13 thg 11, 2025·8 phút
NoSQL ra đời để giải quyết quy mô và tính linh hoạt như thế nào
Tìm hiểu tại sao NoSQL ra đời: quy mô web, nhu cầu dữ liệu linh hoạt và giới hạn của hệ quan hệ — cùng các mô hình chính và đánh đổi.
Tìm hiểu tại sao NoSQL ra đời: quy mô web, nhu cầu dữ liệu linh hoạt và giới hạn của hệ quan hệ — cùng các mô hình chính và đánh đổi.
NoSQL xuất hiện khi nhiều nhóm gặp tình trạng không khớp giữa nhu cầu ứng dụng và những gì cơ sở dữ liệu quan hệ truyền thống (SQL) được tối ưu để làm. SQL không “thất bại” — nhưng ở quy mô web, một số nhóm bắt đầu ưu tiên những mục tiêu khác.
Đầu tiên, quy mô. Ứng dụng tiêu dùng phổ biến bắt đầu chịu các đợt tăng lưu lượng, ghi liên tục và lượng dữ liệu do người dùng tạo ra rất lớn. Với các workload này, “mua máy chủ lớn hơn” trở nên tốn kém, chậm để triển khai và cuối cùng bị giới hạn bởi chiếc máy lớn nhất bạn có thể vận hành hợp lý.
Thứ hai, thay đổi. Tính năng sản phẩm phát triển nhanh, và dữ liệu phía sau không luôn phù hợp với tập bảng cố định. Thêm thuộc tính mới cho hồ sơ người dùng, lưu nhiều loại sự kiện, hoặc ingest JSON bán cấu trúc từ nhiều nguồn thường dẫn đến các migration schema lặp đi lặp lại và cần phối hợp giữa các nhóm.
Cơ sở dữ liệu quan hệ rất tốt trong việc duy trì cấu trúc và hỗ trợ truy vấn phức tạp trên các bảng chuẩn hóa. Nhưng một số workload quy mô lớn khiến những điểm mạnh đó khó tận dụng:
Kết quả: một số nhóm tìm hệ thống đổi một vài đảm bảo để lấy việc mở rộng dễ hơn và lặp nhanh hơn.
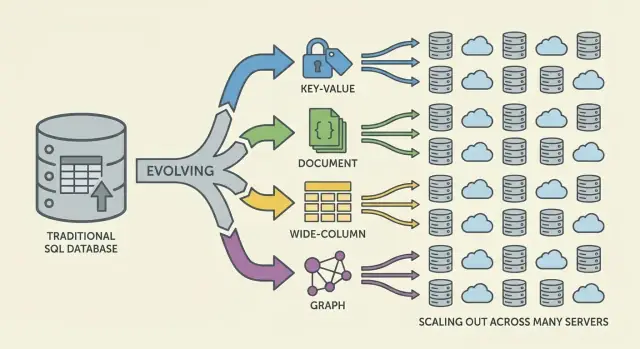
NoSQL không phải một cơ sở dữ liệu đơn lẻ. Đó là thuật ngữ bao gồm các hệ thống nhấn mạnh vào một tổ hợp:
NoSQL không bao giờ được nghĩ là thay thế toàn bộ cho SQL. Đó là một tập các đánh đổi: bạn có thể đổi lấy khả năng mở rộng hoặc linh hoạt schema, nhưng chấp nhận các đảm bảo nhất quán yếu hơn, ít tùy chọn truy vấn ad-hoc, hoặc trách nhiệm lớn hơn trong mô hình hóa dữ liệu ở phía ứng dụng.
Trong nhiều năm, câu trả lời tiêu chuẩn cho cơ sở dữ liệu chậm là: mua máy chủ lớn hơn. Thêm CPU, RAM, ổ đĩa nhanh hơn và giữ nguyên schema cùng mô hình vận hành. Cách “tăng dọc” này có hiệu quả — cho đến khi nó trở nên không thực tế.
Máy cao cấp nhanh chóng trở nên đắt đỏ, và đường cong giá/hiệu năng cuối cùng không còn hấp dẫn. Nâng cấp thường cần phê duyệt ngân sách lớn và cửa sổ bảo trì để di chuyển dữ liệu và cut over. Ngay cả khi bạn đủ khả năng mua phần cứng lớn hơn, một máy vẫn có trần: một bus bộ nhớ, một subsystem lưu trữ và một node chính chịu tải ghi.
