09 thg 8, 2025·8 phút
Khi các trừu tượng của framework rò rỉ khi hệ thống tăng quy mô
Tìm hiểu tại sao framework cao cấp phá vỡ ở quy mô lớn, các kiểu rò rỉ phổ biến, triệu chứng cần chú ý và các cách khắc phục thiết kế và vận hành thực tế.
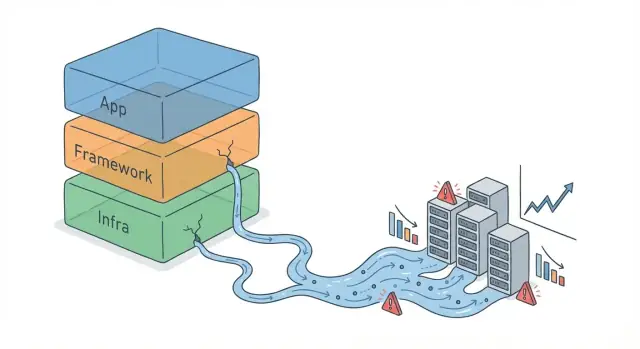
Tìm hiểu tại sao framework cao cấp phá vỡ ở quy mô lớn, các kiểu rò rỉ phổ biến, triệu chứng cần chú ý và các cách khắc phục thiết kế và vận hành thực tế.
Một trừu tượng là một lớp đơn giản hoá: API của framework, ORM, client message queue, thậm chí một helper cache “một dòng”. Nó cho phép bạn nghĩ theo khái niệm cấp cao hơn (“lưu đối tượng này”, “gửi event này”) mà không phải xử lý cơ chế cấp thấp liên tục.
Một rò rỉ trừu tượng xảy ra khi những chi tiết bị ẩn bắt đầu ảnh hưởng đến kết quả thực tế—và bạn buộc phải hiểu và quản lý thứ mà trừu tượng muốn che giấu. Mã vẫn “chạy”, nhưng mô hình đơn giản không còn dự đoán được hành vi thực nữa.
Giai đoạn tăng trưởng ban đầu dễ thở. Với lưu lượng thấp và bộ dữ liệu nhỏ, những bất hiệu quả bị che khuất bởi CPU rảnh, cache ấm và truy vấn nhanh. Spike độ trễ hiếm, retry không chất đống, và một dòng log hơi phí phạm chẳng thành vấn đề.
Khi khối lượng tăng, cùng những lối tắt đó có thể nhân lên:
Trừu tượng rò rỉ thường xuất hiện ở ba lĩnh vực:
Tiếp theo, chúng ta sẽ tập trung vào các tín hiệu thực tế cho thấy trừu tượng đang rò rỉ, cách chẩn đoán nguyên nhân gốc (không chỉ triệu chứng), và các phương án giảm thiểu—từ chỉnh cấu hình đến cố ý “hạ xuống một mức” khi trừu tượng không còn phù hợp với quy mô.
Rất nhiều phần mềm theo cùng một vòng đời: prototype chứng minh ý tưởng, sản phẩm ra mắt, sau đó lượng dùng tăng nhanh hơn kiến trúc ban đầu. Ban đầu, framework cảm thấy thần kỳ vì mặc định cho phép bạn di chuyển nhanh—routing, truy cập DB, logging, retry và background job “miễn phí”.
Khi quy mô, bạn vẫn muốn những lợi ích đó—nhưng mặc định và API tiện lợi bắt đầu hành xử giống như các giả định.
Mặc định framework thường giả định:
Những giả định đó đúng ở giai đoạn đầu, vì vậy trừu tượng trông sạch sẽ. Nhưng khi quy mô thay đổi “bình thường” là gì. Một truy vấn ổn ở 10.000 dòng trở nên chậm ở 100 triệu. Một handler đồng bộ đơn giản bắt đầu timeout khi lưu lượng tăng vọt. Chính sách retry từng che lấp lỗi rải rác có thể khuếch đại sự cố khi hàng nghìn client retry cùng lúc.
