Sharding là gì (và không phải là gì)
Sharding (còn gọi là phân vùng ngang) là việc biến cái nhìn của ứng dụng về một cơ sở dữ liệu thành dữ liệu được chia trên nhiều máy, gọi là shard. Mỗi shard chỉ chứa một phần các dòng, nhưng cùng nhau chúng tạo thành tập dữ liệu đầy đủ.
Một bảng logic, nhiều nơi lưu trữ vật lý
Một mô hình tư duy hữu ích là phân biệt cấu trúc logic và vị trí vật lý.
- Logic: bạn vẫn có một bảng “Users” duy nhất (cùng cột, cùng ý nghĩa).
- Vật lý: các hàng của bảng đó được lưu ở nhiều nơi—ví dụ users có ID 1–1.000.000 trên shard A, và triệu tiếp theo trên shard B.
Với ứng dụng, bạn muốn chạy truy vấn như thể đó là một bảng đơn. Ở bên dưới, hệ thống phải quyết định nên nói chuyện với shard nào.
Không phải replication, không phải “mua máy to hơn”
Sharding khác với replication. Replication tạo bản sao của cùng dữ liệu trên nhiều node, chủ yếu để tăng sẵn sàng và khả năng đọc. Sharding chia dữ liệu sao cho mỗi node chứa các bản ghi khác nhau.
Cũng khác với scaling theo chiều dọc, nơi bạn giữ một DB nhưng chuyển sang máy mạnh hơn (CPU/RAM/đĩa nhanh hơn). Vertical scaling có thể đơn giản hơn, nhưng có giới hạn thực tế và chi phí tăng nhanh.
Những thứ sharding không tự động sửa chữa
Sharding tăng khả năng chứa và throughput, nhưng không tự làm cho cơ sở dữ liệu “dễ” hoặc làm mọi truy vấn nhanh hơn.
- Join có thể trở nên tốn kém nếu các hàng liên quan nằm trên các shard khác nhau.
- Giao dịch xuyên-shard khó hơn; cập nhật “tất cả hoặc không” có thể cần phối hợp.
- Độ phức tạp vận hành tăng: routing, rebalancing, debug và xử lý lỗi trở thành một phần hệ thống.
Vì vậy sharding nên được hiểu như một cách để mở rộng lưu trữ và throughput—không phải một bản nâng cấp miễn phí cho mọi khía cạnh hành vi cơ sở dữ liệu.
Tại sao các đội shard: vấn đề họ muốn giải quyết
Sharding hiếm khi là lựa chọn đầu tiên. Các đội thường hướng tới nó sau khi hệ thống thành công chạm tới giới hạn vật lý—hoặc khi đau đầu vận hành xuất hiện quá thường xuyên để bỏ qua. Động lực ít là “chúng tôi muốn sharding” hơn là “chúng tôi cần cách tiếp tục mở rộng mà không để một DB trở thành điểm lỗi đơn lẻ và chi phí lớn”.
Những điểm đau đẩy đội tới sharding
Một node DB đơn có thể cạn chỗ theo nhiều cách khác nhau:
- Giới hạn lưu trữ: bảng và chỉ mục tăng đến khi đĩa chật, backup chậm, và thao tác bảo trì rủi ro.
- Giới hạn throughput ghi: CPU, WAL/redo, hoặc contention khóa giới hạn số ghi/giây.
- Giới hạn throughput đọc: ngay cả với caching và replicas, một số workload vẫn quá tải primary (hoặc replicas trở nên tốn kém khi mở rộng).
- Noisy neighbors: một tenant, khách hàng, hoặc pattern workload chiếm dụng tài nguyên và làm giảm trải nghiệm của những người khác.
Khi những vấn đề này xuất hiện thường xuyên, vấn đề thường không phải một truy vấn xấu—mà là một máy chịu quá nhiều trách nhiệm.
