07 thg 8, 2025·8 phút
Noam Shazeer và kiến trúc Transformer đứng sau các LLM
Tìm hiểu cách Noam Shazeer góp phần hình thành Transformer: self-attention, multi-head attention và lý do thiết kế này trở thành xương sống của các LLM hiện đại.
Tìm hiểu cách Noam Shazeer góp phần hình thành Transformer: self-attention, multi-head attention và lý do thiết kế này trở thành xương sống của các LLM hiện đại.
Transformer là một cách giúp máy tính hiểu các chuỗi — những thứ mà thứ tự và bối cảnh quan trọng, như câu, mã nguồn, hay chuỗi truy vấn tìm kiếm. Thay vì đọc từng token một và mang theo một bộ nhớ mỏng manh, Transformer nhìn toàn bộ chuỗi và quyết định cần chú ý đến gì khi diễn giải từng phần.
Sự chuyển hướng đơn giản này lại rất quan trọng. Đó là lý do chính khiến các mô hình ngôn ngữ lớn (LLMs) hiện đại có thể giữ ngữ cảnh, theo sát hướng dẫn, viết đoạn văn mạch lạc và sinh mã tham chiếu các hàm và biến đã xuất hiện trước đó.
Nếu bạn đã dùng chatbot, tính năng “tóm tắt”, tìm kiếm ngữ nghĩa, hoặc trợ lý lập trình, bạn đã tương tác với hệ thống dựa trên Transformer. Cùng một kiến trúc nền hỗ trợ:
Chúng ta sẽ bóc tách các phần chính — self-attention, multi-head attention, positional encoding, và khối Transformer cơ bản — và giải thích vì sao thiết kế này mở rộng tốt khi mô hình lớn lên.
Chúng ta cũng sẽ điểm qua các biến thể hiện đại giữ ý chính nhưng tinh chỉnh để tăng tốc, giảm chi phí, hoặc mở rộng cửa sổ ngữ cảnh.
Đây là một chuyến tham quan ở mức độ cao, giải thích bằng ngôn ngữ đơn giản và hầu như không có toán. Mục tiêu là xây dựng trực giác: các phần làm gì, vì sao chúng kết hợp tốt, và điều đó chuyển thành năng lực sản phẩm ra sao.
Noam Shazeer là nhà nghiên cứu và kỹ sư AI được biết đến nhiều nhất như một trong những đồng tác giả của bài báo 2017 “Attention Is All You Need.” Bài báo đó giới thiệu kiến trúc Transformer, sau này trở thành nền tảng cho nhiều LLM hiện đại. Công lao của Shazeer nằm trong nỗ lực nhóm: Transformer được tạo ra bởi một nhóm các nhà nghiên cứu tại Google, và nên ghi nhận như vậy.
Trước Transformer, nhiều hệ thống NLP dựa vào mô hình tuần tự xử lý từng bước. Đề xuất Transformer cho thấy bạn có thể mô hình hóa chuỗi hiệu quả mà không cần tính tuần tự bằng cách dùng attention làm cơ chế chính để kết hợp thông tin xuyên câu.
Sự thay đổi này quan trọng vì nó giúp huấn luyện dễ song song hóa hơn (bạn có thể xử lý nhiều token cùng lúc), và mở đường cho việc tăng quy mô mô hình và dữ liệu theo cách trở nên thực tế cho sản phẩm.
Đóng góp của Shazeer — cùng các tác giả khác — không chỉ dừng ở các benchmark học thuật. Transformer trở thành một module có thể tái sử dụng mà các đội có thể điều chỉnh: hoán đổi thành phần, thay đổi kích thước, điều chỉnh cho nhiệm vụ, và sau đó tiền huấn luyện ở quy mô lớn.
Đây là cách nhiều đột phá lan tỏa: một bài báo giới thiệu một công thức tổng quát; kỹ sư tinh chỉnh; công ty triển khai; và cuối cùng nó trở thành lựa chọn mặc định để xây dựng tính năng ngôn ngữ.
