Tại sao ứng dụng thời gian thực có cảm giác chậm ngay cả khi mã chạy nhanh
Tốc độ có hai khía cạnh: throughput và latency. Throughput là lượng công việc bạn hoàn thành trên giây (yêu cầu, thông điệp, khung hình). Latency là thời gian một đơn vị công việc mất từ đầu đến cuối.
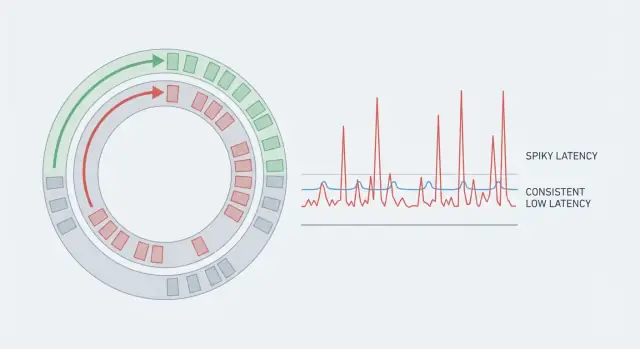
Một hệ thống có thể có throughput tốt nhưng vẫn tạo cảm giác chậm nếu một số yêu cầu mất lâu hơn nhiều so với phần còn lại. Đó là lý do vì sao trung bình dễ gây hiểu nhầm. Nếu 99 hành động mất 5 ms và một hành động mất 80 ms, trung bình trông ổn, nhưng người gặp trường hợp 80 ms sẽ thấy giật. Trong hệ thống thời gian thực, những đột biến hiếm đó là câu chuyện chính vì chúng bẻ gãy nhịp điệu.
Độ trễ dự đoán nghĩa là bạn không chỉ hướng tới một giá trị trung bình thấp. Bạn nhắm tới tính nhất quán, để hầu hết các thao tác hoàn thành trong một khoảng hẹp. Đó là lý do các nhóm theo dõi phần đuôi (p95, p99). Đó là nơi ẩn gián đoạn.
Một đột biến 50 ms có thể quan trọng ở các chỗ như thoại và video (lỗi âm thanh), game nhiều người chơi (rubber-banding), giao dịch thời gian thực (bỏ lỡ giá), giám sát công nghiệp (cảnh báo trễ) và dashboard trực tiếp (số nhảy, cảnh báo mất tin cậy).
Ví dụ đơn giản: một app chat có thể gửi tin nhắn nhanh hầu hết thời gian. Nhưng nếu một tạm dừng nền làm một tin nhắn đến muộn 60 ms, các chỉ báo đang gõ nhấp nháy và cuộc hội thoại cảm thấy giật, mặc dù server trông “nhanh” theo trung bình.
Nếu bạn muốn cảm giác thời gian thực thật sự, bạn cần ít bất ngờ hơn, không chỉ mã nhanh hơn.
Cơ bản về độ trễ: thời gian thực sự mất đi đâu
Hầu hết hệ thống thời gian thực không chậm vì CPU quá tải. Chúng có cảm giác chậm vì công việc phần lớn ở trạng thái chờ: chờ được lập lịch, chờ trong hàng đợi, chờ mạng, hoặc chờ lưu trữ.
End-to-end latency là toàn bộ thời gian từ “có chuyện xảy ra” đến “người dùng thấy kết quả.” Ngay cả khi handler của bạn chạy trong 2 ms, yêu cầu vẫn có thể mất 80 ms nếu nó tạm dừng ở năm chỗ khác nhau.
Một cách hữu ích để phân chia đường đi là:
- Thời gian mạng (client tới edge, service tới service, retry)
- Thời gian lập lịch (thread của bạn chờ để chạy)
- Thời gian trong hàng đợi (công việc đứng sau công việc khác)
- Thời gian lưu trữ (đĩa, khóa database, cache miss)
- Thời gian seri hóa (mã hóa và giải mã dữ liệu)
Những chờ này chồng lên nhau. Vài ms ở mỗi chỗ biến một đường dẫn “nhanh” thành trải nghiệm chậm.
Phần đuôi độ trễ là nơi người dùng bắt đầu phàn nàn. Độ trễ trung bình có thể trông ổn, nhưng p95 hoặc p99 là nơi 5% hoặc 1% chậm nhất. Các ngoại lệ thường đến từ những tạm dừng hiếm: một chu kỳ GC, một neighbor ồn trên host, tranh chấp khóa ngắn, một refill cache, hoặc một cơn bùng nổ tạo thành hàng đợi.
