Nội dung bài viết này (và tại sao nó quan trọng)
Snowflake làm phổ biến một ý tưởng đơn giản nhưng có tầm ảnh hưởng lớn trong kho dữ liệu đám mây: tách riêng lưu trữ dữ liệu và compute để xử lý truy vấn. Sự tách này thay đổi hai vấn đề thường gặp hàng ngày của các đội dữ liệu—cách kho dữ liệu mở rộng và cách bạn trả tiền cho chúng.
Thay vì xem kho dữ liệu như một “hộp” cố định (nơi càng nhiều người dùng, càng nhiều dữ liệu, hoặc truy vấn phức tạp đều cạnh tranh cùng tài nguyên), mô hình của Snowflake cho phép bạn lưu dữ liệu một lần và khởi tạo đúng lượng compute khi cần. Kết quả thường là thời gian trả lời nhanh hơn, ít tắc nghẽn vào giờ cao điểm, và kiểm soát rõ hơn những gì tốn tiền (và khi nào).
Chủ đề #1: hiệu năng và mở rộng mà không phải đánh đổi như trước
Bài viết này giải thích, bằng ngôn ngữ đơn giản, tách lưu trữ và compute thực sự nghĩa là gì—và điều đó ảnh hưởng ra sao tới:
- Độ đồng thời (nhiều người chạy truy vấn cùng lúc)
- Mở rộng đàn hồi (tăng/giảm compute khi cần)
- Hành vi chi phí (chỉ trả cho compute khi nó chạy, cộng chi phí lưu trữ liên tục)
Chúng tôi cũng sẽ chỉ ra nơi mô hình không phải là phép màu—vì một số bất ngờ về chi phí và hiệu năng đến từ cách thiết kế workload, chứ không phải nền tảng.
Chủ đề #2: tại sao hệ sinh thái quan trọng không kém hiệu năng thuần túy
Một nền tảng nhanh không phải là toàn bộ câu chuyện. Với nhiều đội, thời gian để tạo giá trị phụ thuộc vào việc bạn có thể dễ dàng kết nối kho dữ liệu với công cụ mà bạn đang dùng hay không—pipeline ETL/ELT, dashboard BI, công cụ catalog/quản trị, kiểm soát bảo mật, và nguồn dữ liệu từ đối tác.
Hệ sinh thái của Snowflake (bao gồm mẫu chia sẻ dữ liệu và phân phối theo kiểu marketplace) có thể rút ngắn thời gian triển khai và giảm engineering tùy chỉnh. Bài viết này trình bày “độ sâu hệ sinh thái” trông như thế nào trong thực tế, và cách đánh giá nó cho tổ chức của bạn.
Dành cho ai
Hướng dẫn này viết cho lãnh đạo dữ liệu, analyst và những người ra quyết định không chuyên—bất kỳ ai cần hiểu trade-off đằng sau kiến trúc Snowflake, mở rộng, chi phí và lựa chọn tích hợp mà không bị chôn trong jargon của nhà cung cấp.
Trước khi tách: vì sao các kho truyền thống gặp giới hạn
Các kho dữ liệu truyền thống được xây quanh một giả định đơn giản: bạn mua (hoặc thuê) một lượng phần cứng cố định, rồi chạy mọi thứ trên cùng một hộp hoặc cụm. Cách làm đó hiệu quả khi workload dự đoán được và tăng trưởng từ từ—nhưng tạo ra giới hạn cấu trúc khi khối lượng dữ liệu và số người dùng tăng nhanh.
Mô hình cổ điển: cụm cố định và lập kế hoạch công suất cẩn thận
Các hệ on-prem (và triển khai cloud “lift-and-shift” ban đầu) thường trông như sau:
- Một cụm MPP (xử lý song song quy mô lớn) xử lý lưu trữ, CPU và bộ nhớ cùng nhau.
- Bạn phải chọn kích thước cụm cho nhu cầu đỉnh, vì thay đổi kích thước chậm, rủi ro, hoặc cần downtime.
- Lập kế hoạch năng lực trở thành dự án định kỳ: dự báo tăng trưởng, chứng minh ngân sách, đặt phần cứng, cài đặt, di chuyển.
