Những gì tìm kiếm phía máy chủ tức thì nên cung cấp
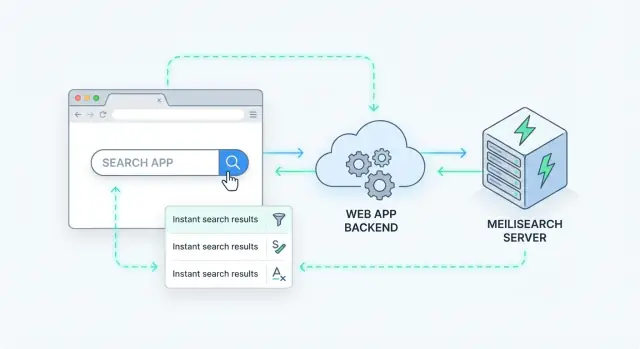
Tìm kiếm phía máy chủ nghĩa là truy vấn được xử lý trên server của bạn (hoặc một dịch vụ tìm kiếm chuyên dụng), không phải trong trình duyệt. Ứng dụng của bạn gửi một yêu cầu tìm kiếm, server chạy nó trên một index và trả về các kết quả đã xếp hạng.
Điều này quan trọng khi dataset quá lớn để gửi cho client, khi bạn cần độ liên quan nhất quán giữa các nền tảng, hoặc khi kiểm soát truy cập là bắt buộc (ví dụ, công cụ nội bộ nơi người dùng chỉ thấy những gì họ được phép). Đây cũng là lựa chọn mặc định khi bạn muốn có phân tích, logging và hiệu năng dự đoán được.
Người dùng mong đợi (và nhận ra ngay lập tức)
Người dùng không nghĩ về engine tìm kiếm — họ đánh giá trải nghiệm. Một luồng tìm kiếm “tức thì” tốt thường có nghĩa:
- Phản hồi nhanh: kết quả cập nhật ngay khi người dùng gõ, không có khoảng dừng khó chịu.
- Gõ sai không làm vỡ trải nghiệm: lỗi chính tả, chữ hoán vị, và từ chưa hoàn chỉnh vẫn tìm được mục đúng.
- Điều khiển hữu dụng: lọc (danh mục, trạng thái, khoảng giá), sắp xếp (mới nhất, rẻ nhất), và facets (số lượng cho mỗi bộ lọc) cảm thấy tự nhiên.
- Thứ tự hợp lý: kết quả “tốt nhất” xuất hiện trước, không chỉ là mục mới nhất hay nhồi nhét từ khóa.
Nếu thiếu bất kỳ điều nào, người dùng sẽ thử các truy vấn khác, cuộn nhiều hơn, hoặc bỏ tìm kiếm hoàn toàn.
Hướng dẫn này giúp bạn làm gì
Bài viết này là hướng dẫn thực tế để xây dựng trải nghiệm đó với Meilisearch. Chúng ta sẽ trình bày cách thiết lập an toàn, cách cấu trúc và đồng bộ dữ liệu đã lập chỉ mục, cách tinh chỉnh độ liên quan và quy tắc xếp hạng, cách thêm bộ lọc/sắp xếp/facets, và cách nghĩ về bảo mật và mở rộng để tìm kiếm vẫn nhanh khi ứng dụng phát triển.
Nơi tìm kiếm phía máy chủ tỏa sáng
Meilisearch phù hợp cho:
- Tài liệu và cơ sở kiến thức (tìm trang nhanh, chịu lỗi chính tả)
- Danh mục sản phẩm và thị trường (bộ lọc và sắp xếp là thiết yếu)
- Công cụ nội bộ (tìm kiếm có ý thức quyền truy cập trên các bản ghi)
- Trang nội dung (tìm kiếm trên bài viết, hướng dẫn, FAQ)
Mục tiêu xuyên suốt: kết quả cảm thấy tức thì, chính xác và đáng tin cậy — mà không biến tìm kiếm thành một dự án kỹ thuật lớn.
