện và dữ liệu thực tế.
- Làm nóng cache và chạy nhiều lần.
- So sánh build với các flag rõ ràng (ví dụ thay
-O2vs-O3, bật/tắt LTO, hay chọn target với-march).
Các thay đổi flag nhỏ có thể dịch hiệu năng theo cả hai hướng. Quy trình an toàn nhất là: đặt giả thuyết, đo nó, và giữ bộ benchmark sát với cách người dùng chạy thực tế.
Công cụ ngoài biên dịch: phân tích, gỡ lỗi và an toàn
Mở rộng theo tốc độ của bạn
Chọn Free, Pro, Business hoặc Enterprise tùy theo mức bạn muốn phát triển.
LLVM thường được mô tả là bộ công cụ trình biên dịch, nhưng nhiều nhà phát triển cảm nhận tác động của nó thông qua các công cụ nằm xung quanh việc biên dịch: bộ phân tích, debugger và kiểm tra an toàn bật trong quá trình build và test.
Phân tích và instrumentation như “addon”
Bởi vì LLVM lộ ra một biểu diễn trung gian (IR) rõ ràng và pipeline các pass, thật tự nhiên để thêm các bước kiểm tra hoặc viết lại mã cho mục đích khác ngoài tốc độ. Một pass có thể chèn bộ đếm để profiling, đánh dấu các phép toán bộ nhớ đáng ngờ, hoặc thu thập dữ liệu độ phủ mã.
Điểm then chốt là những tính năng này có thể tích hợp mà không bắt mọi đội ngôn ngữ viết lại cùng plumbing.
Sanitizer: bắt lỗi gần nguồn
Clang và LLVM phổ biến một gia đình runtime “sanitizer” chèn instrumentation để phát hiện các lớp lỗi phổ biến khi kiểm thử—như truy cập bộ nhớ ngoài ranh, use-after-free, điều kiện data race và mẫu hành vi không xác định. Chúng không phải là tấm khiên kỳ diệu và thường làm chương trình chạy chậm, nên chủ yếu dùng trong CI và kiểm thử trước phát hành. Nhưng khi báo lỗi, thường chỉ đúng vị trí nguồn và giải thích rõ, điều nhóm cần để truy bắt crash không ổn định.
Chẩn đoán tốt = onboard nhanh hơn
Chất lượng công cụ cũng là giao tiếp. Cảnh báo rõ ràng, thông báo lỗi có thể hành động và thông tin gỡ lỗi nhất quán giảm yếu tố “bí ẩn” cho người mới. Khi toolchain giải thích điều gì đã xảy ra và làm sao sửa, các nhà phát triển dành ít thời gian ghi nhớ quirks compiler hơn và nhiều thời gian học codebase.
LLVM không đảm bảo chẩn đoán hoàn hảo hay an toàn tự thân, nhưng nó cung cấp nền tảng chung khiến các công cụ hướng nhà phát triển trở nên thiết thực để xây, duy trì và chia sẻ.
Khi nào nên dùng LLVM (và khi nào không)
LLVM nên được coi là một “bộ công cụ để tự xây trình biên dịch và công cụ”. Sự linh hoạt này là lý do nó cung cấp năng lượng cho nhiều chuỗi công cụ hiện đại—nhưng cũng là lý do nó không phải là câu trả lời cho mọi dự án.
Khi LLVM là lựa chọn phù hợp
LLVM tỏa sáng khi bạn muốn tái sử dụng kỹ thuật trình biên dịch nghiêm túc mà không phải xây lại từ đầu.
Nếu bạn xây ngôn ngữ lập trình mới, LLVM cho bạn pipeline tối ưu đã được kiểm chứng, sinh mã cho nhiều CPU và con đường tới hỗ trợ gỡ lỗi tốt.
Nếu bạn phát hành ứng dụng đa nền tảng, hệ sinh thái backend của LLVM giảm công việc để nhắm tới các kiến trúc khác nhau. Bạn tập trung vào logic ngôn ngữ hoặc sản phẩm thay vì viết các code generator riêng.
Nếu mục tiêu là công cụ cho nhà phát triển—linter, phân tích tĩnh, điều hướng mã, refactor—LLVM (và hệ sinh thái xung quanh) là nền móng mạnh vì compiler đã “hiểu” cấu trúc và kiểu mã.
Khi nó có thể là quá mức cần thiết
LLVM có thể nặng nếu bạn làm hệ thống nhúng nhỏ nơi kích thước build, bộ nhớ và thời gian biên dịch bị siết chặt.
Nó cũng có thể không phù hợp cho pipeline rất chuyên biệt nơi bạn không muốn tối ưu chung chung, hoặc khi “ngôn ngữ” của bạn gần hơn một DSL cố định với ánh xạ thẳng tới mã máy.
Checklist đơn giản
Hỏi ba câu:
- Chúng ta cần nhắm nhiều nền tảng/CPU ngay hoặc sắp tới không?
- Chúng ta hưởng lợi từ tối ưu và debug info có sẵn, thay vì tự xây?
- Chúng ta muốn một con đường hệ sinh thái (công cụ, tích hợp, tuyển dụng) hơn là compiler tối giản?
Nếu trả lời “có” với hầu hết, LLVM thường là một cược thực tế. Nếu bạn chỉ cần trình biên dịch nhỏ nhất giải một vấn đề hẹp, cách tiếp cận nhẹ hơn có thể thắng.
Ghi chú thực tế cho đội sản phẩm: lợi ích của LLVM mà không phải thành chuyên gia trình biên dịch
Hầu hết đội không muốn “áp dụng LLVM” như một dự án. Họ muốn kết quả: build đa nền tảng, binary nhanh, chẩn đoán tốt và công cụ đáng tin cậy.
Đó là lý do các nền tảng như Koder.ai thú vị trong bối cảnh này. Nếu quy trình của bạn ngày càng được điều khiển bởi tự động hóa cấp cao (lập kế hoạch, sinh khung sườn, lặp nhanh), bạn vẫn hưởng lợi từ LLVM gián tiếp qua các toolchain bên dưới—dù bạn đang xây React web app, backend Go với PostgreSQL, hay client Flutter. Cách “vibe-coding” chat-driven của Koder.ai tập trung vào chạy sản phẩm nhanh hơn, trong khi hạ tầng trình biên dịch hiện đại (LLVM/Clang và các thành phần liên quan, khi thích hợp) tiếp tục làm công việc không hào nhoáng về tối ưu, chẩn đoán và di động ở hậu trường.