27 thg 7, 2025·8 phút
Khi ngôn ngữ, cơ sở dữ liệu và framework hoạt động như một hệ thống
Tìm hiểu cách ngôn ngữ, cơ sở dữ liệu và framework hoạt động như một hệ thống. So sánh các đánh đổi, điểm tích hợp và cách thực tế để chọn một stack đồng bộ.
Tìm hiểu cách ngôn ngữ, cơ sở dữ liệu và framework hoạt động như một hệ thống. So sánh các đánh đổi, điểm tích hợp và cách thực tế để chọn một stack đồng bộ.
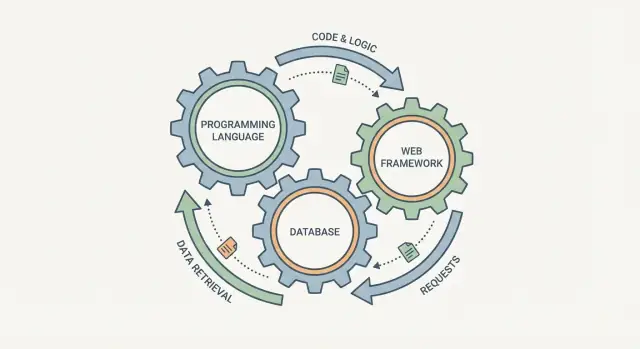
Rất dễ bị cám dỗ khi chọn một ngôn ngữ lập trình, một cơ sở dữ liệu và một framework web như ba ô tích độc lập. Trong thực tế, chúng hoạt động giống những bánh răng liên kết: thay đổi một cái, và những cái khác sẽ cảm nhận được.
Một framework web định hình cách xử lý request, cách dữ liệu được validate và cách lỗi được hiển thị. Cơ sở dữ liệu quyết định điều gì là “dễ lưu” nhất, cách bạn truy vấn thông tin và những đảm bảo bạn nhận được khi nhiều người dùng cùng thao tác. Ngôn ngữ nằm ở giữa: nó quyết định bạn có thể biểu đạt quy tắc an toàn tới đâu, cách quản lý concurrency, và những thư viện cùng tooling bạn có thể dựa vào.
Xem stack như một hệ thống duy nhất có nghĩa là bạn không tối ưu mỗi phần một cách độc lập. Bạn chọn một tổ hợp mà:
Bài viết này giữ tính thực tế và cố ý không quá kỹ thuật. Bạn không cần thuộc lòng lý thuyết cơ sở dữ liệu hay nội bộ ngôn ngữ—chỉ cần thấy các lựa chọn ảnh hưởng như thế nào trong toàn bộ ứng dụng.
Một ví dụ nhanh: dùng cơ sở dữ liệu không schema cho dữ liệu doanh nghiệp có cấu trúc cao và nặng báo cáo thường dẫn tới các “quy tắc” rải rác trong mã ứng dụng và phân tích sau này khó hiểu. Phù hợp hơn là ghép domain đó với cơ sở dữ liệu quan hệ và một framework khuyến khích validate và migrations nhất quán, để dữ liệu của bạn giữ được tính mạch lạc khi sản phẩm phát triển.
Khi bạn lên kế hoạch stack cùng nhau, bạn đang thiết kế một tập các đánh đổi—không phải ba ván cược riêng biệt.
Một cách hữu ích để nghĩ về “stack” là như một pipeline duy nhất: một request người dùng vào hệ thống, và một phản hồi (kèm dữ liệu được lưu) ra. Ngôn ngữ lập trình, framework web và cơ sở dữ liệu không phải là những lựa chọn độc lập—chúng là ba phần của cùng một hành trình.
Hãy tưởng tượng một khách hàng cập nhật địa chỉ giao hàng.
/account/address). Validation kiểm tra dữ liệu vào đầy đủ và hợp lý.Khi ba thứ này đồng bộ, một request chảy mượt. Khi chúng không khớp, bạn gặp ma sát: truy cập dữ liệu vụng về, validate rò rỉ và lỗi nhất quán tinh tế.
