05 thg 10, 2025·8 phút
RabbitMQ cho Ứng Dụng của Bạn: Mẫu, Cài đặt và Vận hành
Tìm hiểu cách dùng RabbitMQ trong ứng dụng: khái niệm cốt lõi, các mẫu phổ biến, mẹo độ tin cậy, mở rộng, bảo mật và giám sát cho môi trường production.
Tìm hiểu cách dùng RabbitMQ trong ứng dụng: khái niệm cốt lõi, các mẫu phổ biến, mẹo độ tin cậy, mở rộng, bảo mật và giám sát cho môi trường production.
RabbitMQ là một trình trung gian tin nhắn: nó đứng giữa các phần của hệ thống và chuyển “công việc” (tin nhắn) một cách đáng tin cậy từ bên tạo (producer) sang bên xử lý (consumer). Các nhóm ứng dụng thường dùng RabbitMQ khi các cuộc gọi đồng bộ trực tiếp (HTTP giữa dịch vụ, cơ sở dữ liệu chia sẻ, cron) bắt đầu tạo ra sự phụ thuộc mong manh, tải không đều và các chuỗi lỗi khó gỡ.
Cú sốc lưu lượng và tải không đồng đều. Nếu ứng dụng của bạn có 10× đăng ký hay đơn hàng trong cửa sổ ngắn, xử lý ngay lập tức có thể làm quá tải dịch vụ phía sau. Với RabbitMQ, bên tạo nhanh chóng đưa các tác vụ vào hàng đợi và bên xử lý (consumer) sẽ xử lý chúng theo nhịp kiểm soát.
Phụ thuộc chặt giữa các dịch vụ. Khi Dịch vụ A phải gọi Dịch vụ B và chờ, lỗi và độ trễ sẽ lan truyền. Messaging tách rời chúng: A phát một tin nhắn rồi tiếp tục; B xử lý khi sẵn sàng.
Xử lý lỗi an toàn hơn. Không phải lỗi nào cũng nên hiện ra cho người dùng. RabbitMQ giúp bạn thử lại xử lý ở nền, cô lập các “poison” message và tránh mất việc khi có sự cố tạm thời.
Các nhóm thường thấy tải công việc mượt hơn (đệm đỉnh), dịch vụ tách rời (ít phụ thuộc lúc chạy), và retry có kiểm soát (ít phải xử lý thủ công). Quan trọng không kém, dễ xác định nơi công việc bị tắc—ở producer, trong hàng đợi, hay ở consumer.
Hướng dẫn này tập trung vào RabbitMQ thực tiễn cho các đội ứng dụng: khái niệm cơ bản, các mẫu phổ biến (pub/sub, work queues, retry và dead-letter queue), và các vấn đề vận hành (bảo mật, mở rộng, quan sát, xử lý sự cố).
Nó không là bản hướng dẫn đầy đủ về AMQP hay đi sâu mọi plugin RabbitMQ. Mục tiêu là giúp bạn thiết kế luồng tin nhắn dễ bảo trì trong hệ thống thực tế.
RabbitMQ là một trình trung gian tin nhắn giúp chuyển tin giữa các phần của hệ thống, để producer có thể giao tiếp công việc và consumer xử lý khi chúng sẵn sàng.
Với HTTP trực tiếp, Dịch vụ A gửi yêu cầu tới Dịch vụ B và thường chờ phản hồi. Nếu B chậm hoặc lỗi, A thất bại hoặc bị treo, và bạn phải xử lý timeout, retry và backpressure ở mọi phía gọi.
Với RabbitMQ (thường qua AMQP), Dịch vụ A publish một tin nhắn tới broker. RabbitMQ lưu và định tuyến nó tới queue phù hợp, và Dịch vụ B tiêu thụ bất đồng bộ. Điểm khác là bạn dùng một lớp trung gian bền vững để đệm các đỉnh và làm mượt tải.
Messaging phù hợp khi bạn:
Messaging không phù hợp khi bạn:
Đồng bộ (HTTP):
Một dịch vụ checkout gọi dịch vụ lập hóa đơn qua HTTP: “Tạo hóa đơn.” Người dùng đợi trong khi lập hóa đơn chạy. Nếu lập hóa đơn chậm, độ trễ checkout tăng; nếu nó chết, checkout thất bại.
Bất đồng bộ (RabbitMQ):
Checkout publish invoice.requested với order id. Người dùng nhận xác nhận ngay là đơn hàng đã được nhận. Lập hóa đơn tiêu thụ tin nhắn, tạo hóa đơn, rồi publish invoice.created để email/notification tiếp tục. Mỗi bước có thể retry độc lập, và sự cố tạm thời không đổ vỡ toàn bộ luồng.