Nói Shazeer là người đóng góp trọng yếu và đồng tác giả bài Transformer là chính xác. Nói ông là người phát minh duy nhất thì không. Tác động đến từ thiết kế tập thể — và từ nhiều cải tiến tiếp theo cộng đồng đã xây dựng trên nền tảng ban đầu đó.
Trước Transformers, các bài toán tuần tự (dịch, phát âm, sinh văn bản) chủ yếu dựa vào Recurrent Neural Networks (RNNs) và sau đó là LSTMs. Ý tưởng lớn đơn giản: đọc văn bản một token tại một thời điểm, giữ một “bộ nhớ” chạy (hidden state), và dùng trạng thái đó để dự đoán tiếp theo.
RNN xử lý câu như một chuỗi. Mỗi bước cập nhật trạng thái ẩn dựa trên từ hiện tại và trạng thái ẩn trước đó. LSTMs cải thiện điều này bằng các cổng quyết định giữ lại, quên, hoặc xuất ra — giúp giữ tín hiệu hữu ích lâu hơn.
Trong thực tế, bộ nhớ tuần tự có nút thắt: nhiều thông tin phải được nén qua một trạng thái duy nhất khi câu dài hơn. Ngay cả với LSTMs, tín hiệu từ những từ cách xa có thể phai mờ hoặc bị ghi đè.
Điều này làm cho một số mối quan hệ khó học đáng tin cậy — như liên kết đại từ với danh từ đúng nhiều từ trước, hoặc theo dõi một chủ đề qua nhiều mệnh đề.
RNNs và LSTMs cũng chậm để huấn luyện vì chúng không thể song song hoàn toàn theo thời gian. Bạn có thể gom batch nhiều câu, nhưng trong một câu, bước 50 phụ thuộc bước 49, bước 49 phụ thuộc bước 48, v.v.
Tính toán tuần tự này là giới hạn nghiêm trọng khi muốn mô hình lớn hơn, nhiều dữ liệu hơn và thử nghiệm nhanh.
Các nhà nghiên cứu cần một thiết kế có thể liên hệ các từ với nhau không cần đi nghiêm ngặt trái→phải khi huấn luyện — một cách mô hình hóa mối quan hệ khoảng cách dài trực tiếp và tận dụng tốt phần cứng hiện đại. Áp lực này dọn đường cho cách tiếp cận lấy attention làm trung tâm được giới thiệu trong Attention Is All You Need.
Attention là cách mô hình hỏi: “Những từ khác nào tôi nên nhìn ngay bây giờ để hiểu từ này?” Thay vì đọc tuần tự và hy vọng bộ nhớ đủ, attention cho phép mô hình xem những phần liên quan của câu khi cần.
Một mô hình tinh tế là một công cụ tìm kiếm nhỏ chạy bên trong câu.
Mô hình tạo query cho vị trí hiện tại, so sánh với keys của mọi vị trí, rồi truy xuất một hỗn hợp các values.
Các phép so sánh tạo ra điểm liên quan: tín hiệu “liên quan như thế nào”. Mô hình chuyển chúng thành trọng số attention, là các tỷ lệ cộng lại bằng 1.
Nếu một từ rất liên quan, nó chiếm phần lớn sự chú ý. Nếu nhiều từ đều quan trọng, attention có thể phân bổ trọng số cho nhiều mục.
Câu: “Maria told Jenna that she would call later.”
Để hiểu she, mô hình nên nhìn lại các ứng viên như “Maria” và “Jenna.” Attention gán trọng số cao hơn cho tên phù hợp với ngữ cảnh.
Hoặc: “The keys to the cabinet are missing.” Attention giúp liên kết “are” với “keys” (chủ ngữ thực sự), không phải “cabinet” mặc dù “cabinet” gần hơn. Lợi ích cốt lõi: attention liên kết nghĩa qua khoảng cách khi cần.