Hầu hết tranh luận về "stack" bắt đầu từ ngôn ngữ hay thương hiệu cơ sở dữ liệu. Một điểm bắt đầu tốt hơn là mô hình dữ liệu của bạn—vì nó quyết định im lặng cái gì sẽ tự nhiên (hoặc đau đớn) ở mọi chỗ khác: validate, truy vấn, API, migration và cả quy trình làm việc của nhóm.
Ứng dụng thường cân bằng bốn dạng cùng lúc:
Một sự phù hợp tốt là khi bạn không phải dành cả ngày dịch giữa các hình dạng. Nếu dữ liệu cốt lõi liên kết cao (users ↔ orders ↔ products), rows và joins có thể giữ logic đơn giản. Nếu dữ liệu chủ yếu là “một blob cho mỗi thực thể” với trường biến, documents có thể giảm thủ tục—cho tới khi bạn cần báo cáo ngang thực thể.
Khi DB có schema mạnh, nhiều quy tắc có thể nằm gần dữ liệu: kiểu, ràng buộc, khóa ngoại, tính duy nhất. Điều đó thường giảm kiểm tra trùng lặp giữa các dịch vụ.
Với cấu trúc linh hoạt, quy tắc dịch chuyển lên ứng dụng: code validate, payload có version, backfill và logic đọc cẩn trọng ("nếu trường tồn tại thì..."). Việc này phù hợp khi yêu cầu sản phẩm thay đổi hàng tuần, nhưng tăng gánh nặng cho framework và kiểm thử.
Mô hình của bạn quyết định mã chủ yếu là:
Điều đó, đến lượt nó, ảnh hưởng đến nhu cầu ngôn ngữ và framework: kiểu mạnh giúp ngăn trôi dần các trường JSON, trong khi tooling migration chín muồi quan trọng hơn khi schema thay đổi thường xuyên.
Chọn mô hình trước; "framework và DB đúng" thường trở nên rõ ràng sau đó.
Transaction là bảo đảm "tất cả hoặc không" mà ứng dụng của bạn thầm phụ thuộc. Khi một checkout thành công, bạn mong đơn hàng, trạng thái thanh toán và cập nhật tồn kho đều xảy ra—hoặc không xảy ra. Không có lời hứa đó, bạn gặp loại lỗi khó nhất: hiếm, tốn kém và khó tái tạo.
Một transaction gom nhiều thao tác DB vào một đơn vị công việc. Nếu có gì đó thất bại giữa chừng (lỗi validate, timeout, process crash), DB có thể rollback về trạng thái an toàn trước đó.
Điều này quan trọng không chỉ với tiền: tạo tài khoản (user row + profile row), xuất bản nội dung (post + tags + con trỏ chỉ mục tìm kiếm), hoặc bất kỳ workflow nào chạm vào nhiều bảng.
Nhất quán nghĩa là “đọc khớp với thực tế”. Tốc độ nghĩa là “trả lời nhanh”. Nhiều hệ thống đánh đổi giữa hai:
Mẫu thất bại phổ biến là chọn setup eventual-consistent rồi code như thể nó mạnh-consistent.
Framework và ORM không tự tạo transaction chỉ vì bạn gọi nhiều phương thức “save”. Một số yêu cầu block transaction rõ ràng; số khác bắt transaction cho mỗi request, điều này có thể che giấu vấn đề hiệu năng.
Retries cũng phức tạp: ORM có thể retry khi deadlock hoặc lỗi tạm thời, nhưng mã của bạn phải an toàn khi chạy hai lần.
Ghi một phần xảy ra khi bạn cập nhật A rồi thất bại trước khi cập nhật B. Hành động trùng lặp xảy ra khi request được retry sau timeout—đặc biệt nếu bạn charge thẻ hoặc gửi email trước khi transaction commit.
Một quy tắc đơn giản giúp: để side effects (email, webhook) xảy ra sau commit DB, và làm các hành động idempotent bằng khóa duy nhất hoặc idempotency key.