Ví dụ cụ thể: một cập nhật giá đến qua mạng trong 5 ms, chờ 10 ms vì worker bận, đứng sau các sự kiện khác 15 ms, rồi gặp trục trặc database 30 ms. Mã của bạn vẫn chạy trong 2 ms, nhưng người dùng chờ 62 ms. Mục tiêu là làm cho mỗi bước đều có thể dự đoán, không chỉ tính toán nhanh.
Những nguồn jitter thông thường ngoài tốc độ mã
Một thuật toán nhanh vẫn có thể khiến ứng dụng cảm thấy chậm nếu thời gian trên mỗi yêu cầu dao động. Người dùng cảm nhận các đột biến, không phải trung bình. Dao động đó là jitter, và thường đến từ những thứ mã của bạn không hoàn toàn kiểm soát.
Bộ nhớ đệm CPU và hành vi bộ nhớ là chi phí ẩn. Nếu dữ liệu nóng không vừa cache, CPU sẽ dừng chờ RAM. Cấu trúc nhiều đối tượng, bộ nhớ rải rác và “thêm một tra cứu nữa” có thể biến thành các cache miss lặp lại.
Cấp phát bộ nhớ thêm tính không định trước. Cấp phát nhiều đối tượng ngắn hạn tăng áp lực heap, sau đó biểu hiện dưới dạng tạm dừng (garbage collection) hoặc tranh chấp allocator. Ngay cả khi không có GC, cấp phát thường xuyên có thể phân mảnh bộ nhớ và làm xấu locality.
Lập lịch luồng là nguồn phổ biến khác. Khi một thread bị deschedule, bạn trả chi phí context switch và mất độ ấm cache. Trên máy bận, thread “thời gian thực” của bạn có thể chờ phía sau công việc không liên quan.
Tranh chấp khóa là nơi các hệ thống dự đoán thường sụp đổ. Một khóa “thường rảnh” có thể biến thành một cuộc xếp hàng: các thread thức dậy, tranh giành khóa và lại ngủ. Công việc vẫn được hoàn thành, nhưng tail latency căng ra.
Chờ I/O có thể vượt trội mọi thứ khác. Một syscall đơn, buffer mạng đầy, bắt tay TLS, flush đĩa, hay lookup DNS chậm có thể tạo ra một đột biến sắc bén mà tối ưu vi mô cũng không sửa được.
Nếu bạn săn jitter, bắt đầu bằng việc tìm cache miss (thường do cấu trúc con trỏ nặng và truy cập ngẫu nhiên), cấp phát thường xuyên, context switch do quá nhiều thread hoặc neighbor ồn, tranh chấp khóa, và bất kỳ I/O chặn nào (mạng, đĩa, logging, gọi đồng bộ).
Ví dụ: một service cập nhật giá có thể tính toán cập nhật trong microseconds, nhưng một lần gọi logger đồng bộ hoặc một khóa metrics tranh chấp có thể thỉnh thoảng thêm hàng chục ms.
Martin Thompson và Disruptor là gì
Martin Thompson nổi tiếng trong kỹ thuật độ trễ thấp vì ông tập trung vào cách hệ thống hành xử khi chịu sức ép: không chỉ tốc độ trung bình mà tốc độ dự đoán. Cùng với đội LMAX, ông giúp phổ biến mẫu Disruptor, một cách tham chiếu để truyền sự kiện qua hệ thống với độ trễ nhỏ và nhất quán.
Cách tiếp cận Disruptor là phản ứng với những gì làm nhiều ứng dụng “nhanh” trở nên không dự đoán: tranh chấp và phối hợp. Hàng đợi thông thường thường dựa vào khóa hoặc atomic nặng, đánh thức các thread lên xuống, và tạo ra các đợt chờ khi producers và consumers tranh giành cấu trúc chia sẻ.
Thay vì một hàng đợi, Disruptor dùng vòng đệm (ring buffer): một mảng tuần hoàn có kích thước cố định chứa các sự kiện trong các ô. Producers chiếm ô tiếp theo, ghi dữ liệu, rồi publish một số thứ tự. Consumers đọc theo thứ tự bằng cách theo số thứ tự đó. Vì buffer được cấp phát trước, bạn tránh cấp phát thường xuyên và giảm áp lực lên garbage collector.