Self-attention là ý tưởng mỗi token trong chuỗi có thể nhìn các token khác trong cùng chuỗi để quyết định điều gì quan trọng ngay lúc đó. Thay vì xử lý từ trái→phải, Transformer cho phép mọi token tổng hợp manh mối từ bất cứ đâu trong đầu vào.
Ví dụ: “I poured the water into the cup because it was empty.” Từ “it” nên liên kết với “cup”, không phải “water.” Với self-attention, token “it” gán trọng số cao cho các token giúp giải nghĩa (“cup”, “empty”) và thấp cho những token không liên quan.
Sau self-attention, mỗi token không còn chỉ là chính nó nữa. Nó trở thành phiên bản có ngữ cảnh — một hỗn hợp có trọng số của thông tin từ các token khác. Bạn có thể tưởng tượng mỗi token tạo ra một bản tóm tắt cá nhân hoá của toàn bộ câu, tinh chỉnh cho nhu cầu của token đó.
Điều này có nghĩa biểu diễn cho “cup” có thể mang tín hiệu từ “poured”, “water”, và “empty”, trong khi “empty” có thể kéo vào những gì nó mô tả.
Bởi vì mỗi token có thể tính attention trên toàn chuỗi cùng lúc, huấn luyện không phải chờ các token trước xử lý tuần tự. Xử lý song song này là lý do lớn khiến Transformer huấn luyện hiệu quả trên tập dữ liệu lớn và có thể mở rộng thành mô hình khổng lồ.
Self-attention giúp kết nối trực tiếp các phần văn bản xa nhau. Một token có thể tập trung ngay vào một từ liên quan ở xa — không cần truyền thông tin qua chuỗi dài các bước trung gian.
Con đường trực tiếp này hữu ích cho các tác vụ như đồng tham chiếu, theo dõi chủ đề qua nhiều đoạn, và xử lý hướng dẫn phụ thuộc chi tiết đã đề cập trước đó.
Một attention đơn lẻ rất mạnh, nhưng vẫn giống như cố gắng hiểu một cuộc hội thoại chỉ bằng một góc camera. Câu thường chứa nhiều quan hệ cùng lúc: ai làm gì, “it” tham chiếu ai, từ nào tạo giọng điệu, chủ đề chung là gì.
Khi bạn đọc “The trophy didn’t fit in the suitcase because it was too small,” bạn có thể cần theo dõi nhiều manh mối cùng lúc (ngữ pháp, nghĩa và ngữ cảnh thực tế). Một head có thể khóa vào danh từ gần nhất; head khác có thể dùng động từ để quyết định “it” là gì.
Multi-head attention chạy nhiều phép tính attention song song. Mỗi “head” có xu hướng nhìn câu qua một lăng kính khác nhau — thường mô tả là các không gian con khác nhau. Trong thực tế, các head có thể chuyên về các mẫu khác nhau như:
Sau khi mỗi head tạo ra tập quan sát riêng, mô hình không chọn chỉ một. Nó nối (concatenate) đầu ra của các head rồi chiếu (project) chúng trở lại không gian làm việc chính với một lớp tuyến tính học được.
Hãy nghĩ như gom nhiều ghi chú nhỏ thành một bản tóm tắt sạch mà lớp tiếp theo có thể dùng. Kết quả là một biểu diễn có thể bắt nhiều quan hệ cùng lúc — một lý do khiến Transformers hoạt động tốt khi mở rộng.
Self-attention rất giỏi phát hiện mối quan hệ — nhưng bản thân nó không biết ai đứng trước ai. Nếu bạn xáo trộn từ trong câu, một lớp self-attention trống có thể coi phiên bản xáo trộn là tương đương, vì nó so sánh token mà không có cảm nhận vị trí sẵn có.
Positional encoding giải quyết vấn đề này bằng cách tiêm thông tin “tôi ở vị trí nào trong chuỗi?” vào biểu diễn token. Khi có vị trí, attention có thể học các mẫu như “từ ngay sau not thường rất quan trọng” hoặc “chủ ngữ thường xuất hiện trước động từ” mà không phải suy ra thứ tự từ đầu.