Tổng quan Meilisearch bằng ngôn ngữ dễ hiểu
Meilisearch là một engine tìm kiếm bạn chạy song song với ứng dụng. Bạn gửi cho nó các tài liệu (như sản phẩm, bài viết, người dùng, hoặc phiếu hỗ trợ), và nó xây dựng một index tối ưu cho truy vấn nhanh. Backend (hoặc frontend) của bạn sau đó truy vấn Meilisearch qua một HTTP API đơn giản và nhận lại kết quả đã xếp hạng trong vài mili-giây.
Những gì bạn nhận được ngay từ đầu
Meilisearch tập trung vào những tính năng người dùng mong đợi từ tìm kiếm hiện đại:
- Chịu lỗi chính tả để “iphnoe” vẫn tìm được “iPhone”.
- Điều khiển độ liên quan (quy tắc xếp hạng) để bạn quyết định “khớp tốt nhất” nghĩa là gì với doanh nghiệp.
- Bộ lọc, sắp xếp và facets để người dùng thu hẹp kết quả theo các thuộc tính như danh mục, khoảng giá, tình trạng, hoặc tags.
Nó được thiết kế để cảm thấy phản hồi và khoan dung, ngay cả khi truy vấn ngắn, hơi sai, hoặc mơ hồ.
Meilisearch không phải là gì
Meilisearch không thay thế database chính của bạn. Database vẫn là nguồn chân lý cho các ghi, giao dịch và ràng buộc. Meilisearch lưu một bản sao các trường bạn chọn để làm searchable, filterable, hoặc hiển thị.
Mô hình tư duy tốt: database để lưu và cập nhật dữ liệu, Meilisearch để tìm nhanh.
Kỳ vọng hiệu năng (những gì ảnh hưởng tới tốc độ)
Meilisearch có thể rất nhanh, nhưng kết quả phụ thuộc vào vài yếu tố thực tế:
- Kích thước và hình dạng dữ liệu (số tài liệu, số trường, và lượng văn bản bạn lập chỉ mục)
- Phần cứng (CPU, RAM, disk)
- Cấu hình (thuộc tính nào searchable/filterable/sortable, và tần suất bạn reindex)
Với dataset nhỏ-trung bình, bạn thường có thể chạy trên một máy. Khi index lớn lên, bạn sẽ muốn cân nhắc kỹ hơn những gì lập chỉ mục và cách giữ nó cập nhật — những chủ đề mà chúng ta sẽ bàn ở phần sau.
Lập kế hoạch index và mô hình dữ liệu
Trước khi cài đặt bất cứ thứ gì, quyết định bạn sẽ thực sự tìm kiếm gì. Meilisearch chỉ cảm thấy “tức thì” nếu index và tài liệu của bạn phù hợp với cách người dùng duyệt ứng dụng.
Ánh xạ thực thể tới index
Bắt đầu bằng cách liệt kê các thực thể có thể tìm kiếm — thường là products, articles, users, help docs, locations, v.v. Trong nhiều app, cách sạch nhất là một index cho mỗi loại thực thể (ví dụ: products, articles). Điều đó giữ quy tắc xếp hạng và bộ lọc dễ đoán.
Nếu UX của bạn tìm kiếm nhiều loại trong một ô (“tìm mọi thứ”), bạn vẫn có thể giữ các index riêng và gộp kết quả ở backend, hoặc tạo một index “global” chuyên dụng sau. Đừng cố nhồi mọi thứ vào một index trừ khi trường và bộ lọc thực sự đồng nhất.
Chọn khóa chính và hình dạng tài liệu
Mỗi tài liệu cần một định danh ổn định (primary key). Chọn thứ:
- không bao giờ (hoặc rất hiếm) thay đổi
- là duy nhất trong index
- đã tồn tại trong database của bạn (ví dụ:
id, sku, slug)
Với hình dạng tài liệu, ưu tiên các trường phẳng khi có thể. Cấu trúc phẳng dễ lọc và sắp xếp hơn. Trường lồng là ổn khi chúng đại diện cho một gói chặt chẽ, không thay đổi (ví dụ: một object author), nhưng tránh lồng sâu giống như sơ đồ quan hệ — tài liệu tìm kiếm nên tối ưu cho đọc, không giống cấu trúc database.