Ngay cả khi nhà cung cấp cung cấp “node” thêm, kiểu mẫu lõi vẫn giống: mở rộng thường nghĩa là thêm node lớn hơn hoặc nhiều hơn vào cùng một môi trường chia sẻ.
Những điểm đau: mở rộng chậm, chi phí lãng phí, và queue
Thiết kế này tạo vài khó khăn phổ biến:
- Mở rộng chậm: Nếu giờ báo cáo quý cần thêm sức mạnh, bạn không luôn có thể tăng nhanh. Bạn hoặc chờ, hoặc cấu hình dư “vì phòng trường hợp.”
- Tài nguyên nhàn rỗi: Cụm được kích cho đỉnh hoạt động thường bị dùng dưới mức phần lớn thời gian—nhưng bạn vẫn trả tiền cho chúng.
- Queue khi tải cao: Khi nhiều đội chạy truy vấn cùng lúc, họ tranh tài nguyên. Job nặng có thể chặn dashboard tương tác, dẫn tới timeout và các quy tắc kiểu “đừng chạy truy vấn đó trong giờ làm việc.”
Công cụ và tích hợp: mạnh mẽ nhưng thường dễ vỡ
Vì những kho này gắn chặt với môi trường, tích hợp thường phát triển theo cách hữu cơ: script ETL tùy chỉnh, connector viết tay, pipeline một lần. Chúng hoạt động—cho tới khi schema thay đổi, hệ thống nguồn di chuyển, hoặc công cụ mới được thêm vào. Giữ mọi thứ chạy có thể giống như bảo trì liên tục thay vì tiến triển ổn định.
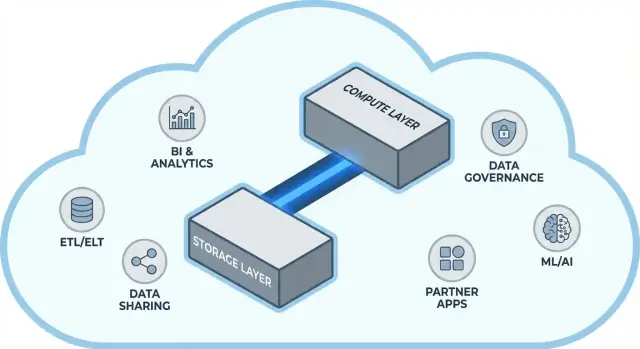
Ý tưởng lõi: tách lưu trữ và compute
Các kho truyền thống thường buộc hai nhiệm vụ rất khác nhau vào cùng một chỗ: storage (nơi dữ liệu nằm) và compute (sức mạnh xử lý đọc, join, aggregate và ghi dữ liệu đó).
Storage vs. compute (ngôn ngữ dễ hiểu)
Storage giống như một kho tàng lâu dài: bảng, file và metadata được giữ an toàn và rẻ, thiết kế để bền và luôn sẵn sàng.
Compute giống như đội bếp: là tập hợp CPU và bộ nhớ thực hiện “nấu” truy vấn của bạn—chạy SQL, sắp xếp, quét, xử lý dữ liệu và trả kết quả cho nhiều người cùng lúc.
Chuyển đổi then chốt: mở rộng độc lập
Snowflake tách hai phần này để bạn có thể điều chỉnh từng phần mà không buộc phần kia phải thay đổi.
- Nếu dung lượng dữ liệu tăng, bạn thêm storage (thường theo từng bước và tương đối dễ dự đoán).
- Nếu lưu lượng báo cáo tăng đột biến, bạn thêm compute (bằng cách thay đổi kích thước hoặc thêm virtual warehouses) mà không cần di chuyển hay nhân bản dữ liệu.
Thực tế, điều này thay đổi vận hành hàng ngày: bạn không cần “mua dư” compute chỉ vì storage đang tăng, và bạn có thể cô lập workload (ví dụ, analyst vs. ETL) để chúng không làm chậm nhau.
Không phải là phép màu
Sự tách này mạnh mẽ, nhưng không phải là phép màu.
- Nó không phải là “tăng không giới hạn miễn phí.” Thêm hoặc nâng kích thước warehouses thông thường đồng nghĩa tốn nhiều compute hơn.
- Nó không tự động tiết kiệm mọi lúc. Truy vấn viết kém, lịch làm mới không cần thiết, hoặc warehouses luôn bật vẫn có thể đốt credits.