Một ý chính là nguyên tắc single-writer: giữ một thành phần chịu trách nhiệm cho một mảnh trạng thái chia sẻ (ví dụ con trỏ con trượt qua ring). Ít người ghi hơn nghĩa là ít các khoảnh khắc “ai tiếp theo?”.
Backpressure là rõ ràng. Khi consumers tụt lại, producers cuối cùng sẽ gặp ô vẫn đang dùng. Lúc đó hệ thống phải chờ, bỏ, hoặc làm chậm, nhưng nó làm như vậy một cách có kiểm soát, có thể quan sát thay vì giấu vấn đề trong một hàng đợi ngày càng lớn.
Các ý tưởng thiết kế cốt lõi giữ độ trễ ổn định
Điều làm cho thiết kế kiểu Disruptor nhanh không phải là một tối ưu vi mô khéo léo. Mà là loại bỏ các tạm dừng không dự đoán xảy ra khi hệ thống tự gây cản trở: cấp phát, cache miss, tranh chấp khóa và công việc chậm lẫn vào đường nóng.
Một mô hình tư duy hữu ích là dây chuyền lắp ráp. Các sự kiện di chuyển qua một tuyến cố định với các chuyển giao rõ ràng. Điều đó giảm trạng thái chia sẻ và làm mỗi bước dễ giữ đơn giản và đo lường.
Giữ bộ nhớ và dữ liệu có thể dự đoán
Hệ thống nhanh tránh các cấp phát bất ngờ. Nếu bạn cấp phát trước buffer và tái sử dụng đối tượng thông điệp, bạn giảm các đột biến “thỉnh thoảng” do garbage collection, tăng heap và tranh chấp allocator.
Cũng hữu ích khi giữ tin nhắn nhỏ và ổn định. Khi dữ liệu bạn chạm cho mỗi sự kiện vừa trong cache CPU, bạn dành ít thời gian chờ bộ nhớ hơn.
Trong thực tế, những thói quen quan trọng thường là: tái sử dụng đối tượng thay vì tạo mới cho mỗi sự kiện, giữ dữ liệu sự kiện gọn, ưu tiên một người ghi cho trạng thái chia sẻ, và batch cẩn thận để trả chi phí phối hợp ít thường xuyên hơn.
Làm đường đi chậm trở nên hiển nhiên
Ứng dụng thời gian thực thường cần các phần phụ như logging, metrics, retry hoặc ghi cơ sở dữ liệu. Tư duy Disruptor là cô lập những thứ đó ra khỏi vòng lặp chính để chúng không thể chặn nó.
Trong feed giá trực tiếp, đường nóng có thể chỉ xác thực một tick và publish snapshot giá tiếp theo. Bất cứ thứ gì có thể làm chậm (đĩa, gọi mạng, seri hóa nặng) được chuyển sang consumer riêng hoặc kênh phụ, để đường đi dự đoán vẫn giữ được tính dự đoán.
Lựa chọn kiến trúc để có độ trễ dự đoán
Độ trễ có thể dự đoán chủ yếu là vấn đề kiến trúc. Bạn có thể có mã nhanh mà vẫn gặp các đột biến nếu quá nhiều luồng tranh cùng một dữ liệu, hoặc nếu thông điệp bật qua mạng không cần thiết.
Bắt đầu bằng cách quyết định có bao nhiêu writer và reader chạm cùng hàng đợi hoặc buffer. Một producer đơn dễ giữ mượt vì tránh phối hợp. Thiết lập nhiều producer có thể tăng throughput, nhưng thường thêm tranh chấp và làm thời gian trường hợp xấu nhất kém dự đoán. Nếu cần nhiều producer, giảm ghi chia sẻ bằng cách shard sự kiện theo key (ví dụ userId hoặc instrumentId) để mỗi shard có đường nóng riêng.
Về phía consumer, một consumer đơn mang lại thời gian ổn định nhất khi ordering quan trọng, vì trạng thái giữ cục bộ trên một thread. Worker pool hữu ích khi nhiệm vụ thực sự độc lập, nhưng chúng thêm độ trễ lập lịch và có thể thay đổi thứ tự công việc trừ khi bạn cẩn thận.