Khi sản phẩm lớn hơn, cơ sở dữ liệu phải chịu áp lực đọc/ghi liên tục thay vì các đỉnh thỉnh thoảng. Lưu lượng trở nên 24/7 thực sự, và một vài tính năng tạo mẫu truy cập không đều. Một số hàng hoặc phân vùng truy cập nhiều có thể chi phối lưu lượng, tạo ra bảng nóng (hot tables) hoặc key nóng (hot keys) kéo mọi thứ xuống.
Các nút thắt vận hành trở nên phổ biến:
Nhiều ứng dụng cần sẵn sàng ở nhiều vùng, không chỉ nhanh ở một data center. Một cơ sở dữ liệu “chính” ở một vị trí làm tăng độ trễ cho người dùng ở xa và khiến sự cố trở nên thảm khốc hơn. Câu hỏi chuyển từ “Làm sao để mua máy to hơn?” sang “Làm sao chạy cơ sở dữ liệu trên nhiều máy và nhiều vùng?”
Cơ sở dữ liệu quan hệ mạnh khi hình dạng dữ liệu ổn định. Nhưng nhiều sản phẩm hiện đại không đứng yên. Schema bảng cố định: mỗi hàng phải tuân theo cùng tập cột, kiểu và ràng buộc. Sự dự đoán đó có giá trị — cho đến khi bạn cần lặp nhanh.
Trong thực tế, thay đổi schema thường tốn kém. Một cập nhật có vẻ nhỏ có thể yêu cầu migration, backfill, cập nhật chỉ mục, thời điểm triển khai phối hợp và lên kế hoạch tương thích để mã cũ không bị hỏng. Trên các bảng lớn, thêm cột hay đổi kiểu có thể là thao tác tốn thời gian với rủi ro vận hành thực sự.
Ma sát đó khiến các nhóm trì hoãn thay đổi, tích tụ giải pháp tạm, hoặc lưu blob bừa bãi trong trường text — không lý tưởng cho việc lặp nhanh.
Nhiều dữ liệu ứng dụng là bán cấu trúc: đối tượng lồng nhau, trường tuỳ chọn và thuộc tính thay đổi theo thời gian.
Ví dụ, một “hồ sơ người dùng” có thể bắt đầu với tên và email, sau đó mở rộng với preference, tài khoản liên kết, địa chỉ giao hàng, cài đặt thông báo và cờ thử nghiệm. Không phải người dùng nào cũng có mọi trường, và trường mới đến dần dần. Mô hình dạng document có thể lưu cấu trúc lồng và không đồng đều trực tiếp mà không ép mọi bản ghi vào cùng khuôn.
Tính linh hoạt cũng giảm nhu cầu join phức tạp cho một số hình dạng dữ liệu. Khi một màn hình cần một đối tượng ghép sẵn (một đơn hàng với mục, thông tin vận chuyển và lịch sử trạng thái), thiết kế quan hệ có thể yêu cầu nhiều bảng và join — cùng với các lớp ORM cố gắng che giấu độ phức tạp nhưng thường gây ma sát.
Các lựa chọn NoSQL giúp mô hình hóa dữ liệu gần hơn với cách ứng dụng đọc và ghi, giúp các nhóm ra tính năng nhanh hơn.
Ứng dụng web không chỉ lớn hơn — chúng thay đổi hình dạng. Thay vì phục vụ số người dùng nội bộ dự đoán được trong giờ hành chính, sản phẩm bắt đầu phục vụ hàng triệu người dùng toàn cầu suốt ngày đêm, với các đột biến do ra mắt, tin tức hoặc chia sẻ xã hội.
Kỳ vọng luôn bật nâng tiêu chuẩn: downtime trở thành chuyện lớn. Đồng thời, nhóm phải phát hành tính năng nhanh hơn — thường trước khi ai đó biết mô hình dữ liệu “cuối cùng” sẽ ra sao.
Để theo kịp, chỉ tăng dọc một máy chủ không đủ. Càng xử lý nhiều lưu lượng, bạn càng cần khả năng thêm phần công suất theo từng bước — thêm node, phân tán tải, cô lập lỗi.