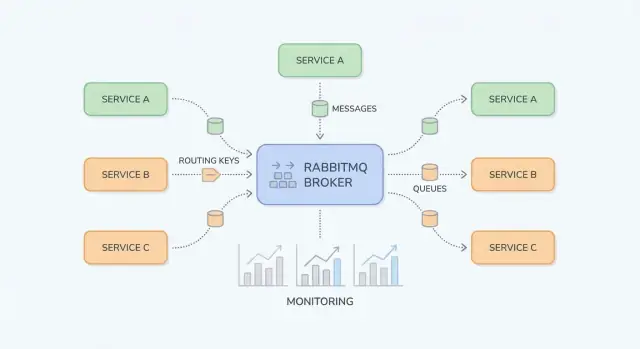
RabbitMQ dễ hiểu nếu tách “nơi publish” khỏi “nơi lưu trữ”. Producer publish tới exchange; exchange định tuyến tới queue; consumer đọc từ queue.
Một exchange không lưu tin nhắn. Nó đánh giá quy tắc và chuyển tiếp tin nhắn tới một hoặc nhiều queue.
billing hoặc email).region=eu AND tier=premium), nhưng giữ nó cho các trường hợp đặc biệt vì khó đoán hơn.Một queue là nơi tin nhắn ngồi chờ đến khi consumer xử lý. Một queue có thể có một hoặc nhiều consumer (competing consumers), và thường mỗi tin nhắn được giao cho một consumer tại một thời điểm.
Một binding kết nối exchange với queue và định nghĩa quy tắc định tuyến. Nghĩ đơn giản: “Khi tin nhắn vào exchange X với routing key Y, chuyển tới queue Q.” Bạn có thể bind nhiều queue vào cùng một exchange (pub/sub) hoặc bind một queue nhiều lần cho các routing key khác nhau.
Với direct exchange, routing là chính xác. Với topic exchange, routing key là những từ ngăn cách bằng dấu chấm, ví dụ:
orders.createdorders.eu.refundedBindings có wildcard:
* khớp đúng một từ (ví dụ orders.* khớp orders.created)# khớp zero hoặc nhiều từ (ví dụ orders.# khớp orders.created và orders.eu.refunded)Điều này cho phép thêm consumer mới mà không thay đổi producer—tạo queue mới và bind theo mẫu cần thiết.
Sau khi RabbitMQ giao tin nhắn, consumer báo lại kết quả:
Cẩn thận với requeue: một tin nhắn luôn thất bại có thể lặp vô hạn và chặn queue. Nhiều đội kết hợp nack với chiến lược retry và một dead-letter queue để xử lý lỗi có dự đoán.
RabbitMQ thể hiện tốt khi bạn cần chuyển công việc hoặc thông báo giữa các phần của hệ thống mà không làm mọi thứ chờ một bước chậm. Dưới đây là các mẫu thực tế xuất hiện thường xuyên.
Khi nhiều consumer cần phản ứng cùng một event—mà publisher không biết họ là ai—pub/sub là phù hợp.
Ví dụ: khi người dùng cập nhật profile, bạn có thể thông báo cho indexing tìm kiếm, analytics, và đồng bộ CRM song song. Với fanout bạn broadcast tới mọi queue bind; với topic bạn định tuyến chọn lọc (ví dụ user.updated, user.deleted). Điều này tránh coupling chặt và cho phép thêm subscriber sau này mà không sửa producer.
Nếu tác vụ tốn thời gian, đẩy nó vào queue và để worker xử lý bất đồng bộ:
Điều này giữ request web nhanh trong khi cho phép scale worker độc lập. Đồng thời dễ kiểm soát concurrency: queue là “danh sách việc cần làm”, và số worker là “nút vặn throughput”.
Nhiều workflow đi qua nhiều dịch vụ: order → billing → shipping. Thay vì một dịch vụ gọi tiếp theo và block, mỗi dịch vụ publish event khi hoàn thành bước. Dịch vụ phía sau tiêu thụ event và tiếp tục workflow.
Điều này cải thiện khả năng chịu lỗi (sự cố tạm thời ở shipping không làm hỏng checkout) và làm rõ ownership: mỗi dịch vụ phản ứng với event mình quan tâm.