Quy mô không chỉ là “nhiều người dùng hơn.” Là khối lượng dữ liệu lớn hơn, lưu lượng đột biến, và nhiều công việc đồng thời cùng lúc. Những yếu tố này đè lên các phần mà trừu tượng che giấu: pool kết nối, lập lịch thread, độ sâu hàng đợi, áp lực bộ nhớ, giới hạn I/O, và giới hạn tốc độ từ phụ thuộc.
Framework thường chọn các cài đặt an toàn, tổng quát (kích thước pool, timeout, hành vi batch). Dưới tải, các cài đặt đó có thể dịch thành contention, độ trễ đuôi dài, và lỗi chuỗi—những vấn đề không hiển thị khi mọi thứ vẫn nằm trong biên độ an toàn.
Môi trường staging hiếm khi phản ánh điều kiện production: dữ liệu nhỏ hơn, ít service hơn, hành vi cache khác, và ít hoạt động “lộn xộn” của người dùng. Trong production bạn còn có biến động mạng thực, noisy neighbors, deploy rolling, và lỗi từng phần. Đó là lý do trừu tượng từng có vẻ kín cổng có thể bắt đầu rò rỉ khi điều kiện thực tế gây áp lực.
Khi trừu tượng framework rò rỉ, triệu chứng hiếm khi xuất hiện dưới dạng thông báo lỗi rõ ràng. Thay vào đó, bạn thấy các mẫu: hành vi ổn ở lưu lượng thấp trở nên không đoán trước hoặc tốn kém ở volume cao hơn.
Một trừu tượng rò rỉ thường báo hiệu bằng độ trễ người dùng nhìn thấy:
Đây là dấu hiệu cổ điển rằng trừu tượng đang che giấu một nút thắt bạn không thể giải quyết mà không hạ xuống (ví dụ: kiểm tra truy vấn thực, sử dụng kết nối, hoặc hành vi I/O).
Một số rò rỉ xuất hiện trước tiên trong hoá đơn hơn là dashboard:
Nếu nâng cấp hạ tầng không khôi phục hiệu năng tương xứng, thường không phải capacity thô—mà là overhead bạn không nhận ra mình đang trả.
Rò rỉ trở thành vấn đề độ tin cậy khi chúng tương tác với retry và chuỗi phụ thuộc:
Dùng điều này để kiểm tra trước khi mua thêm capacity:
Nếu triệu chứng tập trung ở một phụ thuộc (DB, cache, mạng) và không phản ứng dự đoán khi thêm server, đó là chỉ báo mạnh bạn cần nhìn sâu hơn dưới trừu tượng.
ORM tuyệt vời để loại bỏ boilerplate, nhưng cũng khiến bạn dễ quên rằng mỗi đối tượng cuối cùng trở thành một truy vấn SQL. Ở quy mô nhỏ, trao đổi này vô hình. Ở volume cao, cơ sở dữ liệu thường là nơi đầu tiên một trừu tượng “sạch” bắt đầu tính lãi.
N+1 xảy ra khi bạn load danh sách bản ghi cha (1 truy vấn) rồi trong vòng lặp load các bản ghi liên quan cho mỗi cha (N truy vấn nữa). Trong test local trông ổn—có thể N là 20. Trong production, N trở thành 2.000, và app âm thầm biến một request thành hàng nghìn round trip.
Khó ở chỗ không có gì “vỡ” ngay lập tức; độ trễ tăng dần, pool kết nối đầy, và retry nhân đôi tải.
Trừu tượng thường khuyến khích lấy toàn bộ đối tượng theo mặc định, ngay cả khi bạn chỉ cần hai trường. Điều đó tăng I/O, bộ nhớ và truyền mạng.
Đồng thời, ORM có thể sinh truy vấn bỏ qua chỉ mục bạn nghĩ là đang dùng (hoặc chưa tồn tại). Một chỉ mục thiếu có thể biến lookup chọn lọc thành quét bảng.
Join là chi phí ẩn khác: cái đọc như “chỉ include relation” có thể thành truy vấn nhiều join với kết quả trung gian lớn.
Dưới tải, kết nối DB là tài nguyên khan hiếm. Nếu mỗi request bung ra nhiều truy vấn, pool nhanh chóng chạm giới hạn và app bắt đầu queue.