Điều này đẩy kiến trúc hướng tới đội máy thay vì một chiếc “hộp chính”, và thay đổi điều các nhóm mong đợi từ cơ sở dữ liệu: không chỉ đúng, mà còn hiệu năng dự đoán được dưới độ đồng thời cao và hành vi mềm dẻo khi một phần hệ thống không khỏe.
Trước khi “NoSQL” thành xu hướng, nhiều nhóm đã uốn nắn hệ thống về phía thực tế web-scale:
Những kỹ thuật này hiệu quả, nhưng dồn độ phức tạp vào mã ứng dụng: invalidation cache, giữ dữ liệu trùng khớp, và xây pipeline cho các bản ghi “sẵn sàng phục vụ”.
Khi các pattern này trở nên chuẩn, cơ sở dữ liệu phải hỗ trợ phân phối dữ liệu trên nhiều máy, chịu đựng lỗi từng phần, xử lý khối lượng ghi lớn và biểu diễn dữ liệu tiến hóa một cách rõ ràng. NoSQL xuất hiện một phần để biến các chiến lược web-scale phổ biến thành tính năng chính thay vì làm thủ công liên tục.
Khi dữ liệu nằm trên một máy, quy tắc có vẻ đơn giản: có một nguồn chân lý duy nhất và mọi đọc/ghi có thể kiểm tra ngay lập tức. Khi bạn trải dữ liệu trên nhiều server (thường ở nhiều vùng), hiện thực mới xuất hiện: thông điệp có thể bị trễ, node có thể thất bại, và các phần hệ thống tạm thời ngừng giao tiếp.
Một cơ sở dữ liệu phân tán phải quyết định làm gì khi không thể phối hợp an toàn. Nó nên tiếp tục phục vụ để ứng dụng “vẫn hoạt động”, ngay cả khi kết quả có thể hơi lỗi thời? Hay nên từ chối một số thao tác cho đến khi có thể xác nhận các bản sao đồng ý, điều này có thể trông giống downtime với người dùng?
Những tình huống này xảy ra khi router lỗi, mạng quá tải, rollout dần, cấu hình firewall sai và trễ khi replication giữa vùng.
Định lý CAP là cách tóm tắt ba thuộc tính bạn muốn cùng lúc:
Điểm mấu chốt không phải là “chọn hai mãi mãi”. Mà là: khi partition xảy ra, bạn phải chọn giữa consistency và availability. Ở hệ thống web-scale, partition được coi là không tránh khỏi — đặc biệt với triển khai đa vùng.
Giả sử app chạy ở hai vùng để tăng độ bền. Một sự cố cáp quang hoặc lỗi định tuyến ngăn đồng bộ.
Các hệ thống NoSQL khác nhau (và cấu hình khác nhau của cùng một hệ thống) chọn các đánh đổi khác nhau tùy theo điều gì quan trọng nhất: trải nghiệm người dùng khi lỗi, đảm bảo đúng, đơn giản vận hành hay hành vi phục hồi.
Scale out (mở rộng ngang) nghĩa là tăng công suất bằng cách thêm nhiều máy thay vì mua máy lớn hơn. Với nhiều nhóm, đây là thay đổi chi phí và vận hành: node giá rẻ có thể thêm dần, lỗi được chấp nhận, và tăng trưởng không đòi hỏi migration “hộp lớn” rủi ro.
Để nhiều node hữu ích, NoSQL dựa vào sharding (còn gọi partitioning). Thay vì một DB xử lý mọi request, dữ liệu được chia thành phân vùng và phân phối trên các node.
Ví dụ đơn giản là phân vùng theo key (như user_id):
Đọc và ghi được dàn trải, giảm hotspot và cho phép throughput tăng khi thêm node. Khóa phân vùng là quyết định thiết kế: chọn key phù hợp với pattern truy vấn, nếu không bạn có thể dồn quá nhiều lưu lượng vào một shard.
Replication nghĩa là giữ nhiều bản sao dữ liệu trên các node khác nhau. Điều này cải thiện:
Replication cũng cho phép trải dữ liệu qua rack hoặc vùng để chịu được sự cố cục bộ.