Ý tưởng cốt lõi: mỗi embedding token được kết hợp với một tín hiệu vị trí trước khi vào khối Transformer. Tín hiệu vị trí này giống như một tập đặc trưng phụ gắn thẻ token là thứ 1, thứ 2, thứ 3… trong input.
Một số cách phổ biến:
Lựa chọn vị trí có thể ảnh hưởng rõ tới mô hình hóa ngữ cảnh dài — như tóm tắt báo cáo dài, theo dõi thực thể qua nhiều đoạn, hoặc truy xuất chi tiết nhắc đến cách đây hàng ngàn token.
Với input dài, mô hình không chỉ học ngôn ngữ; nó học nơi nên nhìn. Các phương pháp tương đối và rotary thường giúp so sánh token xa nhau dễ hơn và giữ mẫu khi ngữ cảnh tăng, trong khi một số cách tuyệt đối có thể suy giảm nhanh hơn khi vượt quá cửa sổ huấn luyện.
Trong thực tế, positional encoding là một quyết định thiết kế âm thầm nhưng có thể quyết định liệu một LLM có sắc nét ở 2.000 token — và vẫn mạch lạc ở 100.000 hay không.
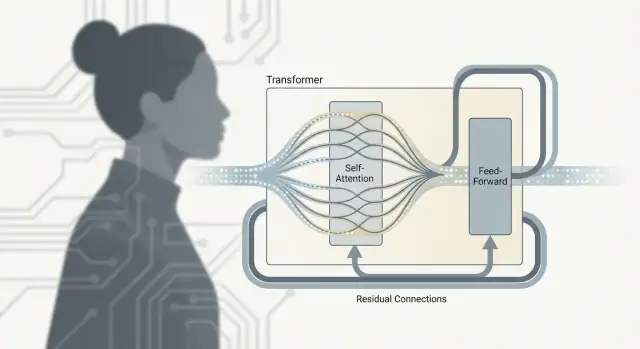
Transformer không chỉ là “attention.” Công việc thực diễn ra trong một đơn vị lặp lại — thường gọi là Transformer block — nơi thông tin được trộn giữa các token rồi tinh chỉnh. Xếp nhiều khối như vậy tạo ra chiều sâu giúp LLM có năng lực.
Self-attention là bước giao tiếp: mỗi token thu thập ngữ cảnh từ các token khác.
Mạng hồi tiếp (feed-forward network, FFN), hay gọi là MLP, là bước suy nghĩ: nó nhận biểu diễn đã cập nhật của mỗi token và chạy cùng một mạng nhỏ độc lập cho từng token.
Nói đơn giản, FFN biến đổi và tạo hình lại những gì mỗi token biết, giúp mô hình xây dựng các đặc trưng giàu hơn (cú pháp, sự thật, phong cách) sau khi thu thập ngữ cảnh liên quan.
Sự xen kẽ quan trọng vì hai phần làm nhiệm vụ khác nhau:
Lặp lại mẫu này cho phép mô hình dần xây nghĩa cao hơn: giao tiếp, tính toán, giao tiếp lại, tính toán lại.
Mỗi lớp con (attention hoặc FFN) được bọc bởi một residual connection: đầu vào được cộng lại vào đầu ra. Điều này giúp mô hình sâu dễ huấn luyện vì gradient có thể chảy qua “làn đường bỏ qua” ngay cả khi một lớp vẫn đang học. Nó cũng cho phép lớp thực hiện các điều chỉnh nhỏ thay vì phải học lại mọi thứ từ đầu.
Layer normalization ổn định các kích hoạt để chúng không quá lớn hoặc quá nhỏ khi đi qua nhiều lớp. Hãy nghĩ nó như việc giữ âm lượng đều để các lớp sau không bị quá tải hoặc thiếu tín hiệu — giúp huấn luyện mượt và đáng tin cậy, đặc biệt ở quy mô LLM.