Giao dịch dài (đôi khi vô tình) cũng gây contention—khoá tồn tại lâu hơn, và độ đồng thời sụp đổ.
Đồng thời là nơi trừu tượng có thể trông “an toàn” trong phát triển rồi thất bại ồn ào dưới tải. Mô hình mặc định của framework thường che giấu giới hạn thực: bạn không chỉ phục vụ request—bạn đang quản lý contention cho CPU, thread, socket và năng lực downstream.
Thread-per-request (phổ biến trong các stack web cổ điển) đơn giản: mỗi request lấy một worker thread. Nó vỡ khi I/O chậm (DB, API) khiến thread tích tụ. Khi pool thread cạn, request queue, độ trễ tăng, và cuối cùng bạn gặp timeout—trong khi server “bận” nhưng thực tế chỉ chờ.
Async/event-loop xử lý nhiều request đang chạy với ít thread hơn, nên tốt cho độ đồng thời cao. Nó vỡ theo cách khác: một cuộc gọi blocking (thư viện sync, parse JSON nặng, logging nặng) có thể làm tắc event loop, biến “một request chậm” thành “mọi thứ đều chậm.” Async cũng dễ tạo quá nhiều concurrency, áp đảo phụ thuộc nhanh hơn giới hạn thread.
Backpressure là hệ thống nói với caller “chậm lại; tôi không thể nhận thêm.” Nếu không có nó, một phụ thuộc chậm (DB, nhà cung cấp thanh toán) không chỉ làm chậm phản hồi—mà còn tăng số công việc đang xử lý, dùng bộ nhớ, và độ sâu hàng đợi. Công việc tăng thêm đó lại làm phụ thuộc chậm hơn, tạo vòng phản hồi.
Timeout phải rõ ràng và theo tầng: client, service, và dependency. Nếu timeout quá dài, hàng đợi lớn và thời gian hồi phục kéo dài. Nếu retry tự động và quá hung hãn, bạn có thể kích hoạt bão retry: phụ thuộc chậm, gọi timeout, caller retry, tải nhân lên, và phụ thuộc sụp đổ.
Framework khiến việc gọi endpoint mạng trông như “chỉ gọi một hàm.” Dưới tải, trừu tượng đó thường rò rỉ qua công việc vô hình do stack middleware, serialization, và xử lý payload thực hiện.
Mỗi lớp—API gateway, auth middleware, rate limiting, request validation, hook observability, retry—thêm một chút thời gian. Một ms thêm hiếm khi đáng kể trong phát triển; ở quy mô, vài lớp middleware có thể biến request 20 ms thành 60–100 ms, nhất là khi hàng đợi hình thành.
Điều then chốt là độ trễ không chỉ cộng—nó nhân lên. Trễ nhỏ làm tăng độ đồng thời (nhiều request đang xử lý), dẫn tới contention (thread pool, connection pool), rồi lại tăng trễ.
JSON tiện lợi, nhưng encode/decode payload lớn có thể chiếm CPU chính. Rò rỉ xuất hiện như độ trễ “mạng” thực ra là CPU của ứng dụng, cùng với churn bộ nhớ do cấp phát buffer.
Payload lớn cũng làm chậm mọi thứ xung quanh chúng:
Header có thể âm thầm làm phình request (cookie, token auth, tracing headers). Sự phình này nhân lên qua mọi call và hop.
Nén là một đánh đổi. Nó có thể tiết kiệm băng thông, nhưng tốn CPU và có thể thêm độ trễ—đặc biệt khi bạn nén payload nhỏ hoặc nén nhiều lần qua proxy.
Cuối cùng, streaming vs buffering quan trọng. Nhiều framework buffer toàn bộ body request/response theo mặc định (để enable retry, logging, hay tính content-length). Điều đó tiện nhưng ở khối lượng lớn tăng dùng bộ nhớ và tạo head-of-line blocking. Streaming giúp duy trì bộ nhớ dự đoán được và giảm time-to-first-byte, nhưng yêu cầu xử lý lỗi cẩn thận hơn.