RabbitMQ cũng là bộ đệm giữa app và các phụ thuộc chậm hoặc flaky (API bên thứ ba, hệ thống legacy, cơ sở dữ liệu batch). Bạn enqueue yêu cầu nhanh, rồi xử lý chúng với retry có kiểm soát. Nếu phụ thuộc sập, công việc tích tụ an toàn và được xử lý sau—thay vì gây timeouts khắp ứng dụng.
Nếu bạn định giới thiệu queue dần dần, một “async outbox” nhỏ hoặc một hàng đợi background đơn thường là bước khởi đầu tốt.
Một hệ thống RabbitMQ dễ làm việc khi luồng định tuyến rõ, tên nhất quán và payload thay đổi mà không làm vỡ consumer cũ. Trước khi thêm queue, đảm bảo “câu chuyện” của tin nhắn rõ ràng: nó phát sinh ở đâu, được định tuyến thế nào, và đồng nghiệp có thể debug end-to-end ra sao.
Chọn exchange đúng ban đầu giảm binding một lần và fan-out bất ngờ:
billing.invoice.created).billing.*.created, *.invoice.*). Đây là lựa chọn phổ biến cho routing kiểu event.Quy tắc hay: nếu bạn đang “viết” logic định tuyến phức tạp trong code, có thể nên dùng topic exchange thay vì đó.
Xử lý body tin nhắn như API công khai. Dùng versioning rõ ràng (ví dụ trường top-level như schema_version: 2) và cố gắng giữ tương thích ngược:
Điều này giúp consumer cũ tiếp tục chạy trong khi consumer mới cập nhật theo lịch của riêng họ.
Làm cho việc gỡ rối rẻ tiền bằng cách chuẩn hóa metadata:
correlation_id: nối các command/event thuộc một hành động nghiệp vụ.trace_id (hoặc W3C traceparent): liên kết message với tracing phân tán giữa HTTP và luồng bất đồng bộ.Khi mọi publisher đặt những trường này đều đặn, bạn có thể theo dõi một giao dịch qua nhiều dịch vụ mà không cần đoán mò.
Dùng tên dễ đoán, dễ tìm kiếm. Một mẫu phổ biến:
<domain>.<type> (ví dụ billing.events)<domain>.<entity>.<verb> (ví dụ billing.invoice.created)<service>.<purpose> (ví dụ reporting.invoice_created.worker)Nhất quán thắng sự sáng tạo: bạn và người trực sau này sẽ cảm ơn.
Giao tiếp tin nhắn đáng tin cậy là lên kế hoạch cho thất bại: consumer crash, API phía sau timeout, và một số event bị sai. RabbitMQ cung cấp công cụ, nhưng mã ứng dụng phải phối hợp.
Cấu hình phổ biến là at-least-once delivery: một tin nhắn có thể được giao nhiều lần, nhưng không nên bị mất một cách im lặng. Điều này xảy ra khi consumer nhận tin nhắn, bắt đầu xử lý rồi fail trước khi ack—RabbitMQ sẽ requeue và redeliver.
Bài học thực tế: bản sao là bình thường, nên handler của bạn phải an toàn khi chạy nhiều lần.
Idempotency nghĩa là “xử lý cùng một tin nhắn hai lần có cùng kết quả như xử lý một lần.” Các cách hữu dụng:
message_id ổn định (hoặc key nghiệp vụ như order_id + event_type + version) và lưu vào bảng/cache “đã xử lý” với TTL.PENDING) hoặc ràng buộc duy nhất trên DB để tránh tạo trùng.Retry tốt nhất là một luồng riêng, không phải vòng lặp chặt trong consumer.
Mẫu phổ biến:
Cách này tạo backoff mà không giữ message “unacked”.
Một số message sẽ không bao giờ thành công (schema sai, dữ liệu tham chiếu thiếu, bug trong code). Phát hiện bằng:
Route chúng vào DLQ để cách ly. Xử lý DLQ như hộp thư vận hành: kiểm tra payload, sửa lỗi gốc, rồi replay thủ công các tin được chọn (tốt nhất bằng công cụ/script có kiểm soát) thay vì đổ tất cả trở lại queue chính.
Hiệu năng RabbitMQ thường bị giới hạn bởi vài yếu tố thực tế: quản lý kết nối, tốc độ consumer xử lý, và việc dùng queue như “kho lưu trữ”. Mục tiêu là throughput ổn định mà không để backlog tăng mãi.
Một lỗi phổ biến là mở kết nối TCP mới cho mỗi publisher/consumer. Kết nối nặng hơn bạn nghĩ (handshake, heartbeat, TLS), nên giữ chúng lâu và tái dùng.