Mục tiêu: mở rộng ngang, cô lập và kiểm soát chi phí
Sharding cơ sở dữ liệu phân tán dữ liệu và lưu lượng qua nhiều node để năng lực tăng bằng cách thêm máy thay vì nâng cấp dọc. Nếu làm tốt, nó còn có thể cô lập workload (một spike của tenant không làm hỏng latency của người khác) và kiểm soát chi phí bằng cách tránh phải dùng các instance đắt tiền ngày càng lớn.
Dấu hiệu sớm bạn đang gần tới giới hạn
Các pattern lặp lại bao gồm p95/p99 latency tăng dần trong giờ cao điểm, replication lag dài hơn, backup/restore vượt quá cửa sổ chấp nhận được, và các thay đổi schema “nhỏ” trở thành các sự kiện lớn.
Tại sao sharding thường là bước cuối cùng
Trước khi quyết định, các đội thường đã thử các lựa chọn đơn giản hơn: indexing và sửa truy vấn, caching, read replicas, partitioning trong một DB đơn, archive dữ liệu cũ, và nâng cấp phần cứng. Sharding có thể giải quyết vấn đề scale, nhưng nó cũng thêm phối hợp, độ phức tạp vận hành và chế độ lỗi mới—vì vậy tiêu chuẩn phải cao.
Một cơ sở dữ liệu sharded không phải là một thứ duy nhất—nó là một hệ nhỏ của các phần hợp tác. Lý do sharding có thể cảm thấy “khó suy luận” là vì tính đúng đắn và hiệu năng phụ thuộc vào cách các phần này tương tác, không chỉ engine DB.
Shard: phân vùng độc lập (với chỉ mục riêng)
Một shard là một tập con của dữ liệu, thường lưu trên server hoặc cluster riêng. Mỗi shard thường có:
- storage riêng (tệp dữ liệu)
- chỉ mục riêng (để truy vấn nhanh trong shard đó)
- giới hạn cục bộ (CPU, bộ nhớ, đĩa, kết nối)
Với ứng dụng, một setup sharded thường cố gắng trông như một DB logic duy nhất. Nhưng ở bên dưới, một truy vấn vốn là “một lần lookup bằng chỉ mục” trên single-node có thể trở thành “tìm shard đúng, rồi thực hiện lookup”.
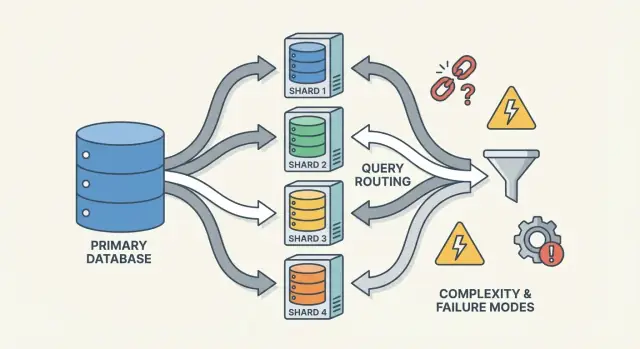
Router/coordinator: làm sao yêu cầu tới đúng shard
Một router (đôi khi gọi coordinator, query router, hoặc proxy) là cảnh sát giao thông. Nó trả lời câu hỏi thực tế: yêu cầu này thì shard nào xử lý?
Có hai mẫu thông dụng:
- Client-side routing: thư viện ứng dụng biết bản đồ shard và kết nối trực tiếp tới shard đúng.
- Proxy routing: app kết nối tới dịch vụ router, router chuyển tiếp yêu cầu.
Router làm giảm độ phức tạp ở app, nhưng nó cũng có thể trở thành điểm nghẽn hoặc điểm lỗi mới nếu không thiết kế cẩn thận.
Sharding dựa vào metadata—nguồn sự thật mô tả:
- shard map (shard nào sở hữu range/hash bucket/ID nào)
- ownership (đặc biệt khi di chuyển, ownership có thể overlap tạm thời)
- health và membership (node nào đang lên, vai trò primary/replica, trạng thái draining)
Thông tin này thường sống trong một dịch vụ config (hoặc một DB “control plane” nhỏ). Nếu metadata lỗi thời hoặc không nhất quán, router có thể gửi traffic đến chỗ sai—dù mỗi shard có thể vẫn khỏe mạnh.
