02 thg 9, 2025·7 phút
Protobuf vs JSON cho API: Tốc độ, Kích thước và Tương thích
So sánh Protobuf và JSON cho API: kích thước payload, tốc độ, độ đọc, tooling, versioning và khi nào mỗi định dạng phù hợp trong sản phẩm thực tế.
So sánh Protobuf và JSON cho API: kích thước payload, tốc độ, độ đọc, tooling, versioning và khi nào mỗi định dạng phù hợp trong sản phẩm thực tế.
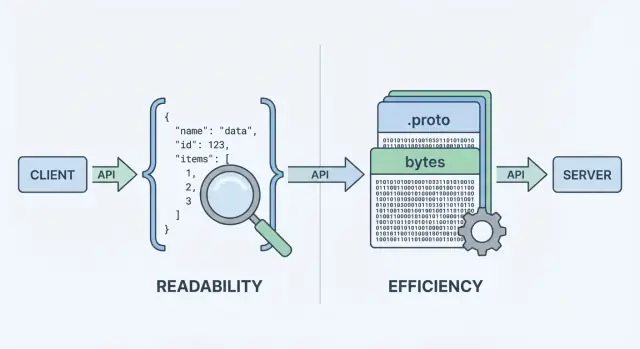
Khi API của bạn gửi hoặc nhận dữ liệu, nó cần một định dạng dữ liệu—một cách chuẩn để đại diện thông tin trong body của request và response. Định dạng đó sau đó được serialize (biến thành byte) để vận chuyển qua mạng, và deserialize trở lại thành các đối tượng có thể dùng trên client và server.
Hai lựa chọn phổ biến là JSON và Protocol Buffers (Protobuf). Chúng có thể biểu diễn cùng dữ liệu nghiệp vụ (người dùng, đơn hàng, timestamp, danh sách mục), nhưng đánh đổi khác nhau về hiệu năng, kích thước payload và luồng làm việc của lập trình viên.
JSON (JavaScript Object Notation) là định dạng dạng văn bản xây dựng từ cấu trúc đơn giản như object và array. Nó phổ biến cho REST API vì dễ đọc, dễ log và dễ kiểm tra với các công cụ như curl và DevTools của trình duyệt.
Một lý do lớn khiến JSON phổ biến: hầu hết ngôn ngữ đều hỗ trợ tốt, và bạn có thể nhìn vào response và hiểu ngay.
Protobuf là định dạng serialization nhị phân do Google phát triển. Thay vì gửi văn bản, nó gửi một biểu diễn nhị phân gọn được định nghĩa bởi schema (file .proto). Schema mô tả các trường, kiểu của chúng và tag số.
Bởi vì là nhị phân và có schema, Protobuf thường tạo payload nhỏ hơn và có thể parse nhanh hơn—điều quan trọng khi bạn có lưu lượng lớn, mạng di động, hoặc dịch vụ nhạy cảm với độ trễ (thường trong thiết lập gRPC, nhưng không chỉ giới hạn ở đó).
Cần phân tách cái gì bạn gửi và cách nó được mã hóa. Một “user” với id, name và email có thể được mô hình hóa cả trong JSON và Protobuf. Sự khác biệt nằm ở chi phí bạn phải trả về:
Không có câu trả lời phù hợp cho mọi tình huống. Với nhiều API công khai, JSON vẫn là mặc định vì dễ tiếp cận và linh hoạt. Với giao tiếp nội bộ giữa dịch vụ, hệ thống nhạy cảm hiệu năng hoặc cần hợp đồng chặt, Protobuf có thể phù hợp hơn. Mục tiêu của hướng dẫn này là giúp bạn chọn dựa trên ràng buộc—không phải ý thức hệ.
Khi API trả dữ liệu, nó không thể gửi “object” trực tiếp qua mạng. Phải biến chúng thành luồng byte trước. Việc chuyển đổi này là serialization—hãy nghĩ như đóng gói dữ liệu để vận chuyển. Phía kia, client thực hiện ngược lại (deserialization), mở gói bytes thành cấu trúc dữ liệu có thể dùng.