Dùng channels để multiplex nhiều luồng qua ít kết nối hơn. Nguyên tắc: ít kết nối, nhiều channel. Tuy nhiên đừng tạo hàng ngàn channel vô tội vạ—mỗi channel vẫn có overhead và thư viện client có giới hạn riêng. Ưu tiên pool channel nhỏ cho mỗi service và tái dùng channel khi publish.
Nếu consumer kéo quá nhiều message cùng lúc, bạn sẽ thấy spike bộ nhớ, thời gian xử lý dài và độ trễ không đều. Đặt prefetch (QoS) để mỗi consumer chỉ giữ số message unacked có kiểm soát.
Hướng dẫn thực tế:
Message lớn giảm throughput và tăng áp lực bộ nhớ (ở publisher, broker, consumer). Nếu payload lớn (document, image, JSON lớn), cân nhắc lưu ở object storage hoặc DB và gửi ID + metadata qua RabbitMQ.
Quy tắc: giữ message trong KB, không phải MB.
Tăng trưởng queue là triệu chứng, không phải chiến lược. Thêm backpressure để producer chậm lại khi consumer không theo kịp:
Khi nghi ngờ, thay đổi một thông số rồi đo: publish rate, ack rate, queue length và độ trễ end-to-end.
Bảo mật RabbitMQ chủ yếu là siết “rìa”: client kết nối thế nào, ai được làm gì, và giữ credential khỏi chỗ không đúng.
Quyền RabbitMQ mạnh khi dùng một cách nhất quán.
Với hardening vận hành (port, firewall, auditing), giữ một runbook nội bộ ngắn và tham chiếu nó từ /docs/security để các đội theo cùng tiêu chuẩn.
Khi RabbitMQ gặp sự cố, triệu chứng xuất hiện ở ứng dụng trước: endpoint chậm, timeout, cập nhật thiếu, hoặc job “không bao giờ xong”. Quan sát tốt cho biết broker có phải nguyên nhân không, tìm nút cổ chai (publisher, broker hay consumer), và hành động trước khi người dùng thấy.
Bắt đầu với một tập tín hiệu nhỏ:
Cảnh báo theo xu hướng, không chỉ ngưỡng tuyệt đối.
Log broker giúp phân biệt “RabbitMQ chết” và “client dùng sai”. Tìm authentication failures, blocked connections (resource alarms), và channel errors lặp.
Ở phía ứng dụng, đảm bảo mỗi lần xử lý log correlation_id, tên queue và kết quả (acked, rejected, retried).
Nếu dùng distributed tracing, truyền header trace qua properties của message để nối “API request → published message → consumer work.”
Xây dashboard cho mỗi luồng quan trọng: publish rate, ack rate, depth, unacked, requeues, và consumer count. Thêm link tới runbook nội bộ và checklist “cần kiểm tra gì trước” cho on-call.
Khi có thứ “bỗng dưng không chạy” trong RabbitMQ, đừng vội restart. Hầu hết vấn đề rõ ràng khi bạn nhìn vào (1) bindings và routing, (2) trạng thái consumer, và (3) resource alarms.
Nếu publisher báo “gửi thành công” nhưng queue trống (hoặc queue sai đầy), kiểm tra routing trước khi vào code.
Bắt đầu ở UI quản lý:
Nếu queue có message nhưng không ai tiêu thụ, kiểm tra:
Duplicates thường do retries (consumer crash sau khi xử lý nhưng trước ack), gián đoạn mạng, hoặc requeue thủ công. Giảm bằng cách làm handler idempotent (ví dụ de-dupe bằng message ID trong DB).
Out-of-order là điều có thể xảy ra khi bạn có nhiều consumer hoặc requeue. Nếu thứ tự quan trọng, dùng một consumer cho queue đó, hoặc phân vùng theo key vào nhiều queue.
Alarm nghĩa RabbitMQ đang tự bảo vệ.
Trước khi replay, sửa nguyên nhân gốc và tránh vòng lặp poison. Requeue từng lô nhỏ, thêm cap retry, và gắn metadata (số lần thử, lỗi gần nhất). Cân nhắc gửi message replay tới queue riêng trước để có thể dừng nhanh nếu lỗi lặp lại.
Chọn công cụ messaging không phải “cái nào tốt nhất” mà phù hợp với mô hình lưu lượng, độ chịu lỗi và năng lực vận hành.