Các job nền: cân bằng, migration và backup
Cuối cùng, sharding phụ thuộc vào các process nền giữ cho hệ thống sống theo thời gian:
- rebalancing dữ liệu khi một shard lớn nhanh hơn các shard khác
- migration khi di chuyển ownership giữa các shard
- backup/restore quy trình hoạt động trên nhiều shard (phù hợp với mục tiêu recovery của bạn)
Những job này dễ bị bỏ qua khi mới bắt đầu, nhưng lại là nơi nhiều bất ngờ trong production xảy ra—vì chúng thay đổi hình dạng hệ thống khi hệ thống vẫn đang phục vụ traffic.
Chọn khóa shard: trao đổi lớn đầu tiên
Shard key là trường (hoặc tổ hợp trường) hệ thống dùng để quyết định shard nào sẽ lưu một hàng/document. Lựa chọn này quyết định hiệu năng, chi phí, và cả những tính năng nào sẽ “dễ” sau này—vì nó kiểm soát liệu các yêu cầu có thể routing tới một shard hay phải fan-out.
Khóa shard “tốt” có gì
Khóa tốt thường có:
- Độ phân biệt cao: nhiều giá trị khả dĩ (ví dụ
user_id thay vì country).
- Phân phối đều: giá trị trải đều đọc/ghi qua các shard thay vì dồn vào một chỗ.
- Mẫu truy cập ổn định: khớp với cách bạn truy vấn dữ liệu hiện nay và cách bạn dự kiến truy vấn quý tới.
Ví dụ phổ biến là shard theo tenant_id trong app đa-tenant: hầu hết đọc/ghi cho một tenant nằm trên một shard, và số tenant đủ lớn để phân tán tải.
Khóa shard “tệ” gây hại như thế nào
Một số khóa gần như đảm bảo rắc rối:
- Khóa theo thời gian monotonic (timestamp, ID tự tăng): dữ liệu mới dồn vào shard “mới nhất”, tạo hotspot ghi.
- Trường độ phân biệt thấp (status, plan_tier, country): quá ít giá trị khiến một vài shard đảm nhận phần lớn công việc.
- Identifier thay đổi được (email, username): nếu khóa thay đổi, di chuyển dữ liệu giữa shard rất tốn kém và rủi ro.
Ngay cả khi một khóa low-cardinality tiện cho lọc, nó thường biến truy vấn thông thường thành scatter-gather, vì các hàng phù hợp nằm khắp nơi.
Trao đổi thực tế: thuận tiện truy vấn vs chất lượng phân phối
Khóa shard tốt cho cân bằng tải không luôn là tốt nhất cho truy vấn sản phẩm.
- Chọn khóa phù hợp với mẫu truy cập chính (ví dụ
user_id), và một số truy vấn “toàn cục” (ví dụ báo cáo admin) sẽ chậm hơn hoặc cần pipeline riêng.
- Chọn khóa phù hợp cho báo cáo (ví dụ
region), bạn dễ gặp hotspot và dung lượng không đều.
Hầu hết đội thiết kế quanh trao đổi này: tối ưu khóa shard cho các thao tác phổ biến, nhạy latency—và xử lý phần còn lại bằng index, denormalization, replicas, hoặc bảng analytics chuyên dụng.
Các chiến lược sharding thông dụng (Range, Hash, Directory)
Không có một cách “tốt nhất” để shard. Chiến lược bạn chọn định hình mức độ dễ routing, phân phối dữ liệu đều, và loại pattern truy cập sẽ gây rắc rối.
Range sharding
Với range sharding, mỗi shard sở hữu một lát liên tục của không gian khóa—ví dụ:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
Routing đơn giản: nhìn vào khóa, chọn shard.
Nhược điểm là hotspot. Nếu người dùng mới luôn nhận ID tăng dần, shard “cuối” sẽ trở thành nút cổ chai ghi. Range sharding cũng nhạy với tăng trưởng không đồng đều (một range nổi tiếng, range khác ít dùng). Ưu điểm: truy vấn theo range ("tất cả order từ 1–31 Oct") có thể hiệu quả vì dữ liệu được nhóm vật lý.