Luồng request/response tiêu biểu:
Bước “mã hóa” là nơi quyết định định dạng có tác động. JSON tạo ra văn bản có thể đọc như {\"id\":123,\"name\":\"Ava\"}. Protobuf tạo ra bytes nhị phân gọn, không có ý nghĩa với con người nếu thiếu tooling.
Bởi mỗi response phải được đóng gói và mở gói, định dạng ảnh hưởng tới:
Phong cách API thường ảnh hưởng đến quyết định:
curl và dễ log.Bạn có thể dùng JSON với gRPC (qua transcoding) hoặc dùng Protobuf trên HTTP thuần, nhưng ergonomics mặc định của stack—framework, gateway, thư viện client và thói quen gỡ lỗi—sẽ quyết định điều gì dễ vận hành hàng ngày hơn.
Khi so sánh protobuf vs json, mọi người thường bắt đầu với hai chỉ số: payload lớn hay nhỏ và thời gian mã hóa/giải mã. Tóm tắt: JSON là văn bản và thường verbose; Protobuf là nhị phân và thường gọn.
JSON lặp tên trường và dùng biểu diễn văn bản cho số, boolean, cấu trúc nên thường gửi nhiều byte hơn. Protobuf thay tên trường bằng tag số và đóng gói giá trị hiệu quả, thường dẫn đến payload nhỏ hơn—đặc biệt với object lớn, trường lặp và dữ liệu lồng sâu.
Tuy nhiên, nén có thể thu hẹp khoảng cách. Với gzip hoặc brotli, JSON nén tốt các khóa lặp, nên khác biệt kích thước giữa JSON và Protobuf có thể nhỏ hơn trong triển khai thực tế. Protobuf cũng có thể nén, nhưng lợi thế tương đối thường giảm.
Bộ parse JSON phải tokenize và kiểm tra văn bản, chuyển chuỗi thành số và xử lý các trường hợp đặc biệt (escaping, whitespace, unicode). Giải mã Protobuf trực tiếp hơn: đọc tag → đọc giá trị kiểu. Trong nhiều dịch vụ, Protobuf giảm CPU và tạo rác ít hơn, cải thiện độ trễ đuôi khi tải cao.
Trên mạng di động hoặc liên kết độ trễ cao, ít byte hơn thường có nghĩa truyền nhanh hơn và ít thời gian radio hơn (cũng giúp tiết kiệm pin). Nhưng nếu response đã nhỏ, overhead handshake, TLS và xử lý server có thể chiếm ưu thế—làm cho lựa chọn định dạng ít rõ rệt hơn.
Đo với payload thực:
Điều này biến tranh luận “serialize API” thành dữ liệu bạn có thể tin tưởng cho API của bạn.
Trải nghiệm dev là nơi JSON thường thắng mặc định. Bạn có thể inspect một payload JSON gần như ở mọi chỗ: DevTools, curl, Postman, reverse proxy và logs dạng văn bản. Khi có lỗi, “chúng ta thực sự gửi gì?” thường chỉ cách một copy/paste.
Protobuf khác: gọn và nghiêm ngặt, nhưng không đọc được. Nếu bạn log raw Protobuf bytes, bạn sẽ thấy base64 hoặc nhị phân không đọc được. Để hiểu payload, bạn cần .proto và bộ decode đúng (ví dụ protoc, tooling theo ngôn ngữ hoặc types sinh tự động của dịch vụ).
Với JSON, tái tạo lỗi là đơn giản: lấy payload log, che secret, replay với curl và bạn gần như có test case tối thiểu.
Với Protobuf, thường debug bằng cách:
Bước thêm này quản lý được—nhưng chỉ khi đội có workflow lặp lại.
Structured logging giúp cả hai định dạng. Log request ID, tên method, identifier user/account và các trường then chốt thay vì log toàn bộ body.
Riêng với Protobuf:
.proto nào?”.Với JSON, cân nhắc log JSON canonicalized (thứ tự khóa ổn định) để dễ diff và đọc timeline sự cố.
API không chỉ chuyển dữ liệu—mà chuyển ý nghĩa. Khác biệt lớn nhất giữa JSON và Protobuf là mức độ rõ ràng và bắt buộc của ý nghĩa đó.
JSON mặc định “không schema”: bạn có thể gửi object với bất cứ trường nào, và nhiều client sẽ chấp nhận miễn là nó trông hợp lý.