- Nó không phải là lý do để bỏ qua kế hoạch. Bạn vẫn phải chọn kích thước warehouse, đặt auto-suspend, và căn chỉnh compute với mô hình sử dụng kinh doanh.
Giá trị là quyền kiểm soát: trả cho storage và compute theo cách riêng của từng loại, và ghép từng loại với nhu cầu thực tế của đội bạn.
Kiến trúc Snowflake ở dạng đơn giản
Snowflake dễ hiểu nhất như ba lớp kết hợp với nhau, nhưng có thể mở rộng độc lập.
1) Storage: object storage của đám mây
Bảng của bạn cuối cùng tồn tại dưới dạng file dữ liệu trong object storage của nhà cung cấp (S3, Azure Blob, hoặc GCS). Snowflake quản lý định dạng file, nén, và tổ chức cho bạn. Bạn không “gắn ổ đĩa” hay phải định kích thước volume—storage tăng khi dữ liệu tăng.
2) Compute: virtual warehouses
Compute được đóng gói thành virtual warehouses: các cụm CPU/bộ nhớ độc lập thực thi truy vấn. Bạn có thể chạy nhiều warehouse trên cùng dữ liệu cùng lúc. Đây là khác biệt chủ chốt so với hệ cũ, nơi workload nặng thường cạnh tranh trong cùng một pool tài nguyên.
Một lớp dịch vụ riêng xử lý “bộ não” của hệ thống: xác thực, phân tích và tối ưu truy vấn, quản lý giao dịch/metadata, và điều phối. Lớp này quyết định cách chạy một truy vấn hiệu quả trước khi compute chạm vào dữ liệu.
Dòng xử lý truy vấn
Khi bạn gửi SQL, lớp dịch vụ của Snowflake phân tích nó, xây kế hoạch thực thi, rồi giao kế hoạch đó cho một virtual warehouse được chọn. Warehouse chỉ đọc những file dữ liệu cần thiết từ object storage (và tận dụng cache khi có thể), xử lý chúng và trả kết quả—mà không di chuyển dữ liệu gốc vào warehouse một cách cố định.
Đồng thời và cô lập (không dùng thuật ngữ phức tạp)
Nếu nhiều người chạy truy vấn cùng lúc, bạn có thể:
- dùng warehouses riêng cho các đội/workload khác nhau (cô lập workload), hoặc
- bật multi-cluster warehouses để Snowflake tự động thêm cụm compute khi nhu cầu tăng vọt rồi thu lại.
Đó là nền tảng kiến trúc phía sau hiệu năng của Snowflake và kiểm soát “hàng xóm ồn ào”.
Mở rộng và đồng thời: điều gì thực sự thay đổi
Bước chuyển lớn của Snowflake là bạn mở rộng compute độc lập với dữ liệu. Thay vì “kho dữ liệu trở nên lớn hơn”, bạn có thể điều chỉnh tài nguyên theo từng workload—mà không cần sao chép bảng, chia lại phân vùng đĩa, hay lên lịch downtime.
Đàn hồi: thay đổi compute mà không dịch dữ liệu
Trong Snowflake, một virtual warehouse là engine compute chạy truy vấn. Bạn có thể thay đổi kích thước nó (ví dụ từ Small lên Large) trong vài giây, và dữ liệu vẫn nằm nguyên trên storage chung. Điều đó biến việc tinh chỉnh hiệu năng thành câu hỏi đơn giản: “Workload này có cần thêm sức mạnh ngay bây giờ không?”
Điều này cũng cho phép tăng đột biến tạm thời: nâng cấp cho kỳ đóng sách cuối tháng, rồi hạ xuống khi đỉnh qua đi.
Đồng thời: ít tranh chấp hơn
Hệ thống truyền thống buộc nhiều đội chia sẻ cùng compute, biến giờ cao điểm thành hàng đợi ở quầy.
Snowflake cho phép bạn chạy warehouses riêng cho từng đội hoặc workload—ví dụ, một cho analyst, một cho dashboard, một cho ETL. Vì các warehouses này đọc cùng dữ liệu nền, bạn giảm vấn đề “dashboard của tôi làm chậm báo cáo của bạn” và làm cho hiệu năng dự đoán hơn.