Sharding và replication đưa vào công việc vận hành liên tục. Khi dữ liệu tăng hoặc node thay đổi, hệ thống phải cân bằng lại — di chuyển phân vùng trong khi giữ hệ thống trực tuyến. Nếu xử lý kém, việc cân bằng lại có thể gây tăng độ trễ, tải không đều hoặc thiếu hụt công suất tạm thời.
Đây là đánh đổi cốt lõi: mở rộng rẻ hơn bằng nhiều node, đổi lại là phân phối phức tạp hơn, giám sát và xử lý lỗi nhiều hơn.
Khi dữ liệu được phân phối, cơ sở dữ liệu phải định nghĩa “đúng” nghĩa là gì khi cập nhật xảy ra đồng thời, mạng chậm, hoặc node không thể giao tiếp.
Với nhất quán mạnh, khi một ghi được xác nhận, mọi reader nên thấy ngay. Điều này tương ứng với trải nghiệm “nguồn chân lý duy nhất” mà nhiều người liên hệ với cơ sở dữ liệu quan hệ.
Thách thức là phối hợp: đảm bảo nghiêm ngặt giữa các node đòi hỏi nhiều thông điệp, chờ đủ phản hồi và xử lý lỗi giữa chừng. Node càng xa nhau (hoặc càng bận), độ trễ bạn thêm vào — đôi khi ở mọi thao tác ghi.
Nhất quán cuối cùng nới lỏng đảm bảo: sau một ghi, các node có thể tạm thời trả khác nhau, nhưng hệ thống hội tụ theo thời gian.
Ví dụ:
Với nhiều trải nghiệm người dùng, sự khác biệt tạm thời chấp nhận được nếu hệ thống nhanh và sẵn sàng.
Nếu hai replica chấp nhận cập nhật gần như cùng lúc, cơ sở dữ liệu cần quy tắc hợp nhất.
Các cách phổ biến gồm:
Nhất quán mạnh thường đáng để trả giá cho các giao dịch tiền tệ, giới hạn tồn kho, tên người dùng duy nhất, quyền truy cập và mọi luồng mà “hai sự thật cùng lúc” có thể gây hại thực sự.
NoSQL là tập các mô hình đánh đổi khác nhau quanh quy mô, độ trễ và hình dạng dữ liệu. Hiểu “họ” giúp dự đoán thứ gì nhanh, thứ gì đau đầu và tại sao.
Key-value lưu một giá trị đằng sau key duy nhất, giống như hashmap phân tán khổng lồ. Vì pattern truy cập thường là “get theo key” / “set theo key”, chúng có thể rất nhanh và mở rộng ngang tốt.
Phù hợp khi bạn đã biết key tra cứu (sessions, caching, feature flags), nhưng giới hạn cho truy vấn ad-hoc: lọc theo nhiều trường không phải mục tiêu của hệ thống.
Document DB lưu tài liệu giống JSON (thường nhóm vào collection). Mỗi tài liệu có thể khác cấu trúc chút ít, hỗ trợ linh hoạt schema khi sản phẩm tiến hóa.
Chúng tối ưu cho đọc/ghi toàn bộ tài liệu và truy vấn theo trường bên trong mà không ép thành bảng cứng. Đổi lại: mô hình quan hệ có thể phức tạp, và join (nếu có) bị hạn chế so với hệ quan hệ.
Wide-column DB (lấy cảm hứng từ Bigtable) tổ chức dữ liệu theo row key, với nhiều cột có thể khác nhau cho mỗi row. Chúng mạnh ở tốc độ ghi khổng lồ và lưu trữ phân tán, phù hợp cho time-series, event và log workloads.
Thường yêu cầu thiết kế cẩn thận quanh access pattern: bạn truy vấn hiệu quả theo primary key và quy tắc clustering, không phải theo bộ lọc bất kỳ.
Graph DB coi mối quan hệ là dữ liệu quan trọng. Thay vì join nhiều lần, chúng duyệt các cạnh giữa các node, khiến truy vấn “những thứ này liên kết thế nào?” trở nên tự nhiên và nhanh (vòng gian lận, gợi ý, đồ thị phụ thuộc).
Cơ sở dữ liệu quan hệ khuyến khích chuẩn hóa: tách dữ liệu vào nhiều bảng và ghép lại bằng join khi truy vấn. Nhiều NoSQL thúc đẩy bạn thiết kế quanh access pattern quan trọng nhất — đôi khi phải đánh đổi bằng sao chép dữ liệu — để độ trễ dự đoán được trên các node.