Phân loại trường: searchable, filterable, displayed
Một cách thiết kế tài liệu thực tế là gắn nhãn mỗi trường với một vai trò:
- Searchable: văn bản người dùng gõ (title, name, description)
- Filterable: thuộc tính dùng làm ràng buộc (category, price range, status, tags)
- Displayed: thứ bạn trả về cho UI (title, URL thumbnail, đoạn trích ngắn)
Điều này tránh sai lầm phổ biến: lập chỉ mục một trường “phòng khi cần” rồi tự hỏi tại sao kết quả nhiễu hoặc bộ lọc chậm.
Lên kế hoạch cho nội dung đa ngôn ngữ
“Ngôn ngữ” có thể nghĩa khác nhau trong dữ liệu của bạn:
- Ngôn ngữ tài liệu (mỗi bài có
lang: "en")
- Locale người dùng (ngôn ngữ giao diện)
- trường hỗn hợp nhiều ngôn ngữ (tên sản phẩm có nhiều bản dịch)
Quyết định sớm bạn sẽ dùng index riêng cho mỗi ngôn ngữ (đơn giản và dễ đoán) hay một index với trường ngôn ngữ (ít index hơn, logic phức tạp hơn). Lựa chọn phụ thuộc vào việc người dùng có tìm kiếm trong một ngôn ngữ mỗi lần hay không và bạn lưu bản dịch ra sao.
Cài đặt và chạy Meilisearch an toàn
Chạy Meilisearch đơn giản, nhưng “an toàn theo mặc định” cần vài lựa chọn có chủ ý: nơi triển khai, cách lưu dữ liệu và cách quản lý master key.
Các tùy chọn triển khai (chọn cái bạn vận hành được)
- Docker (phổ biến nhất): nhanh để bắt đầu, dễ nâng cấp, nhất quán giữa các môi trường. Kết hợp với một persistent volume.
- VM hoặc bare metal: tốt khi bạn đã có pipeline triển khai Linux chuẩn (systemd, log rotation, backup).
- Managed hosting: nếu đội bạn không muốn duy trì server, tìm nhà cung cấp Meilisearch quản lý hoặc nền tảng cung cấp như addon. Bạn sẽ đánh đổi linh hoạt lấy vận hành đơn giản hơn.
Cơ bản môi trường: lưu trữ, bộ nhớ, backup, giám sát
Lưu trữ: Meilisearch ghi index ra đĩa. Đặt thư mục dữ liệu trên storage bền vững (không dùng storage ephemeral của container). Lên dung lượng cho tăng trưởng: index có thể mở rộng nhanh với nhiều trường văn bản và nhiều thuộc tính.
Bộ nhớ: cấp đủ RAM để giữ tìm kiếm phản hồi tốt dưới tải. Nếu thấy swapping, hiệu năng sẽ giảm.
Backup: sao lưu thư mục dữ liệu Meilisearch (hoặc dùng snapshot ở tầng lưu trữ). Thử khôi phục ít nhất một lần; backup không thể khôi phục chỉ là một file.
Giám sát: theo dõi CPU, RAM, disk usage và disk I/O. Cũng giám sát trạng thái process và log lỗi. Tối thiểu, cảnh báo nếu service dừng hoặc dung lượng đĩa gần đầy.
Thiết lập và lưu master key an toàn
Luôn chạy Meilisearch với master key ở mọi môi trường ngoài phát triển local. Lưu nó trong secret manager hoặc store biến môi trường mã hóa (không lưu trong Git, không commit .env plain-text).
Ví dụ (Docker):
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
Cũng nên cân nhắc quy tắc mạng: bind vào interface private hoặc hạn chế truy cập đến chỉ backend của bạn.
Checklist khi khởi động lần đầu
curl -s http://localhost:7700/version
Lập chỉ mục tài liệu và giữ đồng bộ
Bù đắp chi phí xây dựng
Bù đắp chi phí xây dựng: chia sẻ sản phẩm với Koder.ai hoặc giới thiệu đồng đội để nhận tín dụng nền tảng.
Lập chỉ mục Meilisearch là bất đồng bộ: bạn gửi tài liệu, Meilisearch tạo task, và chỉ sau khi task đó thành công tài liệu mới có thể tìm được. Hãy xem việc lập chỉ mục như một hệ thống job, không phải một request đơn.