Các đánh đổi bạn sẽ gặp
Compute đàn hồi không phải là thành công tự động. Một số rủi ro phổ biến gồm:
- Khởi động lạnh: warehouses bị suspend rồi resume mất vài giây, có thể thêm độ trễ cho job ít chạy.
- Chọn kích thước: quá lớn lãng phí tiền; quá nhỏ gây query chậm và khó chịu.
- Cần có guardrails: bật auto-suspend/auto-resume, dùng resource monitors, và phân quyền rõ ràng để tránh warehouses chạy nhàn hoặc lan tràn.
Thay đổi tổng thể: việc mở rộng và xử lý độ đồng thời chuyển từ thành dự án hạ tầng sang quyết định vận hành hàng ngày.
Mô hình chi phí: chỗ nào tiết kiệm và chỗ nào không
Get rewarded for sharing
Chia sẻ câu chuyện xây dựng hoặc giới thiệu đồng nghiệp để nhận credits dùng Koder.ai.
Cách Snowflake tính phí thực tế
Snowflake theo kiểu “trả cho những gì dùng” với hai đồng hồ chạy song song:
- Compute: tính theo thời gian virtual warehouse chạy (bằng credits). Nếu nó bật, đồng hồ chạy.
- Storage: tính theo dung lượng dữ liệu lưu trữ (cộng thêm cho các tính năng như Time Travel/Fail-safe).
Chính sự tách này là nơi có thể tiết kiệm: bạn có thể giữ nhiều dữ liệu với chi phí tương đối rẻ trong khi chỉ bật compute khi cần.
Nơi chi phí dễ tăng vọt
Hầu hết chi phí “bất ngờ” đến từ hành vi compute hơn là lưu trữ. Các nguyên nhân thường gặp gồm:
- Warehouse quá lớn (chọn kích thước lớn hơn nhu cầu)
- Workload luôn bật (warehouses để chạy qua đêm hoặc cuối tuần)
- Truy vấn không hiệu quả (quét không lọc, join không cần thiết, phép biến đổi nặng chạy lặp)
- Mẫu concurrency cao (nhiều dashboard nhỏ refresh liên tục)
Tách storage và compute không tự biến truy vấn thành hiệu quả—SQL kém vẫn tiêu tốn credits nhanh.
Các biện pháp thực dụng hiệu quả
Bạn không cần phòng tài chính quản lý việc này—chỉ vài guardrail:
- Auto-suspend / auto-resume để dừng trả tiền cho thời gian nhàn rỗi
- Resource monitors để cảnh báo hoặc giới hạn tiêu dùng credits theo warehouse/nhóm
- Lên lịch (chạy batch theo cửa sổ định nghĩa; tạm dừng dev/test ngoài giờ làm)
- Right-sizing và thử nghiệm kích thước nhỏ hơn trước khi scale up
Dùng đúng, mô hình thưởng cho kỷ luật: compute ngắn hạn, kích thước phù hợp ghép với tăng trưởng storage có thể dự đoán.
Chia sẻ dữ liệu và cộng tác như tính năng quan trọng
Snowflake xem chia sẻ là thứ được thiết kế ngay từ đầu—không phải là miếng ghép thêm vào export, drop file, hay ETL một lần.
Chia sẻ mà không cần sao chép (trong nhiều trường hợp)
Thay vì gửi extract đi, Snowflake cho phép account khác truy vấn cùng dữ liệu thông qua “share” bảo mật. Trong nhiều kịch bản, dữ liệu không cần nhân bản vào warehouse thứ hai hay đẩy ra object storage để tải xuống. Người tiêu thụ thấy database/table chia sẻ như thể nó là local, còn bên cung cấp vẫn kiểm soát những gì được phơi bày.
Cách tiếp cận “tách rời” này có giá trị vì giảm tràn dữ liệu, tăng tốc truy cập và giảm số pipeline bạn phải xây và duy trì.
Mẫu cộng tác phổ biến
Chia sẻ cho đối tác và khách hàng: Nhà cung cấp có thể xuất bản các dataset đã tuyển chọn cho khách hàng (ví dụ: phân tích sử dụng hoặc dữ liệu tham chiếu) với ranh giới rõ ràng—chỉ schema, bảng hoặc view được phép.