Đặt kích thước payload và độ sâu middleware như ngân sách, không phải sau lưng:
Khi quy mô phơi bày overhead mạng, giải pháp thường không phải “tối ưu mạng” mà là “ngừng thực hiện công việc ẩn trên mỗi request.”
Cache thường được xem như công tắc đơn giản: thêm Redis (hoặc CDN), thấy độ trễ giảm, rồi xong. Trong thực tế, caching là một trừu tượng có thể rò rỉ mạnh—vì nó thay đổi nơi công việc xảy ra, khi nào công việc xảy ra, và cách lỗi lan truyền.
Cache thêm các hop mạng, serialization và phức tạp vận hành. Nó còn giới thiệu nguồn chân lý thứ hai có thể lỗi thời, được điền một phần, hoặc không khả dụng. Khi có sự cố, hệ thống không chỉ chậm hơn—mà có thể hành xử khác (phục vụ dữ liệu cũ, khuếch đại retry, hoặc làm quá tải DB).
Cache stampedes xảy ra khi nhiều request miss cache cùng lúc (thường sau khi hết hạn) và tất cả cùng chạy để rebuild cùng một giá trị. Ở quy mô, điều này có thể biến miss rate nhỏ thành spike DB.
Thiết kế key kém là vấn đề im lặng khác. Nếu key quá rộng (ví dụ user:feed mà không kèm tham số), bạn phục vụ dữ liệu sai. Nếu key quá cụ thể (kèm timestamp, ID ngẫu nhiên, hoặc param không chuẩn hóa), bạn có hit rate gần bằng 0 và trả phí overhead vô ích.
Invalidation là bẫy kinh điển: cập nhật DB dễ, nhưng đảm bảo mọi view cache liên quan được làm mới thì khó. Invalidaton một phần dẫn đến bug “với tôi đã được” và đọc không nhất quán.
Lưu lượng thực không đều. Một profile người nổi tiếng, một sản phẩm hot, hay endpoint config chia sẻ có thể biến thành hot key, tập trung tải vào một entry cache duy nhất và store backing của nó. Ngay cả khi hiệu năng trung bình ổn, đuôi độ trễ và áp lực trên node có thể bùng nổ.
Framework thường khiến bộ nhớ có vẻ “được quản lý”, điều đó an ủi—cho đến khi lưu lượng tăng và độ trễ bắt đầu nhảy theo cách không khớp với đồ thị CPU. Nhiều mặc định được tinh chỉnh cho tiện lợi dev, không phải cho tiến trình chạy lâu dưới tải liên tục.
Các framework cấp cao thường cấp phát các đối tượng ngắn hạn trên mỗi request: wrapper request/response, context middleware, cây JSON, regex matcher tạm, và chuỗi tạm. Lần lượt, chúng nhỏ. Ở quy mô, chúng tạo áp lực cấp phát liên tục, ép runtime chạy GC thường xuyên.
Pause GC có thể trở nên nhìn thấy được như các spike độ trễ ngắn nhưng thường xuyên. Khi heap tăng, pause thường kéo dài hơn—không nhất thiết vì bạn leak, mà vì runtime cần nhiều thời gian hơn để quét và gom.
Dưới tải, service có thể promote đối tượng vào generation “cũ” (hoặc vùng sống lâu) chỉ vì chúng sống sót vài chu kỳ GC trong khi chờ hàng đợi, buffer, pool kết nối, hoặc request đang xử lý. Điều này có thể làm phình heap ngay cả khi ứng dụng “đúng”.
Phân mảnh là chi phí ẩn khác: bộ nhớ có thể rảnh nhưng không thể tái sử dụng cho kích thước bạn cần, nên process tiếp tục yêu cầu OS thêm.
Rò rỉ thực sự là tăng không giới hạn theo thời gian: bộ nhớ lên, không trở về, rồi OOM kill hoặc GC thrash cực đoan. Dùng cao nhưng ổn định khác: bộ nhớ lên đến mức bão hòa sau warm-up, rồi giữ tương đối phẳng.
Bắt đầu bằng profiling (heap snapshot, allocation flame graph) để tìm đường dẫn cấp phát nóng và đối tượng giữ lại.