Luồng lập chỉ mục đơn giản (thêm → đợi → xác minh)
- Thêm tài liệu (đảm bảo mỗi tài liệu có id ổn định, thường là
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
- Đợi task. API trả về
taskUid. Poll cho đến khi trạng thái là succeeded (hoặc failed).
curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Xác minh counts và tìm kiếm cơ bản. Xác nhận index có số tài liệu mong đợi và một truy vấn đơn giản trả về kết quả.
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Nếu counts không khớp, đừng đoán — kiểm tra chi tiết lỗi của task trước.
Batching để tránh bất ngờ sau này
Batching là về giữ task dự đoán được và dễ phục hồi.
- Bắt đầu với 1.000–10.000 tài liệu mỗi batch, hoặc giới hạn theo kích thước payload (với nhiều app, 5–15 MB mỗi request là hợp lý).
- Ưu tiên nhiều batch nhỏ hơn một upload khổng lồ; dễ retry và dễ xác định dữ liệu xấu.
- Nếu có thay đổi thường xuyên, lập chỉ mục liên tục theo lô (ví dụ, mỗi phút) thay vì rebuild toàn bộ.
Cập nhật vs reindex toàn bộ
addDocuments hoạt động như một upsert: tài liệu có cùng primary key sẽ được cập nhật, tài liệu mới thì chèn. Dùng cách này cho cập nhật bình thường.
Thực hiện reindex toàn bộ khi:
- bạn thay đổi đáng kể hình dạng tài liệu,
- cần tính lại các trường dẫn xuất,
- pipeline đồng bộ bị lệch và bạn muốn reset sạch.
Để xóa, gọi deleteDocument(s) rõ ràng; nếu không bản ghi cũ có thể tồn tại.
Idempotency: retry an toàn khi job thất bại
Lập chỉ mục nên có thể retry. Chìa khóa là id tài liệu ổn định.
- Nếu một batch timeout, bạn có thể gửi lại cùng batch: upsert + id ổn định sẽ không tạo bản ghi trùng.
- Lưu
taskUid trả về cùng với id batch/job của bạn, và retry dựa trên trạng thái task.
- Nếu chạy queue, làm worker theo kiểu “at-least-once” an toàn: trùng lặp không gây hại.
Dữ liệu mẫu cho môi trường pre-production
Trước dữ liệu production, lập chỉ mục một bộ dữ liệu nhỏ (200–500 item) khớp với các trường thực. Ví dụ: tập products với id, name, description, category, brand, price, inStock, createdAt. Điều này đủ để xác minh luồng task, counts, và hành vi update/delete — mà không phải chờ import lớn.
Độ liên quan và quy tắc xếp hạng bạn có thể kiểm soát
"Độ liên quan" là: cái gì hiện lên trước, và vì sao. Meilisearch cho phép chỉnh mà không bắt bạn tự xây hệ thống scoring riêng.
Bắt đầu với các thuộc tính đúng
Hai cài đặt định hình khả năng của Meilisearch:
searchableAttributes: các trường Meilisearch tìm khi người dùng gõ (ví dụ: title, summary, tags). Thứ tự quan trọng: trường đứng trước được coi là quan trọng hơn.displayedAttributes: các trường trả về trong response. Điều này quan trọng với quyền riêng tư và kích thước payload — trường không hiển thị sẽ không được gửi lại.
Mốc thực tế là chỉ để vài trường có tín hiệu cao là searchable (title, văn bản chính), và giữ displayedAttributes chỉ những gì UI cần.
Quy tắc xếp hạng ảnh hưởng thứ tự kết quả
Meilisearch sắp xếp tài liệu khớp bằng ranking rules — một pipeline các “tie-breaker”. Về mặt khái niệm, nó ưu tiên:
- kết quả khớp truy vấn tốt (bao gồm chịu lỗi chính tả), rồi
- kết quả có khớp mạnh hơn (từ gần nhau hơn, khớp ở thuộc tính quan trọng hơn), rồi
- kết quả phù hợp logic kinh doanh (sắp xếp tuỳ chỉnh như mới hơn hoặc phổ biến hơn).