Hash sharding
Hash sharding chạy khóa shard qua một hàm băm và dùng kết quả để chọn shard. Thường thì cách này phân phối dữ liệu đều hơn, giúp tránh vấn đề “mọi thứ đổ về shard mới nhất”.
Đổi lại: truy vấn theo range sẽ tốn. Một truy vấn như “customers với ID giữa X và Y” không còn ánh xạ tới ít shard nữa; nó có thể chạm nhiều shard.
Một chi tiết thực tế mà đội thường đánh giá thấp là consistent hashing. Thay vì ánh xạ trực tiếp theo số lượng shard (khi thêm shard thì mọi thứ bị xáo trộn), nhiều hệ thống dùng hash ring với “virtual nodes” để khi thêm capacity chỉ di chuyển một phần khóa.
Directory (lookup) sharding
Directory sharding lưu một ánh xạ rõ ràng (bảng lookup/dịch vụ) từ key → vị trí shard. Đây là cách linh hoạt nhất: bạn có thể đặt tenant cụ thể trên shard dành riêng, di chuyển một khách hàng mà không di chuyển mọi người, và hỗ trợ shard có kích thước không đều.
Nhược điểm là một phụ thuộc thêm. Nếu directory chậm, lỗi thời, hoặc không khả dụng, routing sẽ bị ảnh hưởng—dù các shard vẫn khỏe.
Khóa ghép và sub-sharding
Hệ thống thực tế thường kết hợp các cách. Khóa ghép (ví dụ tenant_id + user_id) giữ tenant được cô lập đồng thời phân tán tải trong tenant đó. Sub-sharding tương tự: đầu tiên route theo tenant, sau đó hash trong nhóm shard của tenant để tránh một tenant lớn chiếm đóng một shard duy nhất.
Truy vấn hoạt động thế nào: Routing vs Scatter-Gather
Mô phỏng Shard Đa-tenant
Xây dựng một app đa-tenant nhỏ và xem cách shard theo tenant_id thay đổi truy vấn của bạn.
Cơ sở dữ liệu sharded có hai “đường đi” truy vấn rất khác nhau. Hiểu bạn đang ở đường nào giải thích phần lớn các bất ngờ về hiệu năng—và tại sao sharding có thể cảm thấy không thể đoán.
Truy vấn một-shard: đường nhanh
Kết quả lý tưởng là routing truy vấn tới đúng một shard. Nếu yêu cầu chứa shard key (hoặc thứ router có thể ánh xạ), hệ thống có thể gửi thẳng đến đúng nơi.
Đó là lý do các đội chú ý làm cho các đọc thông dụng “nhận biết shard key”. Một shard nghĩa là ít hops mạng hơn, thực thi đơn giản hơn, ít khóa hơn và ít phối hợp hơn. Latency chủ yếu là DB làm việc, không phải cluster tranh chấp ai xử lý.
Đọc scatter-gather: fan-out và tail latency
Khi truy vấn không thể routing chính xác (ví dụ, lọc theo trường không phải shard key), hệ thống có thể broadcast nó tới nhiều hoặc tất cả shard. Mỗi shard chạy truy vấn cục bộ, rồi router (hoặc coordinator) hợp nhất kết quả—sắp xếp, loại trùng, áp dụng limit, và kết hợp các aggregate partial.
Fan-out khuếch đại tail latency: ngay cả khi 9 shard trả nhanh, một shard chậm có thể giữ cả request làm con tin. Nó cũng nhân nhân tải: một request người dùng có thể trở thành N request tới các shard.
Join và aggregate xuyên-shard
Join giữa các shard tốn kém vì dữ liệu mà lẽ ra “nằm trong” DB giờ phải chuyền giữa các shard (hoặc tới coordinator). Ngay cả các aggregate đơn giản (COUNT, SUM, GROUP BY) cũng có thể cần kế hoạch hai pha: tính kết quả partial trên mỗi shard, rồi hợp nhất.