Cẩn trọng với pooling: nó giảm cấp phát, nhưng pool cỡ tệ có thể ghim bộ nhớ và làm trầm trọng phân mảnh. Ưu tiên giảm cấp phát trước (streaming thay vì buffering, tránh tạo object không cần thiết, giới hạn cache theo request), rồi thêm pooling khi đo lường cho thấy rõ lợi ích.
Công cụ observability thường trông “miễn phí” vì framework cho mặc định tiện lợi: log request, metrics auto-instrument, và tracing một dòng. Dưới lưu lượng thực, mặc định đó có thể trở thành một phần workload bạn đang cố gắng quan sát.
Log mỗi request là ví dụ kinh điển. Một dòng mỗi request trông vô hại—đến khi bạn đạt hàng nghìn request mỗi giây. Khi đó bạn trả chi phí cho format chuỗi, encode JSON, ghi đĩa hoặc mạng, và ingest downstream. Rò rỉ xuất hiện như độ trễ đuôi cao, spike CPU, pipeline log tụt lại, và đôi khi request timeout do flush log đồng bộ.
Metrics có thể quá tải hệ thống theo cách thầm lặng hơn. Counters và histogram rẻ khi bạn có ít time series. Nhưng framework thường khuyến khích thêm tag/label như user_id, email, path, hoặc order_id. Điều này dẫn đến bùng nổ cardinality: thay vì một metric, bạn tạo hàng triệu series riêng. Hệ quả là bộ nhớ client metric và backend phình to, query dashboard chậm, sample bị drop, và hoá đơn bất ngờ.
Distributed tracing thêm chi phí lưu trữ và compute tăng theo traffic và số span mỗi request. Nếu trace mọi thứ theo mặc định, bạn có thể trả hai lần: một lần cho overhead trong app (tạo span, truyền context) và lần nữa cho backend tracing (ingest, indexing, retention).
Sampling là cách đội lấy lại kiểm soát—nhưng dễ làm sai. Sampling quá mạnh sẽ che những lỗi hiếm; sampling quá ít làm tracing tốn kém. Cách thực tế là sample nhiều hơn với lỗi và request chậm, ít hơn với đường dẫn nhanh khỏe.
Nếu bạn muốn baseline cho những gì nên thu thập (và nên tránh), xem /blog/observability-basics.
Đối xử observability như traffic production: đặt ngân sách (khối lượng log, số series metric, ingest trace), rà thẻ tag cho rủi ro cardinality, và load-test với instrumentation bật. Mục tiêu không phải “ít observability hơn” mà là observability vẫn hoạt động khi hệ thống chịu áp lực.
Framework thường khiến gọi service khác trông như gọi hàm cục bộ: userService.getUser(id) trả nhanh, lỗi là “exception”, và retry trông vô hại. Ở quy mô nhỏ ảo tưởng đó đúng. Ở quy mô lớn, trừu tượng rò rỉ vì mỗi cuộc gọi mang coupling ẩn: độ trễ, giới hạn năng lực, lỗi từng phần, và mismatch phiên bản.
Một cuộc gọi remote gắn chặt chu kỳ release, mô hình dữ liệu, và uptime của hai team. Nếu Service A cho rằng Service B luôn sẵn sàng và nhanh, hành vi của A không còn do code của chính nó định nghĩa—mà do ngày tệ nhất của B. Đây là cách hệ thống trở nên chặt chẽ mặc dù mã trông mô-đun.
Giao dịch phân tán là cái bẫy: cái trông như “lưu user, rồi charge thẻ” trở thành workflow nhiều bước qua DB và service. Two-phase commit hiếm khi giữ được tính đơn giản ở production, nên nhiều hệ thống chuyển sang eventual consistency (ví dụ “thanh toán sẽ được xác nhận sau”). Sự đổi hướng này buộc bạn thiết kế cho retry, bản sao, và sự kiện ngoài thứ tự.
Idempotency trở nên thiết yếu: nếu request được retry do timeout, nó không được tạo charge thứ hai hay gửi đơn thứ hai. Helper retry ở mức framework có thể khuếch đại vấn đề nếu endpoint của bạn không an toàn để lặp lại.