Bạn không cần thuộc lòng chi tiết để tinh chỉnh hiệu quả; chủ yếu là chọn trường nào quan trọng và khi nào áp dụng sắp xếp tuỳ chỉnh.
Mục tiêu tinh chỉnh phổ biến (kèm ví dụ)
Mục tiêu: “Khớp tiêu đề thắng.” Đặt title lên đầu:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Mục tiêu: “Nội dung mới hơn lên đầu.” Thêm một quy tắc sort và sort khi gửi truy vấn (hoặc đặt custom ranking):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Sau đó request:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Mục tiêu: “Đẩy sản phẩm phổ biến.” Làm popularity thành sortable và sắp xếp theo nó khi cần.
Đánh giá thay đổi với test before/after đơn giản
Chọn 5–10 truy vấn thực tế người dùng gõ. Lưu kết quả top trước khi thay đổi, rồi so sánh sau.
Ví dụ:
- Trước: truy vấn
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- Sau (title-first + exactness): truy vấn
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Nếu danh sách “sau” phù hợp ý định người dùng hơn, giữ cài đặt. Nếu làm hỏng các edge case, điều chỉnh từng thứ một (thứ tự attribute, rồi ranking rules) để biết thay đổi nào mang lại cải thiện.
Bộ lọc, sắp xếp và facets cho tìm kiếm thực tế
Một ô tìm kiếm tốt không chỉ là “gõ từ, có kết quả.” Người dùng còn muốn thu hẹp (“chỉ mục có sẵn”) và sắp xếp (“rẻ nhất trước”). Trong Meilisearch, làm điều này bằng filters, sorting, và facets.
Filters và facets (cùng ý, UI khác nhau)
Một filter là một quy tắc bạn áp dụng cho tập kết quả. Một facet là thứ bạn hiển thị trong UI để giúp người dùng xây bộ lọc đó (thường là checkbox hoặc số lượng).
Ví dụ không kỹ thuật:
- Category: “Shoes”, “Jackets”, “Accessories”
- Price: “Dưới $50”, “$50–$100”
- Status: “In stock”, “Backorder”, “Archived”
Người dùng có thể tìm “running” rồi lọc category = Shoes và status = in_stock. Facets hiển thị số lượng như “Shoes (128)” để người dùng biết có bao nhiêu lựa chọn.
Cấu hình fields filterable và sortable (nếu không sẽ không hoạt động)
Meilisearch cần bạn bật rõ các trường dùng cho lọc và sắp xếp.
- Đánh dấu trường là filterable khi bạn sẽ dùng chúng trong filters:
category, status, brand, price, created_at (nếu lọc theo thời gian), tenant_id (nếu cô lập khách hàng).
- Đánh dấu trường là sortable khi bạn sẽ sắp xếp theo chúng:
price, rating, created_at, popularity.
Giữ danh sách gọn. Làm mọi thứ filterable/sortable có thể tăng kích thước index và làm cập nhật chậm.
Phân trang và giới hạn để giữ tìm kiếm nhanh
Dù có 50.000 kết quả, người dùng chỉ thấy trang đầu. Dùng trang nhỏ (thường 20–50 kết quả), đặt limit hợp lý, và phân trang với offset (hoặc tính năng phân trang mới nếu bạn thích). Cũng giới hạn độ sâu trang tối đa trong app để tránh các request tốn kém như “trang 400”.
Từ đồng nghĩa và stop words (tuỳ chọn, dùng thận trọng)
- Synonyms giúp khi từ khác nhau nhưng nghĩa giống nhau (ví dụ: “hoodie” ↔ “sweatshirt”). Thêm dần và xem analytics — nhiều synonym có thể tạo kết quả bất ngờ.
- Stop words loại bỏ từ thường gặp (“the”, “and”). Chúng có thể giảm nhiễu, nhưng cũng làm hỏng các tìm kiếm đúng nghĩa như tên riêng (“The Who”, “A Team”). Chỉ tuỳ chỉnh stop words khi có vấn đề rõ ràng cần fix.
Tích hợp Meilisearch vào backend ứng dụng của bạn
Thiết kế mô hình tìm kiếm của bạn
Sử dụng Chế độ Lập kế hoạch để vạch sơ đồ index, trường và quyền trước khi viết mã.