Đây là "lớp dịch" giữa mã ứng dụng và DB. Lựa chọn ở đây thường quan trọng hơn thương hiệu DB trong công việc hàng ngày.
Một ORM (Object-Relational Mapper) cho phép bạn coi bảng như đối tượng: tạo User, cập nhật Post, và ORM tạo SQL phía sau. Nó nhanh vì chuẩn hóa tác vụ phổ biến và che đi plumbing lặp.
Một query builder rõ ràng hơn: bạn xây một truy vấn giống SQL bằng code (chaining hoặc hàm). Bạn vẫn nghĩ theo "join, filter, group", nhưng có an toàn tham số và tính compose.
Raw SQL là viết SQL thật. Thẳng nhất và thường rõ ràng cho truy vấn báo cáo phức tạp—đổi lại là nhiều việc thủ công và quy ước hơn.
Ngôn ngữ có kiểu mạnh (TypeScript, Kotlin, Rust) thường thúc đẩy bạn dùng công cụ validate truy vấn và kết quả sớm. Điều đó giảm bất ngờ runtime, nhưng cũng đẩy đội về việc tập trung truy cập dữ liệu để kiểu không bị trôi.
Ngôn ngữ có metaprogramming linh hoạt (Ruby, Python) thường làm ORM trở nên tự nhiên và nhanh để lặp—cho tới khi truy vấn ẩn hoặc hành vi ngầm trở nên khó lý giải.
Migrations là script thay đổi schema theo phiên bản: thêm cột, tạo index, backfill dữ liệu. Mục tiêu là đơn giản: ai cũng có thể deploy app và có cùng cấu trúc DB. Đối xử với migrations như mã cần review, test và rollback khi cần.
ORM có thể âm thầm tạo N+1 queries, lấy hàng to bạn không cần, hoặc làm join khó xử. Query builder có thể trở nên chuỗi khó đọc. Raw SQL có thể bị sao chép và không nhất quán.
Một quy tắc tốt: dùng công cụ đơn giản giữ ý định rõ—và với đường dẫn quan trọng, kiểm tra SQL thực thi.
Mọi người thường đổ lỗi cho “cơ sở dữ liệu” khi một trang chậm. Nhưng hầu hết độ trễ người dùng nhìn thấy là tổng các chờ nhỏ trên toàn đường đi request.
Một request thường trả tiền cho:
Ngay cả khi DB trả lời trong 5 ms, một app thực hiện 20 query mỗi request, chặn I/O, và mất 30 ms để serialize một phản hồi lớn vẫn sẽ cảm thấy chậm.
Mở kết nối DB mới tốn kém và có thể làm quá tải DB khi có tải. Một connection pool tái sử dụng kết nối để request không phải trả chi phí thiết lập lặp lại.
Khó khăn: kích thước pool "đúng" phụ thuộc mô hình runtime. Một server async có concurrency cao có thể tạo nhu cầu đồng thời lớn; nếu không giới hạn pool, bạn sẽ thấy queueing, timeout và lỗi ồn. Nếu pool quá chặt, app trở thành nút thắt.
Cache có thể nằm trên trình duyệt, CDN, cache trong tiến trình, hoặc cache chia sẻ (như Redis). Nó hữu ích khi nhiều request cần kết quả giống nhau.
Nhưng cache không cứu được:
Runtime ngôn ngữ định hình throughput. Mô hình thread-per-request có thể lãng phí tài nguyên trong lúc chờ I/O; mô hình async tăng concurrency nhưng cũng khiến backpressure (như giới hạn pool) trở nên thiết yếu. Đó là lý do tuning hiệu năng là quyết định toàn stack, không chỉ của DB.
Bảo mật không phải là thứ bạn “thêm” bằng plugin framework hay cấu hình DB. Nó là điều thỏa thuận giữa runtime/ngôn ngữ, framework web và DB về những gì phải luôn đúng—ngay cả khi một developer mắc lỗi hoặc thêm endpoint mới.