Hạn chế indexing: local vs global
Phần lớn hệ thống mặc định dùng index cục bộ: mỗi shard chỉ index dữ liệu của chính nó. Chúng rẻ để duy trì, nhưng không giúp routing—vì vậy truy vấn vẫn có thể scatter.
Index toàn cục có thể cho phép routing mục tiêu bằng các trường không phải shard key, nhưng chúng thêm chi phí ghi, phối hợp, và các vấn đề scale/consistency riêng.
Ghi và giao dịch xuyên-shard
Ghi là nơi sharding ngừng cảm thấy như “chỉ là mở rộng” và bắt đầu thay đổi cách bạn thiết kế tính năng. Một ghi chạm một shard có thể nhanh và đơn giản. Một ghi chạm nhiều shard có thể chậm, dễ lỗi, và khó đảm bảo chính xác.
Ghi một-shard: đường vui vẻ
Nếu mỗi request có thể routing tới đúng một shard (thường qua shard key), DB có thể dùng cơ chế transaction bình thường. Bạn có tính nguyên tử và cách ly trong shard đó, và hầu hết vấn đề vận hành trông giống như các vấn đề single-node quen thuộc—chỉ lặp lại N lần.
Ghi đa-shard: nơi độ phức tạp tăng vọt
Khi cần cập nhật dữ liệu trên hai shard trong một hành động logic (ví dụ chuyển tiền, chuyển order giữa khách, cập nhật aggregate lưu chỗ khác), bạn rơi vào lãnh thổ giao dịch phân tán.
Giao dịch phân tán khó vì cần phối hợp giữa máy có thể chậm, phân đoạn mạng, hoặc khởi động lại bất cứ lúc nào. Các giao thức kiểu two-phase commit thêm lượt vòng, có thể block khi timeout, và làm cho lỗi trở nên mơ hồ: shard B có áp dụng thay đổi trước khi coordinator chết không? Nếu client retry, có double-apply không? Nếu không retry, có mất dữ liệu không?
Các mẫu tránh ghi xuyên-shard
Một vài chiến thuật phổ biến giảm tần suất cần giao dịch đa-shard:
- Locality dữ liệu: đặt các bản ghi liên quan cùng shard (ví dụ mọi thứ cho một customer).
- Routing theo request: đảm bảo một thao tác được sở hữu bởi một shard và coi các shard khác chỉ là input đọc.
- Denormalization: sao chép một vài mảnh dữ liệu nhỏ để cập nhật không phải fan-out.
Idempotency và an toàn khi retry
Trong hệ thống sharded, retry là điều không tránh khỏi. Hãy làm các ghi idempotent bằng cách dùng ID thao tác ổn định (ví dụ idempotency key) và lưu dấu "đã áp dụng" trong DB. Như vậy nếu timeout và client retry, lần 2 sẽ là no-op thay vì double charge, đơn hàng trùng lặp, hoặc counter không nhất quán.
Tính nhất quán và replication: giữ dữ liệu đúng
Mang theo Mã nguồn
Giữ toàn quyền bằng cách xuất source code khi thiết kế đã ổn.
Sharding chia dữ liệu ra nhiều máy, nhưng không loại bỏ nhu cầu dư thừa. Replication là thứ giữ shard khả dụng khi một node chết—và cũng là thứ làm câu hỏi “hiện giờ cái gì đúng?” trở nên khó trả lời.
Replication bên trong mỗi shard
Hầu hết hệ thống replicate trong mỗi shard: một primary (leader) nhận ghi, và một hoặc nhiều replica sao chép thay đổi đó. Nếu primary chết, hệ thống promote replica (failover). Replica cũng có thể phục vụ đọc để giảm tải.
Đổi lại là thời gian. Replica có thể chậm vài mili giây—hoặc vài giây. Khoảng cách này là bình thường, nhưng quan trọng khi người dùng mong đợi “tôi vừa cập nhật, nên tôi phải thấy ngay”.
Mô hình nhất quán nói đơn giản
- Strong consistency: sau khi ghi thành công, các đọc sẽ phản ánh nó (từ góc nhìn hệ thống cam kết). Thường có nghĩa là đọc từ leader hoặc chờ replica xác nhận.