Cách đơn giản để thêm tìm kiếm phía máy chủ là xem Meilisearch như dịch vụ dữ liệu chuyên dụng chạy sau API của bạn. App nhận yêu cầu tìm kiếm, gọi Meilisearch, rồi trả về response đã tuyển chọn cho client.
Mẫu backend đơn giản
Hầu hết đội triển khai luồng như sau:
- Client gọi endpoint của bạn (ví dụ:
GET /api/search?q=wireless+headphones&limit=20).
- Backend xác thực input, áp dụng luật nghiệp vụ, và quyết định index nào cần truy vấn.
- Backend gọi Search API của Meilisearch với truy vấn người dùng cộng bộ lọc/sort.
- Backend xử lý kết quả sau (ẩn trường riêng tư, ghép với dữ liệu DB, áp dụng quyền truy cập).
- Backend trả về response dạng ổn định cho client.
Mẫu này giữ Meilisearch có thể thay thế được và ngăn frontend phụ thuộc vào nội dung index.
Nếu bạn xây app mới (hoặc rebuild tool nội bộ) và muốn mẫu này triển khai nhanh, nền tảng vibe-coding như Koder.ai có thể giúp scaffold toàn bộ luồng — UI React, backend Go, và PostgreSQL — sau đó tích hợp Meilisearch phía sau một endpoint /api/search để client đơn giản và quyền truy cập giữ ở server.
Truy vấn frontend vs backend (và vì sao backend an toàn hơn)
Meilisearch hỗ trợ truy vấn từ client, nhưng truy vấn qua backend thường an toàn hơn vì:
- Bí mật giữ ở phía server: bạn không lộ các API key có quyền hạn.
- Ủy quyền nhất quán: backend có thể áp quyền “người này được xem gì” trước khi trả kết quả.
- Bạn kiểm soát độ phức tạp truy vấn: giới hạn bộ lọc, tùy chọn sort và phân trang để bảo vệ hiệu năng.
Truy vấn từ frontend vẫn hợp lý cho dữ liệu công khai với key bị hạn chế, nhưng nếu có quy tắc hiển thị theo người dùng, hãy route tìm kiếm qua server.
Cache các truy vấn phổ biến mà không làm hỏng độ liên quan
Lưu lượng tìm kiếm thường lặp lại (“iphone case”, “return policy”). Thêm cache ở lớp API:
- Cache toàn bộ response trong khoảng ngắn (ví dụ 10–60 giây) cho traffic ẩn danh.
- Chuẩn hóa cache key (bỏ khoảng trắng thừa, lowercase, bao gồm bộ lọc/sort).
- Invalidate thận trọng: với index thay đổi nhanh, giữ TTL ngắn thay vì cố gắng purge triệt để.
Rate limiting và kiểm soát lạm dụng
Xem tìm kiếm là endpoint công khai:
- Áp giới hạn theo IP hoặc theo user.
- Đặt
limit tối đa và độ dài truy vấn tối đa.
- Xem xét chặn mềm các bot rõ ràng trong khi vẫn cho phép người dùng thật.
Những điều cơ bản về bảo mật: khóa, kiểm soát truy cập và đa khách hàng
Meilisearch thường nằm “sau” app của bạn vì nó có thể trả nhanh dữ liệu nhạy cảm. Đối xử nó như một database: khóa chặt và chỉ cho phép mỗi caller thấy những gì họ được phép.
API keys: master vs scoped (nguyên tắc ít quyền nhất)
Meilisearch có master key có thể làm mọi thứ: tạo/xóa index, cập nhật settings, đọc/ghi tài liệu. Giữ nó chỉ ở server.
Cho ứng dụng, tạo API keys giới hạn hành động và index. Mẫu phổ biến:
- Jobs backend: key có thể viết tài liệu và cập nhật settings, nhưng chỉ trên index cụ thể.
- App server: key chỉ đọc cho tìm kiếm.
- Client (nếu thực sự cần): key tìm kiếm giới hạn chặt với bộ lọc cố định.
Nguyên tắc ít quyền nhất nghĩa là nếu key bị lộ, nó không thể xóa dữ liệu hoặc đọc index không liên quan.