Authentication (ai là người dùng?) thường ở rìa framework: session, JWT, OAuth, middleware. Authorization (họ được làm gì?) phải được thực thi nhất quán cả trong logic app và quy tắc dữ liệu.
Một mẫu phổ biến: app quyết định intent ("user có thể chỉnh sửa project này"), và DB thực thi ranh giới (tenant ID, ràng buộc ownership, và nơi phù hợp—chính sách hàng mức hàng). Nếu authorization chỉ ở controller, job nền và script nội bộ có thể vô tình bypass nó.
Validation ở framework cho phản hồi nhanh và thông điệp dễ hiểu. Ràng buộc DB là tấm lưới an toàn cuối cùng.
Dùng cả hai khi quan trọng:
Điều này giảm các “trạng thái không thể” xuất hiện khi hai request chạy song song hoặc dịch vụ mới ghi dữ liệu khác.
Secrets nên được runtime và quy trình deploy quản lý (env vars, secret manager), không hardcode trong mã hay migrations. Mã hoá có thể xảy ra ở app (mã hóa trường) và/hoặc ở DB (mã hoá at-rest, KMS quản lý), nhưng bạn cần rõ ai quay khóa và cách phục hồi.
Auditing cũng là trách nhiệm chung: app phát ra sự kiện có ý nghĩa; DB lưu log bất biến khi cần (ví dụ bảng audit append-only, truy cập hạn chế).
Quá tin vào logic app là lỗi kinh điển: thiếu ràng buộc, null im lặng, cờ “admin” lưu mà không kiểm tra. Sửa đơn giản: giả sử sẽ có lỗi, và thiết kế stack sao cho DB có thể từ chối ghi không an toàn—kể cả từ chính mã của bạn.
Scale hiếm khi thất bại vì “DB không chịu được”. Nó thất bại vì toàn stack phản ứng tệ khi tải thay đổi hình dạng: một endpoint nổi tiếng, một query trở nên hot, một workflow bắt đầu retry.
Hầu hết đội gặp các nút thắt ban đầu giống nhau:
Khả năng phản ứng nhanh phụ thuộc vào việc framework và công cụ DB phơi bày plan truy vấn, migrations, connection pooling, và mẫu cache an toàn.
Các bước scale phổ biến thường đến theo thứ tự:
Một stack có thể scale cần hỗ trợ job nền, lên lịch và retry an toàn như tính năng chính.
Nếu hệ thống job của bạn không đảm bảo idempotency (cùng job chạy hai lần mà không bị trừ tiền hay gửi gấp đôi), bạn sẽ "scale" vào hư hại dữ liệu. Các lựa chọn sớm—như dựa vào transaction ngầm, ràng buộc duy nhất yếu, hoặc hành vi ORM mơ hồ—có thể chặn việc đưa ra các pattern outbox, exactly-once-ish hay migration incremental sau này.
Đầu tư sớm có lợi: chọn DB phù hợp nhu cầu nhất quán, và một ecosystem framework khiến bước scale tiếp theo (replica, queue, partition) là đường được hỗ trợ chứ không phải rewrite.
Một stack cảm thấy “dễ” khi dev và ops chia sẻ cùng giả định: cách khởi app, cách dữ liệu thay đổi, cách test chạy và cách biết chuyện gì xảy ra khi có sự cố. Nếu những mảnh đó không khớp, đội lãng phí thời gian vào glue code, script dễ vỡ và runbook thủ công.
Thiết lập local nhanh là một tính năng. Ưu tiên workflow nơi người mới có thể clone, cài, chạy migrations và có dữ liệu test thực tế trong vài phút—không phải vài giờ.
Điều đó thường có nghĩa:
Nếu tooling migration của framework chống lại lựa chọn DB, mỗi thay đổi schema trở thành một dự án nhỏ.