- Eventual consistency: hệ thống sẽ hội tụ, nhưng đọc có thể tạm thời trả dữ liệu cũ.
Trong setup sharded, bạn thường có tính nhất quán mạnh trong một shard và những đảm bảo yếu hơn xuyên các shard, đặc biệt với thao tác đa-shard.
“Nguồn sự thật duy nhất” khi dữ liệu bị chia
Với sharding, “nguồn sự thật duy nhất” thường có nghĩa: với mỗi mảnh dữ liệu có một nơi có thẩm quyền để ghi (thường là leader của shard đó). Nhưng trên phạm vi toàn cục, không có một máy nào có thể xác nhận tức thì trạng thái mới nhất của mọi thứ. Bạn có nhiều chân lý cục bộ cần được giữ đồng bộ qua replication.
Ràng buộc toàn cục: uniqueness, foreign keys, counters
Ràng buộc trở nên khó khi dữ liệu cần kiểm tra nằm trên các shard khác nhau:
- Uniqueness (ví dụ username): đảm bảo "không trùng bất cứ đâu" có thể cần index tập trung, một "constraint shard" chuyên dụng, hoặc workflow đặt chỗ ở tầng ứng dụng.
- Foreign keys: nếu parent và child ở shard khác nhau, DB khó enforcement referential integrity mà không cần phối hợp xuyên-shard.
- Counters (tổng toàn cục, ID tuần tự): cách naive tạo nút thắt. Các sửa phổ biến gồm dải ID theo shard, batching, hoặc chấp nhận số gần đúng.
Những lựa chọn này không chỉ là chi tiết triển khai—chúng xác định cái gọi là “đúng” cho sản phẩm của bạn.
Rebalancing và Resharding không dừng dịch vụ
Rebalancing giữ cho DB sharded dùng được khi thực tế thay đổi. Dữ liệu tăng không đều, khóa shard cân bằng drift thành skew, bạn thêm node để tăng capacity, hoặc cần retire phần cứng. Mọi điều đó có thể biến một shard thành nút cổ chai—dù thiết kế ban đầu có hoàn hảo.
Tại sao khó
Không giống DB đơn, sharding đóng vị trí dữ liệu vào logic routing. Khi bạn di chuyển dữ liệu, bạn không chỉ copy bytes—bạn thay đổi nơi truy vấn phải tới. Điều đó có nghĩa rebalancing không chỉ về storage mà còn về metadata và client.
Mẫu migration trực tuyến (copy → overlap → cutover)
Hầu hết đội hướng tới workflow online tránh việc “dừng thế giới” lớn:
- Copy: Backfill shard đích từ shard nguồn khi hệ thống vẫn live.
- Dual-write (đôi khi dual-read): Trong chuyển đổi, ghi mới vào cả hai nơi. Đọc có thể kiểm tra cả hai (hoặc dùng luật “mới thắng”) cho tới khi bạn tự tin.
- Cutover: Cập nhật shard map để router/clients gửi traffic tới vị trí mới.
- Cleanup: Dừng dual-write, xóa bản cũ, và nén/thu hồi không gian.
Bản đồ shard và hành vi client
Thay đổi shard map là sự kiện phá vỡ nếu client cache quyết định routing. Hệ thống tốt đối xử metadata routing như cấu hình: version hóa, refresh thường xuyên, và rõ ràng điều gì xảy ra khi client chạm vào khóa đã di chuyển (redirect, retry, hoặc proxy).
Rủi ro vận hành cần lên kế hoạch
Rebalancing thường gây sụt hiệu năng tạm thời (ghi thêm, cache churn, tải copy nền). Di chuyển từng phần là phổ biến—một vài range migrate trước—vì vậy bạn cần observability rõ ràng và kế hoạch rollback (ví dụ, lật map về, drain dual-write) trước khi cutover.
Hotspot và Skew: khi “chia đều” vỡ
Sharding giả định công việc sẽ trải đều. Điều bất ngờ là một cụm có thể trông “đều” trên giấy (số hàng giống nhau mỗi shard) nhưng hành xử rất không đều ở production.