Trong DB phân tán, một join có thể đòi lấy dữ liệu từ nhiều partition hoặc máy. Điều đó thêm vòng mạng, phối hợp và độ trễ không dự đoán được. Denormalization (lưu dữ liệu liên quan cùng nhau) giảm vòng đi lại và giữ đọc “cục bộ” càng nhiều càng tốt.
Hệ quả thực tế: bạn có thể lưu tên khách hàng trong bản orders dù nó cũng tồn tại trong customers, vì “xem 20 đơn cuối” là truy vấn cốt lõi.
Nhiều DB NoSQL hỗ trợ join hạn chế (hoặc không hỗ trợ), nên ứng dụng gánh thêm trách nhiệm:
Vì vậy mô hình NoSQL thường bắt đầu với: “Màn hình nào ta cần tải?” và “Top query nào phải nhanh?”
Chỉ mục phụ cho phép truy vấn mới ("tìm user theo email") nhưng không miễn phí. Trong hệ phân tán, mỗi ghi có thể cập nhật nhiều cấu trúc chỉ mục, dẫn đến:
user_profile_summary để phục vụ trang profile mà không phải scan post, like, followNoSQL không được áp dụng vì “tốt hơn” mọi mặt. Nó được áp dụng vì các nhóm chịu đổi một vài tiện nghi của DB quan hệ để lấy tốc độ, quy mô và linh hoạt dưới áp lực web-scale.
Mở rộng ngang theo thiết kế. Nhiều hệ NoSQL làm cho việc thêm máy trở nên thực tế thay vì nâng cấp máy đơn. Sharding và replication là tính năng cốt lõi.
Schema linh hoạt. Document và key-value cho phép ứng dụng tiến hóa mà không phải đưa mọi thay đổi trường qua định nghĩa bảng nghiêm ngặt, giảm ma sát khi yêu cầu thay đổi hàng tuần.
Mẫu sẵn có cao. Replication qua node và vùng giúp dịch vụ giữ hoạt động khi phần cứng lỗi hoặc bảo trì.
Trùng lặp dữ liệu và denormalization. Tránh join thường dẫn tới sao chép dữ liệu. Điều này cải thiện đọc nhưng tăng lưu trữ và thêm độ phức tạp khi cập nhật ở nhiều nơi.
Bất ngờ về nhất quán. Nhất quán cuối cùng có thể chấp nhận được — cho đến khi không. Người dùng có thể thấy dữ liệu cũ hoặc các trường hợp méo mó trừ khi ứng dụng thiết kế để chịu đựng hoặc giải quyết xung đột.
Phân tích khó khăn hơn (đôi khi). Một số store NoSQL tuyệt vời cho đọc/ghi vận hành nhưng khiến truy vấn ad-hoc, báo cáo hoặc tổng hợp phức tạp khó hơn hệ thống ưu tiên SQL.
Áp dụng NoSQL ban đầu thường chuyển nỗ lực từ tính năng DB sang kỷ luật engineering: giám sát replication, quản lý partition, chạy compaction, lên kế hoạch backup/restore và test tình huống lỗi. Những nhóm có maturity vận hành tốt hưởng lợi nhiều nhất.
Chọn dựa trên thực tế workload: độ trễ mong muốn, peak throughput, pattern truy vấn chiếm ưu thế, chịu được đọc cũ và yêu cầu phục hồi (RPO/RTO). Lựa chọn NoSQL “đúng” thường là công cụ phù hợp với cách ứng dụng của bạn lỗi, mở rộng và cần truy vấn — không phải cái có bảng tính ấn tượng nhất.
Chọn NoSQL không nên bắt đầu từ thương hiệu DB hay hype — mà từ việc ứng dụng bạn cần làm gì, cách nó sẽ tăng trưởng và “đúng” nghĩa là gì với người dùng.
Trước khi chọn datastore, ghi ra:
Nếu bạn không thể mô tả rõ pattern truy cập, mọi lựa chọn sẽ là đoán mò — đặc biệt với NoSQL, nơi mô hình hóa thường định hình theo cách bạn đọc và ghi.