Transformer gốc trong Attention Is All You Need được sinh ra cho dịch máy, nơi bạn chuyển chuỗi này (Pháp) sang chuỗi kia (Anh). Công việc đó chia rõ hai vai: đọc đầu vào thật tốt và viết đầu ra trôi chảy.
Trong encoder–decoder, encoder xử lý toàn bộ input cùng lúc và tạo bộ biểu diễn giàu. Decoder sau đó sinh từng token một.
Decoder không chỉ dựa vào token quá khứ của nó; nó còn dùng cross-attention để nhìn xuống đầu ra của encoder, giúp gợi ý từ nguồn gốc.
Cấu hình này vẫn tuyệt vời khi bạn cần điều kiện hoá chặt chẽ trên một input cụ thể — dịch, tóm tắt, hoặc trả lời dựa trên đoạn văn cho trước.
Hầu hết LLM hiện là decoder-only. Chúng được huấn luyện để làm một nhiệm vụ đơn giản mà mạnh: dự đoán token tiếp theo.
Để làm việc này, chúng dùng masked self-attention (causal attention). Mỗi vị trí chỉ có thể attend tới các token trước đó, không phải tương lai, vì vậy khi sinh chúng viết trái→phải liên tục.
Điều này phổ biến vì dễ huấn luyện với khối lượng văn bản lớn, phù hợp trực tiếp cho việc sinh, và mở rộng hiệu quả với dữ liệu và tính toán.
Encoder-only (như kiểu BERT) không sinh văn bản; chúng đọc toàn bộ input hai chiều. Chúng rất tốt cho phân loại, tìm kiếm, và embeddings — mọi việc cần hiểu một đoạn văn hơn là sinh tiếp nối dài.
Transformers tỏ ra thân thiện với việc mở rộng: nếu cho chúng nhiều văn bản hơn, nhiều tính toán hơn, và mô hình lớn hơn, chúng thường cải thiện theo cách dự đoán được.
Một lý do là cấu trúc đơn giản. Transformer được xây từ các khối lặp (self-attention + FFN nhỏ + normalization), và các khối đó hoạt động giống nhau dù bạn huấn luyện trên hàng triệu từ hay hàng nghìn tỷ.
Mô hình tuần tự trước (RNN) phải xử lý từng token một, giới hạn công việc đồng thời. Transformers có thể xử lý tất cả token trong chuỗi song song khi huấn luyện.
Điều này khiến chúng phù hợp tốt với GPU/TPU và thiết lập phân tán lớn — chính xác những gì cần cho huấn luyện LLM hiện đại.
Cửa sổ ngữ cảnh là khối văn bản mô hình có thể “nhìn thấy” cùng lúc — prompt của bạn cộng thêm lịch sử hội thoại hoặc văn bản tài liệu. Cửa sổ lớn hơn cho phép mô hình nối ý tưởng qua nhiều câu hay trang, theo dõi ràng buộc, và trả lời câu hỏi phụ thuộc chi tiết trước đó.
Nhưng ngữ cảnh không miễn phí.
Self-attention so sánh các token với nhau. Khi chuỗi dài hơn, số phép so sánh tăng nhanh (xấp xỉ bình phương độ dài). Đó là lý do cửa sổ rất dài tốn nhiều bộ nhớ và tính toán, và tại sao nhiều nỗ lực hiện đại tập trung làm cho attention hiệu quả hơn.
Khi Transformers được huấn luyện ở quy mô lớn, chúng không chỉ giỏi một nhiệm vụ hẹp. Chúng thường bắt đầu thể hiện năng lực linh hoạt và tổng quát — tóm tắt, dịch, viết, lập mã, và suy luận — vì cùng bộ máy học được áp dụng trên dữ liệu lớn và đa dạng.