Multi-tenancy: index riêng hay filter theo tenantId
Nếu bạn phục vụ nhiều khách hàng (tenant), có hai lựa chọn chính:
1) Một index cho mỗi tenant.
Dễ lý giải và giảm rủi ro truy cập chéo giữa tenant. Hạn chế: nhiều index để quản lý, cần cập nhật settings nhất quán.
2) Shared index + filter theo tenant.
Lưu trường tenantId trên mọi tài liệu và yêu cầu filter như tenantId = "t_123" cho mọi tìm kiếm. Cách này có thể scale tốt, nhưng chỉ khi bạn đảm bảo mọi request luôn áp filter (tốt nhất là qua scoped key để caller không thể bỏ filter).
Ngăn rò rỉ dữ liệu: kiểm soát trường trả về
Ngay cả khi tìm kiếm đúng, kết quả có thể tiết lộ trường bạn không muốn hiển thị (email, ghi chú nội bộ, giá vốn). Cấu hình những gì được trả:
- Giới hạn displayed/retrievable attributes thành danh sách cho phép an toàn.
- Giữ các trường nhạy cảm chỉ lập chỉ mục khi thật sự cần — và tránh trả chúng trong kết quả.
Thử nhanh “worst-case”: tìm một từ phổ biến và xác nhận không có trường riêng tư xuất hiện.
Bảo mật vận hành cơ bản
- Hạn chế truy cập mạng: bind vào localhost hoặc mạng private, và chỉ cho phép server app inbound.
- Đặt Meilisearch sau reverse proxy nếu cần TLS và rate limiting.
- Lưu khóa trong secrets manager (không trong source control hoặc bundle frontend) và xoay khóa định kỳ.
Nếu không chắc khóa nào nên đặt client-side, giả sử “không” và giữ tìm kiếm phía server.
Hiệu năng và mở rộng mà không đoán mò
Đưa tìm kiếm lên mobile
Tạo client Flutter gọi endpoint tìm kiếm backend của bạn một cách nhất quán.
Meilisearch nhanh khi bạn quan tâm hai workload: indexing (ghi) và search queries (đọc). Hầu hết độ chậm bí ẩn là do một trong hai cạnh này cạnh tranh CPU, RAM hoặc disk.
Nơi hiệu năng thường tắc nghẽn
Tải lập chỉ mục có thể tăng mạnh khi bạn import batch lớn, chạy cập nhật thường xuyên, hoặc thêm nhiều trường searchable. Lập chỉ mục là task nền, nhưng vẫn tiêu thụ CPU và băng thông đĩa. Nếu hàng đợi task tăng, tìm kiếm có thể chậm dù lưu lượng truy vấn không đổi.
Tải truy vấn tăng theo traffic, nhưng cũng theo tính năng: nhiều bộ lọc, nhiều facets, tập kết quả lớn, và độ chịu lỗi chính tả có thể tăng khối lượng công việc cho mỗi request.
Disk I/O thường là thủ phạm im lặng. Đĩa chậm (hoặc noisy neighbors trên volume chia sẻ) có thể biến “tức thì” thành “cuối cùng cũng có”. NVMe/SSD là baseline điển hình cho production.
Các bước mở rộng thực tế
Bắt đầu với sizing đơn giản: cấp đủ RAM để giữ index nóng và đủ CPU cho peak QPS. Sau đó tách mối quan tâm:
- Nếu lập chỉ mục can thiệp vào đọc, lên lịch import lớn ngoài giờ cao điểm và ưu tiên batch lớn hơn nhiều batch nhỏ.
- Thêm replica để cao độ khả dụng và tăng khả năng đọc (app có thể load-balance request giữa các replica).
- Sharding: Meilisearch không shard phân tán tự động. Nếu vượt quá node đơn, bạn có thể phân vùng dữ liệu ở tầng ứng dụng (theo tenant, vùng, hoặc khoảng thời gian) thành nhiều index hoặc cluster.