Chia sẻ nội bộ giữa các miền: Các đội trung tâm có thể phơi bày dataset chứng nhận cho product, finance và operations mà không bắt mọi đội phải tạo bản sao. Điều này hỗ trợ văn hóa “một bộ số liệu” trong khi vẫn cho phép mỗi đội chạy compute riêng.
Cộng tác có quản trị: Dự án chung (với agency, nhà cung cấp, hoặc công ty con) có thể làm việc trên dataset chia sẻ trong khi giữ các cột nhạy cảm bị mask và ghi nhật ký truy cập.
Hạn chế cần tính tới
Chia sẻ không phải là “đặt và quên.” Bạn vẫn cần:
- Quản trị: quyền sở hữu rõ ràng, rà soát truy cập, và chính sách cho PII/dữ liệu quy định.
- Hợp đồng và kỳ vọng: ai trả compute, SLA, retention, và điều gì xảy ra khi định nghĩa thay đổi.
- Khả năng khám phá: nếu không có catalog và đặt tên tốt, mọi người sẽ không tìm hoặc không tin dữ liệu chia sẻ. Đồng bộ shares với tài liệu và catalog (nếu có).
Tại sao hệ sinh thái quan trọng không kém hiệu năng
Một kho nhanh là có lợi, nhưng tốc độ hiếm khi quyết định một dự án có triển khai đúng hạn. Thường thì yếu tố quyết định là hệ sinh thái xung quanh nền tảng: các kết nối sẵn có, công cụ và chuyên môn giúp giảm công tùy biến.
Hệ sinh thái với nền tảng dữ liệu nghĩa là gì
Trong thực tế, hệ sinh thái bao gồm:
- Connectors tới nguồn và đích dữ liệu (ứng dụng SaaS, cơ sở dữ liệu, công cụ streaming)
- Công cụ đối tác cho ingest, transform, BI, chất lượng dữ liệu và observability
- Ứng dụng và tích hợp gốc chạy gần dữ liệu
- Mẫu và kiến trúc tham khảo (mô hình phổ biến, pattern, hướng dẫn triển khai)
- Kiến thức cộng đồng: ví dụ, forum, meetup và nguồn tuyển dụng
Tại sao hệ sinh thái có thể quyết định tốc độ triển khai
Benchmark đo một lát cắt hẹp của hiệu năng trong điều kiện kiểm soát. Dự án thực tế dành phần lớn thời gian cho:
- Đưa dữ liệu vào đáng tin cậy và theo lô
- Mô hình hóa, test và tài liệu dataset
- Tác vụ vận hành (giám sát, cảnh báo, kiểm soát chi phí)
- Rà soát bảo mật, quyền truy cập và audit
Nếu nền tảng của bạn có tích hợp trưởng thành cho những bước này, bạn tránh được việc xây glue code. Thông thường điều này rút ngắn thời gian triển khai, cải thiện độ tin cậy và dễ thay đổi đội hoặc nhà cung cấp mà không viết lại mọi thứ.
Ống kính đánh giá đơn giản: bao phủ, chất lượng, dễ duy trì
Khi đánh giá hệ sinh thái, tìm:
- Bao phủ: nó hỗ trợ nguồn chính, công cụ BI, orchestration và nhu cầu quản trị của bạn không?
- Chất lượng: các connector được duy trì tích cực, có tài liệu tốt, và đã chứng minh ở quy mô của bạn?
- Dễ duy trì: cần bao nhiêu công sức duy trì—nâng cấp, thay đổi phá vỡ, gỡ lỗi, hỗ trợ?
Hiệu năng cho bạn khả năng; hệ sinh thái thường quyết định bạn có thể biến khả năng đó thành kết quả kinh doanh nhanh thế nào.
Hệ sinh thái tích hợp: đưa dữ liệu vào, đưa ra và sử dụng
Make governance usable
Thiết lập quy trình yêu cầu dữ liệu được quản trị đơn giản mà các đội thực sự dùng được.
Snowflake có thể chạy truy vấn nhanh, nhưng giá trị xuất hiện khi dữ liệu di chuyển tin cậy qua stack của bạn: từ nguồn, vào Snowflake, rồi ra công cụ mà người dùng cuối sử dụng hàng ngày. “Chặng cuối” thường quyết định nền tảng trông dễ dùng hay luôn mong manh.