Thiết kế Transformer gốc vẫn là mốc tham chiếu, nhưng hầu hết LLM sản xuất hôm nay là “Transformer cộng thêm”: các chỉnh sửa nhỏ, thực dụng giữ khối lõi (attention + MLP) nhưng cải thiện tốc độ, ổn định hoặc độ dài ngữ cảnh.
Nhiều nâng cấp ít thay đổi bản chất mô hình mà tập trung giúp huấn luyện và chạy tốt hơn:
Những thay đổi này thường không làm mất đi tính “Transformer” mà tinh chỉnh nó.
Mở rộng ngữ cảnh từ vài nghìn token lên hàng chục hoặc hàng trăm nghìn thường dựa trên sparse attention (chỉ attend tới token chọn lọc) hoặc các biến thể attention hiệu quả (xấp xỉ hoặc tái cấu trúc attention để giảm tính toán).
Đổi lại là một sự đánh đổi giữa độ chính xác, bộ nhớ và độ phức tạp kỹ thuật.
MoE thêm nhiều mạng con “expert” và điều phối mỗi token chỉ đi qua một tập con trong số đó. Về khái niệm: bạn có một bộ não lớn hơn, nhưng không kích hoạt toàn bộ nó mỗi lần.
Điều này có thể giảm chi phí tính cho mỗi token so với số tham số, nhưng tăng độ phức tạp hệ thống (điều phối, cân bằng expert, phục vụ).
Khi một mô hình quảng bá biến thể Transformer mới, hãy hỏi về:
Phần lớn cải tiến là có giá trị — nhưng hiếm khi miễn phí.
Ý tưởng Transformer như self-attention và mở rộng rất thú vị — nhưng các đội sản phẩm chủ yếu cảm nhận chúng qua các đánh đổi: bao nhiêu văn bản có thể đưa vào, trả lời nhanh thế nào, và chi phí trên mỗi yêu cầu.
Độ dài ngữ cảnh: Ngữ cảnh dài hơn cho phép bao gồm nhiều tài liệu, lịch sử chat và hướng dẫn. Nó cũng tăng chi phí token và có thể làm chậm phản hồi. Nếu tính năng của bạn dựa trên “đọc 30 trang và trả lời,” hãy ưu tiên độ dài ngữ cảnh.
Độ trễ: Trải nghiệm chat mặt người dùng và copilot sống còn bởi thời gian phản hồi. Kết xuất streaming giúp, nhưng lựa chọn mô hình, vùng máy chủ và gom batch cũng quan trọng.
Chi phí: Giá thường tính theo token (input + output). Một mô hình “tốt hơn 10%” có thể tốn 2–5× chi phí. So sánh theo kiểu giá để quyết định mức chất lượng đáng để trả.
Chất lượng: Định nghĩa cho trường hợp của bạn: độ chính xác thực tế, tuân theo hướng dẫn, giọng điệu, khả năng dùng công cụ, hay mã. Đánh giá bằng ví dụ thực tế trong ngành bạn, không chỉ benchmark chung chung.
Nếu bạn chủ yếu cần tìm kiếm, loại trùng, phân cụm, gợi ý, hoặc “tìm tương tự”, embeddings (thường là mô hình kiểu encoder) thường rẻ hơn, nhanh hơn và ổn định hơn so với gọi một mô hình chat để sinh. Dùng sinh chỉ cho bước cuối (tóm tắt, giải thích, soạn thảo) sau khi đã truy xuất.
For a deeper breakdown, link your team to a technical explainer like /blog/embeddings-vs-generation.
Khi biến khả năng Transformer thành sản phẩm, phần khó thường không phải kiến trúc mà là quy trình xung quanh: lặp prompt, grounding, đánh giá và triển khai an toàn.
Một con đường thực tế là dùng nền tảng vibe-coding như Koder.ai để thử nghiệm và triển khai tính năng dùng LLM nhanh hơn: bạn mô tả web app, endpoint backend và data model trong chat, lặp trong chế độ planning, rồi xuất code hoặc deploy với hosting, custom domains và rollback qua snapshots. Điều này đặc biệt hữu ích khi thử nghiệm retrieval, embeddings hoặc vòng gọi công cụ và muốn vòng lặp ngắn mà không phải xây dựng lại khung sườn.