Những gì cần giám sát (để không phải đoán mò)
Theo dõi một tập tín hiệu nhỏ:
- Độ trễ tìm kiếm (p50/p95) và throughput
- Độ dài hàng đợi task / thời gian xử lý task (hàng đợi tăng nghĩa là indexing không kịp)
- CPU, RAM, disk usage và disk I/O wait
- Tỷ lệ lỗi (timeouts, 4xx/5xx, task failed)
Backup và kế hoạch nâng cấp
Backup nên là routine, không phải việc làm gấp. Dùng tính năng snapshot của Meilisearch theo lịch, lưu snapshot ra ngoài, và định kỳ kiểm tra khôi phục. Với nâng cấp, đọc release notes, thử nâng cấp trong môi trường non-prod, và lên kế hoạch thời gian reindex nếu phiên bản ảnh hưởng hành vi lập chỉ mục.
Nếu bạn đã dùng snapshot môi trường và rollback trên nền tảng của mình (ví dụ, qua workflow snapshots/rollback của Koder.ai), đồng bộ rollout tìm kiếm với cùng kỷ luật: snapshot trước thay đổi, kiểm tra health, và có đường lui nhanh về trạng thái tốt đã biết.
Khắc phục sự cố và checklist rollout thực tế
Ngay cả với tích hợp sạch, vấn đề tìm kiếm thường rơi vào vài nhóm lặp lại. Tin tốt: Meilisearch cung cấp đủ thông tin (tasks, logs, settings xác định) để debug nhanh — nếu bạn tiếp cận có hệ thống.
Vấn đề thường gặp (và thường có nghĩa gì)
- “Bộ lọc không hoạt động”: trường chưa được thêm vào
filterableAttributes, hoặc tài liệu lưu nó ở dạng không mong đợi (string vs array vs object lồng).
- “Kết quả xếp hạng kỳ lạ”: ranking rules, synonyms, stop words, hoặc thiếu
sortableAttributes/rankingRules kéo mục “sai” lên trên.
- “Tìm kiếm hiển thị dữ liệu cũ”: task lập chỉ mục vẫn đang xử lý, bạn ghi vào index khác với index đang đọc, hoặc pipeline sync bị rớt cập nhật/xóa.
Luồng debug giữ đầu óc tỉnh táo
Bắt đầu bằng việc kiểm tra Meilisearch đã áp dụng thay đổi gần nhất chưa.
- Kiểm tra trạng thái task: mọi thay đổi settings và update tài liệu tạo task bất đồng bộ. Nếu task thất bại, sửa trước (payload sai, kiểu trường sai, tài liệu quá lớn).
- Dùng logs với một câu hỏi duy nhất: “Server có chấp nhận request của tôi không?” rồi “Nó đã xử lý xong chưa?” Tránh scan mọi thứ cùng lúc.
- Tạo truy vấn tối thiểu có thể tái lập:
- Chọn một index.
- Dùng truy vấn trả về tập nhỏ, ổn định.
- Thêm ràng buộc từng bước:
filter, rồi sort, rồi facets.
Nếu không giải thích được một kết quả, tạm thời lược cấu hình: bỏ synonyms, giảm tweaks ranking, và test với dataset nhỏ. Vấn đề liên quan phức tạp dễ thấy hơn trên 50 tài liệu hơn là trên 5 triệu.
Chiến lược rollout: giảm vùng ảnh hưởng
- Test index trước: xây
your_index_v2 song song, áp settings, và replay một mẫu truy vấn production.
- Canary rollout: chuyển một phần nhỏ traffic tìm kiếm sang index hoặc settings mới, so sánh click-through và tỉ lệ “no results”.
- Hành vi fallback: quyết định người dùng thấy gì nếu tìm kiếm chậm hoặc không sẵn có — kết quả cache, truy vấn đơn giản hơn, hoặc trạng thái “thử lại”. Đừng để lỗi tìm kiếm làm hỏng cả trang.
Checklist bước tiếp theo
- Xác minh
filterableAttributes và sortableAttributes phù hợp yêu cầu UI.
- Xác nhận các task lập chỉ mục hoàn tất sau mỗi deployment.
- Thêm một monitor “sức khỏe tìm kiếm” nhỏ (độ trễ + task failure).
- Thực hành rollback: chuyển traffic về index trước đó.
Related guides: /blog (search reliability, indexing patterns, and production rollout tips).