Các loại tích hợp chính cần lên kế hoạch
Phần lớn đội cần hỗn hợp:
- ELT/ETL để ingest từ database, ứng dụng SaaS, file và object storage.
- BI và analytics cho dashboard, khám phá tự phục vụ và semantic layer.
- Reverse ETL để đẩy dữ liệu đã tuyển sang CRM, marketing và hệ thống hỗ trợ.
- Orchestration cho lên lịch, phụ thuộc, backfill và promote môi trường.
- Streaming cho sự kiện gần thời gian thực và change data capture.
- Công cụ ML cho pipeline feature, workflow huấn luyện và giám sát model.
Câu hỏi nên hỏi trước khi chọn connector
Không phải mọi công cụ “tương thích Snowflake” đều giống nhau. Khi đánh giá, tập trung vào chi tiết thực tế:
- Connector có được chứng nhận/hỗ trợ (bởi ai)? Quy trình eskalation là gì?
- Nó có xử lý tải gia tăng từng phần sạch sẽ không (CDC, timestamp, high-water mark)?
- Nó đối phó với schema drift—thêm cột, thay đổi kiểu, xóa trường—như thế nào?
- Bảo đảm về retry, deduplication, và exactly-once vs at-least-once ra sao?
Đừng bỏ qua vận hành
Tích hợp cần sẵn sàng cho ngày-2: giám sát và cảnh báo, kết nối lineage/catalog, và quy trình phản ứng sự cố (ticketing, on-call, runbook). Một hệ sinh thái mạnh không chỉ có nhiều logo—mà còn ít bất ngờ khi pipeline hỏng lúc 2 giờ sáng.
Quản trị, bảo mật và tin cậy ở quy mô lớn
Khi đội phát triển, phần khó nhất của analytics thường không phải tốc độ—mà là đảm bảo đúng người truy cập đúng dữ liệu với bằng chứng rằng các kiểm soát hoạt động. Các tính năng quản trị của Snowflake thiết kế cho thực tế đó: nhiều người dùng, nhiều sản phẩm dữ liệu và chia sẻ thường xuyên.
Những điều cơ bản quản trị thực tế
Bắt đầu với vai trò rõ ràng và tư duy ít quyền nhất. Thay vì cấp truy cập trực tiếp cho cá nhân, định nghĩa các role như ANALYST_FINANCE hoặc ETL_MARKETING, rồi cấp quyền cho những role đó tới database, schema, table, và khi cần, view.
Với các trường nhạy cảm (PII, định danh tài chính), dùng masking policies để người dùng có thể truy vấn dataset mà không thấy giá trị gốc trừ khi role cho phép. Kết hợp với auditing: ghi lại ai truy vấn gì và khi nào, để nhóm bảo mật và tuân thủ trả lời câu hỏi mà không phải suy đoán.
Tại sao quản trị thay đổi chia sẻ và tự phục vụ
Quản trị tốt làm cho chia sẻ dữ liệu an toàn và dễ mở rộng. Khi mô hình chia sẻ dựa trên role, policy và truy vết, bạn có thể bật tự phục vụ (nhiều người khám phá dữ liệu) mà không mở cửa cho lộ dữ liệu vô tình.
Nó cũng giảm ma sát cho tuân thủ: policy trở thành kiểm soát lặp lại thay vì ngoại lệ một lần. Điều này quan trọng khi dataset được tái sử dụng giữa dự án, phòng ban hoặc đối tác bên ngoài.
Mẹo thực tế tránh đau sau này
- Quy tắc đặt tên: chuẩn hóa tên database/schema để báo hiệu mục đích và độ nhạy (ví dụ
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Tính nhất quán giúp rà soát nhanh và giảm sai sót.
- Tách môi trường: giữ DEV/TEST/PROD tách biệt hợp lý, với kiểm soát chặt hơn ở PROD. Xem dữ liệu production là ngoại lệ, không phải mặc định.
- Rà soát truy cập: đặt nhịp điệu (hàng tháng cho dữ liệu nguy cơ cao, hàng quý cho phần còn lại). Rà soát membership của role, người dùng không còn hoạt động và role đặc quyền.