A Transformer là một kiến trúc mạng neural cho dữ liệu tuần tự, dùng self-attention để liên hệ mỗi token với mọi token khác trong cùng đầu vào.
Thay vì truyền thông tin từng bước (như RNNs/LSTMs), nó xây dựng ngữ cảnh bằng cách quyết định cần chú ý đến gì xuyên suốt toàn bộ chuỗi, giúp hiểu tốt mối quan hệ dài hạn và cho phép huấn luyện song song hiệu quả hơn.
RNNs và LSTMs xử lý văn bản một token tại một thời điểm, khiến việc huấn luyện khó song song hóa và tạo ra nút thắt cho phụ thuộc dài hạn.
Transformers dùng attention để kết nối trực tiếp các token xa nhau, và có thể tính nhiều tương tác token-token cùng lúc khi huấn luyện—do đó dễ mở rộng nhanh với nhiều dữ liệu và phần tính.
Attention là cơ chế để trả lời: “Những token nào khác quan trọng nhất để hiểu token này ngay bây giờ?”
Bạn có thể tưởng tượng như một tìm kiếm nhỏ trong câu:
Kết quả là một hỗn hợp có trọng số của các token liên quan, cho mỗi vị trí một biểu diễn có ngữ cảnh.
Self-attention nghĩa là các token trong một chuỗi sẽ attend đến các token khác trong cùng chuỗi đó.
Đó là công cụ chính giúp mô hình giải quyết đồng tham chiếu (ví dụ: “it” tham chiếu tới gì), quan hệ chủ-vị giữa các mệnh đề, và các phụ thuộc xuất hiện xa nhau—mà không phải truyền mọi thứ qua một “bộ nhớ” tuần tự duy nhất.
Multi-head attention chạy nhiều phép tính attention song song, và mỗi head có thể chuyên môn hoá để bắt các kiểu quan hệ khác nhau.
Thực tế, các head khác nhau thường chú ý đến các cấu trúc khác nhau (cú pháp, liên kết dài-hạn, phân giải đại từ, tín hiệu chủ đề). Sau đó mô hình kết hợp các quan sát này để đại diện nhiều cấu trúc cùng lúc.
Self-attention tự thân không chứa thông tin về thứ tự token—nếu không có tín hiệu vị trí, câu bị xáo trộn có thể trông giống nhau.
Positional encodings tiêm thông tin “tôi ở vị trí thứ mấy trong chuỗi” vào biểu diễn token, để mô hình học các quy tắc như “từ ngay sau not quan trọng” hoặc cấu trúc chủ-vị thông thường.
Các lựa chọn phổ biến gồm sinusoidal (cố định), vị trí tuyệt đối học được, và các phương pháp tương đối/rotary.
Một khối Transformer thường bao gồm:
Transformer ban đầu là encoder–decoder:
Tuy nhiên, hầu hết LLM hiện nay là , được huấn luyện để dự đoán token tiếp theo bằng , phù hợp với sinh chuỗi trái-sang-phải và dễ mở rộng trên tập văn bản lớn.
Noam Shazeer là một đồng tác giả của bài báo 2017 “Attention Is All You Need,” nơi giới thiệu Transformer.
Nên ghi nhận ông là đóng góp chính, nhưng kiến trúc này là sản phẩm của một nhóm tại Google, và ảnh hưởng lớn còn đến từ nhiều cải tiến sau đó của cộng đồng và ngành.
Với input dài, self-attention tiêu tốn vì số phép so sánh tăng xấp xỉ theo bình phương độ dài chuỗi, ảnh hưởng tới bộ nhớ và tính toán.
Các cách thực tế để xử lý gồm:
Xếp nhiều khối như vậy lại tạo chiều sâu, giúp mô hình học các đặc trưng phong phú hơn.