Sự linh hoạt này tiện khi bắt đầu, nhưng có thể che giấu lỗi. Những vấn đề phổ biến:
userId ở chỗ này, user_id ở chỗ khác, hoặc trường bị thiếu tùy đường đi."42", "true", "2025-12-23"—dễ tạo, dễ hiểu sai.null có thể nghĩa là “không biết”, “không được thiết lập” hoặc “rỗng chủ ý”, và client khác nhau xử lý khác nhau.Bạn có thể thêm JSON Schema hoặc OpenAPI, nhưng JSON tự nó không yêu cầu người tiêu thụ tuân thủ.
Protobuf yêu cầu schema trong file .proto. Schema là hợp đồng chung chỉ rõ:
Hợp đồng đó giúp tránh thay đổi vô ý—ví dụ biến một integer thành string—vì code sinh ra mong đợi kiểu cụ thể.
Với Protobuf, số là số, enum bị giới hạn giá trị đã biết, và timestamp thường dùng các well-known types (thay vì format chuỗi tự phát). “Không được thiết lập” cũng rõ hơn: trong proto3, vắng mặt phân biệt với giá trị mặc định khi bạn dùng trường optional hoặc wrapper types.
Nếu API của bạn phụ thuộc vào kiểu chính xác và parsing đồng nhất giữa nhiều đội/ngôn ngữ, Protobuf cung cấp rào chắn mà JSON thường đạt được bằng quy ước.
API tiến hóa: bạn thêm trường, chỉnh hành vi và loại bỏ phần cũ. Mục tiêu là thay đổi hợp đồng mà không làm người tiêu thụ bị bất ngờ.
Chiến lược tốt nhắm tới cả hai, nhưng tương thích ngược thường là rào cản tối thiểu.
Trong Protobuf, mỗi trường có một số (ví dụ email = 3). Số đó—không phải tên trường—là thứ được gửi trên dây. Tên chủ yếu dành cho con người và code sinh.
Vì vậy:
Thay đổi an toàn (thường):
Thay đổi rủi ro (thường phá vỡ):
Thực hành tốt: dùng reserved cho số/tên cũ và giữ changelog.
JSON không có schema tích hợp, nên tương thích phụ thuộc vào pattern của bạn:
Thông báo deprecation sớm: khi một trường bị deprecated, nó được hỗ trợ trong bao lâu và cái gì thay thế. Công bố chính sách versioning đơn giản (ví dụ “thay đổi bổ sung là non-breaking; việc loại bỏ yêu cầu major version mới”) và tuân thủ nó.
Chọn giữa JSON và Protobuf thường phụ thuộc nơi API cần chạy—và đội bạn muốn duy trì gì.
JSON gần như phổ quát: mọi trình duyệt và runtime backend đều parse được nó mà không cần phụ thuộc thêm. Trong web app, fetch() + JSON.parse() là đường đi thuận tiện, và proxy/gateway/observability thường hiểu JSON mặc định.
Protobuf chạy được trên trình duyệt, nhưng không miễn phí. Thường bạn thêm thư viện Protobuf (hoặc code JS/TS sinh), quản lý kích thước bundle và quyết định có gửi Protobuf qua endpoint mà tooling trình duyệt dễ inspect không.
Trên iOS/Android và ngôn ngữ backend (Go, Java, Kotlin, C#, Python...), Protobuf có hỗ trợ trưởng thành. Sự khác là Protobuf giả định bạn dùng thư viện trên từng nền tảng và thường sinh code từ .proto.
Code generation mang lại lợi ích thực tế:
Nó cũng thêm chi phí:
.proto chia sẻ, pin version)Protobuf gắn chặt với gRPC, cung cấp câu chuyện tooling đầy đủ: định nghĩa service, stub client, streaming và interceptor. Nếu bạn cân nhắc gRPC, Protobuf là lựa chọn tự nhiên.
Nếu bạn xây API REST JSON truyền thống, hệ sinh thái tooling JSON (DevTools trình duyệt, debug bằng curl, gateway chung) vẫn đơn giản hơn—đặc biệt cho API công khai và tích hợp nhanh.