Phân vùng nóng (hot keys)
Hotspot xảy ra khi một phần nhỏ không gian khóa nhận phần lớn traffic—nghĩ tới tài khoản celebrity, sản phẩm phổ biến, tenant chạy batch nặng, hoặc khóa theo thời gian mà “hôm nay” thu hút mọi ghi. Nếu những khóa đó map tới một shard, shard đó thành nút cổ chai dù shard khác nhàn rỗi.
Skew: kích thước dữ liệu vs traffic
“Skew” không chỉ một thứ:
- Data skew: một shard giữ nhiều bytes/hàng hơn (áp lực lưu trữ, backup lâu hơn, scan chậm hơn).
- Traffic skew: một shard chịu nhiều QPS hoặc truy vấn nặng hơn (CPU bão hòa, queueing, spike latency).
Chúng không luôn trùng nhau. Một shard ít dữ liệu có thể vẫn nóng nhất nếu nó sở hữu các khóa được yêu cầu nhiều nhất.
Cách phát hiện nhanh
Bạn không cần tracing phức tạp để nhận skew. Bắt đầu với dashboard per-shard:
- p95 latency mỗi shard (một shard có p95 bật lên là cờ đỏ)
- QPS (và write QPS) mỗi shard
- Dung lượng lưu trữ / kích thước bảng mỗi shard
Nếu latency một shard tăng theo QPS trong khi shard khác ổn định, bạn có hotspot.
Giải pháp giảm thiểu
Sửa chữa thường đổi đơn giản lấy cân bằng:
- Chọn khóa shard phân tán lưu lượng, không chỉ bản ghi.
- Thêm bucketing/salting cho các khóa nóng (chia một khóa logic thành nhiều bucket vật lý).
- Dùng caching cho đối tượng đọc nhiều.
- Áp rate limit hoặc quota per-tenant để bảo vệ cụm.
- Tách shard nóng (hoặc di chuyển range nóng) khi một shard không thể nguội lại.
Chế độ lỗi và debug trong hệ thống sharded
Xây dựng Sandbox Sharding
Tạo backend Go + PostgreSQL để thử nghiệm routing, metadata và truy vấn fan-out.
Sharding không chỉ thêm nhiều server—nó thêm nhiều cách để mọi thứ sai, và nhiều nơi để kiểm tra khi lỗi xảy ra. Nhiều sự cố không phải là “DB chết”, mà là “một shard chết”, hoặc “hệ thống không đồng ý dữ liệu ở đâu”.
Các chế độ lỗi phổ biến
Một vài pattern lặp lại:
- Một shard không khả dụng (crash, đĩa đầy, GC dài), gây outage từng phần: vài khách hàng hoạt động, vài người lỗi.
- Router misroute traffic, thường sau thay đổi config hoặc deploy xấu. Đọc có thể trả kết quả rỗng nếu gửi tới shard sai.
- Metadata lỗi thời/không nhất quán (ví dụ shard map, directory table). Trong di chuyển/split, các thành phần khác nhau có thể route cùng khóa khác nhau.
- Vấn đề mạng từng phần: timeout giữa router và một tập shard có thể trông như lỗi “ngẫu nhiên” và kích hoạt retry làm tăng tải.
Debug thay đổi thế nào
Trên DB một node, bạn tail một log và kiểm tra metrics. Trên hệ thống sharded, bạn cần observability theo sát một request qua các shard.
Dùng correlation ID trong mọi request và truyền từ lớp API qua routers tới mỗi shard. Kết hợp với distributed tracing để một truy vấn scatter-gather hiện rõ shard nào chậm hoặc lỗi. Metrics nên được tách per shard (latency, queue depth, error rate), nếu không shard nóng bị che trong trung bình cụm.
Sự cố về tính đúng đắn dữ liệu
Lỗi sharding thường xuất hiện như bug về tính đúng đắn:
- Trùng lặp sau retry hoặc ghi không idempotent.
- Hàng mất khi migration di chuyển dữ liệu nhưng routing vẫn trỏ tới vị trí cũ.