Batching là một đánh đổi khác. Batch nhỏ cắt giảm overhead (ít wakeup hơn, ít cache miss hơn), nhưng batching cũng có thể thêm thời gian chờ nếu bạn giữ sự kiện để đủ batch. Nếu batch trong hệ thống thời gian thực, giới hạn thời gian chờ (ví dụ “tối đa 16 sự kiện hoặc 200 microgiây, cái nào đến trước”).
Ranh giới dịch vụ cũng quan trọng. Messaging trong tiến trình thường tốt nhất khi bạn cần độ trễ chặt chẽ. Hop mạng có thể đáng cho scale, nhưng mỗi hop thêm hàng đợi, retry và độ trễ biến thiên. Nếu cần hop, giữ giao thức đơn giản và tránh fan-out trong đường nóng.
Bộ quy tắc thực tế: giữ một đường single-writer cho mỗi shard khi có thể, scale bằng sharding thay vì chia sẻ một hàng đợi nóng, chỉ batch với ngưỡng thời gian chặt chẽ, thêm worker pool chỉ cho công việc song song và độc lập, và coi mỗi hop mạng là nguồn jitter tiềm năng cho đến khi bạn đo nó.
Từng bước: thiết kế pipeline ít jitter
Bắt đầu với một ngân sách độ trễ viết sẵn trước khi chạm vào mã. Chọn mục tiêu (cảm giác “tốt” là gì) và một p99 (giá trị bạn phải tuân thủ). Chia số đó sang các giai đoạn như input, xác thực, ghép, lưu trữ và cập nhật outbound. Nếu một giai đoạn không có ngân sách, nó không có giới hạn.
Tiếp theo, vẽ toàn bộ luồng dữ liệu và đánh dấu mọi chốt chuyển giao: biên thread, hàng đợi, hop mạng và các gọi lưu trữ. Mỗi chốt là nơi ẩn jitter. Khi bạn thấy chúng, bạn có thể giảm chúng.
Một workflow giúp thiết kế thực tế:
- Viết ngân sách cho từng giai đoạn (target và p99), cộng một đệm nhỏ cho những điều chưa biết.
- Map pipeline và dán nhãn hàng đợi, khóa, cấp phát và các gọi chặn.
- Chọn mô hình đồng thời bạn có thể lý giải (single writer, phân vùng worker theo key, hoặc một thread I/O chuyên dụng).
- Xác định hình dạng thông điệp sớm: schema ổn định, payload nhỏ gọn và ít sao chép.
- Quyết định luật backpressure từ đầu: drop, delay, degrade, hay shed load. Làm cho nó có thể quan sát và đo lường.
Rồi quyết định cái gì có thể bất đồng bộ mà không phá UX. Quy tắc đơn giản: bất cứ thứ gì thay đổi những gì người dùng thấy “ngay bây giờ” ở lại trên đường quan trọng. Mọi thứ khác chuyển ra ngoài.
Analytics, audit logs và secondary indexing thường an toàn để đẩy khỏi đường nóng. Xác thực, ordering và các bước cần để tạo trạng thái tiếp theo thường không thể.
Lựa chọn runtime và OS ảnh hưởng đến tail latency
Mã nhanh vẫn có thể khiến ứng dụng cảm thấy chậm khi runtime hoặc OS tạm dừng công việc của bạn vào thời điểm không đúng. Mục tiêu không chỉ là throughput cao. Mà là ít bất ngờ ở 1% chậm nhất.
Runtime có garbage collector (JVM, Go, .NET) có thể rất tốt cho năng suất, nhưng chúng có thể gây tạm dừng khi bộ nhớ cần dọn. Các collector hiện đại đã tốt hơn trước, nhưng tail latency vẫn có thể nhảy nếu bạn tạo nhiều đối tượng ngắn hạn dưới tải. Ngôn ngữ không GC (Rust, C, C++) tránh được tạm dừng GC, nhưng đẩy chi phí vào quản lý sở hữu và kỷ luật cấp phát thủ công. Dù thế nào, hành vi bộ nhớ quan trọng ngang với tốc độ CPU.
Thói quen thực tế đơn giản: tìm chỗ xảy ra cấp phát và làm cho chúng nhàm chán. Tái sử dụng đối tượng, dự đoán kích thước buffer, và tránh biến dữ liệu đường nóng thành chuỗi hoặc map tạm thời.
Lựa chọn threading cũng biểu hiện dưới dạng jitter. Mỗi hàng đợi thêm, hop async hoặc handoff thread pool thêm chờ và tăng phương sai. Ưu tiên một số ít thread sống lâu, giữ ranh giới producer-consumer rõ ràng, và tránh gọi chặn trên đường nóng.