Tin cậy ở quy mô không phải về một kiểm soát “hoàn hảo” mà là hệ thống các thói quen nhỏ, đáng tin cậy giữ truy cập có chủ ý và có thể giải trình.
Workload và các pattern thực hành tốt
Turn SQL into an app
Tạo nhanh giao diện React và khung API Go cho các truy vấn trong kho dữ liệu của bạn.
Snowflake thể hiện tốt khi nhiều người và công cụ cần truy vấn cùng dữ liệu cho các mục đích khác nhau. Vì compute được đóng gói vào các “warehouses” độc lập, bạn có thể ánh xạ từng workload tới hình dạng và lịch phù hợp.
Ánh xạ workload phổ biến
Analytics & dashboards: Đặt BI trên một warehouse riêng kích thước cho truy vấn ổn định, dự đoán được. Điều này giữ các refresh dashboard không bị chậm do phân tích ad hoc.
Phân tích ad hoc: Cấp cho analyst một warehouse riêng (thường nhỏ hơn) với auto-suspend bật. Bạn có thể lặp nhanh mà không trả tiền cho thời gian nhàn rỗi.
Data science & thử nghiệm: Dùng warehouse cho các quét lớn và spike thỉnh thoảng. Nếu thí nghiệm tăng đột biến, nâng kích thước tạm thời mà không ảnh hưởng tới người dùng BI.
Data apps & embedded analytics: Xử lý traffic ứng dụng như dịch vụ production—warehouse riêng, timeout bảo thủ, và resource monitors để tránh chi phí bất ngờ.
Nếu bạn xây ứng dụng nội bộ nhẹ (ví dụ, portal ops lấy query từ Snowflake và hiển thị KPI), một con đường nhanh là tạo scaffold React + API và lặp với stakeholders. Các nền tảng như Koder.ai (một nền tảng vibe-coding tạo web/server/mobile từ chat) có thể giúp đội prototype các ứng dụng dùng Snowflake nhanh, rồi xuất mã nguồn khi sẵn sàng vận hành.
Pattern thực hành tốt bền vững
Quy tắc đơn giản: tách warehouses theo khán giả và mục đích (BI, ELT, ad hoc, ML, app). Kết hợp với thói quen truy vấn tốt—tránh SELECT * rộng, lọc sớm, và cảnh giác join không hiệu quả. Ở phía mô hình hóa, ưu tiên cấu trúc phù hợp cách người dùng truy vấn (thường là một semantic layer sạch hoặc marts rõ ràng) thay vì tối ưu hóa quá mức bố cục vật lý.
Khi cân nhắc lựa chọn thay thế hoặc bổ sung
Snowflake không thay thế mọi thứ. Với workload giao dịch throughput cao, độ trễ thấp (OLTP), một cơ sở dữ liệu chuyên dụng thường phù hợp hơn; Snowflake dùng cho analytics, báo cáo, chia sẻ và sản phẩm dữ liệu hạ nguồn. Các thiết lập hybrid là phổ biến và thường thực tế nhất.
Cân nhắc khi di chuyển: chuẩn bị những gì trước khi chuyển
Migration lên Snowflake hiếm khi là “lift and shift.” Sự tách storage/compute thay đổi cách bạn định kích thước, tinh chỉnh và trả tiền cho workload—vì vậy lập kế hoạch trước tránh bất ngờ sau này.
Trình tự migration thực tế
Bắt đầu bằng kiểm kê: nguồn dữ liệu nào cấp cho kho, pipeline nào biến đổi, dashboard nào phụ thuộc, và ai đang giữ quyền sở hữu từng phần. Sau đó ưu tiên theo ảnh hưởng kinh doanh và độ phức tạp (ví dụ: báo cáo tài chính quan trọng trước, sandbox thử nghiệm sau).
Tiếp theo, chuyển đổi SQL và logic ETL. Phần lớn SQL chuẩn chuyển được, nhưng chi tiết như hàm, xử lý ngày giờ, mã thủ tục và pattern temp-table thường cần viết lại. Xác thực kết quả sớm: chạy output song song, so sánh số dòng và tổng hợp, và kiểm tra các trường hợp biên (null, timezone, logic dedup). Cuối cùng, lập kế hoạch cutover: window freeze, đường hồi quy, và “định nghĩa hoàn thành” rõ ràng cho từng dataset và báo cáo.