- Split-brain writes nếu hai view metadata cùng chấp nhận ghi cho cùng range.
Backup, restore và DR
"Restore database" trở thành "restore nhiều phần theo thứ tự đúng". Bạn có thể cần restore metadata trước, rồi từng shard, rồi xác minh ranh giới shard và routing khớp với điểm thời gian khôi phục. Kế hoạch DR nên bao gồm diễn tập chứng minh bạn có thể lắp ráp một cluster nhất quán—không chỉ phục hồi các máy đơn lẻ.
Khi không nên shard: các phương án thay thế thực tế và checklist quyết định
Sharding thường được xem như "công tắc mở rộng", nhưng nó cũng là sự tăng vĩnh viễn độ phức tạp hệ thống. Nếu bạn có thể đạt mục tiêu hiệu năng và độ tin cậy mà không chia dữ liệu qua node, thường bạn sẽ có kiến trúc đơn giản hơn, debug dễ hơn, và ít cạnh rủi ro vận hành hơn.
Các phương án thực tế thường tăng đáng kể headroom
Trước khi shard, thử các lựa chọn giữ DB logic duy nhất:
- Tối ưu chỉ mục + truy vấn: Sửa các đường chậm trước—thiếu index, truy vấn không giới hạn, join tốn, pattern N+1.
- Caching: Đặt phản hồi đọc nhiều phía sau cache (cache tầng ứng dụng, CDN cho nội dung công khai, hoặc cache in-memory cho khóa nóng).
- Read replicas: Cắt tải đọc mà không thay đổi đường ghi (và chấp nhận replica lag khi được phép).
- Partitioned tables trên một node: Nhiều DB hỗ trợ partitioning table giúp bảo trì và hiệu năng mà không cần routing cross-node.
Công cụ giúp: prototype dịch vụ nhận biết shard mà không commit quá sớm
Một cách thực tế giảm rủi ro sharding là prototype plumbing (ranh giới routing, idempotency, workflow migration, và observability) trước khi cam kết DB production.
Ví dụ, với Koder.ai bạn có thể nhanh chóng dựng một dịch vụ nhỏ thực tế từ chat—thường là UI admin React kèm backend Go với PostgreSQL—và thử API nhận biết shard key, idempotency key, và hành vi cutover trong môi trường an toàn. Vì Koder.ai hỗ trợ chế độ planning, snapshot/rollback, và xuất source, bạn có thể lặp các quyết định thiết kế liên quan sharding (như routing và hình dạng metadata) rồi mang mã và runbook sang stack chính khi tự tin.
Khi sharding phù hợp (và khi không)
Sharding phù hợp hơn khi dataset hoặc throughput ghi rõ ràng vượt quá giới hạn single-node và mẫu truy vấn của bạn có thể sử dụng shard key đáng tin cậy (ít cross-shard join, ít truy vấn scatter-gather).
Nó không phù hợp khi sản phẩm cần nhiều truy vấn ad-hoc, giao dịch nhiều thực thể thường xuyên, ràng buộc uniqueness toàn cục, hoặc khi đội không thể chịu khối lượng vận hành (rebalancing, resharding, ứng cứu sự cố).
Checklist quyết định nhanh
Hãy hỏi:
- Workload: Núi thắt là CPU, I/O, bộ nhớ, hay contention khóa—và có sửa được mà không sharding không?
- Query patterns: Có thể route 90%+ truy vấn quan trọng bằng shard key không?
- Năng lực đội: Ai chịu trách nhiệm shard mapping, runbook on-call, và hành vi giao dịch xuyên-shard?
- SLOs: Bạn có chịu được suy giảm từng phần (một shard down) và tail latency dài hơn không?
Lên kế hoạch cho tăng trưởng, không chỉ một sơ đồ
Dù bạn tạm hoãn sharding, hãy thiết kế đường di chuyển: chọn identifier không cản trở shard key tương lai, tránh hard-code giả định single-node, và diễn tập cách bạn di chuyển dữ liệu với downtime tối thiểu. Thời điểm tốt nhất để lên kế hoạch resharding là trước khi bạn cần nó.