Dùng đây như bộ lọc nhanh:
Tín hiệu thực tế: nếu “nguồn chân lý” cốt lõi (orders, payments, inventory) phải luôn chính xác, giữ nó trong SQL hoặc store có nhất quán mạnh. Nếu bạn phục vụ nội dung lưu lượng lớn, sessions, cache, feed hoặc dữ liệu do người dùng tạo linh hoạt, NoSQL có thể phù hợp.
Nhiều nhóm thành công khi dùng nhiều store: ví dụ SQL cho giao dịch, document DB cho profile/content và key-value cho session. Mục tiêu không phải phức tạp mà là gán mỗi workload cho công cụ xử lý nó tốt.
Đây cũng là nơi quy trình developer quan trọng. Nếu bạn đang thử nghiệm kiến trúc (SQL vs NoSQL vs hybrid), có thể khởi động prototype nhanh — API, data model và UI — sẽ giảm rủi ro khi quyết định. Nền tảng như Koder.ai giúp tạo app full-stack từ chat, thường với frontend React và backend Go + PostgreSQL, sau đó cho phép export source. Ngay cả khi sau này bạn thêm NoSQL cho một vài workload, có hệ SQL làm “system of record” cộng khả năng prototype nhanh, snapshot và rollback sẽ làm thí nghiệm an toàn và nhanh hơn.
Dù bạn chọn gì, chứng minh nó:
Nếu bạn không thể test những kịch bản này, quyết định cơ sở dữ liệu sẽ chỉ là lý thuyết — và production sẽ là nơi thử nghiệm thực sự.
NoSQL giải quyết hai áp lực phổ biến:
Không phải vì SQL “tệ”, mà vì những workload khác ưu tiên các đánh đổi khác nhau.
Chiến lược “tăng cấu hình” truyền thống gặp giới hạn thực tế:
NoSQL thiên về scale out — thêm node thay vì mua máy lớn hơn.
Schema quan hệ thiết kế để nghiêm ngặt, tốt cho ổn định nhưng đau đầu khi thay đổi nhanh. Trên bảng lớn, các thay đổi “đơn giản” thường yêu cầu:
Mô hình dạng tài liệu (document) giảm ma sát này bằng cách cho phép trường tùy chọn và cấu trúc tiến hóa.
Không hẳn vậy. Nhiều cơ sở dữ liệu SQL có thể scale out, nhưng thường phức tạp về vận hành (chiến lược sharding, cross-shard joins, giao dịch phân tán).
Hệ thống NoSQL thường coi phân vùng và sao chép là tính năng mấu chốt, tối ưu cho các access pattern đơn giản, dự đoán được ở quy mô lớn.
Denormalization lưu dữ liệu theo cách bạn đọc nó, thường trùng lặp một vài trường để tránh join tốn kém.
Ví dụ: lưu tên khách hàng trong bản orders để truy vấn “20 đơn gần nhất” chỉ cần một đọc nhanh.
Đổi lại, bạn phải giải quyết vấn đề cập nhật ở nhiều nơi qua logic ứng dụng hoặc pipeline.
Trong hệ phân tán, khi mạng bị phân đoạn bạn phải chọn cách xử lý:
CAP nhắc rằng khi partition xảy ra, không thể đồng thời đảm bảo cả tính nhất quán hoàn hảo và tính sẵn sàng đầy đủ.
Strong consistency tức là khi một ghi được xác nhận, mọi reader nhìn thấy ngay; thường cần phối hợp giữa các node.
Eventual consistency nghĩa là các bản sao có thể khác nhau tạm thời nhưng sẽ hội tụ theo thời gian. Thích hợp cho feed, bộ đếm, trải nghiệm có thể chịu được độ trễ ngắn của dữ liệu.
Xung đột xảy ra khi các bản sao chấp nhận cập nhật đồng thời. Các chiến lược phổ biến:
Lựa chọn phụ thuộc vào việc có chấp nhận mất cập nhật trung gian hay không.
Lời khuyên nhanh:
Chọn dựa trên access pattern chiếm ưu thế, không phải theo xu hướng chung.
Bắt đầu bằng yêu cầu và kiểm chứng bằng bài test:
Nhiều hệ thống thực tế là : SQL cho hệ thống ghi nhận chính (payments, inventory), NoSQL cho dữ liệu volume cao hoặc linh hoạt (feeds, sessions, profiles).