Một vài thiết lập OS và container thường quyết định tail của bạn có sạch hay không. CPU bị throttle do giới hạn chặt, neighbor ồn trên host chia sẻ, và logging/metrics đặt sai chỗ có thể tạo tụt đột ngột. Nếu chỉ thay đổi một thứ, bắt đầu bằng đo tỉ lệ cấp phát và context switch trong các đột biến độ trễ.
Dữ liệu, lưu trữ và ranh giới dịch vụ không gây tạm dừng bất ngờ
Nhiều đột biến độ trễ không phải do “mã chậm.” Chúng là các chờ bạn không lường trước: khóa database, cơn bão retry, cuộc gọi cross-service dừng, hoặc cache miss thành vòng trip đầy đủ.
Giữ đường nóng ngắn. Mỗi hop thêm lập lịch, seri hóa, hàng đợi mạng và nhiều chỗ để chặn. Nếu bạn có thể trả lời một yêu cầu từ một process và một datastore, hãy làm trước. Chia thành nhiều service chỉ khi mỗi gọi là tuỳ chọn hoặc có hạn chặt.
Chờ có giới hạn là khác biệt giữa trung bình nhanh và độ trễ dự đoán. Đặt timeout cứng cho các cuộc gọi từ xa, và fail nhanh khi phụ thuộc không khỏe. Circuit breaker không chỉ cứu server. Chúng giới hạn thời gian người dùng bị mắc kẹt.
Khi truy cập dữ liệu gây chặn, tách đường đi. Reads thường muốn hình dạng index, denormalize, thân thiện cache. Writes thường cần durability và ordering. Tách chúng có thể loại bỏ tranh chấp và giảm thời gian khóa. Nếu nhu cầu nhất quán cho phép, ghi chỉ thêm (append-only, event log) thường ổn định hơn so với cập nhật tại chỗ gây khóa hàng nóng hoặc bảo trì nền.
Quy tắc đơn giản cho app thời gian thực: persistence không nên nằm trên đường nóng trừ khi bạn thực sự cần cho độ chính xác. Hình thức tốt hơn thường là: cập nhật trong bộ nhớ, phản hồi, rồi persist bất đồng bộ với cơ chế replay (như outbox hoặc write-ahead log).
Trong nhiều pipeline vòng đệm, điều này thường thành: publish vào buffer trong bộ nhớ, cập nhật state, phản hồi, rồi để consumer riêng batch ghi vào PostgreSQL.
Ví dụ thực tế: cập nhật thời gian thực với độ trễ dự đoán
Hình dung một ứng dụng hợp tác trực tiếp (hoặc một game nhỏ nhiều người) đẩy cập nhật mỗi 16 ms (khoảng 60 lần/giây). Mục tiêu không phải “nhanh theo trung bình.” Mà là “thường dưới 16 ms,” ngay cả khi kết nối của một người dùng kém.
Một luồng kiểu Disruptor đơn giản trông như: input người dùng thành một sự kiện nhỏ, được publish vào vòng đệm đã cấp phát trước, rồi xử lý bởi một chuỗi handler cố định theo thứ tự (validate -> apply -> prepare outbound messages), và cuối cùng broadcast tới client.
Batching có thể giúp ở rìa. Ví dụ, batch gửi outbound theo client mỗi tick để gọi tầng mạng ít lần hơn. Nhưng đừng batch bên trong đường nóng theo cách chờ “thêm chút nữa” để có nhiều sự kiện hơn. Chờ là cách bạn trễ tick.
Khi có cái gì đó chậm, coi đó là vấn đề cô lập. Nếu một handler chậm, cô lập nó sau buffer riêng và publish một công việc nhẹ thay vì chặn vòng lặp chính. Nếu một client chậm, đừng để nó làm backup broadcaster; cho mỗi client một hàng đợi gửi nhỏ và drop hoặc gộp các cập nhật cũ để giữ state mới nhất. Nếu độ sâu buffer tăng, áp dụng backpressure ở biên (dừng chấp nhận input thêm cho tick đó, hoặc giảm tính năng).
Bạn biết nó hiệu quả khi các con số giữ ổn: độ sâu backlog quanh mức 0, sự kiện drop/gộp hiếm và giải thích được, và p99 nằm dưới ngân sách tick trong tải thực tế.