Stack của bạn nên khiến bạn dễ viết:
Một lỗi thường thấy: đội dựa nhiều vào unit tests vì integration tests chậm hoặc khó thiết lập. Đó thường là mismatch giữa stack và ops—provision DB test, migrations và fixtures không được hợp lý.
Khi latency tăng, bạn cần theo dõi một request qua framework vào DB.
Tìm kiếm log có cấu trúc nhất quán, metrics cơ bản (tỷ lệ request, lỗi, thời gian DB) và trace bao gồm thời gian query. Ngay cả một correlation ID xuất hiện trong log app và log DB cũng biến “đoán” thành “tìm thấy”.
Ops không tách rời dev; đó là sự tiếp nối. Chọn tooling hỗ trợ:
Nếu bạn không thể diễn tập restore hay migration cục bộ, bạn sẽ làm tệ dưới áp lực.
Chọn stack không phải về công cụ “tốt nhất” mà là chọn công cụ hợp lại với những ràng buộc thực tế. Dùng checklist này để buộc sự đồng nhất sớm.
Giới hạn thời gian 2–5 ngày. Xây một lát đứng mỏng: một workflow cốt lõi, một job nền, một truy vấn dạng báo cáo và xác thực cơ bản. Đo ma sát developer, ergonomics migration, độ rõ truy vấn và độ dễ test.
Nếu muốn tăng tốc, một công cụ vibe-coding như Koder.ai có thể hữu ích để nhanh chóng tạo lát đứng hoạt động (UI, API và DB) từ spec chat-driven—sau đó bạn có thể lặp với snapshot/rollback và xuất mã nguồn khi sẵn sàng cam kết.
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks \u0026 mitigations:
When we’ll revisit:
Ngay cả các đội mạnh cũng rơi vào mismatch—lựa chọn có vẻ tốt khi nhìn độc lập nhưng gây ma sát khi hệ thống được xây. Tin tốt: hầu hết có thể dự đoán và tránh bằng vài kiểm tra.
Một mùi hôi cổ điển là chọn DB hoặc framework vì nó đang thịnh hành trong khi mô hình dữ liệu thực vẫn mơ hồ. Một mùi khác là scale sớm: tối ưu cho hàng triệu người trước khi bạn xử lý tốt hàng trăm, dẫn đến hạ tầng thừa và nhiều chế độ lỗi hơn.
Cũng cảnh giác với các stack mà đội không giải thích được tại sao mỗi phần chính tồn tại. Nếu câu trả lời hầu hết là “mọi người đều dùng”, bạn đã tích tụ rủi ro.
Nhiều vấn đề xuất hiện ở mối nối:
Đây không phải là “vấn đề DB” hay “vấn đề framework”—đó là vấn đề hệ thống.
Ưu tiên ít phần chuyển động hơn và một con đường rõ cho các tác vụ thông thường: một cách migration, một style truy vấn cho hầu hết tính năng, và convention nhất quán giữa dịch vụ. Nếu framework khuyến khích một pattern (lifecycle request, dependency injection, job pipeline), dựa vào nó thay vì trộn lẫn phong cách.
Xem lại khi bạn thấy sự cố production lặp lại, friction developer dai dẳng, hoặc yêu cầu sản phẩm mới thay đổi căn bản mẫu truy cập dữ liệu.
Thay đổi an toàn bằng cách cô lập mối nối: thêm adapter, migrate từng bước (dual-write hoặc backfill khi cần), và chứng minh parity bằng test tự động trước khi chuyển traffic.
Chọn ngôn ngữ, framework web và cơ sở dữ liệu không phải là ba quyết định độc lập—đó là một quyết định thiết kế hệ thống được thể hiện ở ba nơi. "Tốt nhất" là tổ hợp phù hợp với hình dạng dữ liệu, nhu cầu nhất quán, quy trình làm việc đội và cách bạn muốn sản phẩm phát triển.