Nếu bạn đang khám phá bề mặt API, hữu ích khi prototype nhanh cả hai trước khi chuẩn hoá. Ví dụ, đội dùng Koder.ai thường dựng API REST JSON cho tương thích rộng và dịch vụ nội bộ gRPC/Protobuf cho hiệu quả, rồi benchmark payload thực trước khi quyết định cái nào trở thành “mặc định”. Vì Koder.ai có thể sinh app full-stack (React web, Go + PostgreSQL backend, Flutter mobile) và hỗ trợ chế độ planning cùng snapshot/rollback, nên dễ lặp hợp đồng mà không biến quyết định định dạng thành refactor lớn.
JSON là định dạng dạng văn bản, dễ đọc, dễ log và kiểm thử bằng công cụ thông dụng. Protobuf là định dạng nhị phân gọn, được định nghĩa bởi .proto, thường cho payload nhỏ hơn và parse nhanh hơn.
Chọn dựa trên ràng buộc: khả năng tiếp cận và dễ gỡ lỗi (JSON) so với hiệu năng và hợp đồng chặt chẽ (Protobuf).
API gửi byte, không gửi object trong bộ nhớ. Serialization mã hóa object trên server thành payload (JSON text hoặc Protobuf binary) để truyền; deserialization giải mã bytes đó thành object trên client/server.
Lựa chọn định dạng ảnh hưởng đến băng thông, độ trễ và CPU dùng cho (giải) mã hóa.
Thường là vậy, đặc biệt với object lớn, lồng nhau hoặc trường lặp, vì Protobuf dùng tag số và mã hóa nhị phân hiệu quả.
Tuy nhiên, nếu bật gzip/brotli, JSON với các khóa lặp nén rất tốt, nên khác biệt kích thước thực tế có thể thu hẹp. Hãy đo cả kích thước thô và nén.
Có thể. Phân tích JSON phải tokenize văn bản, xử lý escaping/unicode và chuyển chuỗi thành số. Giải mã Protobuf trực tiếp hơn (tag → giá trị kiểu), thường giảm CPU và allocation.
Dù vậy, nếu payload rất nhỏ, độ trễ tổng thể có thể do TLS, RTT mạng và công việc ứng dụng hơn là serialization.
Theo mặc định thì khó hơn. JSON đọc được bằng mắt và dễ inspect trong DevTools, logs, curl và Postman. Payload Protobuf là nhị phân, nên thường cần .proto phù hợp và công cụ giải mã.
Cải tiến phổ biến: log một view debug đã giải mã và đã che bớt (thường là JSON) cùng với request ID và các trường then chốt.
JSON linh hoạt và thường “không schema” trừ khi bạn áp JSON Schema/OpenAPI. Tính linh hoạt này có thể dẫn đến trường không nhất quán, giá trị kiểu chuỗi ("stringly-typed") và ý nghĩa null mơ hồ.
Protobuf bắt buộc kiểu qua .proto, sinh code có kiểu mạnh và làm cho tiến hóa hợp đồng rõ ràng hơn—đặc biệt khi nhiều đội và nhiều ngôn ngữ cùng tham gia.
Trong Protobuf, số trường (field numbers) là danh tính thực trên dây. Thay đổi an toàn thường là thêm trường optional với số mới; thay đổi phá vỡ gồm tái sử dụng số trường hoặc đổi kiểu không tương thích.
Với Protobuf, dùng reserved cho số/tên đã bỏ và giữ changelog. Với JSON, ưu tiên thay đổi bổ sung, giữ ổn định kiểu và coi trường không nhận diện được là có thể bỏ qua.
Có. Dùng content negotiation:
Accept: application/json hoặc Accept: application/x-protobufContent-Type tương ứngVary: Accept để cache không trộn lẫn định dạngNếu tooling khó xử lý negotiation, bạn có thể tạm dùng endpoint/version riêng như một chiến lược chuyển đổi.
Tùy môi trường của bạn:
Cân nhắc chi phí duy trì codegen và quản lý version schema khi chọn Protobuf.
Không tự động. Hãy coi cả hai là input không đáng tin. Các biện pháp thực tế:
Giữ thư viện/parsers cập nhật để giảm rủi ro lỗ hổng parser.