Sai lầm phổ biến tạo đột biến độ trễ
Phần lớn đột biến độ trễ là tự gây ra. Mã có thể nhanh, nhưng hệ thống vẫn tạm dừng khi chờ các thread khác, OS, hoặc bất cứ thứ gì ngoài cache CPU.
Một vài sai lầm lặp lại:
- Dùng khóa chia sẻ khắp nơi vì cảm thấy đơn giản. Một khóa bị contended có thể làm trì hàng loạt yêu cầu.
- Trộn I/O chậm vào đường nóng, như logging đồng bộ, ghi database, hoặc gọi từ xa đồng bộ.
- Giữ hàng đợi không giới hạn. Chúng giấu quá tải cho tới khi bạn có backlog tính bằng giây.
- Theo dõi trung bình thay vì p95 và p99.
- Tối ưu quá sớm. Gắn chặt thread không giúp nếu trì hoãn đến từ GC, tranh chấp hay chờ socket.
Cách nhanh để giảm đột biến là làm cho các chờ hiển hiện và có giới hạn. Đặt công việc chậm sang đường riêng, giới hạn hàng đợi, và quyết định trước điều gì xảy ra khi đầy (drop, shed, hoặc degrade).
Checklist nhanh cho độ trễ dự đoán
Đối xử với độ trễ dự đoán như một tính năng sản phẩm, không phải ngẫu nhiên. Trước khi tune mã, chắc chắn hệ thống có mục tiêu và biện pháp bảo vệ rõ ràng.
- Đặt mục tiêu p99 rõ ràng (và p99.9 nếu quan trọng), sau đó viết ngân sách độ trễ theo từng giai đoạn.
- Giữ đường nóng không có I/O chặn. Nếu I/O phải xảy ra, chuyển nó sang đường phụ và quyết định hành vi khi nó chậm.
- Dùng hàng đợi có giới hạn và định nghĩa hành vi khi quá tải (drop, shed load, coalesce, hoặc backpressure).
- Đo liên tục: độ sâu backlog, thời gian từng giai đoạn, và tail latency.
- Giảm cấp phát trong vòng lặp nóng và làm cho nó dễ thấy trên profile.
Một bài kiểm tra đơn giản: mô phỏng một burst (10x lưu lượng bình thường trong 30 giây). Nếu p99 bùng nổ, hỏi chỗ chờ xuất hiện: hàng đợi lớn dần, consumer chậm, tạm dừng GC, hay tài nguyên chia sẻ?
Bước tiếp theo: áp dụng vào ứng dụng của bạn
Xem mẫu Disruptor như một quy trình, không chỉ là lựa chọn thư viện. Chứng minh độ trễ dự đoán với một lát cắt mỏng trước khi thêm tính năng.
Chọn một hành động người dùng cần cảm thấy tức thì (ví dụ “giá mới tới, UI cập nhật”). Viết ngân sách end-to-end, rồi đo p50, p95 và p99 từ ngày đầu.
Một chuỗi thường hiệu quả:
- Xây pipeline mỏng với một input, một vòng lặp lõi và một output. Xác thực p99 dưới tải sớm.
- Làm rõ trách nhiệm (ai quản lý state, ai publish, ai consume), và giữ trạng thái chia sẻ nhỏ.
- Thêm đồng thời và buffering từng bước nhỏ, và giữ các thay đổi có thể hoàn nguyên.
- Triển khai gần người dùng khi ngân sách chặt, rồi đo lại dưới tải thực tế (cùng kích thước payload, cùng mẫu burst).
Nếu bạn xây dựng trên Koder.ai (koder.ai), có thể hữu ích khi vẽ trước luồng sự kiện trong Planning Mode để hàng đợi, khóa và ranh giới dịch vụ không xuất hiện một cách tình cờ. Snapshots và rollback cũng giúp dễ chạy các thí nghiệm độ trễ lặp lại và hoàn tác thay đổi làm tăng throughput nhưng xấu đi p99.
Giữ phép đo trung thực. Dùng một kịch bản kiểm tra cố định, làm nóng hệ thống, và ghi lại cả throughput lẫn latency. Khi p99 nhảy lên cùng tải, đừng bắt đầu bằng “tối ưu mã.” Hãy tìm các tạm dừng từ GC, neighbor ồn, bùng nổ logging, lập lịch thread, hoặc các gọi chặn ẩn.