Rủi ro điển hình cần chú ý
Phụ thuộc ẩn là phổ biến nhất: extract trên spreadsheet, chuỗi kết nối hard-coded, job hạ nguồn mà không ai nhớ. Bất ngờ về hiệu năng xảy ra khi các giả định tuning cũ không còn phù hợp (ví dụ: dùng warehouses quá nhỏ, hoặc chạy nhiều truy vấn nhỏ mà không tính tới concurrency). Tăng chi phí thường do để warehouses chạy, retry không kiểm soát, hoặc trùng lặp dev/test workloads. Lỗ hổng quyền xảy ra khi di từ role thô sang quản trị chi tiết hơn—bài test nên bao gồm chạy dưới quyền “least privilege”.
Quản lý thay đổi (đừng bỏ qua)
Đặt mô hình sở hữu (ai sở hữu dữ liệu, pipeline, chi phí), đào tạo theo vai trò cho analyst và engineer, và xác định kế hoạch hỗ trợ cho vài tuần đầu sau cutover (on-call rotation, runbook sự cố, và nơi báo issue).
Cách đánh giá một nền tảng: câu hỏi cần hỏi (và kế hoạch pilot)
Chọn nền tảng dữ liệu hiện đại không chỉ là về tốc độ benchmark cao nhất. Làm sao nền tảng phù hợp với workload thực tế, cách làm việc của đội, và công cụ bạn đã dựa vào?
Checklist đánh giá thực tế
Dùng các câu hỏi sau để hướng shortlist và cuộc trò chuyện với nhà cung cấp:
- Workloads: Bạn chủ yếu chạy dashboard theo lịch, phân tích ad-hoc, data science, ELT/ETL, hay ứng dụng khách hàng? Bạn cần cửa sổ batch dự đoán hay khả năng burst đàn hồi?
- Nhu cầu đồng thời: Bao nhiêu người (hoặc ứng dụng) sẽ truy vấn cùng lúc, và mức độ “spiky” của giờ cao điểm thế nào?
- Yêu cầu chia sẻ dữ liệu: Bạn cần chia dữ liệu trực tiếp với đối tác, đơn vị kinh doanh, hay khách hàng mà không gửi file? Bạn có dự định tiêu thụ datasets từ bên thứ ba?
- Phù hợp công cụ: BI, orchestration, catalog và workflow CI/CD của bạn tích hợp mượt không? Điều gì hỏng nếu bạn chuyển?
- Quản trị và bảo mật: Bạn cần kiểm soát truy cập tinh vi, trail audit, masking, retention, và phân tách nhiệm vụ rõ ràng không?
- Hạn chế chi phí: Chi phí nào quan trọng nhất—chi phí trạng thái ổn định, chi phí giờ cao điểm, hay khả năng tắt compute? Bạn sẽ ngăn “luôn bật” ra sao?
Kế hoạch pilot ngắn (2–4 tuần)
Chọn 2–3 dataset đại diện (không phải mẫu bé): một fact lớn, một nguồn bán cấu trúc rối, và một miền “quan trọng với kinh doanh”.
Rồi chạy truy vấn người dùng thực: dashboard giờ cao điểm buổi sáng, phân tích ad-hoc của analyst, nạp theo lịch, và vài join trường hợp xấu nhất. Theo dõi: thời gian truy vấn, hành vi concurrency, thời gian ingest, nỗ lực vận hành, và chi phí theo workload.
Nếu một phần đánh giá của bạn là “bao nhanh có thể bàn giao cho người dùng,” cân nhắc thêm một deliverable nhỏ vào pilot—ví dụ một ứng dụng metrics nội bộ hoặc quy trình yêu cầu dữ liệu được quản trị truy vấn Snowflake. Xây lớp mỏng đó thường phơi bày thực tế tích hợp và bảo mật nhanh hơn benchmark, và các công cụ như Koder.ai có thể đẩy nhanh chu trình prototype→production bằng cách tạo cấu trúc app qua chat và cho phép xuất mã nguồn để duy trì lâu dài.
Bước tiếp theo gợi ý
Nếu bạn muốn trợ giúp ước tính chi phí và so sánh lựa chọn, bắt đầu với trang Định giá.
Với hướng dẫn về migration và quản trị, tham khảo thêm trong blog.