RabbitMQ mạnh khi bạn cần giao hàng tin nhắn đáng tin cậy và routing linh hoạt giữa các thành phần ứng dụng. Là lựa chọn tốt cho workflow async cổ điển—commands, background jobs, fan-out notifications, và request/response patterns—đặc biệt khi bạn muốn:
Nếu mục tiêu là chuyển công việc chứ không phải lưu trữ lịch sử event dài, RabbitMQ thường là mặc định dễ chịu.
Kafka và các nền tảng tương tự xây cho streaming throughput cao và event log dài hạn. Chọn Kafka khi bạn cần:
Đổi lại: hệ thống kiểu Kafka có thể phức tạp vận hành hơn và thúc đẩy thiết kế hướng throughput (batching, partition). RabbitMQ dễ cho throughput thấp-trung bình với độ trễ end-to-end thấp và routing phức tạp.
Nếu chỉ có một app tạo job và một worker pool tiêu thụ—và bạn chấp nhận semantics đơn giản—một queue dựa trên Redis (hoặc dịch vụ quản lý task) có thể đủ. Teams thường outgrow khi cần đảm bảo giao hàng mạnh mẽ hơn, dead-lettering, nhiều pattern routing, hoặc tách rõ producer/consumer.
Thiết kế hợp đồng tin nhắn như thể bạn có thể chuyển đổi sau này:
Nếu sau này cần stream replayable, bạn có thể bridge event từ RabbitMQ sang hệ thống log-based trong khi vẫn dùng RabbitMQ cho workflow vận hành.
Triển khai RabbitMQ tốt khi bạn coi nó như một sản phẩm: bắt đầu nhỏ, xác định ownership, và kiểm chứng độ tin cậy trước khi mở rộng.
Chọn một workflow đơn mà hưởng lợi từ async (ví dụ: gửi email, tạo báo cáo, sync API thứ ba).
Nếu cần template tham chiếu cho tên, retry tiers và chính sách cơ bản, giữ nó tập trung trong /docs.
Khi triển khai các pattern này, cân nhắc chuẩn hóa scaffolding giữa các đội. Ví dụ, đội dùng Koder.ai thường generate bộ khung producer/consumer từ prompt (bao gồm naming, wiring retry/DLQ, và trace/correlation headers), rồi export mã để review và lặp lại trước khi rollout.
RabbitMQ thành công khi “có người sở hữu queue.” Quyết trước khi lên prod:
Nếu bạn formal hoá support hoặc hosted service, thống nhất kỳ vọng sớm (ví dụ, tham chiếu /pricing) và đặt đường liên hệ cho incidents hoặc onboarding tại /contact.
Chạy các bài test nhỏ, có thời hạn để xây dựng tự tin:
Khi một service ổn định vài tuần, nhân rộng cùng pattern—đừng mỗi đội lại làm khác nhau.
Use RabbitMQ when you want to decouple services, absorb traffic spikes, or move slow work off the request path.
Good fits include background jobs (emails, PDFs), event notifications to multiple consumers, and workflows that should keep running during temporary downstream outages.
Avoid it when you truly need an immediate response (simple reads/validation) or when you can’t commit to versioning, retries, and monitoring—those aren’t optional in production.
Publish to an exchange and route into queues:
orders.* or orders.#.Most teams default to topic exchanges for maintainable event-style routing.
A queue stores messages until a consumer processes them; a binding is the rule that connects an exchange to a queue.
To debug routing issues:
These three checks explain most “published but not consumed” incidents.
Use a work queue when you want one of many workers to process each task.
Practical setup tips:
At-least-once delivery means a message can be delivered more than once (for example, if a consumer crashes after doing work but before ack).
Make consumers safe by:
message_id (or business key) and recording processed IDs with a TTL.Assume duplicates are normal, and design for them.
Avoid tight requeue loops. A common approach is “retry queues” plus DLQ:
Replay from DLQ only after fixing the root cause, and do it in small batches.
Start with predictable names and treat messages like public APIs:
schema_version to payloads.Also standardize metadata:
Focus on a few signals that show whether work is flowing:
Alert on trends (e.g., “backlog growing for 10 minutes”), then use logs that include queue name, correlation_id, and the processing outcome (acked/retried/rejected).
Do the basics consistently:
Keep a short internal runbook so teams follow one standard (for example, link from /docs/security).
Start by locating where the flow stops:
Restarting is rarely the first or best move.
correlation_id to tie events/commands to one business action.trace_id (or W3C trace headers) to connect async work to distributed traces.This makes onboarding and incident response much easier.