Một phụ thuộc chậm có thể làm cạn pool thread, pool kết nối, hoặc hàng đợi, tạo hiệu ứng dây chuyền: timeout kích hoạt retry, retry tăng tải, và sớm thôi endpoint không liên quan cũng suy giảm. “Chỉ thêm instance” có thể làm xấu thêm cơn bão nếu mọi người đều retry cùng lúc.
Định nghĩa hợp đồng rõ ràng (schema, mã lỗi, versioning), đặt timeout và ngân sách cho mỗi cuộc gọi, và triển khai fallback (read cache, degrade response) khi phù hợp.
Cuối cùng, đặt SLO cho mỗi phụ thuộc và thực thi chúng: nếu Service B không đáp ứng SLO, Service A nên fail fast hoặc degrade gracefully thay vì âm thầm kéo cả hệ thống xuống.
Khi một trừu tượng rò rỉ ở quy mô, nó thường xuất hiện như triệu chứng mơ hồ (timeout, spike CPU, truy vấn chậm) khiến team muốn rewrite sớm. Cách tốt hơn là biến linh cảm thành bằng chứng.
1) Tái hiện (khiến nó fail theo nhu cầu).
Bắt kịch bản nhỏ nhất vẫn kích hoạt vấn đề: endpoint, job nền hoặc luồng người dùng. Tái hiện local hoặc staging với cấu hình giống production (feature flag, timeout, pool kết nối).
2) Đo (chọn hai hoặc ba tín hiệu).
Chọn vài metric cho biết thời gian và tài nguyên đi đâu: p95/p99 latency, tỷ lệ lỗi, CPU, memory, thời gian GC, thời gian truy vấn DB, độ sâu hàng đợi. Tránh thêm hàng chục đồ thị mới giữa sự cố.
3) Cô lập (thu hẹp nghi phạm).
Dùng tooling để tách “overhead framework” khỏi “mã của bạn”:
4) Xác nhận (chứng minh nhân quả).
Thay đổi một biến tại một thời điểm: bypass ORM cho một truy vấn, vô hiệu middleware, giảm volume log, giới hạn concurrency, hoặc thay đổi kích thước pool. Nếu triệu chứng di chuyển theo dự đoán, bạn đã tìm ra rò rỉ.
Dùng kích thước dữ liệu thực tế (số hàng, kích thước payload) và độ đồng thời thực tế (đột biến, đuôi dài, client chậm). Nhiều rò rỉ chỉ xuất hiện khi cache lạnh, bảng lớn, hoặc retry khuếch đại tải.
Rò rỉ trừu tượng không phải là thất bại đạo đức của framework—mà là tín hiệu rằng nhu cầu hệ thống đã vượt quá “đường mặc định.” Mục tiêu không phải bỏ framework, mà là deliberate quyết định khi tinh chỉnh và khi bypass.
Ở lại trong framework khi vấn đề là cấu hình hoặc cách dùng hơn là bất tương hợp căn bản. Ứng viên tốt:
Nếu bạn có thể sửa bằng tinh chỉnh và guardrail, bạn giữ được lợi ích nâng cấp và giảm các “trường hợp đặc biệt”.
Hầu hết framework trưởng thành cung cấp cách bước ra khỏi abstraction mà không viết lại mọi thứ. Các pattern phổ biến:
Điều này giữ framework như một công cụ, không phải dependency chi phối kiến trúc.
Giảm thiểu vừa là vận hành vừa là code:
Với các thực hành rollout liên quan, xem /blog/canary-releases.
Hạ xuống một mức khi (1) vấn đề nằm trên đường dẫn quan trọng, (2) bạn có thể đo được lợi ích, và (3) thay đổi không tạo chi phí bảo trì dài hạn đội bạn không chịu nổi. Nếu chỉ một người hiểu cách bypass, đó không phải là “fix”—mà là mong manh.