Viết ra lý do đằng sau lựa chọn: mô hình traffic dự kiến, latency chấp nhận được, quy định giữ dữ liệu, chế độ lỗi chấp nhận được và điều bạn rõ ràng không tối ưu ngay bây giờ. Điều này làm cho các đánh đổi hiển thị, giúp đồng đội tương lai hiểu “tại sao”, và ngăn drift kiến trúc vô ý khi yêu cầu thay đổi.
Chạy thiết lập hiện tại qua checklist ở phần trước và ghi chú nơi các quyết định không khớp (ví dụ, schema chống lại ORM, hoặc framework làm job nền lúng túng).
Nếu bạn đang khám phá hướng mới, các công cụ như Koder.ai cũng có thể giúp so sánh giả định stack nhanh bằng cách tạo một app nền (thường React web, Go service với PostgreSQL, và Flutter mobile) mà bạn có thể kiểm tra, xuất và phát triển—mà không phải commit vào chu trình build dài hạn.
Duyệt các hướng dẫn liên quan trên /blog, tra cứu chi tiết triển khai trong /docs, hoặc so sánh hỗ trợ và tùy chọn triển khai trên /pricing.
Hãy coi chúng như một pipeline đơn cho mọi yêu cầu: framework → mã (ngôn ngữ) → cơ sở dữ liệu → phản hồi. Nếu một phần khuyến khích những mô hình mà phần khác chống lại (ví dụ: lưu trữ không có schema + phân tích nặng), bạn sẽ mất thời gian viết mã nối, nhân bản quy tắc và gặp những vấn đề nhất quán khó gỡ lỗi.
Bắt đầu với mô hình dữ liệu cốt lõi và các thao tác bạn sẽ thực hiện thường xuyên nhất:
Khi mô hình rõ, các tính năng tự nhiên của cơ sở dữ liệu và framework bạn cần thường trở nên hiển nhiên.
Khi cơ sở dữ liệu áp đặt schema mạnh, nhiều quy tắc có thể sống gần dữ liệu:
NOT NULL, tính duy nhấtCHECK constraints cho phạm vi/trạng thái hợp lệVới cấu trúc linh hoạt hơn, nhiều quy tắc chuyển lên mã ứng dụng (validate, payload có version, backfill). Điều này giúp lặp nhanh ban đầu nhưng tăng gánh nặng kiểm thử và khả năng bị lệch giữa các dịch vụ.
Dùng transaction bất cứ khi nào nhiều thao tác ghi phải cùng thành công hoặc cùng thất bại (ví dụ: đơn hàng + trạng thái thanh toán + cập nhật tồn kho). Nếu không có transaction, bạn có nguy cơ:
Ngoài ra, đặt các side effect (email/webhook) sau khi commit và làm các thao tác idempotent (an toàn khi chạy lại).
Chọn công cụ đơn giản nhất mà vẫn giữ ý định rõ ràng:
Với các endpoint quan trọng, luôn kiểm tra SQL thực thi.
Giữ schema và mã đồng bộ bằng cách coi migrations như mã sản xuất:
Nếu migrations thủ công hoặc lỗi, môi trường sẽ bị lệch và deploy trở nên rủi ro.
Hãy đo toàn bộ đường đi của một request, không chỉ DB:
Một cơ sở dữ liệu trả lời trong 5 ms sẽ không cứu được nếu ứng dụng thực hiện 20 query hay chặn I/O.
Dùng connection pool để tránh chi phí thiết lập kết nối trên mỗi request và để bảo vệ DB khi tải tăng.
Hướng dẫn thực tế:
Pool kích thước sai thường xuất hiện dưới dạng timeout và lỗi ồn ào khi lưu lượng đột biến.
Dùng cả hai lớp:
NOT NULL, CHECK)Điều này ngăn các "trạng thái không thể xảy ra" khi hai request race, job nền ghi dữ liệu, hoặc endpoint mới quên kiểm tra.
Giới hạn thời gian 2–5 ngày để làm một proof of concept mỏng bao phủ các mối nối thật:
Rồi viết một decision record một trang để tương lai mọi thay đổi có chủ ý (xem hướng dẫn liên quan trong /docs và /blog).