Khi đi săn rò rỉ, tốc độ quan trọng—nhưng cũng cần thay đổi có thể hoàn tác. Các team thường dùng Koder.ai để dựng nhanh các bản tái hiện nhỏ, cô lập của vấn đề production (một UI React tối giản, một service Go, schema PostgreSQL, và harness load-test) mà không tốn ngày làm scaffolding. Chế độ planning giúp ghi chép những gì bạn thay đổi và lý do, trong khi snapshot và rollback làm an toàn khi thử nghiệm “hạ xuống một mức” (như đổi một truy vấn ORM sang SQL thô) rồi quay lại nếu dữ liệu không ủng hộ.
Nếu bạn làm công việc này qua nhiều môi trường, khả năng deployment/hosting và xuất mã của Koder.ai cũng giúp giữ artifact chẩn đoán (benchmark, app tái hiện, dashboard nội bộ) như phần mềm thực—có version, dễ chia sẻ và không kẹt trong thư mục local của ai đó.
Một abstraction rò rỉ là một lớp cố gắng che giấu sự phức tạp (ORM, helper retry, wrapper cache, middleware), nhưng dưới tải trọng cao những chi tiết bị ẩn bắt đầu thay đổi kết quả thực tế.
Thực tế, đó là khi mô hình tư duy “đơn giản” không còn dự đoán được hành vi thật, và bạn buộc phải hiểu các thứ như kế hoạch truy vấn, pool kết nối, độ sâu hàng đợi, GC, timeout và cơ chế retry.
Các hệ thống giai đoạn đầu có thừa tài nguyên: bảng nhỏ, độ đồng thời thấp, cache ấm, và ít tương tác lỗi.
Khi lưu lượng tăng, các chi phí nhỏ trở thành nút thắt liên tục, và các trường hợp biên hiếm (timeout, lỗi từng phần) trở nên bình thường. Khi đó chi phí và giới hạn ẩn của abstraction bắt đầu xuất hiện trong hành vi production.
Tìm các mẫu không cải thiện theo cách dự đoán khi bạn tăng tài nguyên:
Việc tăng tài nguyên thường cải thiện hiệu năng theo tỷ lệ tương đối nếu chỉ thiếu hụt năng lực.
Một rò rỉ thường biểu hiện:
Dùng checklist trong bài: nếu tăng gấp đôi tài nguyên mà không khôi phục tương xứng, hãy nghi ngờ có rò rỉ.
ORM che dấu rằng mỗi thao tác trên đối tượng cuối cùng thành một truy vấn SQL. Các rò rỉ phổ biến:
Khắc phục: eager loading có chủ ý, chỉ select cột cần thiết, phân trang, batch, và kiểm tra SQL sinh ra với EXPLAIN.
Pool kết nối giới hạn độ đồng thời để bảo vệ DB, nhưng sự sinh ra truy vấn ẩn có thể làm cạn pool.
Khi pool đầy, request queue ở tầng app, tăng độ trễ và giữ tài nguyên lâu hơn. Giao dịch dài làm trầm trọng tình trạng bằng cách giữ khoá và giảm khả năng đồng thời.
Sửa thực tế:
Thread-per-request sẽ hỏng khi I/O chậm làm đầy pool thread; mọi thứ queue lại và timeout tăng vọt.
Async/event-loop sẽ hỏng khi một cuộc gọi blocking làm nghẽn loop, hoặc khi bạn tạo quá nhiều concurrency và áp đảo phụ thuộc.
Cả hai đều khiến abstraction “framework quản lý concurrency” rò rỉ thành nhu cầu đặt giới hạn rõ ràng, timeout, và backpressure.
Backpressure là cơ chế để thành phần nói “chậm lại” khi nó không thể nhận thêm việc một cách an toàn.
Không có backpressure, phụ thuộc chậm làm tăng số request đang xử lý, dùng nhiều bộ nhớ và làm dài hàng đợi—làm cho phụ thuộc còn chậm hơn (vòng phản hồi tiêu cực).
Công cụ phổ biến:
Retry tự động có thể biến chậm thành sập:
Giảm thiểu bằng:
Instrumentation tốn công việc thực khi traffic lớn:
user_id, email, order_id) có thể nổ số time series và tăng chi phíKiểm soát thực tế: